 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Increasing the Accuracy of a Neural Network Using Frequency Selective Mesh-to-Grid Resampling
Sep 28, 2022

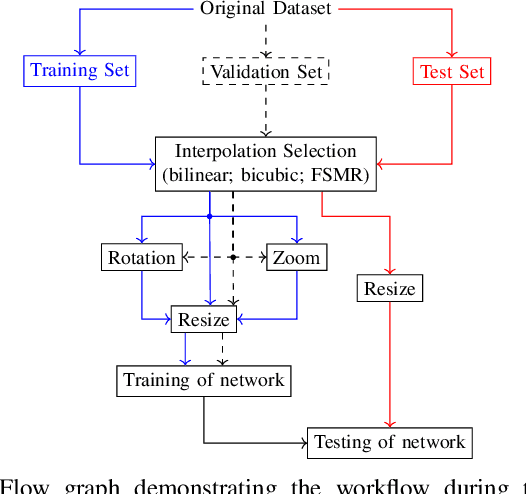
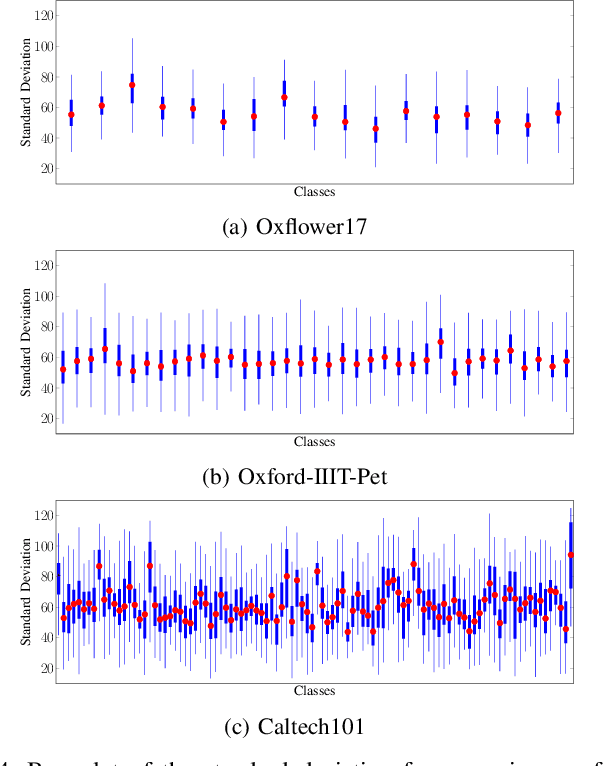
Neural networks are widely used for almost any task of recognizing image content. Even though much effort has been put into investigating efficient network architectures, optimizers, and training strategies, the influence of image interpolation on the performance of neural networks is not well studied. Furthermore, research has shown that neural networks are often sensitive to minor changes in the input image leading to drastic drops of their performance. Therefore, we propose the use of keypoint agnostic frequency selective mesh-to-grid resampling (FSMR) for the processing of input data for neural networks in this paper. This model-based interpolation method already showed that it is capable of outperforming common interpolation methods in terms of PSNR. Using an extensive experimental evaluation we show that depending on the network architecture and classification task the application of FSMR during training aids the learning process. Furthermore, we show that the usage of FSMR in the application phase is beneficial. The classification accuracy can be increased by up to 4.31 percentage points for ResNet50 and the Oxflower17 dataset.
A clinically motivated self-supervised approach for content-based image retrieval of CT liver images
Jul 11, 2022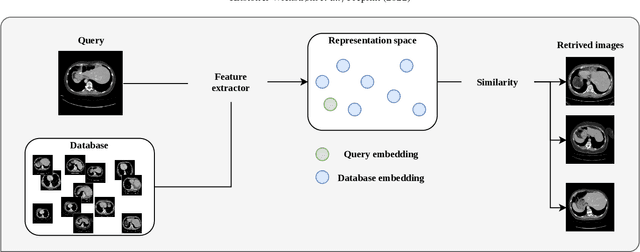
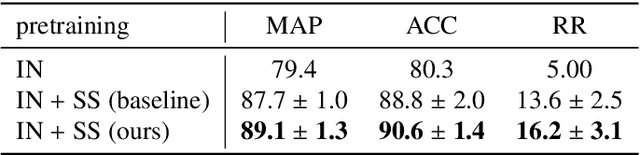
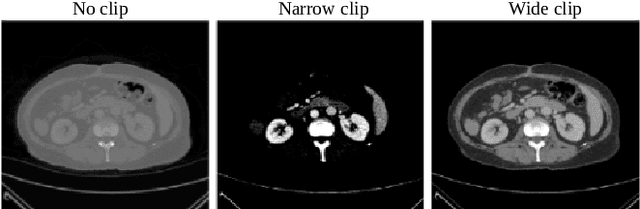
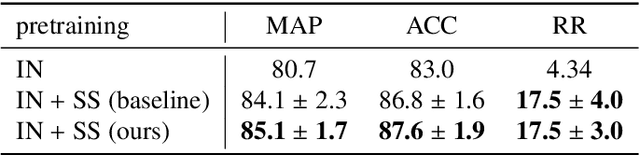
Deep learning-based approaches for content-based image retrieval (CBIR) of CT liver images is an active field of research, but suffers from some critical limitations. First, they are heavily reliant on labeled data, which can be challenging and costly to acquire. Second, they lack transparency and explainability, which limits the trustworthiness of deep CBIR systems. We address these limitations by (1) proposing a self-supervised learning framework that incorporates domain-knowledge into the training procedure and (2) providing the first representation learning explainability analysis in the context of CBIR of CT liver images. Results demonstrate improved performance compared to the standard self-supervised approach across several metrics, as well as improved generalisation across datasets. Further, we conduct the first representation learning explainability analysis in the context of CBIR, which reveals new insights into the feature extraction process. Lastly, we perform a case study with cross-examination CBIR that demonstrates the usability of our proposed framework. We believe that our proposed framework could play a vital role in creating trustworthy deep CBIR systems that can successfully take advantage of unlabeled data.
The Change You Want to See
Sep 28, 2022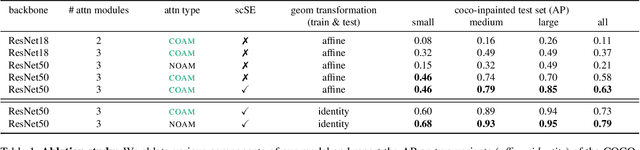
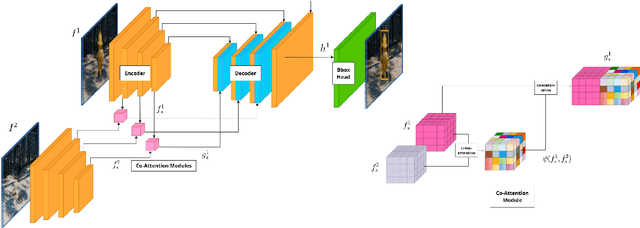

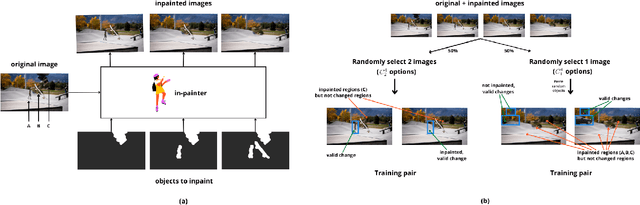
We live in a dynamic world where things change all the time. Given two images of the same scene, being able to automatically detect the changes in them has practical applications in a variety of domains. In this paper, we tackle the change detection problem with the goal of detecting "object-level" changes in an image pair despite differences in their viewpoint and illumination. To this end, we make the following four contributions: (i) we propose a scalable methodology for obtaining a large-scale change detection training dataset by leveraging existing object segmentation benchmarks; (ii) we introduce a co-attention based novel architecture that is able to implicitly determine correspondences between an image pair and find changes in the form of bounding box predictions; (iii) we contribute four evaluation datasets that cover a variety of domains and transformations, including synthetic image changes, real surveillance images of a 3D scene, and synthetic 3D scenes with camera motion; (iv) we evaluate our model on these four datasets and demonstrate zero-shot and beyond training transformation generalization.
It's a long way! Layer-wise Relevance Propagation for Echo State Networks applied to Earth System Variability
Oct 18, 2022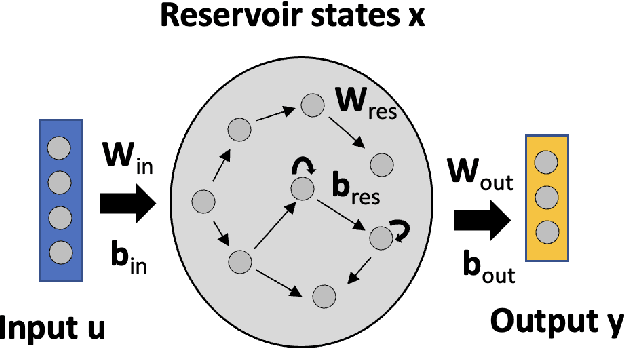
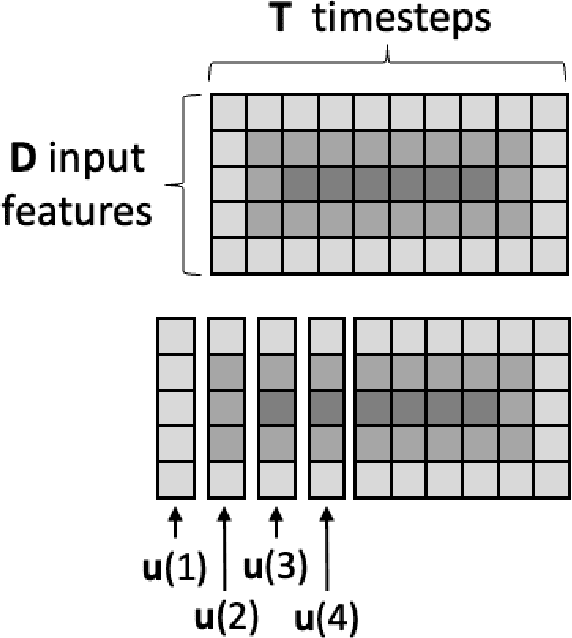
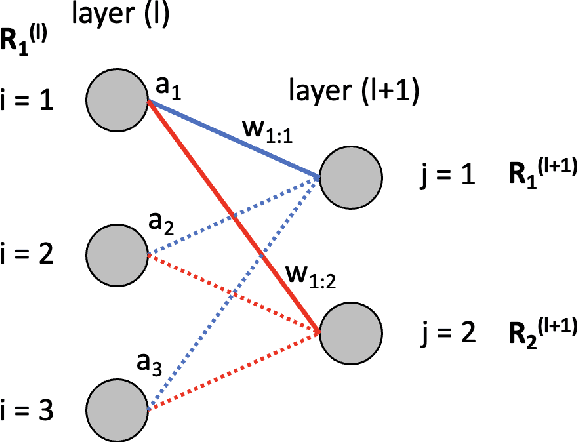
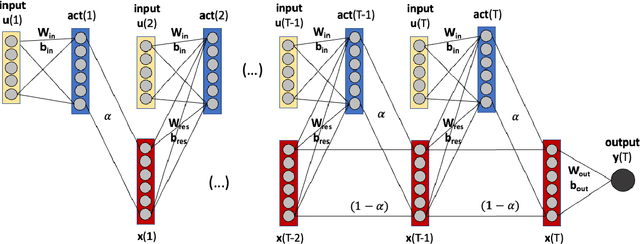
Artificial neural networks (ANNs) are known to be powerful methods for many hard problems (e.g. image classification, speech recognition or time series prediction). However, these models tend to produce black-box results and are often difficult to interpret. Layer-wise relevance propagation (LRP) is a widely used technique to understand how ANN models come to their conclusion and to understand what a model has learned. Here, we focus on Echo State Networks (ESNs) as a certain type of recurrent neural networks, also known as reservoir computing. ESNs are easy to train and only require a small number of trainable parameters, but are still black-box models. We show how LRP can be applied to ESNs in order to open the black-box. We also show how ESNs can be used not only for time series prediction but also for image classification: Our ESN model serves as a detector for El Nino Southern Oscillation (ENSO) from sea surface temperature anomalies. ENSO is actually a well-known problem and has been extensively discussed before. But here we use this simple problem to demonstrate how LRP can significantly enhance the explainablility of ESNs.
Degradation-invariant Enhancement of Fundus Images via Pyramid Constraint Network
Oct 18, 2022As an economical and efficient fundus imaging modality, retinal fundus images have been widely adopted in clinical fundus examination. Unfortunately, fundus images often suffer from quality degradation caused by imaging interferences, leading to misdiagnosis. Despite impressive enhancement performances that state-of-the-art methods have achieved, challenges remain in clinical scenarios. For boosting the clinical deployment of fundus image enhancement, this paper proposes the pyramid constraint to develop a degradation-invariant enhancement network (PCE-Net), which mitigates the demand for clinical data and stably enhances unknown data. Firstly, high-quality images are randomly degraded to form sequences of low-quality ones sharing the same content (SeqLCs). Then individual low-quality images are decomposed to Laplacian pyramid features (LPF) as the multi-level input for the enhancement. Subsequently, a feature pyramid constraint (FPC) for the sequence is introduced to enforce the PCE-Net to learn a degradation-invariant model. Extensive experiments have been conducted under the evaluation metrics of enhancement and segmentation. The effectiveness of the PCE-Net was demonstrated in comparison with state-of-the-art methods and the ablation study. The source code of this study is publicly available at https://github.com/HeverLaw/PCENet-Image-Enhancement.
Towards visually prompted keyword localisation for zero-resource spoken languages
Oct 12, 2022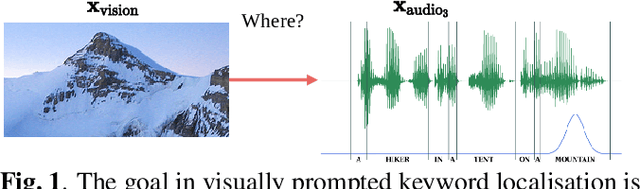
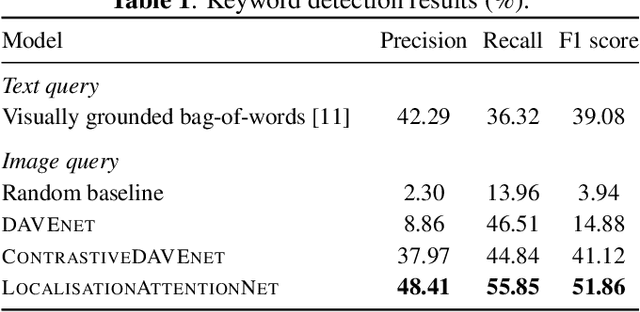
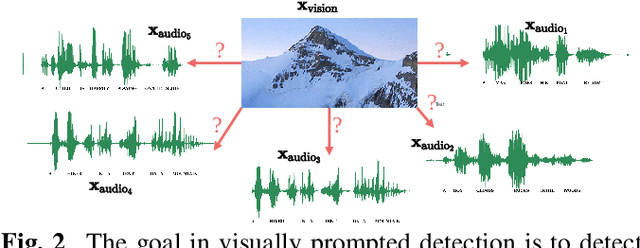
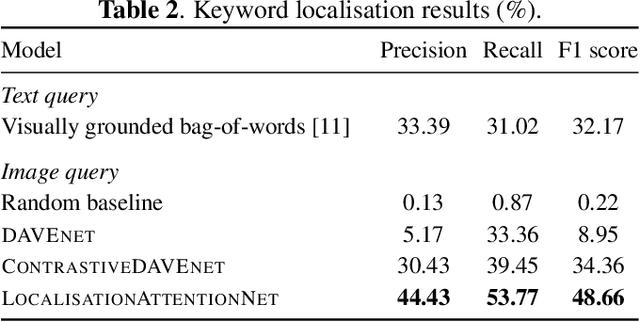
Imagine being able to show a system a visual depiction of a keyword and finding spoken utterances that contain this keyword from a zero-resource speech corpus. We formalise this task and call it visually prompted keyword localisation (VPKL): given an image of a keyword, detect and predict where in an utterance the keyword occurs. To do VPKL, we propose a speech-vision model with a novel localising attention mechanism which we train with a new keyword sampling scheme. We show that these innovations give improvements in VPKL over an existing speech-vision model. We also compare to a visual bag-of-words (BoW) model where images are automatically tagged with visual labels and paired with unlabelled speech. Although this visual BoW can be queried directly with a written keyword (while our's takes image queries), our new model still outperforms the visual BoW in both detection and localisation, giving a 16% relative improvement in localisation F1.
convoHER2: A Deep Neural Network for Multi-Stage Classification of HER2 Breast Cancer
Nov 19, 2022
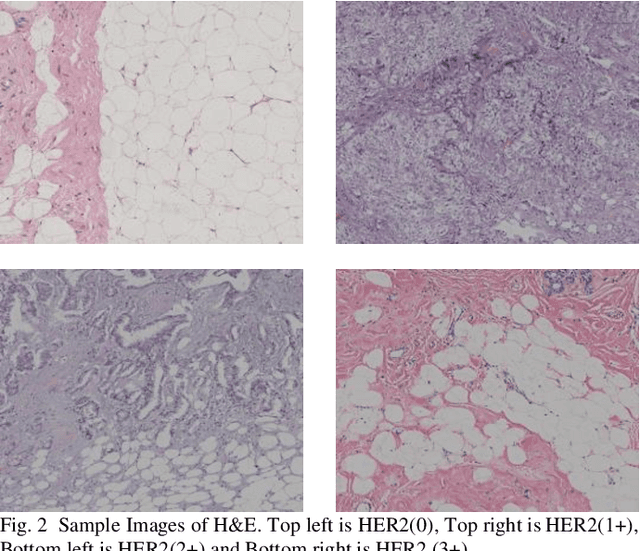
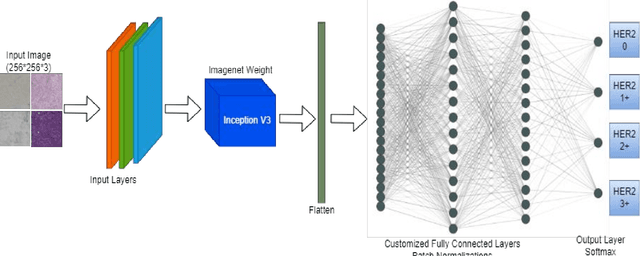
Generally, human epidermal growth factor 2 (HER2) breast cancer is more aggressive than other kinds of breast cancer. Currently, HER2 breast cancer is detected using expensive medical tests are most expensive. Therefore, the aim of this study was to develop a computational model named convoHER2 for detecting HER2 breast cancer with image data using convolution neural network (CNN). Hematoxylin and eosin (H&E) and immunohistochemical (IHC) stained images has been used as raw data from the Bayesian information criterion (BIC) benchmark dataset. This dataset consists of 4873 images of H&E and IHC. Among all images of the dataset, 3896 and 977 images are applied to train and test the convoHER2 model, respectively. As all the images are in high resolution, we resize them so that we can feed them in our convoHER2 model. The cancerous samples images are classified into four classes based on the stage of the cancer (0+, 1+, 2+, 3+). The convoHER2 model is able to detect HER2 cancer and its grade with accuracy 85% and 88% using H&E images and IHC images, respectively. The outcomes of this study determined that the HER2 cancer detecting rates of the convoHER2 model are much enough to provide better diagnosis to the patient for recovering their HER2 breast cancer in future.
D3T-GAN: Data-Dependent Domain Transfer GANs for Few-shot Image Generation
May 12, 2022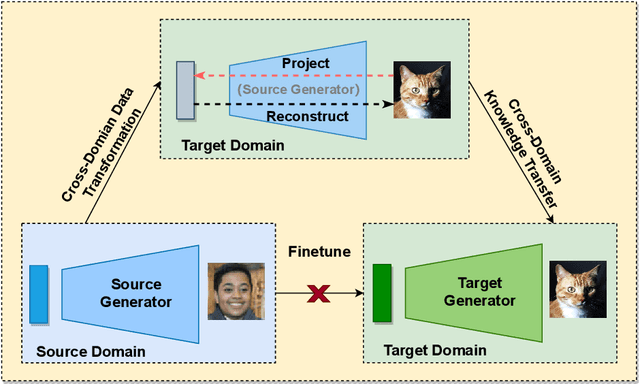
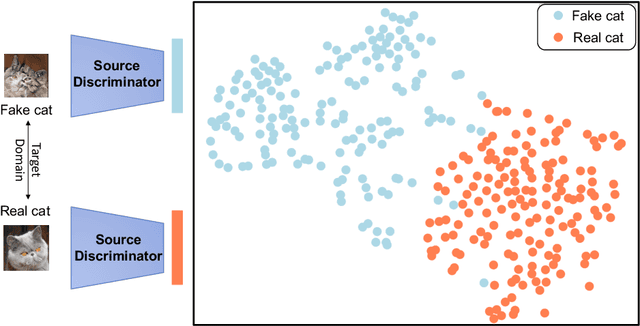
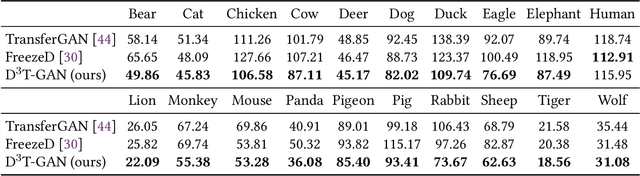
As an important and challenging problem, few-shot image generation aims at generating realistic images through training a GAN model given few samples. A typical solution for few-shot generation is to transfer a well-trained GAN model from a data-rich source domain to the data-deficient target domain. In this paper, we propose a novel self-supervised transfer scheme termed D3T-GAN, addressing the cross-domain GANs transfer in few-shot image generation. Specifically, we design two individual strategies to transfer knowledge between generators and discriminators, respectively. To transfer knowledge between generators, we conduct a data-dependent transformation, which projects and reconstructs the target samples into the source generator space. Then, we perform knowledge transfer from transformed samples to generated samples. To transfer knowledge between discriminators, we design a multi-level discriminant knowledge distillation from the source discriminator to the target discriminator on both the real and fake samples. Extensive experiments show that our method improve the quality of generated images and achieves the state-of-the-art FID scores on commonly used datasets.
Automatic Number Plate Recognition (ANPR) with YOLOv3-CNN
Nov 07, 2022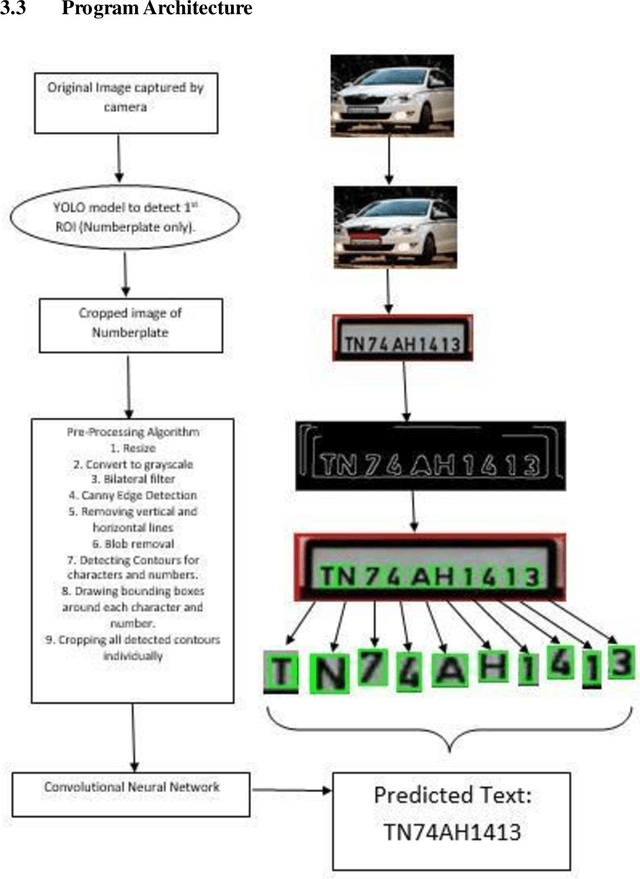
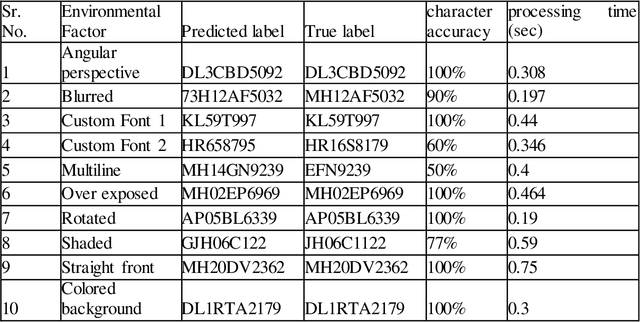


We present a YOLOv3-CNN pipeline for detecting vehicles, segregation of number plates, and local storage of final recognized characters. Vehicle identification is performed under various image correction schemes to determine the effect of environmental factors (angle of perception, luminosity, motion-blurring, and multi-line custom font etc.). A YOLOv3 object detection model was trained to identify vehicles from a dataset of traffic images. A second YOLOv3 layer was trained to identify number plates from vehicle images. Based upon correction schemes, individual characters were segregated and verified against real-time data to calculate accuracy of this approach. While characters under direct view were recognized accurately, some numberplates affected by environmental factors had reduced levels of accuracy. We summarize the results under various environmental factors against real-time data and produce an overall accuracy of the pipeline model.
Blind Surveillance Image Quality Assessment via Deep Neural Network Combined with the Visual Saliency
Jun 09, 2022
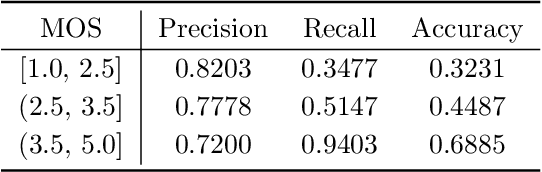
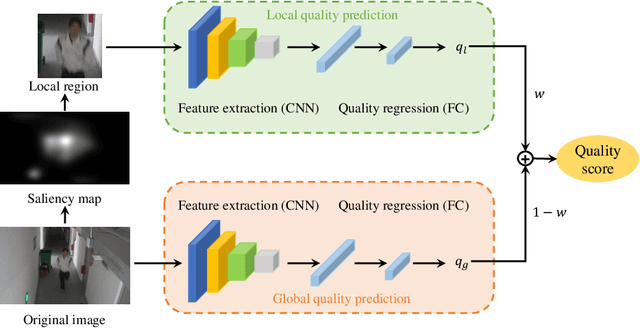
The intelligent video surveillance system (IVSS) can automatically analyze the content of the surveillance image (SI) and reduce the burden of the manual labour. However, the SIs may suffer quality degradations in the procedure of acquisition, compression, and transmission, which makes IVSS hard to understand the content of SIs. In this paper, we first conduct an example experiment (i.e. the face detection task) to demonstrate that the quality of the SIs has a crucial impact on the performance of the IVSS, and then propose a saliency-based deep neural network for the blind quality assessment of the SIs, which helps IVSS to filter the low-quality SIs and improve the detection and recognition performance. Specifically, we first compute the saliency map of the SI to select the most salient local region since the salient regions usually contain rich semantic information for machine vision and thus have a great impact on the overall quality of the SIs. Next, the convolutional neural network (CNN) is adopted to extract quality-aware features for the whole image and local region, which are then mapped into the global and local quality scores through the fully connected (FC) network respectively. Finally, the overall quality score is computed as the weighted sum of the global and local quality scores. Experimental results on the SI quality database (SIQD) show that the proposed method outperforms all compared state-of-the-art BIQA methods.