 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
QueryForm: A Simple Zero-shot Form Entity Query Framework
Nov 14, 2022
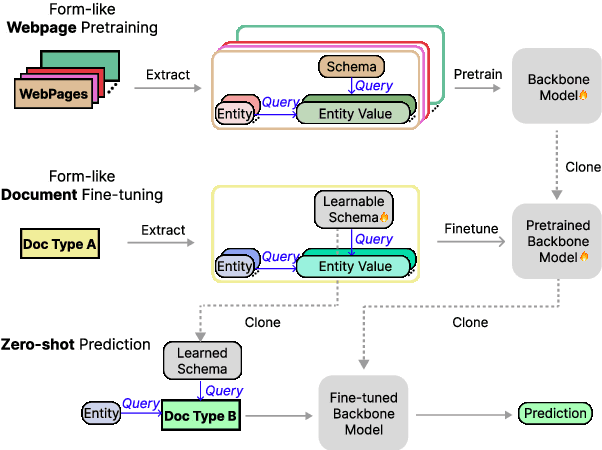

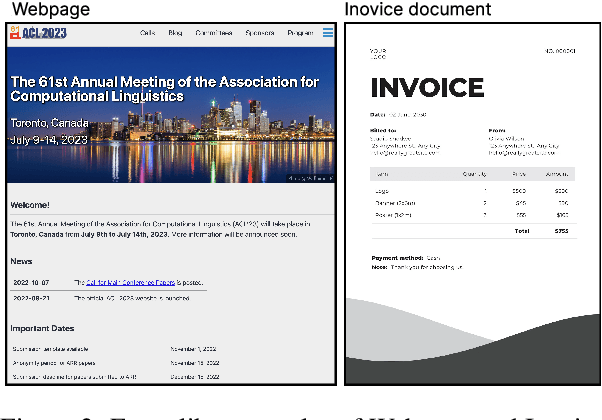
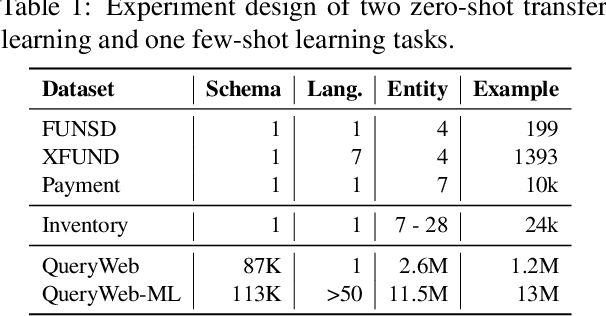
Zero-shot transfer learning for document understanding is a crucial yet under-investigated scenario to help reduce the high cost involved in annotating document entities. We present a novel query-based framework, QueryForm, that extracts entity values from form-like documents in a zero-shot fashion. QueryForm contains a dual prompting mechanism that composes both the document schema and a specific entity type into a query, which is used to prompt a Transformer model to perform a single entity extraction task. Furthermore, we propose to leverage large-scale query-entity pairs generated from form-like webpages with weak HTML annotations to pre-train QueryForm. By unifying pre-training and fine-tuning into the same query-based framework, QueryForm enables models to learn from structured documents containing various entities and layouts, leading to better generalization to target document types without the need for target-specific training data. QueryForm sets new state-of-the-art average F1 score on both the XFUND (+4.6%~10.1%) and the Payment (+3.2%~9.5%) zero-shot benchmark, with a smaller model size and no additional image input.
Controllable GAN Synthesis Using Non-Rigid Structure-from-Motion
Nov 14, 2022

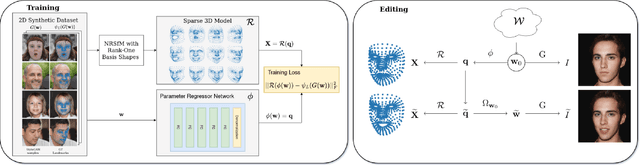
In this paper, we present an approach for combining non-rigid structure-from-motion (NRSfM) with deep generative models,and propose an efficient framework for discovering trajectories in the latent space of 2D GANs corresponding to changes in 3D geometry. Our approach uses recent advances in NRSfM and enables editing of the camera and non-rigid shape information associated with the latent codes without needing to retrain the generator. This formulation provides an implicit dense 3D reconstruction as it enables the image synthesis of novel shapes from arbitrary view angles and non-rigid structure. The method is built upon a sparse backbone, where a neural regressor is first trained to regress parameters describing the cameras and sparse non-rigid structure directly from the latent codes. The latent trajectories associated with changes in the camera and structure parameters are then identified by estimating the local inverse of the regressor in the neighborhood of a given latent code. The experiments show that our approach provides a versatile, systematic way to model, analyze, and edit the geometry and non-rigid structures of faces.
Interpreting Bias in the Neural Networks: A Peek Into Representational Similarity
Nov 14, 2022
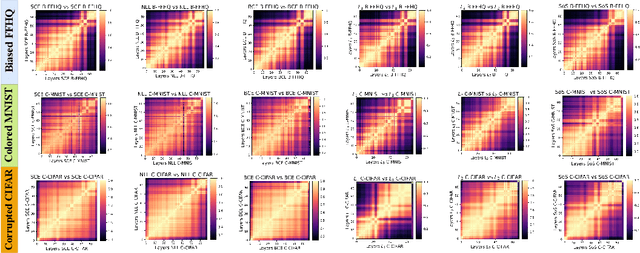
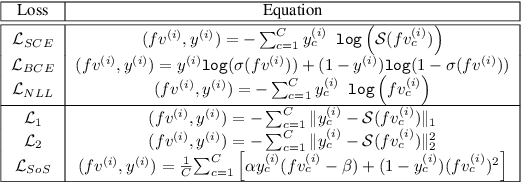
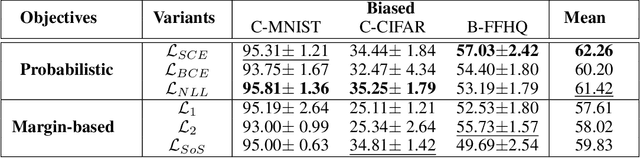
Neural networks trained on standard image classification data sets are shown to be less resistant to data set bias. It is necessary to comprehend the behavior objective function that might correspond to superior performance for data with biases. However, there is little research on the selection of the objective function and its representational structure when trained on data set with biases. In this paper, we investigate the performance and internal representational structure of convolution-based neural networks (e.g., ResNets) trained on biased data using various objective functions. We specifically study similarities in representations, using Centered Kernel Alignment (CKA), for different objective functions (probabilistic and margin-based) and offer a comprehensive analysis of the chosen ones. According to our findings, ResNets representations obtained with Negative Log Likelihood $(\mathcal{L}_{NLL})$ and Softmax Cross-Entropy ($\mathcal{L}_{SCE}$) as loss functions are equally capable of producing better performance and fine representations on biased data. We note that without progressive representational similarities among the layers of a neural network, the performance is less likely to be robust.
A survey of Identification and mitigation of Machine Learning algorithmic biases in Image Analysis
Oct 10, 2022


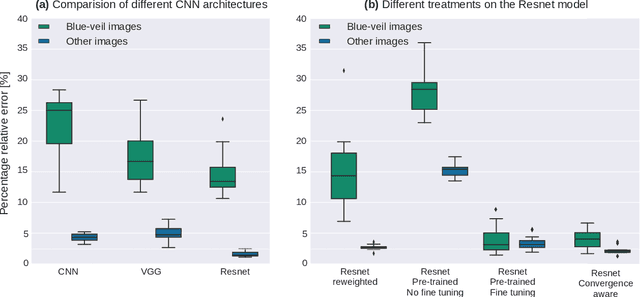
The problem of algorithmic bias in machine learning has gained a lot of attention in recent years due to its concrete and potentially hazardous implications in society. In much the same manner, biases can also alter modern industrial and safety-critical applications where machine learning are based on high dimensional inputs such as images. This issue has however been mostly left out of the spotlight in the machine learning literature. Contrarily to societal applications where a set of proxy variables can be provided by the common sense or by regulations to draw the attention on potential risks, industrial and safety-critical applications are most of the times sailing blind. The variables related to undesired biases can indeed be indirectly represented in the input data, or can be unknown, thus making them harder to tackle. This raises serious and well-founded concerns towards the commercial deployment of AI-based solutions, especially in a context where new regulations clearly address the issues opened by undesired biases in AI. Consequently, we propose here to make an overview of recent advances in this area, firstly by presenting how such biases can demonstrate themselves, then by exploring different ways to bring them to light, and by probing different possibilities to mitigate them. We finally present a practical remote sensing use-case of industrial Fairness.
Using Whole Slide Image Representations from Self-Supervised Contrastive Learning for Melanoma Concordance Regression
Oct 10, 2022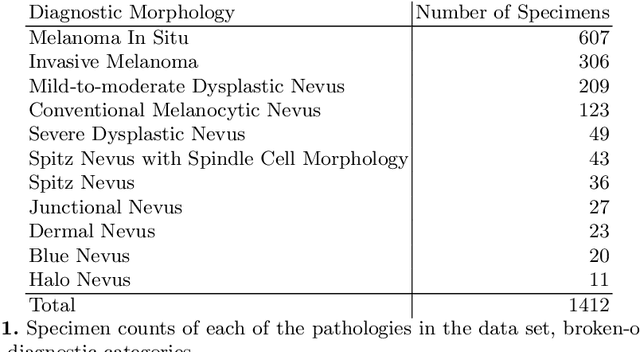
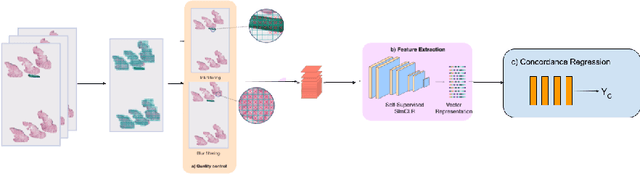

Although melanoma occurs more rarely than several other skin cancers, patients' long term survival rate is extremely low if the diagnosis is missed. Diagnosis is complicated by a high discordance rate among pathologists when distinguishing between melanoma and benign melanocytic lesions. A tool that provides potential concordance information to healthcare providers could help inform diagnostic, prognostic, and therapeutic decision-making for challenging melanoma cases. We present a melanoma concordance regression deep learning model capable of predicting the concordance rate of invasive melanoma or melanoma in-situ from digitized Whole Slide Images (WSIs). The salient features corresponding to melanoma concordance were learned in a self-supervised manner with the contrastive learning method, SimCLR. We trained a SimCLR feature extractor with 83,356 WSI tiles randomly sampled from 10,895 specimens originating from four distinct pathology labs. We trained a separate melanoma concordance regression model on 990 specimens with available concordance ground truth annotations from three pathology labs and tested the model on 211 specimens. We achieved a Root Mean Squared Error (RMSE) of 0.28 +/- 0.01 on the test set. We also investigated the performance of using the predicted concordance rate as a malignancy classifier, and achieved a precision and recall of 0.85 +/- 0.05 and 0.61 +/- 0.06, respectively, on the test set. These results are an important first step for building an artificial intelligence (AI) system capable of predicting the results of consulting a panel of experts and delivering a score based on the degree to which the experts would agree on a particular diagnosis. Such a system could be used to suggest additional testing or other action such as ordering additional stains or genetic tests.
Multi-level Data Representation For Training Deep Helmholtz Machines
Oct 26, 2022
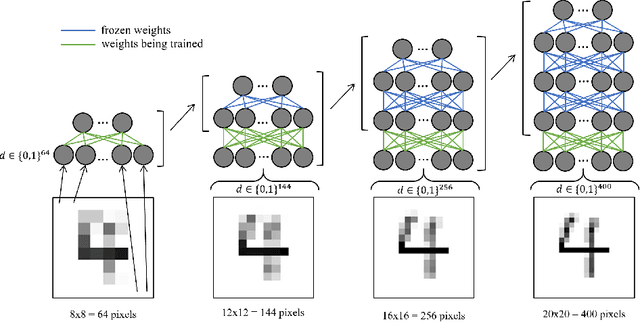
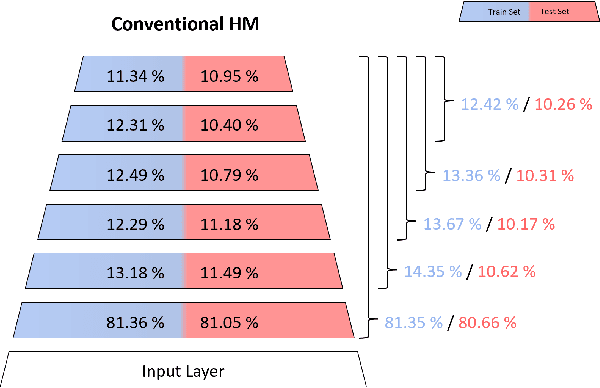
A vast majority of the current research in the field of Machine Learning is done using algorithms with strong arguments pointing to their biological implausibility such as Backpropagation, deviating the field's focus from understanding its original organic inspiration to a compulsive search for optimal performance. Yet, there have been a few proposed models that respect most of the biological constraints present in the human brain and are valid candidates for mimicking some of its properties and mechanisms. In this paper, we will focus on guiding the learning of a biologically plausible generative model called the Helmholtz Machine in complex search spaces using a heuristic based on the Human Image Perception mechanism. We hypothesize that this model's learning algorithm is not fit for Deep Networks due to its Hebbian-like local update rule, rendering it incapable of taking full advantage of the compositional properties that multi-layer networks provide. We propose to overcome this problem, by providing the network's hidden layers with visual queues at different resolutions using a Multi-level Data representation. The results on several image datasets showed the model was able to not only obtain better overall quality but also a wider diversity in the generated images, corroborating our intuition that using our proposed heuristic allows the model to take more advantage of the network's depth growth. More importantly, they show the unexplored possibilities underlying brain-inspired models and techniques.
Computational Choreography using Human Motion Synthesis
Oct 09, 2022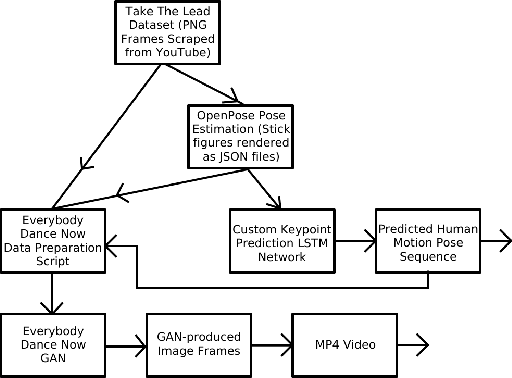
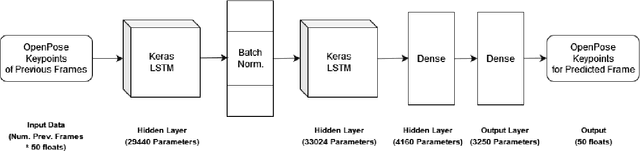
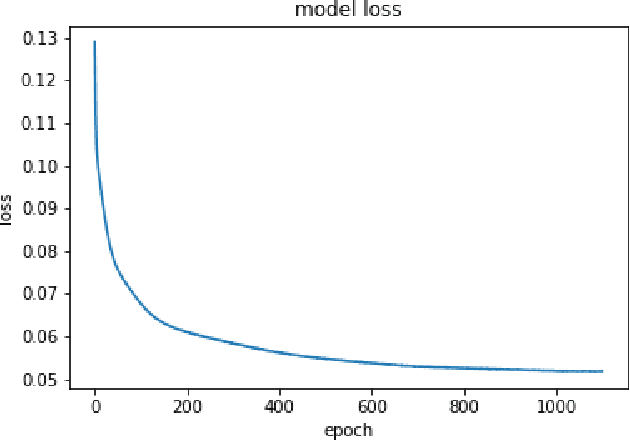
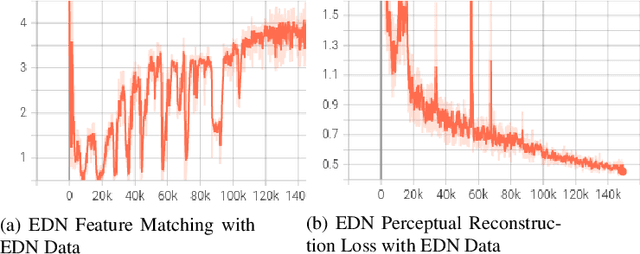
Should deep learning models be trained to analyze human performance art? To help answer this question, we explore an application of deep neural networks to synthesize artistic human motion. Problem tasks in human motion synthesis can include predicting the motions of humans in-the-wild, as well as generating new sequences of motions based on said predictions. We will discuss the potential of a less traditional application, where learning models are applied to predicting dance movements. There have been notable, recent efforts to analyze dance movements in a computational light, such as the Everybody Dance Now (EDN) learning model and a recent Cal Poly master's thesis, Take The Lead (TTL). We have effectively combined these two works along with our own deep neural network to produce a new system for dance motion prediction, image-to-image translation, and video generation.
Feature Re-calibration based MIL for Whole Slide Image Classification
Jun 22, 2022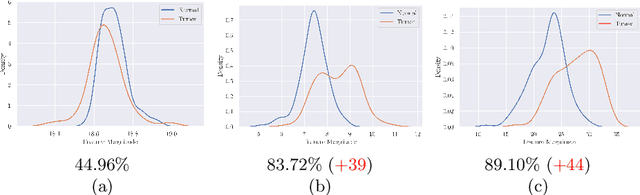
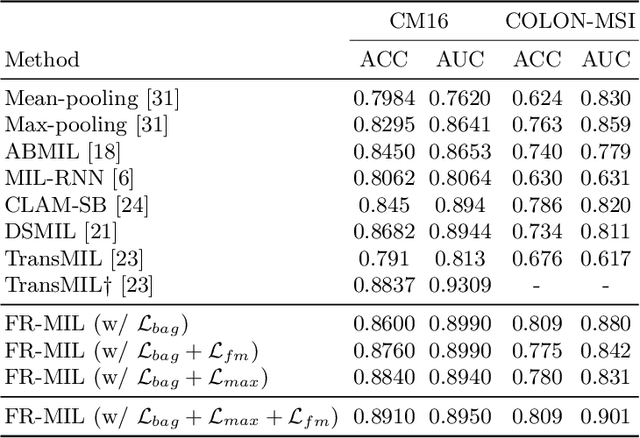
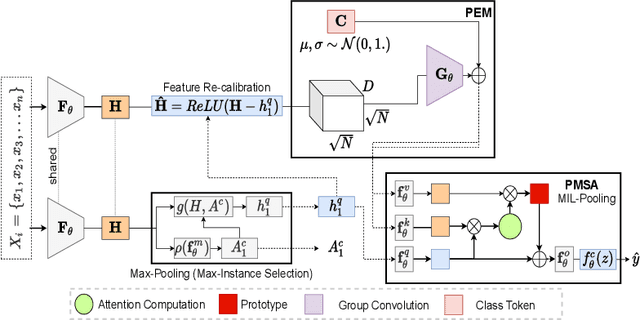
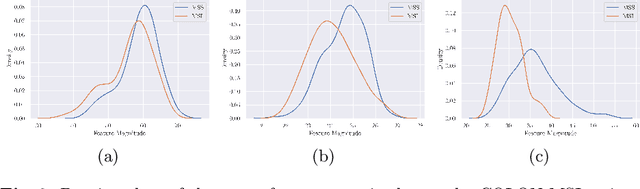
Whole slide image (WSI) classification is a fundamental task for the diagnosis and treatment of diseases; but, curation of accurate labels is time-consuming and limits the application of fully-supervised methods. To address this, multiple instance learning (MIL) is a popular method that poses classification as a weakly supervised learning task with slide-level labels only. While current MIL methods apply variants of the attention mechanism to re-weight instance features with stronger models, scant attention is paid to the properties of the data distribution. In this work, we propose to re-calibrate the distribution of a WSI bag (instances) by using the statistics of the max-instance (critical) feature. We assume that in binary MIL, positive bags have larger feature magnitudes than negatives, thus we can enforce the model to maximize the discrepancy between bags with a metric feature loss that models positive bags as out-of-distribution. To achieve this, unlike existing MIL methods that use single-batch training modes, we propose balanced-batch sampling to effectively use the feature loss i.e., (+/-) bags simultaneously. Further, we employ a position encoding module (PEM) to model spatial/morphological information, and perform pooling by multi-head self-attention (PSMA) with a Transformer encoder. Experimental results on existing benchmark datasets show our approach is effective and improves over state-of-the-art MIL methods.
Cross-Modality High-Frequency Transformer for MR Image Super-Resolution
Mar 29, 2022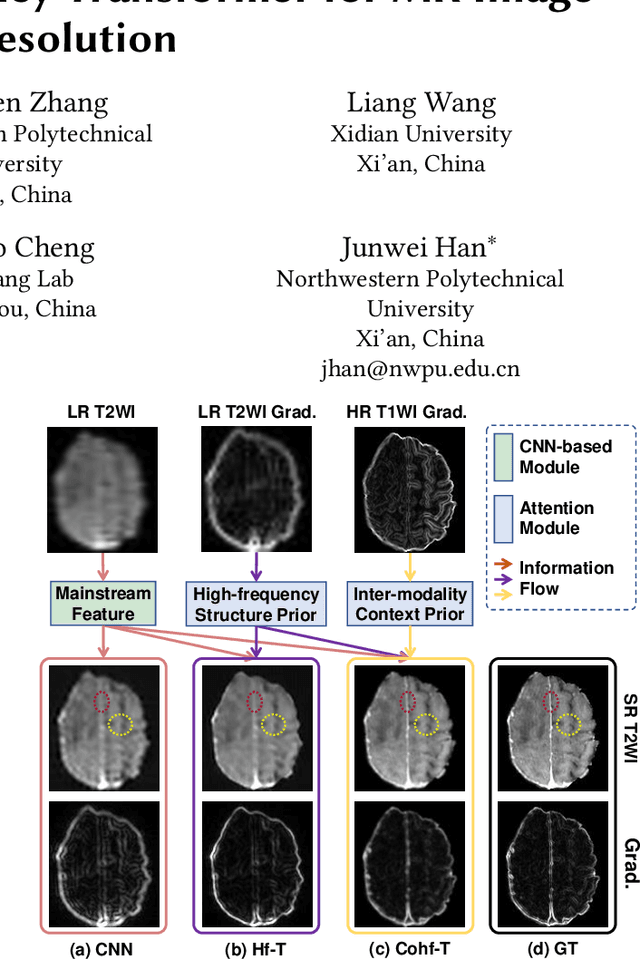
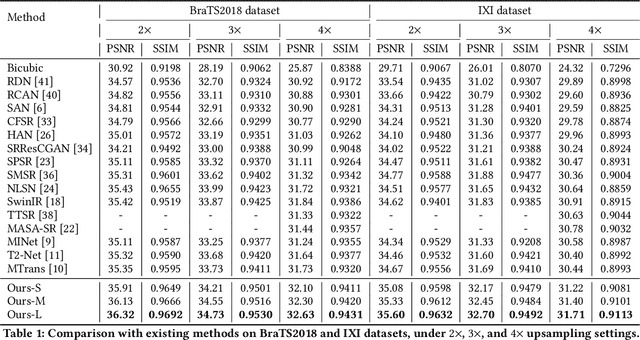
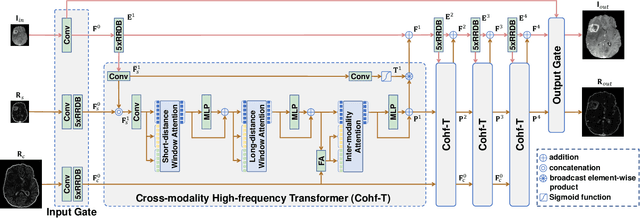
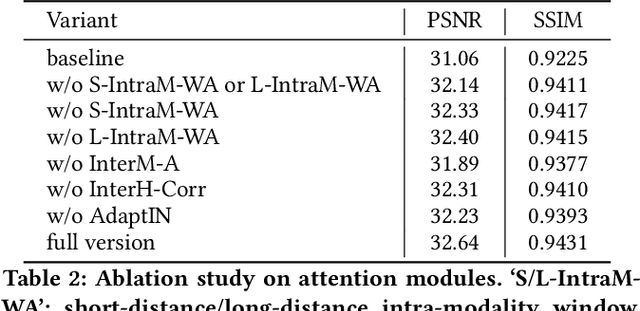
Improving the resolution of magnetic resonance (MR) image data is critical to computer-aided diagnosis and brain function analysis. Higher resolution helps to capture more detailed content, but typically induces to lower signal-to-noise ratio and longer scanning time. To this end, MR image super-resolution has become a widely-interested topic in recent times. Existing works establish extensive deep models with the conventional architectures based on convolutional neural networks (CNN). In this work, to further advance this research field, we make an early effort to build a Transformer-based MR image super-resolution framework, with careful designs on exploring valuable domain prior knowledge. Specifically, we consider two-fold domain priors including the high-frequency structure prior and the inter-modality context prior, and establish a novel Transformer architecture, called Cross-modality high-frequency Transformer (Cohf-T), to introduce such priors into super-resolving the low-resolution (LR) MR images. Comprehensive experiments on two datasets indicate that Cohf-T achieves new state-of-the-art performance.
Increasing the Accuracy of a Neural Network Using Frequency Selective Mesh-to-Grid Resampling
Sep 28, 2022

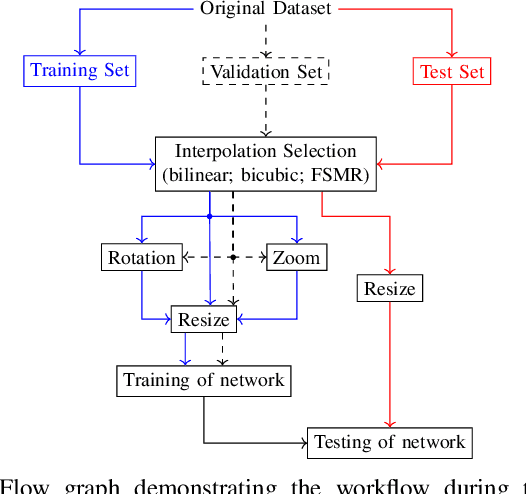
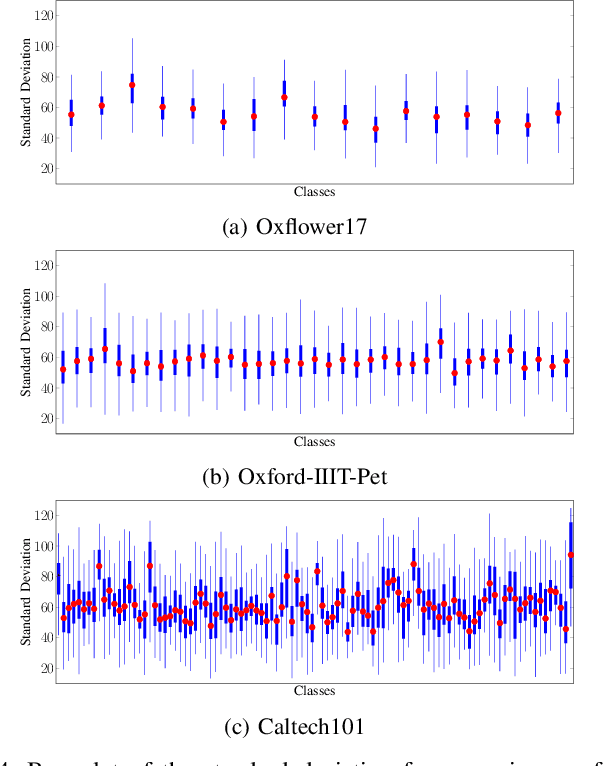
Neural networks are widely used for almost any task of recognizing image content. Even though much effort has been put into investigating efficient network architectures, optimizers, and training strategies, the influence of image interpolation on the performance of neural networks is not well studied. Furthermore, research has shown that neural networks are often sensitive to minor changes in the input image leading to drastic drops of their performance. Therefore, we propose the use of keypoint agnostic frequency selective mesh-to-grid resampling (FSMR) for the processing of input data for neural networks in this paper. This model-based interpolation method already showed that it is capable of outperforming common interpolation methods in terms of PSNR. Using an extensive experimental evaluation we show that depending on the network architecture and classification task the application of FSMR during training aids the learning process. Furthermore, we show that the usage of FSMR in the application phase is beneficial. The classification accuracy can be increased by up to 4.31 percentage points for ResNet50 and the Oxflower17 dataset.