 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Legged Locomotion in Challenging Terrains using Egocentric Vision
Nov 14, 2022
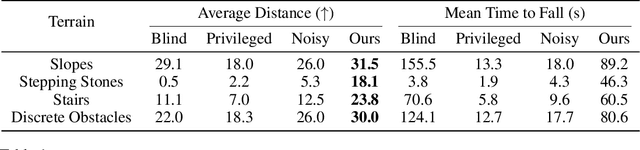

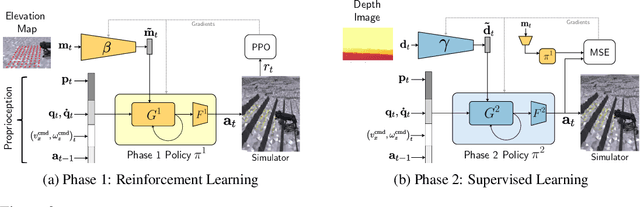
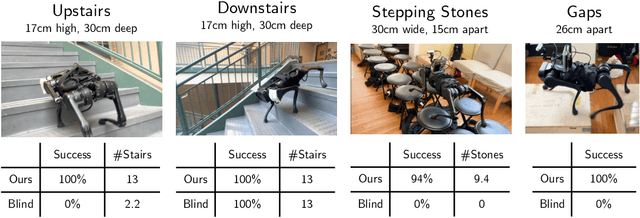
Animals are capable of precise and agile locomotion using vision. Replicating this ability has been a long-standing goal in robotics. The traditional approach has been to decompose this problem into elevation mapping and foothold planning phases. The elevation mapping, however, is susceptible to failure and large noise artifacts, requires specialized hardware, and is biologically implausible. In this paper, we present the first end-to-end locomotion system capable of traversing stairs, curbs, stepping stones, and gaps. We show this result on a medium-sized quadruped robot using a single front-facing depth camera. The small size of the robot necessitates discovering specialized gait patterns not seen elsewhere. The egocentric camera requires the policy to remember past information to estimate the terrain under its hind feet. We train our policy in simulation. Training has two phases - first, we train a policy using reinforcement learning with a cheap-to-compute variant of depth image and then in phase 2 distill it into the final policy that uses depth using supervised learning. The resulting policy transfers to the real world and is able to run in real-time on the limited compute of the robot. It can traverse a large variety of terrain while being robust to perturbations like pushes, slippery surfaces, and rocky terrain. Videos are at https://vision-locomotion.github.io
A Wavelet-based Dual-stream Network for Underwater Image Enhancement
Feb 17, 2022

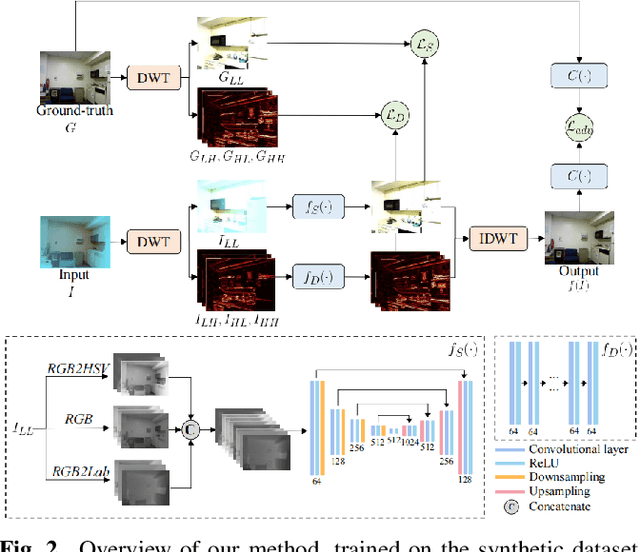
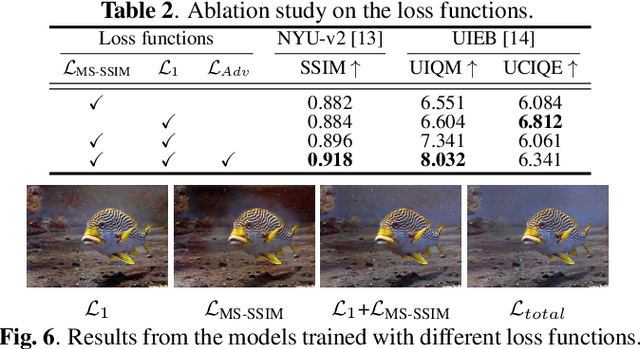
We present a wavelet-based dual-stream network that addresses color cast and blurry details in underwater images. We handle these artifacts separately by decomposing an input image into multiple frequency bands using discrete wavelet transform, which generates the downsampled structure image and detail images. These sub-band images are used as input to our dual-stream network that incorporates two sub-networks: the multi-color space fusion network and the detail enhancement network. The multi-color space fusion network takes the decomposed structure image as input and estimates the color corrected output by employing the feature representations from diverse color spaces of the input. The detail enhancement network addresses the blurriness of the original underwater image by improving the image details from high-frequency sub-bands. We validate the proposed method on both real-world and synthetic underwater datasets and show the effectiveness of our model in color correction and blur removal with low computational complexity.
Multi-Scale Adaptive Network for Single Image Denoising
Mar 08, 2022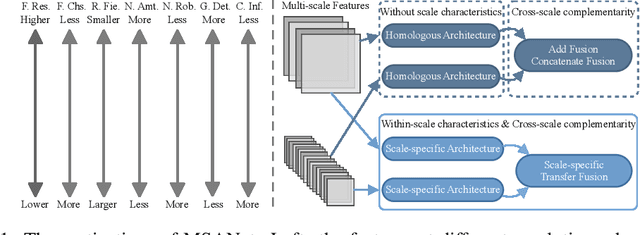
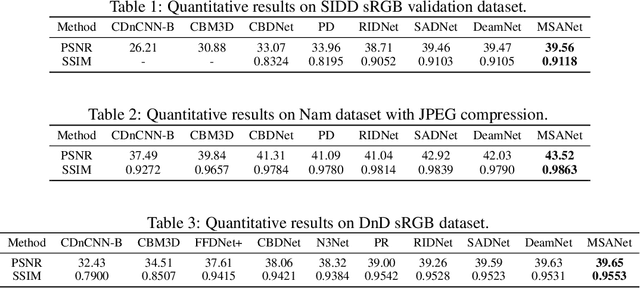
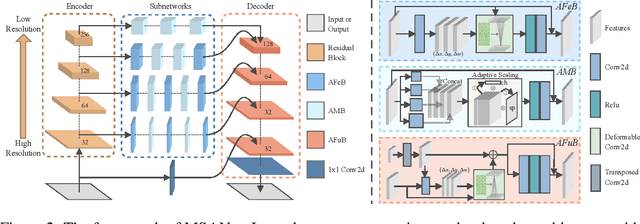

Multi-scale architectures have shown effectiveness in a variety of tasks including single image denoising, thanks to appealing cross-scale complementarity. However, existing methods treat different scale features equally without considering their scale-specific characteristics, i.e., the within-scale characteristics are ignored. In this paper, we reveal this missing piece for multi-scale architecture design and accordingly propose a novel Multi-Scale Adaptive Network (MSANet) for single image denoising. To be specific, MSANet simultaneously embraces the within-scale characteristics and the cross-scale complementarity thanks to three novel neural blocks, i.e., adaptive feature block (AFeB), adaptive multi-scale block (AMB), and adaptive fusion block (AFuB). In brief, AFeB is designed to adaptively select details and filter noises, which is highly expected for fine-grained features. AMB could enlarge the receptive field and aggregate the multi-scale information, which is designed to satisfy the demands of both fine- and coarse-grained features. AFuB devotes to adaptively sampling and transferring the features from one scale to another scale, which is used to fuse the features with varying characteristics from coarse to fine. Extensive experiments on both three real and six synthetic noisy image datasets show the superiority of MSANet compared with 12 methods.
Measurement-Consistent Networks via a Deep Implicit Layer for Solving Inverse Problems
Nov 06, 2022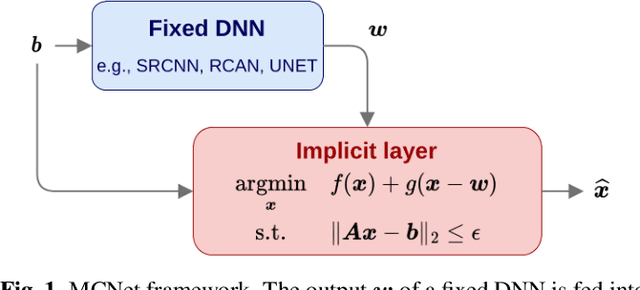
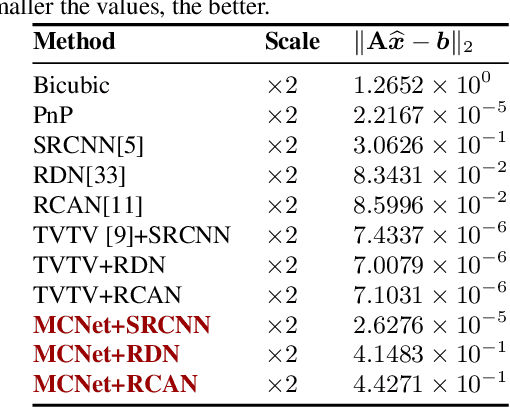
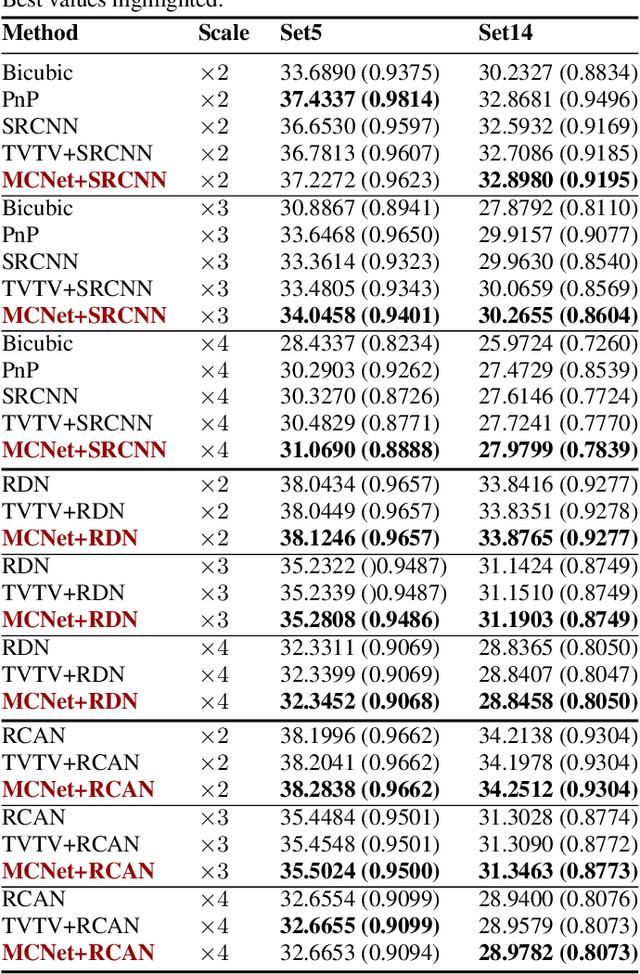
End-to-end deep neural networks (DNNs) have become state-of-the-art (SOTA) for solving inverse problems. Despite their outstanding performance, during deployment, such networks are sensitive to minor variations in the training pipeline and often fail to reconstruct small but important details, a feature critical in medical imaging, astronomy, or defence. Such instabilities in DNNs can be explained by the fact that they ignore the forward measurement model during deployment, and thus fail to enforce consistency between their output and the input measurements. To overcome this, we propose a framework that transforms any DNN for inverse problems into a measurement-consistent one. This is done by appending to it an implicit layer (or deep equilibrium network) designed to solve a model-based optimization problem. The implicit layer consists of a shallow learnable network that can be integrated into the end-to-end training. Experiments on single-image super-resolution show that the proposed framework leads to significant improvements in reconstruction quality and robustness over the SOTA DNNs.
Deep Learning for Global Wildfire Forecasting
Nov 06, 2022
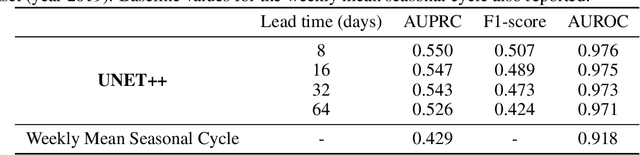
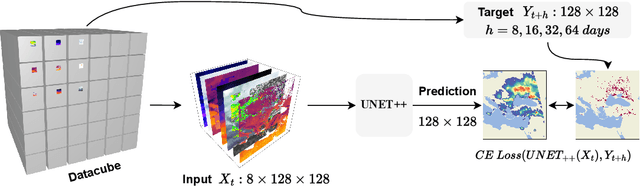
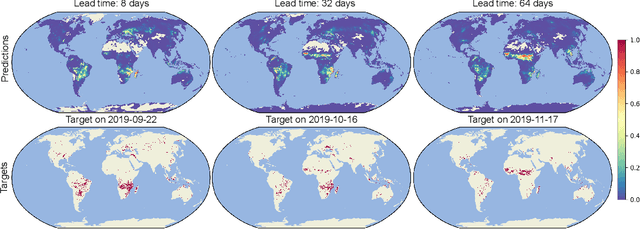
Climate change is expected to aggravate wildfire activity through the exacerbation of fire weather. Improving our capabilities to anticipate wildfires on a global scale is of uttermost importance for mitigating their negative effects. In this work, we create a global fire dataset and demonstrate a prototype for predicting the presence of global burned areas on a sub-seasonal scale with the use of segmentation deep learning models. Particularly, we present an open-access global analysis-ready datacube, which contains a variety of variables related to the seasonal and sub-seasonal fire drivers (climate, vegetation, oceanic indices, human-related variables), as well as the historical burned areas and wildfire emissions for 2001-2021. We train a deep learning model, which treats global wildfire forecasting as an image segmentation task and skillfully predicts the presence of burned areas 8, 16, 32 and 64 days ahead of time. Our work motivates the use of deep learning for global burned area forecasting and paves the way towards improved anticipation of global wildfire patterns.
Leveraging Haptic Feedback to Improve Data Quality and Quantity for Deep Imitation Learning Models
Nov 06, 2022
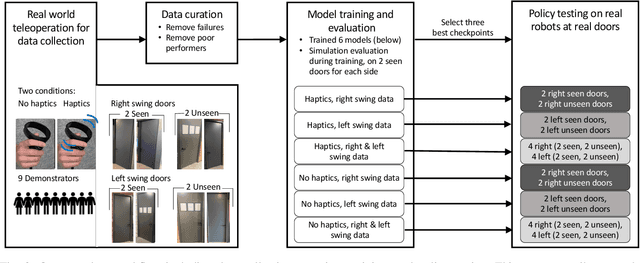
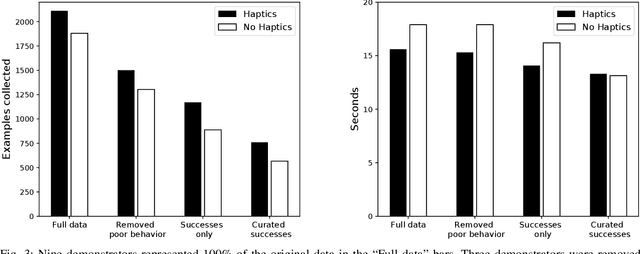

Learning from demonstration (LfD) is a proven technique to teach robots new skills. Data quality and quantity play a critical role in LfD trained model performance. In this paper we analyze the effect of enhancing an existing teleoperation data collection system with real-time haptic feedback; we observe improvements in the collected data throughput and its quality for model training. Our experiment testbed was a mobile manipulator robot that opened doors with latch handles. Evaluation of teleoperated data collection on eight real world conference room doors found that adding the haptic feedback improved the data throughput by 6%. We additionally used the collected data to train six image-based deep imitation learning models, three with haptic feedback and three without it. These models were used to implement autonomous door-opening with the same type of robot used during data collection. Our results show that a policy from a behavior cloning model trained with haptic data performed on average 11% better than its counterpart with no haptic feedback data, indicating that haptic feedback resulted in collection of a higher quality dataset.
Computational pathology in renal disease: a comprehensive perspective
Oct 18, 2022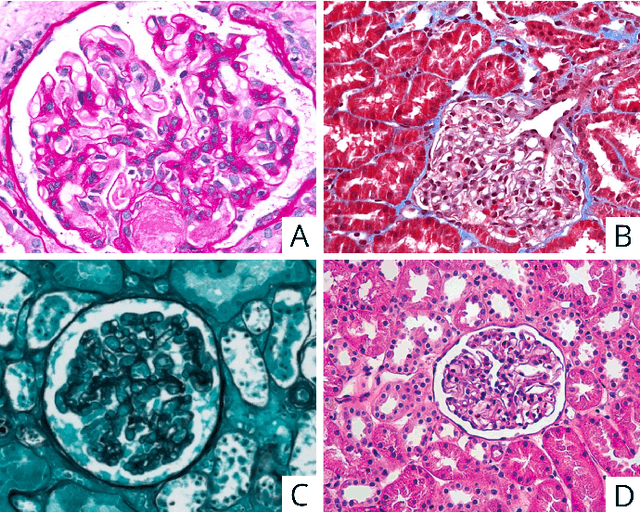
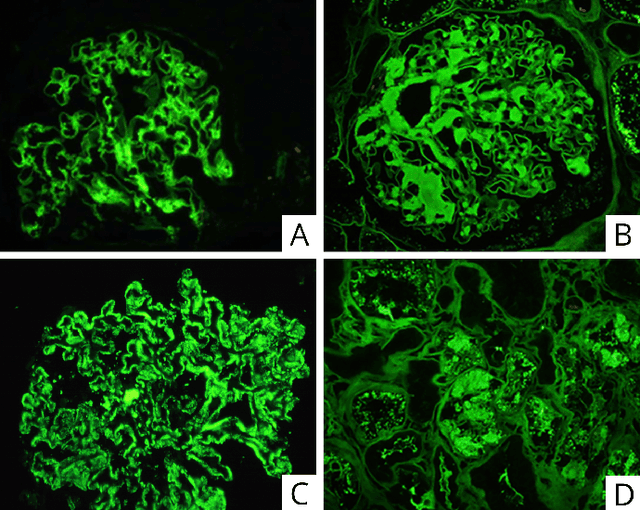
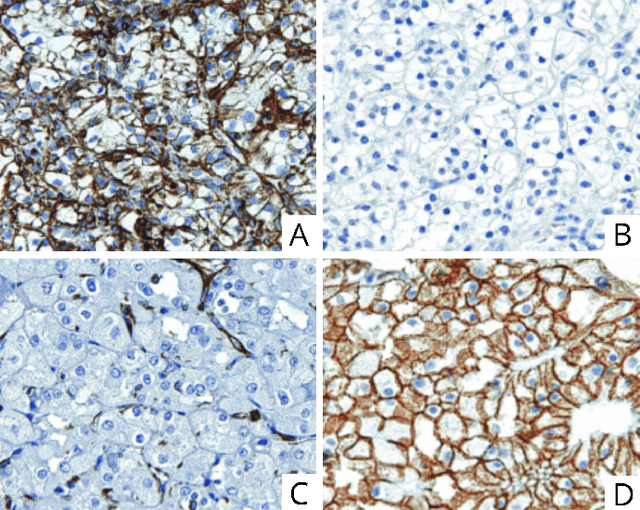
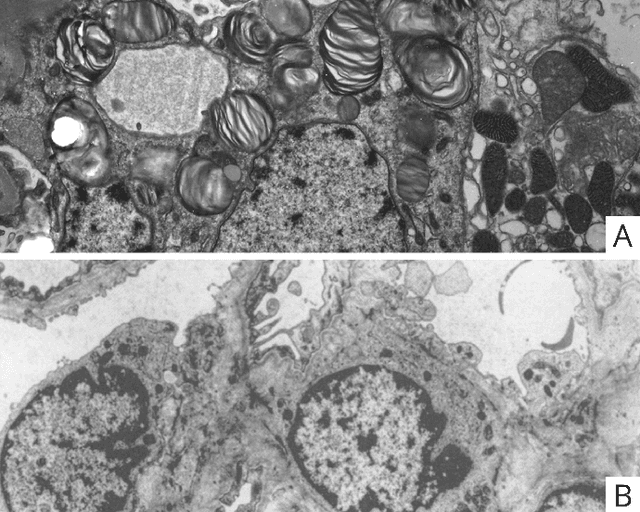
Computational pathology is a field that has complemented various subspecialties of diagnostic pathology over the last few years. In this article a brief analyzis the different applications in nephrology is developed. To begin, an overview of the different forms of image production is provided. To continue, the most frequent applications of computer vision models, the salient features of the different clinical applications, and the data protection considerations encountered are described. To finish the development, I delve into the interpretability of these applications, expanding in depth on the three dimensions of this area.
Knowledge-Free Black-Box Watermark and Ownership Proof for Image Classification Neural Networks
Apr 09, 2022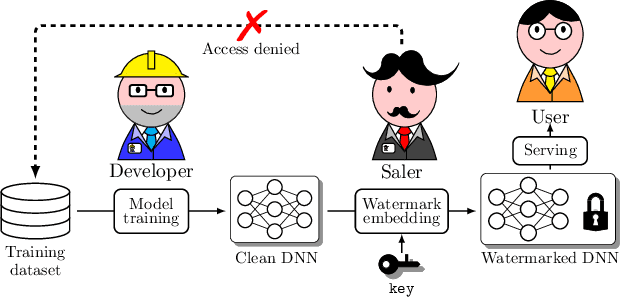

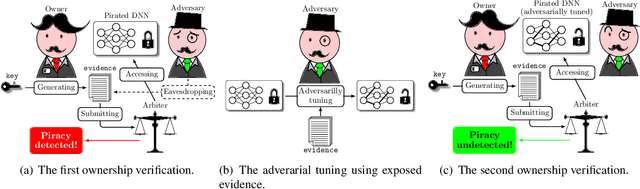

Watermarking has become a plausible candidate for ownership verification and intellectual property protection of deep neural networks. Regarding image classification neural networks, current watermarking schemes uniformly resort to backdoor triggers. However, injecting a backdoor into a neural network requires knowledge of the training dataset, which is usually unavailable in the real-world commercialization. Meanwhile, established watermarking schemes oversight the potential damage of exposed evidence during ownership verification and the watermarking algorithms themselves. Those concerns decline current watermarking schemes from industrial applications. To confront these challenges, we propose a knowledge-free black-box watermarking scheme for image classification neural networks. The image generator obtained from a data-free distillation process is leveraged to stabilize the network's performance during the backdoor injection. A delicate encoding and verification protocol is designed to ensure the scheme's security against knowledgable adversaries. We also give a pioneering analysis of the capacity of the watermarking scheme. Experiment results proved the functionality-preserving capability and security of the proposed watermarking scheme.
MonoNHR: Monocular Neural Human Renderer
Oct 02, 2022
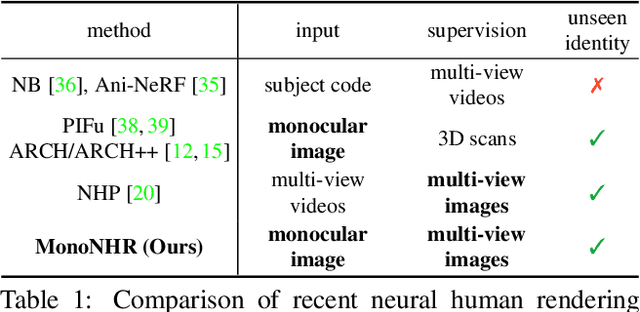
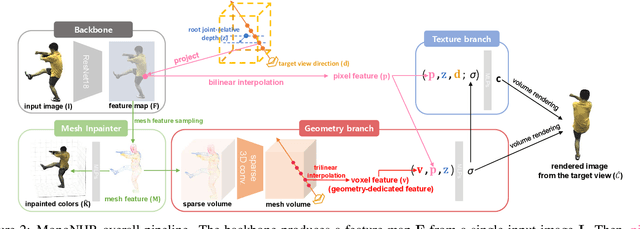
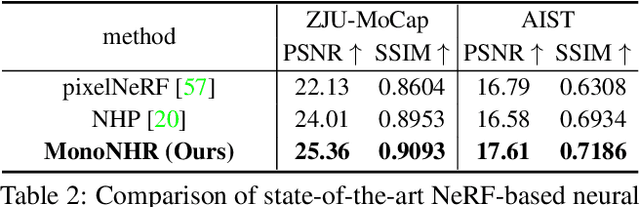
Existing neural human rendering methods struggle with a single image input due to the lack of information in invisible areas and the depth ambiguity of pixels in visible areas. In this regard, we propose Monocular Neural Human Renderer (MonoNHR), a novel approach that renders robust free-viewpoint images of an arbitrary human given only a single image. MonoNHR is the first method that (i) renders human subjects never seen during training in a monocular setup, and (ii) is trained in a weakly-supervised manner without geometry supervision. First, we propose to disentangle 3D geometry and texture features and to condition the texture inference on the 3D geometry features. Second, we introduce a Mesh Inpainter module that inpaints the occluded parts exploiting human structural priors such as symmetry. Experiments on ZJU-MoCap, AIST, and HUMBI datasets show that our approach significantly outperforms the recent methods adapted to the monocular case.
Bilateral Network with Channel Splitting Network and Transformer for Thermal Image Super-Resolution
Jun 24, 2022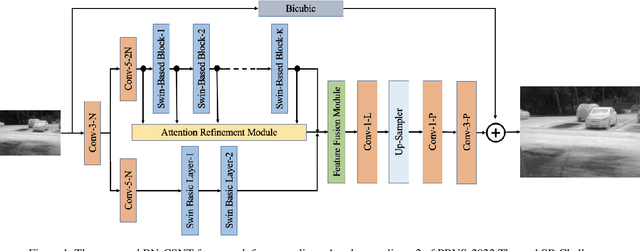
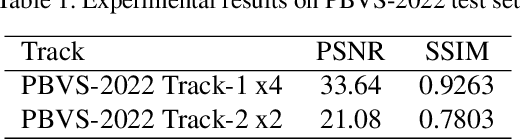
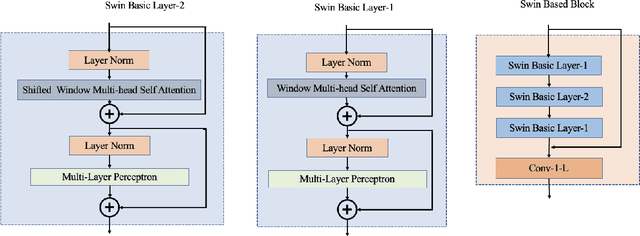
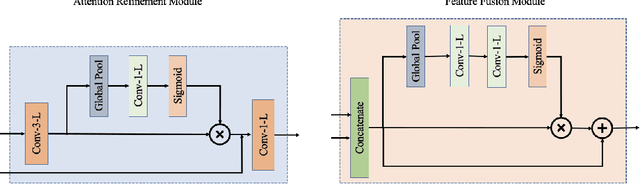
In recent years, the Thermal Image Super-Resolution (TISR) problem has become an attractive research topic. TISR would been used in a wide range of fields, including military, medical, agricultural and animal ecology. Due to the success of PBVS-2020 and PBVS-2021 workshop challenge, the result of TISR keeps improving and attracts more researchers to sign up for PBVS-2022 challenge. In this paper, we will introduce the technical details of our submission to PBVS-2022 challenge designing a Bilateral Network with Channel Splitting Network and Transformer(BN-CSNT) to tackle the TISR problem. Firstly, we designed a context branch based on channel splitting network with transformer to obtain sufficient context information. Secondly, we designed a spatial branch with shallow transformer to extract low level features which can preserve the spatial information. Finally, for the context branch in order to fuse the features from channel splitting network and transformer, we proposed an attention refinement module, and then features from context branch and spatial branch are fused by proposed feature fusion module. The proposed method can achieve PSNR=33.64, SSIM=0.9263 for x4 and PSNR=21.08, SSIM=0.7803 for x2 in the PBVS-2022 challenge test dataset.