 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mitigating Dialogue Hallucination for Large Multi-modal Models via Adversarial Instruction Tuning
Mar 15, 2024

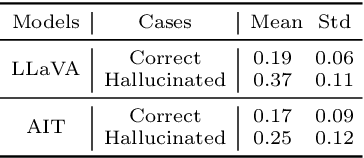
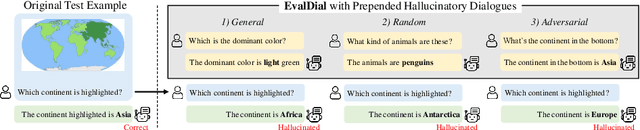
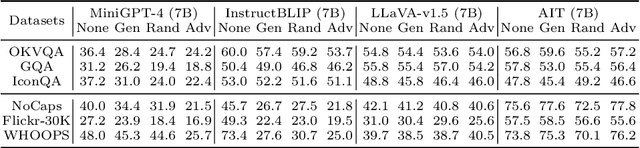
Mitigating hallucinations of Large Multi-modal Models(LMMs) is crucial to enhance their reliability for general-purpose assistants. This paper shows that such hallucinations of LMMs can be significantly exacerbated by preceding user-system dialogues. To precisely measure this, we first present an evaluation benchmark by extending popular multi-modal benchmark datasets with prepended hallucinatory dialogues generated by our novel Adversarial Question Generator, which can automatically generate image-related yet adversarial dialogues by adopting adversarial attacks on LMMs. On our benchmark, the zero-shot performance of state-of-the-art LMMs dropped significantly for both the VQA and Captioning tasks. Next, we further reveal this hallucination is mainly due to the prediction bias toward preceding dialogues rather than visual content. To reduce this bias, we propose Adversarial Instruction Tuning that robustly fine-tunes LMMs on augmented multi-modal instruction-following datasets with hallucinatory dialogues. Extensive experiments show that our proposed approach successfully reduces dialogue hallucination while maintaining or even improving performance.
Improving Medical Multi-modal Contrastive Learning with Expert Annotations
Mar 15, 2024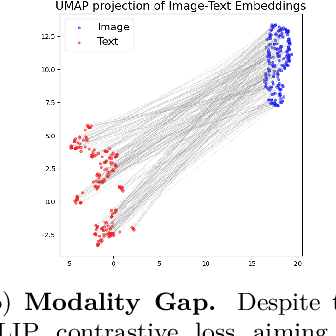
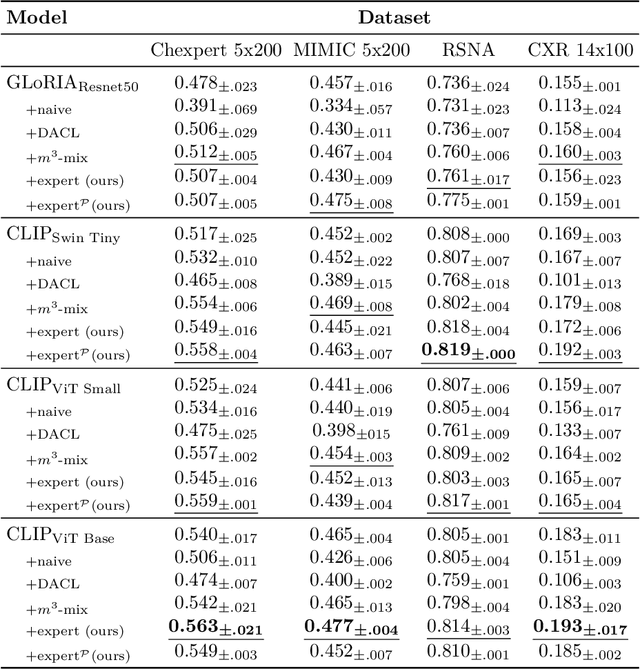
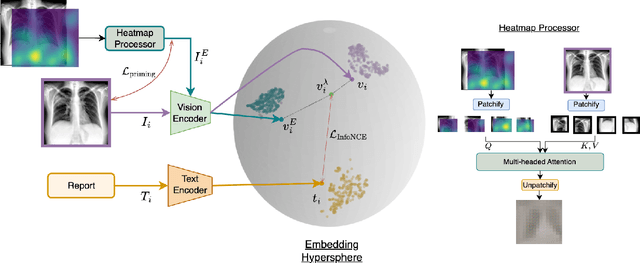
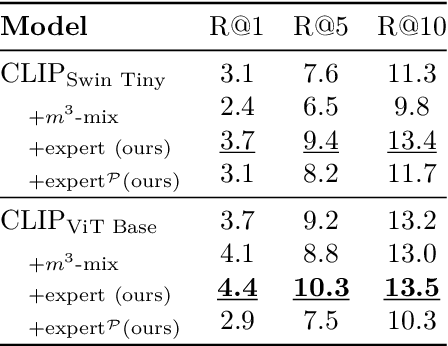
We introduce eCLIP, an enhanced version of the CLIP model that integrates expert annotations in the form of radiologist eye-gaze heatmaps. It tackles key challenges in contrastive multi-modal medical imaging analysis, notably data scarcity and the "modality gap" -- a significant disparity between image and text embeddings that diminishes the quality of representations and hampers cross-modal interoperability. eCLIP integrates a heatmap processor and leverages mixup augmentation to efficiently utilize the scarce expert annotations, thus boosting the model's learning effectiveness. eCLIP is designed to be generally applicable to any variant of CLIP without requiring any modifications of the core architecture. Through detailed evaluations across several tasks, including zero-shot inference, linear probing, cross-modal retrieval, and Retrieval Augmented Generation (RAG) of radiology reports using a frozen Large Language Model, eCLIP showcases consistent improvements in embedding quality. The outcomes reveal enhanced alignment and uniformity, affirming eCLIP's capability to harness high-quality annotations for enriched multi-modal analysis in the medical imaging domain.
Chaining text-to-image and large language model: A novel approach for generating personalized e-commerce banners
Feb 28, 2024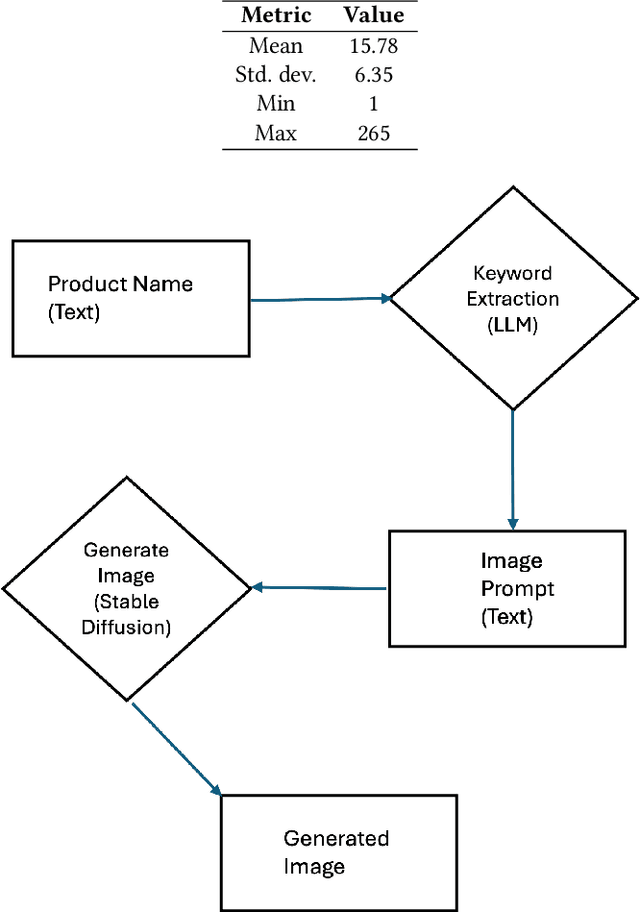
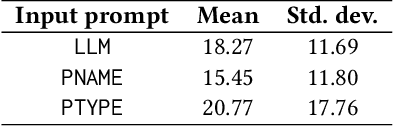
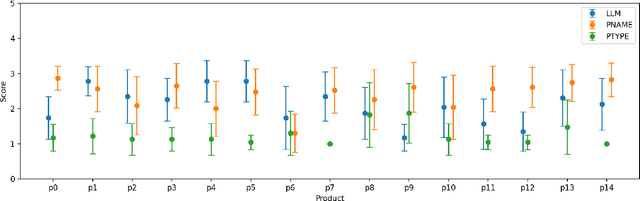

Text-to-image models such as stable diffusion have opened a plethora of opportunities for generating art. Recent literature has surveyed the use of text-to-image models for enhancing the work of many creative artists. Many e-commerce platforms employ a manual process to generate the banners, which is time-consuming and has limitations of scalability. In this work, we demonstrate the use of text-to-image models for generating personalized web banners with dynamic content for online shoppers based on their interactions. The novelty in this approach lies in converting users' interaction data to meaningful prompts without human intervention. To this end, we utilize a large language model (LLM) to systematically extract a tuple of attributes from item meta-information. The attributes are then passed to a text-to-image model via prompt engineering to generate images for the banner. Our results show that the proposed approach can create high-quality personalized banners for users.
Reconstructing Visual Stimulus Images from EEG Signals Based on Deep Visual Representation Model
Mar 11, 2024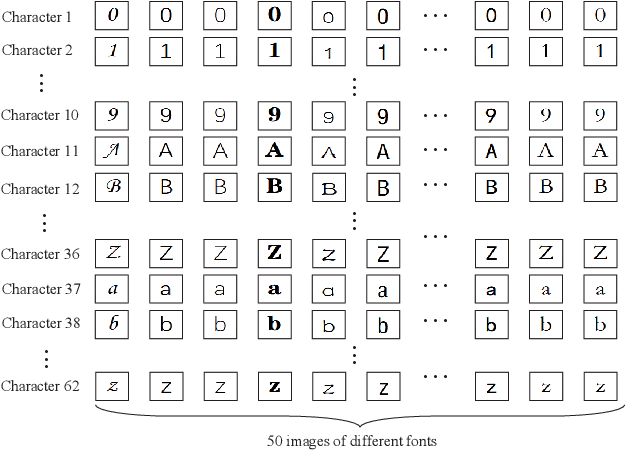
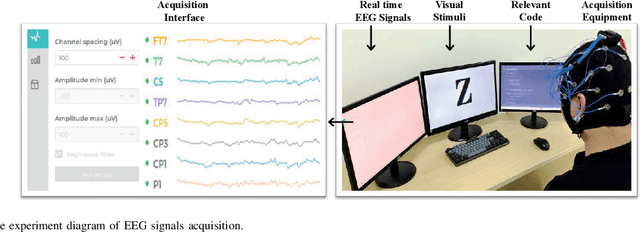
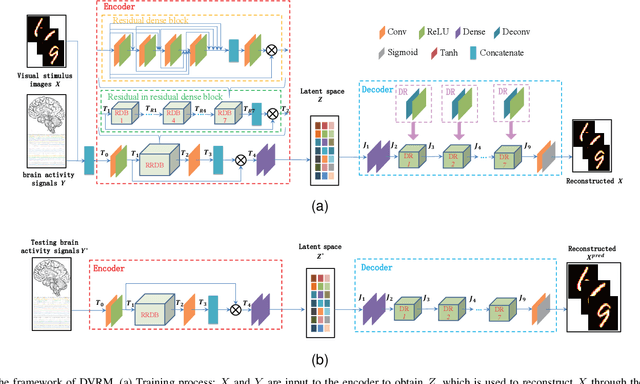
Reconstructing visual stimulus images is a significant task in neural decoding, and up to now, most studies consider the functional magnetic resonance imaging (fMRI) as the signal source. However, the fMRI-based image reconstruction methods are difficult to widely applied because of the complexity and high cost of the acquisition equipments. Considering the advantages of low cost and easy portability of the electroencephalogram (EEG) acquisition equipments, we propose a novel image reconstruction method based on EEG signals in this paper. Firstly, to satisfy the high recognizability of visual stimulus images in fast switching manner, we build a visual stimuli image dataset, and obtain the EEG dataset by a corresponding EEG signals collection experiment. Secondly, the deep visual representation model(DVRM) consisting of a primary encoder and a subordinate decoder is proposed to reconstruct visual stimuli. The encoder is designed based on the residual-in-residual dense blocks to learn the distribution characteristics between EEG signals and visual stimulus images, while the decoder is designed based on the deep neural network to reconstruct the visual stimulus image from the learned deep visual representation. The DVRM can fit the deep and multiview visual features of human natural state and make the reconstructed images more precise. Finally, we evaluate the DVRM in the quality of the generated images on our EEG dataset. The results show that the DVRM have good performance in the task of learning deep visual representation from EEG signals and generating reconstructed images that are realistic and highly resemble the original images.
Learning Exposure Correction in Dynamic Scenes
Mar 10, 2024Capturing videos with wrong exposure usually produces unsatisfactory visual effects. While image exposure correction is a popular topic, the video counterpart is less explored in the literature. Directly applying prior image-based methods to input videos often results in temporal incoherence with low visual quality. Existing research in this area is also limited by the lack of high-quality benchmark datasets. To address these issues, we construct the first real-world paired video dataset, including both underexposure and overexposure dynamic scenes. To achieve spatial alignment, we utilize two DSLR cameras and a beam splitter to simultaneously capture improper and normal exposure videos. In addition, we propose a Video Exposure Correction Network (VECNet) based on Retinex theory, which incorporates a two-stream illumination learning mechanism to enhance the overexposure and underexposure factors, respectively. The estimated multi-frame reflectance and dual-path illumination components are fused at both feature and image levels, leading to visually appealing results. Experimental results demonstrate that the proposed method outperforms existing image exposure correction and underexposed video enhancement methods. The code and dataset will be available soon.
The R2D2 deep neural network series paradigm for fast precision imaging in radio astronomy
Mar 12, 2024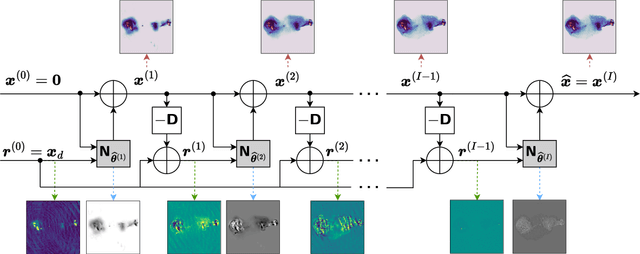
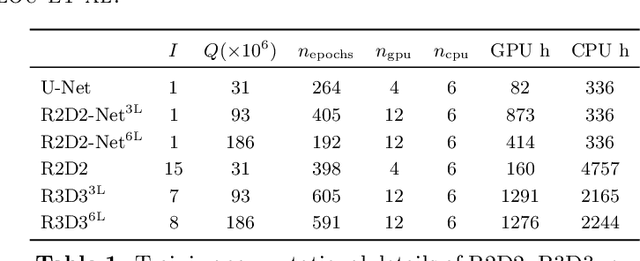

Radio-interferometric (RI) imaging entails solving high-resolution high-dynamic range inverse problems from large data volumes. Recent image reconstruction techniques grounded in optimization theory have demonstrated remarkable capability for imaging precision, well beyond CLEAN's capability. These range from advanced proximal algorithms propelled by handcrafted regularization operators, such as the SARA family, to hybrid plug-and-play (PnP) algorithms propelled by learned regularization denoisers, such as AIRI. Optimization and PnP structures are however highly iterative, which hinders their ability to handle the extreme data sizes expected from future instruments. To address this scalability challenge, we introduce a novel deep learning approach, dubbed ``Residual-to-Residual DNN series for high-Dynamic range imaging''. R2D2's reconstruction is formed as a series of residual images, iteratively estimated as outputs of Deep Neural Networks (DNNs) taking the previous iteration's image estimate and associated data residual as inputs. It thus takes a hybrid structure between a PnP algorithm and a learned version of the matching pursuit algorithm that underpins CLEAN. We present a comprehensive study of our approach, featuring its multiple incarnations distinguished by their DNN architectures. We provide a detailed description of its training process, targeting a telescope-specific approach. R2D2's capability to deliver high precision is demonstrated in simulation, across a variety of image and observation settings using the Very Large Array (VLA). Its reconstruction speed is also demonstrated: with only few iterations required to clean data residuals at dynamic ranges up to 100000, R2D2 opens the door to fast precision imaging. R2D2 codes are available in the BASPLib library on GitHub.
Continual All-in-One Adverse Weather Removal with Knowledge Replay on a Unified Network Structure
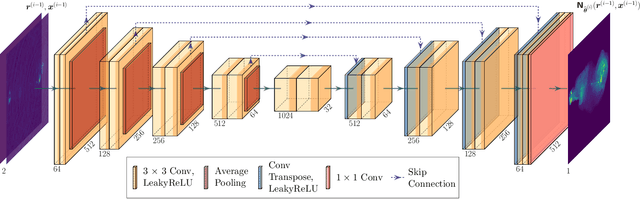
Mar 12, 2024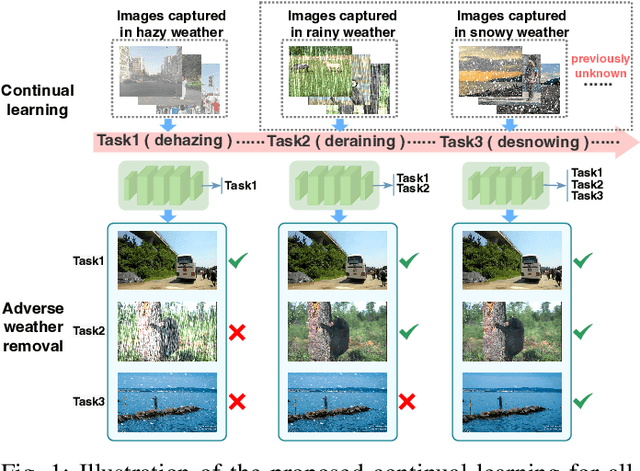
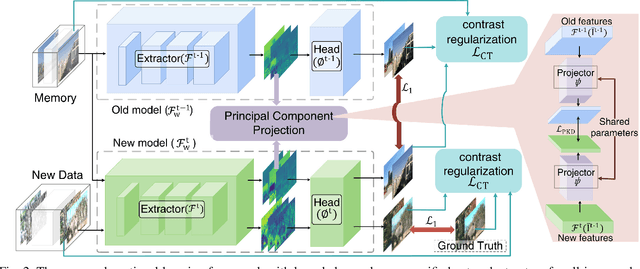
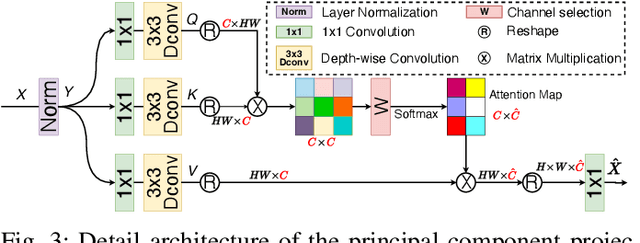

In real-world applications, image degeneration caused by adverse weather is always complex and changes with different weather conditions from days and seasons. Systems in real-world environments constantly encounter adverse weather conditions that are not previously observed. Therefore, it practically requires adverse weather removal models to continually learn from incrementally collected data reflecting various degeneration types. Existing adverse weather removal approaches, for either single or multiple adverse weathers, are mainly designed for a static learning paradigm, which assumes that the data of all types of degenerations to handle can be finely collected at one time before a single-phase learning process. They thus cannot directly handle the incremental learning requirements. To address this issue, we made the earliest effort to investigate the continual all-in-one adverse weather removal task, in a setting closer to real-world applications. Specifically, we develop a novel continual learning framework with effective knowledge replay (KR) on a unified network structure. Equipped with a principal component projection and an effective knowledge distillation mechanism, the proposed KR techniques are tailored for the all-in-one weather removal task. It considers the characteristics of the image restoration task with multiple degenerations in continual learning, and the knowledge for different degenerations can be shared and accumulated in the unified network structure. Extensive experimental results demonstrate the effectiveness of the proposed method to deal with this challenging task, which performs competitively to existing dedicated or joint training image restoration methods. Our code is available at https://github.com/xiaojihh/CL_all-in-one.
JSTR: Joint Spatio-Temporal Reasoning for Event-based Moving Object Detection
Mar 12, 2024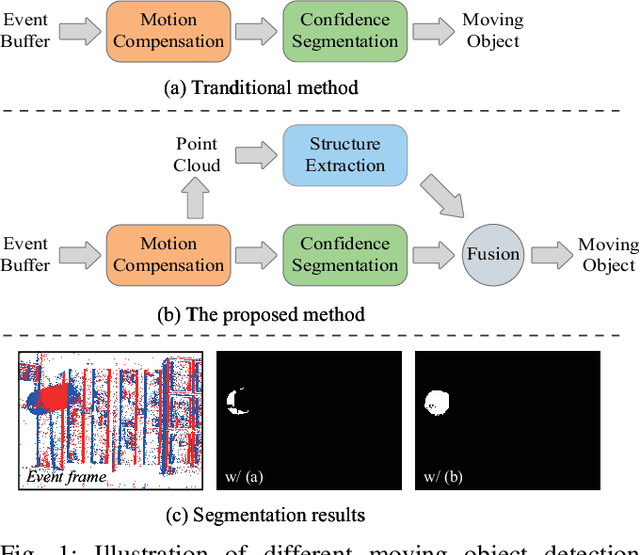
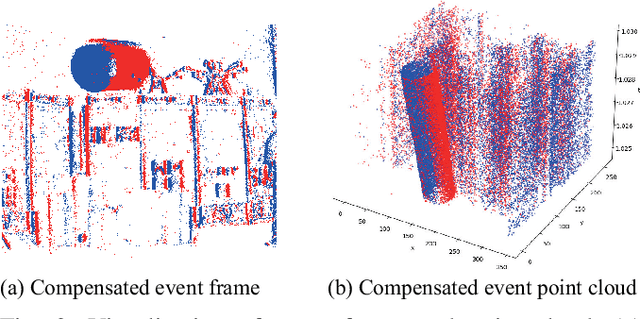
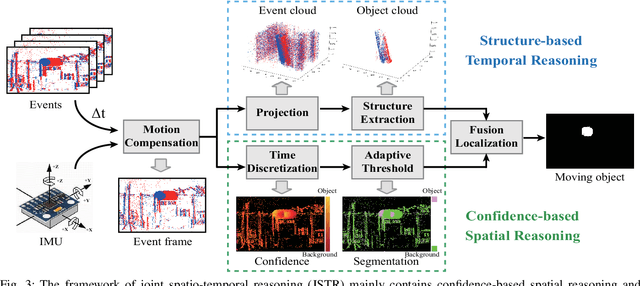

Event-based moving object detection is a challenging task, where static background and moving object are mixed together. Typically, existing methods mainly align the background events to the same spatial coordinate system via motion compensation to distinguish the moving object. However, they neglect the potential spatial tailing effect of moving object events caused by excessive motion, which may affect the structure integrity of the extracted moving object. We discover that the moving object has a complete columnar structure in the point cloud composed of motion-compensated events along the timestamp. Motivated by this, we propose a novel joint spatio-temporal reasoning method for event-based moving object detection. Specifically, we first compensate the motion of background events using inertial measurement unit. In spatial reasoning stage, we project the compensated events into the same image coordinate, discretize the timestamp of events to obtain a time image that can reflect the motion confidence, and further segment the moving object through adaptive threshold on the time image. In temporal reasoning stage, we construct the events into a point cloud along timestamp, and use RANSAC algorithm to extract the columnar shape in the cloud for peeling off the background. Finally, we fuse the results from the two reasoning stages to extract the final moving object region. This joint spatio-temporal reasoning framework can effectively detect the moving object from motion confidence and geometric structure. Moreover, we conduct extensive experiments on various datasets to verify that the proposed method can improve the moving object detection accuracy by 13\%.
Learning A Physical-aware Diffusion Model Based on Transformer for Underwater Image Enhancement
Mar 03, 2024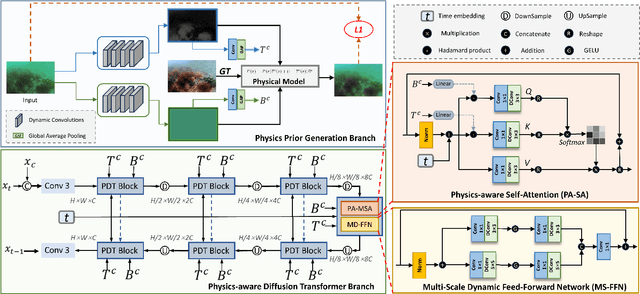
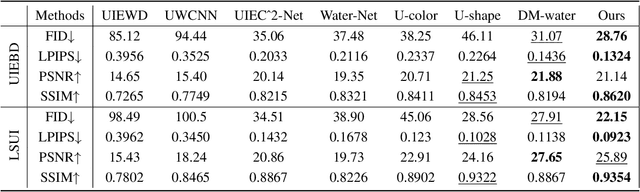


Underwater visuals undergo various complex degradations, inevitably influencing the efficiency of underwater vision tasks. Recently, diffusion models were employed to underwater image enhancement (UIE) tasks, and gained SOTA performance. However, these methods fail to consider the physical properties and underwater imaging mechanisms in the diffusion process, limiting information completion capacity of diffusion models. In this paper, we introduce a novel UIE framework, named PA-Diff, designed to exploiting the knowledge of physics to guide the diffusion process. PA-Diff consists of Physics Prior Generation (PPG) Branch and Physics-aware Diffusion Transformer (PDT) Branch. Our designed PPG branch is a plug-and-play network to produce the physics prior, which can be integrated into any deep framework. With utilizing the physics prior knowledge to guide the diffusion process, PDT branch can obtain underwater-aware ability and model the complex distribution in real-world underwater scenes. Extensive experiments prove that our method achieves best performance on UIE tasks.
CustomSketching: Sketch Concept Extraction for Sketch-based Image Synthesis and Editing
Feb 27, 2024Personalization techniques for large text-to-image (T2I) models allow users to incorporate new concepts from reference images. However, existing methods primarily rely on textual descriptions, leading to limited control over customized images and failing to support fine-grained and local editing (e.g., shape, pose, and details). In this paper, we identify sketches as an intuitive and versatile representation that can facilitate such control, e.g., contour lines capturing shape information and flow lines representing texture. This motivates us to explore a novel task of sketch concept extraction: given one or more sketch-image pairs, we aim to extract a special sketch concept that bridges the correspondence between the images and sketches, thus enabling sketch-based image synthesis and editing at a fine-grained level. To accomplish this, we introduce CustomSketching, a two-stage framework for extracting novel sketch concepts. Considering that an object can often be depicted by a contour for general shapes and additional strokes for internal details, we introduce a dual-sketch representation to reduce the inherent ambiguity in sketch depiction. We employ a shape loss and a regularization loss to balance fidelity and editability during optimization. Through extensive experiments, a user study, and several applications, we show our method is effective and superior to the adapted baselines.