 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dual-Cycle: Self-Supervised Dual-View Fluorescence Microscopy Image Reconstruction using CycleGAN
Sep 23, 2022
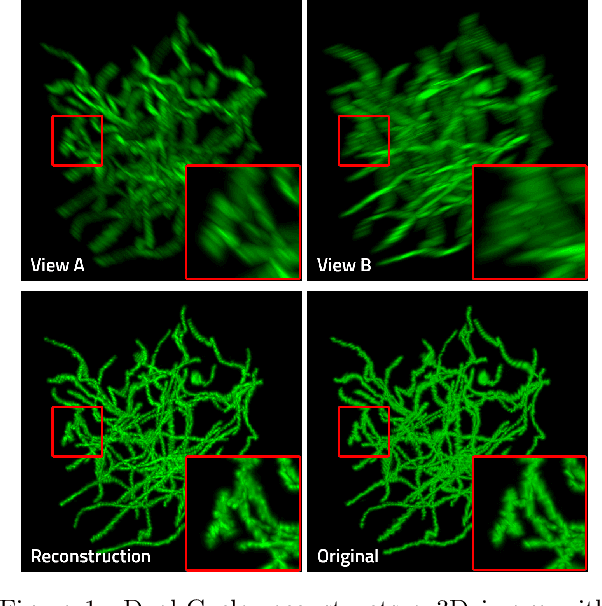

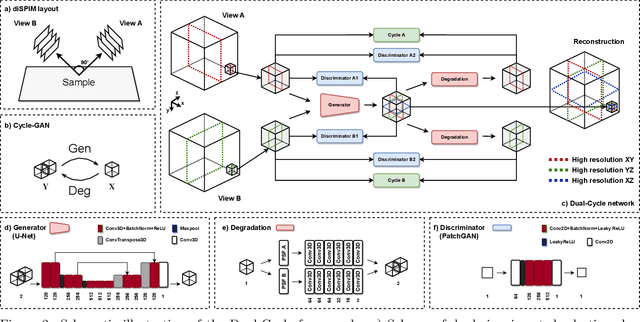
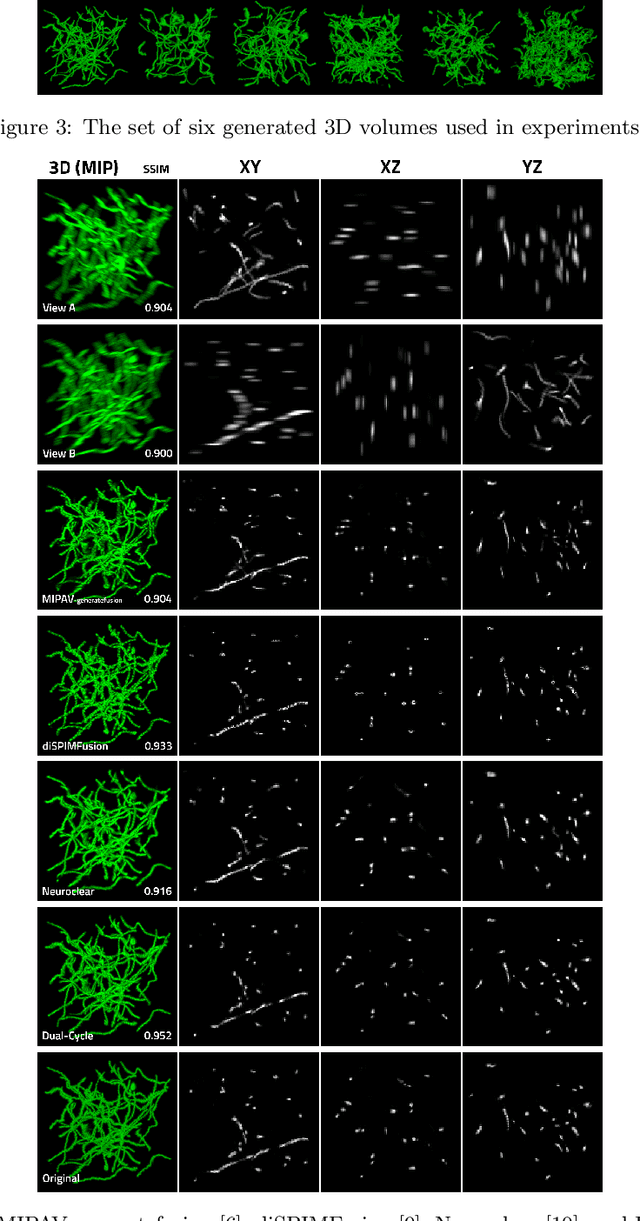
Three-dimensional fluorescence microscopy often suffers from anisotropy, where the resolution along the axial direction is lower than that within the lateral imaging plane. We address this issue by presenting Dual-Cycle, a new framework for joint deconvolution and fusion of dual-view fluorescence images. Inspired by the recent Neuroclear method, Dual-Cycle is designed as a cycle-consistent generative network trained in a self-supervised fashion by combining a dual-view generator and prior-guided degradation model. We validate Dual-Cycle on both synthetic and real data showing its state-of-the-art performance without any external training data.
On the Shift Invariance of Max Pooling Feature Maps in Convolutional Neural Networks
Sep 19, 2022
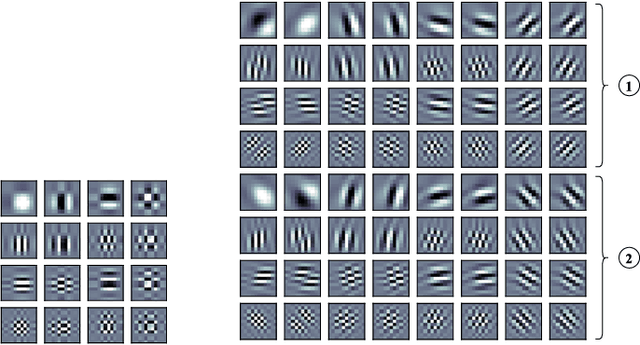
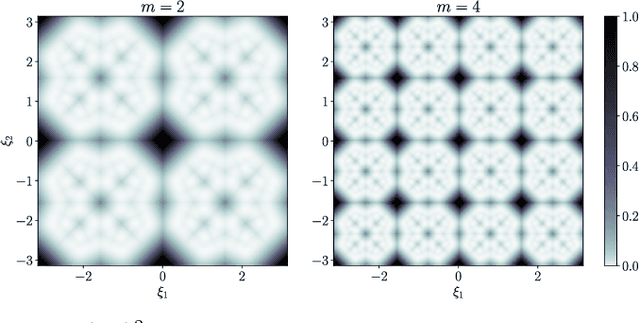
In this paper, we aim to improve the mathematical interpretability of convolutional neural networks for image classification. When trained on natural image datasets, such networks tend to learn parameters in the first layer that closely resemble oriented Gabor filters. By leveraging the properties of discrete Gabor-like convolutions, we prove that, under specific conditions, feature maps computed by the subsequent max pooling operator tend to approximate the modulus of complex Gabor-like coefficients, and as such, are stable with respect to certain input shifts. We then compute a probabilistic measure of shift invariance for these layers. More precisely, we show that some filters, depending on their frequency and orientation, are more likely than others to produce stable image representations. We experimentally validate our theory by considering a deterministic feature extractor based on the dual-tree wavelet packet transform, a particular case of discrete Gabor-like decomposition. We demonstrate a strong correlation between shift invariance on the one hand and similarity with complex modulus on the other hand.
Neural Texture Extraction and Distribution for Controllable Person Image Synthesis
Apr 13, 2022

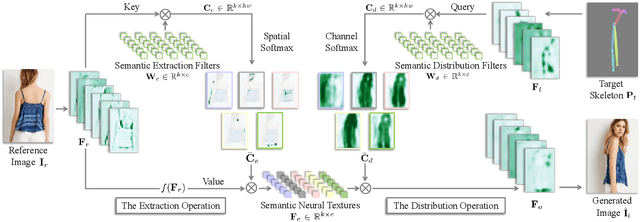
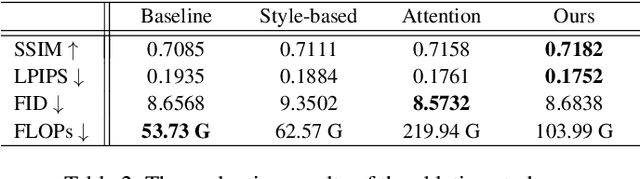
We deal with the controllable person image synthesis task which aims to re-render a human from a reference image with explicit control over body pose and appearance. Observing that person images are highly structured, we propose to generate desired images by extracting and distributing semantic entities of reference images. To achieve this goal, a neural texture extraction and distribution operation based on double attention is described. This operation first extracts semantic neural textures from reference feature maps. Then, it distributes the extracted neural textures according to the spatial distributions learned from target poses. Our model is trained to predict human images in arbitrary poses, which encourages it to extract disentangled and expressive neural textures representing the appearance of different semantic entities. The disentangled representation further enables explicit appearance control. Neural textures of different reference images can be fused to control the appearance of the interested areas. Experimental comparisons show the superiority of the proposed model. Code is available at https://github.com/RenYurui/Neural-Texture-Extraction-Distribution.
Best Prompts for Text-to-Image Models and How to Find Them
Sep 23, 2022

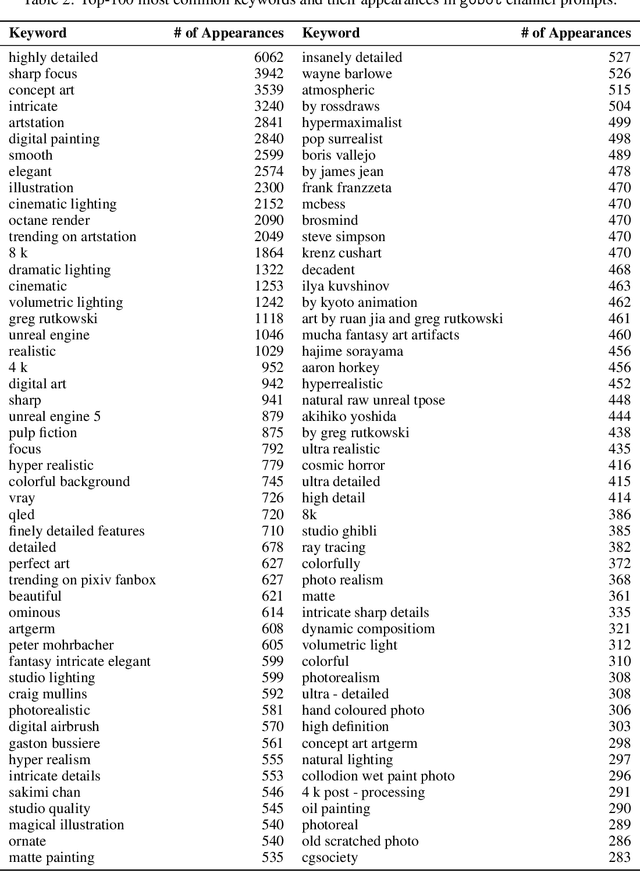

Recent progress in generative models, especially in text-guided diffusion models, has enabled the production of aesthetically-pleasing imagery resembling the works of professional human artists. However, one has to carefully compose the textual description, called the prompt, and augment it with a set of clarifying keywords. Since aesthetics are challenging to evaluate computationally, human feedback is needed to determine the optimal prompt formulation and keyword combination. In this paper, we present a human-in-the-loop approach to learning the most useful combination of prompt keywords using a genetic algorithm. We also show how such an approach can improve the aesthetic appeal of images depicting the same descriptions.
Pruning-based Topology Refinement of 3D Mesh using a 2D Alpha Mask
Oct 17, 2022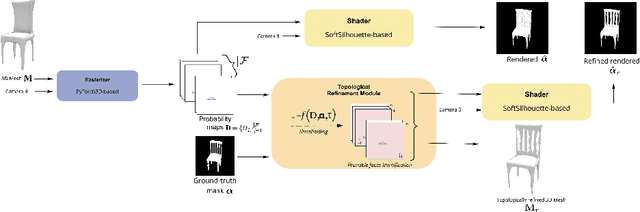


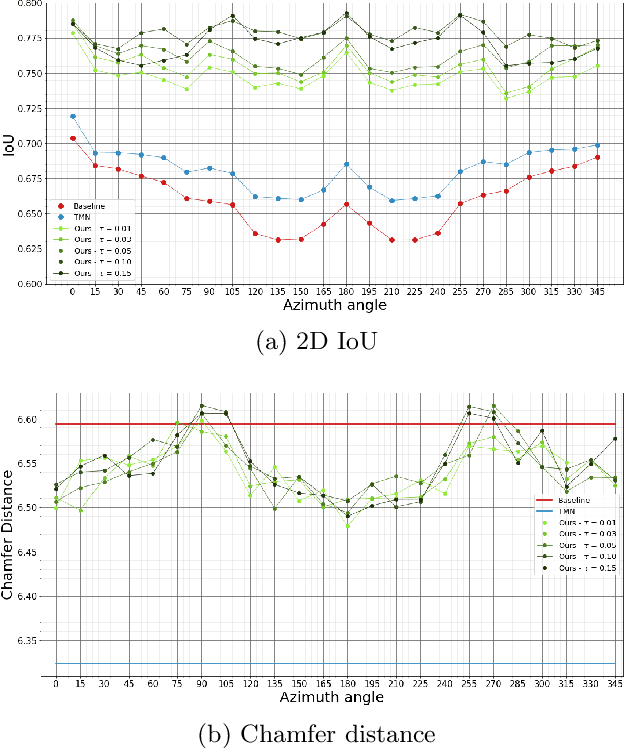
Image-based 3D reconstruction has increasingly stunning results over the past few years with the latest improvements in computer vision and graphics. Geometry and topology are two fundamental concepts when dealing with 3D mesh structures. But the latest often remains a side issue in the 3D mesh-based reconstruction literature. Indeed, performing per-vertex elementary displacements over a 3D sphere mesh only impacts its geometry and leaves the topological structure unchanged and fixed. Whereas few attempts propose to update the geometry and the topology, all need to lean on costly 3D ground-truth to determine the faces/edges to prune. We present in this work a method that aims to refine the topology of any 3D mesh through a face-pruning strategy that extensively relies upon 2D alpha masks and camera pose information. Our solution leverages a differentiable renderer that renders each face as a 2D soft map. Its pixel intensity reflects the probability of being covered during the rendering process by such a face. Based on the 2D soft-masks available, our method is thus able to quickly highlight all the incorrectly rendered faces for a given viewpoint. Because our module is agnostic to the network that produces the 3D mesh, it can be easily plugged into any self-supervised image-based (either synthetic or natural) 3D reconstruction pipeline to get complex meshes with a non-spherical topology.
A Mosquito is Worth 16x16 Larvae: Evaluation of Deep Learning Architectures for Mosquito Larvae Classification
Sep 16, 2022
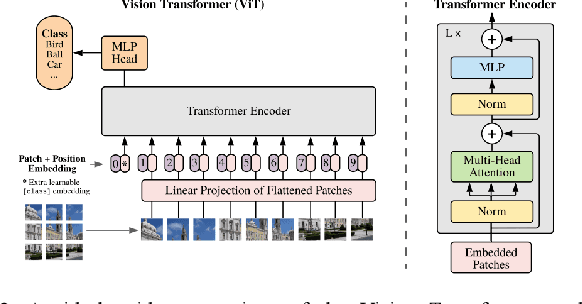
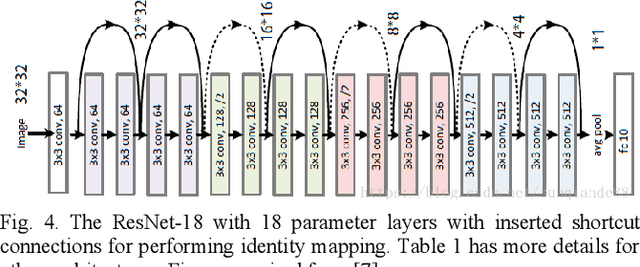
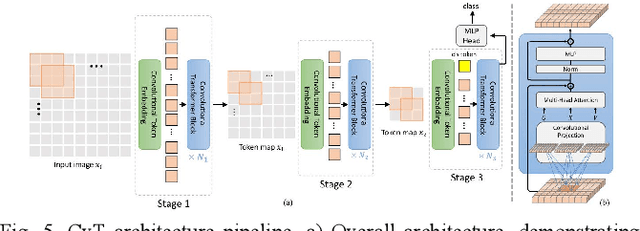
Mosquito-borne diseases (MBDs), such as dengue virus, chikungunya virus, and West Nile virus, cause over one million deaths globally every year. Because many such diseases are spread by the Aedes and Culex mosquitoes, tracking these larvae becomes critical in mitigating the spread of MBDs. Even as citizen science grows and obtains larger mosquito image datasets, the manual annotation of mosquito images becomes ever more time-consuming and inefficient. Previous research has used computer vision to identify mosquito species, and the Convolutional Neural Network (CNN) has become the de-facto for image classification. However, these models typically require substantial computational resources. This research introduces the application of the Vision Transformer (ViT) in a comparative study to improve image classification on Aedes and Culex larvae. Two ViT models, ViT-Base and CvT-13, and two CNN models, ResNet-18 and ConvNeXT, were trained on mosquito larvae image data and compared to determine the most effective model to distinguish mosquito larvae as Aedes or Culex. Testing revealed that ConvNeXT obtained the greatest values across all classification metrics, demonstrating its viability for mosquito larvae classification. Based on these results, future research includes creating a model specifically designed for mosquito larvae classification by combining elements of CNN and transformer architecture.
Mixed-Block Neural Architecture Search for Medical Image Segmentation
Feb 23, 2022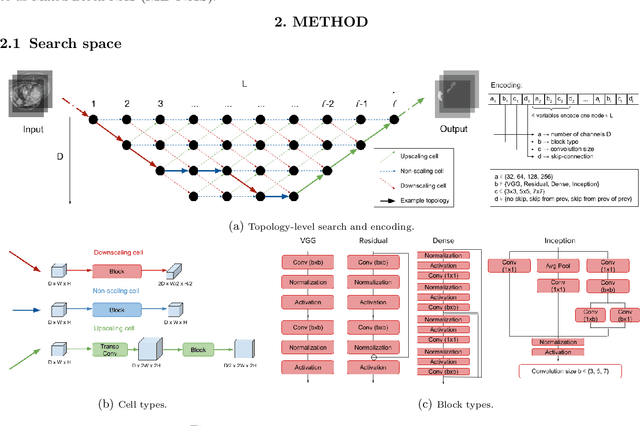
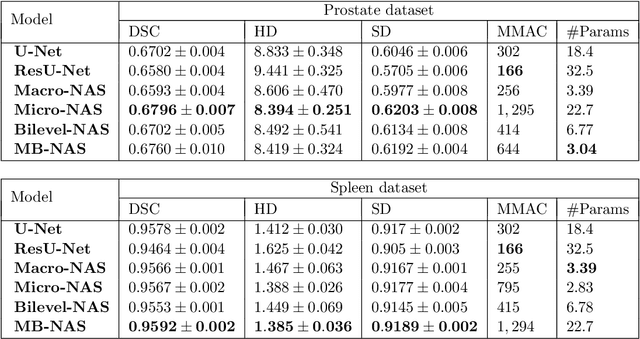
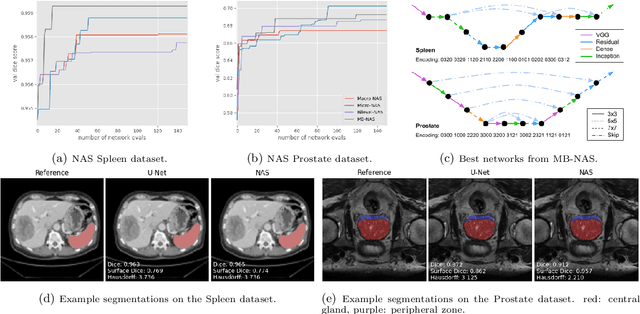
Deep Neural Networks (DNNs) have the potential for making various clinical procedures more time-efficient by automating medical image segmentation. Due to their strong, in some cases human-level, performance, they have become the standard approach in this field. The design of the best possible medical image segmentation DNNs, however, is task-specific. Neural Architecture Search (NAS), i.e., the automation of neural network design, has been shown to have the capability to outperform manually designed networks for various tasks. However, the existing NAS methods for medical image segmentation have explored a quite limited range of types of DNN architectures that can be discovered. In this work, we propose a novel NAS search space for medical image segmentation networks. This search space combines the strength of a generalised encoder-decoder structure, well known from U-Net, with network blocks that have proven to have a strong performance in image classification tasks. The search is performed by looking for the best topology of multiple cells simultaneously with the configuration of each cell within, allowing for interactions between topology and cell-level attributes. From experiments on two publicly available datasets, we find that the networks discovered by our proposed NAS method have better performance than well-known handcrafted segmentation networks, and outperform networks found with other NAS approaches that perform only topology search, and topology-level search followed by cell-level search.
Visual Semantic Segmentation Based on Few/Zero-Shot Learning: An Overview
Nov 13, 2022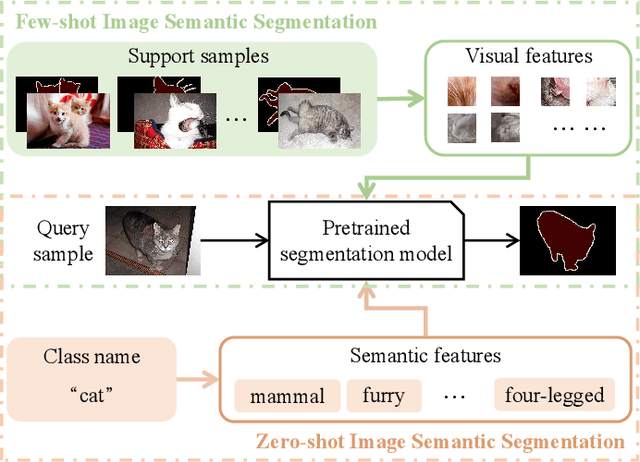
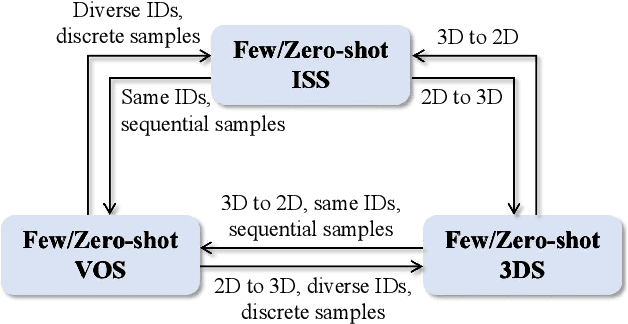
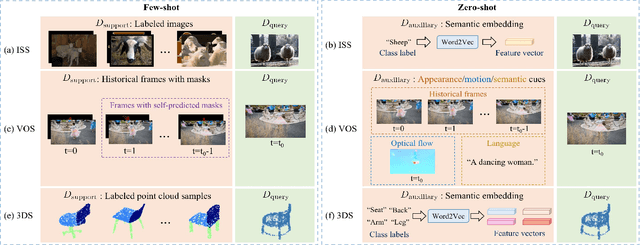
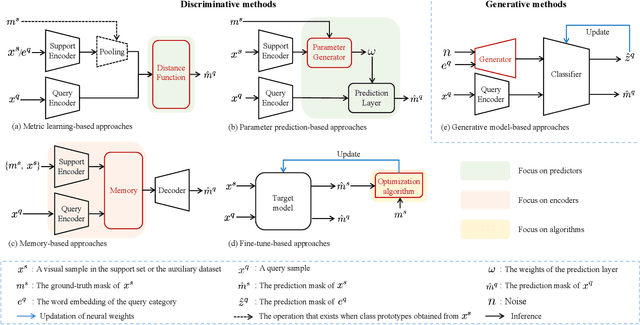
Visual semantic segmentation aims at separating a visual sample into diverse blocks with specific semantic attributes and identifying the category for each block, and it plays a crucial role in environmental perception. Conventional learning-based visual semantic segmentation approaches count heavily on large-scale training data with dense annotations and consistently fail to estimate accurate semantic labels for unseen categories. This obstruction spurs a craze for studying visual semantic segmentation with the assistance of few/zero-shot learning. The emergence and rapid progress of few/zero-shot visual semantic segmentation make it possible to learn unseen-category from a few labeled or zero-labeled samples, which advances the extension to practical applications. Therefore, this paper focuses on the recently published few/zero-shot visual semantic segmentation methods varying from 2D to 3D space and explores the commonalities and discrepancies of technical settlements under different segmentation circumstances. Specifically, the preliminaries on few/zero-shot visual semantic segmentation, including the problem definitions, typical datasets, and technical remedies, are briefly reviewed and discussed. Moreover, three typical instantiations are involved to uncover the interactions of few/zero-shot learning with visual semantic segmentation, including image semantic segmentation, video object segmentation, and 3D segmentation. Finally, the future challenges of few/zero-shot visual semantic segmentation are discussed.
Scale-Aware Crowd Counting Using a Joint Likelihood Density Map and Synthetic Fusion Pyramid Network
Nov 13, 2022
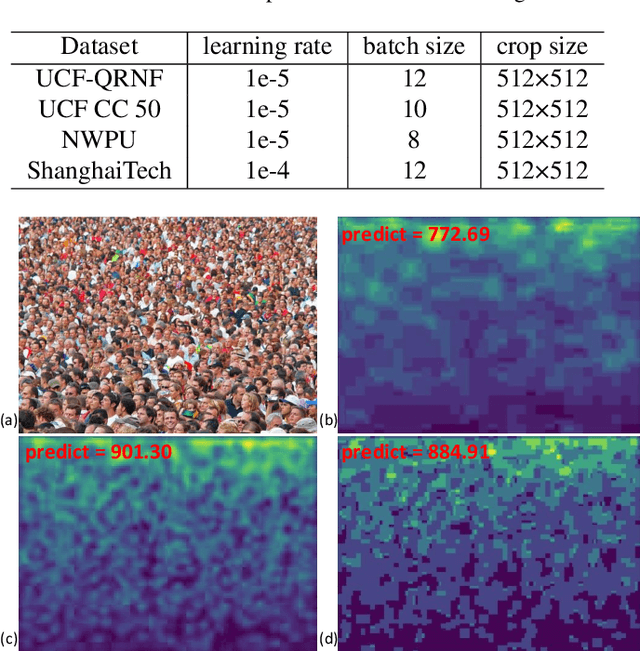
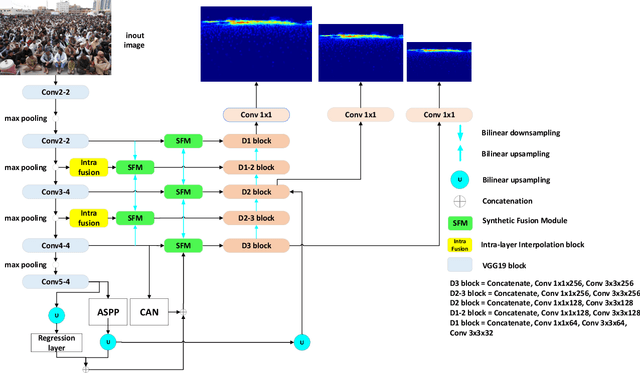
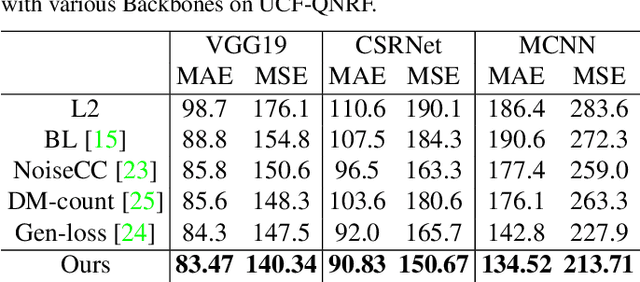
We develop a Synthetic Fusion Pyramid Network (SPF-Net) with a scale-aware loss function design for accurate crowd counting. Existing crowd-counting methods assume that the training annotation points were accurate and thus ignore the fact that noisy annotations can lead to large model-learning bias and counting error, especially for counting highly dense crowds that appear far away. To the best of our knowledge, this work is the first to properly handle such noise at multiple scales in end-to-end loss design and thus push the crowd counting state-of-the-art. We model the noise of crowd annotation points as a Gaussian and derive the crowd probability density map from the input image. We then approximate the joint distribution of crowd density maps with the full covariance of multiple scales and derive a low-rank approximation for tractability and efficient implementation. The derived scale-aware loss function is used to train the SPF-Net. We show that it outperforms various loss functions on four public datasets: UCF-QNRF, UCF CC 50, NWPU and ShanghaiTech A-B datasets. The proposed SPF-Net can accurately predict the locations of people in the crowd, despite training on noisy training annotations.
Quantum Natural Language Generation on Near-Term Devices
Nov 01, 2022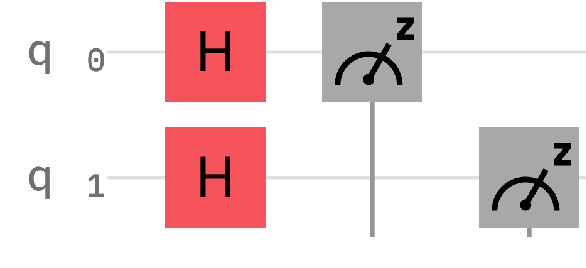
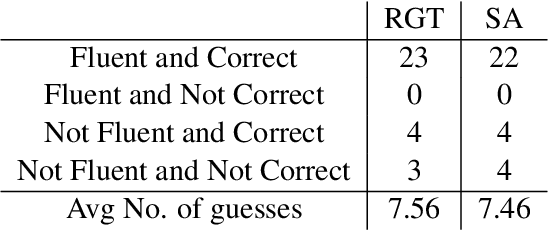
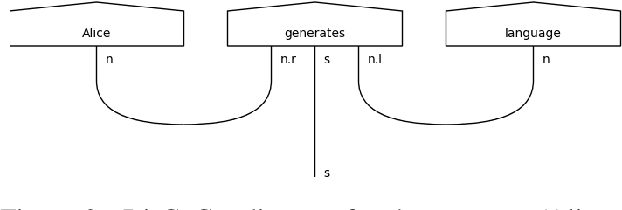
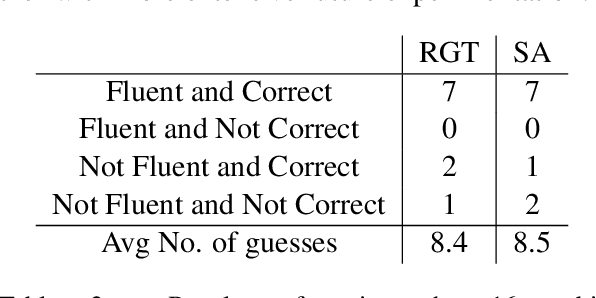
The emergence of noisy medium-scale quantum devices has led to proof-of-concept applications for quantum computing in various domains. Examples include Natural Language Processing (NLP) where sentence classification experiments have been carried out, as well as procedural generation, where tasks such as geopolitical map creation, and image manipulation have been performed. We explore applications at the intersection of these two areas by designing a hybrid quantum-classical algorithm for sentence generation. Our algorithm is based on the well-known simulated annealing technique for combinatorial optimisation. An implementation is provided and used to demonstrate successful sentence generation on both simulated and real quantum hardware. A variant of our algorithm can also be used for music generation. This paper aims to be self-contained, introducing all the necessary background on NLP and quantum computing along the way.