 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Visual onoma-to-wave: environmental sound synthesis from visual onomatopoeias and sound-source images
Oct 17, 2022
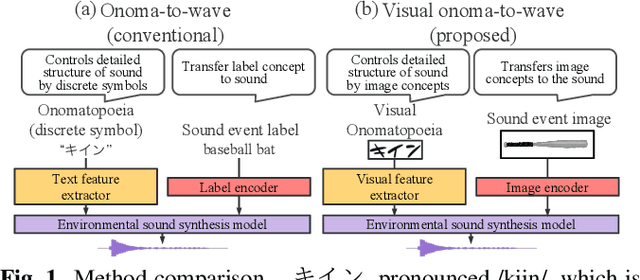
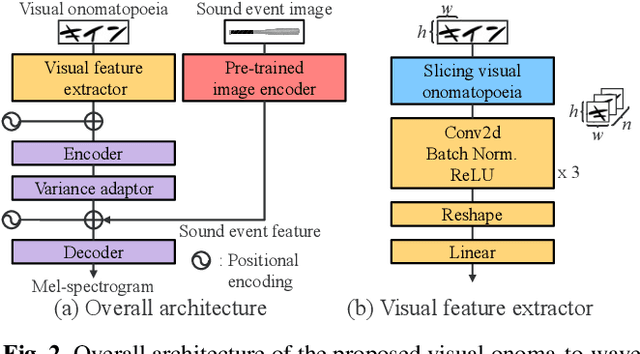

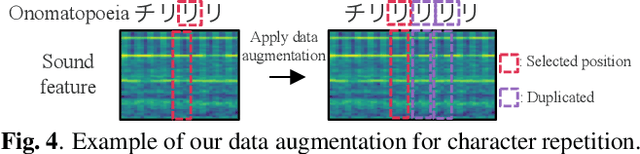
We propose a method for synthesizing environmental sounds from visually represented onomatopoeias and sound sources. An onomatopoeia is a word that imitates a sound structure, i.e., the text representation of sound. From this perspective, onoma-to-wave has been proposed to synthesize environmental sounds from the desired onomatopoeia texts. Onomatopoeias have another representation: visual-text representations of sounds in comics, advertisements, and virtual reality. A visual onomatopoeia (visual text of onomatopoeia) contains rich information that is not present in the text, such as a long-short duration of the image, so the use of this representation is expected to synthesize diverse sounds. Therefore, we propose visual onoma-to-wave for environmental sound synthesis from visual onomatopoeia. The method can transfer visual concepts of the visual text and sound-source image to the synthesized sound. We also propose a data augmentation method focusing on the repetition of onomatopoeias to enhance the performance of our method. An experimental evaluation shows that the methods can synthesize diverse environmental sounds from visual text and sound-source images.
TSP-Bot: Robotic TSP Pen Art using High-DoF Manipulators
Oct 17, 2022
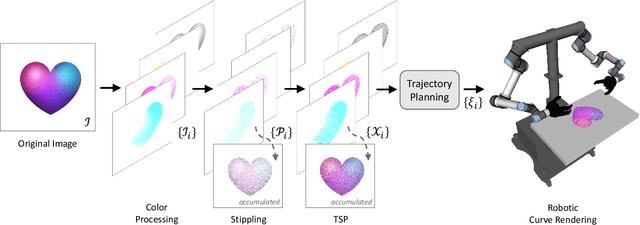
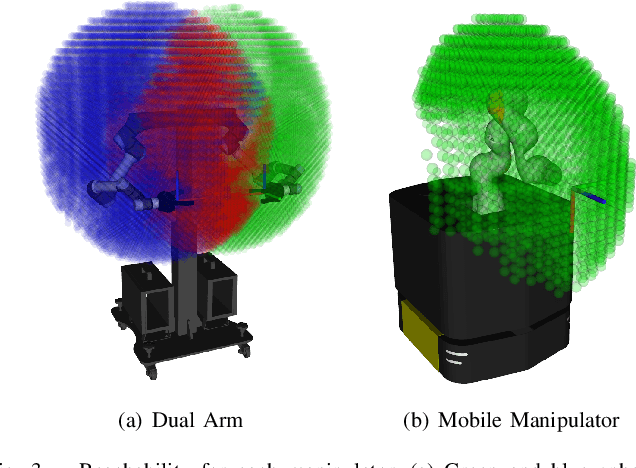

TSP art is an art form for drawing an image using piecewise-continuous line segments with no crossings. This paper presents a multi-color robotic pen drawing system capable of drawing complicated TSP pen art on a planar surface. Given a colored, raster image, we first convert it into a set of points representing the original image's tone by controlling the density of the points. Then, we find a piecewise-continuous linear path that visits every point exactly once, equivalent to solving a Traveling Salesman Problem (TSP). Our robotic drawing system consisting of single or dual manipulators with fingered grippers and a mobile platform, performs the drawing task by following the resulting complex and sophisticated path composed of thousands of TSP sites. As a result, our system can draw a complicated and visually-pleasing TSP pen art with high accuracy and efficiency. We also demonstrate that our system can draw a TSP pen art on a large wall, which is very hard for a human artist to achieve.
Results and findings of the 2021 Image Similarity Challenge
Feb 08, 2022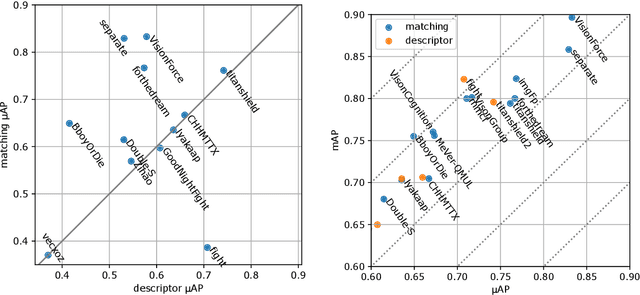
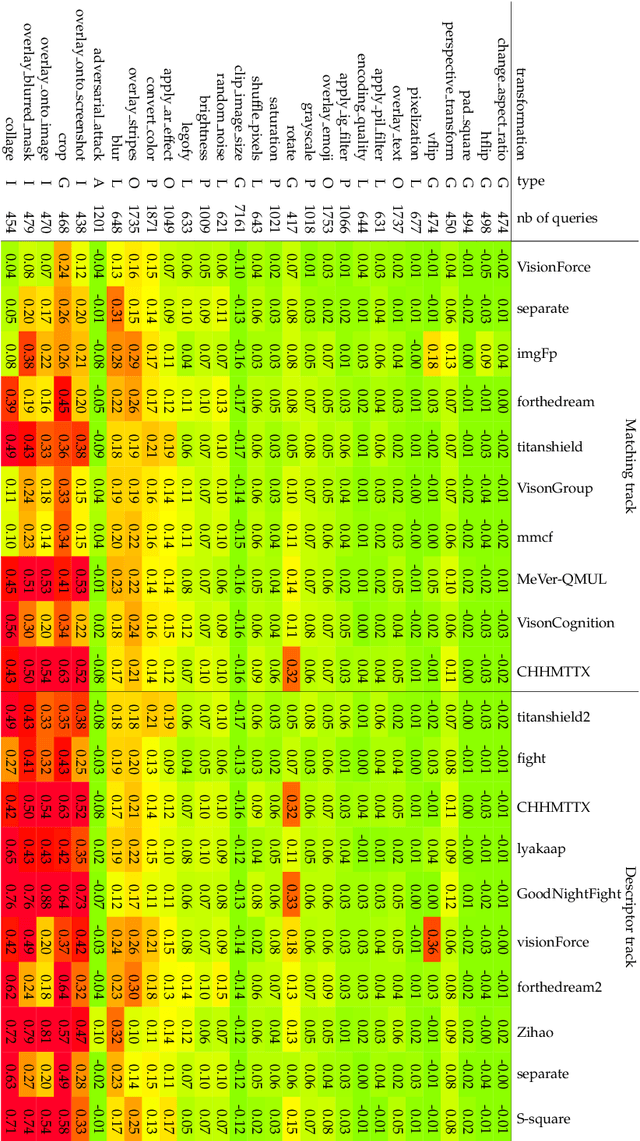
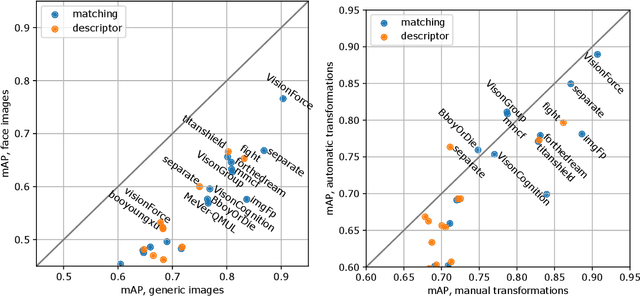
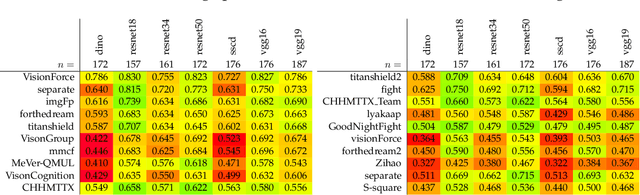
The 2021 Image Similarity Challenge introduced a dataset to serve as a new benchmark to evaluate recent image copy detection methods. There were 200 participants to the competition. This paper presents a quantitative and qualitative analysis of the top submissions. It appears that the most difficult image transformations involve either severe image crops or hiding into unrelated images, combined with local pixel perturbations. The key algorithmic elements in the winning submissions are: training on strong augmentations, self-supervised learning, score normalization, explicit overlay detection, and global descriptor matching followed by pairwise image comparison.
Scale-arbitrary Invertible Image Downscaling
Feb 08, 2022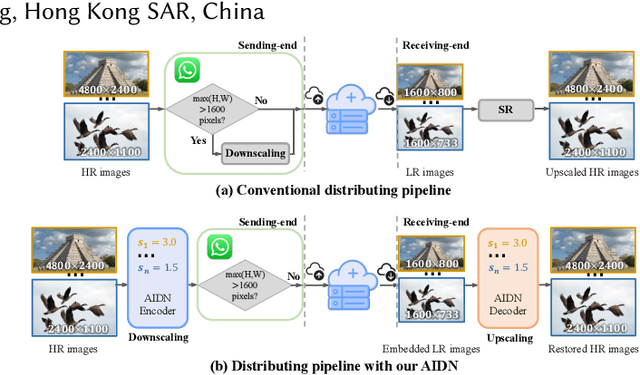
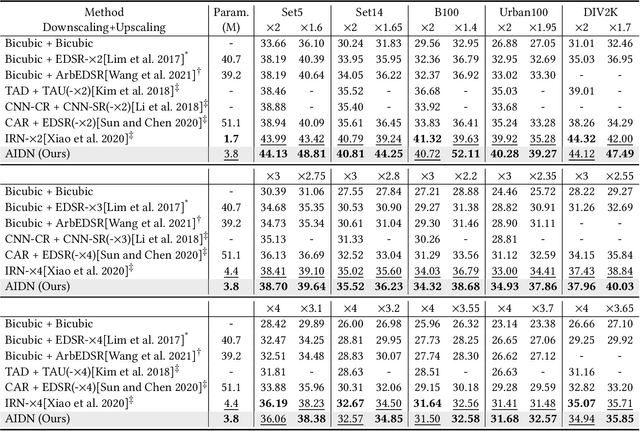
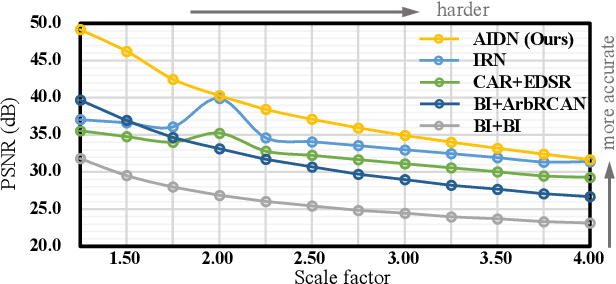
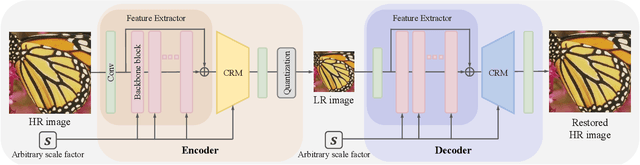
Downscaling is indispensable when distributing high-resolution (HR) images over the Internet to fit the displays of various resolutions, while upscaling is also necessary when users want to see details of the distributed images. Recent invertible image downscaling methods jointly model these two problems and achieve significant improvements. However, they only consider fixed integer scale factors that cannot meet the requirement of conveniently fitting the displays of various resolutions in real-world applications. In this paper, we propose a scale-Arbitrary Invertible image Downscaling Network (AIDN), to natively downscale HR images with arbitrary scale factors for fitting various target resolutions. Meanwhile, the HR information is embedded in the downscaled low-resolution (LR) counterparts in a nearly imperceptible form such that our AIDN can also restore the original HR images solely from the LR images. The key to supporting arbitrary scale factors is our proposed Conditional Resampling Module (CRM) that conditions the downscaling/upscaling kernels and sampling locations on both scale factors and image content. Extensive experimental results demonstrate that our AIDN achieves top performance for invertible downscaling with both arbitrary integer and non-integer scale factors.
CLIP-GEN: Language-Free Training of a Text-to-Image Generator with CLIP
Mar 01, 2022
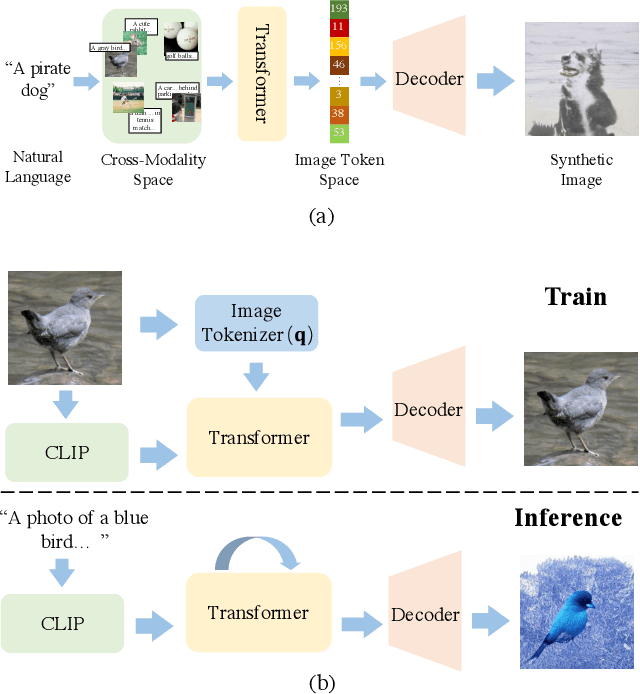
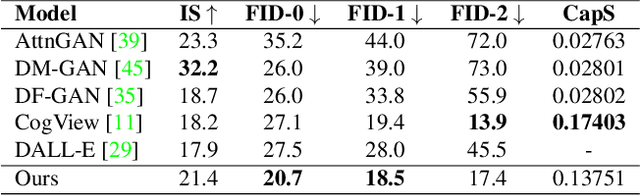
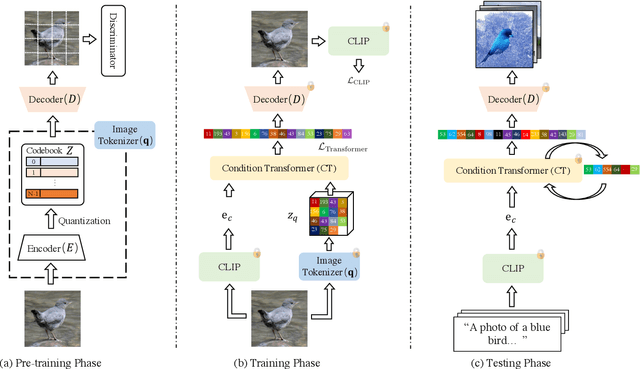
Training a text-to-image generator in the general domain (e.g., Dall.e, CogView) requires huge amounts of paired text-image data, which is too expensive to collect. In this paper, we propose a self-supervised scheme named as CLIP-GEN for general text-to-image generation with the language-image priors extracted with a pre-trained CLIP model. In our approach, we only require a set of unlabeled images in the general domain to train a text-to-image generator. Specifically, given an image without text labels, we first extract the embedding of the image in the united language-vision embedding space with the image encoder of CLIP. Next, we convert the image into a sequence of discrete tokens in the VQGAN codebook space (the VQGAN model can be trained with the unlabeled image dataset in hand). Finally, we train an autoregressive transformer that maps the image tokens from its unified language-vision representation. Once trained, the transformer can generate coherent image tokens based on the text embedding extracted from the text encoder of CLIP upon an input text. Such a strategy enables us to train a strong and general text-to-image generator with large text-free image dataset such as ImageNet. Qualitative and quantitative evaluations verify that our method significantly outperforms optimization-based text-to-image methods in terms of image quality while not compromising the text-image matching. Our method can even achieve comparable performance as flagship supervised models like CogView.
MARSIM: A light-weight point-realistic simulator for LiDAR-based UAVs
Dec 01, 2022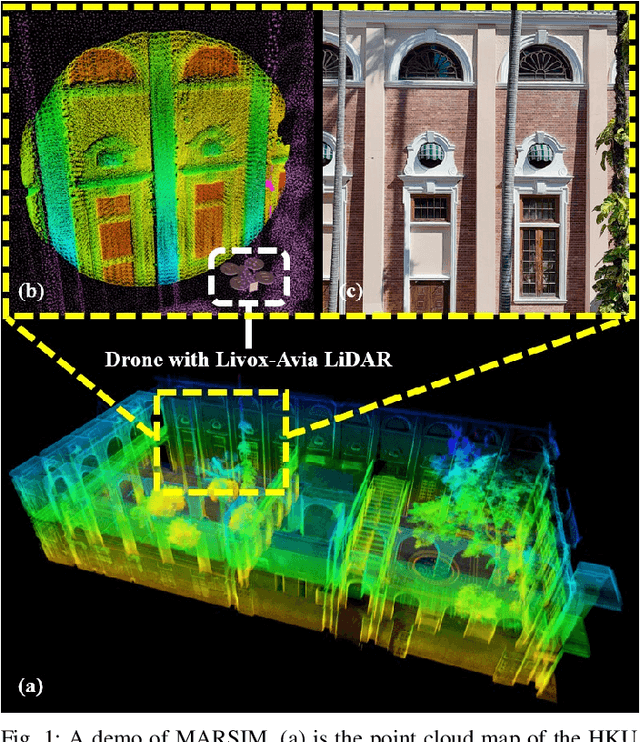
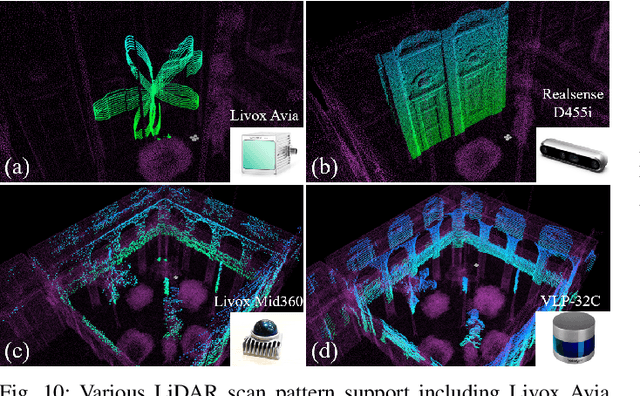
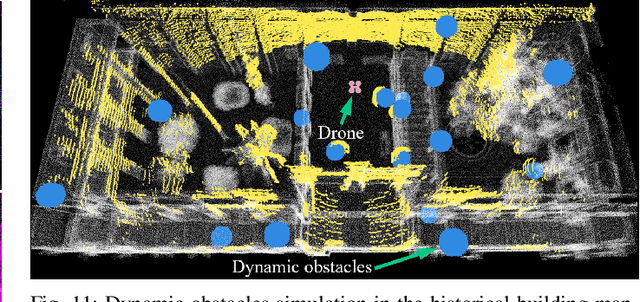
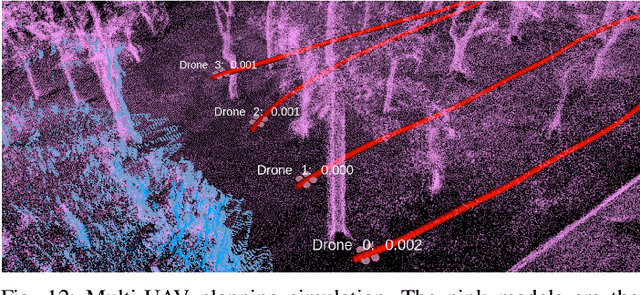
The emergence of low-cost, small form factor and light-weight solid-state LiDAR sensors have brought new opportunities for autonomous unmanned aerial vehicles (UAVs) by advancing navigation safety and computation efficiency. Yet the successful developments of LiDAR-based UAVs must rely on extensive simulations. Existing simulators can hardly perform simulations of real-world environments due to the requirements of dense mesh maps that are difficult to obtain. In this paper, we develop a point-realistic simulator of real-world scenes for LiDAR-based UAVs. The key idea is the underlying point rendering method, where we construct a depth image directly from the point cloud map and interpolate it to obtain realistic LiDAR point measurements. Our developed simulator is able to run on a light-weight computing platform and supports the simulation of LiDARs with different resolution and scanning patterns, dynamic obstacles, and multi-UAV systems. Developed in the ROS framework, the simulator can easily communicate with other key modules of an autonomous robot, such as perception, state estimation, planning, and control. Finally, the simulator provides 10 high-resolution point cloud maps of various real-world environments, including forests of different densities, historic building, office, parking garage, and various complex indoor environments. These realistic maps provide diverse testing scenarios for an autonomous UAV. Evaluation results show that the developed simulator achieves superior performance in terms of time and memory consumption against Gazebo and that the simulated UAV flights highly match the actual one in real-world environments. We believe such a point-realistic and light-weight simulator is crucial to bridge the gap between UAV simulation and experiments and will significantly facilitate the research of LiDAR-based autonomous UAVs in the future.
Exploiting Kernel Compression on BNNs
Dec 01, 2022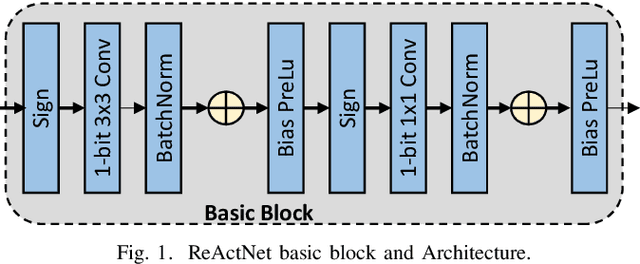
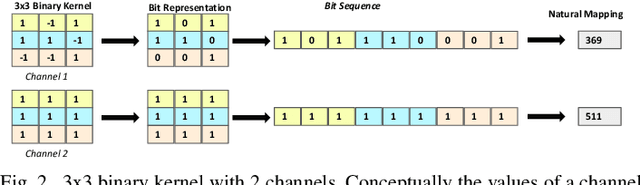
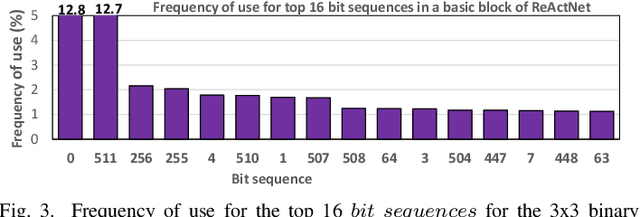
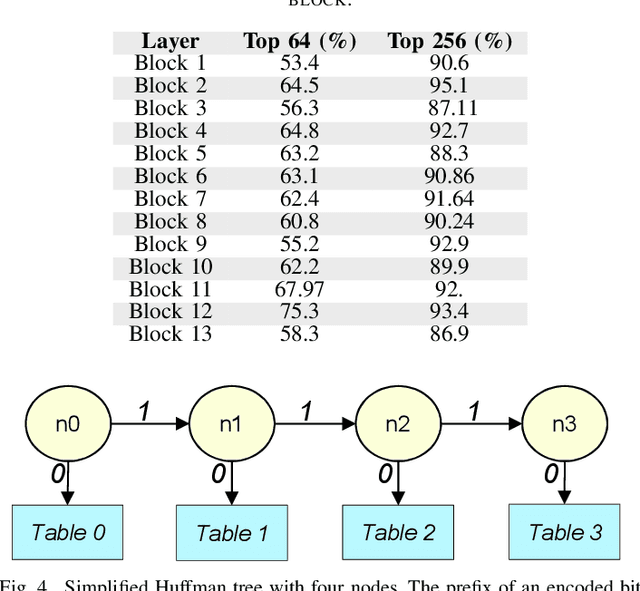
Binary Neural Networks (BNNs) are showing tremendous success on realistic image classification tasks. Notably, their accuracy is similar to the state-of-the-art accuracy obtained by full-precision models tailored to edge devices. In this regard, BNNs are very amenable to edge devices since they employ 1-bit to store the inputs and weights, and thus, their storage requirements are low. Also, BNNs computations are mainly done using xnor and pop-counts operations which are implemented very efficiently using simple hardware structures. Nonetheless, supporting BNNs efficiently on mobile CPUs is far from trivial since their benefits are hindered by frequent memory accesses to load weights and inputs. In BNNs, a weight or an input is stored using one bit, and aiming to increase storage and computation efficiency, several of them are packed together as a sequence of bits. In this work, we observe that the number of unique sequences representing a set of weights is typically low. Also, we have seen that during the evaluation of a BNN layer, a small group of unique sequences is employed more frequently than others. Accordingly, we propose exploiting this observation by using Huffman Encoding to encode the bit sequences and then using an indirection table to decode them during the BNN evaluation. Also, we propose a clustering scheme to identify the most common sequences of bits and replace the less common ones with some similar common sequences. Hence, we decrease the storage requirements and memory accesses since common sequences are encoded with fewer bits. We extend a mobile CPU by adding a small hardware structure that can efficiently cache and decode the compressed sequence of bits. We evaluate our scheme using the ReAacNet model with the Imagenet dataset. Our experimental results show that our technique can reduce memory requirement by 1.32x and improve performance by 1.35x.
Identification of Surface Defects on Solar PV Panels and Wind Turbine Blades using Attention based Deep Learning Model
Nov 23, 2022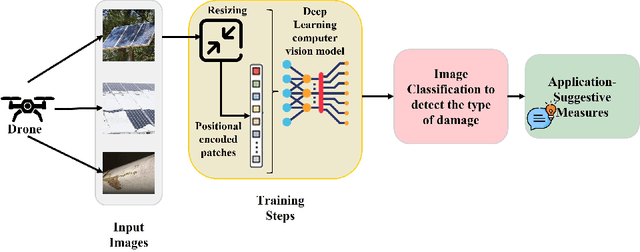



According to Global Electricity Review 2022, electricity generation from renewable energy sources has increased by 20% worldwide primarily due to more installation of large green power plants. Monitoring the renewable energy assets in those large power plants is still challenging as the assets are highly impacted by several environmental factors, resulting in issues like less power generation, malfunctioning, and degradation of asset life. Therefore, detecting the surface defects on the renewable energy assets would facilitate the process to maintain the safety and efficiency of the green power plants. An innovative detection framework is proposed to achieve an economical renewable energy asset surface monitoring system. First capture the asset's high-resolution images on a regular basis and inspect them to detect the damages. For inspection this paper presents a unified deep learning-based image inspection model which analyzes the captured images to identify the surface or structural damages on the various renewable energy assets in large power plants. We use the Vision Transformer (ViT), the latest developed deep-learning model in computer vision, to detect the damages on solar panels and wind turbine blades and classify the type of defect to suggest the preventive measures. With the ViT model, we have achieved above 97% accuracy for both the assets, which outperforms the benchmark classification models for the input images of varied modalities taken from publicly available sources.
Word-Level Representation From Bytes For Language Modeling
Nov 23, 2022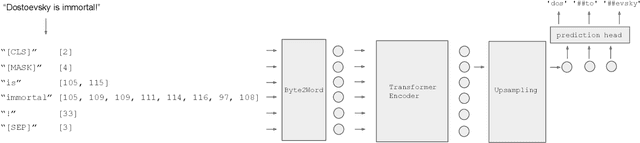
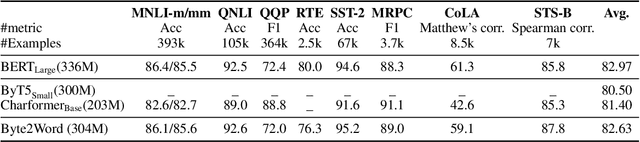

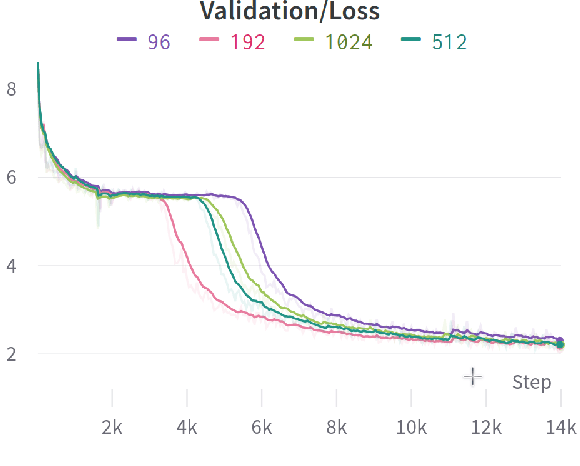
Modern language models mostly take sub-words as input, a design that balances the trade-off between vocabulary size, number of parameters, and performance. However, sub-word tokenization still has disadvantages like not being robust to noise and difficult to generalize to new languages. Also, the current trend of scaling up models reveals that larger models require larger embeddings but that makes parallelization hard. Previous work on image classification proves splitting raw input into a sequence of chucks is a strong, model-agnostic inductive bias. Based on this observation, we rethink the existing character-aware method that takes character-level inputs but makes word-level sequence modeling and prediction. We overhaul this method by introducing a cross-attention network that builds word-level representation directly from bytes, and a sub-word level prediction based on word-level hidden states to avoid the time and space requirement of word-level prediction. With these two improvements combined, we have a token free model with slim input embeddings for downstream tasks. We name our method Byte2Word and perform evaluations on language modeling and text classification. Experiments show that Byte2Word is on par with the strong sub-word baseline BERT but only takes up 10\% of embedding size. We further test our method on synthetic noise and cross-lingual transfer and find it competitive to baseline methods on both settings.
Crown-CAM: Reliable Visual Explanations for Tree Crown Detection in Aerial Images
Nov 23, 2022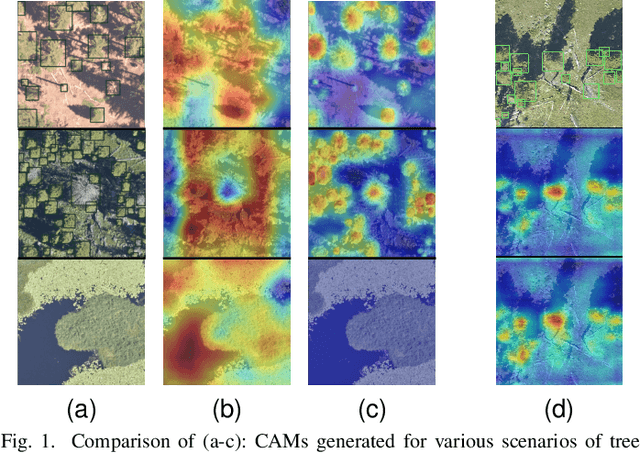
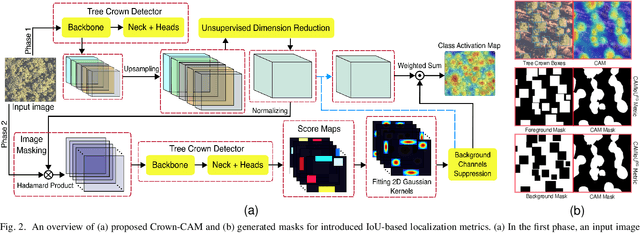
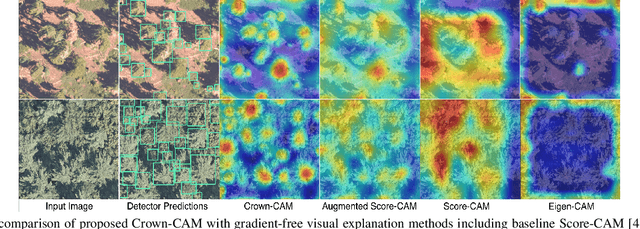

Visual explanation of "black-box" models has enabled researchers and experts in artificial intelligence (AI) to exploit the localization abilities of such methods to a much greater extent. Despite most of the developed visual explanation methods applied to single object classification problems, they are not well-explored in the detection task, where the challenges may go beyond simple coarse area-based discrimination. This is of particular importance when a detector should face several objects with different scales from various viewpoints or if the objects of interest are absent. In this paper, we propose CrownCAM to generate reliable visual explanations for the challenging and dynamic problem of tree crown detection in aerial images. It efficiently provides fine-grain localization of tree crowns and non-contextual background suppression for scenarios with highly dense forest trees in the presence of potential distractors or scenes without tree crowns. Additionally, two Intersection over Union (IoU)-based metrics are introduced that can effectively quantify both the accuracy and inaccuracy of generated visual explanations with respect to regions with or without tree crowns in the image. Empirical evaluations demonstrate that the proposed Crown-CAM outperforms the Score-CAM, Augmented ScoreCAM, and Eigen-CAM methods by an average IoU margin of 8.7, 5.3, and 21.7 (and 3.3, 9.8, and 16.5) respectively in improving the accuracy (and decreasing inaccuracy) of visual explanations on the challenging NEON tree crown dataset.