 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multiple Degradation and Reconstruction Network for Single Image Denoising via Knowledge Distillation
Apr 29, 2022

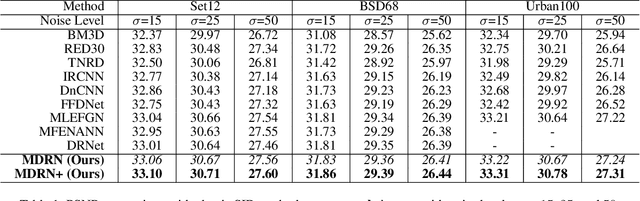

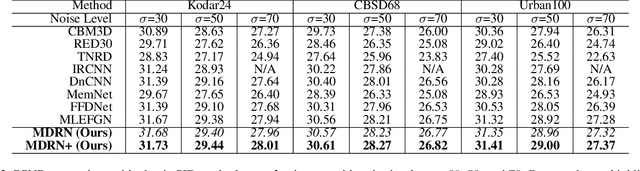
Single image denoising (SID) has achieved significant breakthroughs with the development of deep learning. However, the proposed methods are often accompanied by plenty of parameters, which greatly limits their application scenarios. Different from previous works that blindly increase the depth of the network, we explore the degradation mechanism of the noisy image and propose a lightweight Multiple Degradation and Reconstruction Network (MDRN) to progressively remove noise. Meanwhile, we propose two novel Heterogeneous Knowledge Distillation Strategies (HMDS) to enable MDRN to learn richer and more accurate features from heterogeneous models, which make it possible to reconstruct higher-quality denoised images under extreme conditions. Extensive experiments show that our MDRN achieves favorable performance against other SID models with fewer parameters. Meanwhile, plenty of ablation studies demonstrate that the introduced HMDS can improve the performance of tiny models or the model under high noise levels, which is extremely useful for related applications.
Masked Reconstruction Contrastive Learning with Information Bottleneck Principle
Nov 15, 2022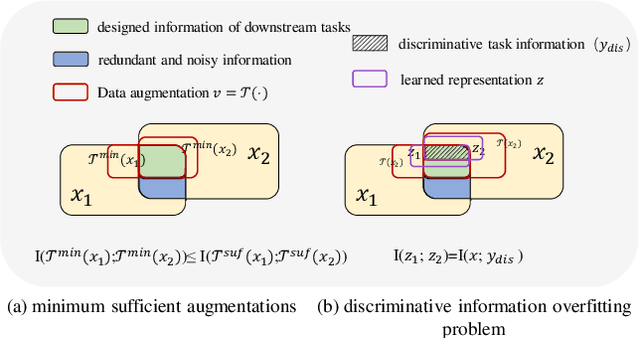
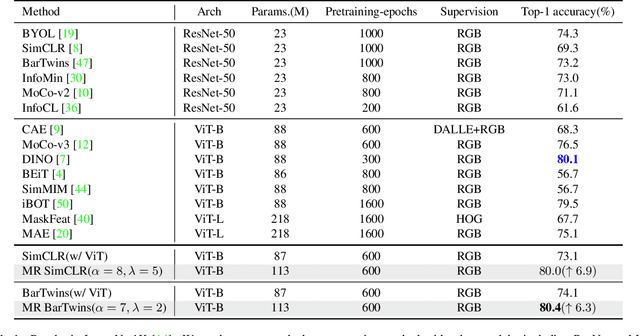
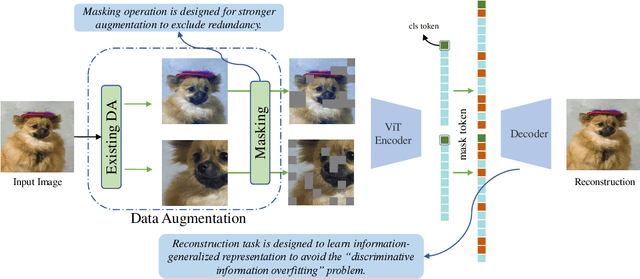
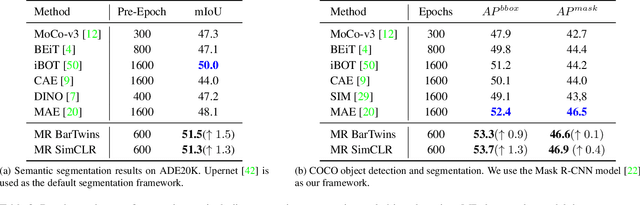
Contrastive learning (CL) has shown great power in self-supervised learning due to its ability to capture insight correlations among large-scale data. Current CL models are biased to learn only the ability to discriminate positive and negative pairs due to the discriminative task setting. However, this bias would lead to ignoring its sufficiency for other downstream tasks, which we call the discriminative information overfitting problem. In this paper, we propose to tackle the above problems from the aspect of the Information Bottleneck (IB) principle, further pushing forward the frontier of CL. Specifically, we present a new perspective that CL is an instantiation of the IB principle, including information compression and expression. We theoretically analyze the optimal information situation and demonstrate that minimum sufficient augmentation and information-generalized representation are the optimal requirements for achieving maximum compression and generalizability to downstream tasks. Therefore, we propose the Masked Reconstruction Contrastive Learning~(MRCL) model to improve CL models. For implementation in practice, MRCL utilizes the masking operation for stronger augmentation, further eliminating redundant and noisy information. In order to alleviate the discriminative information overfitting problem effectively, we employ the reconstruction task to regularize the discriminative task. We conduct comprehensive experiments and show the superiority of the proposed model on multiple tasks, including image classification, semantic segmentation and objective detection.
Application of Graph Based Features in Computer Aided Diagnosis for Histopathological Image Classification of Gastric Cancer
May 17, 2022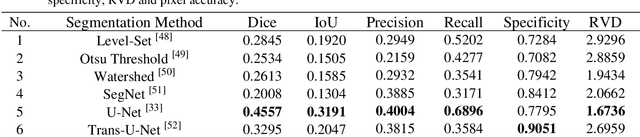
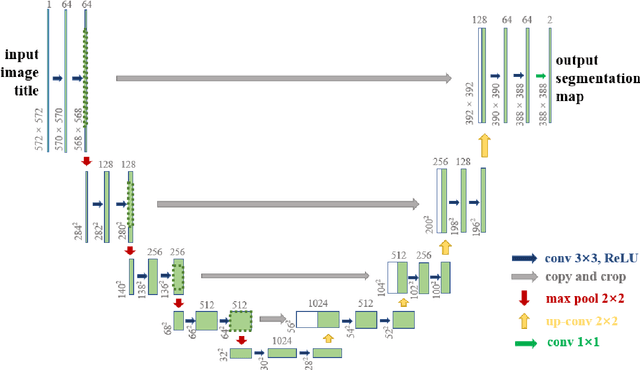

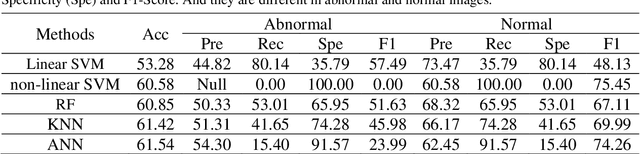
The gold standard for gastric cancer detection is gastric histopathological image analysis, but there are certain drawbacks in the existing histopathological detection and diagnosis. In this paper, based on the study of computer aided diagnosis system, graph based features are applied to gastric cancer histopathology microscopic image analysis, and a classifier is used to classify gastric cancer cells from benign cells. Firstly, image segmentation is performed, and after finding the region, cell nuclei are extracted using the k-means method, the minimum spanning tree (MST) is drawn, and graph based features of the MST are extracted. The graph based features are then put into the classifier for classification. In this study, different segmentation methods are compared in the tissue segmentation stage, among which are Level-Set, Otsu thresholding, watershed, SegNet, U-Net and Trans-U-Net segmentation; Graph based features, Red, Green, Blue features, Grey-Level Co-occurrence Matrix features, Histograms of Oriented Gradient features and Local Binary Patterns features are compared in the feature extraction stage; Radial Basis Function (RBF) Support Vector Machine (SVM), Linear SVM, Artificial Neural Network, Random Forests, k-NearestNeighbor, VGG16, and Inception-V3 are compared in the classifier stage. It is found that using U-Net to segment tissue areas, then extracting graph based features, and finally using RBF SVM classifier gives the optimal results with 94.29%.
Exploring Structural Sparsity in Neural Image Compression
Feb 10, 2022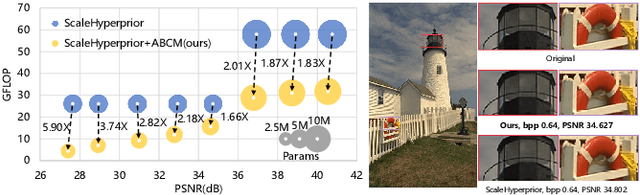
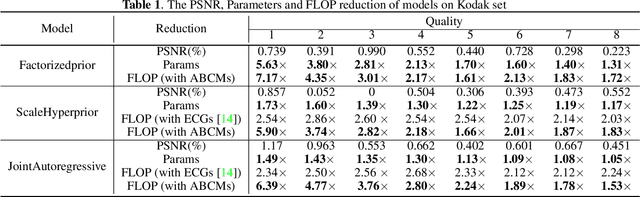
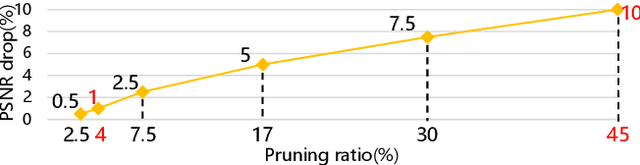

Neural image compression have reached or out-performed traditional methods (such as JPEG, BPG, WebP). However,their sophisticated network structures with cascaded convolution layers bring heavy computational burden for practical deployment. In this paper, we explore the structural sparsity in neural image compression network to obtain real-time acceleration without any specialized hardware design or algorithm. We propose a simple plug-in adaptive binary channel masking(ABCM) to judge the importance of each convolution channel and introduce sparsity during training. During inference, the unimportant channels are pruned to obtain slimmer network and less computation. We implement our method into three neural image compression networks with different entropy models to verify its effectiveness and generalization, the experiment results show that up to 7x computation reduction and 3x acceleration can be achieved with negligible performance drop.
mm-Wave Radar Hand Shape Classification Using Deformable Transformers
Oct 24, 2022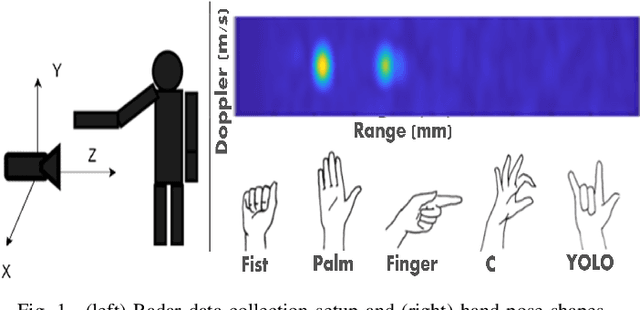

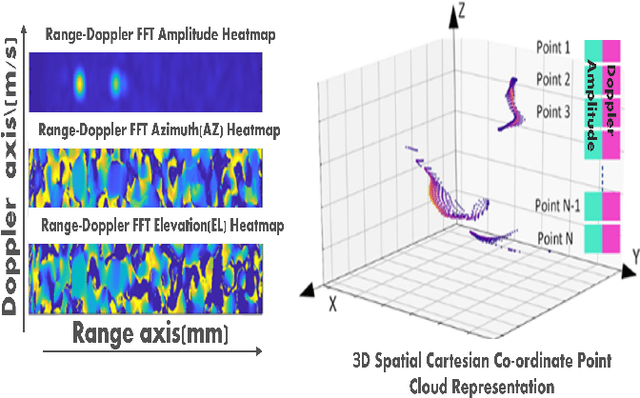
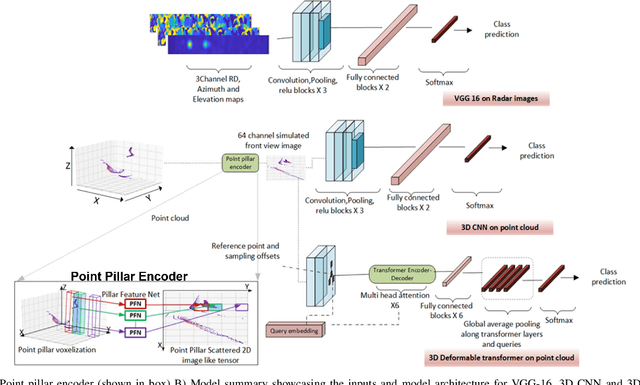
A novel, real-time, mm-Wave radar-based static hand shape classification algorithm and implementation are proposed. The method finds several applications in low cost and privacy sensitive touchless control technology using 60 Ghz radar as the sensor input. As opposed to prior Range-Doppler image based 2D classification solutions, our method converts raw radar data to 3D sparse cartesian point clouds.The demonstrated 3D radar neural network model using deformable transformers significantly surpasses the performance results set by prior methods which either utilize custom signal processing or apply generic convolutional techniques on Range-Doppler FFT images. Experiments are performed on an internally collected dataset using an off-the-shelf radar sensor.
Conditional GANs for Sonar Image Filtering with Applications to Underwater Occupancy Mapping
Sep 23, 2022
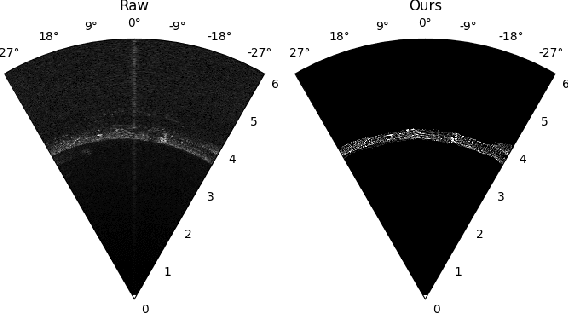
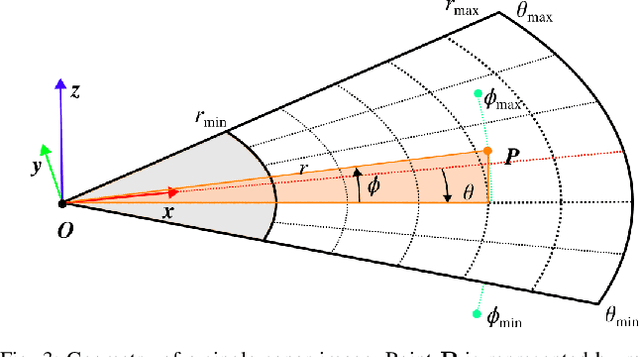
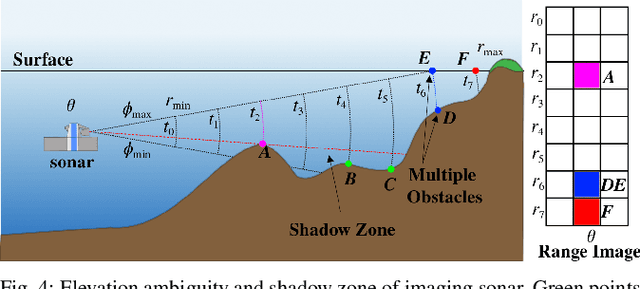
Underwater robots typically rely on acoustic sensors like sonar to perceive their surroundings. However, these sensors are often inundated with multiple sources and types of noise, which makes using raw data for any meaningful inference with features, objects, or boundary returns very difficult. While several conventional methods of dealing with noise exist, their success rates are unsatisfactory. This paper presents a novel application of conditional Generative Adversarial Networks (cGANs) to train a model to produce noise-free sonar images, outperforming several conventional filtering methods. Estimating free space is crucial for autonomous robots performing active exploration and mapping. Thus, we apply our approach to the task of underwater occupancy mapping and show superior free and occupied space inference when compared to conventional methods.
The transport problem for non-additive measures
Nov 23, 2022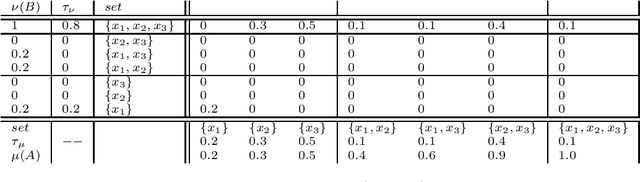
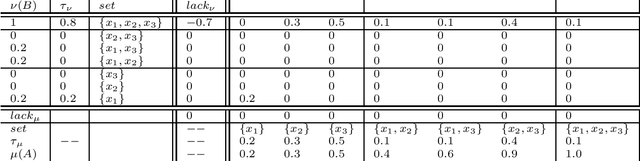

Non-additive measures, also known as fuzzy measures, capacities, and monotonic games, are increasingly used in different fields. Applications have been built within computer science and artificial intelligence related to e.g. decision making, image processing, machine learning for both classification, and regression. Tools for measure identification have been built. In short, as non-additive measures are more general than additive ones (i.e., than probabilities), they have better modeling capabilities allowing to model situations and problems that cannot be modelled by the latter. See e.g. the application of non-additive measures and the Choquet integral to model both Ellsberg paradox and Allais paradox. Because of that, there is an increasing need to analyze non-additive measures. The need for distances and similarities to compare them is no exception. Some work has been done for definining $f$-divergence for them. In this work we tackle the problem of definining the transport problem for non-additive measures, which has not been considered up to our knowledge up to now. Distances for pairs of probability distributions based on the optimal transport are extremely used in practical applications, and they are being studied extensively for the mathematical properties. We consider that it is necessary to provide appropriate definitions with a similar flavour, and that generalize the standard ones, for non-additive measures. We provide definitions based on the M\"obius transform, but also based on the $(\max, +)$-transform that we consider that has some advantages. We will discuss in this paper the problems that arise to define the transport problem for non-additive measures, and discuss ways to solve them. In this paper we provide the definitions of the optimal transport problem, and prove some properties.
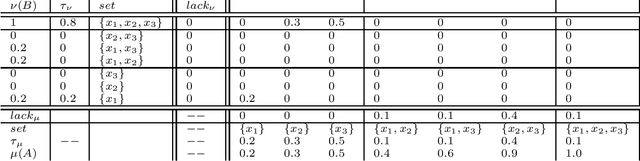
Dual-Cycle: Self-Supervised Dual-View Fluorescence Microscopy Image Reconstruction using CycleGAN
Sep 23, 2022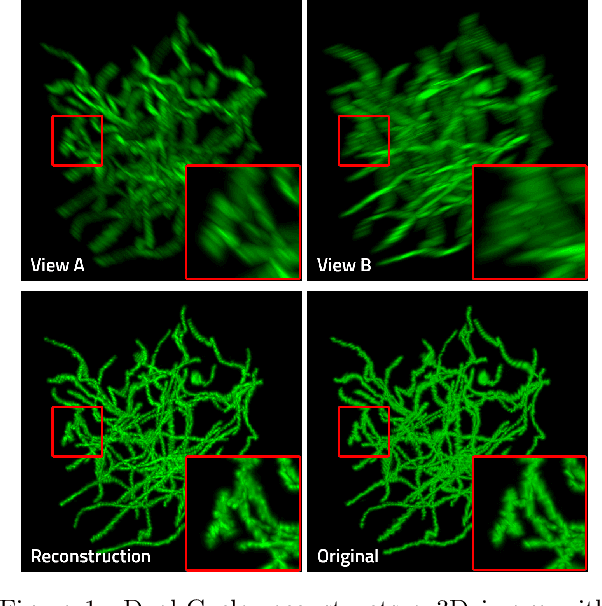

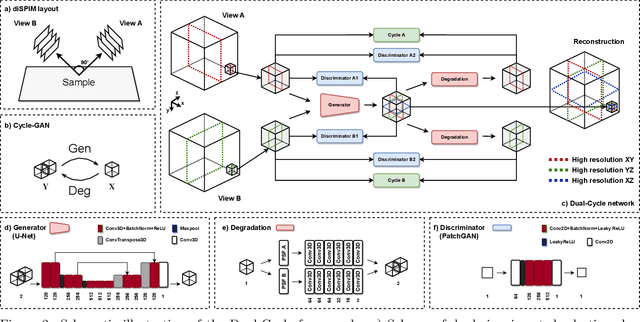
Three-dimensional fluorescence microscopy often suffers from anisotropy, where the resolution along the axial direction is lower than that within the lateral imaging plane. We address this issue by presenting Dual-Cycle, a new framework for joint deconvolution and fusion of dual-view fluorescence images. Inspired by the recent Neuroclear method, Dual-Cycle is designed as a cycle-consistent generative network trained in a self-supervised fashion by combining a dual-view generator and prior-guided degradation model. We validate Dual-Cycle on both synthetic and real data showing its state-of-the-art performance without any external training data.
Best Prompts for Text-to-Image Models and How to Find Them
Sep 23, 2022


Recent progress in generative models, especially in text-guided diffusion models, has enabled the production of aesthetically-pleasing imagery resembling the works of professional human artists. However, one has to carefully compose the textual description, called the prompt, and augment it with a set of clarifying keywords. Since aesthetics are challenging to evaluate computationally, human feedback is needed to determine the optimal prompt formulation and keyword combination. In this paper, we present a human-in-the-loop approach to learning the most useful combination of prompt keywords using a genetic algorithm. We also show how such an approach can improve the aesthetic appeal of images depicting the same descriptions.
On the Shift Invariance of Max Pooling Feature Maps in Convolutional Neural Networks
Sep 19, 2022
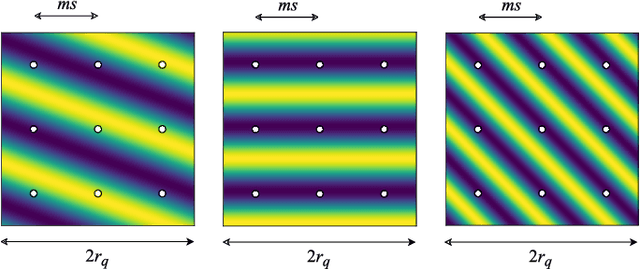
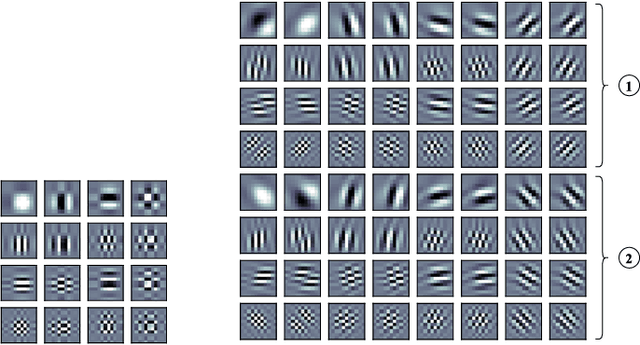
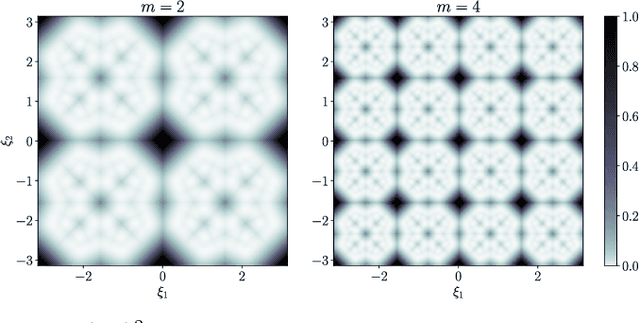
In this paper, we aim to improve the mathematical interpretability of convolutional neural networks for image classification. When trained on natural image datasets, such networks tend to learn parameters in the first layer that closely resemble oriented Gabor filters. By leveraging the properties of discrete Gabor-like convolutions, we prove that, under specific conditions, feature maps computed by the subsequent max pooling operator tend to approximate the modulus of complex Gabor-like coefficients, and as such, are stable with respect to certain input shifts. We then compute a probabilistic measure of shift invariance for these layers. More precisely, we show that some filters, depending on their frequency and orientation, are more likely than others to produce stable image representations. We experimentally validate our theory by considering a deterministic feature extractor based on the dual-tree wavelet packet transform, a particular case of discrete Gabor-like decomposition. We demonstrate a strong correlation between shift invariance on the one hand and similarity with complex modulus on the other hand.