 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Conditional GANs for Sonar Image Filtering with Applications to Underwater Occupancy Mapping
Sep 23, 2022

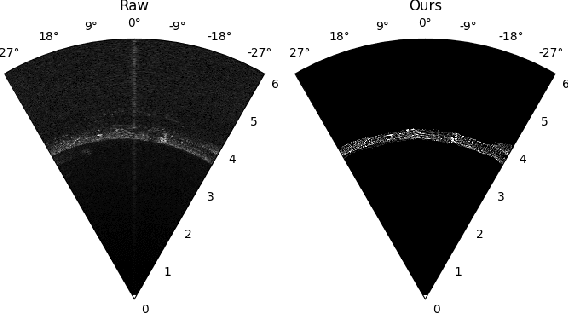
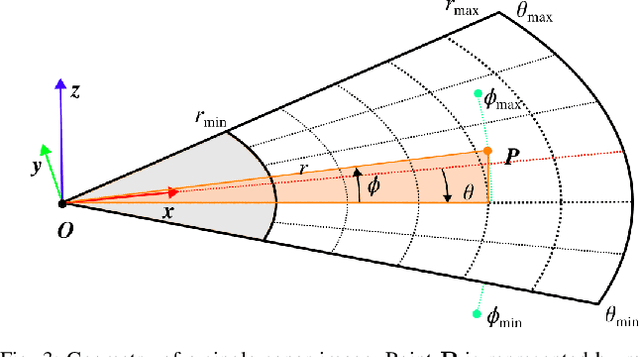
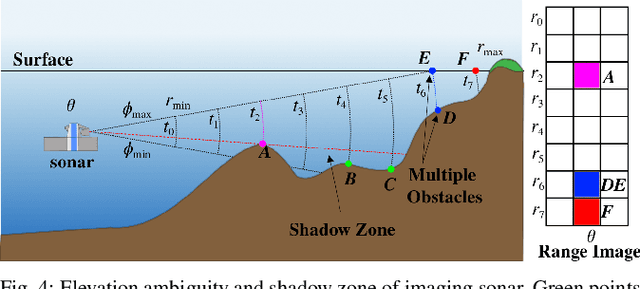
Underwater robots typically rely on acoustic sensors like sonar to perceive their surroundings. However, these sensors are often inundated with multiple sources and types of noise, which makes using raw data for any meaningful inference with features, objects, or boundary returns very difficult. While several conventional methods of dealing with noise exist, their success rates are unsatisfactory. This paper presents a novel application of conditional Generative Adversarial Networks (cGANs) to train a model to produce noise-free sonar images, outperforming several conventional filtering methods. Estimating free space is crucial for autonomous robots performing active exploration and mapping. Thus, we apply our approach to the task of underwater occupancy mapping and show superior free and occupied space inference when compared to conventional methods.
Towards Efficient Neural Scene Graphs by Learning Consistency Fields
Oct 09, 2022
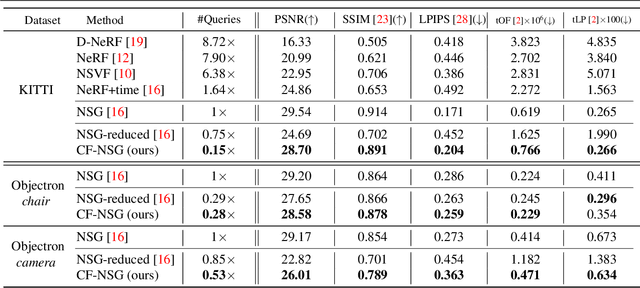
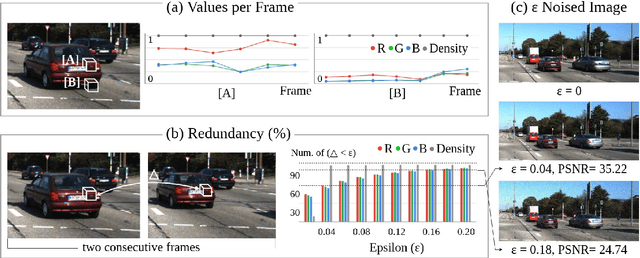

Neural Radiance Fields (NeRF) achieves photo-realistic image rendering from novel views, and the Neural Scene Graphs (NSG) \cite{ost2021neural} extends it to dynamic scenes (video) with multiple objects. Nevertheless, computationally heavy ray marching for every image frame becomes a huge burden. In this paper, taking advantage of significant redundancy across adjacent frames in videos, we propose a feature-reusing framework. From the first try of naively reusing the NSG features, however, we learn that it is crucial to disentangle object-intrinsic properties consistent across frames from transient ones. Our proposed method, \textit{Consistency-Field-based NSG (CF-NSG)}, reformulates neural radiance fields to additionally consider \textit{consistency fields}. With disentangled representations, CF-NSG takes full advantage of the feature-reusing scheme and performs an extended degree of scene manipulation in a more controllable manner. We empirically verify that CF-NSG greatly improves the inference efficiency by using 85\% less queries than NSG without notable degradation in rendering quality. Code will be available at: https://github.com/ldynx/CF-NSG
SIOD: Single Instance Annotated Per Category Per Image for Object Detection
Mar 30, 2022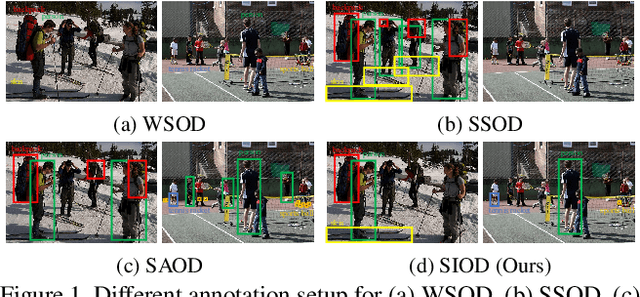



Object detection under imperfect data receives great attention recently. Weakly supervised object detection (WSOD) suffers from severe localization issues due to the lack of instance-level annotation, while semi-supervised object detection (SSOD) remains challenging led by the inter-image discrepancy between labeled and unlabeled data. In this study, we propose the Single Instance annotated Object Detection (SIOD), requiring only one instance annotation for each existing category in an image. Degraded from inter-task (WSOD) or inter-image (SSOD) discrepancies to the intra-image discrepancy, SIOD provides more reliable and rich prior knowledge for mining the rest of unlabeled instances and trades off the annotation cost and performance. Under the SIOD setting, we propose a simple yet effective framework, termed Dual-Mining (DMiner), which consists of a Similarity-based Pseudo Label Generating module (SPLG) and a Pixel-level Group Contrastive Learning module (PGCL). SPLG firstly mines latent instances from feature representation space to alleviate the annotation missing problem. To avoid being misled by inaccurate pseudo labels, we propose PGCL to boost the tolerance to false pseudo labels. Extensive experiments on MS COCO verify the feasibility of the SIOD setting and the superiority of the proposed method, which obtains consistent and significant improvements compared to baseline methods and achieves comparable results with fully supervised object detection (FSOD) methods with only 40% instances annotated.
Dual-Cycle: Self-Supervised Dual-View Fluorescence Microscopy Image Reconstruction using CycleGAN
Sep 23, 2022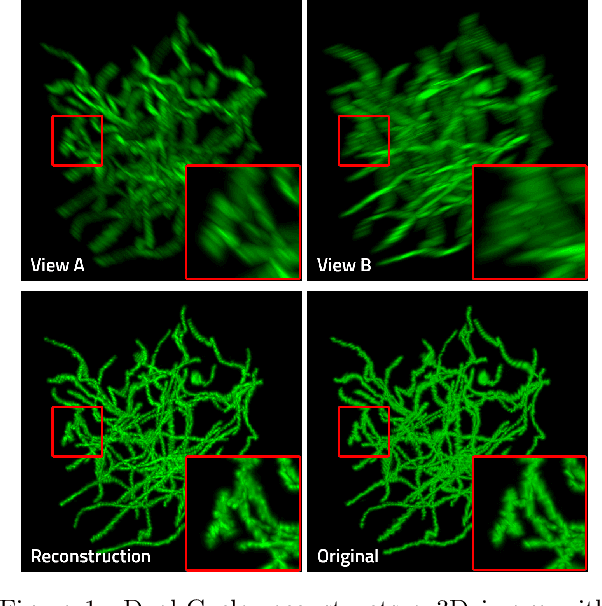

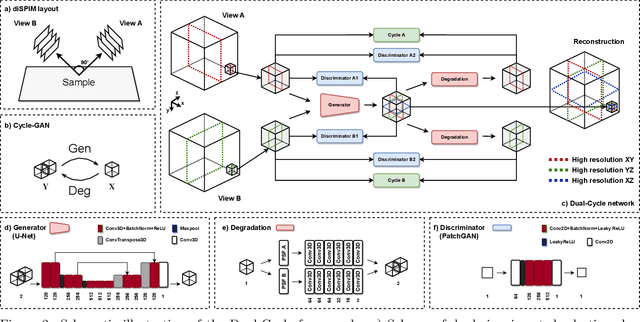
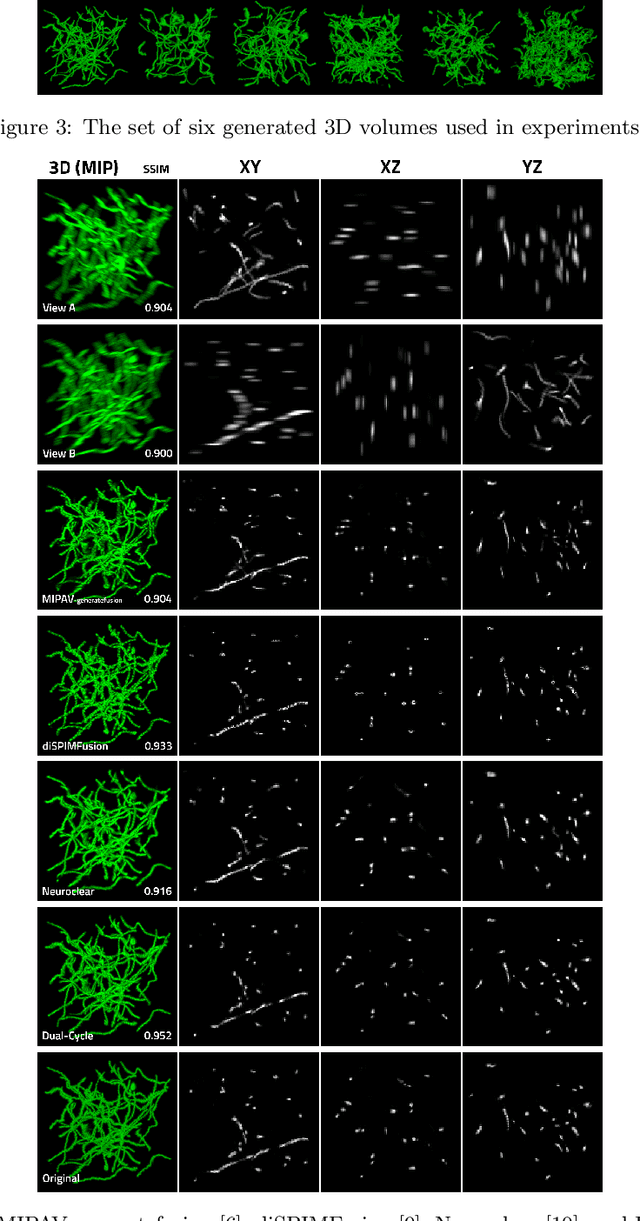
Three-dimensional fluorescence microscopy often suffers from anisotropy, where the resolution along the axial direction is lower than that within the lateral imaging plane. We address this issue by presenting Dual-Cycle, a new framework for joint deconvolution and fusion of dual-view fluorescence images. Inspired by the recent Neuroclear method, Dual-Cycle is designed as a cycle-consistent generative network trained in a self-supervised fashion by combining a dual-view generator and prior-guided degradation model. We validate Dual-Cycle on both synthetic and real data showing its state-of-the-art performance without any external training data.
Quantum Natural Language Generation on Near-Term Devices
Nov 01, 2022
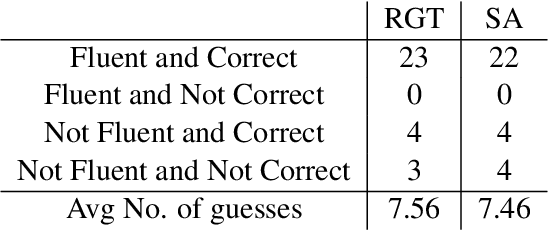
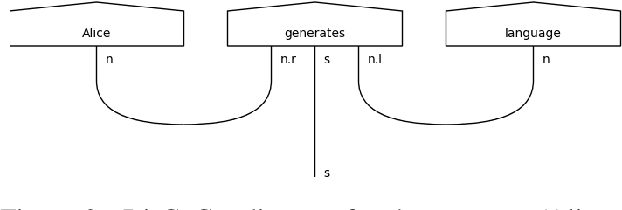
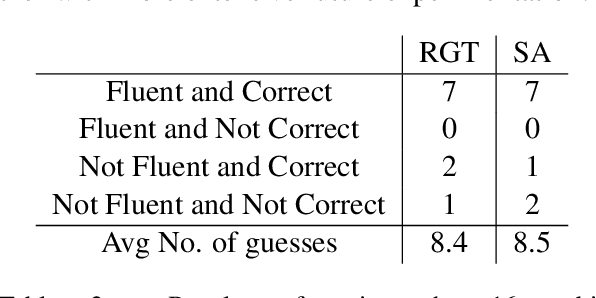
The emergence of noisy medium-scale quantum devices has led to proof-of-concept applications for quantum computing in various domains. Examples include Natural Language Processing (NLP) where sentence classification experiments have been carried out, as well as procedural generation, where tasks such as geopolitical map creation, and image manipulation have been performed. We explore applications at the intersection of these two areas by designing a hybrid quantum-classical algorithm for sentence generation. Our algorithm is based on the well-known simulated annealing technique for combinatorial optimisation. An implementation is provided and used to demonstrate successful sentence generation on both simulated and real quantum hardware. A variant of our algorithm can also be used for music generation. This paper aims to be self-contained, introducing all the necessary background on NLP and quantum computing along the way.
Confusing Image Quality Assessment: Towards Better Augmented Reality Experience
Apr 11, 2022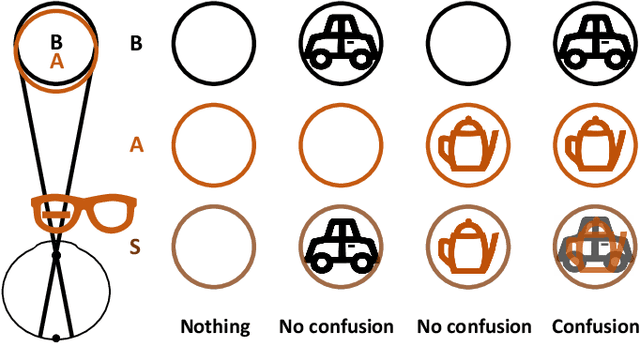
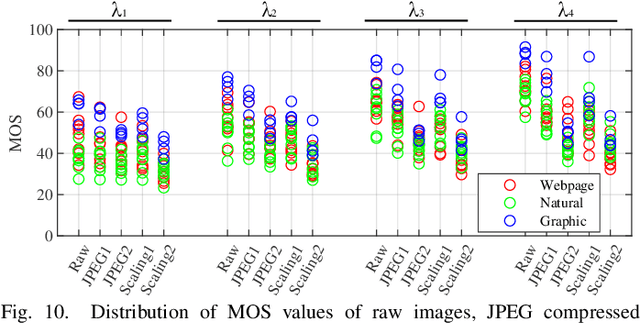
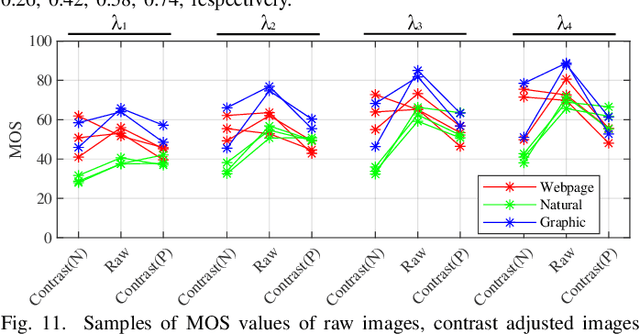
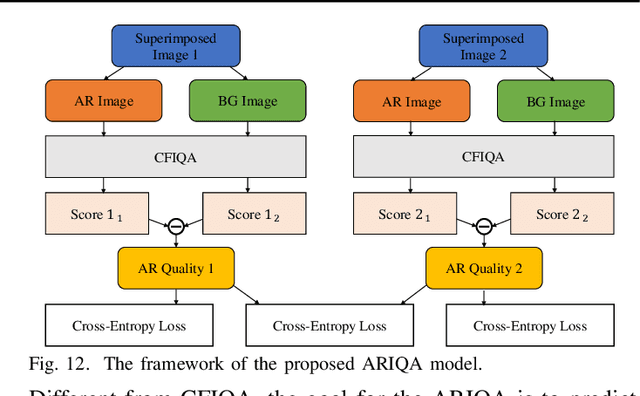
With the development of multimedia technology, Augmented Reality (AR) has become a promising next-generation mobile platform. The primary value of AR is to promote the fusion of digital contents and real-world environments, however, studies on how this fusion will influence the Quality of Experience (QoE) of these two components are lacking. To achieve better QoE of AR, whose two layers are influenced by each other, it is important to evaluate its perceptual quality first. In this paper, we consider AR technology as the superimposition of virtual scenes and real scenes, and introduce visual confusion as its basic theory. A more general problem is first proposed, which is evaluating the perceptual quality of superimposed images, i.e., confusing image quality assessment. A ConFusing Image Quality Assessment (CFIQA) database is established, which includes 600 reference images and 300 distorted images generated by mixing reference images in pairs. Then a subjective quality perception study and an objective model evaluation experiment are conducted towards attaining a better understanding of how humans perceive the confusing images. An objective metric termed CFIQA is also proposed to better evaluate the confusing image quality. Moreover, an extended ARIQA study is further conducted based on the CFIQA study. We establish an ARIQA database to better simulate the real AR application scenarios, which contains 20 AR reference images, 20 background (BG) reference images, and 560 distorted images generated from AR and BG references, as well as the correspondingly collected subjective quality ratings. We also design three types of full-reference (FR) IQA metrics to study whether we should consider the visual confusion when designing corresponding IQA algorithms. An ARIQA metric is finally proposed for better evaluating the perceptual quality of AR images.
Best Prompts for Text-to-Image Models and How to Find Them
Sep 23, 2022


Recent progress in generative models, especially in text-guided diffusion models, has enabled the production of aesthetically-pleasing imagery resembling the works of professional human artists. However, one has to carefully compose the textual description, called the prompt, and augment it with a set of clarifying keywords. Since aesthetics are challenging to evaluate computationally, human feedback is needed to determine the optimal prompt formulation and keyword combination. In this paper, we present a human-in-the-loop approach to learning the most useful combination of prompt keywords using a genetic algorithm. We also show how such an approach can improve the aesthetic appeal of images depicting the same descriptions.
Efficient Unsupervised Learning for Plankton Images
Sep 14, 2022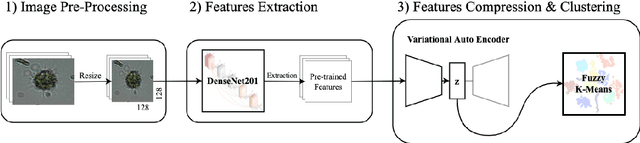

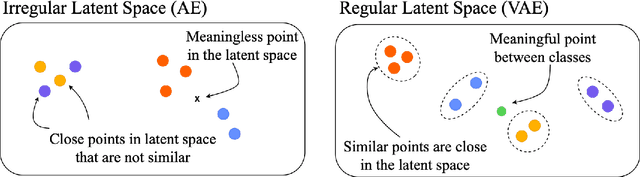

Monitoring plankton populations in situ is fundamental to preserve the aquatic ecosystem. Plankton microorganisms are in fact susceptible of minor environmental perturbations, that can reflect into consequent morphological and dynamical modifications. Nowadays, the availability of advanced automatic or semi-automatic acquisition systems has been allowing the production of an increasingly large amount of plankton image data. The adoption of machine learning algorithms to classify such data may be affected by the significant cost of manual annotation, due to both the huge quantity of acquired data and the numerosity of plankton species. To address these challenges, we propose an efficient unsupervised learning pipeline to provide accurate classification of plankton microorganisms. We build a set of image descriptors exploiting a two-step procedure. First, a Variational Autoencoder (VAE) is trained on features extracted by a pre-trained neural network. We then use the learnt latent space as image descriptor for clustering. We compare our method with state-of-the-art unsupervised approaches, where a set of pre-defined hand-crafted features is used for clustering of plankton images. The proposed pipeline outperforms the benchmark algorithms for all the plankton datasets included in our analysis, providing better image embedding properties.
Domain Adaptation for Underwater Image Enhancement via Content and Style Separation
Feb 17, 2022


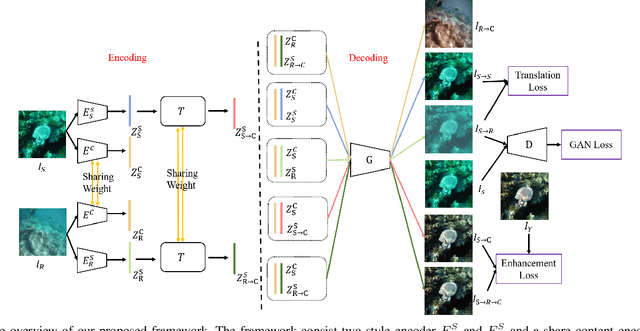
Underwater image suffer from color cast, low contrast and hazy effect due to light absorption, refraction and scattering, which degraded the high-level application, e.g, object detection and object tracking. Recent learning-based methods demonstrate astonishing performance on underwater image enhancement, however, most of these works use synthesis pair data for supervised learning and ignore the domain gap to real-world data. In this paper, we propose a domain adaptation framework for underwater image enhancement via content and style separation, we assume image could be disentangled to content and style latent, and image could be clustered to the sub-domain of associated style in latent space, the goal is to build up the mapping between underwater style latent and clean one. Different from prior works of domain adaptation for underwater image enhancement, which target to minimize the latent discrepancy of synthesis and real-world data, we aim to distinguish style latent from different sub-domains. To solve the problem of lacking pair real-world data, we leverage synthesis to real image-to-image translation to obtain pseudo real underwater image pairs for supervised learning, and enhancement can be achieved by input content and clean style latent into generator. Our model provide a user interact interface to adjust different enhanced level by latent manipulation. Experiment on various public real-world underwater benchmarks demonstrate that the proposed framework is capable to perform domain adaptation for underwater image enhancement and outperform various state-of-the-art underwater image enhancement algorithms in quantity and quality. The model and source code are available at https://github.com/fordevoted/UIESS
Multiple Degradation and Reconstruction Network for Single Image Denoising via Knowledge Distillation
Apr 29, 2022
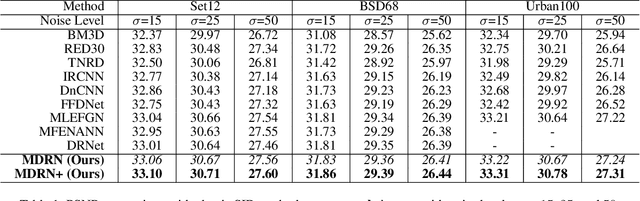

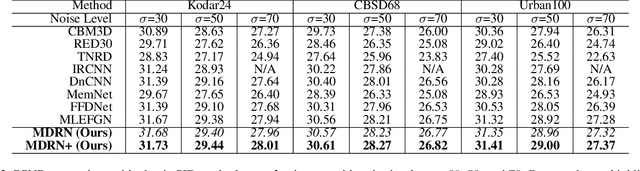
Single image denoising (SID) has achieved significant breakthroughs with the development of deep learning. However, the proposed methods are often accompanied by plenty of parameters, which greatly limits their application scenarios. Different from previous works that blindly increase the depth of the network, we explore the degradation mechanism of the noisy image and propose a lightweight Multiple Degradation and Reconstruction Network (MDRN) to progressively remove noise. Meanwhile, we propose two novel Heterogeneous Knowledge Distillation Strategies (HMDS) to enable MDRN to learn richer and more accurate features from heterogeneous models, which make it possible to reconstruct higher-quality denoised images under extreme conditions. Extensive experiments show that our MDRN achieves favorable performance against other SID models with fewer parameters. Meanwhile, plenty of ablation studies demonstrate that the introduced HMDS can improve the performance of tiny models or the model under high noise levels, which is extremely useful for related applications.