 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust Manifold Nonnegative Tucker Factorization for Tensor Data Representation
Nov 08, 2022
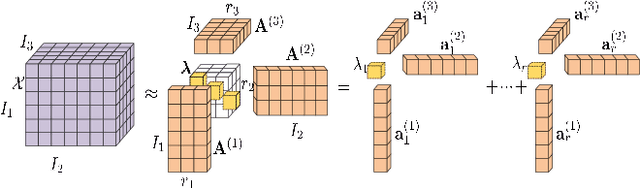
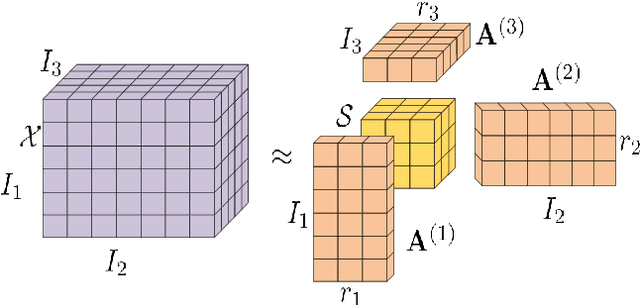
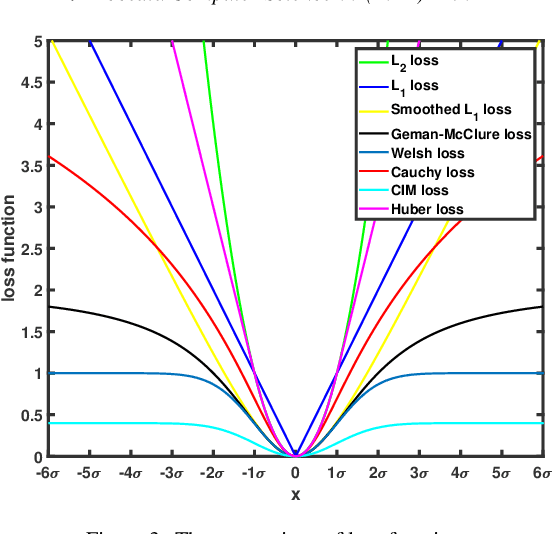

Nonnegative Tucker Factorization (NTF) minimizes the euclidean distance or Kullback-Leibler divergence between the original data and its low-rank approximation which often suffers from grossly corruptions or outliers and the neglect of manifold structures of data. In particular, NTF suffers from rotational ambiguity, whose solutions with and without rotation transformations are equally in the sense of yielding the maximum likelihood. In this paper, we propose three Robust Manifold NTF algorithms to handle outliers by incorporating structural knowledge about the outliers. They first applies a half-quadratic optimization algorithm to transform the problem into a general weighted NTF where the weights are influenced by the outliers. Then, we introduce the correntropy induced metric, Huber function and Cauchy function for weights respectively, to handle the outliers. Finally, we introduce a manifold regularization to overcome the rotational ambiguity of NTF. We have compared the proposed method with a number of representative references covering major branches of NTF on a variety of real-world image databases. Experimental results illustrate the effectiveness of the proposed method under two evaluation metrics (accuracy and nmi).
Semantic-SuPer: A Semantic-aware Surgical Perception Framework for Endoscopic Tissue Classification, Reconstruction, and Tracking
Oct 29, 2022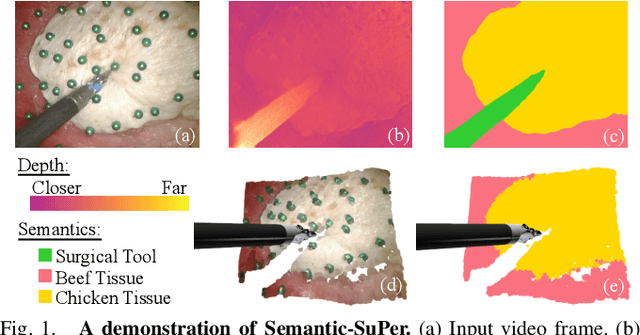
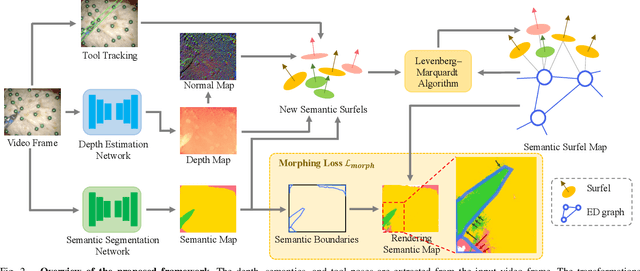


Accurate and robust tracking and reconstruction of the surgical scene is a critical enabling technology toward autonomous robotic surgery. Existing algorithms for 3D perception in surgery mainly rely on geometric information, while we propose to also leverage semantic information inferred from the endoscopic video using image segmentation algorithms. In this paper, we present a novel, comprehensive surgical perception framework, Semantic-SuPer, that integrates geometric and semantic information to facilitate data association, 3D reconstruction, and tracking of endoscopic scenes, benefiting downstream tasks like surgical navigation. The proposed framework is demonstrated on challenging endoscopic data with deforming tissue, showing its advantages over our baseline and several other state-of the-art approaches. Our code and dataset will be available at https://github.com/ucsdarclab/Python-SuPer.
Detecting Line Segments in Motion-blurred Images with Events
Nov 20, 2022
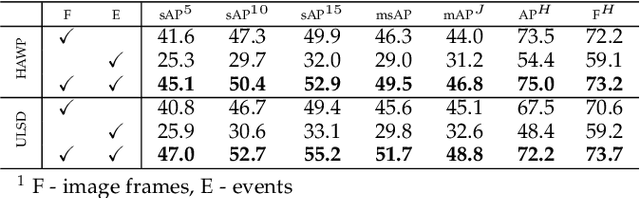

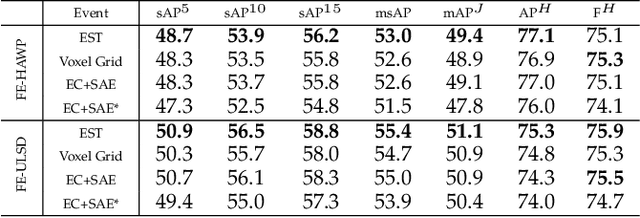
Making line segment detectors more reliable under motion blurs is one of the most important challenges for practical applications, such as visual SLAM and 3D reconstruction. Existing line segment detection methods face severe performance degradation for accurately detecting and locating line segments when motion blur occurs. While event data shows strong complementary characteristics to images for minimal blur and edge awareness at high-temporal resolution, potentially beneficial for reliable line segment recognition. To robustly detect line segments over motion blurs, we propose to leverage the complementary information of images and events. To achieve this, we first design a general frame-event feature fusion network to extract and fuse the detailed image textures and low-latency event edges, which consists of a channel-attention-based shallow fusion module and a self-attention-based dual hourglass module. We then utilize two state-of-the-art wireframe parsing networks to detect line segments on the fused feature map. Besides, we contribute a synthetic and a realistic dataset for line segment detection, i.e., FE-Wireframe and FE-Blurframe, with pairwise motion-blurred images and events. Extensive experiments on both datasets demonstrate the effectiveness of the proposed method. When tested on the real dataset, our method achieves 63.3% mean structural average precision (msAP) with the model pre-trained on the FE-Wireframe and fine-tuned on the FE-Blurframe, improved by 32.6 and 11.3 points compared with models trained on synthetic only and real only, respectively. The codes, datasets, and trained models are released at: https://levenberg.github.io/FE-LSD
Heavy Rain Face Image Restoration: Integrating Physical Degradation Model and Facial Component Guided Adversarial Learning
Apr 18, 2022
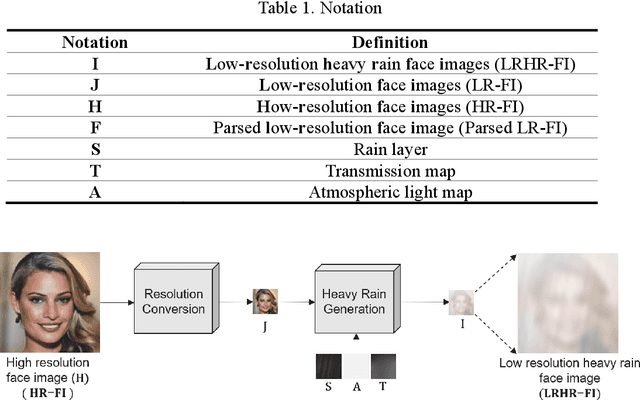
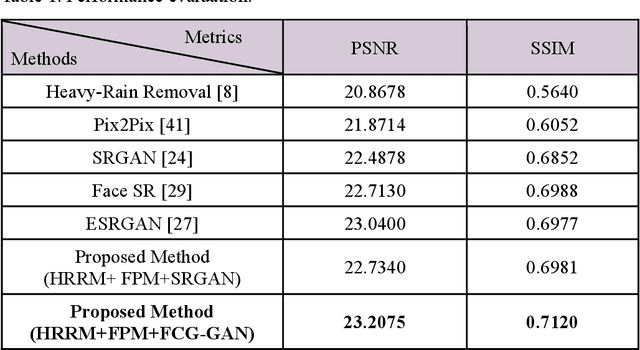

With the recent increase in intelligent CCTVs for visual surveillance, a new image degradation that integrates resolution conversion and synthetic rain models is required. For example, in heavy rain, face images captured by CCTV from a distance have significant deterioration in both visibility and resolution. Unlike traditional image degradation models (IDM), such as rain removal and superresolution, this study addresses a new IDM referred to as a scale-aware heavy rain model and proposes a method for restoring high-resolution face images (HR-FIs) from low-resolution heavy rain face images (LRHR-FI). To this end, a 2-stage network is presented. The first stage generates low-resolution face images (LR-FIs), from which heavy rain has been removed from the LRHR-FIs to improve visibility. To realize this, an interpretable IDM-based network is constructed to predict physical parameters, such as rain streaks, transmission maps, and atmospheric light. In addition, the image reconstruction loss is evaluated to enhance the estimates of the physical parameters. For the second stage, which aims to reconstruct the HR-FIs from the LR-FIs outputted in the first stage, facial component guided adversarial learning (FCGAL) is applied to boost facial structure expressions. To focus on informative facial features and reinforce the authenticity of facial components, such as the eyes and nose, a face-parsing-guided generator and facial local discriminators are designed for FCGAL. The experimental results verify that the proposed approach based on physical-based network design and FCGAL can remove heavy rain and increase the resolution and visibility simultaneously. Moreover, the proposed heavy-rain face image restoration outperforms state-of-the-art models of heavy rain removal, image-to-image translation, and superresolution.
Immiscible Color Flows in Optimal Transport Networks for Image Classification
May 04, 2022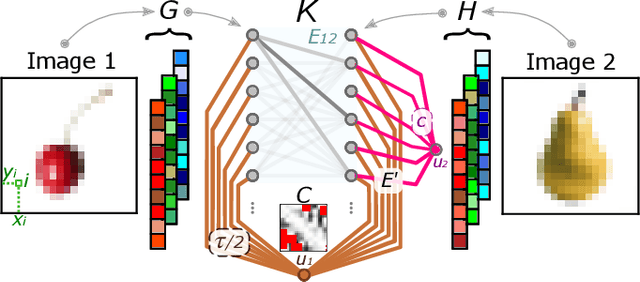
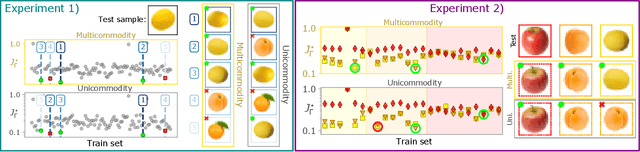
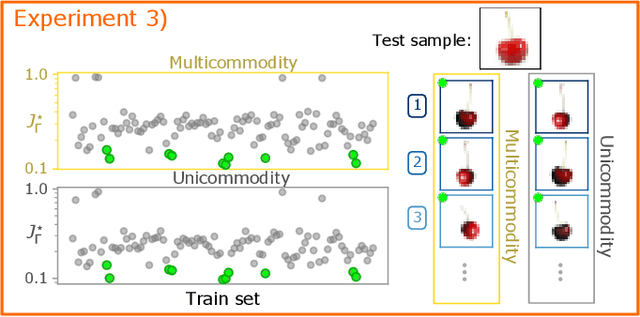
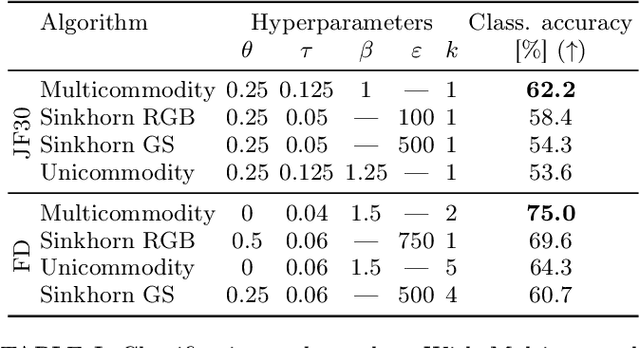
In classification tasks, it is crucial to meaningfully exploit information contained in data. Here, we propose a physics-inspired dynamical system that adapts Optimal Transport principles to effectively leverage color distributions of images. Our dynamics regulates immiscible fluxes of colors traveling on a network built from images. Instead of aggregating colors together, it treats them as different commodities that interact with a shared capacity on edges. Our method outperforms competitor algorithms on image classification tasks in datasets where color information matters.
Post-Training Quantization for Cross-Platform Learned Image Compression
Feb 15, 2022
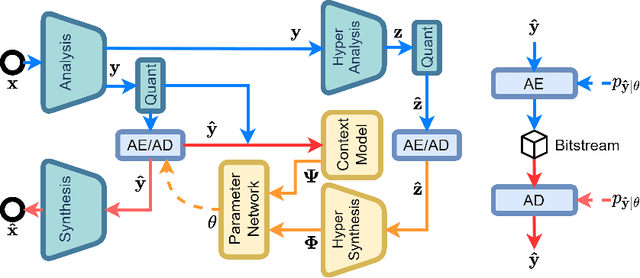

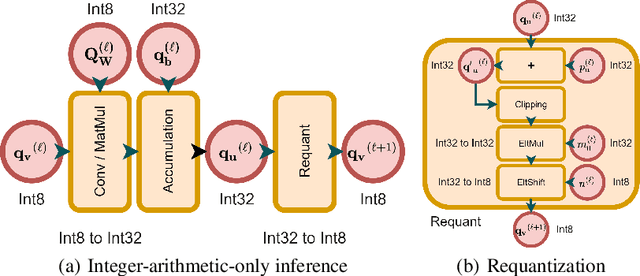
It has been witnessed that learned image compression has outperformed conventional image coding techniques and tends to be practical in industrial applications. One of the most critical issues that need to be considered is the non-deterministic calculation, which makes the probability prediction cross-platform inconsistent and frustrates successful decoding. We propose to solve this problem by introducing well-developed post-training quantization and making the model inference integer-arithmetic-only, which is much simpler than presently existing training and fine-tuning based approaches yet still keeps the superior rate-distortion performance of learned image compression. Based on that, we further improve the discretization of the entropy parameters and extend the deterministic inference to fit Gaussian mixture models. With our proposed methods, the current state-of-the-art image compression models can infer in a cross-platform consistent manner, which makes the further development and practice of learned image compression more promising.
Visual Semantic Segmentation Based on Few/Zero-Shot Learning: An Overview
Nov 13, 2022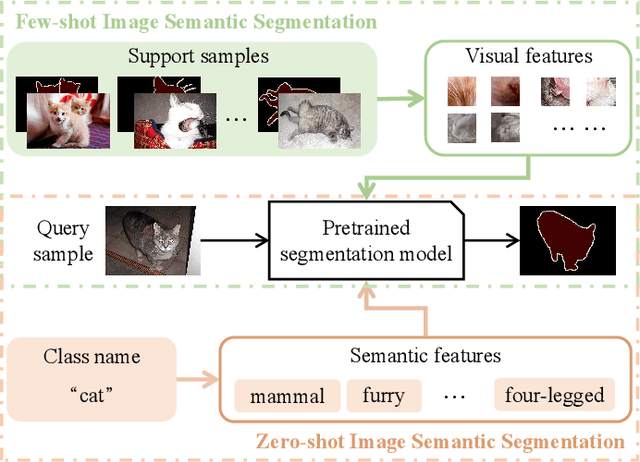
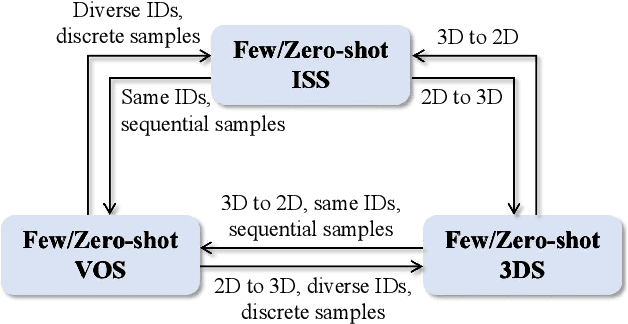
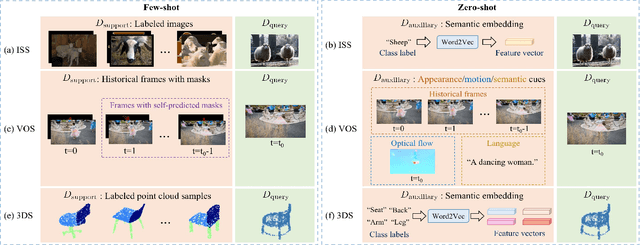
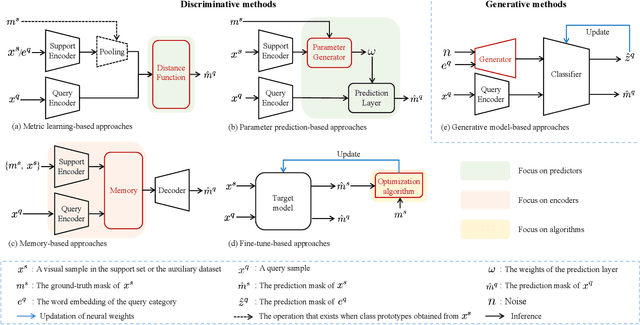
Visual semantic segmentation aims at separating a visual sample into diverse blocks with specific semantic attributes and identifying the category for each block, and it plays a crucial role in environmental perception. Conventional learning-based visual semantic segmentation approaches count heavily on large-scale training data with dense annotations and consistently fail to estimate accurate semantic labels for unseen categories. This obstruction spurs a craze for studying visual semantic segmentation with the assistance of few/zero-shot learning. The emergence and rapid progress of few/zero-shot visual semantic segmentation make it possible to learn unseen-category from a few labeled or zero-labeled samples, which advances the extension to practical applications. Therefore, this paper focuses on the recently published few/zero-shot visual semantic segmentation methods varying from 2D to 3D space and explores the commonalities and discrepancies of technical settlements under different segmentation circumstances. Specifically, the preliminaries on few/zero-shot visual semantic segmentation, including the problem definitions, typical datasets, and technical remedies, are briefly reviewed and discussed. Moreover, three typical instantiations are involved to uncover the interactions of few/zero-shot learning with visual semantic segmentation, including image semantic segmentation, video object segmentation, and 3D segmentation. Finally, the future challenges of few/zero-shot visual semantic segmentation are discussed.
Scale-Aware Crowd Counting Using a Joint Likelihood Density Map and Synthetic Fusion Pyramid Network
Nov 13, 2022
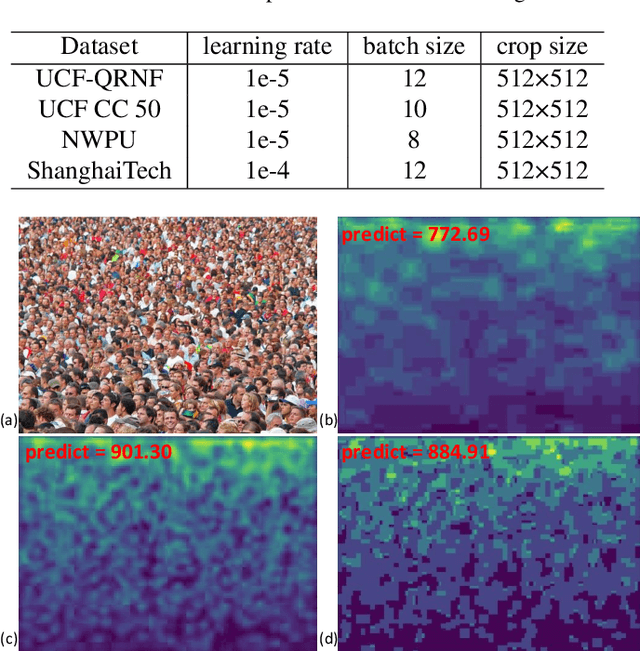
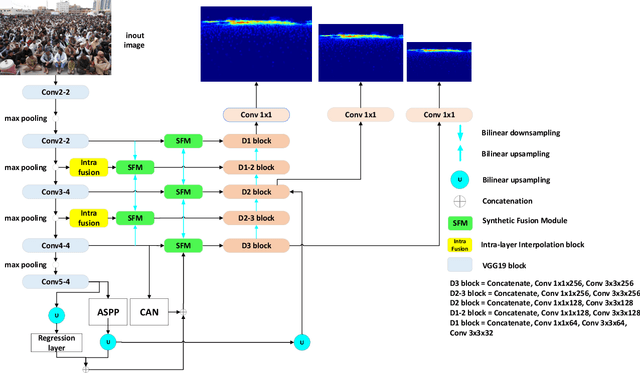
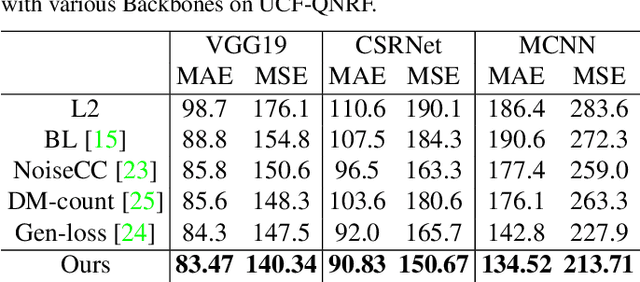
We develop a Synthetic Fusion Pyramid Network (SPF-Net) with a scale-aware loss function design for accurate crowd counting. Existing crowd-counting methods assume that the training annotation points were accurate and thus ignore the fact that noisy annotations can lead to large model-learning bias and counting error, especially for counting highly dense crowds that appear far away. To the best of our knowledge, this work is the first to properly handle such noise at multiple scales in end-to-end loss design and thus push the crowd counting state-of-the-art. We model the noise of crowd annotation points as a Gaussian and derive the crowd probability density map from the input image. We then approximate the joint distribution of crowd density maps with the full covariance of multiple scales and derive a low-rank approximation for tractability and efficient implementation. The derived scale-aware loss function is used to train the SPF-Net. We show that it outperforms various loss functions on four public datasets: UCF-QNRF, UCF CC 50, NWPU and ShanghaiTech A-B datasets. The proposed SPF-Net can accurately predict the locations of people in the crowd, despite training on noisy training annotations.
Unlocking High-Accuracy Differentially Private Image Classification through Scale
Apr 28, 2022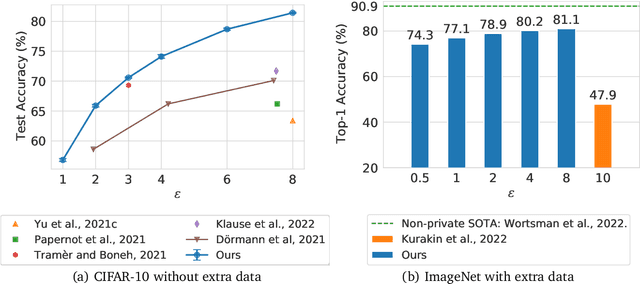
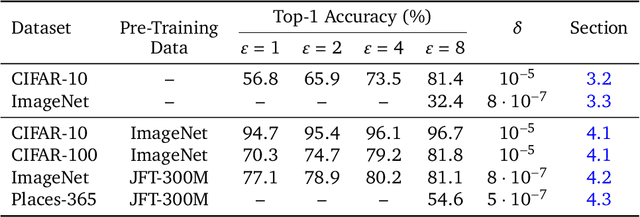


Differential Privacy (DP) provides a formal privacy guarantee preventing adversaries with access to a machine learning model from extracting information about individual training points. Differentially Private Stochastic Gradient Descent (DP-SGD), the most popular DP training method, realizes this protection by injecting noise during training. However previous works have found that DP-SGD often leads to a significant degradation in performance on standard image classification benchmarks. Furthermore, some authors have postulated that DP-SGD inherently performs poorly on large models, since the norm of the noise required to preserve privacy is proportional to the model dimension. In contrast, we demonstrate that DP-SGD on over-parameterized models can perform significantly better than previously thought. Combining careful hyper-parameter tuning with simple techniques to ensure signal propagation and improve the convergence rate, we obtain a new SOTA on CIFAR-10 of 81.4% under (8, 10^{-5})-DP using a 40-layer Wide-ResNet, improving over the previous SOTA of 71.7%. When fine-tuning a pre-trained 200-layer Normalizer-Free ResNet, we achieve a remarkable 77.1% top-1 accuracy on ImageNet under (1, 8*10^{-7})-DP, and achieve 81.1% under (8, 8*10^{-7})-DP. This markedly exceeds the previous SOTA of 47.9% under a larger privacy budget of (10, 10^{-6})-DP. We believe our results are a significant step towards closing the accuracy gap between private and non-private image classification.
ViNTER: Image Narrative Generation with Emotion-Arc-Aware Transformer
Feb 15, 2022
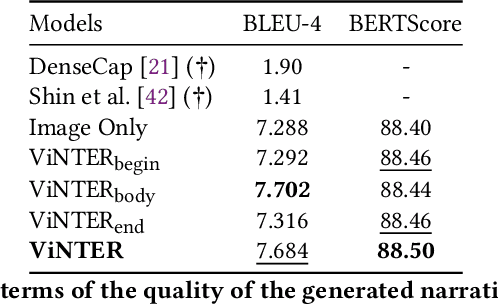
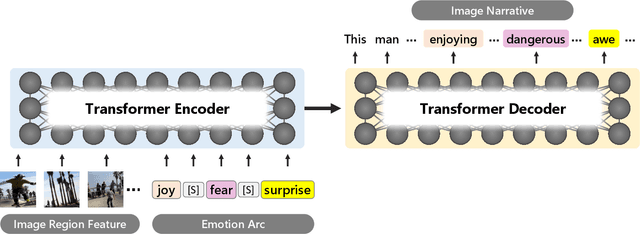
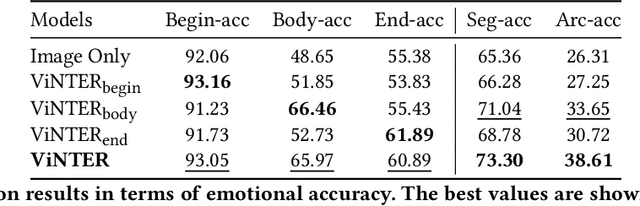
Image narrative generation describes the creation of stories regarding the content of image data from a subjective viewpoint. Given the importance of the subjective feelings of writers, characters, and readers in storytelling, image narrative generation methods must consider human emotion, which is their major difference from descriptive caption generation tasks. The development of automated methods to generate story-like text associated with images may be considered to be of considerable social significance, because stories serve essential functions both as entertainment and also for many practical purposes such as education and advertising. In this study, we propose a model called ViNTER (Visual Narrative Transformer with Emotion arc Representation) to generate image narratives that focus on time series representing varying emotions as "emotion arcs," to take advantage of recent advances in multimodal Transformer-based pre-trained models. We present experimental results of both manual and automatic evaluations, which demonstrate the effectiveness of the proposed emotion-aware approach to image narrative generation.