 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Non-invasive color imaging through scattering medium under broadband illumination
Oct 10, 2022

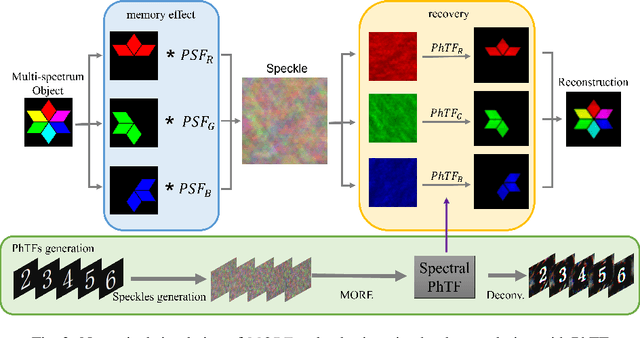
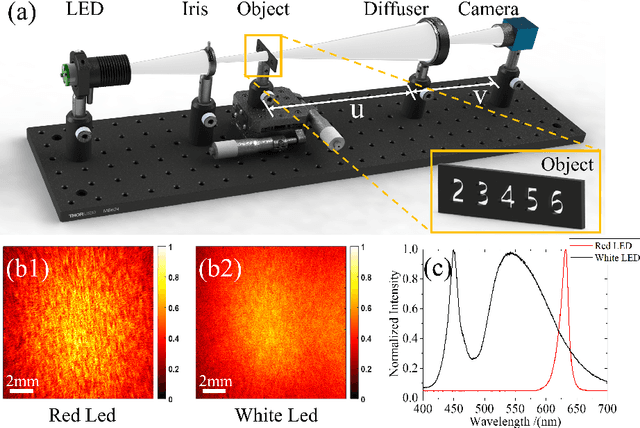
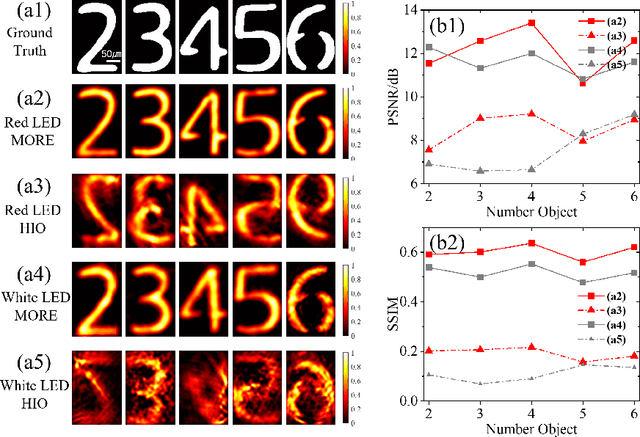
Due to the complex of mixed spectral point spread function within memory effect range, it is unreliable and slow to use speckle correlation technology for non-invasive imaging through scattering medium under broadband illumination. The contrast of the speckles will drastically drop as the light source's spectrum width increases. Here, we propose a method for producing the optical transfer function with several speckle frames within memory effect range to image under broadband illumination. The method can be applied to image amplitude and color objects under white LED illumination. Compared to other approaches of imaging under broadband illumination, such as deep learning and modified phase retrieval, our method can provide more stable results with faster convergence speed, which can be applied in high speed scattering imaging under natural light illumination.
3D Matting: A Soft Segmentation Method Applied in Computed Tomography
Sep 16, 2022
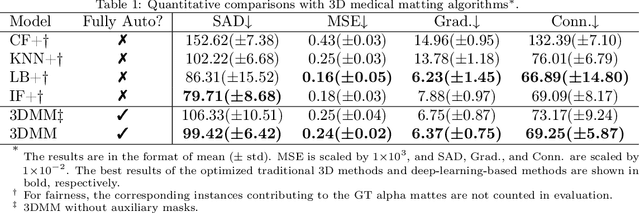
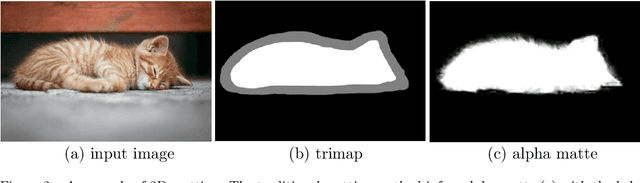
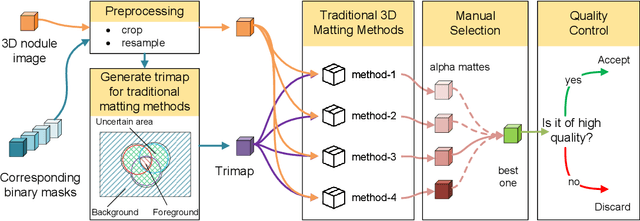
Three-dimensional (3D) images, such as CT, MRI, and PET, are common in medical imaging applications and important in clinical diagnosis. Semantic ambiguity is a typical feature of many medical image labels. It can be caused by many factors, such as the imaging properties, pathological anatomy, and the weak representation of the binary masks, which brings challenges to accurate 3D segmentation. In 2D medical images, using soft masks instead of binary masks generated by image matting to characterize lesions can provide rich semantic information, describe the structural characteristics of lesions more comprehensively, and thus benefit the subsequent diagnoses and analyses. In this work, we introduce image matting into the 3D scenes to describe the lesions in 3D medical images. The study of image matting in 3D modality is limited, and there is no high-quality annotated dataset related to 3D matting, therefore slowing down the development of data-driven deep-learning-based methods. To address this issue, we constructed the first 3D medical matting dataset and convincingly verified the validity of the dataset through quality control and downstream experiments in lung nodules classification. We then adapt the four selected state-of-the-art 2D image matting algorithms to 3D scenes and further customize the methods for CT images. Also, we propose the first end-to-end deep 3D matting network and implement a solid 3D medical image matting benchmark, which will be released to encourage further research.
Sparse4D: Multi-view 3D Object Detection with Sparse Spatial-Temporal Fusion
Nov 19, 2022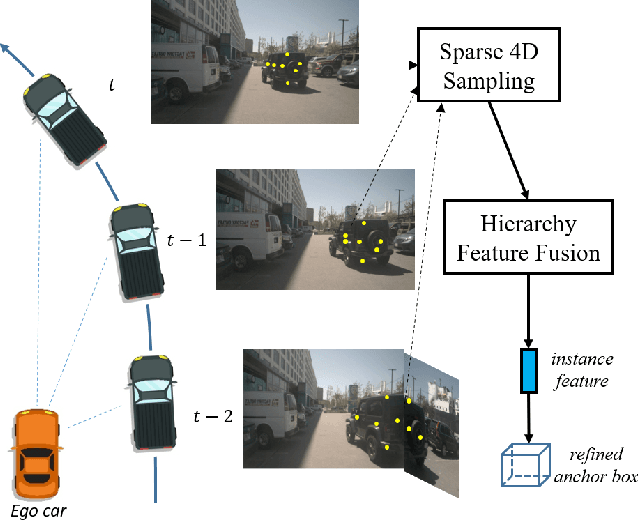
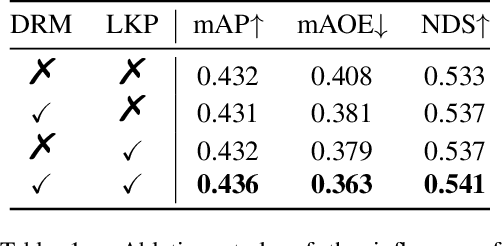
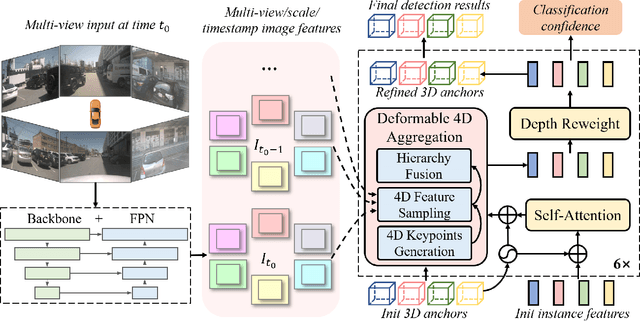
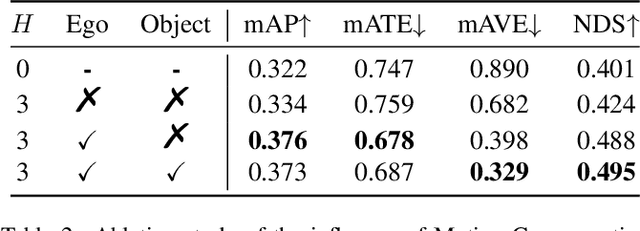
Bird-eye-view (BEV) based methods have made great progress recently in multi-view 3D detection task. Comparing with BEV based methods, sparse based methods lag behind in performance, but still have lots of non-negligible merits. To push sparse 3D detection further, in this work, we introduce a novel method, named Sparse4D, which does the iterative refinement of anchor boxes via sparsely sampling and fusing spatial-temporal features. (1) Sparse 4D Sampling: for each 3D anchor, we assign multiple 4D keypoints, which are then projected to multi-view/scale/timestamp image features to sample corresponding features; (2) Hierarchy Feature Fusion: we hierarchically fuse sampled features of different view/scale, different timestamp and different keypoints to generate high-quality instance feature. In this way, Sparse4D can efficiently and effectively achieve 3D detection without relying on dense view transformation nor global attention, and is more friendly to edge devices deployment. Furthermore, we introduce an instance-level depth reweight module to alleviate the ill-posed issue in 3D-to-2D projection. In experiment, our method outperforms all sparse based methods and most BEV based methods on detection task in the nuScenes dataset.
Self-conditioned Embedding Diffusion for Text Generation
Nov 08, 2022
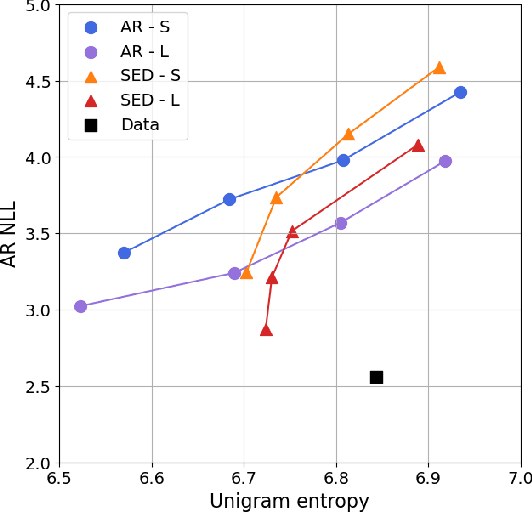

Can continuous diffusion models bring the same performance breakthrough on natural language they did for image generation? To circumvent the discrete nature of text data, we can simply project tokens in a continuous space of embeddings, as is standard in language modeling. We propose Self-conditioned Embedding Diffusion, a continuous diffusion mechanism that operates on token embeddings and allows to learn flexible and scalable diffusion models for both conditional and unconditional text generation. Through qualitative and quantitative evaluation, we show that our text diffusion models generate samples comparable with those produced by standard autoregressive language models - while being in theory more efficient on accelerator hardware at inference time. Our work paves the way for scaling up diffusion models for text, similarly to autoregressive models, and for improving performance with recent refinements to continuous diffusion.
When & How to Transfer with Transfer Learning
Nov 08, 2022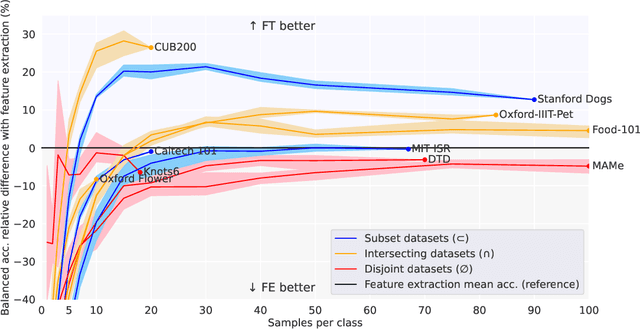

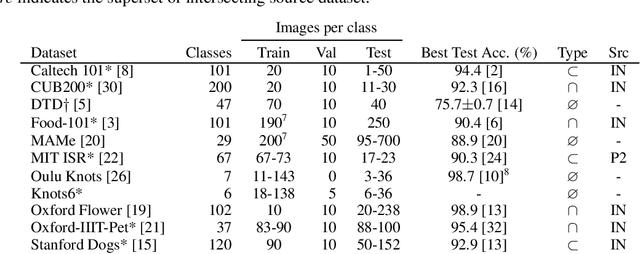
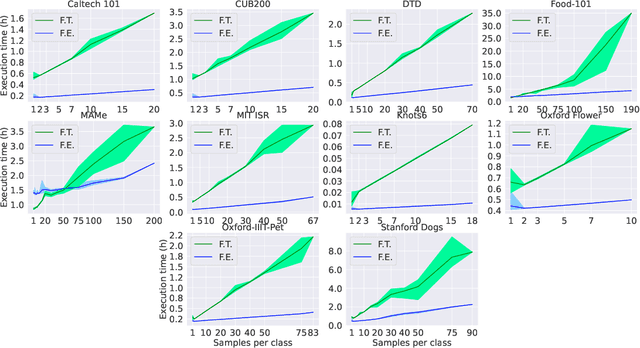
In deep learning, transfer learning (TL) has become the de facto approach when dealing with image related tasks. Visual features learnt for one task have been shown to be reusable for other tasks, improving performance significantly. By reusing deep representations, TL enables the use of deep models in domains with limited data availability, limited computational resources and/or limited access to human experts. Domains which include the vast majority of real-life applications. This paper conducts an experimental evaluation of TL, exploring its trade-offs with respect to performance, environmental footprint, human hours and computational requirements. Results highlight the cases were a cheap feature extraction approach is preferable, and the situations where an expensive fine-tuning effort may be worth the added cost. Finally, a set of guidelines on the use of TL are proposed.
Equivariance Regularization for Image Reconstruction
Feb 10, 2022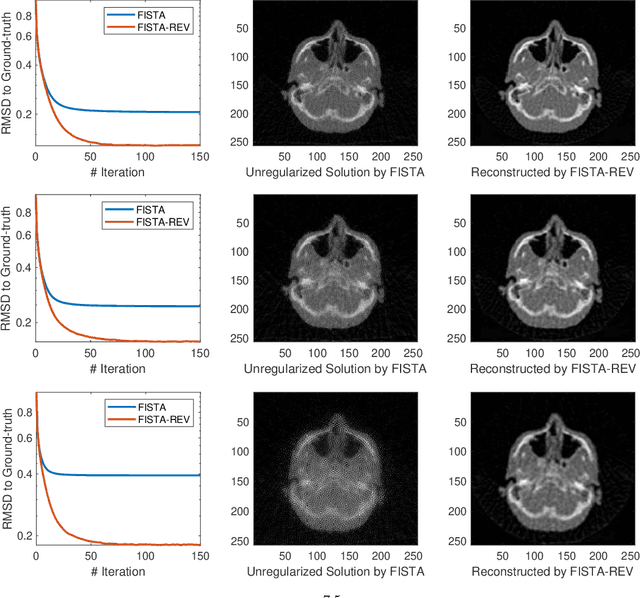
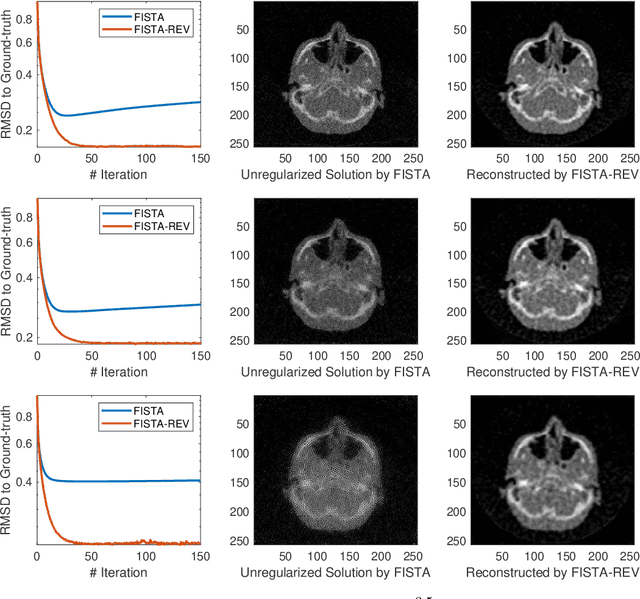
In this work, we propose Regularization-by-Equivariance (REV), a novel structure-adaptive regularization scheme for solving imaging inverse problems under incomplete measurements. Our regularization scheme utilizes the equivariant structure in the physics of the measurements -- which is prevalent in many inverse problems such as tomographic image reconstruction -- to mitigate the ill-poseness of the inverse problem. Our proposed scheme can be applied in a plug-and-play manner alongside with any classic first-order optimization algorithm such as the accelerated gradient descent/FISTA for simplicity and fast convergence. Our numerical experiments in sparse-view X-ray CT image reconstruction tasks demonstrate the effectiveness of our approach.
Split-PU: Hardness-aware Training Strategy for Positive-Unlabeled Learning
Nov 30, 2022
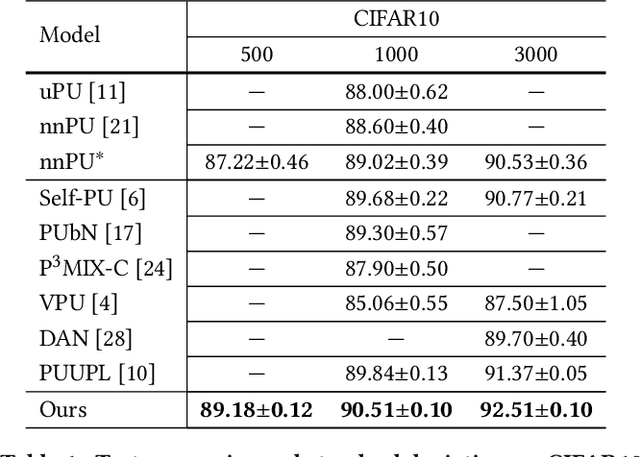
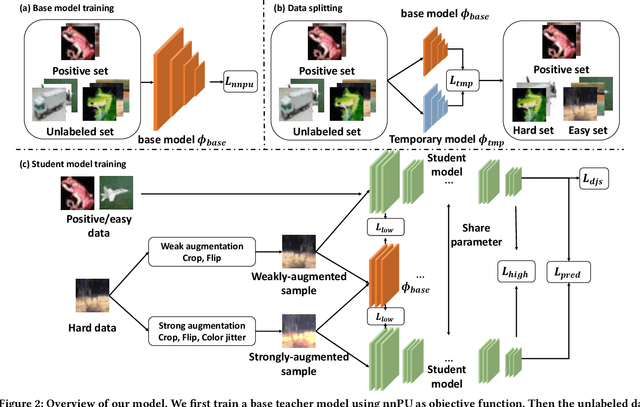
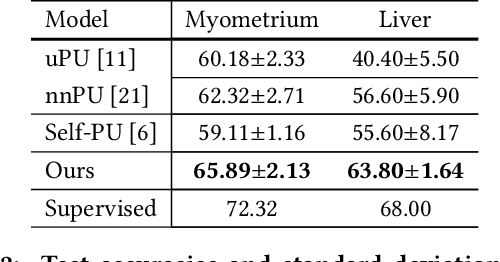
Positive-Unlabeled (PU) learning aims to learn a model with rare positive samples and abundant unlabeled samples. Compared with classical binary classification, the task of PU learning is much more challenging due to the existence of many incompletely-annotated data instances. Since only part of the most confident positive samples are available and evidence is not enough to categorize the rest samples, many of these unlabeled data may also be the positive samples. Research on this topic is particularly useful and essential to many real-world tasks which demand very expensive labelling cost. For example, the recognition tasks in disease diagnosis, recommendation system and satellite image recognition may only have few positive samples that can be annotated by the experts. These methods mainly omit the intrinsic hardness of some unlabeled data, which can result in sub-optimal performance as a consequence of fitting the easy noisy data and not sufficiently utilizing the hard data. In this paper, we focus on improving the commonly-used nnPU with a novel training pipeline. We highlight the intrinsic difference of hardness of samples in the dataset and the proper learning strategies for easy and hard data. By considering this fact, we propose first splitting the unlabeled dataset with an early-stop strategy. The samples that have inconsistent predictions between the temporary and base model are considered as hard samples. Then the model utilizes a noise-tolerant Jensen-Shannon divergence loss for easy data; and a dual-source consistency regularization for hard data which includes a cross-consistency between student and base model for low-level features and self-consistency for high-level features and predictions, respectively.
Pex: Memory-efficient Microcontroller Deep Learning through Partial Execution
Nov 30, 2022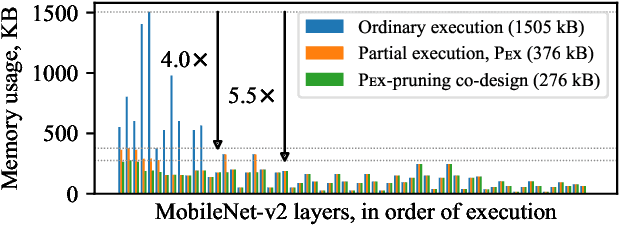
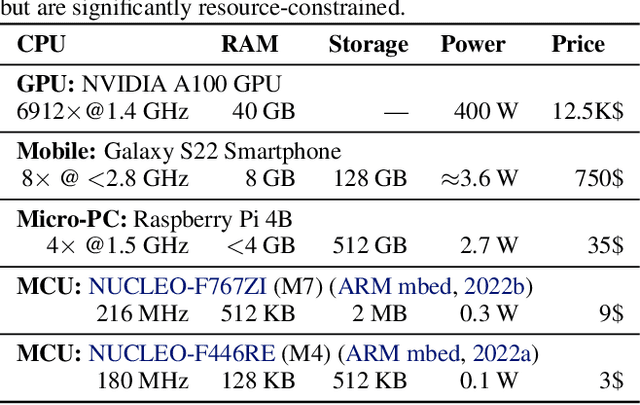
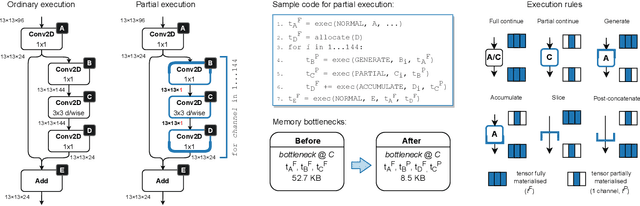

Embedded and IoT devices, largely powered by microcontroller units (MCUs), could be made more intelligent by leveraging on-device deep learning. One of the main challenges of neural network inference on an MCU is the extremely limited amount of read-write on-chip memory (SRAM, < 512 kB). SRAM is consumed by the neural network layer (operator) input and output buffers, which, traditionally, must be in memory (materialised) for an operator to execute. We discuss a novel execution paradigm for microcontroller deep learning, which modifies the execution of neural networks to avoid materialising full buffers in memory, drastically reducing SRAM usage with no computation overhead. This is achieved by exploiting the properties of operators, which can consume/produce a fraction of their input/output at a time. We describe a partial execution compiler, Pex, which produces memory-efficient execution schedules automatically by identifying subgraphs of operators whose execution can be split along the feature ("channel") dimension. Memory usage is reduced further by targeting memory bottlenecks with structured pruning, leading to the co-design of the network architecture and its execution schedule. Our evaluation of image and audio classification models: (a) establishes state-of-the-art performance in low SRAM usage regimes for considered tasks with up to +2.9% accuracy increase; (b) finds that a 4x memory reduction is possible by applying partial execution alone, or up to 10.5x when using the compiler-pruning co-design, while maintaining the classification accuracy compared to prior work; (c) uses the recovered SRAM to process higher resolution inputs instead, increasing accuracy by up to +3.9% on Visual Wake Words.
Residual Aligned: Gradient Optimization for Non-Negative Image Synthesis
Feb 08, 2022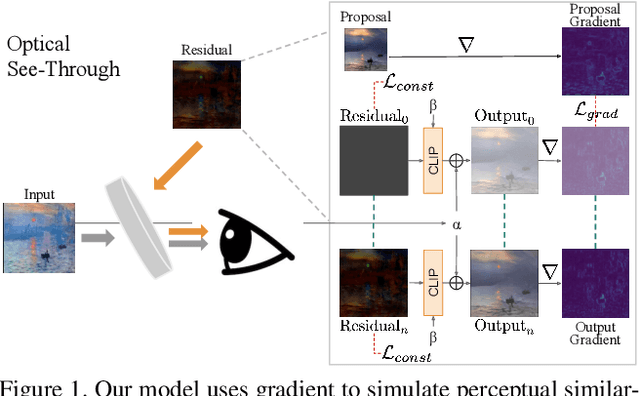

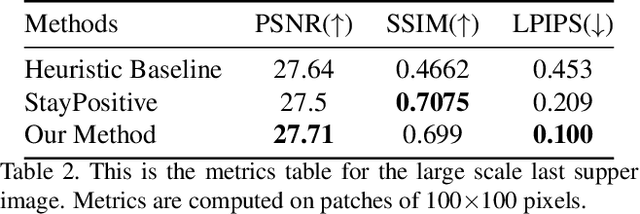

In this work, we address an important problem of optical see through (OST) augmented reality: non-negative image synthesis. Most of the image generation methods fail under this condition, since they assume full control over each pixel and cannot create darker pixels by adding light. In order to solve the non-negative image generation problem in AR image synthesis, prior works have attempted to utilize optical illusion to simulate human vision but fail to preserve lightness constancy well under situations such as high dynamic range. In our paper, we instead propose a method that is able to preserve lightness constancy at a local level, thus capturing high frequency details. Compared with existing work, our method shows strong performance in image-to-image translation tasks, particularly in scenarios such as large scale images, high resolution images, and high dynamic range image transfer.
ManiTrans: Entity-Level Text-Guided Image Manipulation via Token-wise Semantic Alignment and Generation
Apr 09, 2022

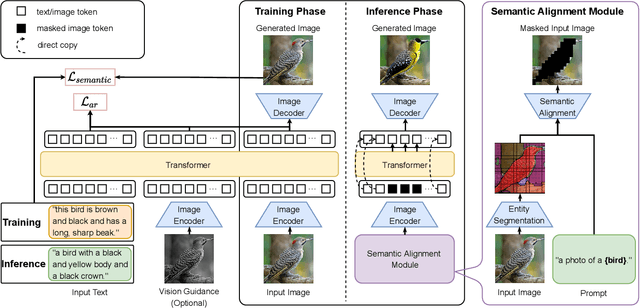
Existing text-guided image manipulation methods aim to modify the appearance of the image or to edit a few objects in a virtual or simple scenario, which is far from practical application. In this work, we study a novel task on text-guided image manipulation on the entity level in the real world. The task imposes three basic requirements, (1) to edit the entity consistent with the text descriptions, (2) to preserve the text-irrelevant regions, and (3) to merge the manipulated entity into the image naturally. To this end, we propose a new transformer-based framework based on the two-stage image synthesis method, namely \textbf{ManiTrans}, which can not only edit the appearance of entities but also generate new entities corresponding to the text guidance. Our framework incorporates a semantic alignment module to locate the image regions to be manipulated, and a semantic loss to help align the relationship between the vision and language. We conduct extensive experiments on the real datasets, CUB, Oxford, and COCO datasets to verify that our method can distinguish the relevant and irrelevant regions and achieve more precise and flexible manipulation compared with baseline methods. The project homepage is \url{https://jawang19.github.io/manitrans}.