 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Distilling Representations from GAN Generator via Squeeze and Span
Nov 06, 2022
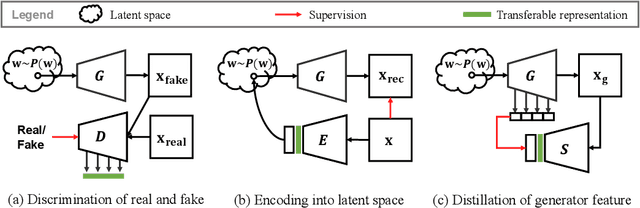
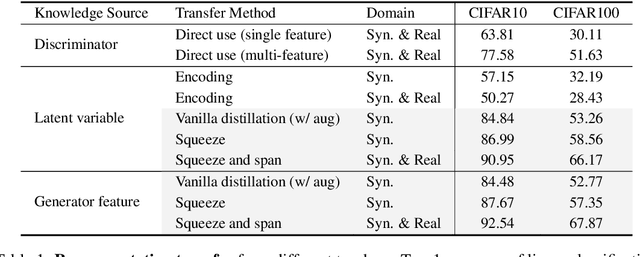

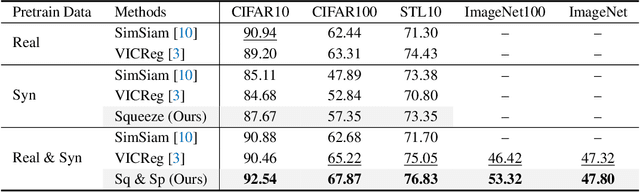
In recent years, generative adversarial networks (GANs) have been an actively studied topic and shown to successfully produce high-quality realistic images in various domains. The controllable synthesis ability of GAN generators suggests that they maintain informative, disentangled, and explainable image representations, but leveraging and transferring their representations to downstream tasks is largely unexplored. In this paper, we propose to distill knowledge from GAN generators by squeezing and spanning their representations. We squeeze the generator features into representations that are invariant to semantic-preserving transformations through a network before they are distilled into the student network. We span the distilled representation of the synthetic domain to the real domain by also using real training data to remedy the mode collapse of GANs and boost the student network performance in a real domain. Experiments justify the efficacy of our method and reveal its great significance in self-supervised representation learning. Code is available at https://github.com/yangyu12/squeeze-and-span.
Plug and Play Active Learning for Object Detection
Nov 21, 2022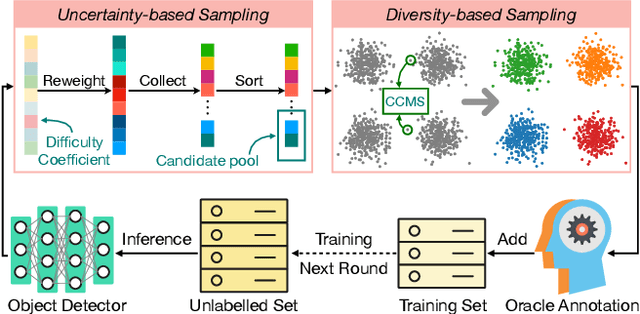
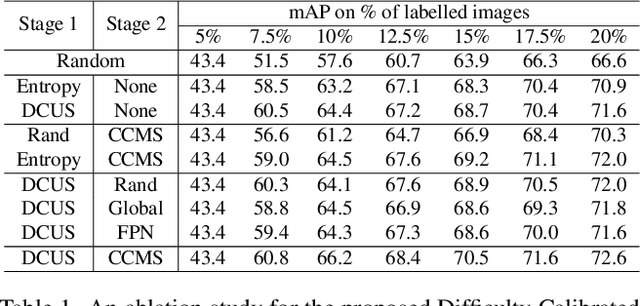
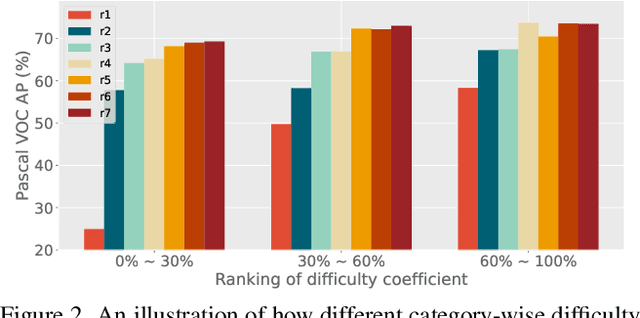
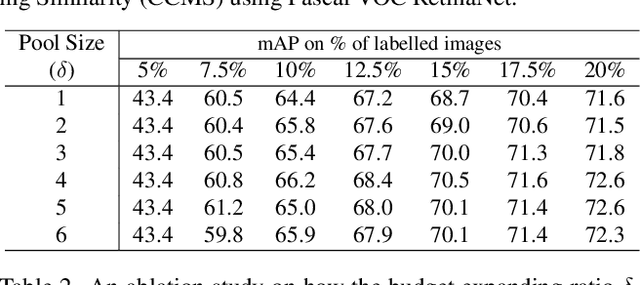
Annotating data for supervised learning is expensive and tedious, and we want to do as little of it as possible. To make the most of a given "annotation budget" we can turn to active learning (AL) which aims to identify the most informative samples in a dataset for annotation. Active learning algorithms are typically uncertainty-based or diversity-based. Both have seen success in image classification, but fall short when it comes to object detection. We hypothesise that this is because: (1) it is difficult to quantify uncertainty for object detection as it consists of both localisation and classification, where some classes are harder to localise, and others are harder to classify; (2) it is difficult to measure similarities for diversity-based AL when images contain different numbers of objects. We propose a two-stage active learning algorithm Plug and Play Active Learning (PPAL) that overcomes these difficulties. It consists of (1) Difficulty Calibrated Uncertainty Sampling, in which we used a category-wise difficulty coefficient that takes both classification and localisation into account to re-weight object uncertainties for uncertainty-based sampling; (2) Category Conditioned Matching Similarity to compute the similarities of multi-instance images as ensembles of their instance similarities. PPAL is highly generalisable because it makes no change to model architectures or detector training pipelines. We benchmark PPAL on the MS-COCO and Pascal VOC datasets using different detector architectures and show that our method outperforms the prior state-of-the-art. Code is available at https://github.com/ChenhongyiYang/PPAL
Deep Projective Rotation Estimation through Relative Supervision
Nov 21, 2022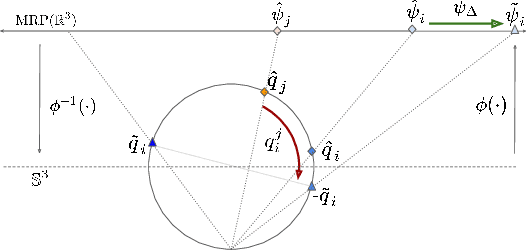

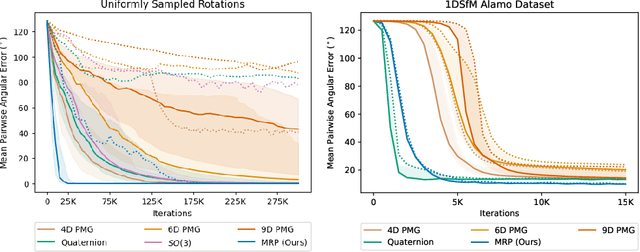
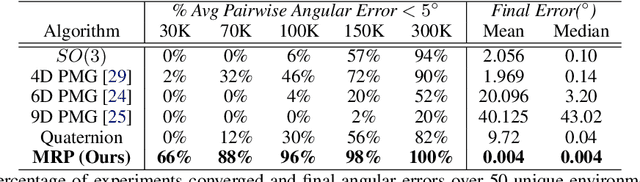
Orientation estimation is the core to a variety of vision and robotics tasks such as camera and object pose estimation. Deep learning has offered a way to develop image-based orientation estimators; however, such estimators often require training on a large labeled dataset, which can be time-intensive to collect. In this work, we explore whether self-supervised learning from unlabeled data can be used to alleviate this issue. Specifically, we assume access to estimates of the relative orientation between neighboring poses, such that can be obtained via a local alignment method. While self-supervised learning has been used successfully for translational object keypoints, in this work, we show that naively applying relative supervision to the rotational group $SO(3)$ will often fail to converge due to the non-convexity of the rotational space. To tackle this challenge, we propose a new algorithm for self-supervised orientation estimation which utilizes Modified Rodrigues Parameters to stereographically project the closed manifold of $SO(3)$ to the open manifold of $\mathbb{R}^{3}$, allowing the optimization to be done in an open Euclidean space. We empirically validate the benefits of the proposed algorithm for rotational averaging problem in two settings: (1) direct optimization on rotation parameters, and (2) optimization of parameters of a convolutional neural network that predicts object orientations from images. In both settings, we demonstrate that our proposed algorithm is able to converge to a consistent relative orientation frame much faster than algorithms that purely operate in the $SO(3)$ space. Additional information can be found at https://sites.google.com/view/deep-projective-rotation/home .
EVNet: An Explainable Deep Network for Dimension Reduction
Nov 21, 2022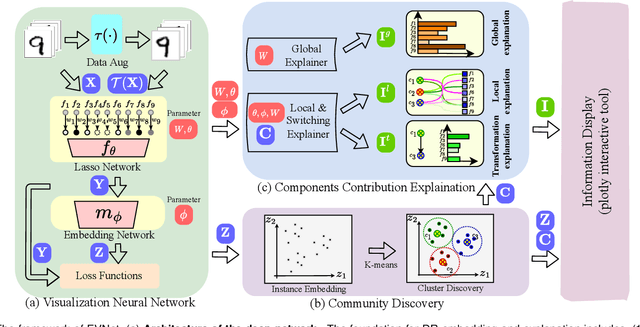
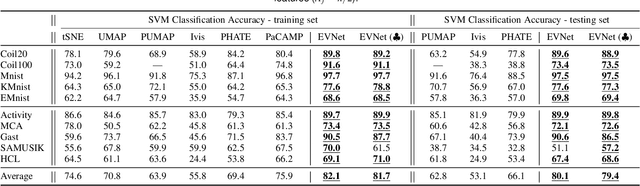
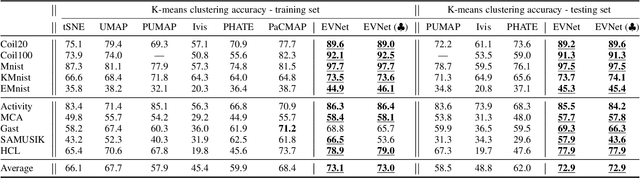
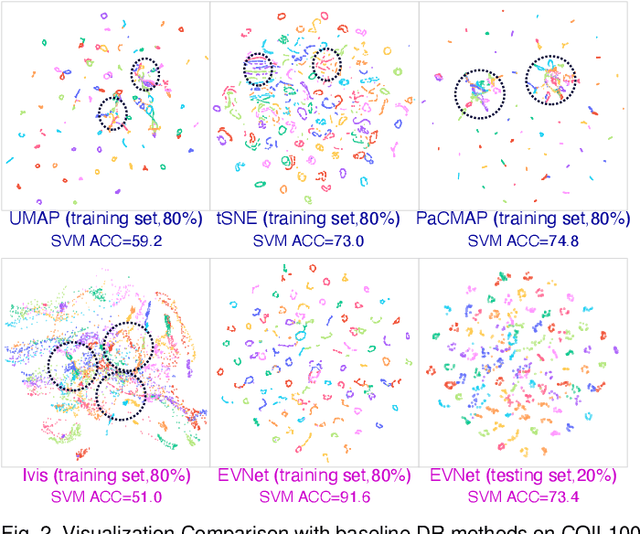
Dimension reduction (DR) is commonly utilized to capture the intrinsic structure and transform high-dimensional data into low-dimensional space while retaining meaningful properties of the original data. It is used in various applications, such as image recognition, single-cell sequencing analysis, and biomarker discovery. However, contemporary parametric-free and parametric DR techniques suffer from several significant shortcomings, such as the inability to preserve global and local features and the pool generalization performance. On the other hand, regarding explainability, it is crucial to comprehend the embedding process, especially the contribution of each part to the embedding process, while understanding how each feature affects the embedding results that identify critical components and help diagnose the embedding process. To address these problems, we have developed a deep neural network method called EVNet, which provides not only excellent performance in structural maintainability but also explainability to the DR therein. EVNet starts with data augmentation and a manifold-based loss function to improve embedding performance. The explanation is based on saliency maps and aims to examine the trained EVNet parameters and contributions of components during the embedding process. The proposed techniques are integrated with a visual interface to help the user to adjust EVNet to achieve better DR performance and explainability. The interactive visual interface makes it easier to illustrate the data features, compare different DR techniques, and investigate DR. An in-depth experimental comparison shows that EVNet consistently outperforms the state-of-the-art methods in both performance measures and explainability.
Adaptive Finite-Time Model Estimation and Control for Manipulator Visual Servoing using Sliding Mode Control and Neural Networks
Nov 21, 2022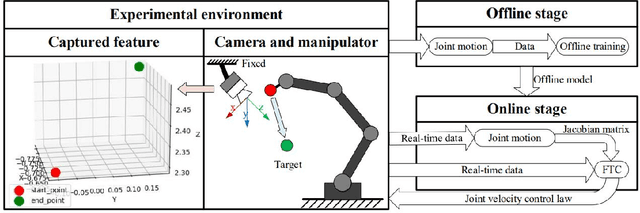
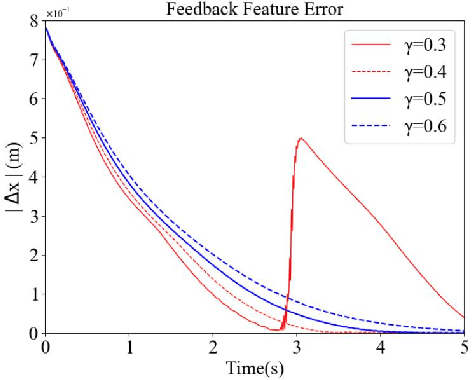
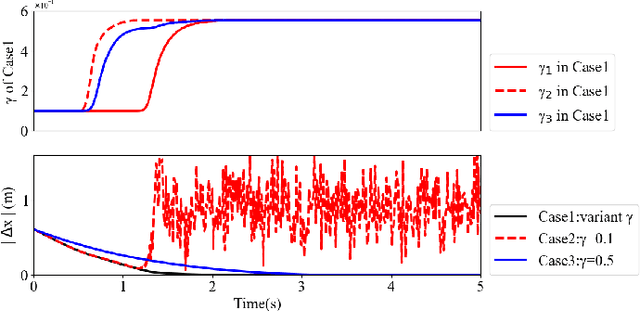
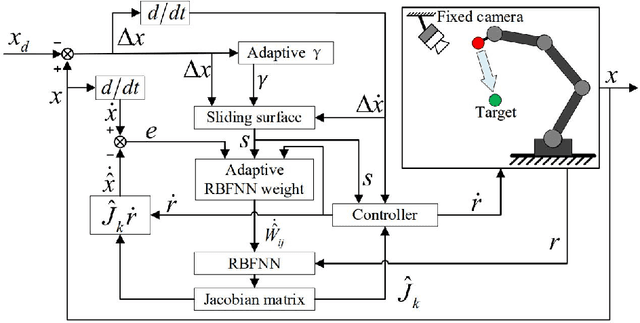
The image-based visual servoing without models of system is challenging since it is hard to fetch an accurate estimation of hand-eye relationship via merely visual measurement. Whereas, the accuracy of estimated hand-eye relationship expressed in local linear format with Jacobian matrix is important to whole system's performance. In this article, we proposed a finite-time controller as well as a Jacobian matrix estimator in a combination of online and offline way. The local linear formulation is formulated first. Then, we use a combination of online and offline method to boost the estimation of the highly coupled and nonlinear hand-eye relationship with data collected via depth camera. A neural network (NN) is pre-trained to give a relative reasonable initial estimation of Jacobian matrix. Then, an online updating method is carried out to modify the offline trained NN for a more accurate estimation. Moreover, sliding mode control algorithm is introduced to realize a finite-time controller. Compared with previous methods, our algorithm possesses better convergence speed. The proposed estimator possesses excellent performance in the accuracy of initial estimation and powerful tracking capabilities for time-varying estimation for Jacobian matrix compared with other data-driven estimators. The proposed scheme acquires the combination of neural network and finite-time control effect which drives a faster convergence speed compared with the exponentially converge ones. Another main feature of our algorithm is that the state signals in system is proved to be semi-global practical finite-time stable. Several experiments are carried out to validate proposed algorithm's performance.
Side-Informed Steganography for JPEG Images by Modeling Decompressed Images
Nov 09, 2022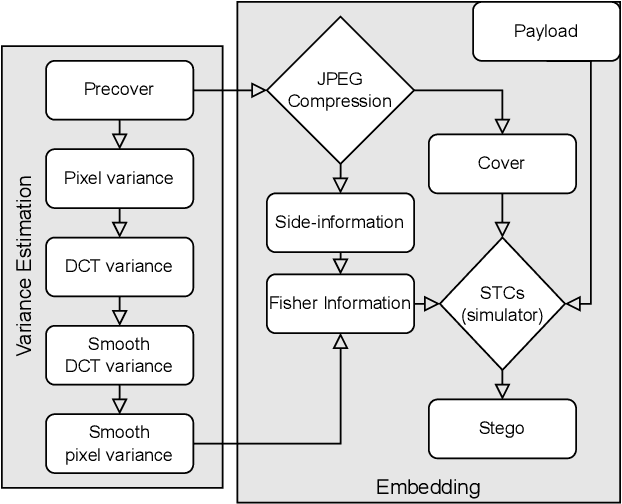
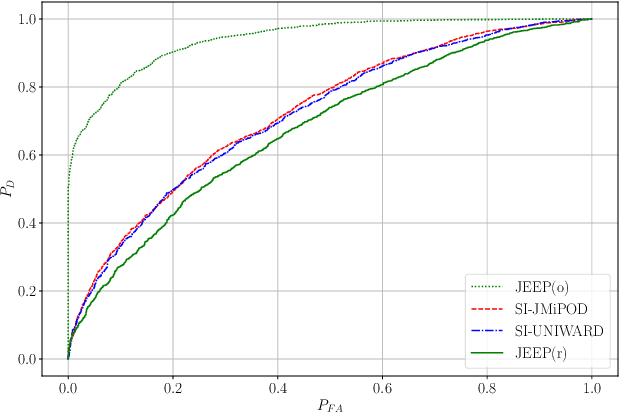
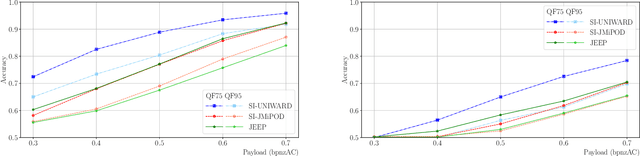
Side-informed steganography has always been among the most secure approaches in the field. However, a majority of existing methods for JPEG images use the side information, here the rounding error, in a heuristic way. For the first time, we show that the usefulness of the rounding error comes from its covariance with the embedding changes. Unfortunately, this covariance between continuous and discrete variables is not analytically available. An estimate of the covariance is proposed, which allows to model steganography as a change in the variance of DCT coefficients. Since steganalysis today is best performed in the spatial domain, we derive a likelihood ratio test to preserve a model of a decompressed JPEG image. The proposed method then bounds the power of this test by minimizing the Kullback-Leibler divergence between the cover and stego distributions. We experimentally demonstrate in two popular datasets that it achieves state-of-the-art performance against deep learning detectors. Moreover, by considering a different pixel variance estimator for images compressed with Quality Factor 100, even greater improvements are obtained.
Manifold Modeling in Quotient Space: Learning An Invariant Mapping with Decodability of Image Patches
Mar 10, 2022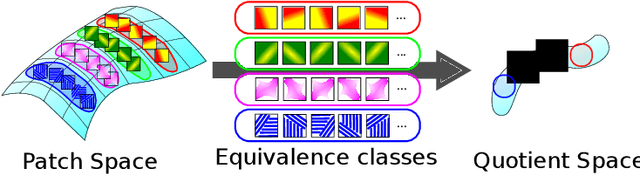
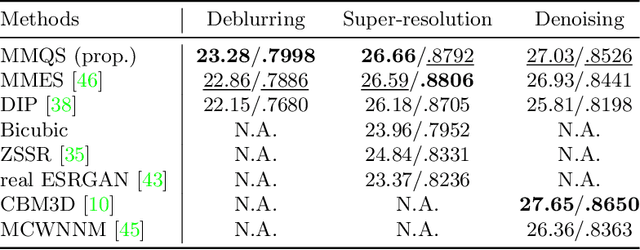
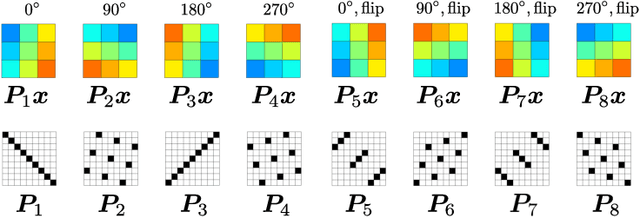
This study proposes a framework for manifold learning of image patches using the concept of equivalence classes: manifold modeling in quotient space (MMQS). In MMQS, we do not consider a set of local patches of the image as it is, but rather the set of their canonical patches obtained by introducing the concept of equivalence classes and performing manifold learning on their canonical patches. Canonical patches represent equivalence classes, and their auto-encoder constructs a manifold in the quotient space. Based on this framework, we produce a novel manifold-based image model by introducing rotation-flip-equivalence relations. In addition, we formulate an image reconstruction problem by fitting the proposed image model to a corrupted observed image and derive an algorithm to solve it. Our experiments show that the proposed image model is effective for various self-supervised image reconstruction tasks, such as image inpainting, deblurring, super-resolution, and denoising.
Automated analysis of diabetic retinopathy using vessel segmentation maps as inductive bias
Oct 28, 2022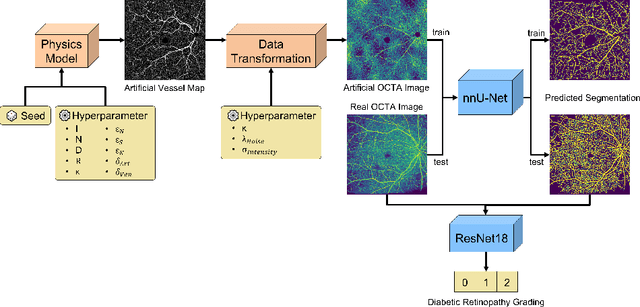

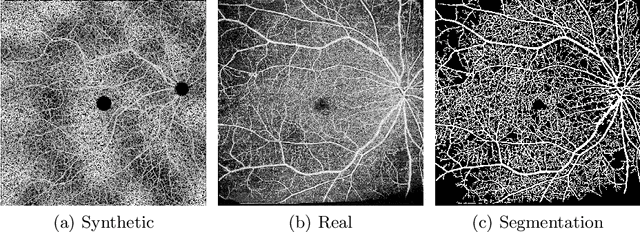
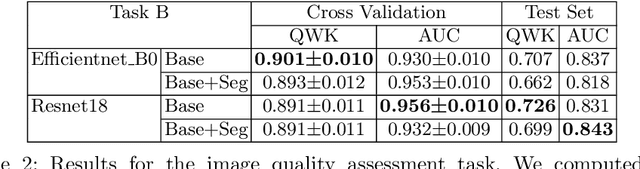
Recent studies suggest that early stages of diabetic retinopathy (DR) can be diagnosed by monitoring vascular changes in the deep vascular complex. In this work, we investigate a novel method for automated DR grading based on optical coherence tomography angiography (OCTA) images. Our work combines OCTA scans with their vessel segmentations, which then serve as inputs to task specific networks for lesion segmentation, image quality assessment and DR grading. For this, we generate synthetic OCTA images to train a segmentation network that can be directly applied on real OCTA data. We test our approach on MICCAI 2022's DR analysis challenge (DRAC). In our experiments, the proposed method performs equally well as the baseline model.
Laplacian Pyramid-like Autoencoder
Aug 26, 2022In this paper, we develop the Laplacian pyramid-like autoencoder (LPAE) by adding the Laplacian pyramid (LP) concept widely used to analyze images in Signal Processing. LPAE decomposes an image into the approximation image and the detail image in the encoder part and then tries to reconstruct the original image in the decoder part using the two components. We use LPAE for experiments on classifications and super-resolution areas. Using the detail image and the smaller-sized approximation image as inputs of a classification network, our LPAE makes the model lighter. Moreover, we show that the performance of the connected classification networks has remained substantially high. In a super-resolution area, we show that the decoder part gets a high-quality reconstruction image by setting to resemble the structure of LP. Consequently, LPAE improves the original results by combining the decoder part of the autoencoder and the super-resolution network.
* 20 pages, 3 figures, 5 tables, Science and Information Conference 2022, Intelligent Computing
Make-A-Video: Text-to-Video Generation without Text-Video Data
Sep 29, 2022

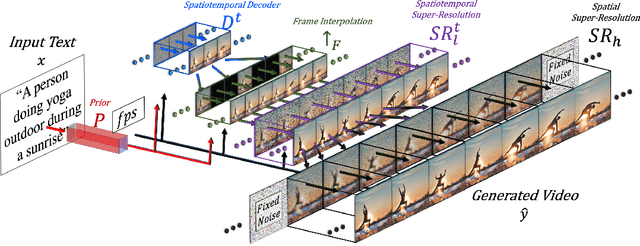
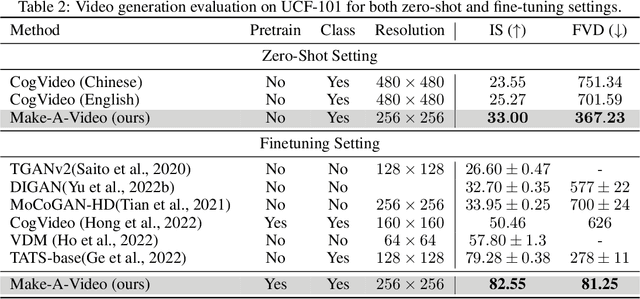
We propose Make-A-Video -- an approach for directly translating the tremendous recent progress in Text-to-Image (T2I) generation to Text-to-Video (T2V). Our intuition is simple: learn what the world looks like and how it is described from paired text-image data, and learn how the world moves from unsupervised video footage. Make-A-Video has three advantages: (1) it accelerates training of the T2V model (it does not need to learn visual and multimodal representations from scratch), (2) it does not require paired text-video data, and (3) the generated videos inherit the vastness (diversity in aesthetic, fantastical depictions, etc.) of today's image generation models. We design a simple yet effective way to build on T2I models with novel and effective spatial-temporal modules. First, we decompose the full temporal U-Net and attention tensors and approximate them in space and time. Second, we design a spatial temporal pipeline to generate high resolution and frame rate videos with a video decoder, interpolation model and two super resolution models that can enable various applications besides T2V. In all aspects, spatial and temporal resolution, faithfulness to text, and quality, Make-A-Video sets the new state-of-the-art in text-to-video generation, as determined by both qualitative and quantitative measures.