 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multimodal Query-guided Object Localization
Dec 01, 2022
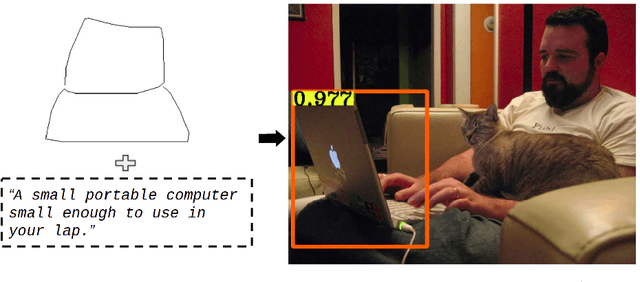
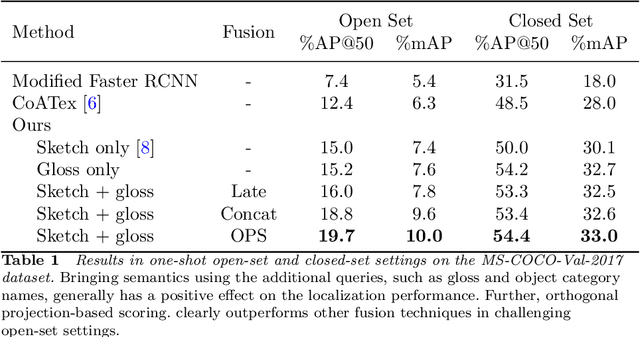
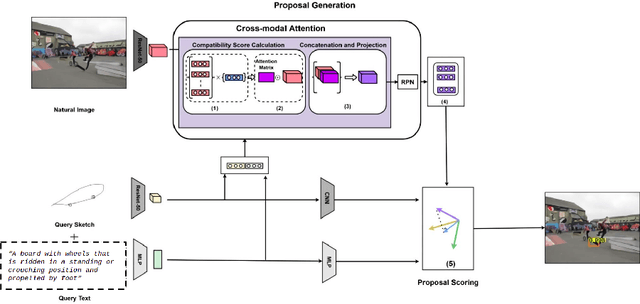

Consider a scenario in one-shot query-guided object localization where neither an image of the object nor the object category name is available as a query. In such a scenario, a hand-drawn sketch of the object could be a choice for a query. However, hand-drawn crude sketches alone, when used as queries, might be ambiguous for object localization, e.g., a sketch of a laptop could be confused for a sofa. On the other hand, a linguistic definition of the category, e.g., a small portable computer small enough to use in your lap" along with the sketch query, gives better visual and semantic cues for object localization. In this work, we present a multimodal query-guided object localization approach under the challenging open-set setting. In particular, we use queries from two modalities, namely, hand-drawn sketch and description of the object (also known as gloss), to perform object localization. Multimodal query-guided object localization is a challenging task, especially when a large domain gap exists between the queries and the natural images, as well as due to the challenge of combining the complementary and minimal information present across the queries. For example, hand-drawn crude sketches contain abstract shape information of an object, while the text descriptions often capture partial semantic information about a given object category. To address the aforementioned challenges, we present a novel cross-modal attention scheme that guides the region proposal network to generate object proposals relevant to the input queries and a novel orthogonal projection-based proposal scoring technique that scores each proposal with respect to the queries, thereby yielding the final localization results. ...
Equivariance Regularization for Image Reconstruction
Feb 12, 2022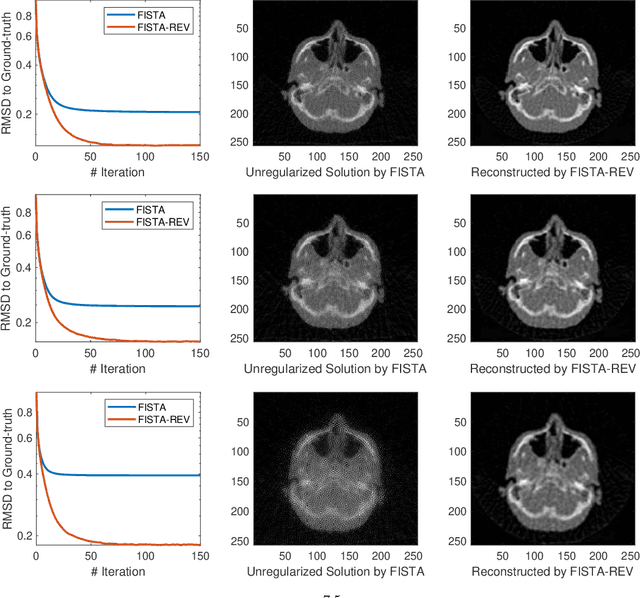
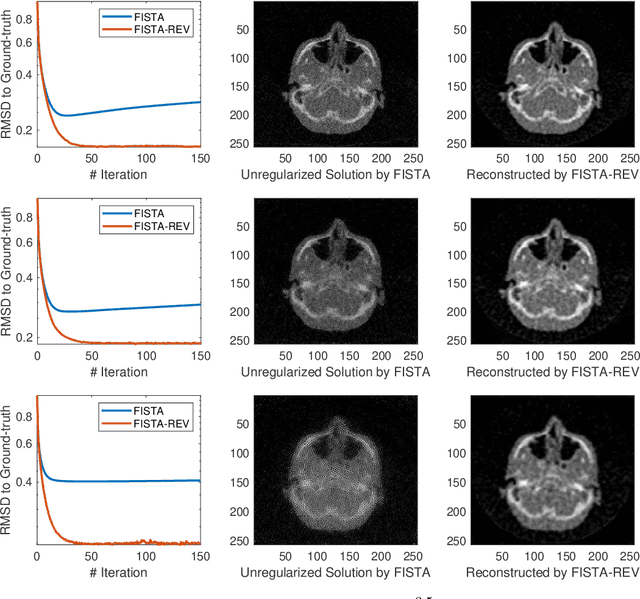
In this work, we propose Regularization-by-Equivariance (REV), a novel structure-adaptive regularization scheme for solving imaging inverse problems under incomplete measurements. This regularization scheme utilizes the equivariant structure in the physics of the measurements -- which is prevalent in many inverse problems such as tomographic image reconstruction -- to mitigate the ill-poseness of the inverse problem. Our proposed scheme can be applied in a plug-and-play manner alongside with any classic first-order optimization algorithm such as the accelerated gradient descent/FISTA for simplicity and fast convergence. The numerical experiments in sparse-view X-ray CT image reconstruction tasks demonstrate the effectiveness of our approach.
Editable Indoor Lighting Estimation
Nov 09, 2022
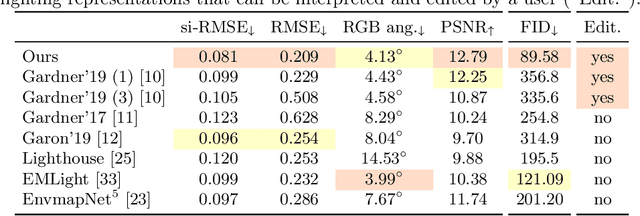
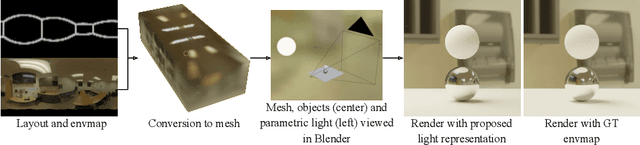
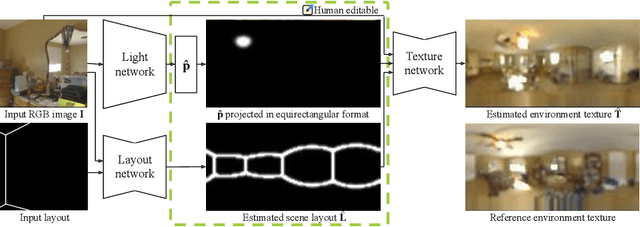
We present a method for estimating lighting from a single perspective image of an indoor scene. Previous methods for predicting indoor illumination usually focus on either simple, parametric lighting that lack realism, or on richer representations that are difficult or even impossible to understand or modify after prediction. We propose a pipeline that estimates a parametric light that is easy to edit and allows renderings with strong shadows, alongside with a non-parametric texture with high-frequency information necessary for realistic rendering of specular objects. Once estimated, the predictions obtained with our model are interpretable and can easily be modified by an artist/user with a few mouse clicks. Quantitative and qualitative results show that our approach makes indoor lighting estimation easier to handle by a casual user, while still producing competitive results.
Joint Multi-Person Body Detection and Orientation Estimation via One Unified Embedding
Oct 27, 2022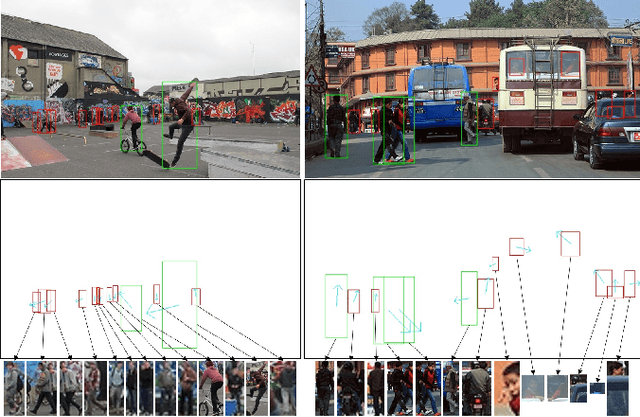
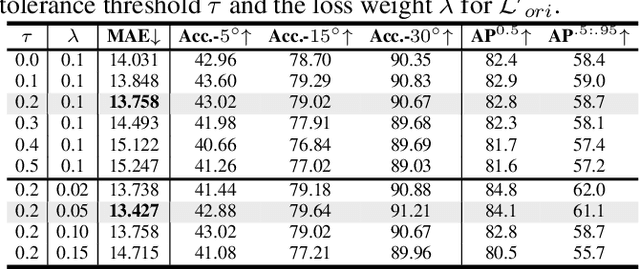
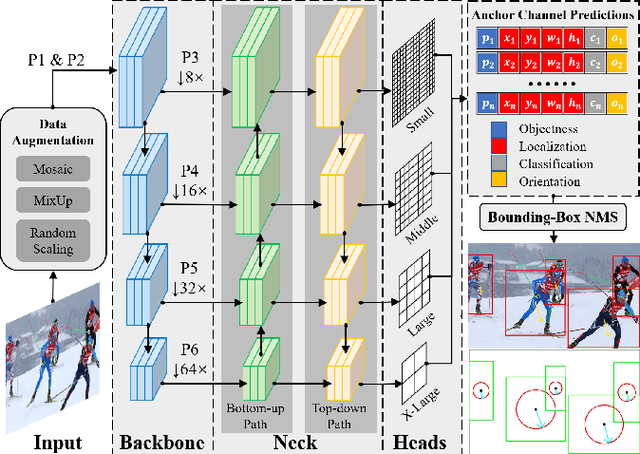
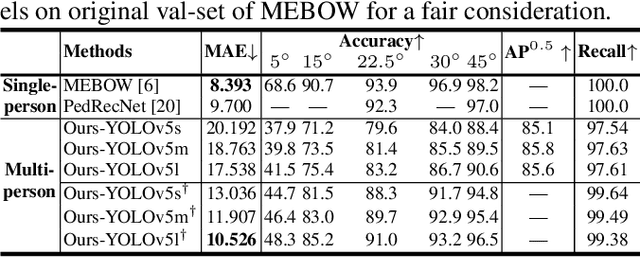
Human body orientation estimation (HBOE) is widely applied into various applications, including robotics, surveillance, pedestrian analysis and autonomous driving. Although many approaches have been addressing the HBOE problem from specific under-controlled scenes to challenging in-the-wild environments, they assume human instances are already detected and take a well cropped sub-image as the input. This setting is less efficient and prone to errors in real application, such as crowds of people. In the paper, we propose a single-stage end-to-end trainable framework for tackling the HBOE problem with multi-persons. By integrating the prediction of bounding boxes and direction angles in one embedding, our method can jointly estimate the location and orientation of all bodies in one image directly. Our key idea is to integrate the HBOE task into the multi-scale anchor channel predictions of persons for concurrently benefiting from engaged intermediate features. Therefore, our approach can naturally adapt to difficult instances involving low resolution and occlusion as in object detection. We validated the efficiency and effectiveness of our method in the recently presented benchmark MEBOW with extensive experiments. Besides, we completed ambiguous instances ignored by the MEBOW dataset, and provided corresponding weak body-orientation labels to keep the integrity and consistency of it for supporting studies toward multi-persons. Our work is available at \url{https://github.com/hnuzhy/JointBDOE}.
covEcho Resource constrained lung ultrasound image analysis tool for faster triaging and active learning
Jun 21, 2022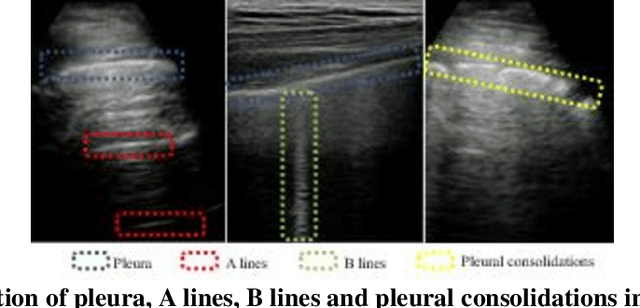
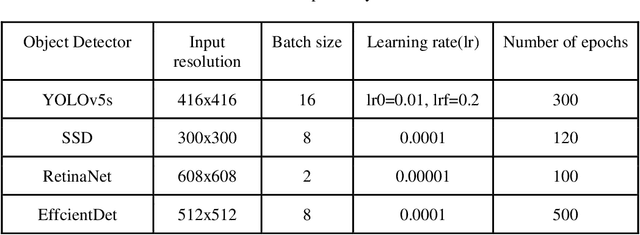
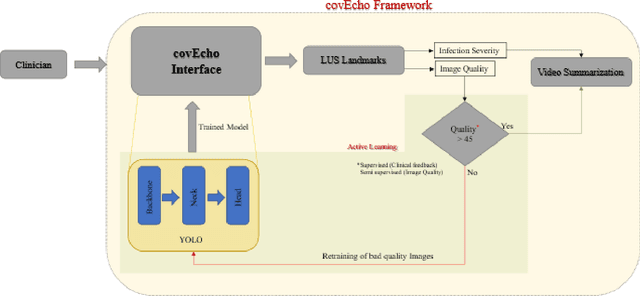
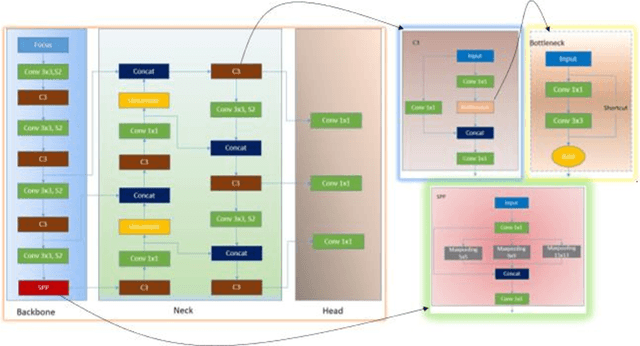
Lung ultrasound (LUS) is possibly the only medical imaging modality which could be used for continuous and periodic monitoring of the lung. This is extremely useful in tracking the lung manifestations either during the onset of lung infection or to track the effect of vaccination on lung as in pandemics such as COVID-19. There have been many attempts in automating the classification of severity of lung into various classes or automatic segmentation of various LUS landmarks and manifestations. However, all these approaches are based on training static machine learning models which require a significantly clinically annotated large dataset and are computationally heavy and most of the time non-real time. In this work, a real-time light weight active learning-based approach is presented for faster triaging in COVID-19 subjects in resource constrained settings. The tool, based on the you look only once (YOLO) network, has the capability of providing the quality of images based on the identification of various LUS landmarks, artefacts and manifestations, prediction of severity of lung infection, possibility of active learning based on the feedback from clinicians or on the image quality and a summarization of the significant frames which are having high severity of infection and high image quality for further analysis. The results show that the proposed tool has a mean average precision (mAP) of 66% at an Intersection over Union (IoU) threshold of 0.5 for the prediction of LUS landmarks. The 14MB lightweight YOLOv5s network achieves 123 FPS while running in a Quadro P4000 GPU. The tool is available for usage and analysis upon request from the authors.
Guided Unsupervised Learning by Subaperture Decomposition for Ocean SAR Image Retrieval
Sep 29, 2022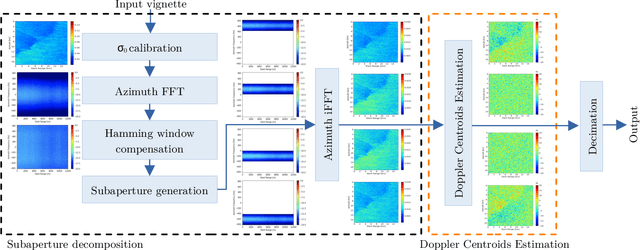
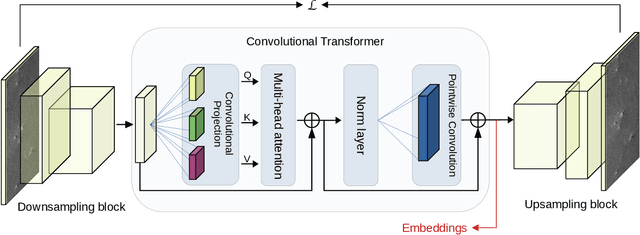
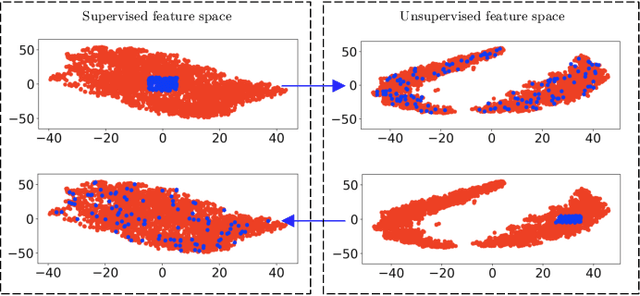
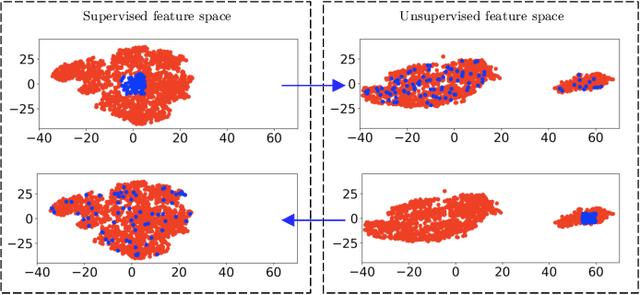
Spaceborne synthetic aperture radar (SAR) can provide accurate images of the ocean surface roughness day-or-night in nearly all weather conditions, being an unique asset for many geophysical applications. Considering the huge amount of data daily acquired by satellites, automated techniques for physical features extraction are needed. Even if supervised deep learning methods attain state-of-the-art results, they require great amount of labeled data, which are difficult and excessively expensive to acquire for ocean SAR imagery. To this end, we use the subaperture decomposition (SD) algorithm to enhance the unsupervised learning retrieval on the ocean surface, empowering ocean researchers to search into large ocean databases. We empirically prove that SD improve the retrieval precision with over 20% for an unsupervised transformer auto-encoder network. Moreover, we show that SD brings important performance boost when Doppler centroid images are used as input data, leading the way to new unsupervised physics guided retrieval algorithms.
Explainer Divergence Scores (EDS): Some Post-Hoc Explanations May be Effective for Detecting Unknown Spurious Correlations
Nov 14, 2022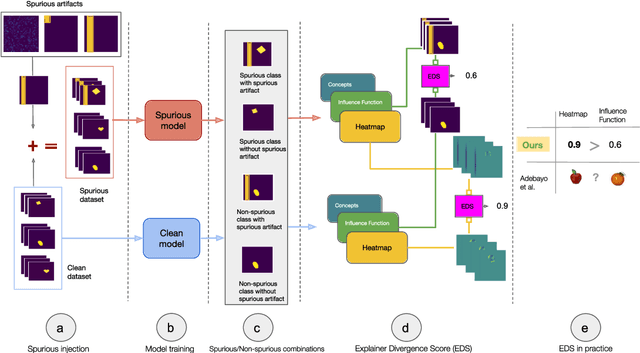
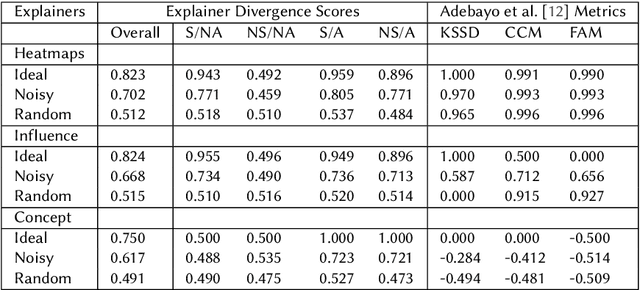
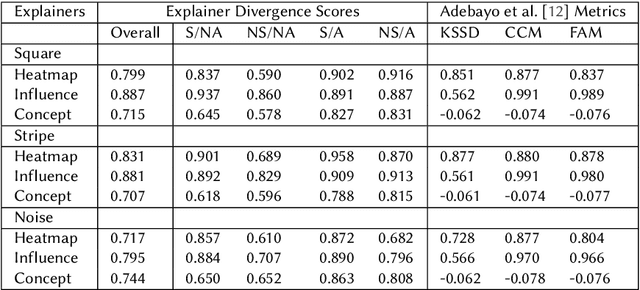
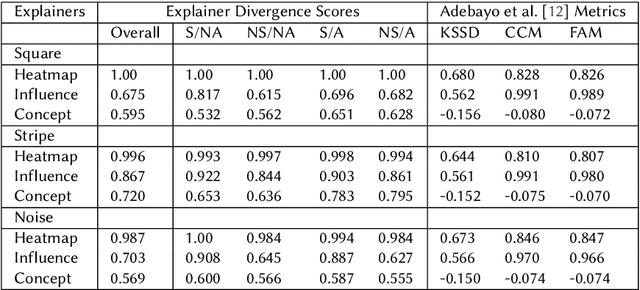
Recent work has suggested post-hoc explainers might be ineffective for detecting spurious correlations in Deep Neural Networks (DNNs). However, we show there are serious weaknesses with the existing evaluation frameworks for this setting. Previously proposed metrics are extremely difficult to interpret and are not directly comparable between explainer methods. To alleviate these constraints, we propose a new evaluation methodology, Explainer Divergence Scores (EDS), grounded in an information theory approach to evaluate explainers. EDS is easy to interpret and naturally comparable across explainers. We use our methodology to compare the detection performance of three different explainers - feature attribution methods, influential examples and concept extraction, on two different image datasets. We discover post-hoc explainers often contain substantial information about a DNN's dependence on spurious artifacts, but in ways often imperceptible to human users. This suggests the need for new techniques that can use this information to better detect a DNN's reliance on spurious correlations.
Few-shot Metric Learning: Online Adaptation of Embedding for Retrieval
Nov 14, 2022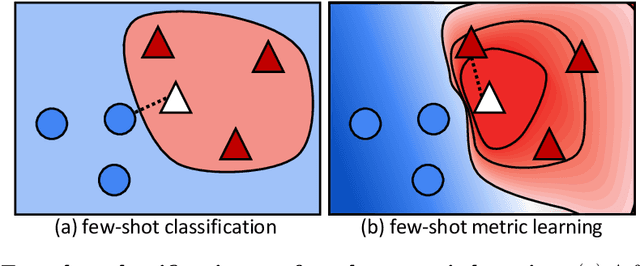
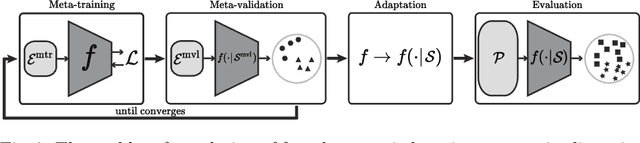

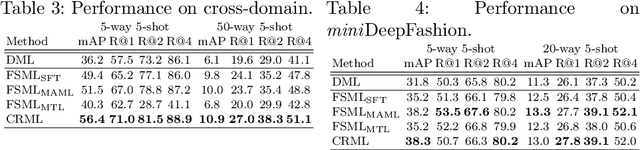
Metric learning aims to build a distance metric typically by learning an effective embedding function that maps similar objects into nearby points in its embedding space. Despite recent advances in deep metric learning, it remains challenging for the learned metric to generalize to unseen classes with a substantial domain gap. To tackle the issue, we explore a new problem of few-shot metric learning that aims to adapt the embedding function to the target domain with only a few annotated data. We introduce three few-shot metric learning baselines and propose the Channel-Rectifier Meta-Learning (CRML), which effectively adapts the metric space online by adjusting channels of intermediate layers. Experimental analyses on miniImageNet, CUB-200-2011, MPII, as well as a new dataset, miniDeepFashion, demonstrate that our method consistently improves the learned metric by adapting it to target classes and achieves a greater gain in image retrieval when the domain gap from the source classes is larger.
TriDoNet: A Triple Domain Model-driven Network for CT Metal Artifact Reduction
Nov 14, 2022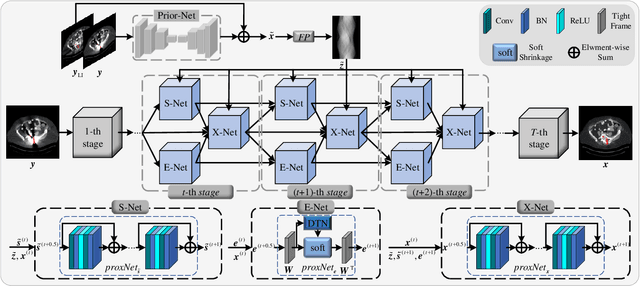
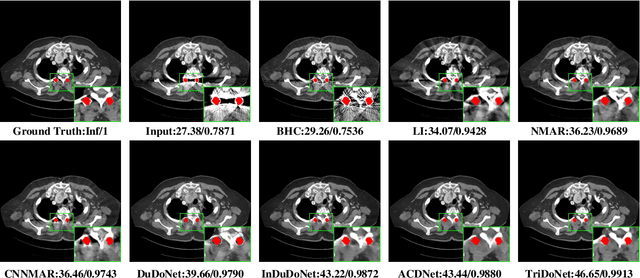
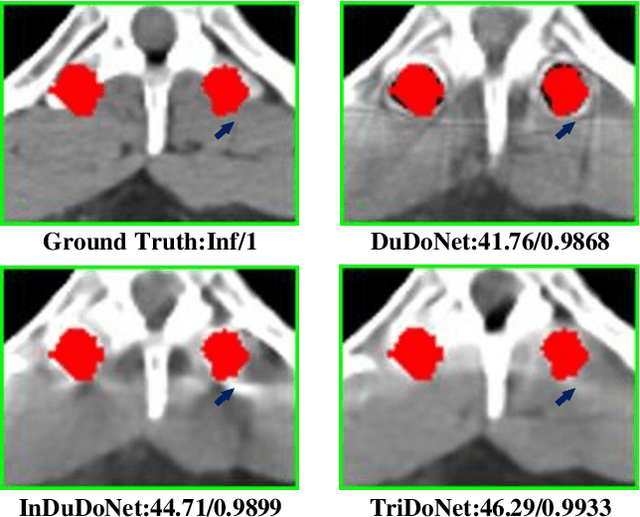
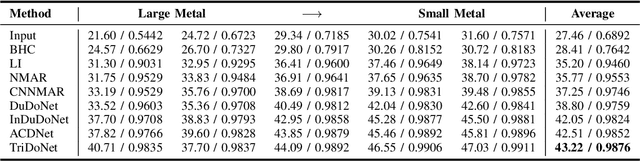
Recent deep learning-based methods have achieved promising performance for computed tomography metal artifact reduction (CTMAR). However, most of them suffer from two limitations: (i) the domain knowledge is not fully embedded into the network training; (ii) metal artifacts lack effective representation models. The aforementioned limitations leave room for further performance improvement. Against these issues, we propose a novel triple domain model-driven CTMAR network, termed as TriDoNet, whose network training exploits triple domain knowledge, i.e., the knowledge of the sinogram, CT image, and metal artifact domains. Specifically, to explore the non-local repetitive streaking patterns of metal artifacts, we encode them as an explicit tight frame sparse representation model with adaptive thresholds. Furthermore, we design a contrastive regularization (CR) built upon contrastive learning to exploit clean CT images and metal-affected images as positive and negative samples, respectively. Experimental results show that our TriDoNet can generate superior artifact-reduced CT images.
Image Synthesis with Disentangled Attributes for Chest X-Ray Nodule Augmentation and Detection
Jul 19, 2022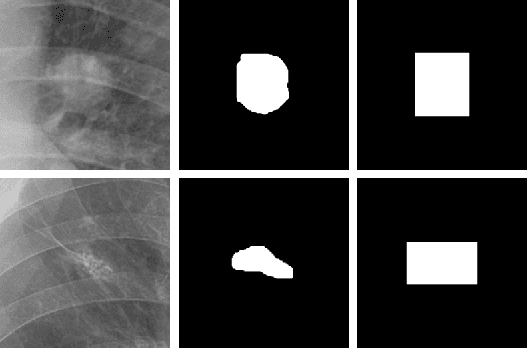
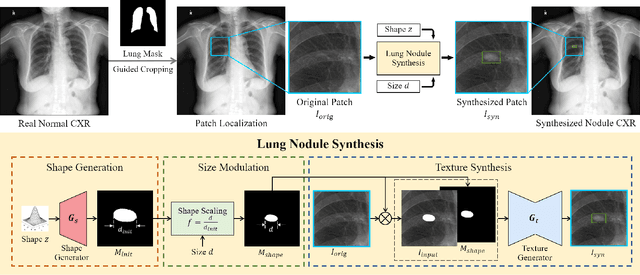
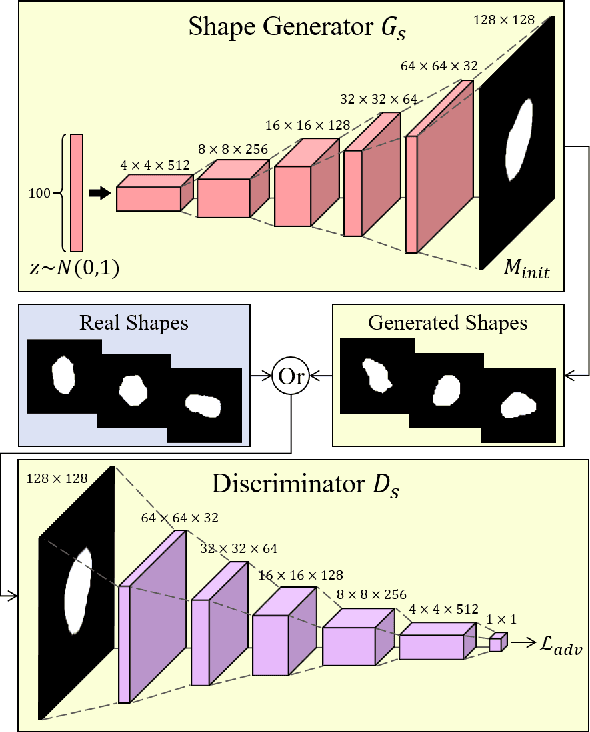
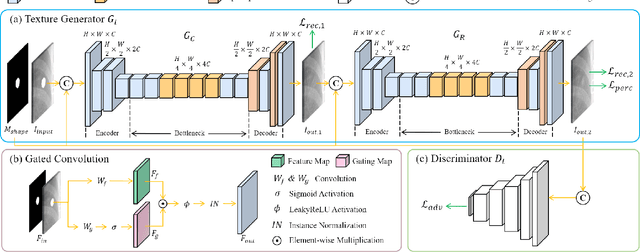
Lung nodule detection in chest X-ray (CXR) images is common to early screening of lung cancers. Deep-learning-based Computer-Assisted Diagnosis (CAD) systems can support radiologists for nodule screening in CXR. However, it requires large-scale and diverse medical data with high-quality annotations to train such robust and accurate CADs. To alleviate the limited availability of such datasets, lung nodule synthesis methods are proposed for the sake of data augmentation. Nevertheless, previous methods lack the ability to generate nodules that are realistic with the size attribute desired by the detector. To address this issue, we introduce a novel lung nodule synthesis framework in this paper, which decomposes nodule attributes into three main aspects including shape, size, and texture, respectively. A GAN-based Shape Generator firstly models nodule shapes by generating diverse shape masks. The following Size Modulation then enables quantitative control on the diameters of the generated nodule shapes in pixel-level granularity. A coarse-to-fine gated convolutional Texture Generator finally synthesizes visually plausible nodule textures conditioned on the modulated shape masks. Moreover, we propose to synthesize nodule CXR images by controlling the disentangled nodule attributes for data augmentation, in order to better compensate for the nodules that are easily missed in the detection task. Our experiments demonstrate the enhanced image quality, diversity, and controllability of the proposed lung nodule synthesis framework. We also validate the effectiveness of our data augmentation on greatly improving nodule detection performance.