 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Survey on Infrared Image and Video Sets
Mar 16, 2022
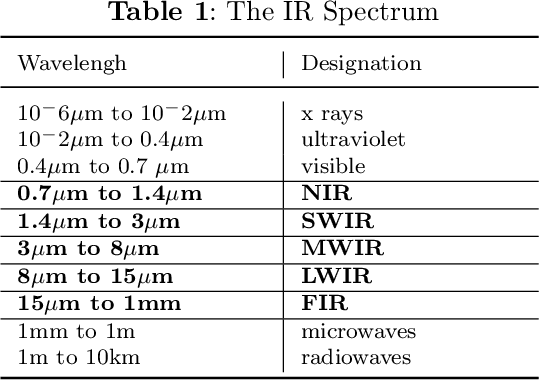
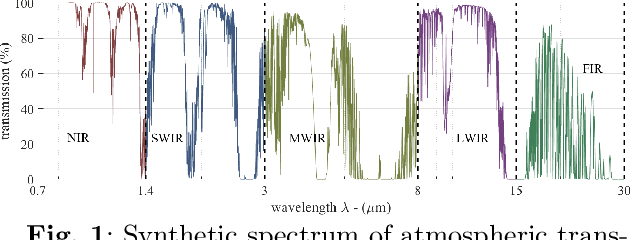
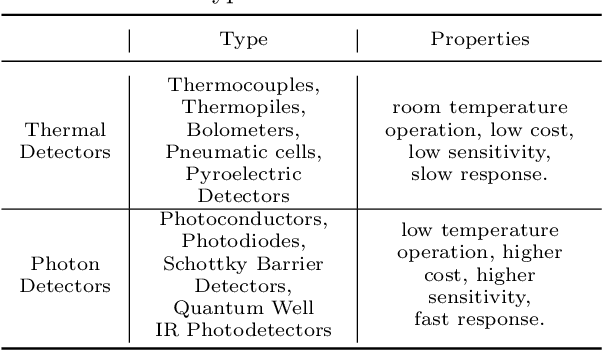
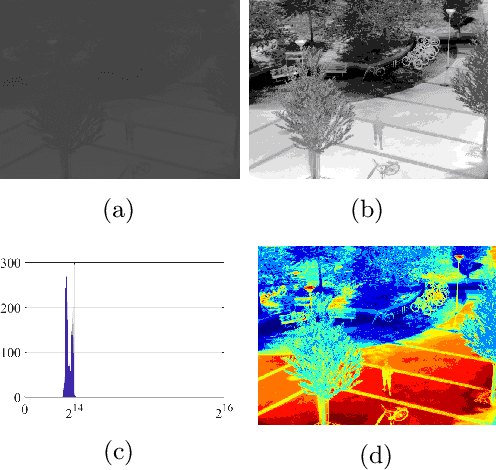
In this survey, we compile a list of publicly available infrared image and video sets for artificial intelligence and computer vision researchers. We mainly focus on IR image and video sets which are collected and labelled for computer vision applications such as object detection, object segmentation, classification, and motion detection. We categorize 92 different publicly available or private sets according to their sensor types, image resolution, and scale. We describe each and every set in detail regarding their collection purpose, operation environment, optical system properties, and area of application. We also cover a general overview of fundamental concepts that relate to IR imagery, such as IR radiation, IR detectors, IR optics and application fields. We analyse the statistical significance of the entire corpus from different perspectives. We believe that this survey will be a guideline for computer vision and artificial intelligence researchers that are interested in working with the spectra beyond the visible domain.
A New Path: Scaling Vision-and-Language Navigation with Synthetic Instructions and Imitation Learning
Oct 06, 2022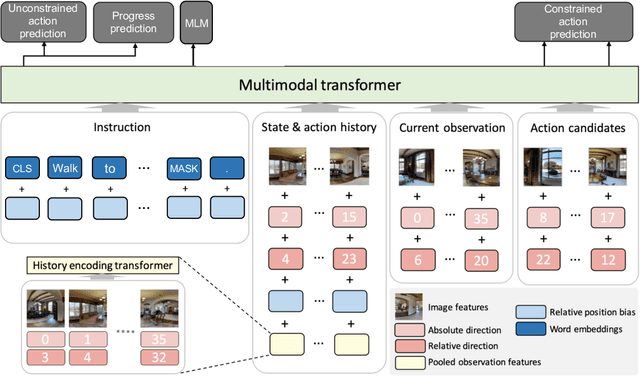
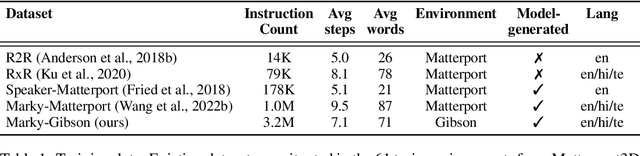
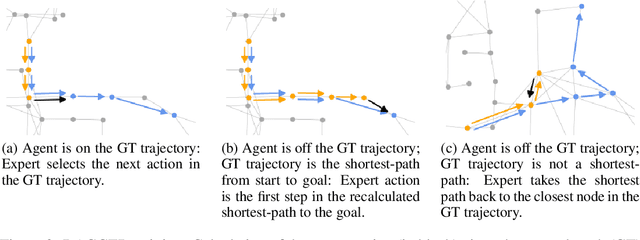

Recent studies in Vision-and-Language Navigation (VLN) train RL agents to execute natural-language navigation instructions in photorealistic environments, as a step towards intelligent agents or robots that can follow human instructions. However, given the scarcity of human instruction data and limited diversity in the training environments, these agents still struggle with complex language grounding and spatial language understanding. Pre-training on large text and image-text datasets from the web has been extensively explored but the improvements are limited. To address the scarcity of in-domain instruction data, we investigate large-scale augmentation with synthetic instructions. We take 500+ indoor environments captured in densely-sampled 360 deg panoramas, construct navigation trajectories through these panoramas, and generate a visually-grounded instruction for each trajectory using Marky (Wang et al., 2022), a high-quality multilingual navigation instruction generator. To further increase the variability of the trajectories, we also synthesize image observations from novel viewpoints using an image-to-image GAN. The resulting dataset of 4.2M instruction-trajectory pairs is two orders of magnitude larger than existing human-annotated datasets, and contains a wider variety of environments and viewpoints. To efficiently leverage data at this scale, we train a transformer agent with imitation learning for over 700M steps of experience. On the challenging Room-across-Room dataset, our approach outperforms all existing RL agents, improving the state-of-the-art NDTW from 71.1 to 79.1 in seen environments, and from 64.6 to 66.8 in unseen test environments. Our work points to a new path to improving instruction-following agents, emphasizing large-scale imitation learning and the development of synthetic instruction generation capabilities.
SVFormer: Semi-supervised Video Transformer for Action Recognition
Nov 23, 2022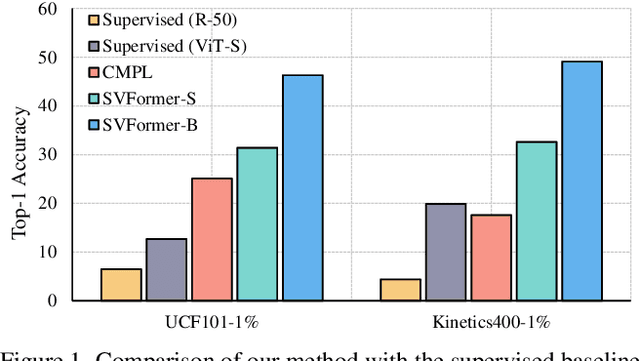
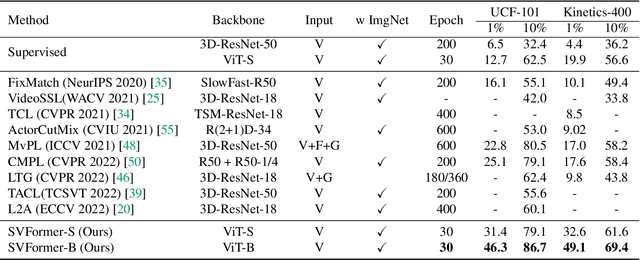


Semi-supervised action recognition is a challenging but critical task due to the high cost of video annotations. Existing approaches mainly use convolutional neural networks, yet current revolutionary vision transformer models have been less explored. In this paper, we investigate the use of transformer models under the SSL setting for action recognition. To this end, we introduce SVFormer, which adopts a steady pseudo-labeling framework (ie, EMA-Teacher) to cope with unlabeled video samples. While a wide range of data augmentations have been shown effective for semi-supervised image classification, they generally produce limited results for video recognition. We therefore introduce a novel augmentation strategy, Tube TokenMix, tailored for video data where video clips are mixed via a mask with consistent masked tokens over the temporal axis. In addition, we propose a temporal warping augmentation to cover the complex temporal variation in videos, which stretches selected frames to various temporal durations in the clip. Extensive experiments on three datasets Kinetics-400, UCF-101, and HMDB-51 verify the advantage of SVFormer. In particular, SVFormer outperforms the state-of-the-art by 31.5% with fewer training epochs under the 1% labeling rate of Kinetics-400. Our method can hopefully serve as a strong benchmark and encourage future search on semi-supervised action recognition with Transformer networks.
Learning Compact Features via In-Training Representation Alignment
Nov 23, 2022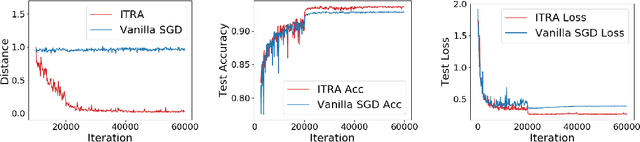
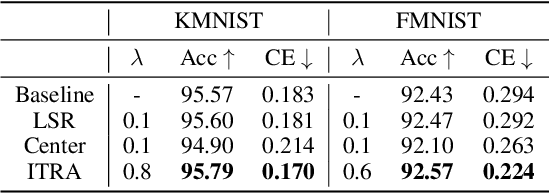
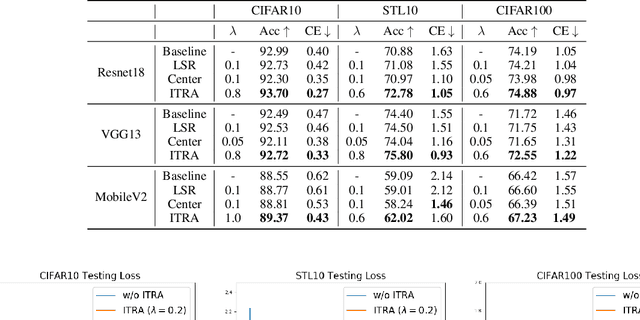
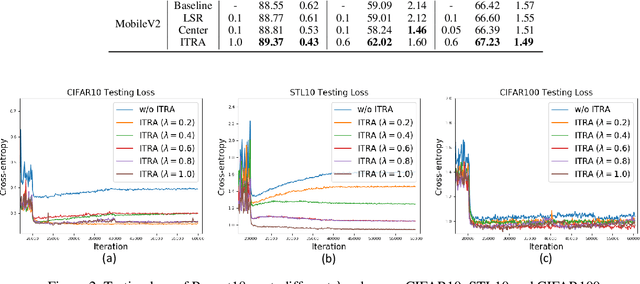
Deep neural networks (DNNs) for supervised learning can be viewed as a pipeline of the feature extractor (i.e., last hidden layer) and a linear classifier (i.e., output layer) that are trained jointly with stochastic gradient descent (SGD) on the loss function (e.g., cross-entropy). In each epoch, the true gradient of the loss function is estimated using a mini-batch sampled from the training set and model parameters are then updated with the mini-batch gradients. Although the latter provides an unbiased estimation of the former, they are subject to substantial variances derived from the size and number of sampled mini-batches, leading to noisy and jumpy updates. To stabilize such undesirable variance in estimating the true gradients, we propose In-Training Representation Alignment (ITRA) that explicitly aligns feature distributions of two different mini-batches with a matching loss in the SGD training process. We also provide a rigorous analysis of the desirable effects of the matching loss on feature representation learning: (1) extracting compact feature representation; (2) reducing over-adaption on mini-batches via an adaptive weighting mechanism; and (3) accommodating to multi-modalities. Finally, we conduct large-scale experiments on both image and text classifications to demonstrate its superior performance to the strong baselines.
Paired Image to Image Translation for Strikethrough Removal From Handwritten Words
Jan 24, 2022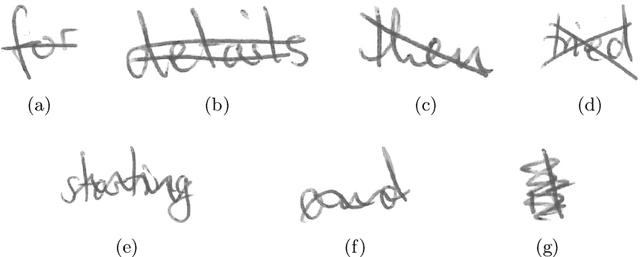
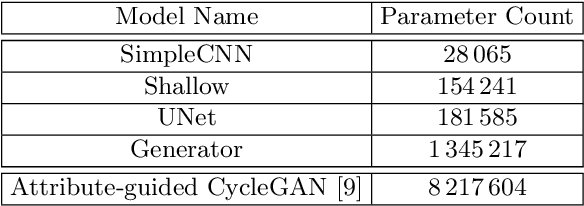
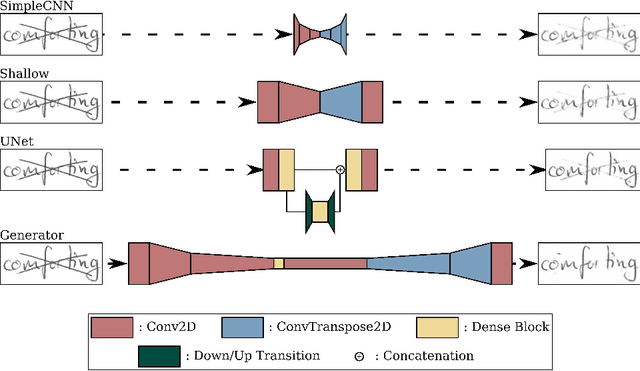
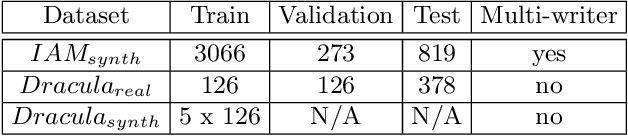
Transcribing struck-through, handwritten words, for example for the purpose of genetic criticism, can pose a challenge to both humans and machines, due to the obstructive properties of the superimposed strokes. This paper investigates the use of paired image to image translation approaches to remove strikethrough strokes from handwritten words. Four different neural network architectures are examined, ranging from a few simple convolutional layers to deeper ones, employing Dense blocks. Experimental results, obtained from one synthetic and one genuine paired strikethrough dataset, confirm that the proposed paired models outperform the CycleGAN-based state of the art, while using less than a sixth of the trainable parameters.
Contextual Squeeze-and-Excitation for Efficient Few-Shot Image Classification
Jun 20, 2022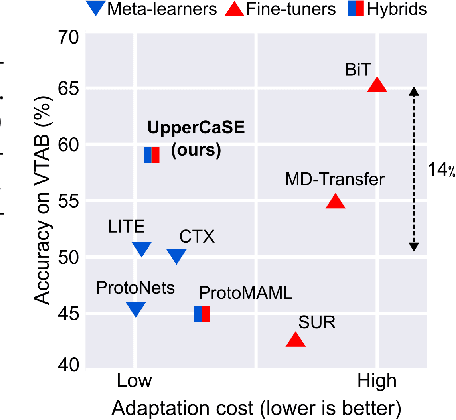
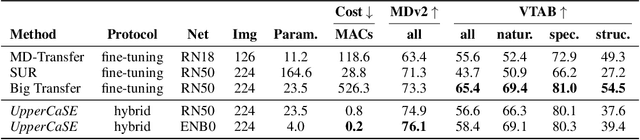
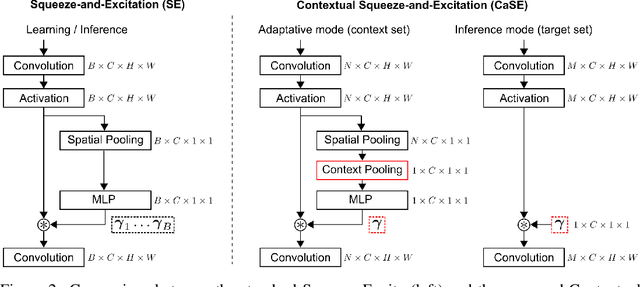
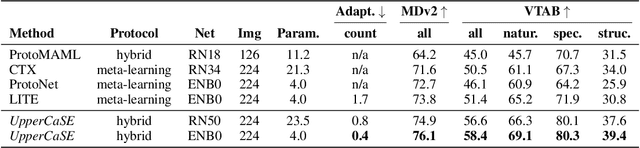
Recent years have seen a growth in user-centric applications that require effective knowledge transfer across tasks in the low-data regime. An example is personalization, where a pretrained system is adapted by learning on small amounts of labeled data belonging to a specific user. This setting requires high accuracy under low computational complexity, therefore the Pareto frontier of accuracy vs.~adaptation cost plays a crucial role. In this paper we push this Pareto frontier in the few-shot image classification setting with two key contributions: (i) a new adaptive block called Contextual Squeeze-and-Excitation (CaSE) that adjusts a pretrained neural network on a new task to significantly improve performance with a single forward pass of the user data (context), and (ii) a hybrid training protocol based on Coordinate-Descent called UpperCaSE that exploits meta-trained CaSE blocks and fine-tuning routines for efficient adaptation. UpperCaSE achieves a new state-of-the-art accuracy relative to meta-learners on the 26 datasets of VTAB+MD and on a challenging real-world personalization benchmark (ORBIT), narrowing the gap with leading fine-tuning methods with the benefit of orders of magnitude lower adaptation cost.
Unfolded Deep Kernel Estimation for Blind Image Super-resolution
Mar 10, 2022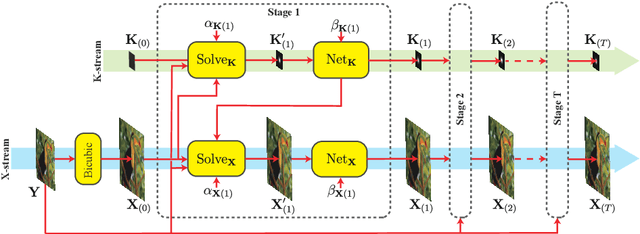
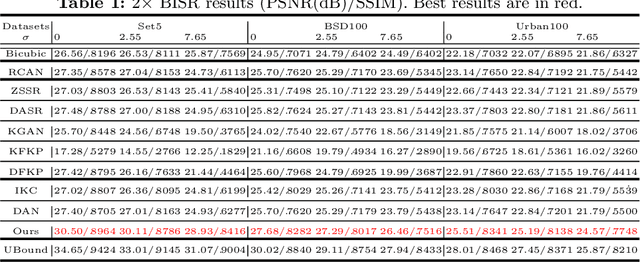

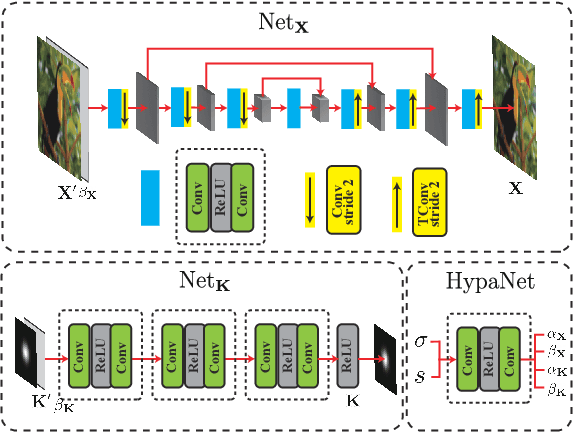
Blind image super-resolution (BISR) aims to reconstruct a high-resolution image from its low-resolution counterpart degraded by unknown blur kernel and noise. Many deep neural network based methods have been proposed to tackle this challenging problem without considering the image degradation model. However, they largely rely on the training sets and often fail to handle images with unseen blur kernels during inference. Deep unfolding methods have also been proposed to perform BISR by utilizing the degradation model. Nonetheless, the existing deep unfolding methods cannot explicitly solve the data term of the unfolding objective function, limiting their capability in blur kernel estimation. In this work, we propose a novel unfolded deep kernel estimation (UDKE) method, which, for the first time to our best knowledge, explicitly solves the data term with high efficiency. The UDKE based BISR method can jointly learn image and kernel priors in an end-to-end manner, and it can effectively exploit the information in both training data and image degradation model. Experiments on benchmark datasets and real-world data demonstrate that the proposed UDKE method could well predict complex unseen non-Gaussian blur kernels in inference, achieving significantly better BISR performance than state-of-the-art. The source code of UDKE is available at: https://github.com/natezhenghy/UDKE.
Dual-Stream Transformer with Cross-Attention on Whole-Slide Image Pyramids for Cancer Prognosis
Jun 22, 2022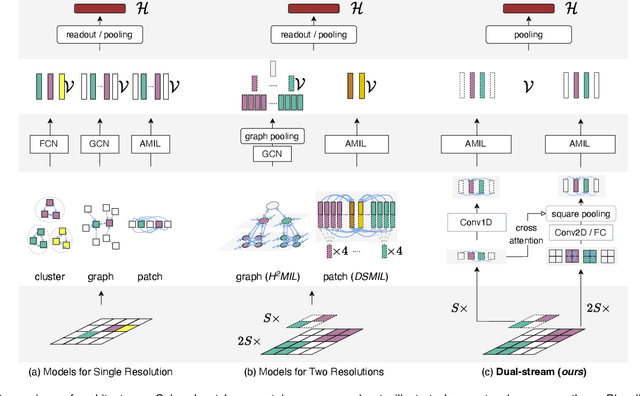
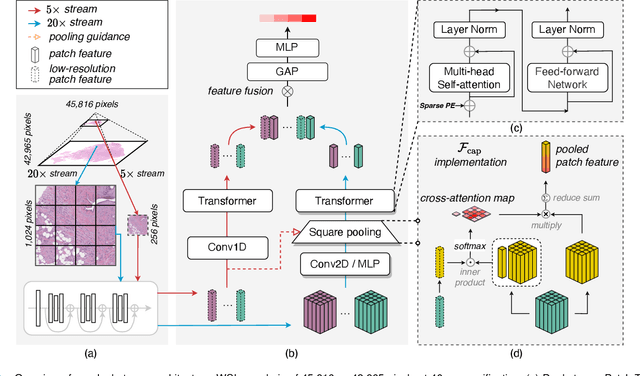
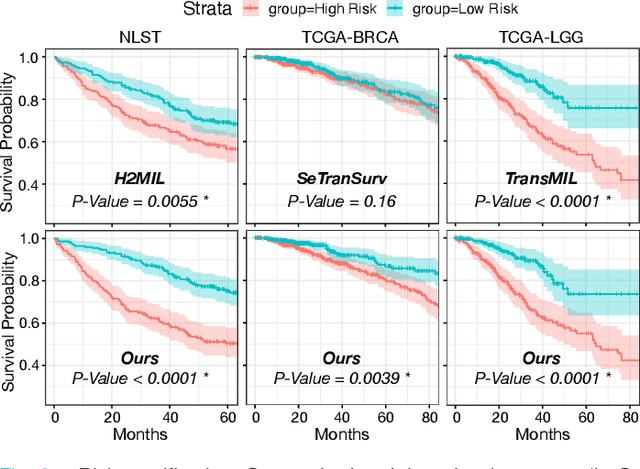
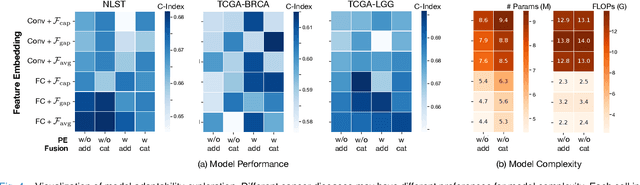
The cancer prognosis on gigapixel Whole-Slide Images (WSIs) has always been a challenging task. Most existing approaches focus solely on single-resolution images. The multi-resolution schemes, utilizing image pyramids to enhance WSI visual representations, have not yet been paid enough attention to. In order to explore a multi-resolution solution for improving cancer prognosis accuracy, this paper proposes a dual-stream architecture to model WSIs by an image pyramid strategy. This architecture consists of two sub-streams: one for low-resolution WSIs, and the other especially for high-resolution ones. Compared to other approaches, our scheme has three highlights: (i) there exists a one-to-one relation between stream and resolution; (ii) a square pooling layer is added to align the patches from two resolution streams, largely reducing computation cost and enabling a natural stream feature fusion; (iii) a cross-attention-based method is proposed to pool high-resolution patches spatially under the guidance of low-resolution ones. We validate our scheme on three publicly-available datasets with a total number of 3,101 WSIs from 1,911 patients. Experimental results verify that (i) hierarchical dual-stream representation is more effective than single-stream ones for cancer prognosis, gaining an average C-Index rise of 5.0% and 1.8% on a single low-resolution and high-resolution stream, respectively; (ii) our dual-stream scheme could outperform current state-of-the-art ones, by an average C-Index improvement of 5.1%; (iii) the cancer diseases with observable survival differences could have different preferences for model complexity. Our scheme could serve as an alternative tool for further facilitating WSI prognosis research.
Self-supervised Image-specific Prototype Exploration for Weakly Supervised Semantic Segmentation
Mar 06, 2022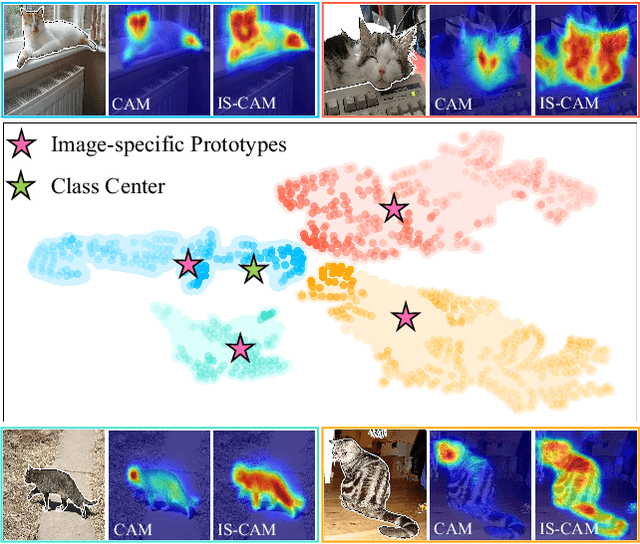
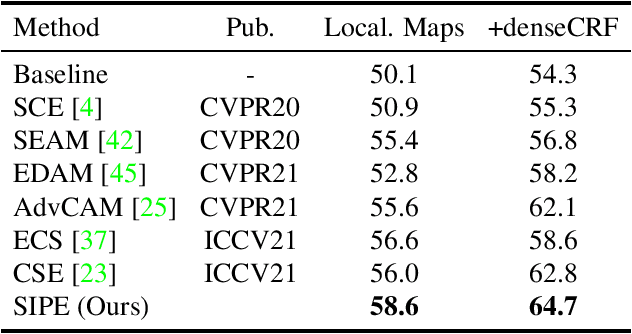
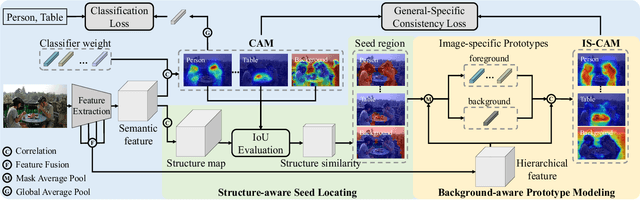
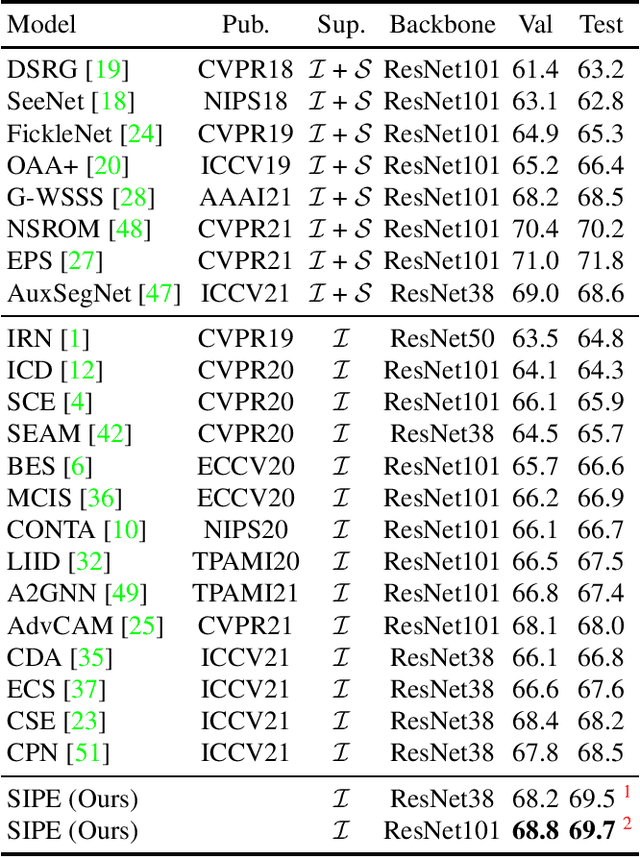
Weakly Supervised Semantic Segmentation (WSSS) based on image-level labels has attracted much attention due to low annotation costs. Existing methods often rely on Class Activation Mapping (CAM) that measures the correlation between image pixels and classifier weight. However, the classifier focuses only on the discriminative regions while ignoring other useful information in each image, resulting in incomplete localization maps. To address this issue, we propose a Self-supervised Image-specific Prototype Exploration (SIPE) that consists of an Image-specific Prototype Exploration (IPE) and a General-Specific Consistency (GSC) loss. Specifically, IPE tailors prototypes for every image to capture complete regions, formed our Image-Specific CAM (IS-CAM), which is realized by two sequential steps. In addition, GSC is proposed to construct the consistency of general CAM and our specific IS-CAM, which further optimizes the feature representation and empowers a self-correction ability of prototype exploration. Extensive experiments are conducted on PASCAL VOC 2012 and MS COCO 2014 segmentation benchmark and results show our SIPE achieves new state-of-the-art performance using only image-level labels. The code is available at https://github.com/chenqi1126/SIPE.
Evidence fusion with contextual discounting for multi-modality medical image segmentation
Jun 23, 2022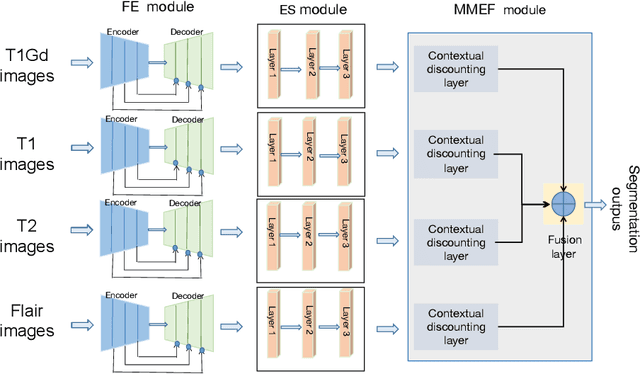
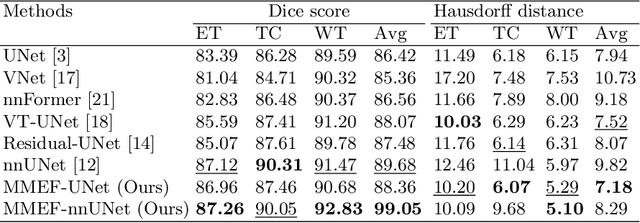
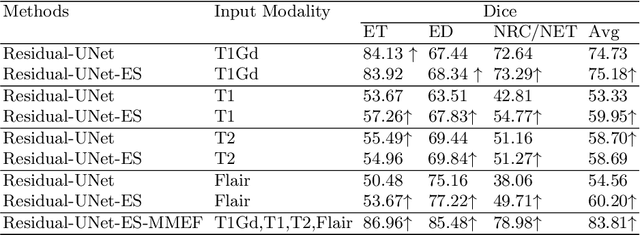
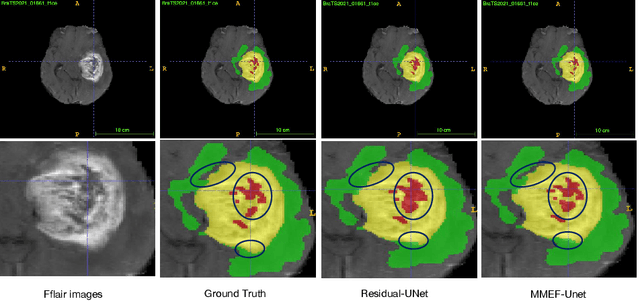
As information sources are usually imperfect, it is necessary to take into account their reliability in multi-source information fusion tasks. In this paper, we propose a new deep framework allowing us to merge multi-MR image segmentation results using the formalism of Dempster-Shafer theory while taking into account the reliability of different modalities relative to different classes. The framework is composed of an encoder-decoder feature extraction module, an evidential segmentation module that computes a belief function at each voxel for each modality, and a multi-modality evidence fusion module, which assigns a vector of discount rates to each modality evidence and combines the discounted evidence using Dempster's rule. The whole framework is trained by minimizing a new loss function based on a discounted Dice index to increase segmentation accuracy and reliability. The method was evaluated on the BraTs 2021 database of 1251 patients with brain tumors. Quantitative and qualitative results show that our method outperforms the state of the art, and implements an effective new idea for merging multi-information within deep neural networks.