 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ASIF: Coupled Data Turns Unimodal Models to Multimodal Without Training
Oct 04, 2022
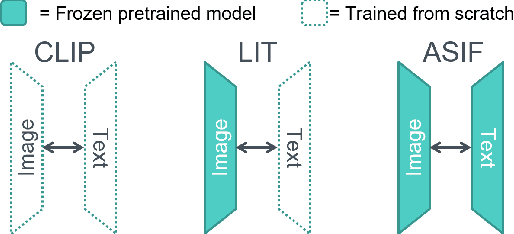
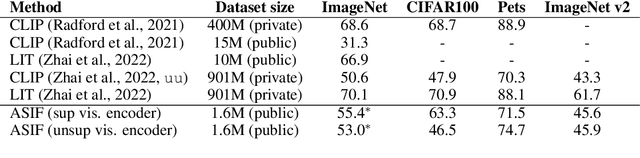
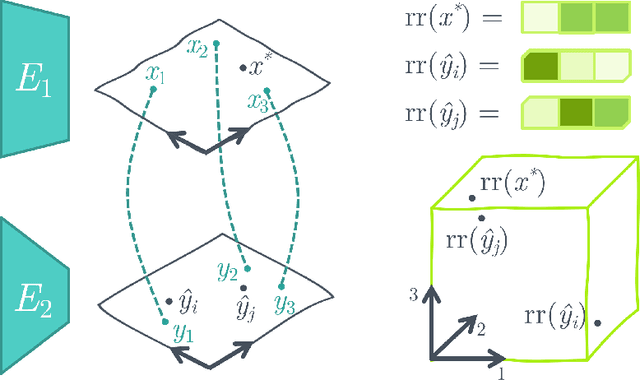
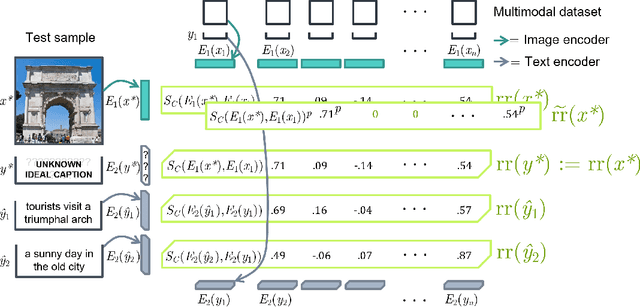
Aligning the visual and language spaces requires to train deep neural networks from scratch on giant multimodal datasets; CLIP trains both an image and a text encoder, while LiT manages to train just the latter by taking advantage of a pretrained vision network. In this paper, we show that sparse relative representations are sufficient to align text and images without training any network. Our method relies on readily available single-domain encoders (trained with or without supervision) and a modest (in comparison) number of image-text pairs. ASIF redefines what constitutes a multimodal model by explicitly disentangling memory from processing: here the model is defined by the embedded pairs of all the entries in the multimodal dataset, in addition to the parameters of the two encoders. Experiments on standard zero-shot visual benchmarks demonstrate the typical transfer ability of image-text models. Overall, our method represents a simple yet surprisingly strong baseline for foundation multimodal models, raising important questions on their data efficiency and on the role of retrieval in machine learning.
UIU-Net: U-Net in U-Net for Infrared Small Object Detection
Dec 02, 2022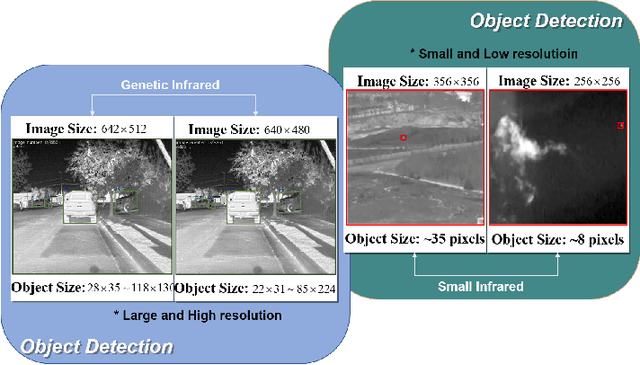
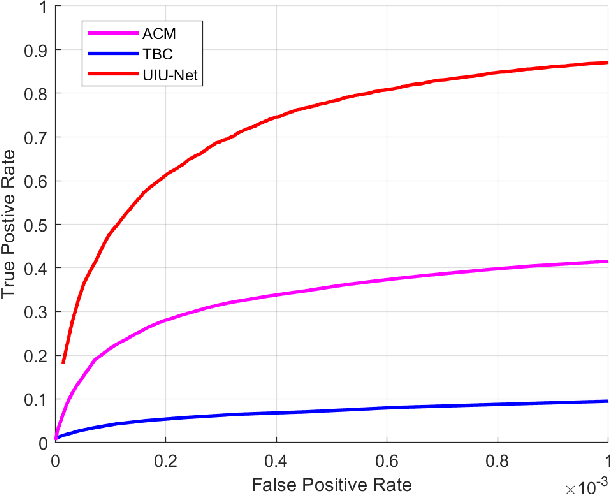
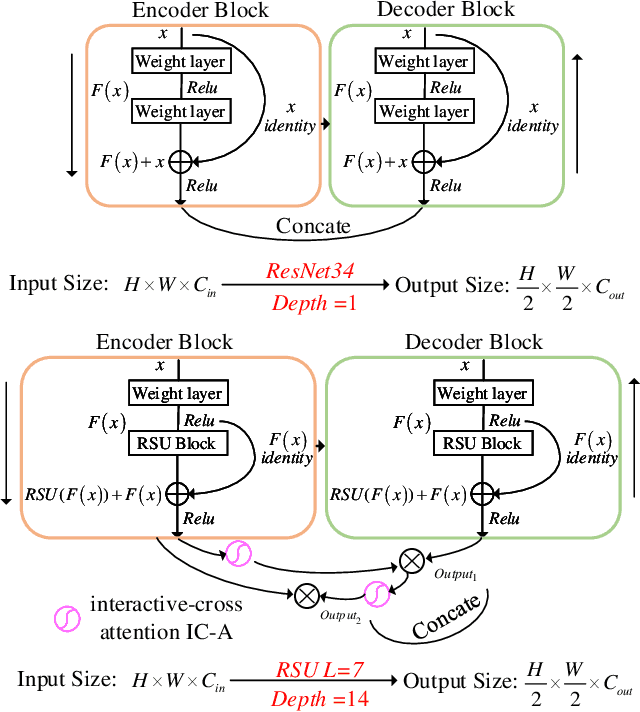
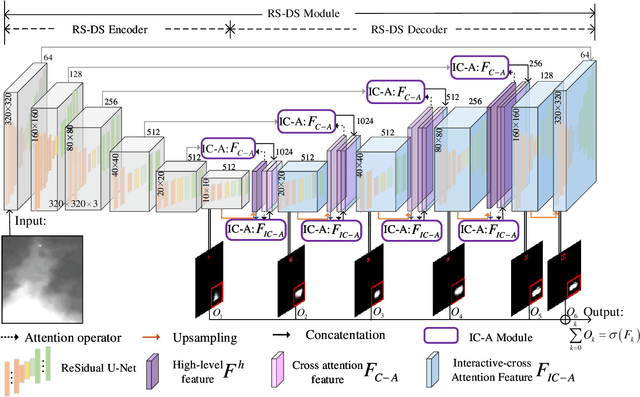
Learning-based infrared small object detection methods currently rely heavily on the classification backbone network. This tends to result in tiny object loss and feature distinguishability limitations as the network depth increases. Furthermore, small objects in infrared images are frequently emerged bright and dark, posing severe demands for obtaining precise object contrast information. For this reason, we in this paper propose a simple and effective ``U-Net in U-Net'' framework, UIU-Net for short, and detect small objects in infrared images. As the name suggests, UIU-Net embeds a tiny U-Net into a larger U-Net backbone, enabling the multi-level and multi-scale representation learning of objects. Moreover, UIU-Net can be trained from scratch, and the learned features can enhance global and local contrast information effectively. More specifically, the UIU-Net model is divided into two modules: the resolution-maintenance deep supervision (RM-DS) module and the interactive-cross attention (IC-A) module. RM-DS integrates Residual U-blocks into a deep supervision network to generate deep multi-scale resolution-maintenance features while learning global context information. Further, IC-A encodes the local context information between the low-level details and high-level semantic features. Extensive experiments conducted on two infrared single-frame image datasets, i.e., SIRST and Synthetic datasets, show the effectiveness and superiority of the proposed UIU-Net in comparison with several state-of-the-art infrared small object detection methods. The proposed UIU-Net also produces powerful generalization performance for video sequence infrared small object datasets, e.g., ATR ground/air video sequence dataset. The codes of this work are available openly at \url{https://github.com/danfenghong/IEEE_TIP_UIU-Net}.
Self Pre-training with Masked Autoencoders for Medical Image Analysis
Mar 10, 2022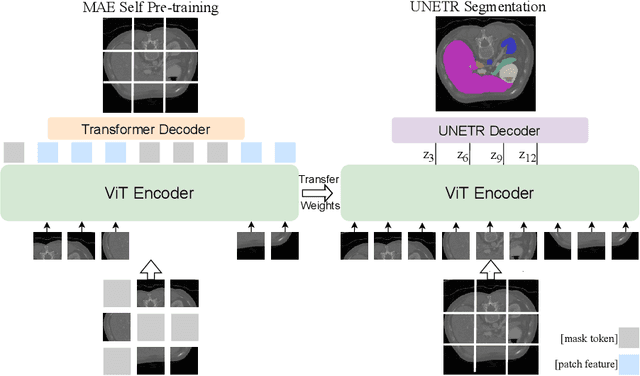
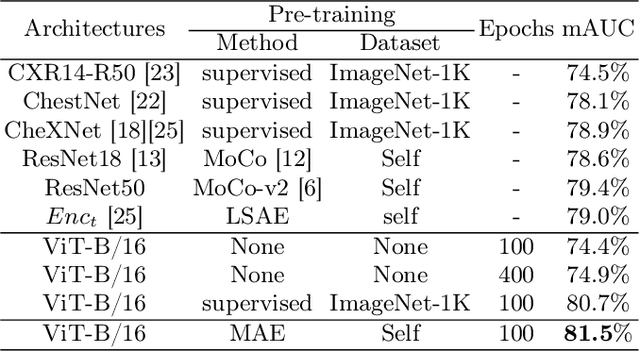
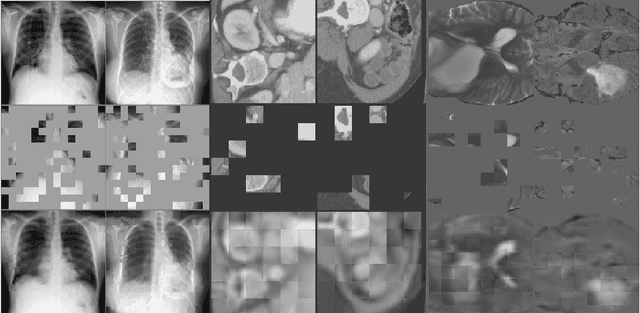
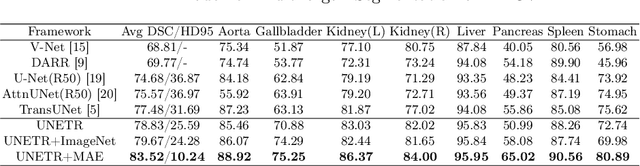
Masked Autoencoder (MAE) has recently been shown to be effective in pre-training Vision Transformers (ViT) for natural image analysis. By performing the pretext task of reconstructing the original image from only partial observations, the encoder, which is a ViT, is encouraged to aggregate contextual information to infer content in masked image regions. We believe that this context aggregation ability is also essential to the medical image domain where each anatomical structure is functionally and mechanically connected to other structures and regions. However, there is no ImageNet-scale medical image dataset for pre-training. Thus, in this paper, we investigate a self pre-training paradigm with MAE for medical images, i.e., models are pre-trained on the same target dataset. To validate the MAE self pre-training, we consider three diverse medical image tasks including chest X-ray disease classification, CT abdomen multi-organ segmentation and MRI brain tumor segmentation. It turns out MAE self pre-training benefits all the tasks markedly. Specifically, the mAUC on lung disease classification is increased by 9.4%. The average DSC on brain tumor segmentation is improved from 77.4% to 78.9%. Most interestingly, on the small-scale multi-organ segmentation dataset (N=30), the average DSC improves from 78.8% to 83.5% and the HD95 is reduced by 60%, indicating its effectiveness in limited data scenarios. The segmentation and classification results reveal the promising potential of MAE self pre-training for medical image analysis.
An Unpaired Cross-modality Segmentation Framework Using Data Augmentation and Hybrid Convolutional Networks for Segmenting Vestibular Schwannoma and Cochlea
Nov 28, 2022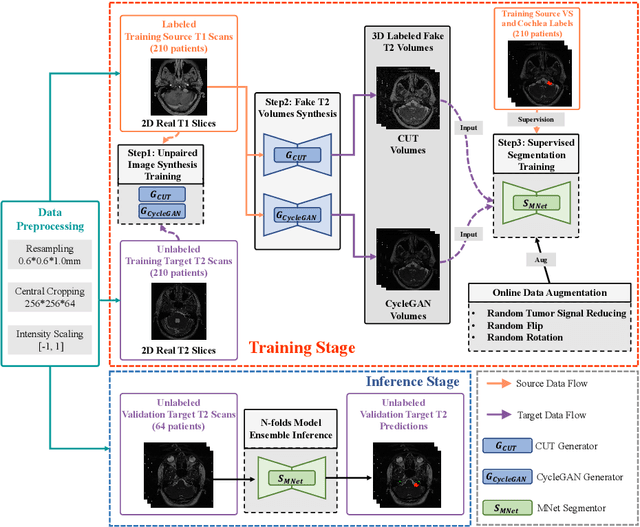
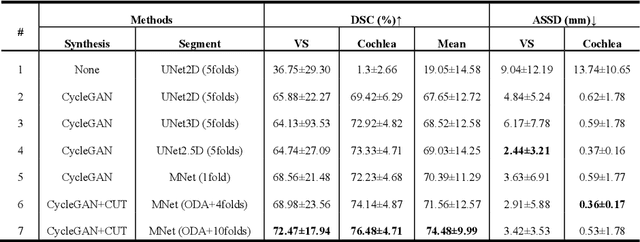
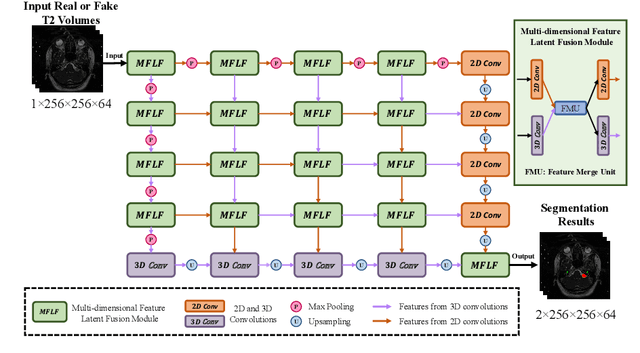
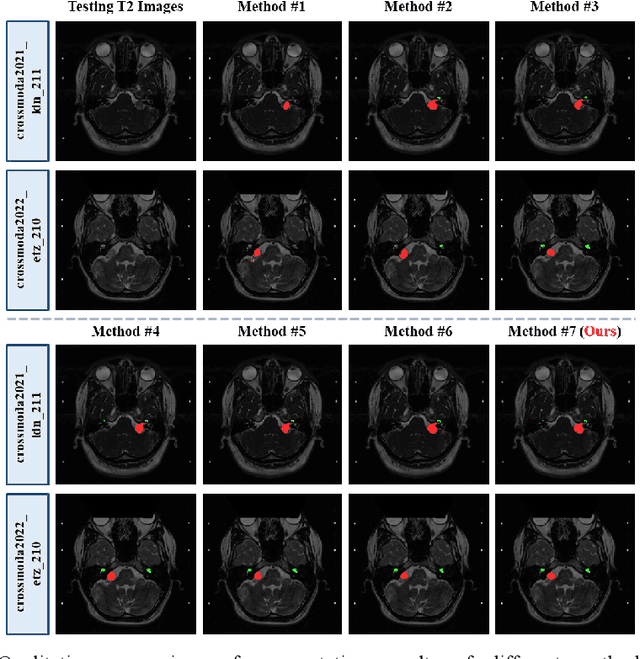
The crossMoDA challenge aims to automatically segment the vestibular schwannoma (VS) tumor and cochlea regions of unlabeled high-resolution T2 scans by leveraging labeled contrast-enhanced T1 scans. The 2022 edition extends the segmentation task by including multi-institutional scans. In this work, we proposed an unpaired cross-modality segmentation framework using data augmentation and hybrid convolutional networks. Considering heterogeneous distributions and various image sizes for multi-institutional scans, we apply the min-max normalization for scaling the intensities of all scans between -1 and 1, and use the voxel size resampling and center cropping to obtain fixed-size sub-volumes for training. We adopt two data augmentation methods for effectively learning the semantic information and generating realistic target domain scans: generative and online data augmentation. For generative data augmentation, we use CUT and CycleGAN to generate two groups of realistic T2 volumes with different details and appearances for supervised segmentation training. For online data augmentation, we design a random tumor signal reducing method for simulating the heterogeneity of VS tumor signals. Furthermore, we utilize an advanced hybrid convolutional network with multi-dimensional convolutions to adaptively learn sparse inter-slice information and dense intra-slice information for accurate volumetric segmentation of VS tumor and cochlea regions in anisotropic scans. On the crossMoDA2022 validation dataset, our method produces promising results and achieves the mean DSC values of 72.47% and 76.48% and ASSD values of 3.42 mm and 0.53 mm for VS tumor and cochlea regions, respectively.
AnimeRun: 2D Animation Visual Correspondence from Open Source 3D Movies
Nov 10, 2022
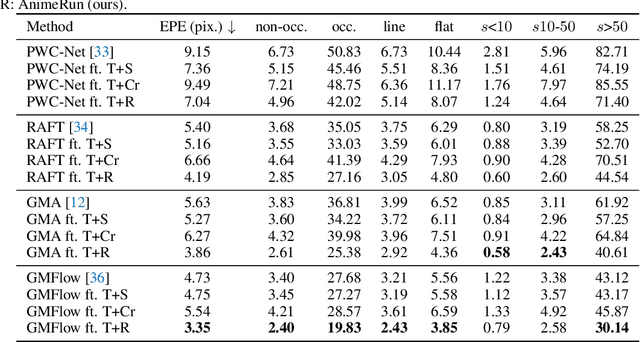

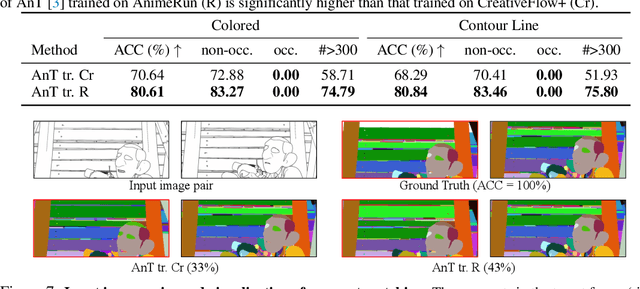
Existing correspondence datasets for two-dimensional (2D) cartoon suffer from simple frame composition and monotonic movements, making them insufficient to simulate real animations. In this work, we present a new 2D animation visual correspondence dataset, AnimeRun, by converting open source three-dimensional (3D) movies to full scenes in 2D style, including simultaneous moving background and interactions of multiple subjects. Our analyses show that the proposed dataset not only resembles real anime more in image composition, but also possesses richer and more complex motion patterns compared to existing datasets. With this dataset, we establish a comprehensive benchmark by evaluating several existing optical flow and segment matching methods, and analyze shortcomings of these methods on animation data. Data, code and other supplementary materials are available at https://lisiyao21.github.io/projects/AnimeRun.
MixUp-MIL: Novel Data Augmentation for Multiple Instance Learning and a Study on Thyroid Cancer Diagnosis
Nov 10, 2022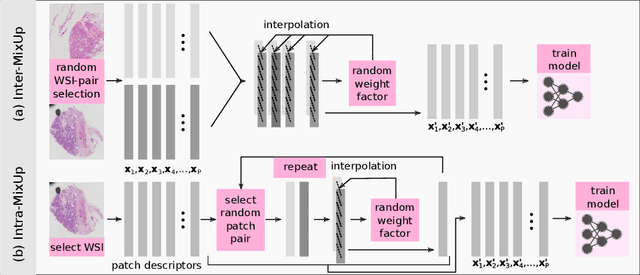
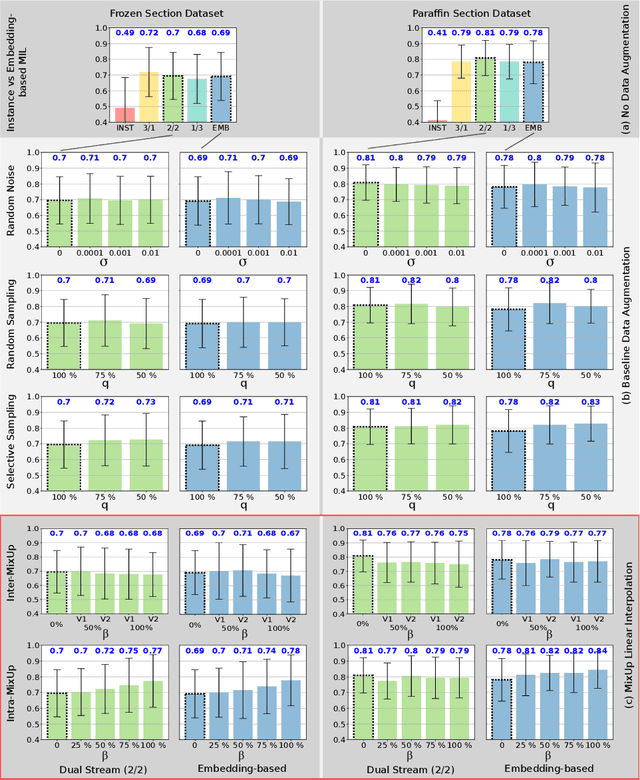
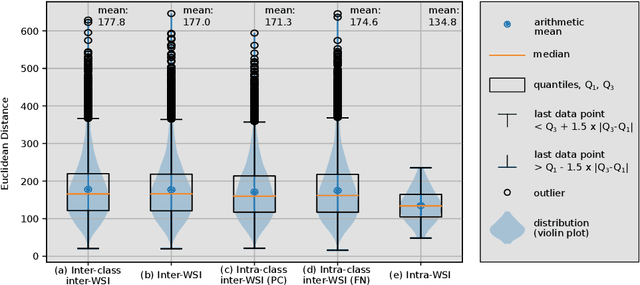
Multiple instance learning exhibits a powerful approach for whole slide image-based diagnosis in the absence of pixel- or patch-level annotations. In spite of the huge size of hole slide images, the number of individual slides is often rather small, leading to a small number of labeled samples. To improve training, we propose and investigate different data augmentation strategies for multiple instance learning based on the idea of linear interpolations of feature vectors (known as MixUp). Based on state-of-the-art multiple instance learning architectures and two thyroid cancer data sets, an exhaustive study is conducted considering a range of common data augmentation strategies. Whereas a strategy based on to the original MixUp approach showed decreases in accuracy, the use of a novel intra-slide interpolation method led to consistent increases in accuracy.
Feedback Chain Network For Hippocampus Segmentation
Nov 15, 2022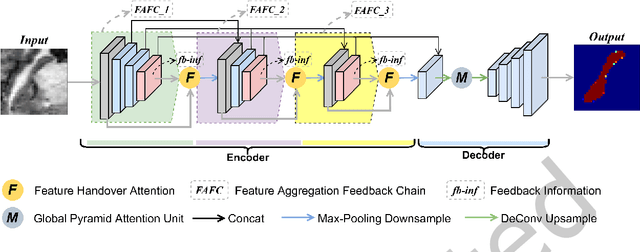
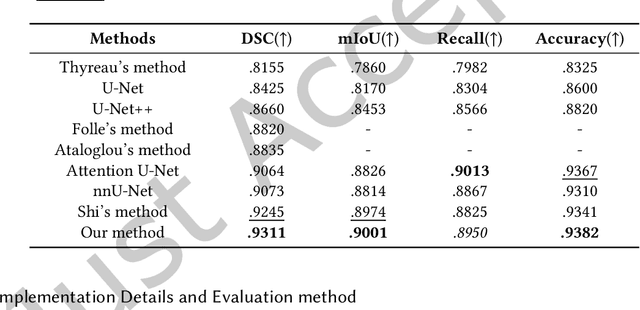
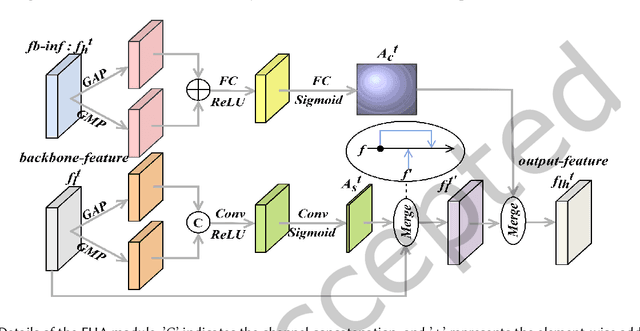
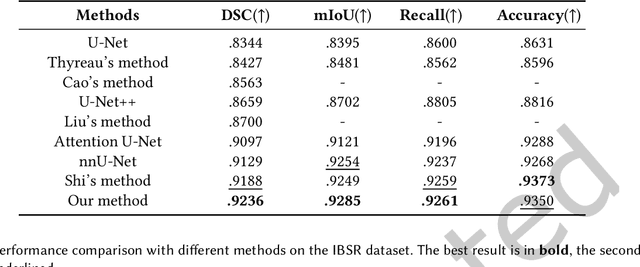
The hippocampus plays a vital role in the diagnosis and treatment of many neurological disorders. Recent years, deep learning technology has made great progress in the field of medical image segmentation, and the performance of related tasks has been constantly refreshed. In this paper, we focus on the hippocampus segmentation task and propose a novel hierarchical feedback chain network. The feedback chain structure unit learns deeper and wider feature representation of each encoder layer through the hierarchical feature aggregation feedback chains, and achieves feature selection and feedback through the feature handover attention module. Then, we embed a global pyramid attention unit between the feature encoder and the decoder to further modify the encoder features, including the pair-wise pyramid attention module for achieving adjacent attention interaction and the global context modeling module for capturing the long-range knowledge. The proposed approach achieves state-of-the-art performance on three publicly available datasets, compared with existing hippocampus segmentation approaches.
CorruptEncoder: Data Poisoning based Backdoor Attacks to Contrastive Learning
Nov 15, 2022
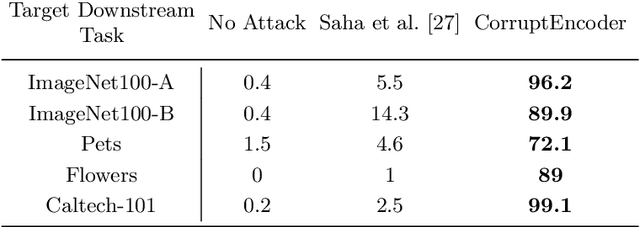
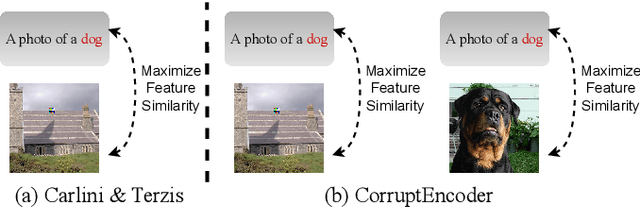
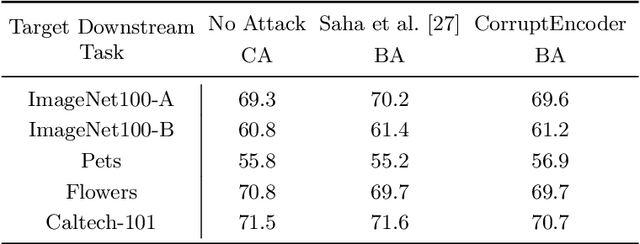
Contrastive learning (CL) pre-trains general-purpose encoders using an unlabeled pre-training dataset, which consists of images (called single-modal CL) or image-text pairs (called multi-modal CL). CL is vulnerable to data poisoning based backdoor attacks (DPBAs), in which an attacker injects poisoned inputs into the pre-training dataset so the encoder is backdoored. However, existing DPBAs achieve limited effectiveness. In this work, we propose new DPBAs called CorruptEncoder to CL. Our experiments show that CorruptEncoder substantially outperforms existing DPBAs for both single-modal and multi-modal CL. CorruptEncoder is the first DPBA that achieves more than 90% attack success rates on single-modal CL with only a few (3) reference images and a small poisoning ratio (0.5%). Moreover, we also propose a defense, called localized cropping, to defend single-modal CL against DPBAs. Our results show that our defense can reduce the effectiveness of DPBAs, but it sacrifices the utility of the encoder, highlighting the needs of new defenses.
Contrastive Losses Are Natural Criteria for Unsupervised Video Summarization
Nov 18, 2022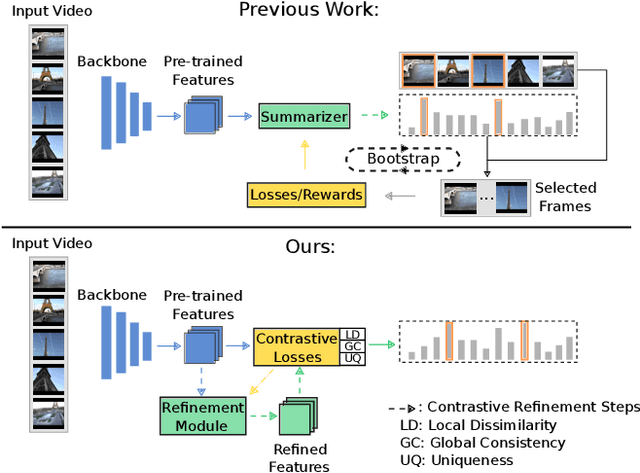
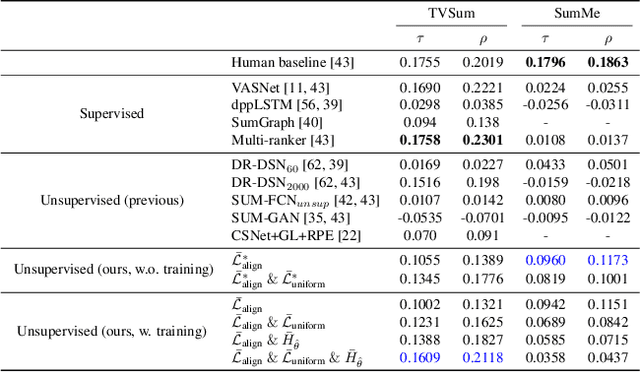

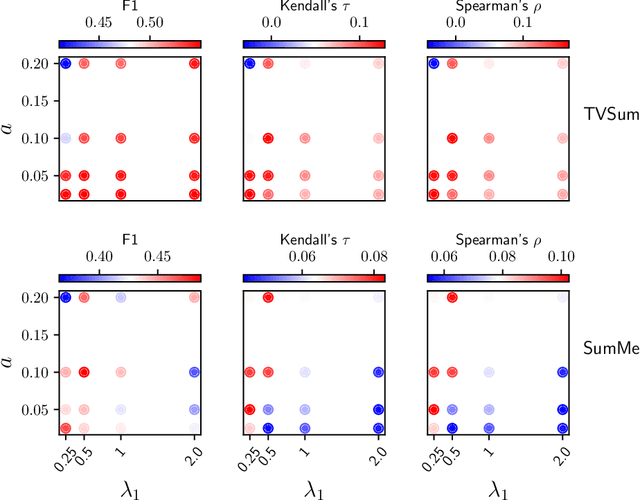
Video summarization aims to select the most informative subset of frames in a video to facilitate efficient video browsing. Unsupervised methods usually rely on heuristic training objectives such as diversity and representativeness. However, such methods need to bootstrap the online-generated summaries to compute the objectives for importance score regression. We consider such a pipeline inefficient and seek to directly quantify the frame-level importance with the help of contrastive losses in the representation learning literature. Leveraging the contrastive losses, we propose three metrics featuring a desirable key frame: local dissimilarity, global consistency, and uniqueness. With features pre-trained on the image classification task, the metrics can already yield high-quality importance scores, demonstrating competitive or better performance than past heavily-trained methods. We show that by refining the pre-trained features with a lightweight contrastively learned projection module, the frame-level importance scores can be further improved, and the model can also leverage a large number of random videos and generalize to test videos with decent performance. Code available at https://github.com/pangzss/pytorch-CTVSUM.
SeaDroneSim: Simulation of Aerial Images for Detection of Objects Above Water
Nov 18, 2022



Unmanned Aerial Vehicles (UAVs) are known for their fast and versatile applicability. With UAVs' growth in availability and applications, they are now of vital importance in serving as technological support in search-and-rescue(SAR) operations in marine environments. High-resolution cameras and GPUs can be equipped on the UAVs to provide effective and efficient aid to emergency rescue operations. With modern computer vision algorithms, we can detect objects for aiming such rescue missions. However, these modern computer vision algorithms are dependent on numerous amounts of training data from UAVs, which is time-consuming and labor-intensive for maritime environments. To this end, we present a new benchmark suite, SeaDroneSim, that can be used to create photo-realistic aerial image datasets with the ground truth for segmentation masks of any given object. Utilizing only the synthetic data generated from SeaDroneSim, we obtain 71 mAP on real aerial images for detecting BlueROV as a feasibility study. This result from the new simulation suit also serves as a baseline for the detection of BlueROV.