 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Equilibrium Approaches to Diffusion Models
Oct 23, 2022
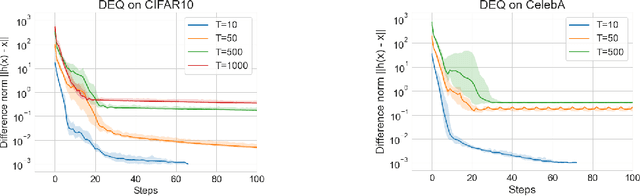
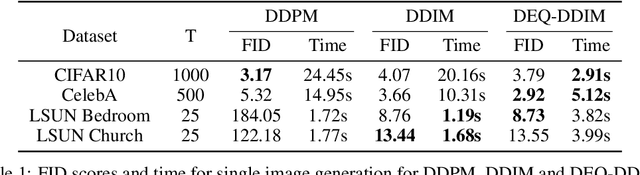

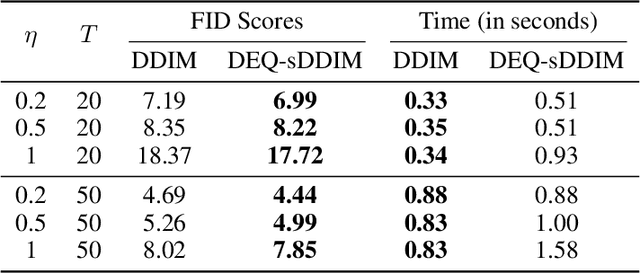
Diffusion-based generative models are extremely effective in generating high-quality images, with generated samples often surpassing the quality of those produced by other models under several metrics. One distinguishing feature of these models, however, is that they typically require long sampling chains to produce high-fidelity images. This presents a challenge not only from the lenses of sampling time, but also from the inherent difficulty in backpropagating through these chains in order to accomplish tasks such as model inversion, i.e. approximately finding latent states that generate known images. In this paper, we look at diffusion models through a different perspective, that of a (deep) equilibrium (DEQ) fixed point model. Specifically, we extend the recent denoising diffusion implicit model (DDIM; Song et al. 2020), and model the entire sampling chain as a joint, multivariate fixed point system. This setup provides an elegant unification of diffusion and equilibrium models, and shows benefits in 1) single image sampling, as it replaces the fully-serial typical sampling process with a parallel one; and 2) model inversion, where we can leverage fast gradients in the DEQ setting to much more quickly find the noise that generates a given image. The approach is also orthogonal and thus complementary to other methods used to reduce the sampling time, or improve model inversion. We demonstrate our method's strong performance across several datasets, including CIFAR10, CelebA, and LSUN Bedrooms and Churches.
Delving into Masked Autoencoders for Multi-Label Thorax Disease Classification
Oct 23, 2022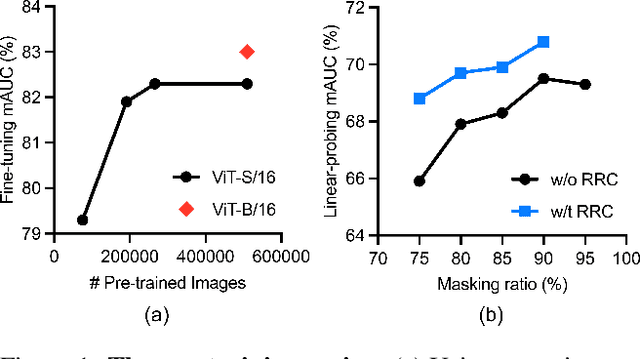
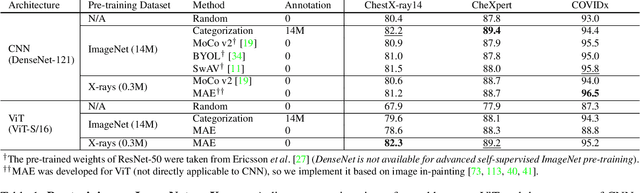

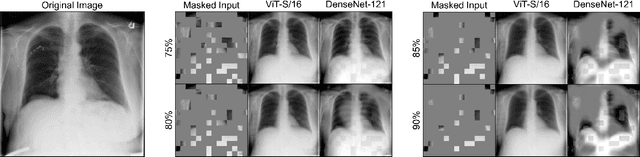
Vision Transformer (ViT) has become one of the most popular neural architectures due to its great scalability, computational efficiency, and compelling performance in many vision tasks. However, ViT has shown inferior performance to Convolutional Neural Network (CNN) on medical tasks due to its data-hungry nature and the lack of annotated medical data. In this paper, we pre-train ViTs on 266,340 chest X-rays using Masked Autoencoders (MAE) which reconstruct missing pixels from a small part of each image. For comparison, CNNs are also pre-trained on the same 266,340 X-rays using advanced self-supervised methods (e.g., MoCo v2). The results show that our pre-trained ViT performs comparably (sometimes better) to the state-of-the-art CNN (DenseNet-121) for multi-label thorax disease classification. This performance is attributed to the strong recipes extracted from our empirical studies for pre-training and fine-tuning ViT. The pre-training recipe signifies that medical reconstruction requires a much smaller proportion of an image (10% vs. 25%) and a more moderate random resized crop range (0.5~1.0 vs. 0.2~1.0) compared with natural imaging. Furthermore, we remark that in-domain transfer learning is preferred whenever possible. The fine-tuning recipe discloses that layer-wise LR decay, RandAug magnitude, and DropPath rate are significant factors to consider. We hope that this study can direct future research on the application of Transformers to a larger variety of medical imaging tasks.
Intra-Source Style Augmentation for Improved Domain Generalization
Oct 18, 2022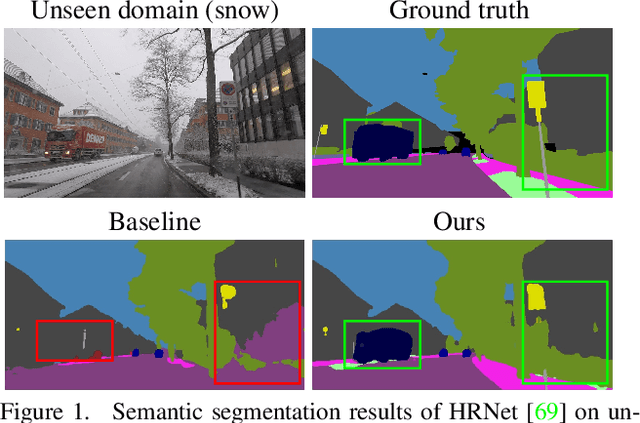
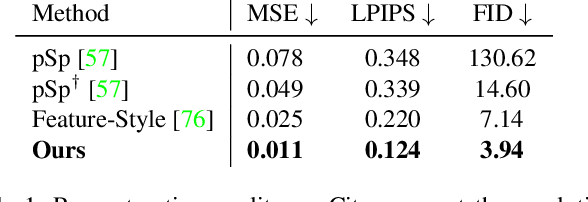

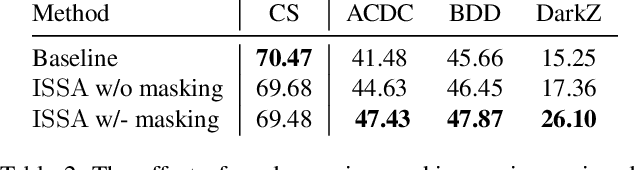
The generalization with respect to domain shifts, as they frequently appear in applications such as autonomous driving, is one of the remaining big challenges for deep learning models. Therefore, we propose an intra-source style augmentation (ISSA) method to improve domain generalization in semantic segmentation. Our method is based on a novel masked noise encoder for StyleGAN2 inversion. The model learns to faithfully reconstruct the image preserving its semantic layout through noise prediction. Random masking of the estimated noise enables the style mixing capability of our model, i.e. it allows to alter the global appearance without affecting the semantic layout of an image. Using the proposed masked noise encoder to randomize style and content combinations in the training set, ISSA effectively increases the diversity of training data and reduces spurious correlation. As a result, we achieve up to $12.4\%$ mIoU improvements on driving-scene semantic segmentation under different types of data shifts, i.e., changing geographic locations, adverse weather conditions, and day to night. ISSA is model-agnostic and straightforwardly applicable with CNNs and Transformers. It is also complementary to other domain generalization techniques, e.g., it improves the recent state-of-the-art solution RobustNet by $3\%$ mIoU in Cityscapes to Dark Z\"urich.
HistoStarGAN: A Unified Approach to Stain Normalisation, Stain Transfer and Stain Invariant Segmentation in Renal Histopathology
Oct 18, 2022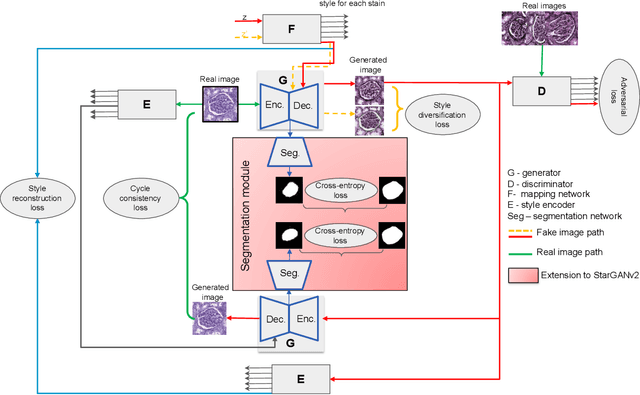
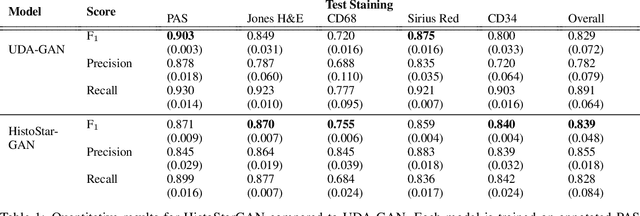
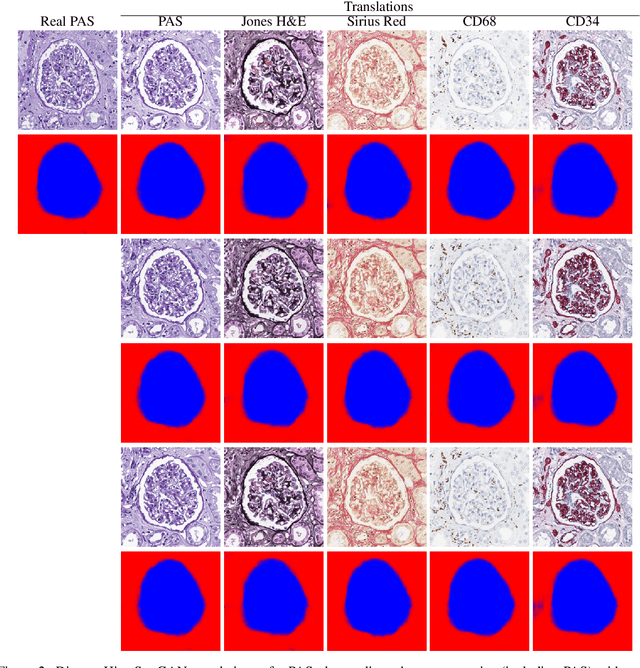
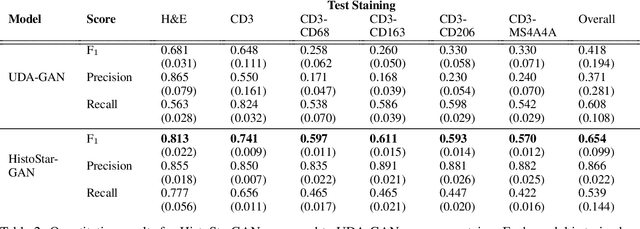
Virtual stain transfer is a promising area of research in Computational Pathology, which has a great potential to alleviate important limitations when applying deeplearningbased solutions such as lack of annotations and sensitivity to a domain shift. However, in the literature, the majority of virtual staining approaches are trained for a specific staining or stain combination, and their extension to unseen stainings requires the acquisition of additional data and training. In this paper, we propose HistoStarGAN, a unified framework that performs stain transfer between multiple stainings, stain normalisation and stain invariant segmentation, all in one inference of the model. We demonstrate the generalisation abilities of the proposed solution to perform diverse stain transfer and accurate stain invariant segmentation over numerous unseen stainings, which is the first such demonstration in the field. Moreover, the pre-trained HistoStar-GAN model can serve as a synthetic data generator, which paves the way for the use of fully annotated synthetic image data to improve the training of deep learning-based algorithms. To illustrate the capabilities of our approach, as well as the potential risks in the microscopy domain, inspired by applications in natural images, we generated KidneyArtPathology, a fully annotated artificial image dataset for renal pathology.
Attacking Object Detector Using A Universal Targeted Label-Switch Patch
Nov 16, 2022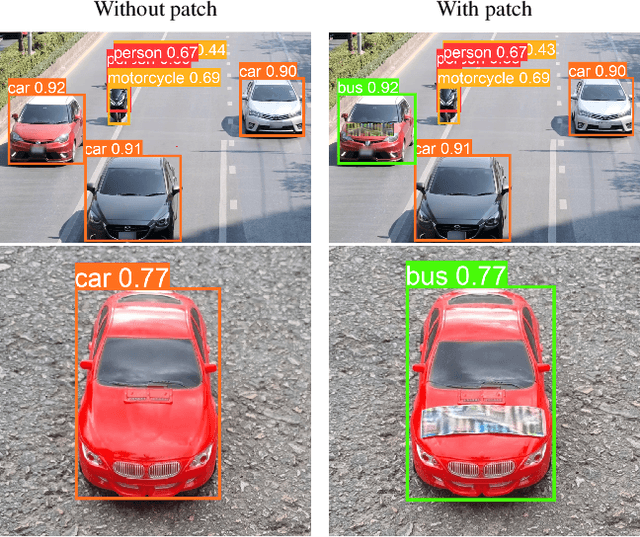
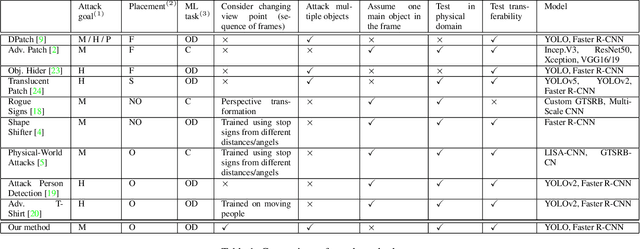
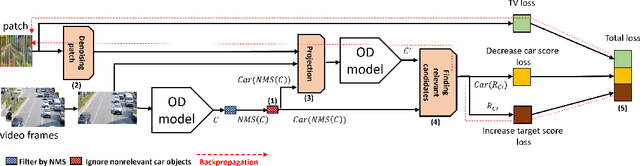

Adversarial attacks against deep learning-based object detectors (ODs) have been studied extensively in the past few years. These attacks cause the model to make incorrect predictions by placing a patch containing an adversarial pattern on the target object or anywhere within the frame. However, none of prior research proposed a misclassification attack on ODs, in which the patch is applied on the target object. In this study, we propose a novel, universal, targeted, label-switch attack against the state-of-the-art object detector, YOLO. In our attack, we use (i) a tailored projection function to enable the placement of the adversarial patch on multiple target objects in the image (e.g., cars), each of which may be located a different distance away from the camera or have a different view angle relative to the camera, and (ii) a unique loss function capable of changing the label of the attacked objects. The proposed universal patch, which is trained in the digital domain, is transferable to the physical domain. We performed an extensive evaluation using different types of object detectors, different video streams captured by different cameras, and various target classes, and evaluated different configurations of the adversarial patch in the physical domain.
Shrinking unit: a Graph Convolution-Based Unit for CNN-like 3D Point Cloud Feature Extractors
Sep 26, 2022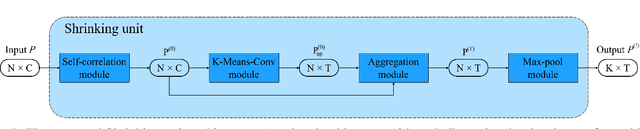

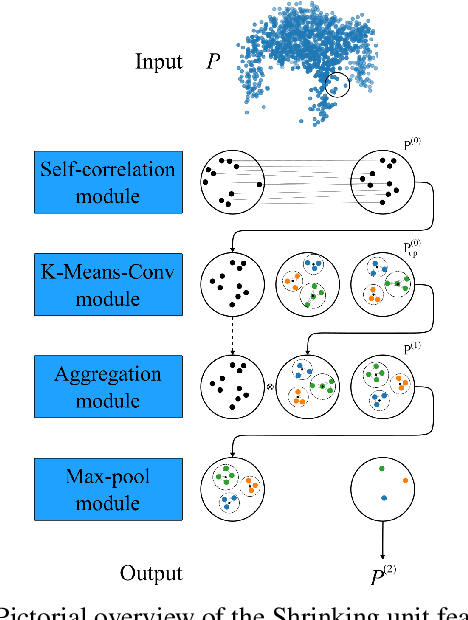
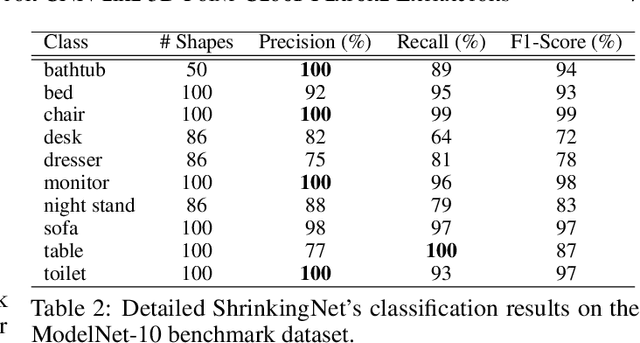
3D point clouds have attracted increasing attention in architecture, engineering, and construction due to their high-quality object representation and efficient acquisition methods. Consequently, many point cloud feature detection methods have been proposed in the literature to automate some workflows, such as their classification or part segmentation. Nevertheless, the performance of point cloud automated systems significantly lags behind their image counterparts. While part of this failure stems from the irregularity, unstructuredness, and disorder of point clouds, which makes the task of point cloud feature detection significantly more challenging than the image one, we argue that a lack of inspiration from the image domain might be the primary cause of such a gap. Indeed, given the overwhelming success of Convolutional Neural Networks (CNNs) in image feature detection, it seems reasonable to design their point cloud counterparts, but none of the proposed approaches closely resembles them. Specifically, even though many approaches generalise the convolution operation in point clouds, they fail to emulate the CNNs multiple-feature detection and pooling operations. For this reason, we propose a graph convolution-based unit, dubbed Shrinking unit, that can be stacked vertically and horizontally for the design of CNN-like 3D point cloud feature extractors. Given that self, local and global correlations between points in a point cloud convey crucial spatial geometric information, we also leverage them during the feature extraction process. We evaluate our proposal by designing a feature extractor model for the ModelNet-10 benchmark dataset and achieve 90.64% classification accuracy, demonstrating that our innovative idea is effective. Our code is available at github.com/albertotamajo/Shrinking-unit.
Use Classifier as Generator
Sep 10, 2022



Image recognition/classification is a widely studied problem, but its reverse problem, image generation, has drawn much less attention until recently. But the vast majority of current methods for image generation require training/retraining a classifier and/or a generator with certain constraints, which can be hard to achieve. In this paper, we propose a simple approach to directly use a normally trained classifier to generate images. We evaluate our method on MNIST and show that it produces recognizable results for human eyes with limited quality with experiments.
THOR-Net: End-to-end Graformer-based Realistic Two Hands and Object Reconstruction with Self-supervision
Oct 25, 2022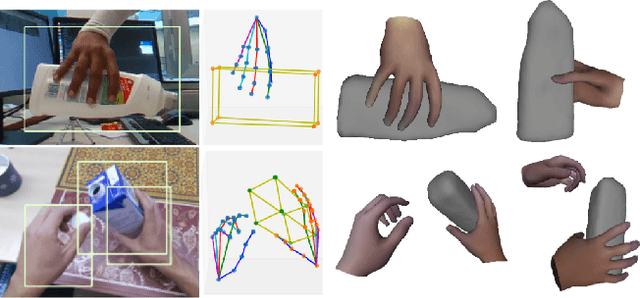
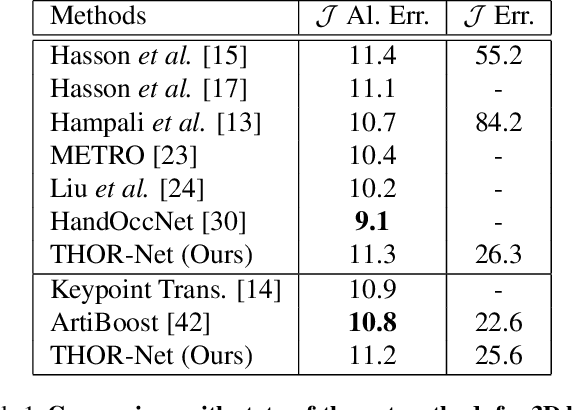
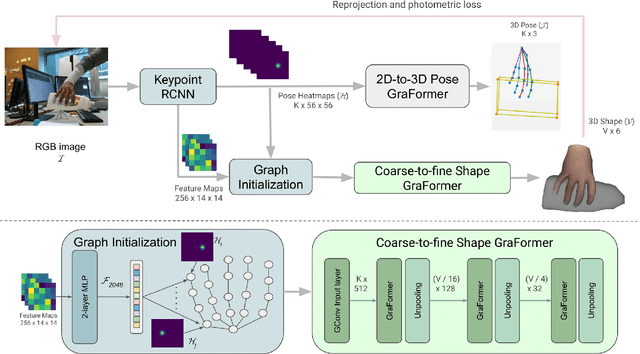
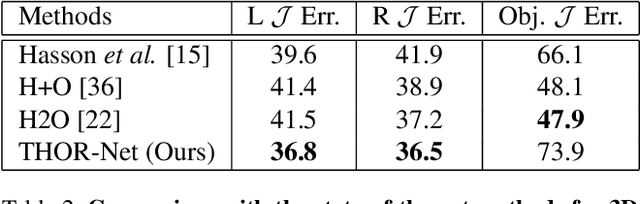
Realistic reconstruction of two hands interacting with objects is a new and challenging problem that is essential for building personalized Virtual and Augmented Reality environments. Graph Convolutional networks (GCNs) allow for the preservation of the topologies of hands poses and shapes by modeling them as a graph. In this work, we propose the THOR-Net which combines the power of GCNs, Transformer, and self-supervision to realistically reconstruct two hands and an object from a single RGB image. Our network comprises two stages; namely the features extraction stage and the reconstruction stage. In the features extraction stage, a Keypoint RCNN is used to extract 2D poses, features maps, heatmaps, and bounding boxes from a monocular RGB image. Thereafter, this 2D information is modeled as two graphs and passed to the two branches of the reconstruction stage. The shape reconstruction branch estimates meshes of two hands and an object using our novel coarse-to-fine GraFormer shape network. The 3D poses of the hands and objects are reconstructed by the other branch using a GraFormer network. Finally, a self-supervised photometric loss is used to directly regress the realistic textured of each vertex in the hands' meshes. Our approach achieves State-of-the-art results in Hand shape estimation on the HO-3D dataset (10.0mm) exceeding ArtiBoost (10.8mm). It also surpasses other methods in hand pose estimation on the challenging two hands and object (H2O) dataset by 5mm on the left-hand pose and 1 mm on the right-hand pose.
Efficient Long-Range Attention Network for Image Super-resolution
Mar 13, 2022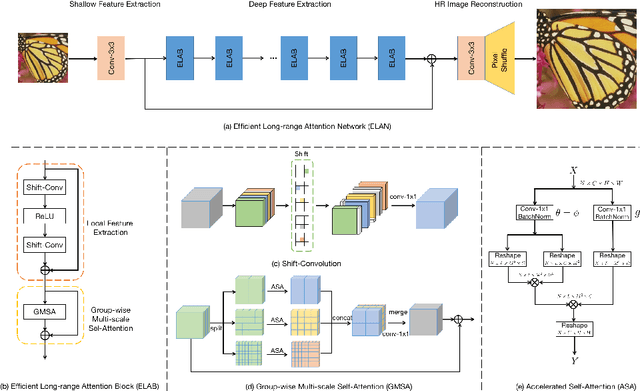
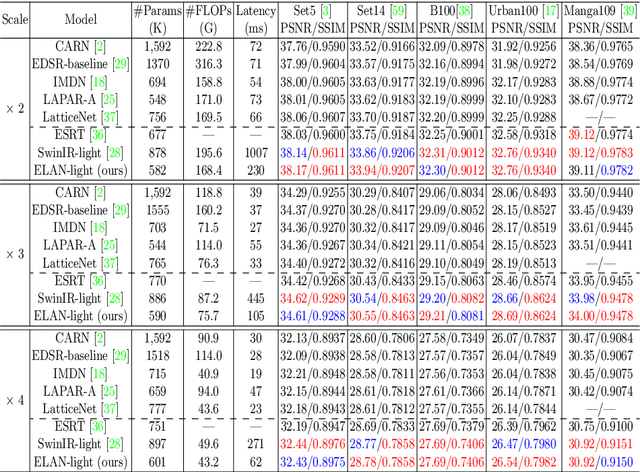
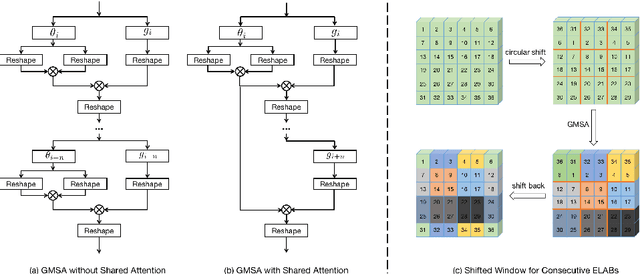
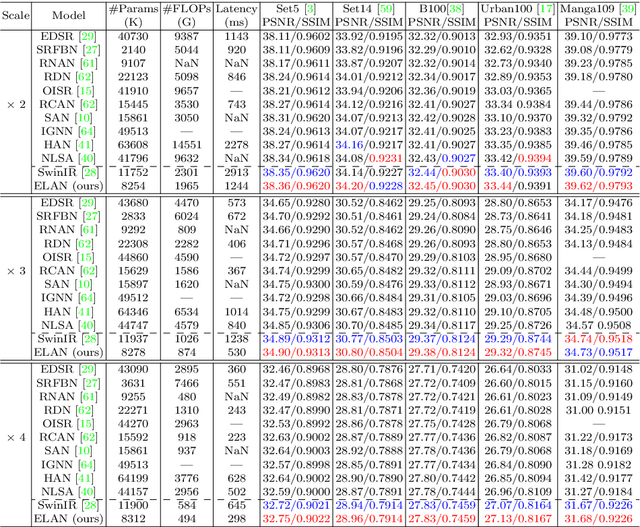
Recently, transformer-based methods have demonstrated impressive results in various vision tasks, including image super-resolution (SR), by exploiting the self-attention (SA) for feature extraction. However, the computation of SA in most existing transformer based models is very expensive, while some employed operations may be redundant for the SR task. This limits the range of SA computation and consequently the SR performance. In this work, we propose an efficient long-range attention network (ELAN) for image SR. Specifically, we first employ shift convolution (shift-conv) to effectively extract the image local structural information while maintaining the same level of complexity as 1x1 convolution, then propose a group-wise multi-scale self-attention (GMSA) module, which calculates SA on non-overlapped groups of features using different window sizes to exploit the long-range image dependency. A highly efficient long-range attention block (ELAB) is then built by simply cascading two shift-conv with a GMSA module, which is further accelerated by using a shared attention mechanism. Without bells and whistles, our ELAN follows a fairly simple design by sequentially cascading the ELABs. Extensive experiments demonstrate that ELAN obtains even better results against the transformer-based SR models but with significantly less complexity. The source code can be found at https://github.com/xindongzhang/ELAN.
Green Hierarchical Vision Transformer for Masked Image Modeling
May 26, 2022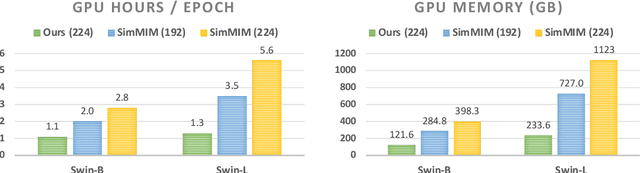
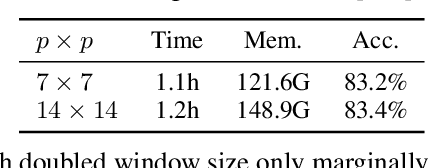
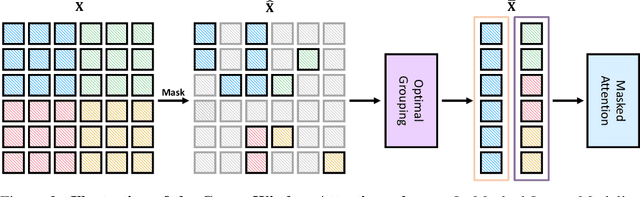
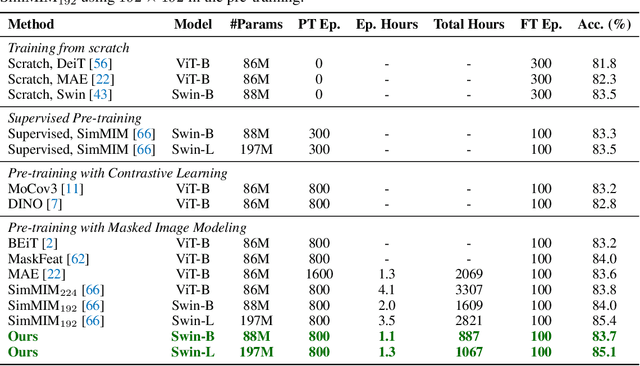
We present an efficient approach for Masked Image Modeling (MIM) with hierarchical Vision Transformers (ViTs), e.g., Swin Transformer, allowing the hierarchical ViTs to discard masked patches and operate only on the visible ones. Our approach consists of two key components. First, for the window attention, we design a Group Window Attention scheme following the Divide-and-Conquer strategy. To mitigate the quadratic complexity of the self-attention w.r.t. the number of patches, group attention encourages a uniform partition that visible patches within each local window of arbitrary size can be grouped with equal size, where masked self-attention is then performed within each group. Second, we further improve the grouping strategy via the Dynamic Programming algorithm to minimize the overall computation cost of the attention on the grouped patches. As a result, MIM now can work on hierarchical ViTs in a green and efficient way. For example, we can train the hierarchical ViTs about 2.7$\times$ faster and reduce the GPU memory usage by 70%, while still enjoying competitive performance on ImageNet classification and the superiority on downstream COCO object detection benchmarks. Code and pre-trained models have been made publicly available at https://github.com/LayneH/GreenMIM.