 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Compositional Scene Modeling with Global Object-Centric Representations
Nov 24, 2022
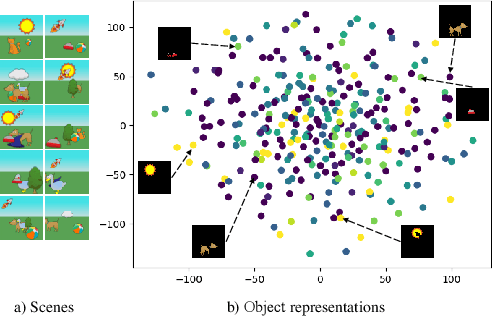
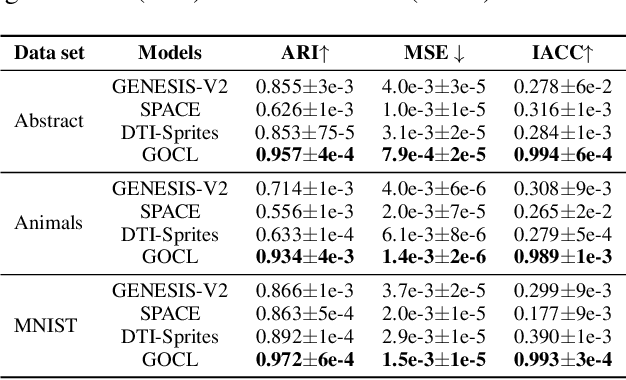
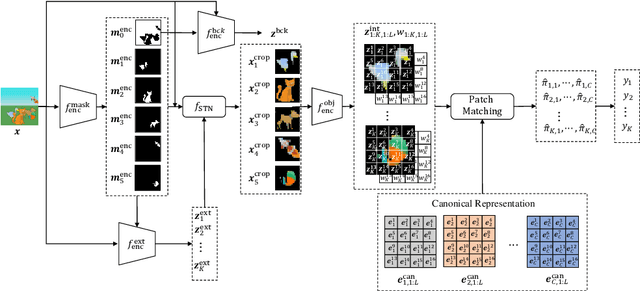
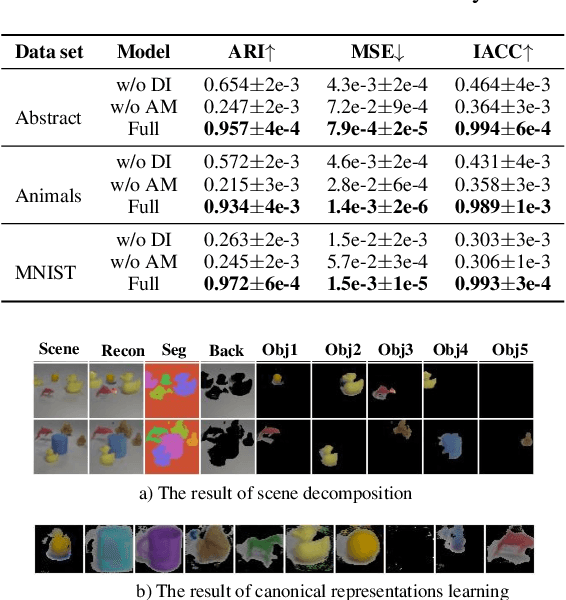
The appearance of the same object may vary in different scene images due to perspectives and occlusions between objects. Humans can easily identify the same object, even if occlusions exist, by completing the occluded parts based on its canonical image in the memory. Achieving this ability is still a challenge for machine learning, especially under the unsupervised learning setting. Inspired by such an ability of humans, this paper proposes a compositional scene modeling method to infer global representations of canonical images of objects without any supervision. The representation of each object is divided into an intrinsic part, which characterizes globally invariant information (i.e. canonical representation of an object), and an extrinsic part, which characterizes scene-dependent information (e.g., position and size). To infer the intrinsic representation of each object, we employ a patch-matching strategy to align the representation of a potentially occluded object with the canonical representations of objects, and sample the most probable canonical representation based on the category of object determined by amortized variational inference. Extensive experiments are conducted on four object-centric learning benchmarks, and experimental results demonstrate that the proposed method not only outperforms state-of-the-arts in terms of segmentation and reconstruction, but also achieves good global object identification performance.
Detecting Anomalies using Generative Adversarial Networks on Images
Nov 24, 2022

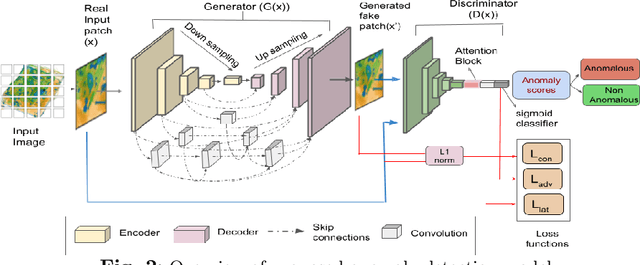
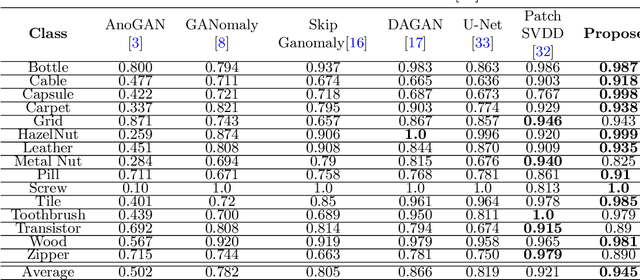
Automatic detection of anomalies such as weapons or threat objects in baggage security, or detecting impaired items in industrial production is an important computer vision task demanding high efficiency and accuracy. Most of the available data in the anomaly detection task is imbalanced as the number of positive/anomalous instances is sparse. Inadequate availability of the data makes training of a deep neural network architecture for anomaly detection challenging. This paper proposes a novel Generative Adversarial Network (GAN) based model for anomaly detection. It uses normal (non-anomalous) images to learn about the normality based on which it detects if an input image contains an anomalous/threat object. The proposed model uses a generator with an encoder-decoder network having dense convolutional skip connections for enhanced reconstruction and to capture the data distribution. A self-attention augmented discriminator is used having the ability to check the consistency of detailed features even in distant portions. We use spectral normalisation to facilitate stable and improved training of the GAN. Experiments are performed on three datasets, viz. CIFAR-10, MVTec AD (for industrial applications) and SIXray (for X-ray baggage security). On the MVTec AD and SIXray datasets, our model achieves an improvement of upto 21% and 4.6%, respectively
Shortcut Removal for Improved OOD-Generalization
Nov 24, 2022


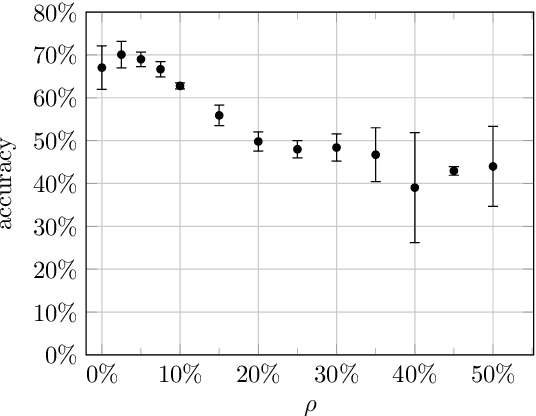
Machine learning is a data-driven discipline, and learning success is largely dependent on the quality of the underlying data sets. However, it is becoming increasingly clear that even high performance on held-out test data does not necessarily mean that a model generalizes or learns anything meaningful at all. One reason for this is the presence of machine learning shortcuts, i.e., hints in the data that are predictive but accidental and semantically unconnected to the problem. We present a new approach to detect such shortcuts and a technique to automatically remove them from datasets. Using an adversarially trained lens, any small and highly predictive clues in images can be detected and removed. We show that this approach 1) does not cause degradation of model performance in the absence of these shortcuts, and 2) reliably identifies and neutralizes shortcuts from different image datasets. In our experiments, we are able to recover up to 93,8% of model performance in the presence of different shortcuts. Finally, we apply our model to a real-world dataset from the medical domain consisting of chest x-rays and identify and remove several types of shortcuts that are known to hinder real-world applicability. Thus, we hope that our proposed approach fosters real-world applicability of machine learning.
Multi-Task Learning of Object State Changes from Uncurated Videos
Nov 24, 2022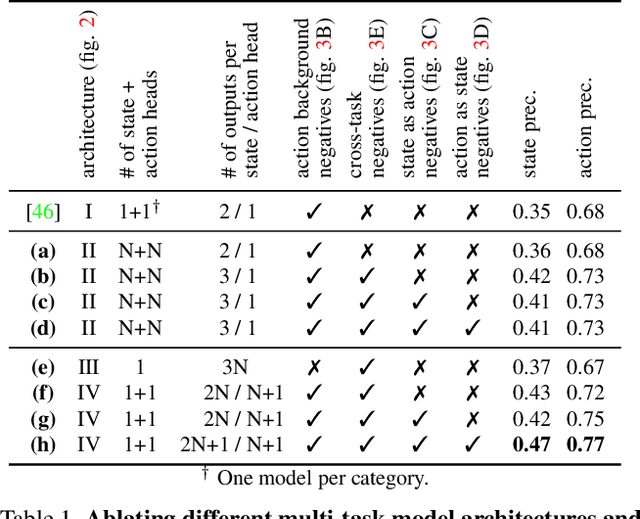
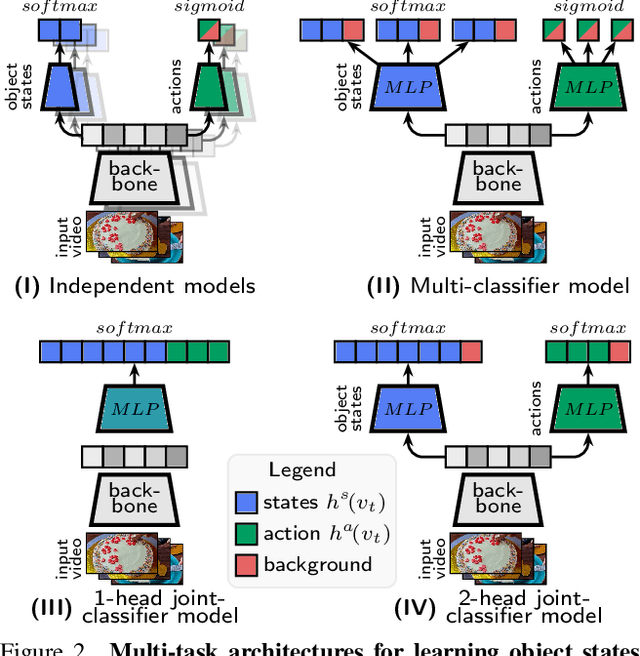
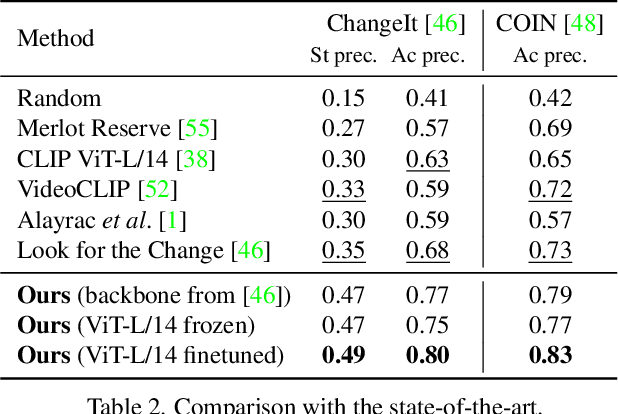
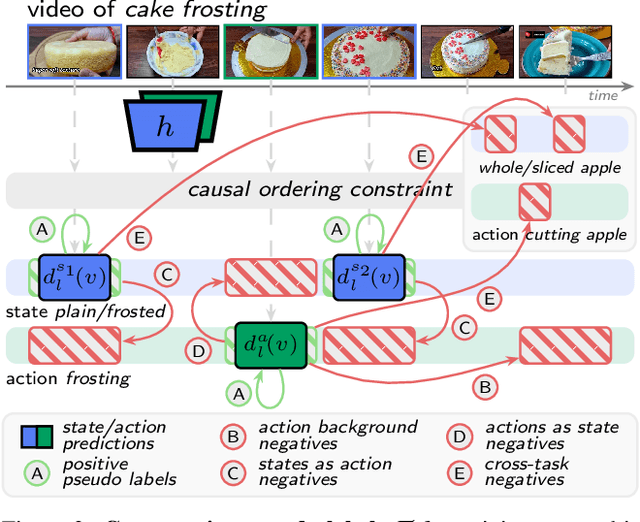
We aim to learn to temporally localize object state changes and the corresponding state-modifying actions by observing people interacting with objects in long uncurated web videos. We introduce three principal contributions. First, we explore alternative multi-task network architectures and identify a model that enables efficient joint learning of multiple object states and actions such as pouring water and pouring coffee. Second, we design a multi-task self-supervised learning procedure that exploits different types of constraints between objects and state-modifying actions enabling end-to-end training of a model for temporal localization of object states and actions in videos from only noisy video-level supervision. Third, we report results on the large-scale ChangeIt and COIN datasets containing tens of thousands of long (un)curated web videos depicting various interactions such as hole drilling, cream whisking, or paper plane folding. We show that our multi-task model achieves a relative improvement of 40% over the prior single-task methods and significantly outperforms both image-based and video-based zero-shot models for this problem. We also test our method on long egocentric videos of the EPIC-KITCHENS and the Ego4D datasets in a zero-shot setup demonstrating the robustness of our learned model.
Pose-disentangled Contrastive Learning for Self-supervised Facial Representation
Nov 24, 2022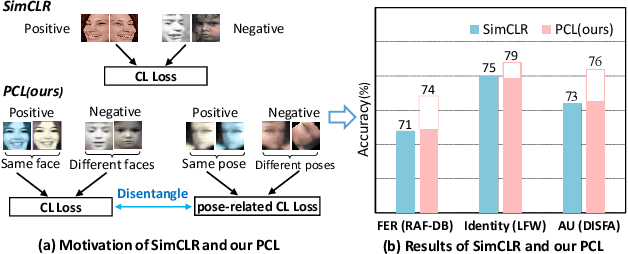
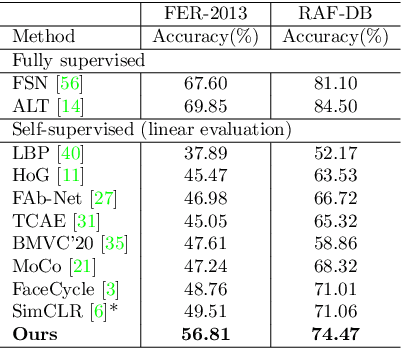
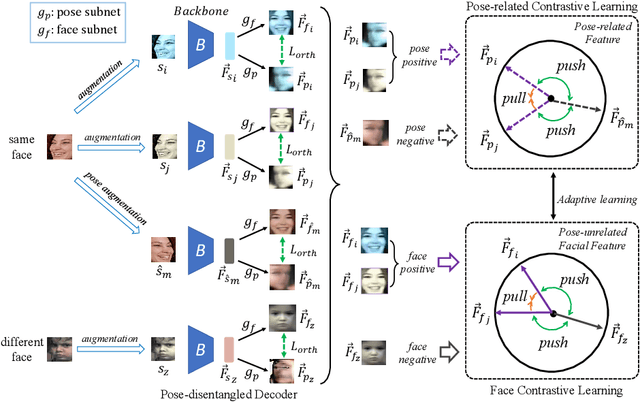
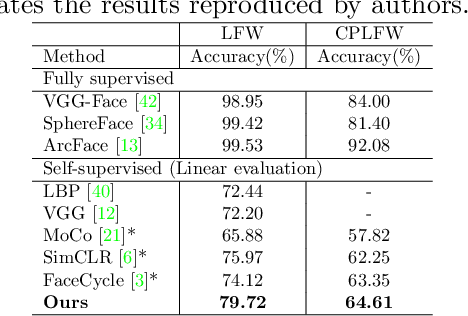
Self-supervised facial representation has recently attracted increasing attention due to its ability to perform face understanding without relying on large-scale annotated datasets heavily. However, analytically, current contrastive-based self-supervised learning still performs unsatisfactorily for learning facial representation. More specifically, existing contrastive learning (CL) tends to learn pose-invariant features that cannot depict the pose details of faces, compromising the learning performance. To conquer the above limitation of CL, we propose a novel Pose-disentangled Contrastive Learning (PCL) method for general self-supervised facial representation. Our PCL first devises a pose-disentangled decoder (PDD) with a delicately designed orthogonalizing regulation, which disentangles the pose-related features from the face-aware features; therefore, pose-related and other pose-unrelated facial information could be performed in individual subnetworks and do not affect each other's training. Furthermore, we introduce a pose-related contrastive learning scheme that learns pose-related information based on data augmentation of the same image, which would deliver more effective face-aware representation for various downstream tasks. We conducted a comprehensive linear evaluation on three challenging downstream facial understanding tasks, i.e., facial expression recognition, face recognition, and AU detection. Experimental results demonstrate that our method outperforms cutting-edge contrastive and other self-supervised learning methods with a great margin.
Cross-Modality Knowledge Distillation Network for Monocular 3D Object Detection
Nov 14, 2022Leveraging LiDAR-based detectors or real LiDAR point data to guide monocular 3D detection has brought significant improvement, e.g., Pseudo-LiDAR methods. However, the existing methods usually apply non-end-to-end training strategies and insufficiently leverage the LiDAR information, where the rich potential of the LiDAR data has not been well exploited. In this paper, we propose the Cross-Modality Knowledge Distillation (CMKD) network for monocular 3D detection to efficiently and directly transfer the knowledge from LiDAR modality to image modality on both features and responses. Moreover, we further extend CMKD as a semi-supervised training framework by distilling knowledge from large-scale unlabeled data and significantly boost the performance. Until submission, CMKD ranks $1^{st}$ among the monocular 3D detectors with publications on both KITTI $test$ set and Waymo $val$ set with significant performance gains compared to previous state-of-the-art methods.
APRNet: Attention-based Pixel-wise Rendering Network for Photo-Realistic Text Image Generation
Mar 15, 2022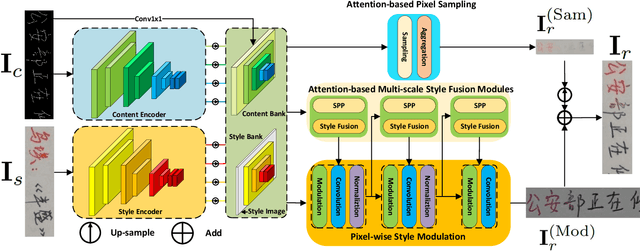

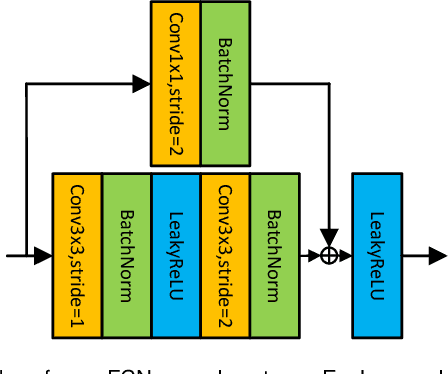
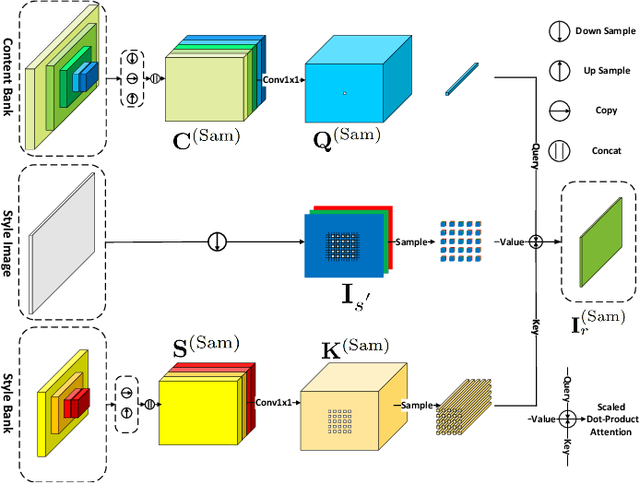
Style-guided text image generation tries to synthesize text image by imitating reference image's appearance while keeping text content unaltered. The text image appearance includes many aspects. In this paper, we focus on transferring style image's background and foreground color patterns to the content image to generate photo-realistic text image. To achieve this goal, we propose 1) a content-style cross attention based pixel sampling approach to roughly mimicking the style text image's background; 2) a pixel-wise style modulation technique to transfer varying color patterns of the style image to the content image spatial-adaptively; 3) a cross attention based multi-scale style fusion approach to solving text foreground misalignment issue between style and content images; 4) an image patch shuffling strategy to create style, content and ground truth image tuples for training. Experimental results on Chinese handwriting text image synthesis with SCUT-HCCDoc and CASIA-OLHWDB datasets demonstrate that the proposed method can improve the quality of synthetic text images and make them more photo-realistic.
Efficient Image Representation Learning with Federated Sampled Softmax
Mar 09, 2022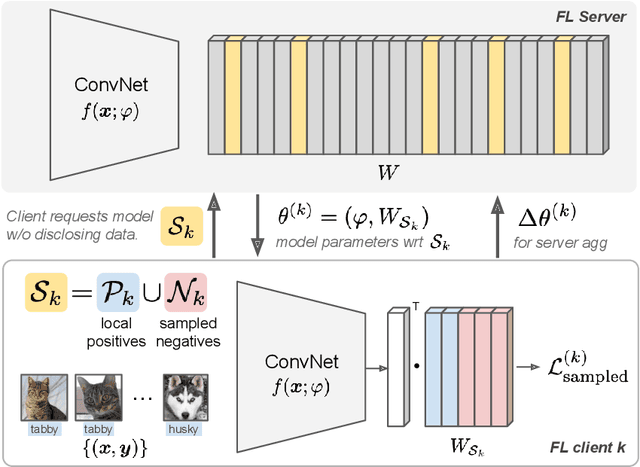
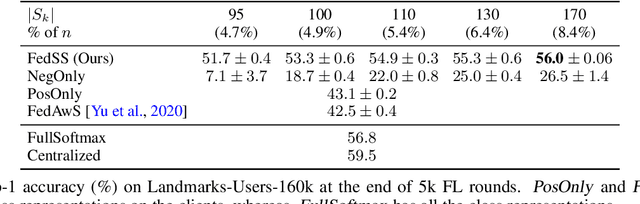
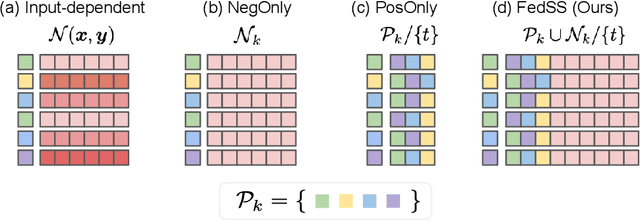
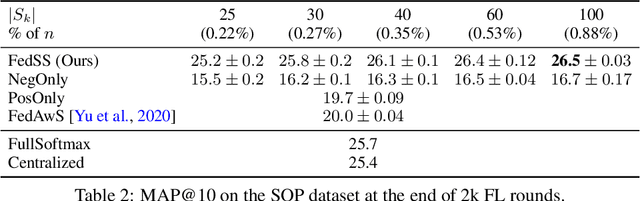
Learning image representations on decentralized data can bring many benefits in cases where data cannot be aggregated across data silos. Softmax cross entropy loss is highly effective and commonly used for learning image representations. Using a large number of classes has proven to be particularly beneficial for the descriptive power of such representations in centralized learning. However, doing so on decentralized data with Federated Learning is not straightforward as the demand on FL clients' computation and communication increases proportionally to the number of classes. In this work we introduce federated sampled softmax (FedSS), a resource-efficient approach for learning image representation with Federated Learning. Specifically, the FL clients sample a set of classes and optimize only the corresponding model parameters with respect to a sampled softmax objective that approximates the global full softmax objective. We examine the loss formulation and empirically show that our method significantly reduces the number of parameters transferred to and optimized by the client devices, while performing on par with the standard full softmax method. This work creates a possibility for efficiently learning image representations on decentralized data with a large number of classes under the federated setting.
Training Semantic Descriptors for Image-Based Localization
Feb 02, 2022Vision based solutions for the localization of vehicles have become popular recently. We employ an image retrieval based visual localization approach. The database images are kept with GPS coordinates and the location of the retrieved database image serves as an approximate position of the query image. We show that localization can be performed via descriptors solely extracted from semantically segmented images. It is reliable especially when the environment is subjected to severe illumination and seasonal changes. Our experiments reveal that the localization performance of a semantic descriptor can increase up to the level of state-of-the-art RGB image based methods.
Data Augmentation using Feature Generation for Volumetric Medical Images
Sep 28, 2022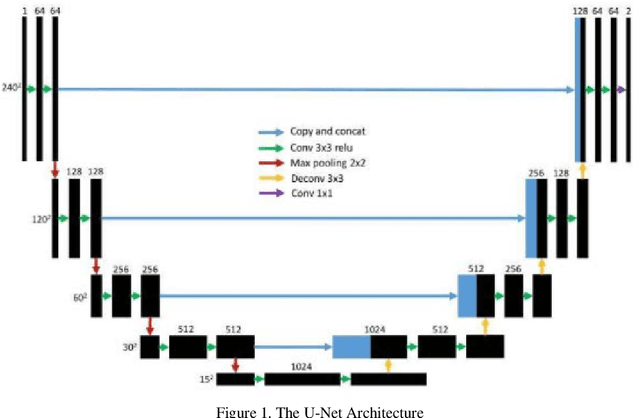
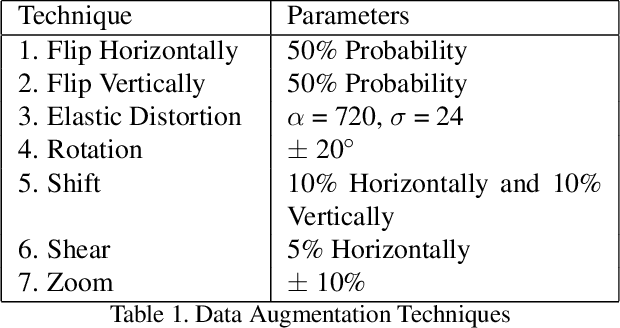
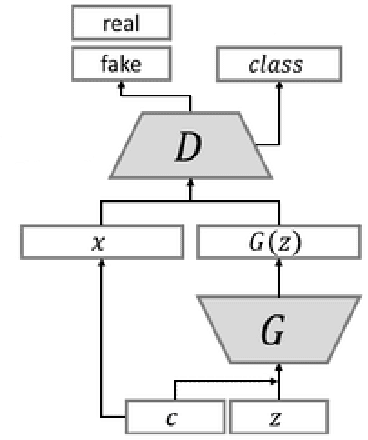
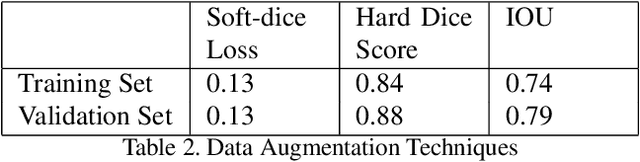
Medical image classification is one of the most critical problems in the image recognition area. One of the major challenges in this field is the scarcity of labelled training data. Additionally, there is often class imbalance in datasets as some cases are very rare to happen. As a result, accuracy in classification task is normally low. Deep Learning models, in particular, show promising results on image segmentation and classification problems, but they require very large datasets for training. Therefore, there is a need to generate more of synthetic samples from the same distribution. Previous work has shown that feature generation is more efficient and leads to better performance than corresponding image generation. We apply this idea in the Medical Imaging domain. We use transfer learning to train a segmentation model for the small dataset for which gold-standard class annotations are available. We extracted the learnt features and use them to generate synthetic features conditioned on class labels, using Auxiliary Classifier GAN (ACGAN). We test the quality of the generated features in a downstream classification task for brain tumors according to their severity level. Experimental results show a promising result regarding the validity of these generated features and their overall contribution to balancing the data and improving the classification class-wise accuracy.