 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Flow Guidance Deformable Compensation Network for Video Frame Interpolation
Nov 22, 2022
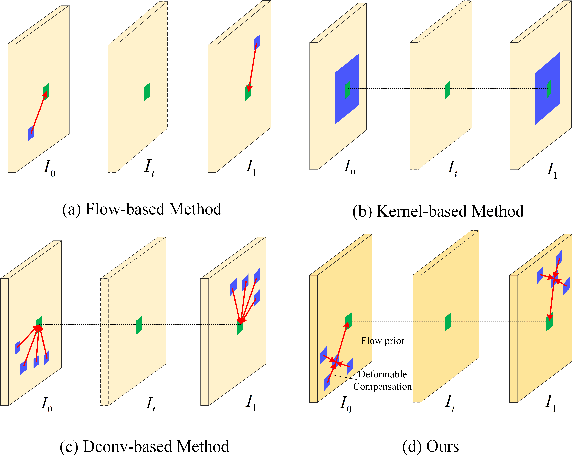

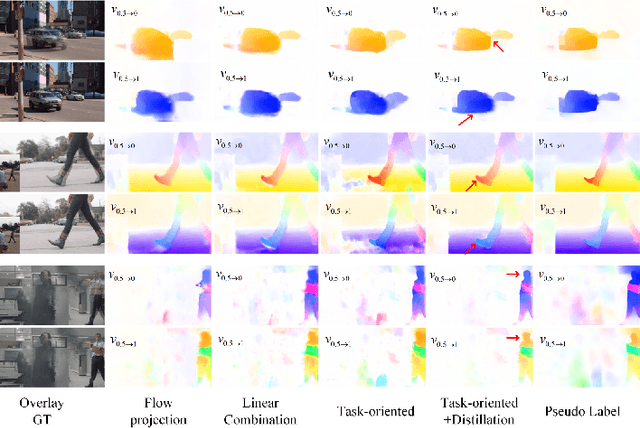

Motion-based video frame interpolation (VFI) methods have made remarkable progress with the development of deep convolutional networks over the past years. While their performance is often jeopardized by the inaccuracy of flow map estimation, especially in the case of large motion and occlusion. In this paper, we propose a flow guidance deformable compensation network (FGDCN) to overcome the drawbacks of existing motion-based methods. FGDCN decomposes the frame sampling process into two steps: a flow step and a deformation step. Specifically, the flow step utilizes a coarse-to-fine flow estimation network to directly estimate the intermediate flows and synthesizes an anchor frame simultaneously. To ensure the accuracy of the estimated flow, a distillation loss and a task-oriented loss are jointly employed in this step. Under the guidance of the flow priors learned in step one, the deformation step designs a pyramid deformable compensation network to compensate for the missing details of the flow step. In addition, a pyramid loss is proposed to supervise the model in both the image and frequency domain. Experimental results show that the proposed algorithm achieves excellent performance on various datasets with fewer parameters.
Progressive Learning with Cross-Window Consistency for Semi-Supervised Semantic Segmentation
Nov 22, 2022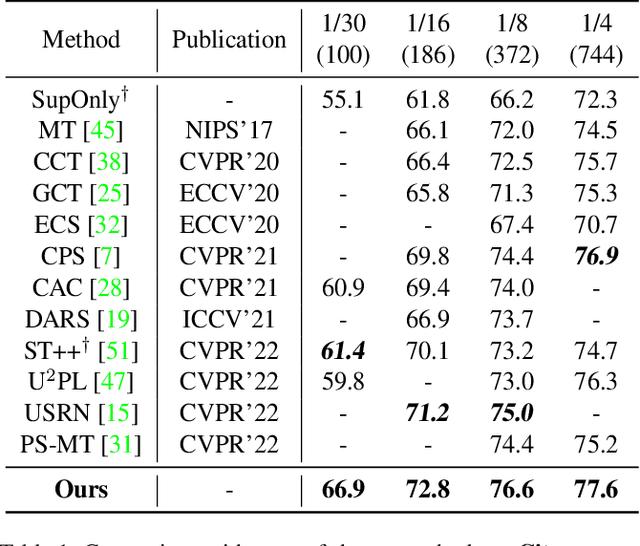
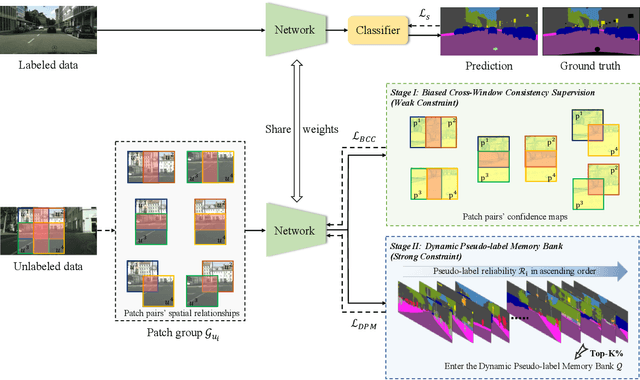
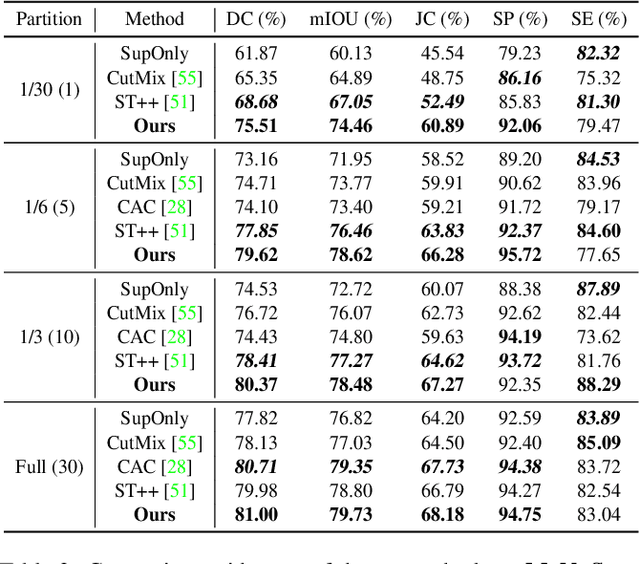
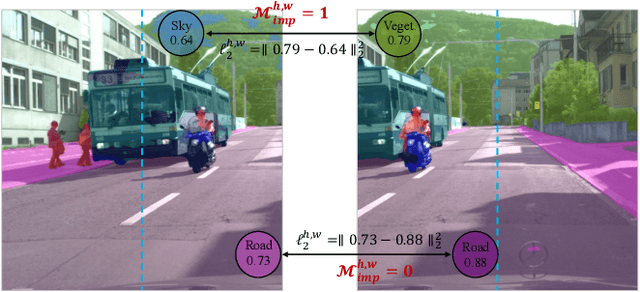
Semi-supervised semantic segmentation focuses on the exploration of a small amount of labeled data and a large amount of unlabeled data, which is more in line with the demands of real-world image understanding applications. However, it is still hindered by the inability to fully and effectively leverage unlabeled images. In this paper, we reveal that cross-window consistency (CWC) is helpful in comprehensively extracting auxiliary supervision from unlabeled data. Additionally, we propose a novel CWC-driven progressive learning framework to optimize the deep network by mining weak-to-strong constraints from massive unlabeled data. More specifically, this paper presents a biased cross-window consistency (BCC) loss with an importance factor, which helps the deep network explicitly constrain confidence maps from overlapping regions in different windows to maintain semantic consistency with larger contexts. In addition, we propose a dynamic pseudo-label memory bank (DPM) to provide high-consistency and high-reliability pseudo-labels to further optimize the network. Extensive experiments on three representative datasets of urban views, medical scenarios, and satellite scenes demonstrate our framework consistently outperforms the state-of-the-art methods with a large margin. Code will be available publicly.
Building Resilience to Out-of-Distribution Visual Data via Input Optimization and Model Finetuning
Nov 29, 2022

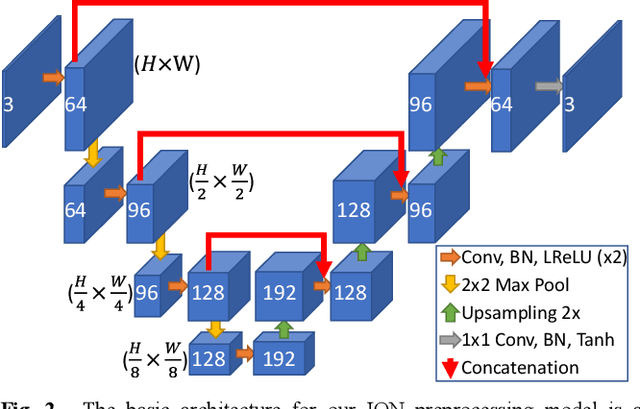

A major challenge in machine learning is resilience to out-of-distribution data, that is data that exists outside of the distribution of a model's training data. Training is often performed using limited, carefully curated datasets and so when a model is deployed there is often a significant distribution shift as edge cases and anomalies not included in the training data are encountered. To address this, we propose the Input Optimisation Network, an image preprocessing model that learns to optimise input data for a specific target vision model. In this work we investigate several out-of-distribution scenarios in the context of semantic segmentation for autonomous vehicles, comparing an Input Optimisation based solution to existing approaches of finetuning the target model with augmented training data and an adversarially trained preprocessing model. We demonstrate that our approach can enable performance on such data comparable to that of a finetuned model, and subsequently that a combined approach, whereby an input optimization network is optimised to target a finetuned model, delivers superior performance to either method in isolation. Finally, we propose a joint optimisation approach, in which input optimization network and target model are trained simultaneously, which we demonstrate achieves significant further performance gains, particularly in challenging edge-case scenarios. We also demonstrate that our architecture can be reduced to a relatively compact size without a significant performance impact, potentially facilitating real time embedded applications.
SAC-GAN: Structure-Aware Image-to-Image Composition for Self-Driving
Dec 30, 2021
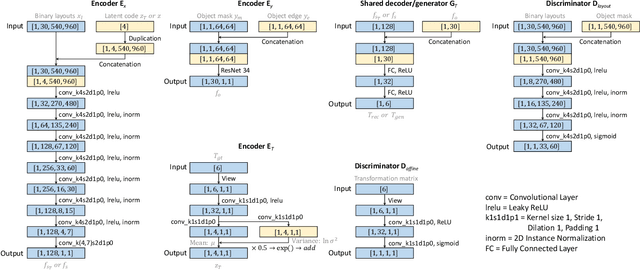
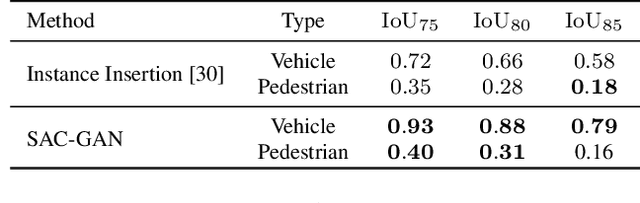

We present a compositional approach to image augmentation for self-driving applications. It is an end-to-end neural network that is trained to seamlessly compose an object (e.g., a vehicle or pedestrian) represented as a cropped patch from an object image, into a background scene image. As our approach emphasizes more on semantic and structural coherence of the composed images, rather than their pixel-level RGB accuracies, we tailor the input and output of our network with structure-aware features and design our network losses accordingly. Specifically, our network takes the semantic layout features from the input scene image, features encoded from the edges and silhouette in the input object patch, as well as a latent code as inputs, and generates a 2D spatial affine transform defining the translation and scaling of the object patch. The learned parameters are further fed into a differentiable spatial transformer network to transform the object patch into the target image, where our model is trained adversarially using an affine transform discriminator and a layout discriminator. We evaluate our network, coined SAC-GAN for structure-aware composition, on prominent self-driving datasets in terms of quality, composability, and generalizability of the composite images. Comparisons are made to state-of-the-art alternatives, confirming superiority of our method.
Automated anomaly-aware 3D segmentation of bones and cartilages in knee MR images from the Osteoarthritis Initiative
Dec 01, 2022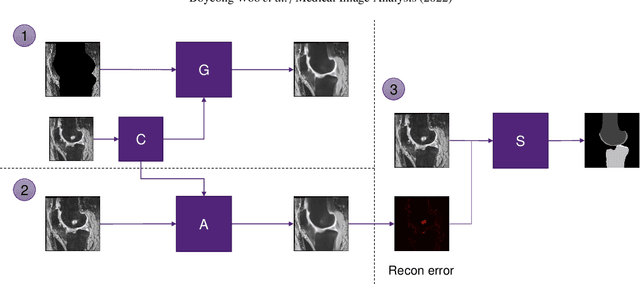
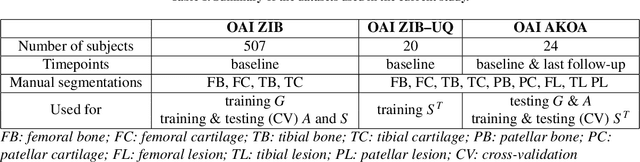
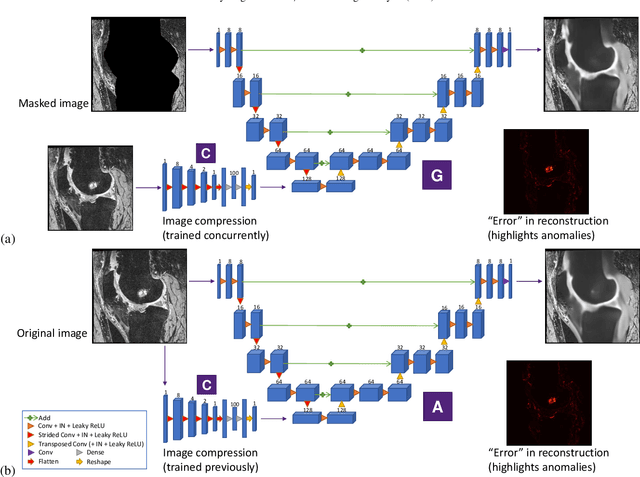
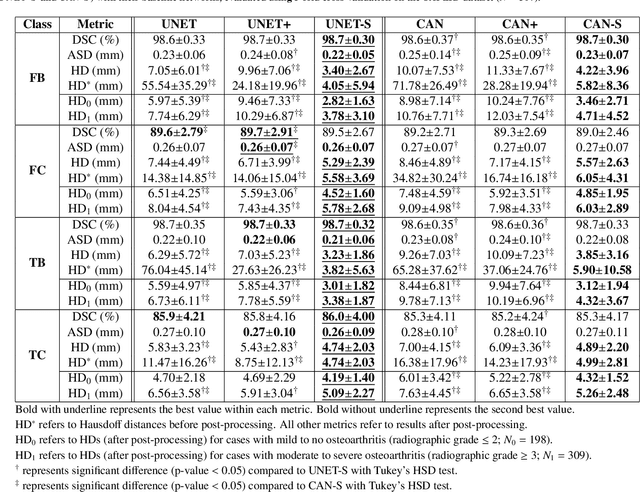
In medical image analysis, automated segmentation of multi-component anatomical structures, which often have a spectrum of potential anomalies and pathologies, is a challenging task. In this work, we develop a multi-step approach using U-Net-based neural networks to initially detect anomalies (bone marrow lesions, bone cysts) in the distal femur, proximal tibia and patella from 3D magnetic resonance (MR) images of the knee in individuals with varying grades of osteoarthritis. Subsequently, the extracted data are used for downstream tasks involving semantic segmentation of individual bone and cartilage volumes as well as bone anomalies. For anomaly detection, the U-Net-based models were developed to reconstruct the bone profiles of the femur and tibia in images via inpainting so anomalous bone regions could be replaced with close to normal appearances. The reconstruction error was used to detect bone anomalies. A second anomaly-aware network, which was compared to anomaly-na\"ive segmentation networks, was used to provide a final automated segmentation of the femoral, tibial and patellar bones and cartilages from the knee MR images containing a spectrum of bone anomalies. The anomaly-aware segmentation approach provided up to 58% reduction in Hausdorff distances for bone segmentations compared to the results from the anomaly-na\"ive segmentation networks. In addition, the anomaly-aware networks were able to detect bone lesions in the MR images with greater sensitivity and specificity (area under the receiver operating characteristic curve [AUC] up to 0.896) compared to the anomaly-na\"ive segmentation networks (AUC up to 0.874).
Multi-Objective Evolutionary for Object Detection Mobile Architectures Search
Nov 05, 2022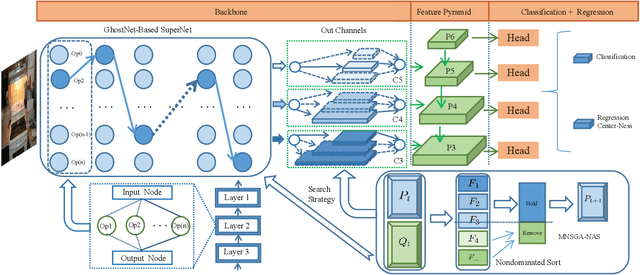
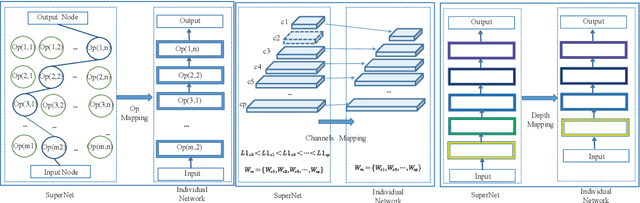
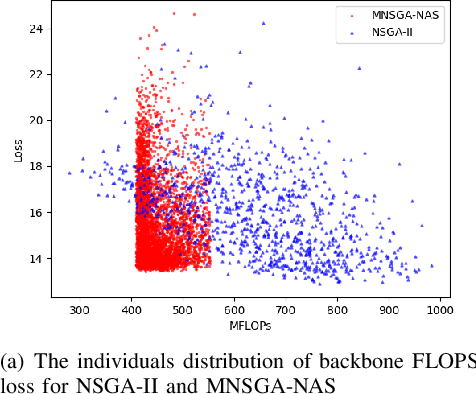

Recently, Neural architecture search has achieved great success on classification tasks for mobile devices. The backbone network for object detection is usually obtained on the image classification task. However, the architecture which is searched through the classification task is sub-optimal because of the gap between the task of image and object detection. As while work focuses on backbone network architecture search for mobile device object detection is limited, mainly because the backbone always requires expensive ImageNet pre-training. Accordingly, it is necessary to study the approach of network architecture search for mobile device object detection without expensive pre-training. In this work, we propose a mobile object detection backbone network architecture search algorithm which is a kind of evolutionary optimized method based on non-dominated sorting for NAS scenarios. It can quickly search to obtain the backbone network architecture within certain constraints. It better solves the problem of suboptimal linear combination accuracy and computational cost. The proposed approach can search the backbone networks with different depths, widths, or expansion sizes via a technique of weight mapping, making it possible to use NAS for mobile devices detection tasks a lot more efficiently. In our experiments, we verify the effectiveness of the proposed approach on YoloX-Lite, a lightweight version of the target detection framework. Under similar computational complexity, the accuracy of the backbone network architecture we search for is 2.0% mAP higher than MobileDet. Our improved backbone network can reduce the computational effort while improving the accuracy of the object detection network. To prove its effectiveness, a series of ablation studies have been carried out and the working mechanism has been analyzed in detail.
Image analysis for automatic measurement of crustose lichens
Mar 01, 2022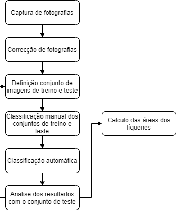
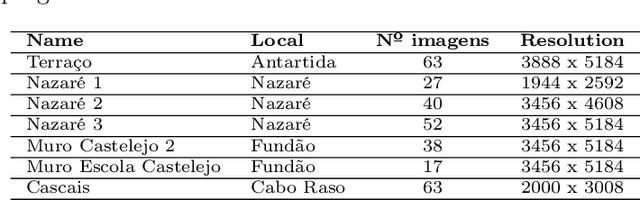


Lichens, organisms resulting from a symbiosis between a fungus and an algae, are frequently used as age estimators, especially in recent geological deposits and archaeological structures, using the correlation between lichen size and age. Current non-automated manual lichen and measurement (with ruler, calipers or using digital image processing tools) is a time-consuming and laborious process, especially when the number of samples is high. This work presents a workflow and set of image acquisition and processing tools developed to efficiently identify lichen thalli in flat rocky surfaces, and to produce relevant lichen size statistics (percentage cover, number of thalli, their area and perimeter). The developed workflow uses a regular digital camera for image capture along with specially designed targets to allow for automatic image correction and scale assignment. After this step, lichen identification is done in a flow comprising assisted image segmentation and classification based on interactive foreground extraction tool (GrabCut) and automatic classification of images using Simple Linear Iterative Clustering (SLIC) for image segmentation and Support Vector Machines (SV) and Random Forest classifiers. Initial evaluation shows promising results. The manual classification of images (for training) using GrabCut show an average speedup of 4 if compared with currently used techniques and presents an average precision of 95\%. The automatic classification using SLIC and SVM with default parameters produces results with average precision higher than 70\%. The developed system is flexible and allows a considerable reduction of processing time, the workflow allows it applicability to data sets of new lichen populations.
Semantically Consistent Image-to-Image Translation for Unsupervised Domain Adaptation
Nov 25, 2021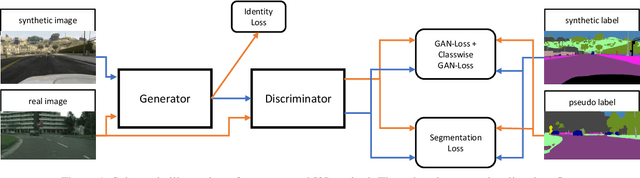
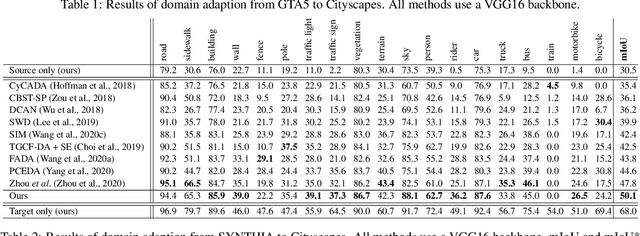
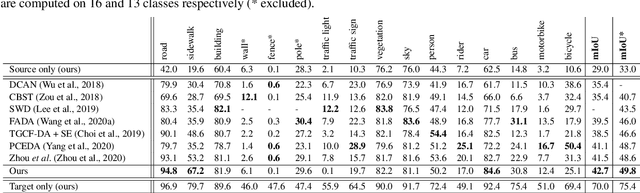

Unsupervised Domain Adaptation (UDA) aims to adapt models trained on a source domain to a new target domain where no labelled data is available. In this work, we investigate the problem of UDA from a synthetic computer-generated domain to a similar but real-world domain for learning semantic segmentation. We propose a semantically consistent image-to-image translation method in combination with a consistency regularisation method for UDA. We overcome previous limitations on transferring synthetic images to real looking images. We leverage pseudo-labels in order to learn a generative image-to-image translation model that receives additional feedback from semantic labels on both domains. Our method outperforms state-of-the-art methods that combine image-to-image translation and semi-supervised learning on relevant domain adaptation benchmarks, i.e., on GTA5 to Cityscapes and SYNTHIA to Cityscapes.
CoNFies: Controllable Neural Face Avatars
Nov 16, 2022



Neural Radiance Fields (NeRF) are compelling techniques for modeling dynamic 3D scenes from 2D image collections. These volumetric representations would be well suited for synthesizing novel facial expressions but for two problems. First, deformable NeRFs are object agnostic and model holistic movement of the scene: they can replay how the motion changes over time, but they cannot alter it in an interpretable way. Second, controllable volumetric representations typically require either time-consuming manual annotations or 3D supervision to provide semantic meaning to the scene. We propose a controllable neural representation for face self-portraits (CoNFies), that solves both of these problems within a common framework, and it can rely on automated processing. We use automated facial action recognition (AFAR) to characterize facial expressions as a combination of action units (AU) and their intensities. AUs provide both the semantic locations and control labels for the system. CoNFies outperformed competing methods for novel view and expression synthesis in terms of visual and anatomic fidelity of expressions.
Boosting Object Representation Learning via Motion and Object Continuity
Nov 16, 2022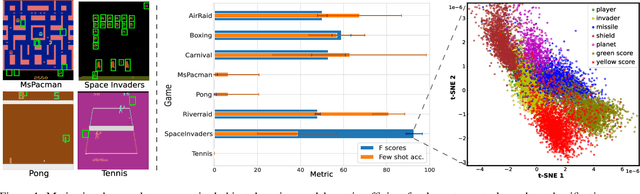
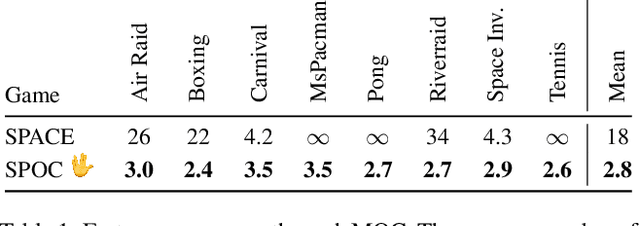
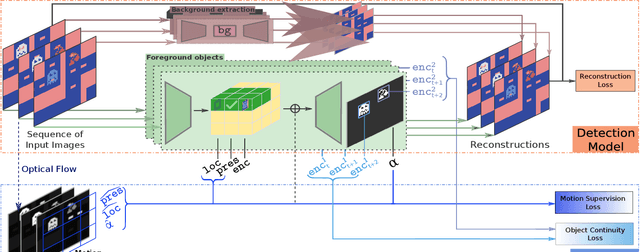
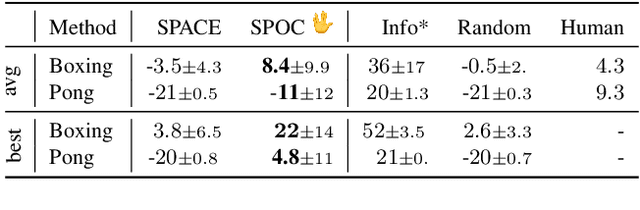
Recent unsupervised multi-object detection models have shown impressive performance improvements, largely attributed to novel architectural inductive biases. Unfortunately, they may produce suboptimal object encodings for downstream tasks. To overcome this, we propose to exploit object motion and continuity, i.e., objects do not pop in and out of existence. This is accomplished through two mechanisms: (i) providing priors on the location of objects through integration of optical flow, and (ii) a contrastive object continuity loss across consecutive image frames. Rather than developing an explicit deep architecture, the resulting Motion and Object Continuity (MOC) scheme can be instantiated using any baseline object detection model. Our results show large improvements in the performances of a SOTA model in terms of object discovery, convergence speed and overall latent object representations, particularly for playing Atari games. Overall, we show clear benefits of integrating motion and object continuity for downstream tasks, moving beyond object representation learning based only on reconstruction.