 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
An In-depth Study of Stochastic Backpropagation
Sep 30, 2022
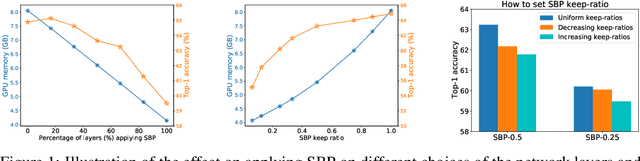
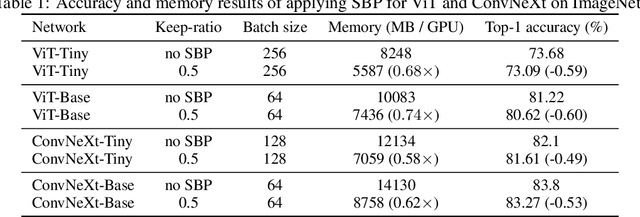
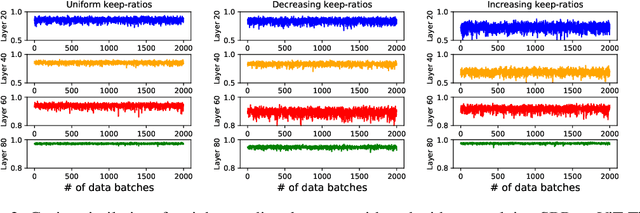
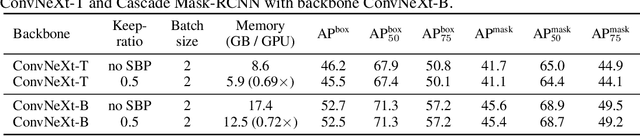
In this paper, we provide an in-depth study of Stochastic Backpropagation (SBP) when training deep neural networks for standard image classification and object detection tasks. During backward propagation, SBP calculates the gradients by only using a subset of feature maps to save the GPU memory and computational cost. We interpret SBP as an efficient way to implement stochastic gradient decent by performing backpropagation dropout, which leads to considerable memory saving and training process speedup, with a minimal impact on the overall model accuracy. We offer some good practices to apply SBP in training image recognition models, which can be adopted in learning a wide range of deep neural networks. Experiments on image classification and object detection show that SBP can save up to 40% of GPU memory with less than 1% accuracy degradation.
Multi-Camera Calibration Free BEV Representation for 3D Object Detection
Oct 31, 2022

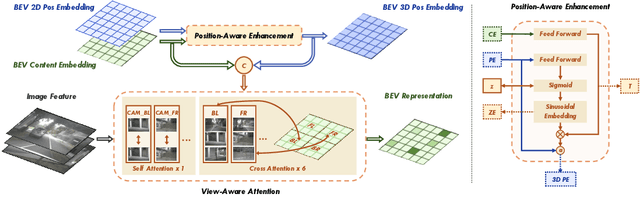
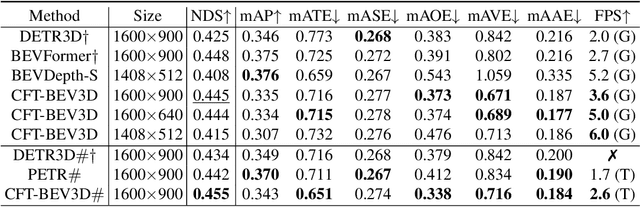
In advanced paradigms of autonomous driving, learning Bird's Eye View (BEV) representation from surrounding views is crucial for multi-task framework. However, existing methods based on depth estimation or camera-driven attention are not stable to obtain transformation under noisy camera parameters, mainly with two challenges, accurate depth prediction and calibration. In this work, we present a completely Multi-Camera Calibration Free Transformer (CFT) for robust BEV representation, which focuses on exploring implicit mapping, not relied on camera intrinsics and extrinsics. To guide better feature learning from image views to BEV, CFT mines potential 3D information in BEV via our designed position-aware enhancement (PA). Instead of camera-driven point-wise or global transformation, for interaction within more effective region and lower computation cost, we propose a view-aware attention which also reduces redundant computation and promotes converge. CFT achieves 49.7% NDS on the nuScenes detection task leaderboard, which is the first work removing camera parameters, comparable to other geometry-guided methods. Without temporal input and other modal information, CFT achieves second highest performance with a smaller image input 1600 * 640. Thanks to view-attention variant, CFT reduces memory and transformer FLOPs for vanilla attention by about 12% and 60%, respectively, with improved NDS by 1.0%. Moreover, its natural robustness to noisy camera parameters makes CFT more competitive.
A Federated Learning Scheme for Neuro-developmental Disorders: Multi-Aspect ASD Detection
Oct 31, 2022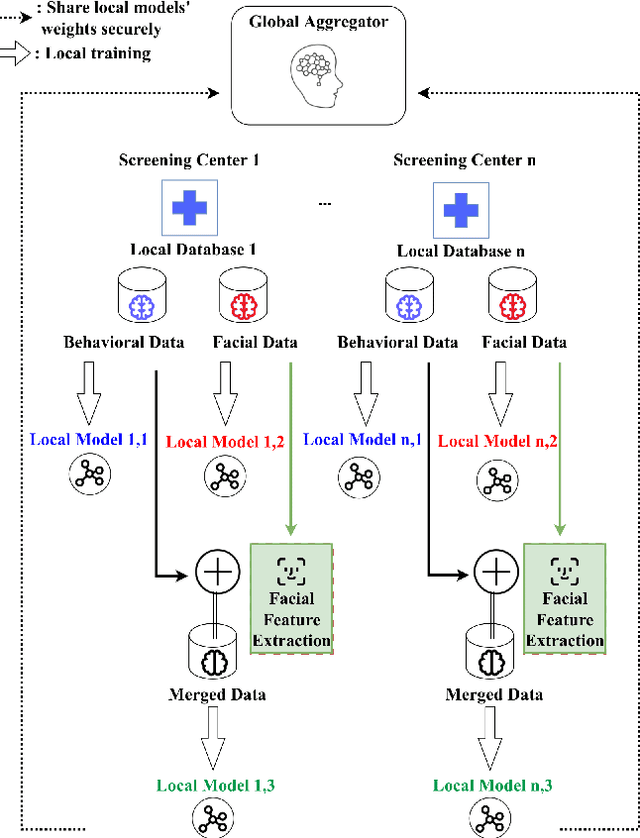


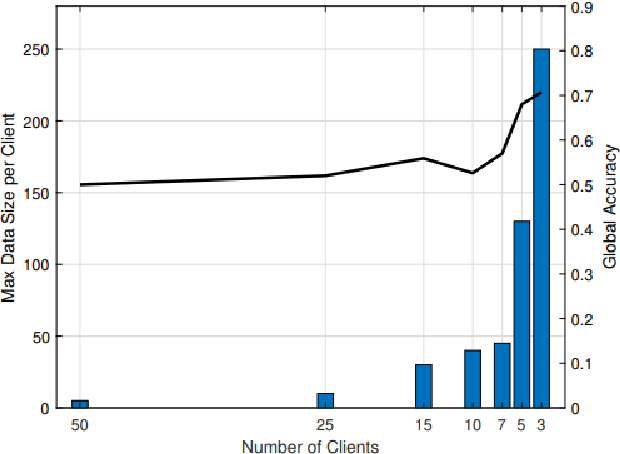
Autism Spectrum Disorder (ASD) is a neuro-developmental syndrome resulting from alterations in the embryological brain before birth. This disorder distinguishes its patients by special socially restricted and repetitive behavior in addition to specific behavioral traits. Hence, this would possibly deteriorate their social behavior among other individuals, as well as their overall interaction within their community. Moreover, medical research has proved that ASD also affects the facial characteristics of its patients, making the syndrome recognizable from distinctive signs within an individual's face. Given that as a motivation behind our work, we propose a novel privacy-preserving federated learning scheme to predict ASD in a certain individual based on their behavioral and facial features, embedding a merging process of both data features through facial feature extraction while respecting patient data privacy. After training behavioral and facial image data on federated machine learning models, promising results are achieved, with 70\% accuracy for the prediction of ASD according to behavioral traits in a federated learning environment, and a 62\% accuracy is reached for the prediction of ASD given an image of the patient's face. Then, we test the behavior of regular as well as federated ML on our merged data, behavioral and facial, where a 65\% accuracy is achieved with the regular logistic regression model and 63\% accuracy with the federated learning model.
Neural Architectural Nonlinear Pre-Processing for mmWave Radar-based Human Gesture Perception
Nov 07, 2022
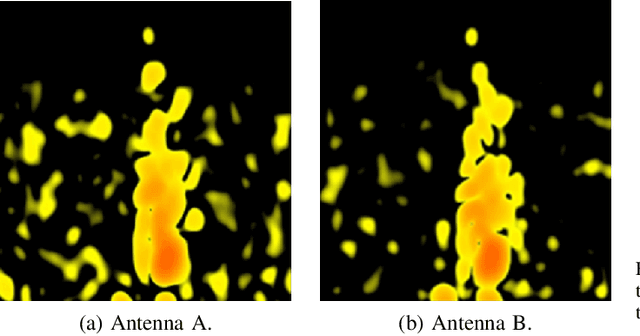

In modern on-driving computing environments, many sensors are used for context-aware applications. This paper utilizes two deep learning models, U-Net and EfficientNet, which consist of a convolutional neural network (CNN), to detect hand gestures and remove noise in the Range Doppler Map image that was measured through a millimeter-wave (mmWave) radar. To improve the performance of classification, accurate pre-processing algorithms are essential. Therefore, a novel pre-processing approach to denoise images before entering the first deep learning model stage increases the accuracy of classification. Thus, this paper proposes a deep neural network based high-performance nonlinear pre-processing method.
DC-ShadowNet: Single-Image Hard and Soft Shadow Removal Using Unsupervised Domain-Classifier Guided Network
Jul 21, 2022
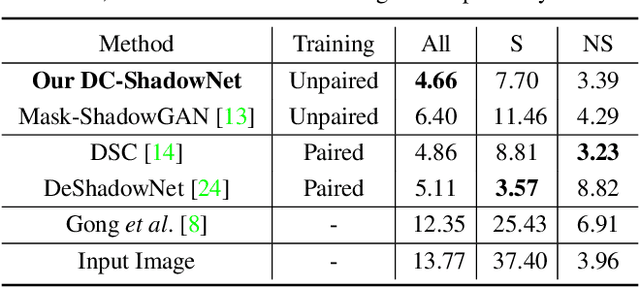
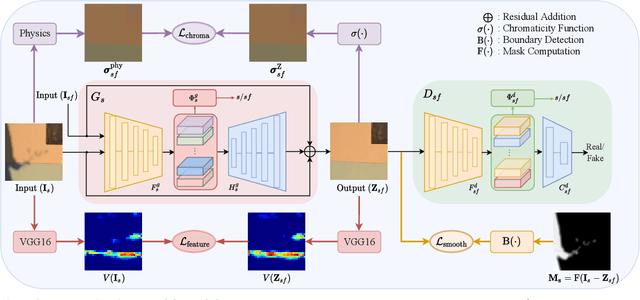
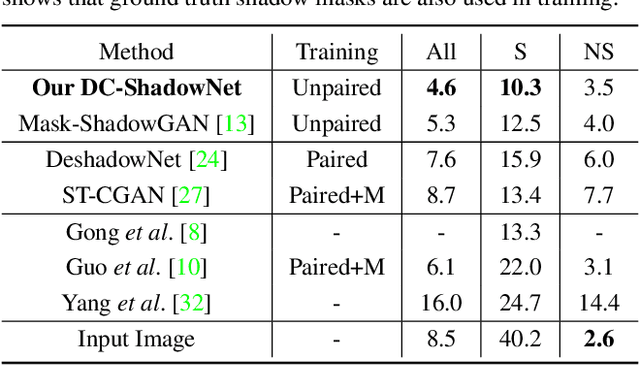
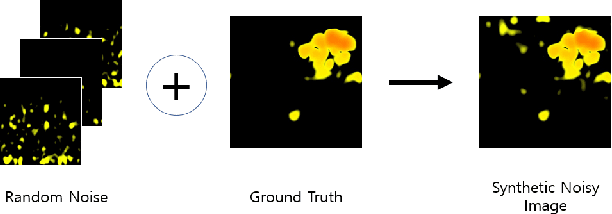
Shadow removal from a single image is generally still an open problem. Most existing learning-based methods use supervised learning and require a large number of paired images (shadow and corresponding non-shadow images) for training. A recent unsupervised method, Mask-ShadowGAN, addresses this limitation. However, it requires a binary mask to represent shadow regions, making it inapplicable to soft shadows. To address the problem, in this paper, we propose an unsupervised domain-classifier guided shadow removal network, DC-ShadowNet. Specifically, we propose to integrate a shadow/shadow-free domain classifier into a generator and its discriminator, enabling them to focus on shadow regions. To train our network, we introduce novel losses based on physics-based shadow-free chromaticity, shadow-robust perceptual features, and boundary smoothness. Moreover, we show that our unsupervised network can be used for test-time training that further improves the results. Our experiments show that all these novel components allow our method to handle soft shadows, and also to perform better on hard shadows both quantitatively and qualitatively than the existing state-of-the-art shadow removal methods.
* Accepted to ICCV2021, https://github.com/jinyeying/DC-ShadowNet-Hard-and-Soft-Shadow-Removal
Detecting Shortcuts in Medical Images -- A Case Study in Chest X-rays
Nov 09, 2022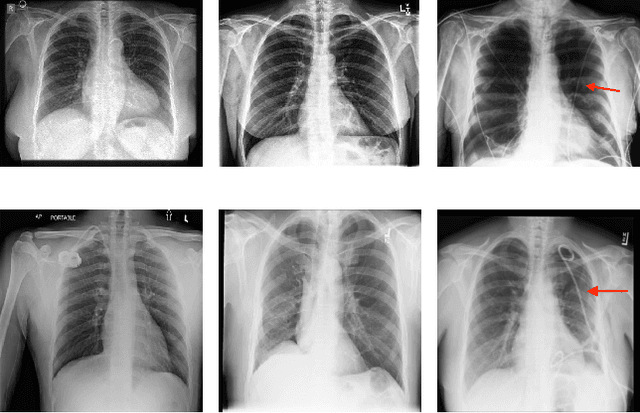

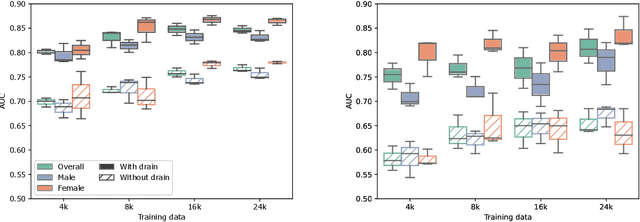
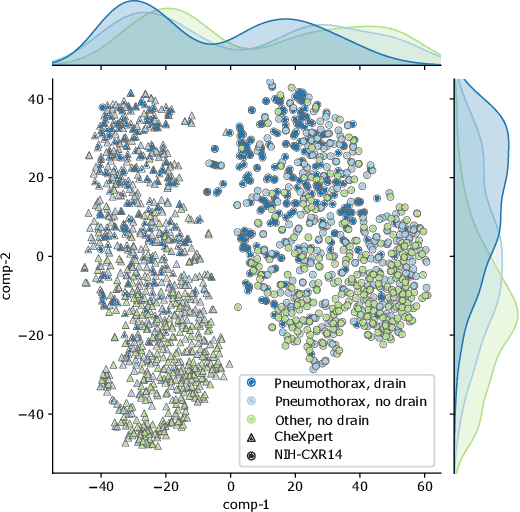
The availability of large public datasets and the increased amount of computing power have shifted the interest of the medical community to high-performance algorithms. However, little attention is paid to the quality of the data and their annotations. High performance on benchmark datasets may be reported without considering possible shortcuts or artifacts in the data, besides, models are not tested on subpopulation groups. With this work, we aim to raise awareness about shortcuts problems. We validate previous findings, and present a case study on chest X-rays using two publicly available datasets. We share annotations for a subset of pneumothorax images with drains. We conclude with general recommendations for medical image classification.
Single Image Internal Distribution Measurement Using Non-Local Variational Autoencoder
Apr 02, 2022
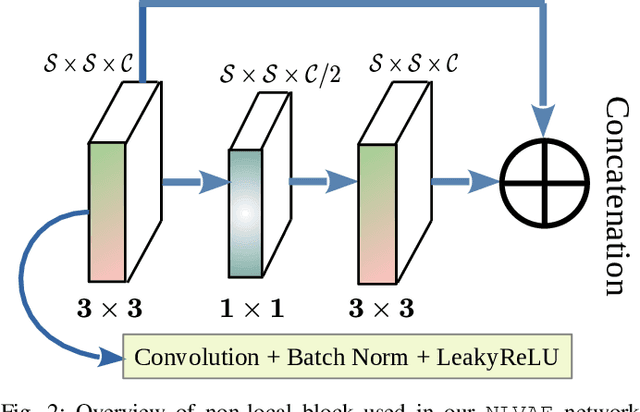
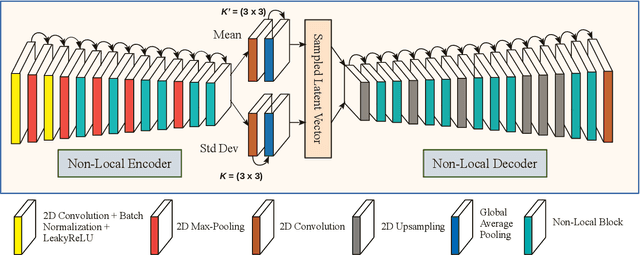

Deep learning-based super-resolution methods have shown great promise, especially for single image super-resolution (SISR) tasks. Despite the performance gain, these methods are limited due to their reliance on copious data for model training. In addition, supervised SISR solutions rely on local neighbourhood information focusing only on the feature learning processes for the reconstruction of low-dimensional images. Moreover, they fail to capitalize on global context due to their constrained receptive field. To combat these challenges, this paper proposes a novel image-specific solution, namely non-local variational autoencoder (\texttt{NLVAE}), to reconstruct a high-resolution (HR) image from a single low-resolution (LR) image without the need for any prior training. To harvest maximum details for various receptive regions and high-quality synthetic images, \texttt{NLVAE} is introduced as a self-supervised strategy that reconstructs high-resolution images using disentangled information from the non-local neighbourhood. Experimental results from seven benchmark datasets demonstrate the effectiveness of the \texttt{NLVAE} model. Moreover, our proposed model outperforms a number of baseline and state-of-the-art methods as confirmed through extensive qualitative and quantitative evaluations.
Membership Privacy Protection for Image Translation Models via Adversarial Knowledge Distillation
Mar 10, 2022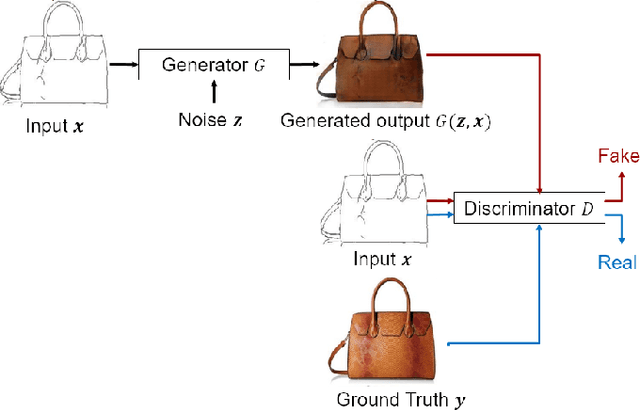
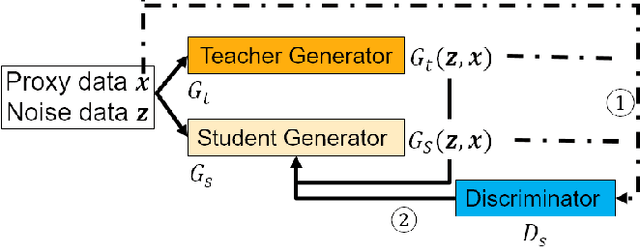
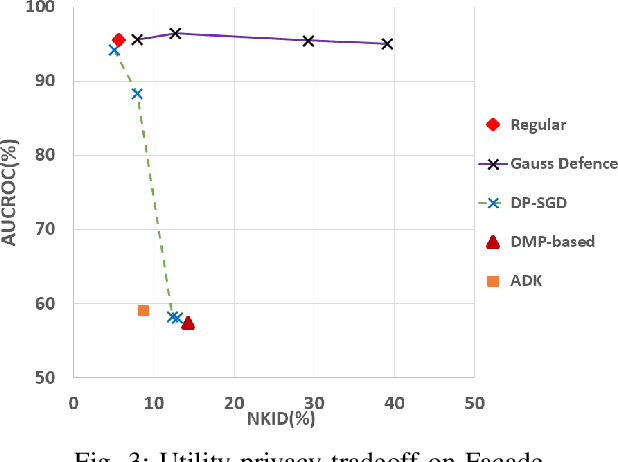
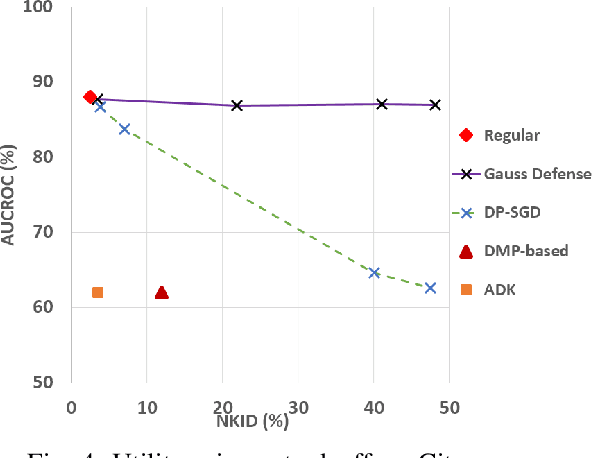
Image-to-image translation models are shown to be vulnerable to the Membership Inference Attack (MIA), in which the adversary's goal is to identify whether a sample is used to train the model or not. With daily increasing applications based on image-to-image translation models, it is crucial to protect the privacy of these models against MIAs. We propose adversarial knowledge distillation (AKD) as a defense method against MIAs for image-to-image translation models. The proposed method protects the privacy of the training samples by improving the generalizability of the model. We conduct experiments on the image-to-image translation models and show that AKD achieves the state-of-the-art utility-privacy tradeoff by reducing the attack performance up to 38.9% compared with the regular training model at the cost of a slight drop in the quality of the generated output images. The experimental results also indicate that the models trained by AKD generalize better than the regular training models. Furthermore, compared with existing defense methods, the results show that at the same privacy protection level, image translation models trained by AKD generate outputs with higher quality; while at the same quality of outputs, AKD enhances the privacy protection over 30%.
Unsupervised Image Fusion Using Deep Image Priors
Oct 18, 2021
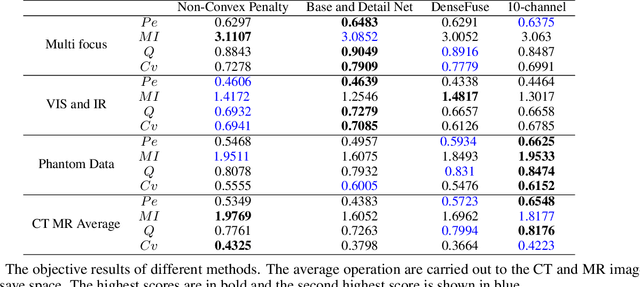
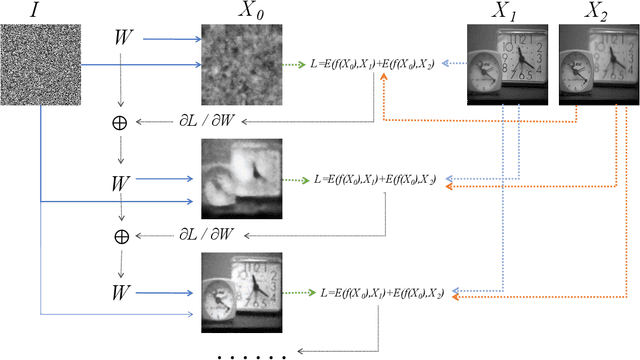
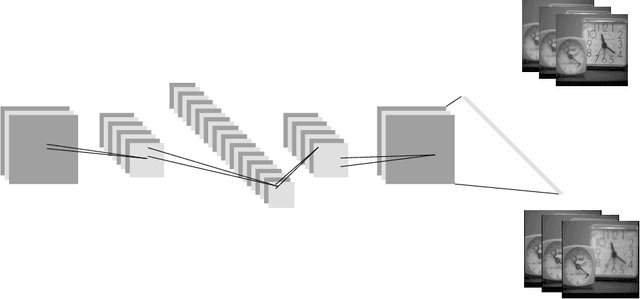
A significant number of researchers have recently applied deep learning methods to image fusion. However, most of these works either require a large amount of training data or depend on pre-trained models or frameworks. This inevitably encounters a shortage of training data or a mismatch between the framework and the actual problem. Recently, the publication of Deep Image Prior (DIP) method made it possible to do image restoration totally training-data-free. However, the original design of DIP is hard to be generalized to multi-image processing problems. This paper introduces a novel loss calculation structure, in the framework of DIP, while formulating image fusion as an inverse problem. This enables the extension of DIP to general multisensor/multifocus image fusion problems. Secondly, we propose a multi-channel approach to improve the effect of DIP. Finally, an evaluation is conducted using several commonly used image fusion assessment metrics. The results are compared with state-of-the-art traditional and deep learning image fusion methods. Our method outperforms previous techniques for a range of metrics. In particular, it is shown to provide the best objective results for most metrics when applied to medical images.
Incremental Predictive Coding: A Parallel and Fully Automatic Learning Algorithm
Nov 16, 2022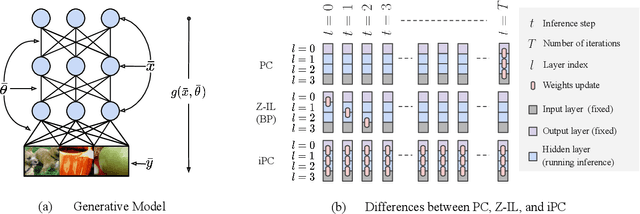
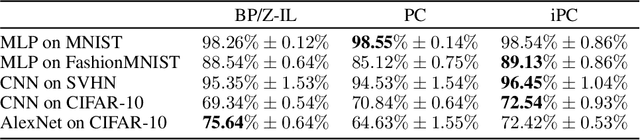


Neuroscience-inspired models, such as predictive coding, have the potential to play an important role in the future of machine intelligence. However, they are not yet used in industrial applications due to some limitations, such as the lack of efficiency. In this work, we address this by proposing incremental predictive coding (iPC), a variation of the original framework derived from the incremental expectation maximization algorithm, where every operation can be performed in parallel without external control. We show both theoretically and empirically that iPC is much faster than the original algorithm originally developed by Rao and Ballard, while maintaining performance comparable to backpropagation in image classification tasks. This work impacts several areas, has general applications in computational neuroscience and machine learning, and specific applications in scenarios where automatization and parallelization are important, such as distributed computing and implementations of deep learning models on analog and neuromorphic chips.