 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hyper-Universal Policy Approximation: Learning to Generate Actions from a Single Image using Hypernets
Jul 07, 2022
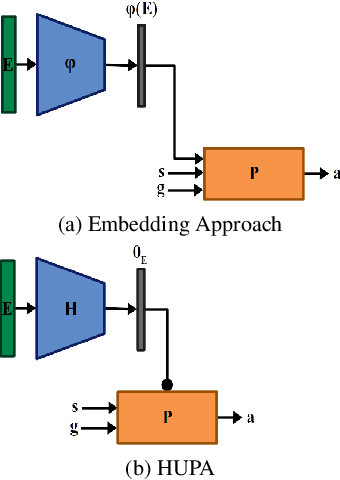
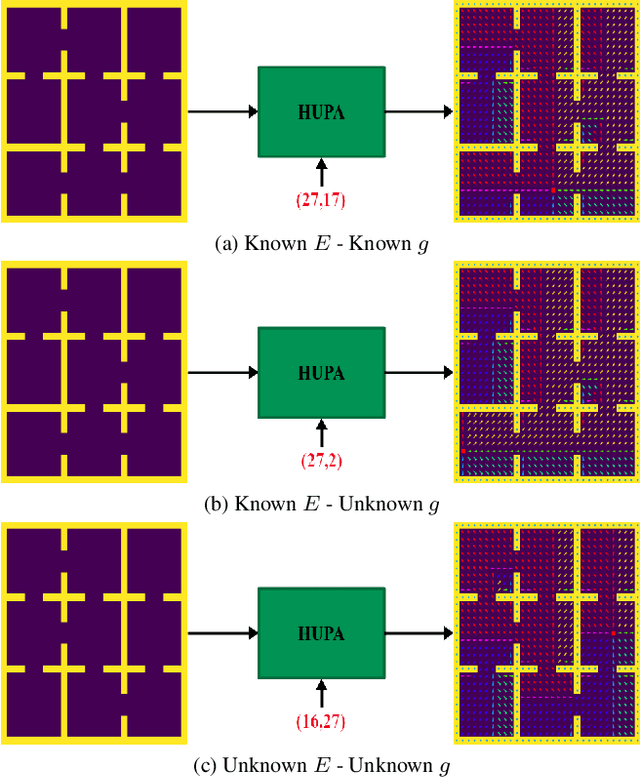
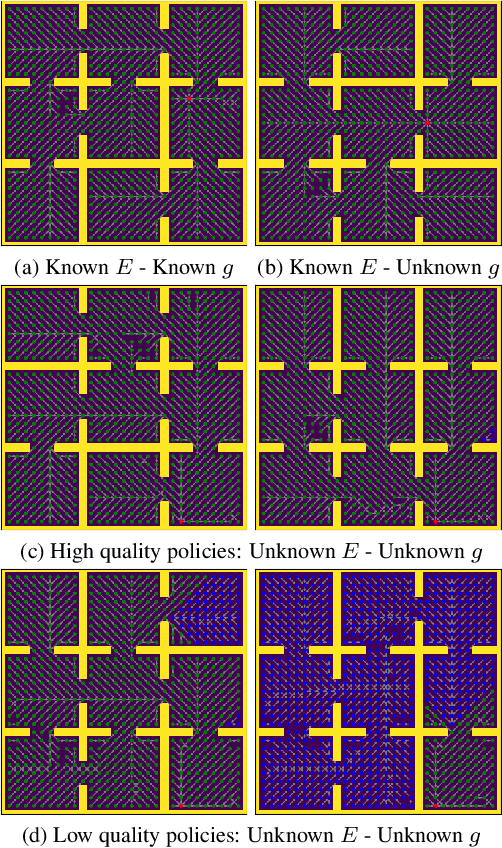
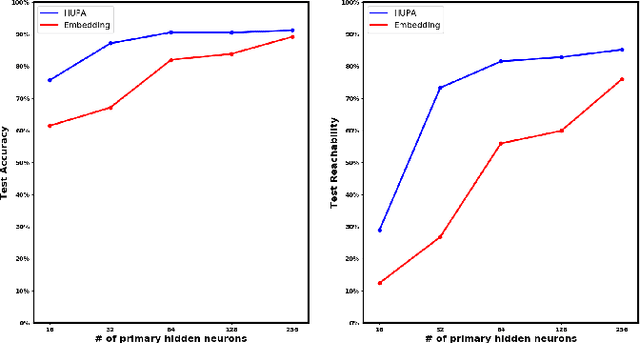
Inspired by Gibson's notion of object affordances in human vision, we ask the question: how can an agent learn to predict an entire action policy for a novel object or environment given only a single glimpse? To tackle this problem, we introduce the concept of Universal Policy Functions (UPFs) which are state-to-action mappings that generalize not only to new goals but most importantly to novel, unseen environments. Specifically, we consider the problem of efficiently learning such policies for agents with limited computational and communication capacity, constraints that are frequently encountered in edge devices. We propose the Hyper-Universal Policy Approximator (HUPA), a hypernetwork-based model to generate small task- and environment-conditional policy networks from a single image, with good generalization properties. Our results show that HUPAs significantly outperform an embedding-based alternative for generated policies that are size-constrained. Although this work is restricted to a simple map-based navigation task, future work includes applying the principles behind HUPAs to learning more general affordances for objects and environments.
Deep Learning Approaches on Image Captioning: A Review
Jan 31, 2022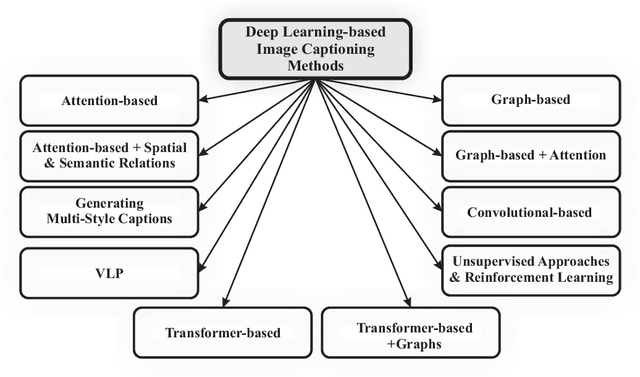
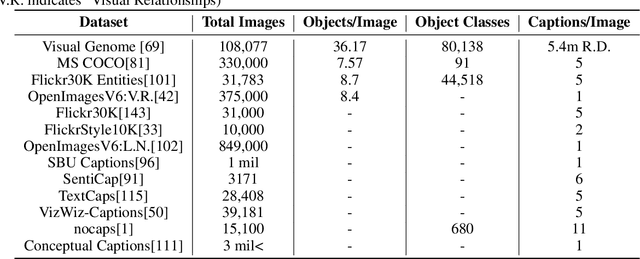
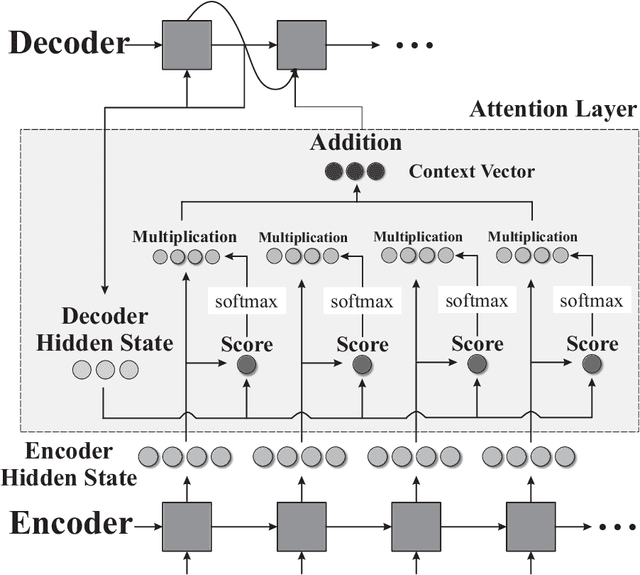
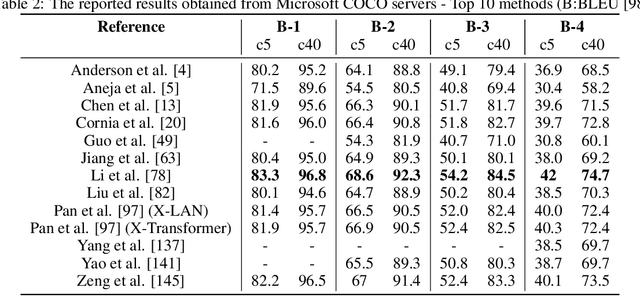
Automatic image captioning, which involves describing the contents of an image, is a challenging problem with many applications in various research fields. One notable example is designing assistants for the visually impaired. Recently, there have been significant advances in image captioning methods owing to the breakthroughs in deep learning. This survey paper aims to provide a structured review of recent image captioning techniques, and their performance, focusing mainly on deep learning methods. We also review widely-used datasets and performance metrics, in addition to the discussions on open problems and unsolved challenges in image captioning.
Increasing the Accuracy of a Neural Network Using Frequency Selective Mesh-to-Grid Resampling
Sep 28, 2022

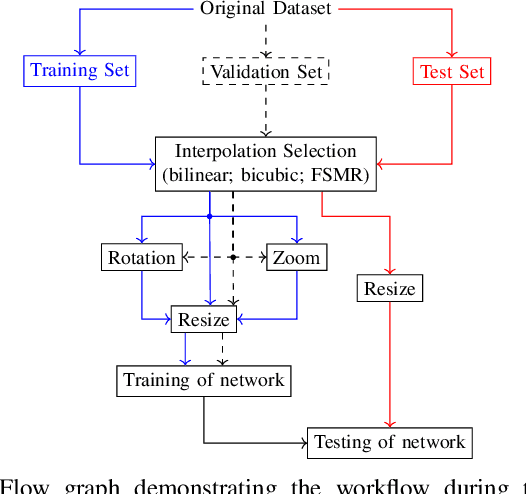
Neural networks are widely used for almost any task of recognizing image content. Even though much effort has been put into investigating efficient network architectures, optimizers, and training strategies, the influence of image interpolation on the performance of neural networks is not well studied. Furthermore, research has shown that neural networks are often sensitive to minor changes in the input image leading to drastic drops of their performance. Therefore, we propose the use of keypoint agnostic frequency selective mesh-to-grid resampling (FSMR) for the processing of input data for neural networks in this paper. This model-based interpolation method already showed that it is capable of outperforming common interpolation methods in terms of PSNR. Using an extensive experimental evaluation we show that depending on the network architecture and classification task the application of FSMR during training aids the learning process. Furthermore, we show that the usage of FSMR in the application phase is beneficial. The classification accuracy can be increased by up to 4.31 percentage points for ResNet50 and the Oxflower17 dataset.
Image-to-Image Translation-based Data Augmentation for Robust EV Charging Inlet Detection
Dec 10, 2021

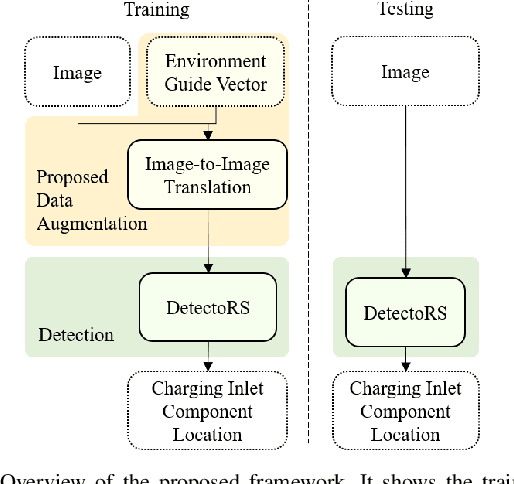

This work addresses the task of electric vehicle (EV) charging inlet detection for autonomous EV charging robots. Recently, automated EV charging systems have received huge attention to improve users' experience and to efficiently utilize charging infrastructures and parking lots. However, most related works have focused on system design, robot control, planning, and manipulation. Towards robust EV charging inlet detection, we propose a new dataset (EVCI dataset) and a novel data augmentation method that is based on image-to-image translation where typical image-to-image translation methods synthesize a new image in a different domain given an image. To the best of our knowledge, the EVCI dataset is the first EV charging inlet dataset. For the data augmentation method, we focus on being able to control synthesized images' captured environments (e.g., time, lighting) in an intuitive way. To achieve this, we first propose the environment guide vector that humans can intuitively interpret. We then propose a novel image-to-image translation network that translates a given image towards the environment described by the vector. Accordingly, it aims to synthesize a new image that has the same content as the given image while looking like captured in the provided environment by the environment guide vector. Lastly, we train a detection method using the augmented dataset. Through experiments on the EVCI dataset, we demonstrate that the proposed method outperforms the state-of-the-art methods. We also show that the proposed method is able to control synthesized images using an image and environment guide vectors.
The Change You Want to See
Sep 28, 2022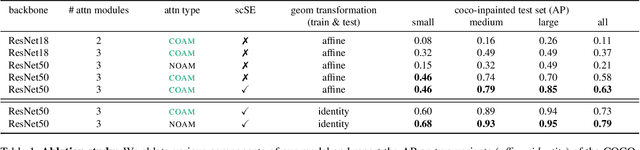
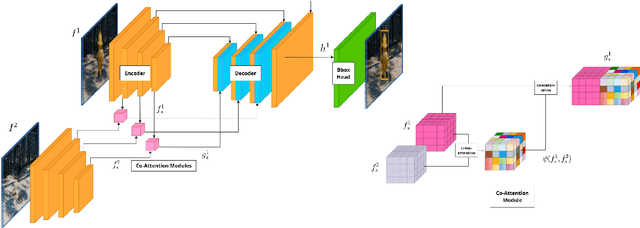

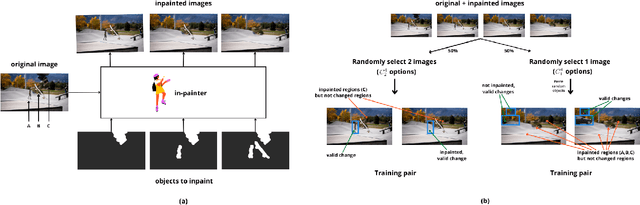
We live in a dynamic world where things change all the time. Given two images of the same scene, being able to automatically detect the changes in them has practical applications in a variety of domains. In this paper, we tackle the change detection problem with the goal of detecting "object-level" changes in an image pair despite differences in their viewpoint and illumination. To this end, we make the following four contributions: (i) we propose a scalable methodology for obtaining a large-scale change detection training dataset by leveraging existing object segmentation benchmarks; (ii) we introduce a co-attention based novel architecture that is able to implicitly determine correspondences between an image pair and find changes in the form of bounding box predictions; (iii) we contribute four evaluation datasets that cover a variety of domains and transformations, including synthetic image changes, real surveillance images of a 3D scene, and synthetic 3D scenes with camera motion; (iv) we evaluate our model on these four datasets and demonstrate zero-shot and beyond training transformation generalization.
Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors
Mar 24, 2022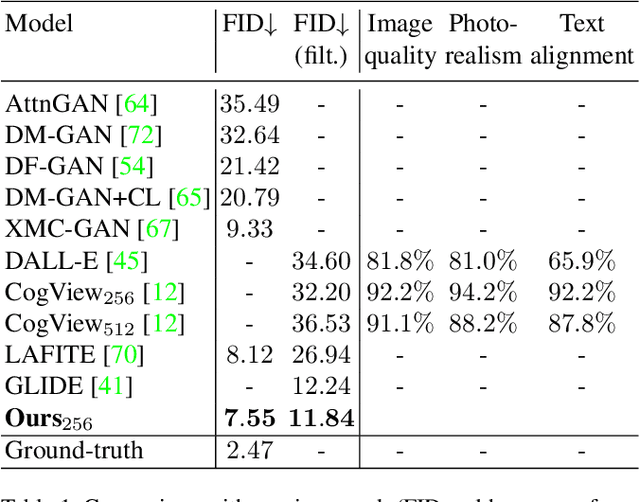

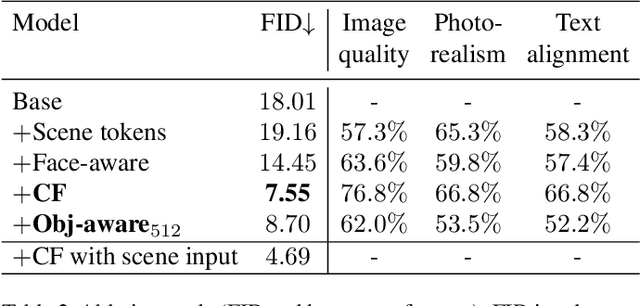

Recent text-to-image generation methods provide a simple yet exciting conversion capability between text and image domains. While these methods have incrementally improved the generated image fidelity and text relevancy, several pivotal gaps remain unanswered, limiting applicability and quality. We propose a novel text-to-image method that addresses these gaps by (i) enabling a simple control mechanism complementary to text in the form of a scene, (ii) introducing elements that substantially improve the tokenization process by employing domain-specific knowledge over key image regions (faces and salient objects), and (iii) adapting classifier-free guidance for the transformer use case. Our model achieves state-of-the-art FID and human evaluation results, unlocking the ability to generate high fidelity images in a resolution of 512x512 pixels, significantly improving visual quality. Through scene controllability, we introduce several new capabilities: (i) Scene editing, (ii) text editing with anchor scenes, (iii) overcoming out-of-distribution text prompts, and (iv) story illustration generation, as demonstrated in the story we wrote.
Equivariance Regularization for Image Reconstruction
Feb 10, 2022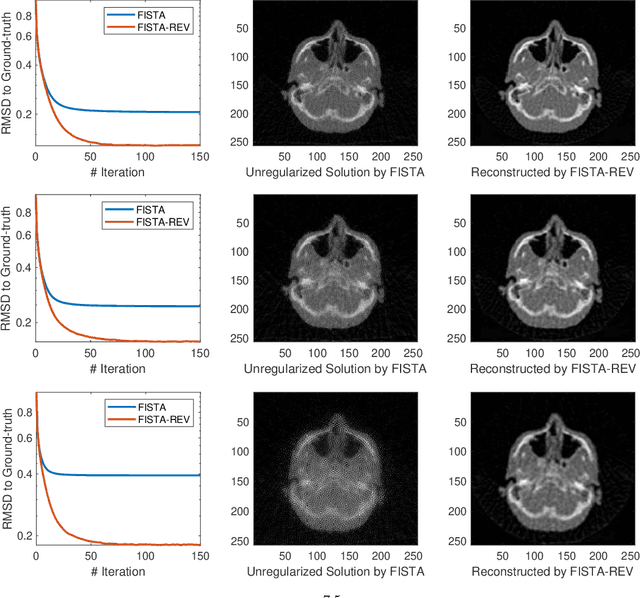
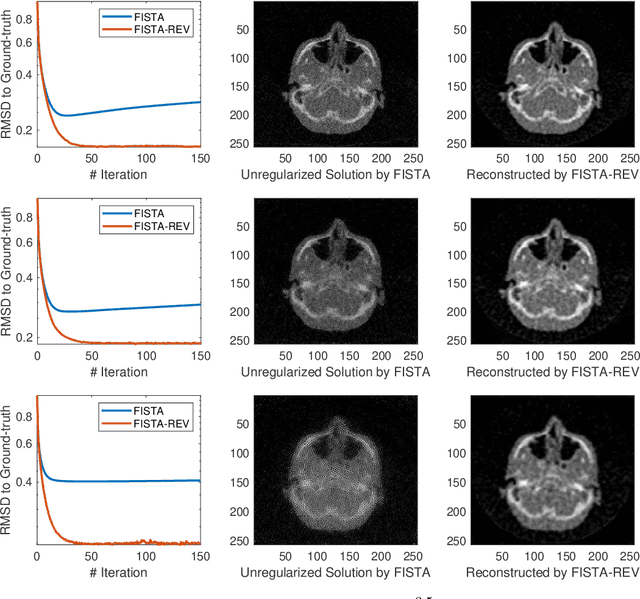
In this work, we propose Regularization-by-Equivariance (REV), a novel structure-adaptive regularization scheme for solving imaging inverse problems under incomplete measurements. Our regularization scheme utilizes the equivariant structure in the physics of the measurements -- which is prevalent in many inverse problems such as tomographic image reconstruction -- to mitigate the ill-poseness of the inverse problem. Our proposed scheme can be applied in a plug-and-play manner alongside with any classic first-order optimization algorithm such as the accelerated gradient descent/FISTA for simplicity and fast convergence. Our numerical experiments in sparse-view X-ray CT image reconstruction tasks demonstrate the effectiveness of our approach.
Water Simulation and Rendering from a Still Photograph
Oct 05, 2022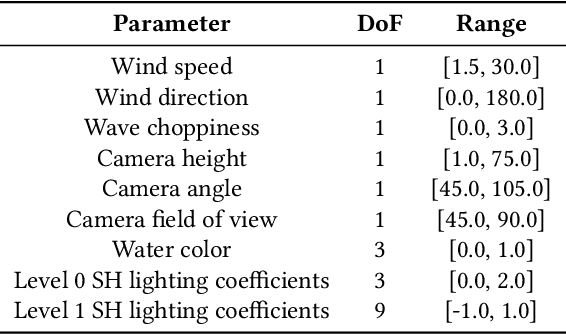
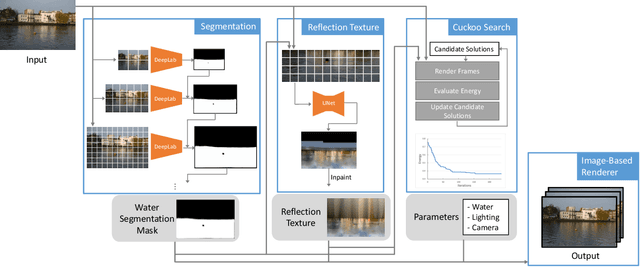


We propose an approach to simulate and render realistic water animation from a single still input photograph. We first segment the water surface, estimate rendering parameters, and compute water reflection textures with a combination of neural networks and traditional optimization techniques. Then we propose an image-based screen space local reflection model to render the water surface overlaid on the input image and generate real-time water animation. Our approach creates realistic results with no user intervention for a wide variety of natural scenes containing large bodies of water with different lighting and water surface conditions. Since our method provides a 3D representation of the water surface, it naturally enables direct editing of water parameters and also supports interactive applications like adding synthetic objects to the scene.
Progressively Dual Prior Guided Few-shot Semantic Segmentation
Nov 20, 2022
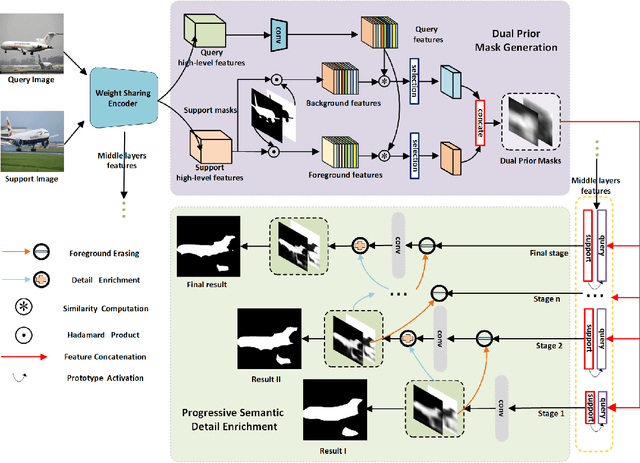
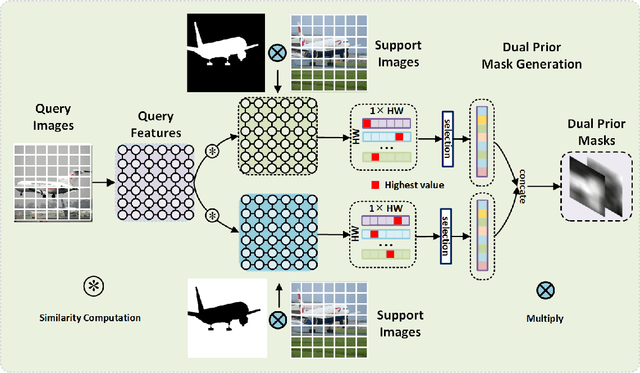
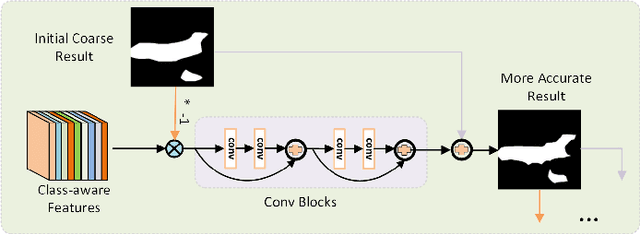
Few-shot semantic segmentation task aims at performing segmentation in query images with a few annotated support samples. Currently, few-shot segmentation methods mainly focus on leveraging foreground information without fully utilizing the rich background information, which could result in wrong activation of foreground-like background regions with the inadaptability to dramatic scene changes of support-query image pairs. Meanwhile, the lack of detail mining mechanism could cause coarse parsing results without some semantic components or edge areas since prototypes have limited ability to cope with large object appearance variance. To tackle these problems, we propose a progressively dual prior guided few-shot semantic segmentation network. Specifically, a dual prior mask generation (DPMG) module is firstly designed to suppress the wrong activation in foreground-background comparison manner by regarding background as assisted refinement information. With dual prior masks refining the location of foreground area, we further propose a progressive semantic detail enrichment (PSDE) module which forces the parsing model to capture the hidden semantic details by iteratively erasing the high-confidence foreground region and activating details in the rest region with a hierarchical structure. The collaboration of DPMG and PSDE formulates a novel few-shot segmentation network that can be learned in an end-to-end manner. Comprehensive experiments on PASCAL-5i and MS COCO powerfully demonstrate that our proposed algorithm achieves the great performance.
Overfreezing Meets Overparameterization: A Double Descent Perspective on Transfer Learning of Deep Neural Networks
Nov 20, 2022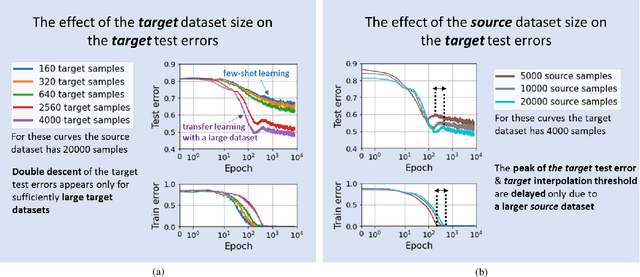
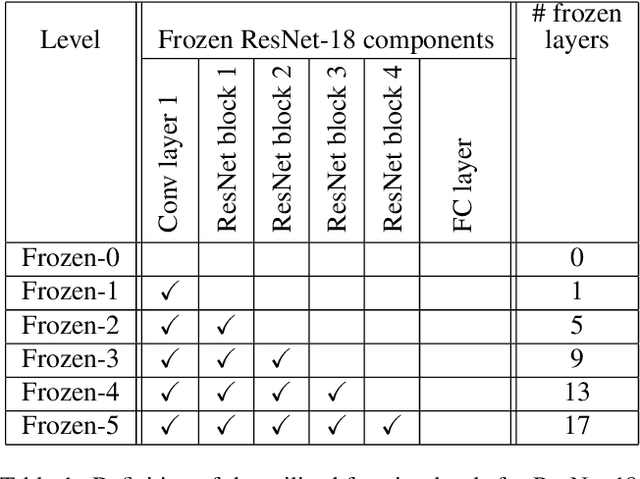
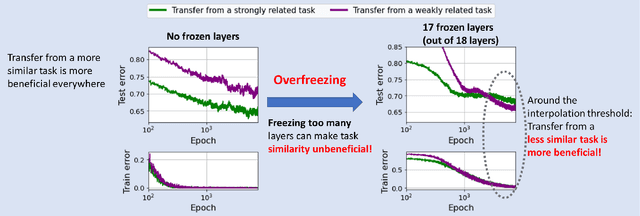
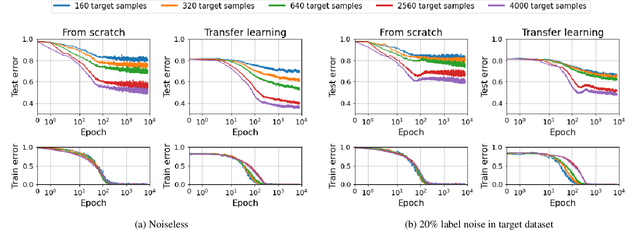
We study the generalization behavior of transfer learning of deep neural networks (DNNs). We adopt the overparameterization perspective -- featuring interpolation of the training data (i.e., approximately zero train error) and the double descent phenomenon -- to explain the delicate effect of the transfer learning setting on generalization performance. We study how the generalization behavior of transfer learning is affected by the dataset size in the source and target tasks, the number of transferred layers that are kept frozen in the target DNN training, and the similarity between the source and target tasks. We show that the test error evolution during the target DNN training has a more significant double descent effect when the target training dataset is sufficiently large with some label noise. In addition, a larger source training dataset can delay the arrival to interpolation and double descent peak in the target DNN training. Moreover, we demonstrate that the number of frozen layers can determine whether the transfer learning is effectively underparameterized or overparameterized and, in turn, this may affect the relative success or failure of learning. Specifically, we show that too many frozen layers may make a transfer from a less related source task better or on par with a transfer from a more related source task; we call this case overfreezing. We establish our results using image classification experiments with the residual network (ResNet) and vision transformer (ViT) architectures.