 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Feature Weaken: Vicinal Data Augmentation for Classification
Nov 20, 2022
Deep learning usually relies on training large-scale data samples to achieve better performance. However, over-fitting based on training data always remains a problem. Scholars have proposed various strategies, such as feature dropping and feature mixing, to improve the generalization continuously. For the same purpose, we subversively propose a novel training method, Feature Weaken, which can be regarded as a data augmentation method. Feature Weaken constructs the vicinal data distribution with the same cosine similarity for model training by weakening features of the original samples. In especially, Feature Weaken changes the spatial distribution of samples, adjusts sample boundaries, and reduces the gradient optimization value of back-propagation. This work can not only improve the classification performance and generalization of the model, but also stabilize the model training and accelerate the model convergence. We conduct extensive experiments on classical deep convolution neural models with five common image classification datasets and the Bert model with four common text classification datasets. Compared with the classical models or the generalization improvement methods, such as Dropout, Mixup, Cutout, and CutMix, Feature Weaken shows good compatibility and performance. We also use adversarial samples to perform the robustness experiments, and the results show that Feature Weaken is effective in improving the robustness of the model.
Automatic satellite building construction monitoring
Sep 29, 2022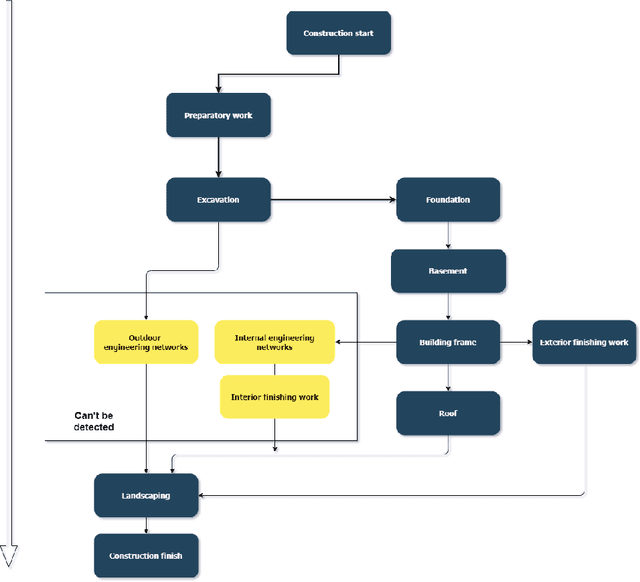
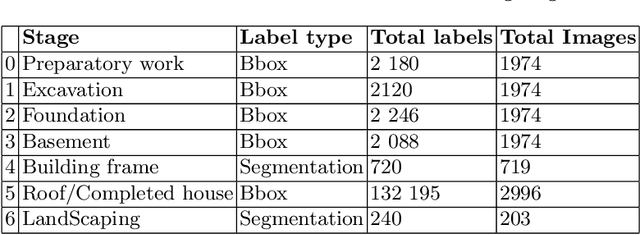
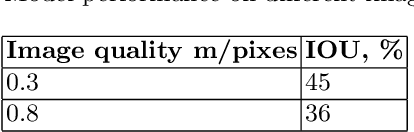
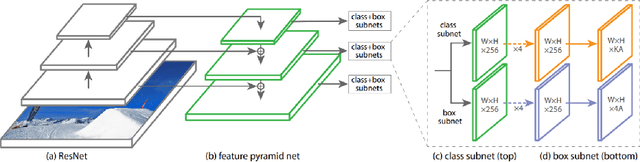
One of the promising applications of satellite images is building construction monitoring. It allows to control the construction progress around the world even in the locations that are hard to reach. One of the main hurdles of this approach is the interpretation of the image data. In this paper, we have employed several novel deep learning techniques to tackle the problem. Various image segmentation and object detection networks were combined into a unified pipeline, which was then used to determine the building construction progress.
Search Space Adaptation for Differentiable Neural Architecture Search in Image Classification
Jun 05, 2022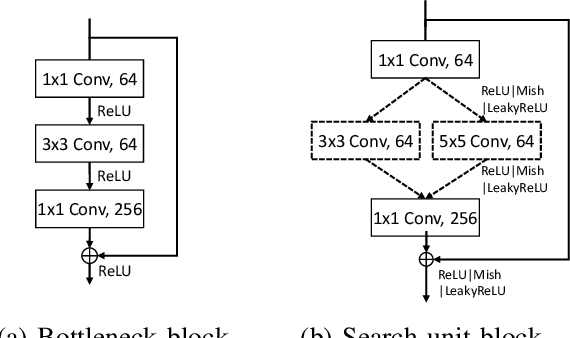
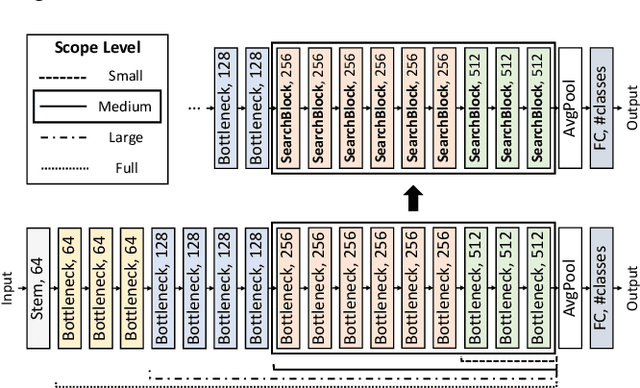
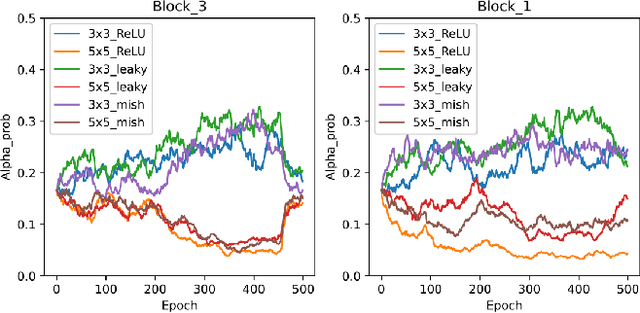
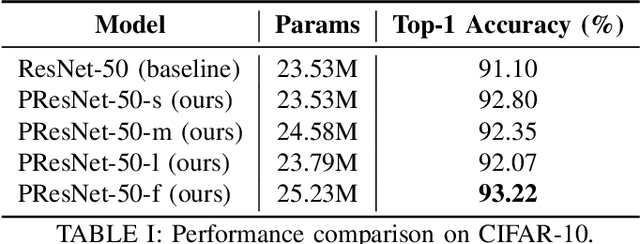
As deep neural networks achieve unprecedented performance in various tasks, neural architecture search (NAS), a research field for designing neural network architectures with automated processes, is actively underway. More recently, differentiable NAS has a great impact by reducing the search cost to the level of training a single network. Besides, the search space that defines candidate architectures to be searched directly affects the performance of the final architecture. In this paper, we propose an adaptation scheme of the search space by introducing a search scope. The effectiveness of proposed method is demonstrated with ProxylessNAS for the image classification task. Furthermore, we visualize the trajectory of architecture parameter updates and provide insights to improve the architecture search.
TSP-Bot: Robotic TSP Pen Art using High-DoF Manipulators
Oct 17, 2022
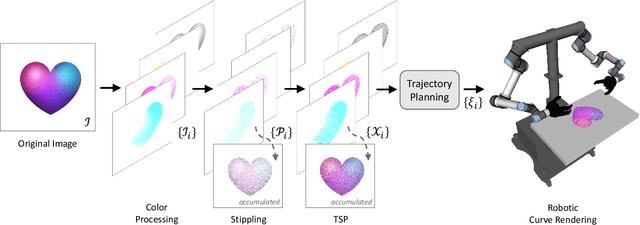
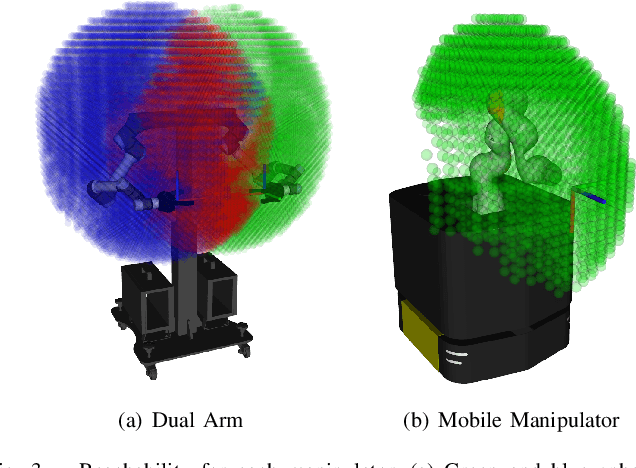

TSP art is an art form for drawing an image using piecewise-continuous line segments with no crossings. This paper presents a multi-color robotic pen drawing system capable of drawing complicated TSP pen art on a planar surface. Given a colored, raster image, we first convert it into a set of points representing the original image's tone by controlling the density of the points. Then, we find a piecewise-continuous linear path that visits every point exactly once, equivalent to solving a Traveling Salesman Problem (TSP). Our robotic drawing system consisting of single or dual manipulators with fingered grippers and a mobile platform, performs the drawing task by following the resulting complex and sophisticated path composed of thousands of TSP sites. As a result, our system can draw a complicated and visually-pleasing TSP pen art with high accuracy and efficiency. We also demonstrate that our system can draw a TSP pen art on a large wall, which is very hard for a human artist to achieve.
Visual onoma-to-wave: environmental sound synthesis from visual onomatopoeias and sound-source images
Oct 17, 2022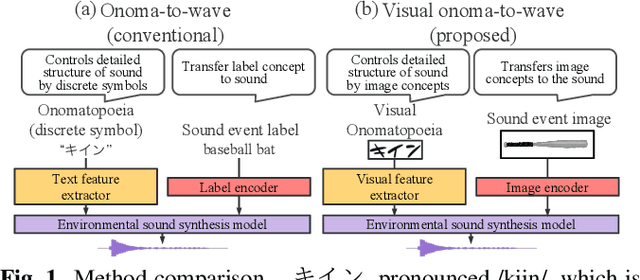
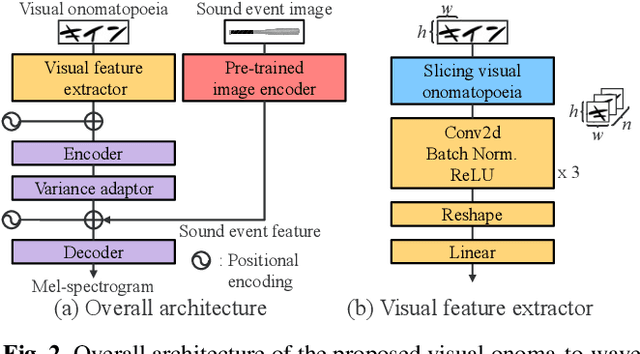

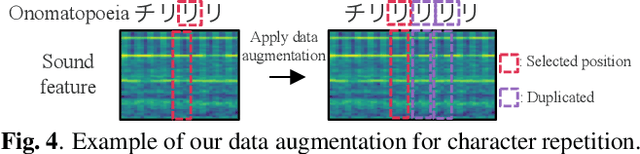
We propose a method for synthesizing environmental sounds from visually represented onomatopoeias and sound sources. An onomatopoeia is a word that imitates a sound structure, i.e., the text representation of sound. From this perspective, onoma-to-wave has been proposed to synthesize environmental sounds from the desired onomatopoeia texts. Onomatopoeias have another representation: visual-text representations of sounds in comics, advertisements, and virtual reality. A visual onomatopoeia (visual text of onomatopoeia) contains rich information that is not present in the text, such as a long-short duration of the image, so the use of this representation is expected to synthesize diverse sounds. Therefore, we propose visual onoma-to-wave for environmental sound synthesis from visual onomatopoeia. The method can transfer visual concepts of the visual text and sound-source image to the synthesized sound. We also propose a data augmentation method focusing on the repetition of onomatopoeias to enhance the performance of our method. An experimental evaluation shows that the methods can synthesize diverse environmental sounds from visual text and sound-source images.
Stroke-based Rendering and Planning for Robotic Performance of Artistic Drawing
Oct 14, 2022



We present a new robotic drawing system based on stroke-based rendering (SBR). Our motivation is the artistic quality of the whole performance. Not only should the generated strokes in the final drawing resemble the input image, but the stroke sequence should also exhibit a human artist's planning process. Thus, when a robot executes the drawing task, both the drawing results and the way the robot executes would look artistic. Our SBR system is based on image segmentation and depth estimation. It generates the drawing strokes in an order that allows for the intended shape to be perceived quickly and for its detailed features to be filled in and emerge gradually when observed by the human. This ordering represents a stroke plan that the drawing robot should follow to create an artistic rendering of images. We experimentally demonstrate that our SBR-based drawing makes visually pleasing artistic images, and our robotic system can replicate the result with proper sequences of stroke drawing.
A Novel Hybrid Endoscopic Dataset for Evaluating Machine Learning-based Photometric Image Enhancement Models
Jul 06, 2022
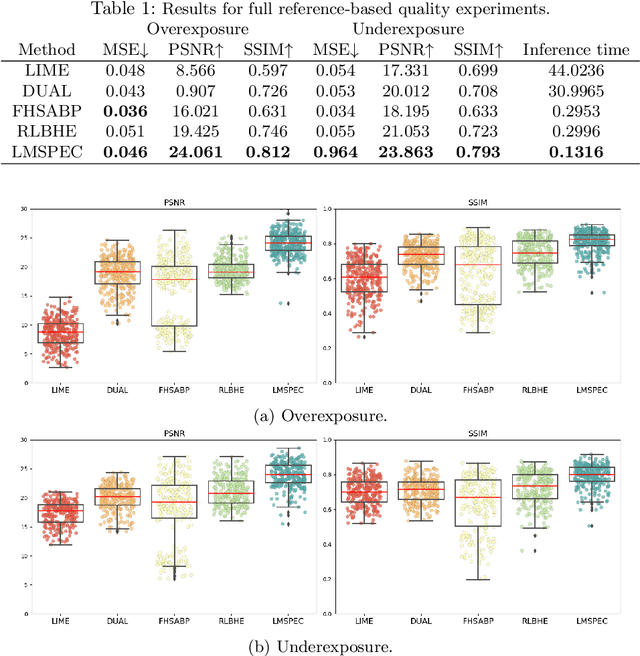
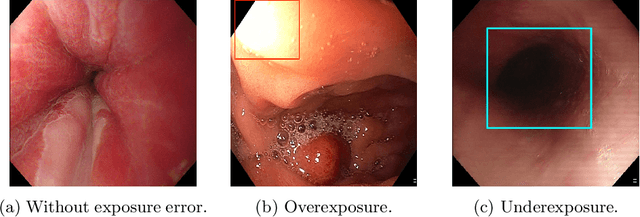
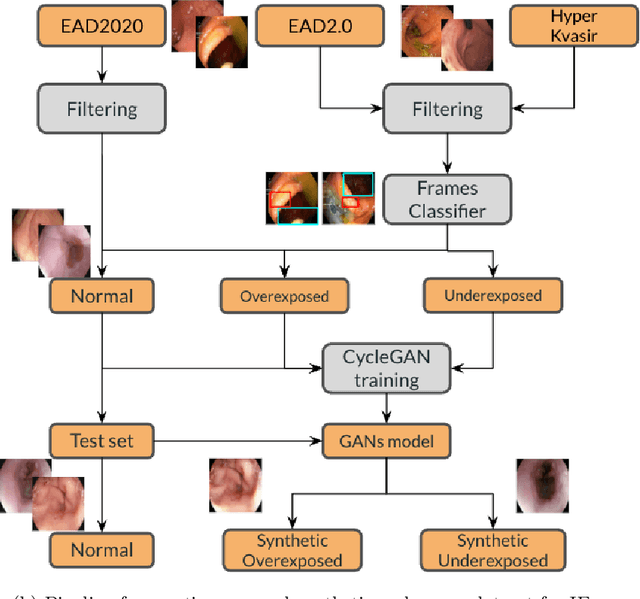
Endoscopy is the most widely used medical technique for cancer and polyp detection inside hollow organs. However, images acquired by an endoscope are frequently affected by illumination artefacts due to the enlightenment source orientation. There exist two major issues when the endoscope's light source pose suddenly changes: overexposed and underexposed tissue areas are produced. These two scenarios can result in misdiagnosis due to the lack of information in the affected zones or hamper the performance of various computer vision methods (e.g., SLAM, structure from motion, optical flow) used during the non invasive examination. The aim of this work is two-fold: i) to introduce a new synthetically generated data-set generated by a generative adversarial techniques and ii) and to explore both shallow based and deep learning-based image-enhancement methods in overexposed and underexposed lighting conditions. Best quantitative results (i.e., metric based results), were obtained by the deep-learnnig-based LMSPEC method,besides a running time around 7.6 fps)
Unfolded Deep Kernel Estimation for Blind Image Super-resolution
Mar 10, 2022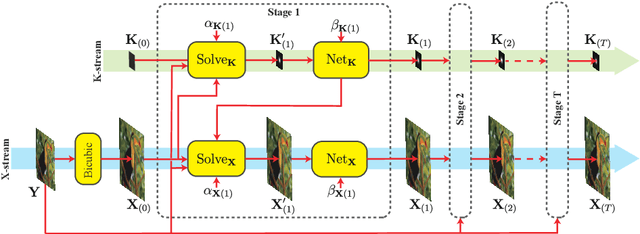
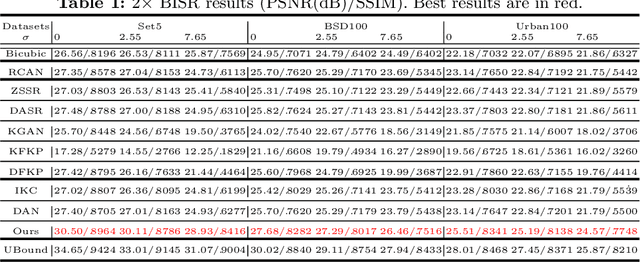

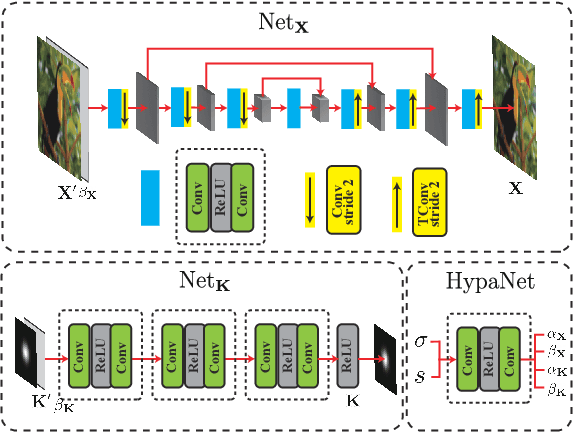
Blind image super-resolution (BISR) aims to reconstruct a high-resolution image from its low-resolution counterpart degraded by unknown blur kernel and noise. Many deep neural network based methods have been proposed to tackle this challenging problem without considering the image degradation model. However, they largely rely on the training sets and often fail to handle images with unseen blur kernels during inference. Deep unfolding methods have also been proposed to perform BISR by utilizing the degradation model. Nonetheless, the existing deep unfolding methods cannot explicitly solve the data term of the unfolding objective function, limiting their capability in blur kernel estimation. In this work, we propose a novel unfolded deep kernel estimation (UDKE) method, which, for the first time to our best knowledge, explicitly solves the data term with high efficiency. The UDKE based BISR method can jointly learn image and kernel priors in an end-to-end manner, and it can effectively exploit the information in both training data and image degradation model. Experiments on benchmark datasets and real-world data demonstrate that the proposed UDKE method could well predict complex unseen non-Gaussian blur kernels in inference, achieving significantly better BISR performance than state-of-the-art. The source code of UDKE is available at: https://github.com/natezhenghy/UDKE.
DGMIL: Distribution Guided Multiple Instance Learning for Whole Slide Image Classification
Jun 17, 2022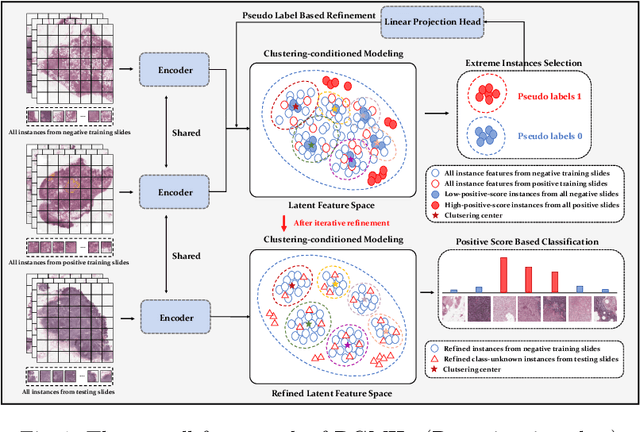
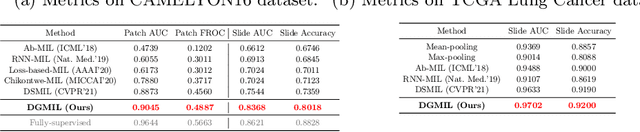

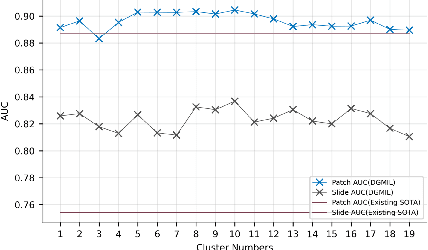
Multiple Instance Learning (MIL) is widely used in analyzing histopathological Whole Slide Images (WSIs). However, existing MIL methods do not explicitly model the data distribution, and instead they only learn a bag-level or instance-level decision boundary discriminatively by training a classifier. In this paper, we propose DGMIL: a feature distribution guided deep MIL framework for WSI classification and positive patch localization. Instead of designing complex discriminative network architectures, we reveal that the inherent feature distribution of histopathological image data can serve as a very effective guide for instance classification. We propose a cluster-conditioned feature distribution modeling method and a pseudo label-based iterative feature space refinement strategy so that in the final feature space the positive and negative instances can be easily separated. Experiments on the CAMELYON16 dataset and the TCGA Lung Cancer dataset show that our method achieves new SOTA for both global classification and positive patch localization tasks.
One Eye is All You Need: Lightweight Ensembles for Gaze Estimation with Single Encoders
Nov 22, 2022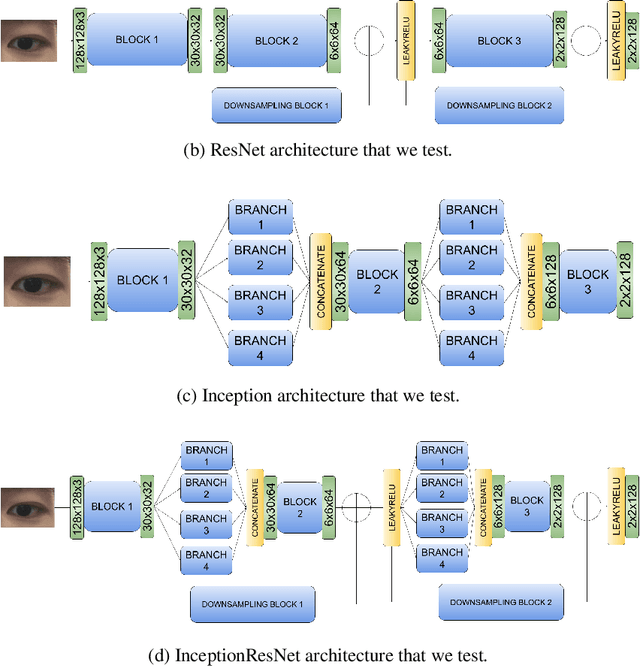

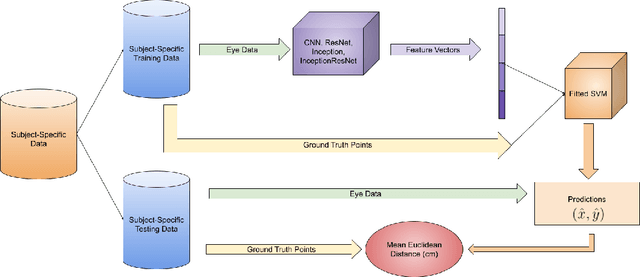
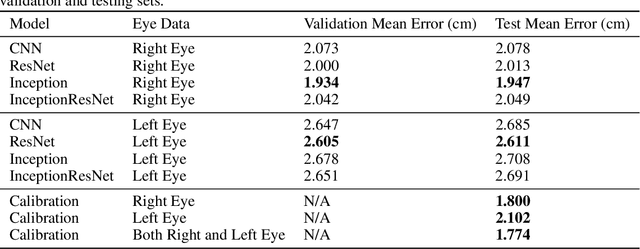
Gaze estimation has grown rapidly in accuracy in recent years. However, these models often fail to take advantage of different computer vision (CV) algorithms and techniques (such as small ResNet and Inception networks and ensemble models) that have been shown to improve results for other CV problems. Additionally, most current gaze estimation models require the use of either both eyes or an entire face, whereas real-world data may not always have both eyes in high resolution. Thus, we propose a gaze estimation model that implements the ResNet and Inception model architectures and makes predictions using only one eye image. Furthermore, we propose an ensemble calibration network that uses the predictions from several individual architectures for subject-specific predictions. With the use of lightweight architectures, we achieve high performance on the GazeCapture dataset with very low model parameter counts. When using two eyes as input, we achieve a prediction error of 1.591 cm on the test set without calibration and 1.439 cm with an ensemble calibration model. With just one eye as input, we still achieve an average prediction error of 2.312 cm on the test set without calibration and 1.951 cm with an ensemble calibration model. We also notice significantly lower errors on the right eye images in the test set, which could be important in the design of future gaze estimation-based tools.