 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers
Apr 28, 2022

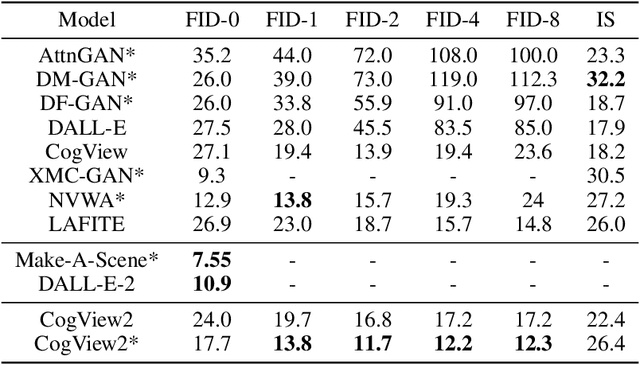
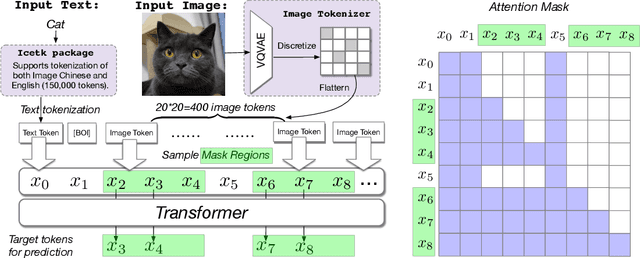

The development of the transformer-based text-to-image models are impeded by its slow generation and complexity for high-resolution images. In this work, we put forward a solution based on hierarchical transformers and local parallel auto-regressive generation. We pretrain a 6B-parameter transformer with a simple and flexible self-supervised task, Cross-modal general language model (CogLM), and finetune it for fast super-resolution. The new text-to-image system, CogView2, shows very competitive generation compared to concurrent state-of-the-art DALL-E-2, and naturally supports interactive text-guided editing on images.
A Multi-Head Convolutional Neural Network With Multi-path Attention improves Image Denoising
Apr 27, 2022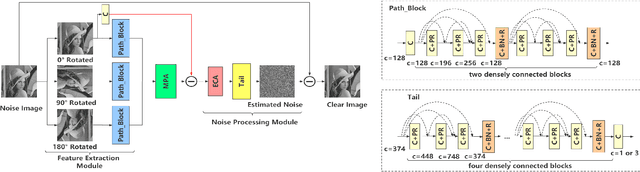
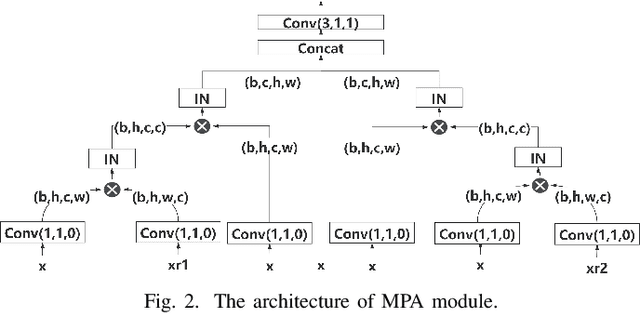


Recently, convolutional neural networks (CNNs) and attention mechanisms have been widely used in image denoising and achieved satisfactory performance. However, the previous works mostly use a single head to receive the noisy image, limiting the richness of extracted features. Therefore, a novel CNN with multiple heads (MH) named MHCNN is proposed in this paper, whose heads will receive the input images rotated by different rotation angles. MH makes MHCNN simultaneously utilize features of rotated images to remove noise. We also present a novel multi-path attention mechanism (MPA) to integrate these features effectively. Unlike previous attention mechanisms that handle pixel-level, channel-level, and patch-level features, MPA focuses on features at the image level. Experiments show MHCNN surpasses other state-of-the-art CNN models on additive white Gaussian noise (AWGN) denoising and real-world image denoising. Its peak signal-to-noise ratio (PSNR) results are higher than other networks, such as DnCNN, BRDNet, RIDNet, PAN-Net, and CSANN. It is also demonstrated that the proposed MH with MPA mechanism can be used as a pluggable component.
Interactive Image Synthesis with Panoptic Layout Generation
Mar 10, 2022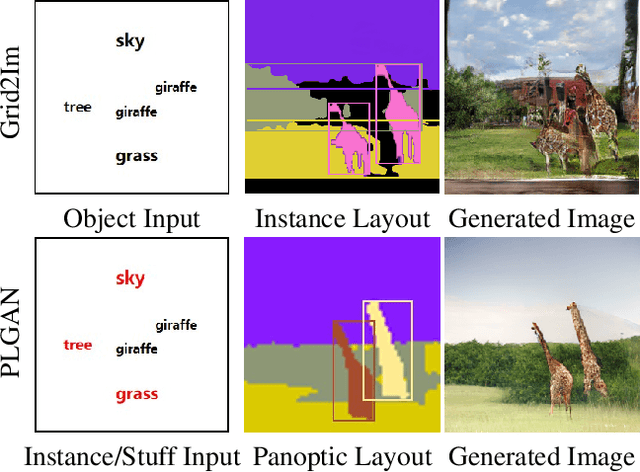
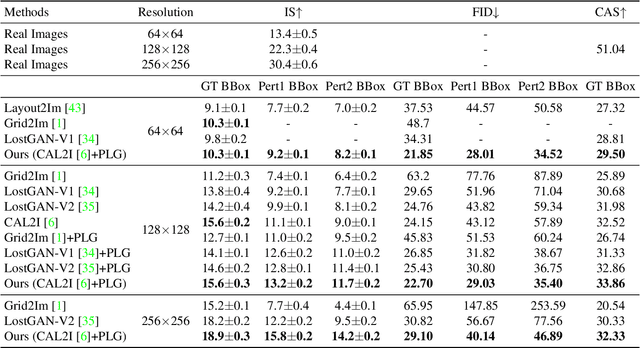
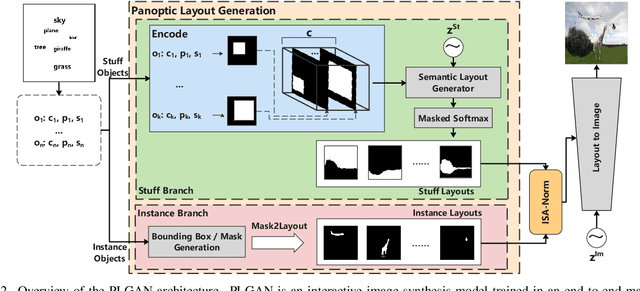
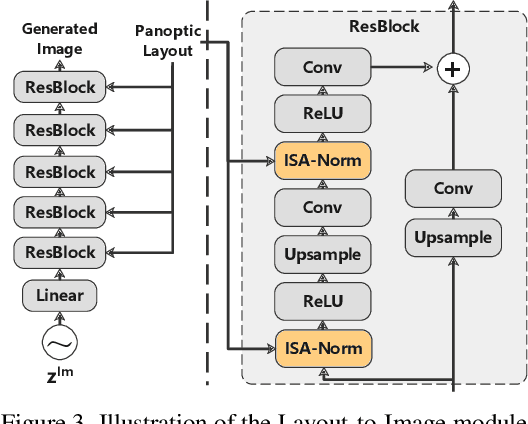
Interactive image synthesis from user-guided input is a challenging task when users wish to control the scene structure of a generated image with ease.Although remarkable progress has been made on layout-based image synthesis approaches, in order to get realistic fake image in interactive scene, existing methods require high-precision inputs, which probably need adjustment several times and are unfriendly to novice users. When placement of bounding boxes is subject to perturbation, layout-based models suffer from "missing regions" in the constructed semantic layouts and hence undesirable artifacts in the generated images. In this work, we propose Panoptic Layout Generative Adversarial Networks (PLGAN) to address this challenge. The PLGAN employs panoptic theory which distinguishes object categories between "stuff" with amorphous boundaries and "things" with well-defined shapes, such that stuff and instance layouts are constructed through separate branches and later fused into panoptic layouts. In particular, the stuff layouts can take amorphous shapes and fill up the missing regions left out by the instance layouts. We experimentally compare our PLGAN with state-of-the-art layout-based models on the COCO-Stuff, Visual Genome, and Landscape datasets. The advantages of PLGAN are not only visually demonstrated but quantitatively verified in terms of inception score, Fr\'echet inception distance, classification accuracy score, and coverage.
Exploring and Evaluating Image Restoration Potential in Dynamic Scenes
Mar 23, 2022
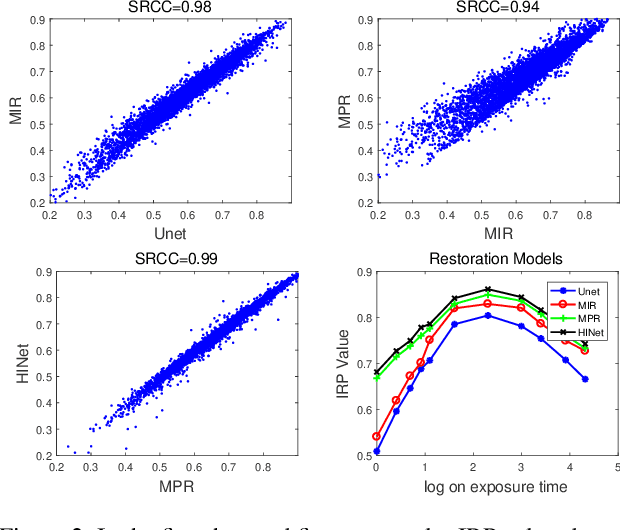
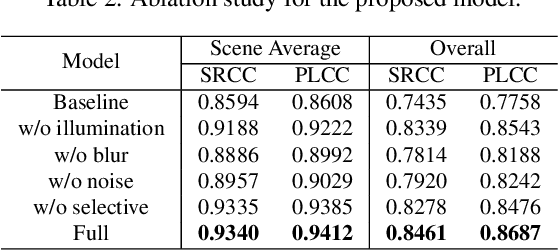
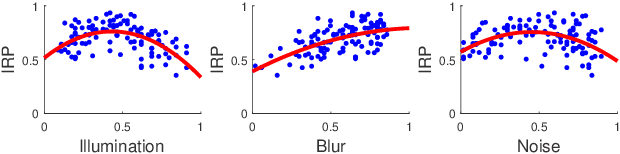
In dynamic scenes, images often suffer from dynamic blur due to superposition of motions or low signal-noise ratio resulted from quick shutter speed when avoiding motions. Recovering sharp and clean results from the captured images heavily depends on the ability of restoration methods and the quality of the input. Although existing research on image restoration focuses on developing models for obtaining better restored results, fewer have studied to evaluate how and which input image leads to superior restored quality. In this paper, to better study an image's potential value that can be explored for restoration, we propose a novel concept, referring to image restoration potential (IRP). Specifically, We first establish a dynamic scene imaging dataset containing composite distortions and applied image restoration processes to validate the rationality of the existence to IRP. Based on this dataset, we investigate several properties of IRP and propose a novel deep model to accurately predict IRP values. By gradually distilling and selective fusing the degradation features, the proposed model shows its superiority in IRP prediction. Thanks to the proposed model, we are then able to validate how various image restoration related applications are benefited from IRP prediction. We show the potential usages of IRP as a filtering principle to select valuable frames, an auxiliary guidance to improve restoration models, and even an indicator to optimize camera settings for capturing better images under dynamic scenarios.
Learning Granularity-Unified Representations for Text-to-Image Person Re-identification
Jul 16, 2022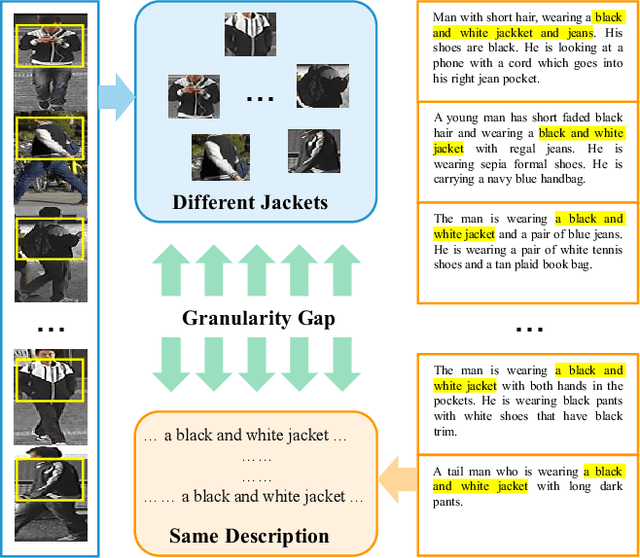
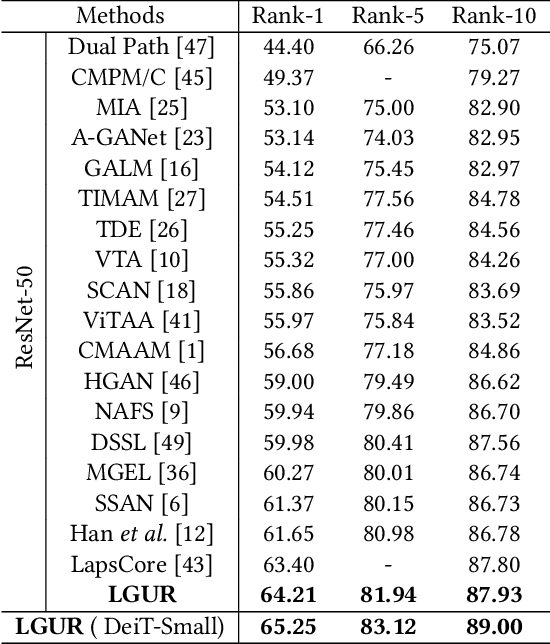
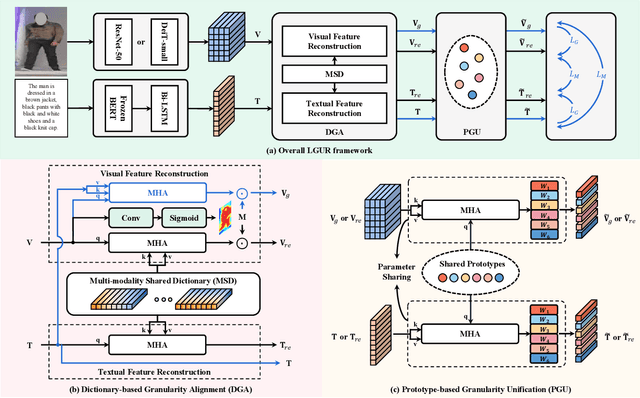
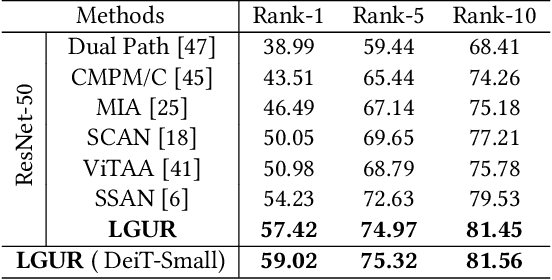
Text-to-image person re-identification (ReID) aims to search for pedestrian images of an interested identity via textual descriptions. It is challenging due to both rich intra-modal variations and significant inter-modal gaps. Existing works usually ignore the difference in feature granularity between the two modalities, i.e., the visual features are usually fine-grained while textual features are coarse, which is mainly responsible for the large inter-modal gaps. In this paper, we propose an end-to-end framework based on transformers to learn granularity-unified representations for both modalities, denoted as LGUR. LGUR framework contains two modules: a Dictionary-based Granularity Alignment (DGA) module and a Prototype-based Granularity Unification (PGU) module. In DGA, in order to align the granularities of two modalities, we introduce a Multi-modality Shared Dictionary (MSD) to reconstruct both visual and textual features. Besides, DGA has two important factors, i.e., the cross-modality guidance and the foreground-centric reconstruction, to facilitate the optimization of MSD. In PGU, we adopt a set of shared and learnable prototypes as the queries to extract diverse and semantically aligned features for both modalities in the granularity-unified feature space, which further promotes the ReID performance. Comprehensive experiments show that our LGUR consistently outperforms state-of-the-arts by large margins on both CUHK-PEDES and ICFG-PEDES datasets. Code will be released at https://github.com/ZhiyinShao-H/LGUR.
Where to Pay Attention in Sparse Training for Feature Selection?
Nov 26, 2022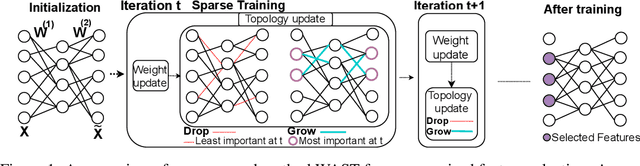
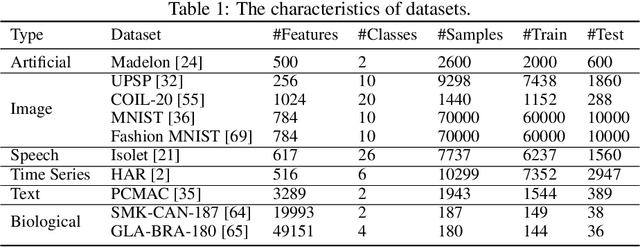
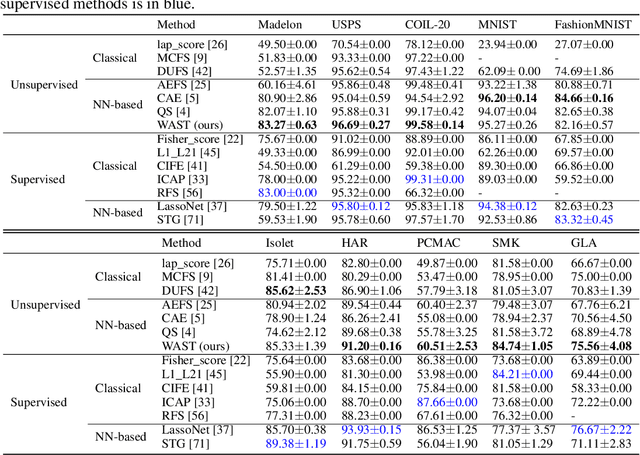
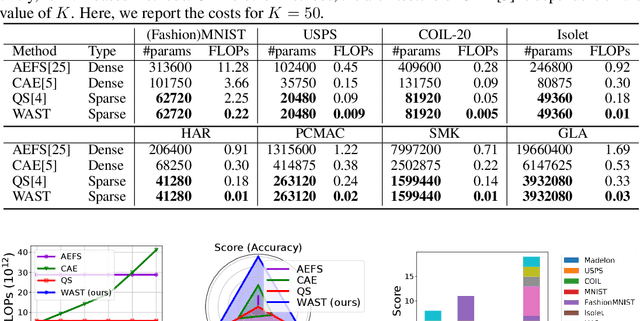
A new line of research for feature selection based on neural networks has recently emerged. Despite its superiority to classical methods, it requires many training iterations to converge and detect informative features. The computational time becomes prohibitively long for datasets with a large number of samples or a very high dimensional feature space. In this paper, we present a new efficient unsupervised method for feature selection based on sparse autoencoders. In particular, we propose a new sparse training algorithm that optimizes a model's sparse topology during training to pay attention to informative features quickly. The attention-based adaptation of the sparse topology enables fast detection of informative features after a few training iterations. We performed extensive experiments on 10 datasets of different types, including image, speech, text, artificial, and biological. They cover a wide range of characteristics, such as low and high-dimensional feature spaces, and few and large training samples. Our proposed approach outperforms the state-of-the-art methods in terms of selecting informative features while reducing training iterations and computational costs substantially. Moreover, the experiments show the robustness of our method in extremely noisy environments.
Box2Mask: Box-supervised Instance Segmentation via Level-set Evolution
Dec 03, 2022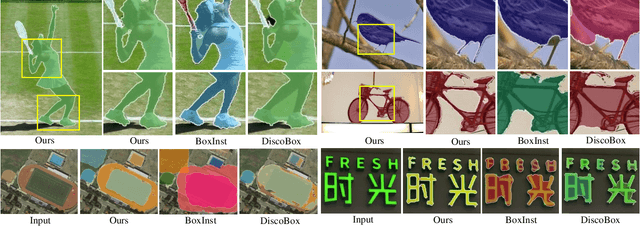
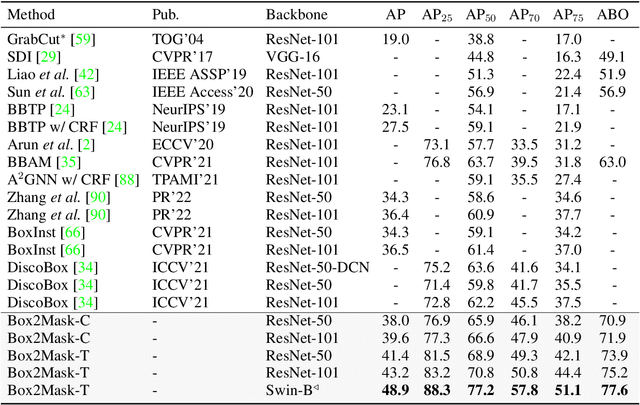
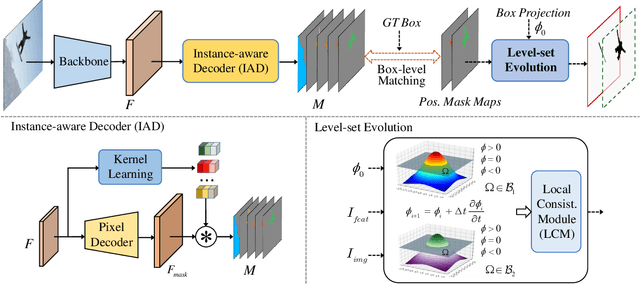
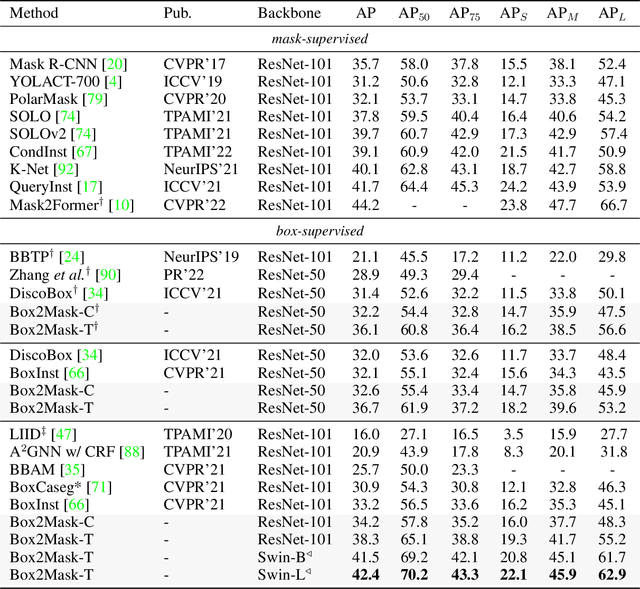
In contrast to fully supervised methods using pixel-wise mask labels, box-supervised instance segmentation takes advantage of simple box annotations, which has recently attracted increasing research attention. This paper presents a novel single-shot instance segmentation approach, namely Box2Mask, which integrates the classical level-set evolution model into deep neural network learning to achieve accurate mask prediction with only bounding box supervision. Specifically, both the input image and its deep features are employed to evolve the level-set curves implicitly, and a local consistency module based on a pixel affinity kernel is used to mine the local context and spatial relations. Two types of single-stage frameworks, i.e., CNN-based and transformer-based frameworks, are developed to empower the level-set evolution for box-supervised instance segmentation, and each framework consists of three essential components: instance-aware decoder, box-level matching assignment and level-set evolution. By minimizing the level-set energy function, the mask map of each instance can be iteratively optimized within its bounding box annotation. The experimental results on five challenging testbeds, covering general scenes, remote sensing, medical and scene text images, demonstrate the outstanding performance of our proposed Box2Mask approach for box-supervised instance segmentation. In particular, with the Swin-Transformer large backbone, our Box2Mask obtains 42.4% mask AP on COCO, which is on par with the recently developed fully mask-supervised methods. The code is available at: https://github.com/LiWentomng/boxlevelset.
Beyond ADMM: A Unified Client-variance-reduced Adaptive Federated Learning Framework
Dec 03, 2022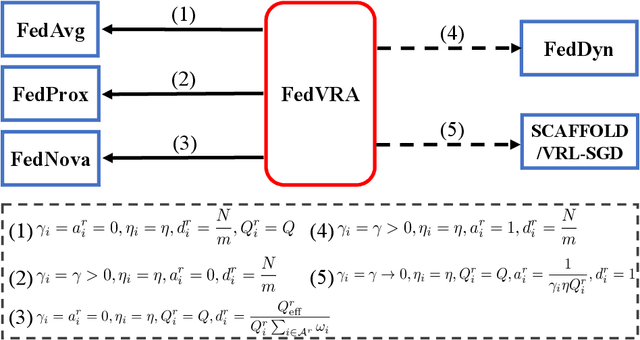
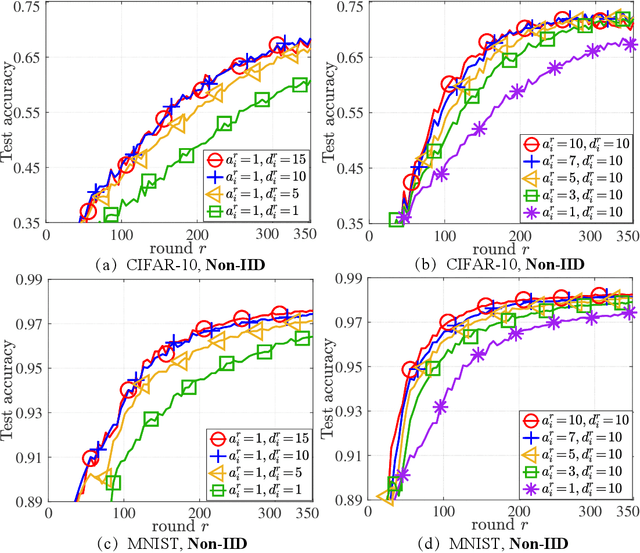
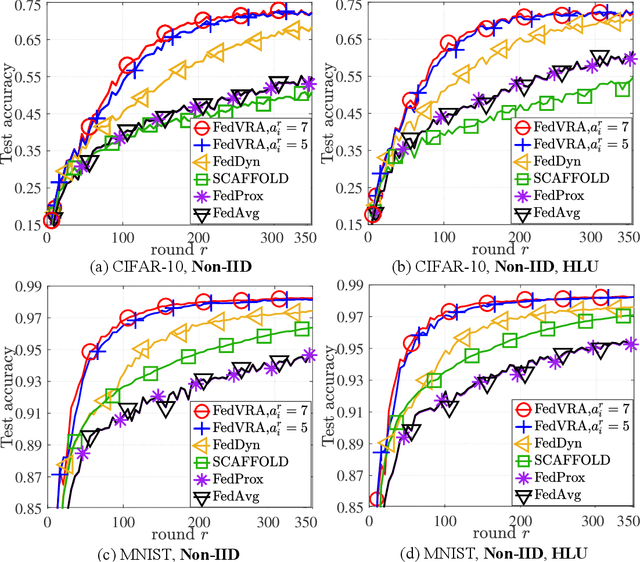
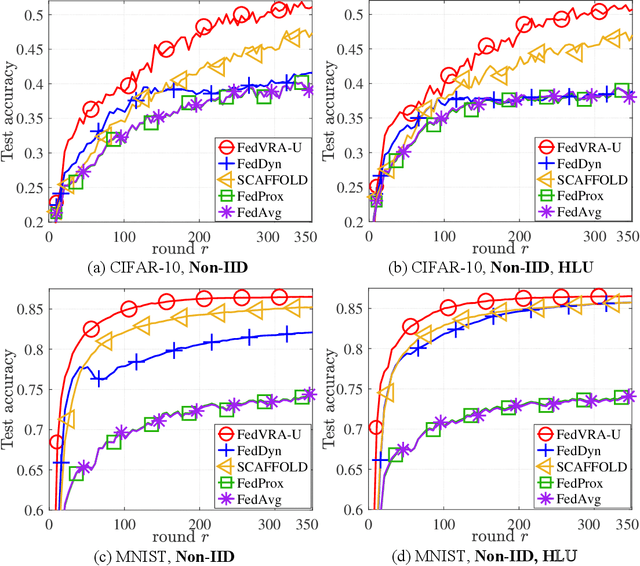
As a novel distributed learning paradigm, federated learning (FL) faces serious challenges in dealing with massive clients with heterogeneous data distribution and computation and communication resources. Various client-variance-reduction schemes and client sampling strategies have been respectively introduced to improve the robustness of FL. Among others, primal-dual algorithms such as the alternating direction of method multipliers (ADMM) have been found being resilient to data distribution and outperform most of the primal-only FL algorithms. However, the reason behind remains a mystery still. In this paper, we firstly reveal the fact that the federated ADMM is essentially a client-variance-reduced algorithm. While this explains the inherent robustness of federated ADMM, the vanilla version of it lacks the ability to be adaptive to the degree of client heterogeneity. Besides, the global model at the server under client sampling is biased which slows down the practical convergence. To go beyond ADMM, we propose a novel primal-dual FL algorithm, termed FedVRA, that allows one to adaptively control the variance-reduction level and biasness of the global model. In addition, FedVRA unifies several representative FL algorithms in the sense that they are either special instances of FedVRA or are close to it. Extensions of FedVRA to semi/un-supervised learning are also presented. Experiments based on (semi-)supervised image classification tasks demonstrate superiority of FedVRA over the existing schemes in learning scenarios with massive heterogeneous clients and client sampling.
Analysis of the performance of U-Net neural networks for the segmentation of living cells
Oct 04, 2022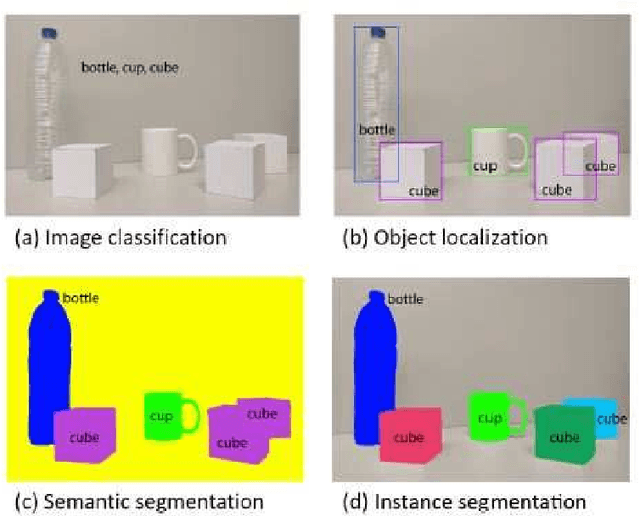
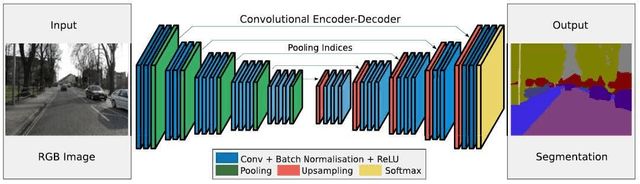
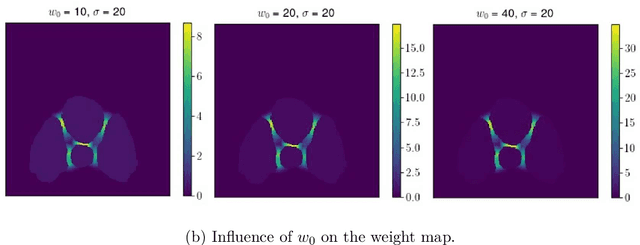
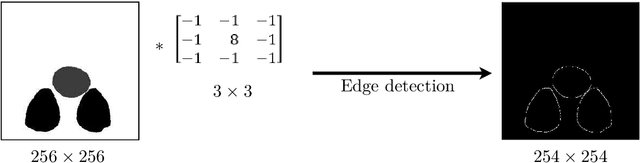
The automated analysis of microscopy images is a challenge in the context of single-cell tracking and quantification. This work has as goals the study of the performance of deep learning for segmenting microscopy images and the improvement of the previously available pipeline for tracking single cells. Deep learning techniques, mainly convolutional neural networks, have been applied to cell segmentation problems and have shown high accuracy and fast performance. To perform the image segmentation, an analysis of hyperparameters was done in order to implement a convolutional neural network with U-Net architecture. Furthermore, different models were built in order to optimize the size of the network and the number of learnable parameters. The trained network is then used in the pipeline that localizes the traps in a microfluidic device, performs the image segmentation on trap images, and evaluates the fluorescence intensity and the area of single cells over time. The tracking of the cells during an experiment is performed by image processing algorithms, such as centroid estimation and watershed. Finally, with all improvements in the neural network to segment single cells and in the pipeline, quasi-real-time image analysis was enabled, where 6.20GB of data was processed in 4 minutes.
Unsupervised Cross-Domain Feature Extraction for Single Blood Cell Image Classification
Jul 01, 2022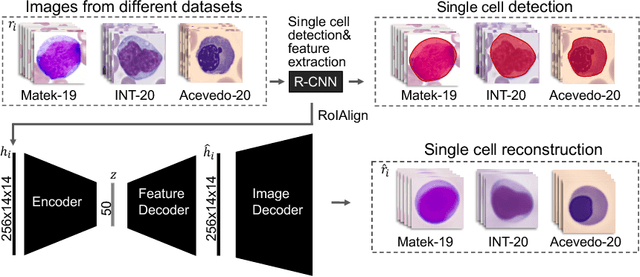
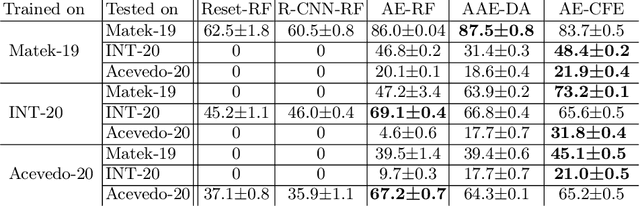
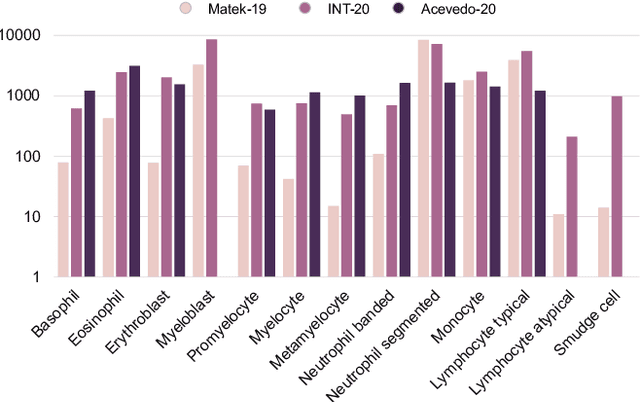
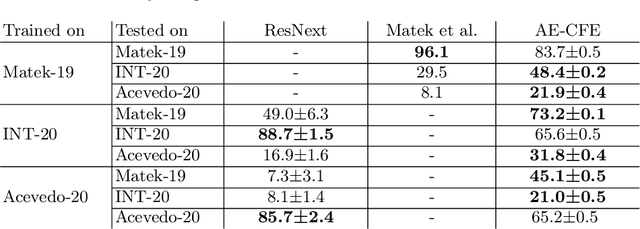
Diagnosing hematological malignancies requires identification and classification of white blood cells in peripheral blood smears. Domain shifts caused by different lab procedures, staining, illumination, and microscope settings hamper the re-usability of recently developed machine learning methods on data collected from different sites. Here, we propose a cross-domain adapted autoencoder to extract features in an unsupervised manner on three different datasets of single white blood cells scanned from peripheral blood smears. The autoencoder is based on an R-CNN architecture allowing it to focus on the relevant white blood cell and eliminate artifacts in the image. To evaluate the quality of the extracted features we use a simple random forest to classify single cells. We show that thanks to the rich features extracted by the autoencoder trained on only one of the datasets, the random forest classifier performs satisfactorily on the unseen datasets, and outperforms published oracle networks in the cross-domain task. Our results suggest the possibility of employing this unsupervised approach in more complicated diagnosis and prognosis tasks without the need to add expensive expert labels to unseen data.