 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Model-based Reconstruction for Multi-Frequency Collimated Beam Ultrasound Systems
Nov 29, 2022
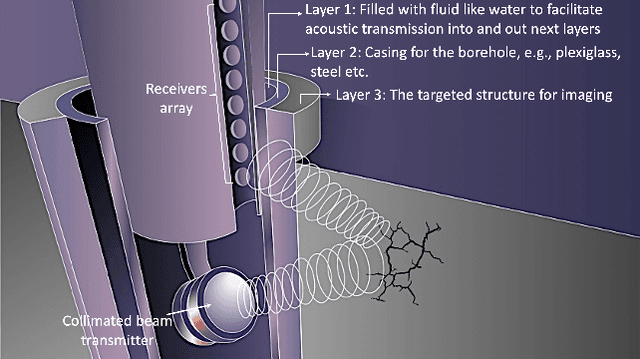
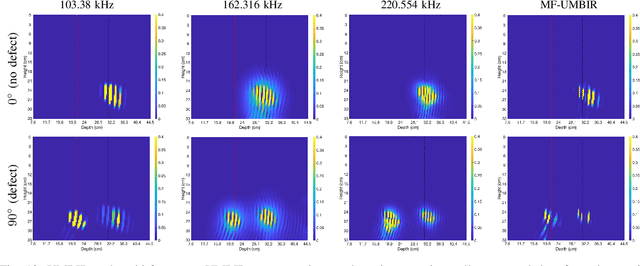
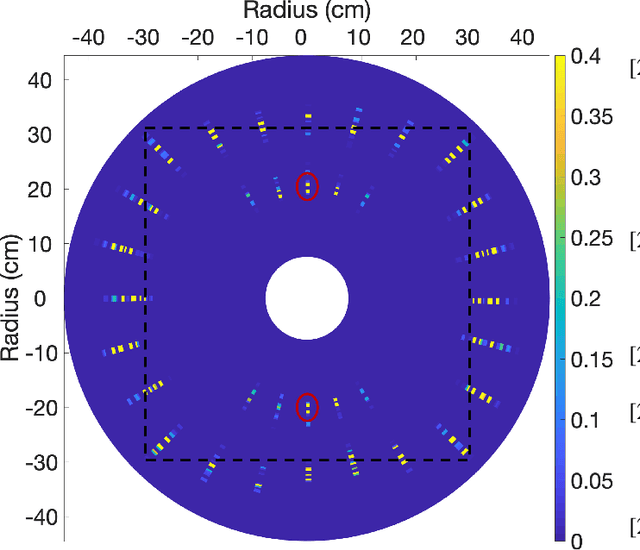
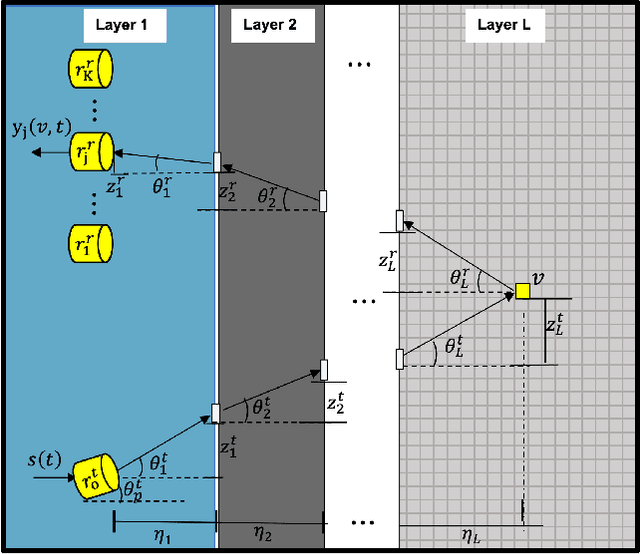
Collimated beam ultrasound systems are a technology for imaging inside multi-layered structures such as geothermal wells. These systems work by using a collimated narrow-band ultrasound transmitter that can penetrate through multiple layers of heterogeneous material. A series of measurements can then be made at multiple transmit frequencies. However, commonly used reconstruction algorithms such as Synthetic Aperture Focusing Technique (SAFT) tend to produce poor quality reconstructions for these systems both because they do not model collimated beam systems and they do not jointly reconstruct the multiple frequencies. In this paper, we propose a multi-frequency ultrasound model-based iterative reconstruction (UMBIR) algorithm designed for multi-frequency collimated beam ultrasound systems. The combined system targets reflective imaging of heterogeneous, multi-layered structures. For each transmitted frequency band, we introduce a physics-based forward model to accurately account for the propagation of the collimated narrow-band ultrasonic beam through the multi-layered media. We then show how the joint multi-frequency UMBIR reconstruction can be computed by modeling the direct arrival signals, detector noise, and incorporating a spatially varying image prior. Results using both simulated and experimental data indicate that multi-frequency UMBIR reconstruction yields much higher reconstruction quality than either single frequency UMBIR or SAFT.
SAC-GAN: Structure-Aware Image-to-Image Composition for Self-Driving
Jan 08, 2022
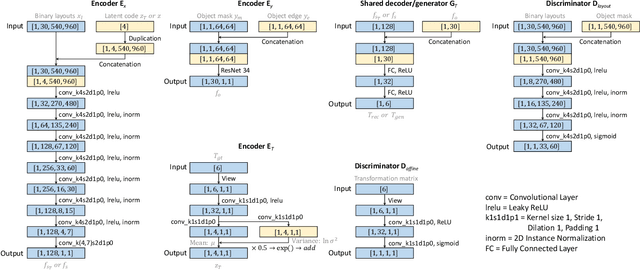
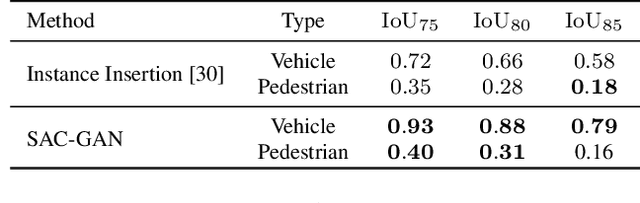

We present a compositional approach to image augmentation for self-driving applications. It is an end-to-end neural network that is trained to seamlessly compose an object (e.g., a vehicle or pedestrian) represented as a cropped patch from an object image, into a background scene image. As our approach emphasizes more on semantic and structural coherence of the composed images, rather than their pixel-level RGB accuracies, we tailor the input and output of our network with structure-aware features and design our network losses accordingly. Specifically, our network takes the semantic layout features from the input scene image, features encoded from the edges and silhouette in the input object patch, as well as a latent code as inputs, and generates a 2D spatial affine transform defining the translation and scaling of the object patch. The learned parameters are further fed into a differentiable spatial transformer network to transform the object patch into the target image, where our model is trained adversarially using an affine transform discriminator and a layout discriminator. We evaluate our network, coined SAC-GAN for structure-aware composition, on prominent self-driving datasets in terms of quality, composability, and generalizability of the composite images. Comparisons are made to state-of-the-art alternatives, confirming superiority of our method.
StereoPose: Category-Level 6D Transparent Object Pose Estimation from Stereo Images via Back-View NOCS
Nov 03, 2022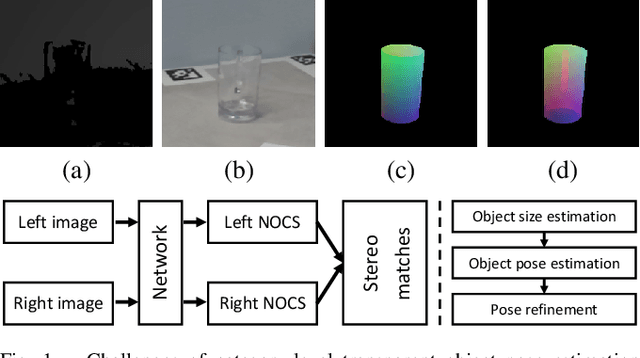
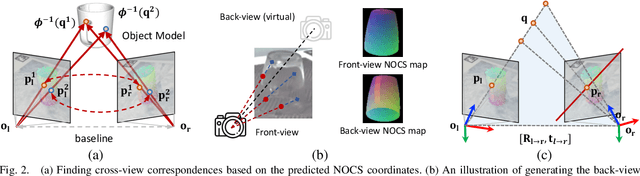
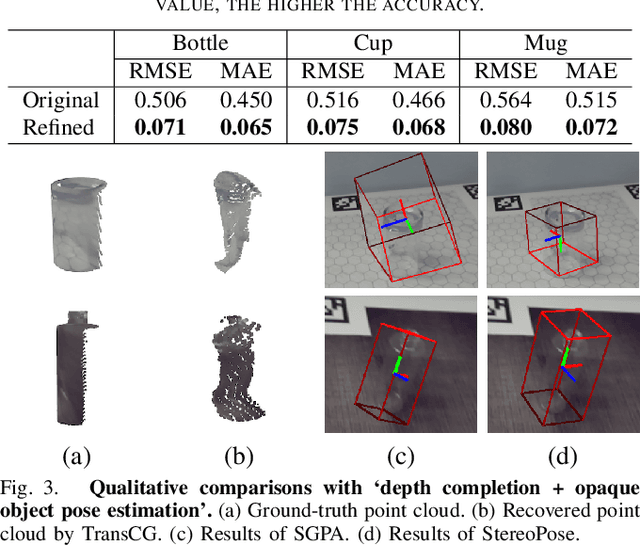
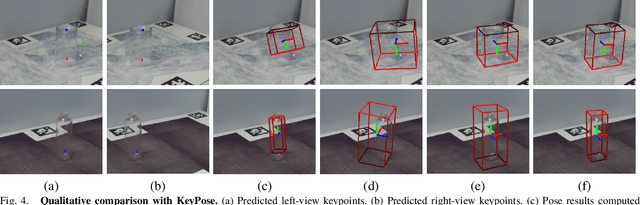
Most existing methods for category-level pose estimation rely on object point clouds. However, when considering transparent objects, depth cameras are usually not able to capture meaningful data, resulting in point clouds with severe artifacts. Without a high-quality point cloud, existing methods are not applicable to challenging transparent objects. To tackle this problem, we present StereoPose, a novel stereo image framework for category-level object pose estimation, ideally suited for transparent objects. For a robust estimation from pure stereo images, we develop a pipeline that decouples category-level pose estimation into object size estimation, initial pose estimation, and pose refinement. StereoPose then estimates object pose based on representation in the normalized object coordinate space~(NOCS). To address the issue of image content aliasing, we further define a back-view NOCS map for the transparent object. The back-view NOCS aims to reduce the network learning ambiguity caused by content aliasing, and leverage informative cues on the back of the transparent object for more accurate pose estimation. To further improve the performance of the stereo framework, StereoPose is equipped with a parallax attention module for stereo feature fusion and an epipolar loss for improving the stereo-view consistency of network predictions. Extensive experiments on the public TOD dataset demonstrate the superiority of the proposed StereoPose framework for category-level 6D transparent object pose estimation.
Multi-Scale Structural-aware Exposure Correction for Endoscopic Imaging
Oct 26, 2022
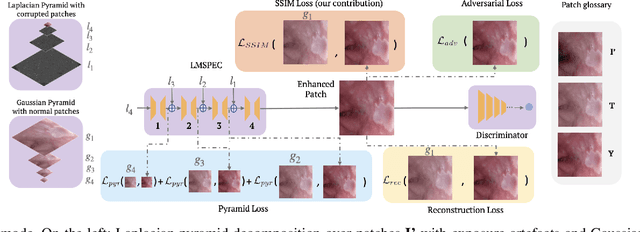
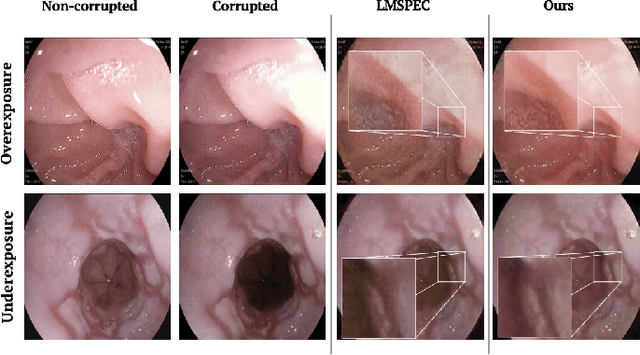
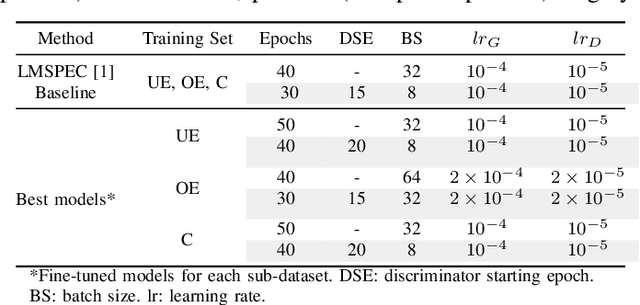
Endoscopy is the most widely used imaging technique for the diagnosis of cancerous lesions in hollow organs. However, endoscopic images are often affected by illumination artefacts: image parts may be over- or underexposed according to the light source pose and the tissue orientation. These artifacts have a strong negative impact on the performance of computer vision or AI-based diagnosis tools. Although endoscopic image enhancement methods are greatly required, little effort has been devoted to over- and under-exposition enhancement in real-time. This contribution presents an extension to the objective function of LMSPEC, a method originally introduced to enhance images from natural scenes. It is used here for the exposure correction in endoscopic imaging and the preservation of structural information. To the best of our knowledge, this contribution is the first one that addresses the enhancement of endoscopic images using deep learning (DL) methods. Tested on the Endo4IE dataset, the proposed implementation has yielded a significant improvement over LMSPEC reaching a SSIM increase of 4.40% and 4.21% for over- and underexposed images, respectively.
Extending Phrase Grounding with Pronouns in Visual Dialogues
Oct 23, 2022
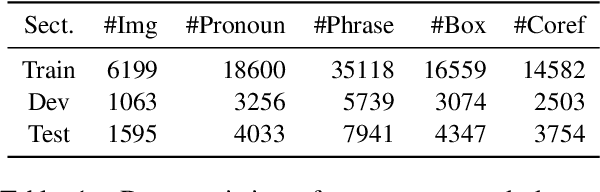

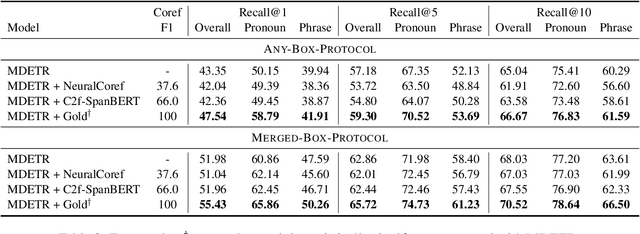
Conventional phrase grounding aims to localize noun phrases mentioned in a given caption to their corresponding image regions, which has achieved great success recently. Apparently, sole noun phrase grounding is not enough for cross-modal visual language understanding. Here we extend the task by considering pronouns as well. First, we construct a dataset of phrase grounding with both noun phrases and pronouns to image regions. Based on the dataset, we test the performance of phrase grounding by using a state-of-the-art literature model of this line. Then, we enhance the baseline grounding model with coreference information which should help our task potentially, modeling the coreference structures with graph convolutional networks. Experiments on our dataset, interestingly, show that pronouns are easier to ground than noun phrases, where the possible reason might be that these pronouns are much less ambiguous. Additionally, our final model with coreference information can significantly boost the grounding performance of both noun phrases and pronouns.
ReSTR: Convolution-free Referring Image Segmentation Using Transformers
Mar 31, 2022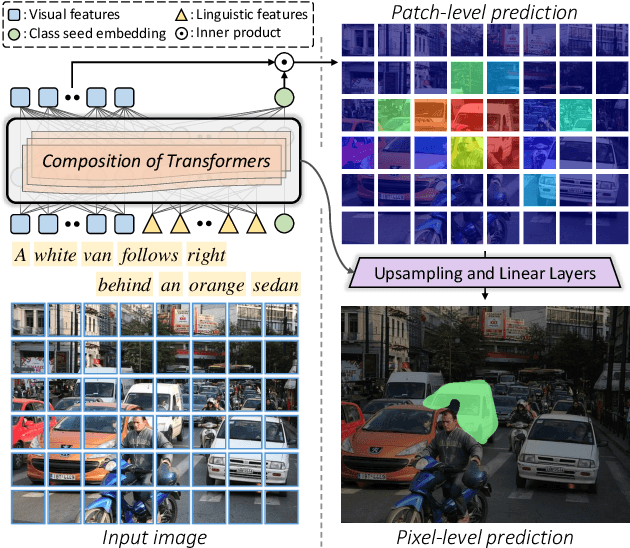
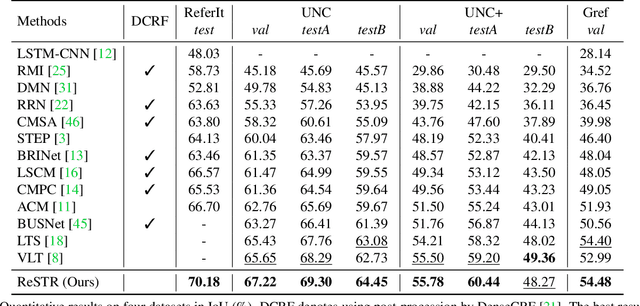
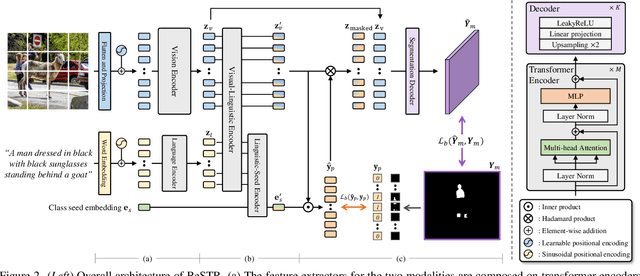
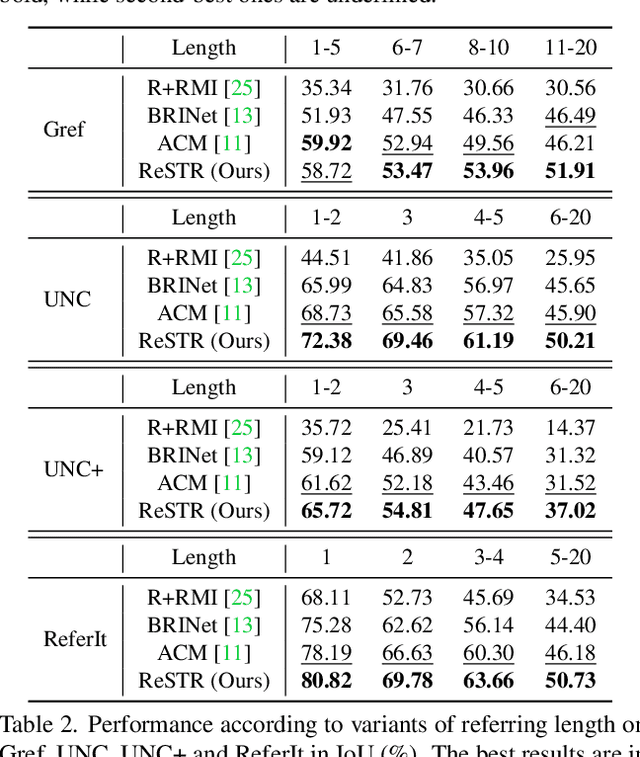
Referring image segmentation is an advanced semantic segmentation task where target is not a predefined class but is described in natural language. Most of existing methods for this task rely heavily on convolutional neural networks, which however have trouble capturing long-range dependencies between entities in the language expression and are not flexible enough for modeling interactions between the two different modalities. To address these issues, we present the first convolution-free model for referring image segmentation using transformers, dubbed ReSTR. Since it extracts features of both modalities through transformer encoders, it can capture long-range dependencies between entities within each modality. Also, ReSTR fuses features of the two modalities by a self-attention encoder, which enables flexible and adaptive interactions between the two modalities in the fusion process. The fused features are fed to a segmentation module, which works adaptively according to the image and language expression in hand. ReSTR is evaluated and compared with previous work on all public benchmarks, where it outperforms all existing models.
Rolling Shutter Inversion: Bring Rolling Shutter Images to High Framerate Global Shutter Video
Oct 06, 2022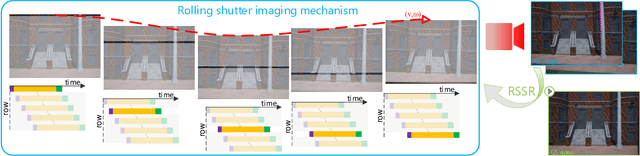
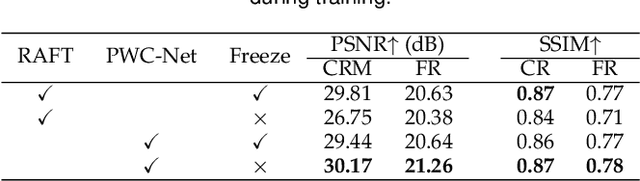
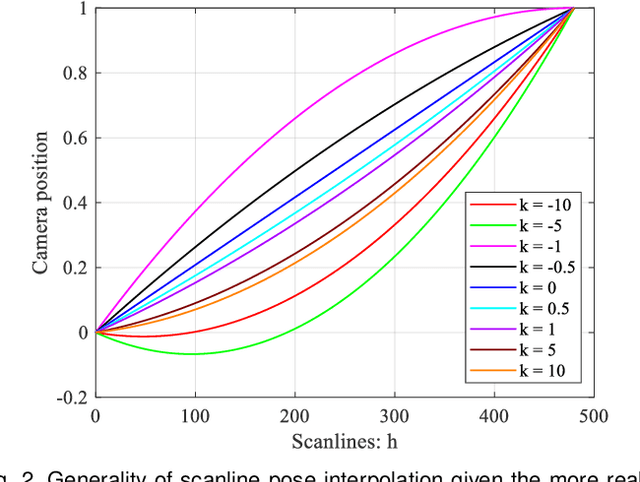
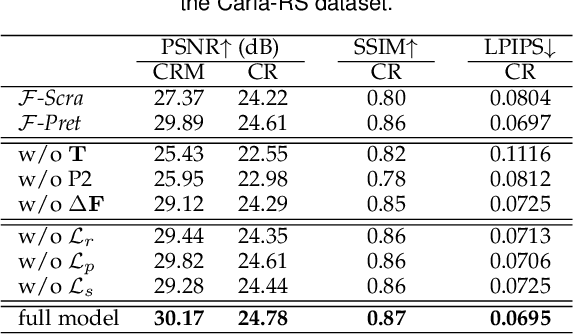
A single rolling-shutter (RS) image may be viewed as a row-wise combination of a sequence of global-shutter (GS) images captured by a (virtual) moving GS camera within the exposure duration. Although RS cameras are widely used, the RS effect causes obvious image distortion especially in the presence of fast camera motion, hindering downstream computer vision tasks. In this paper, we propose to invert the RS image capture mechanism, i.e., recovering a continuous high framerate GS video from two time-consecutive RS frames. We call this task the RS temporal super-resolution (RSSR) problem. The RSSR is a very challenging task, and to our knowledge, no practical solution exists to date. This paper presents a novel deep-learning based solution. By leveraging the multi-view geometry relationship of the RS imaging process, our learning-based framework successfully achieves high framerate GS generation. Specifically, three novel contributions can be identified: (i) novel formulations for bidirectional RS undistortion flows under constant velocity as well as constant acceleration motion model. (ii) a simple linear scaling operation, which bridges the RS undistortion flow and regular optical flow. (iii) a new mutual conversion scheme between varying RS undistortion flows that correspond to different scanlines. Our method also exploits the underlying spatial-temporal geometric relationships within a deep learning framework, where no additional supervision is required beyond the necessary middle-scanline GS image. Building upon these contributions, we represent the very first rolling-shutter temporal super-resolution deep-network that is able to recover high framerate GS videos from just two RS frames. Extensive experimental results on both synthetic and real data show that our proposed method can produce high-quality GS image sequences with rich details, outperforming the state-of-the-art methods.
Word to Sentence Visual Semantic Similarity for Caption Generation: Lessons Learned
Sep 26, 2022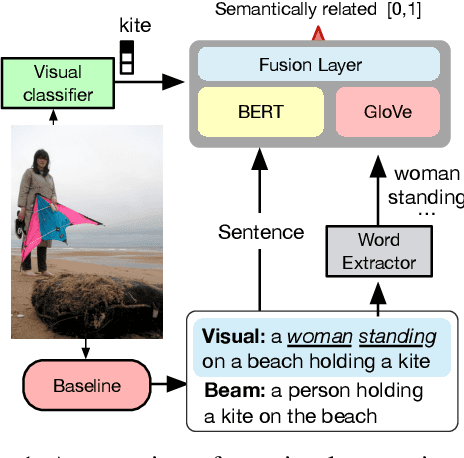
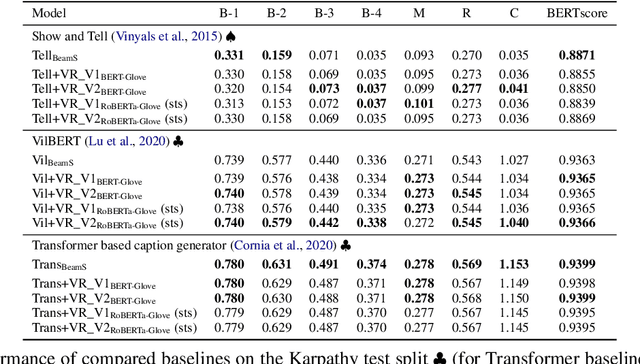
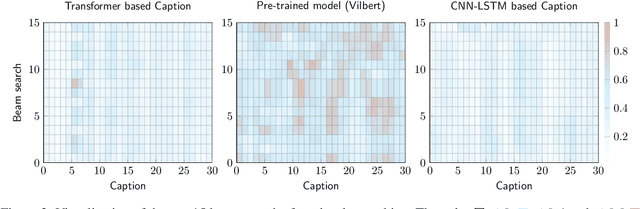
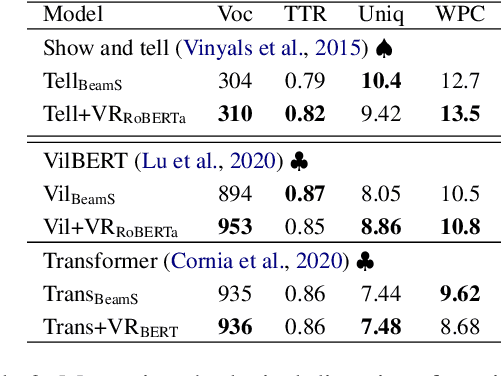
This paper focuses on enhancing the captions generated by image-caption generation systems. We propose an approach for improving caption generation systems by choosing the most closely related output to the image rather than the most likely output produced by the model. Our model revises the language generation output beam search from a visual context perspective. We employ a visual semantic measure in a word and sentence level manner to match the proper caption to the related information in the image. The proposed approach can be applied to any caption system as a post-processing based method.
FoPro: Few-Shot Guided Robust Webly-Supervised Prototypical Learning
Dec 01, 2022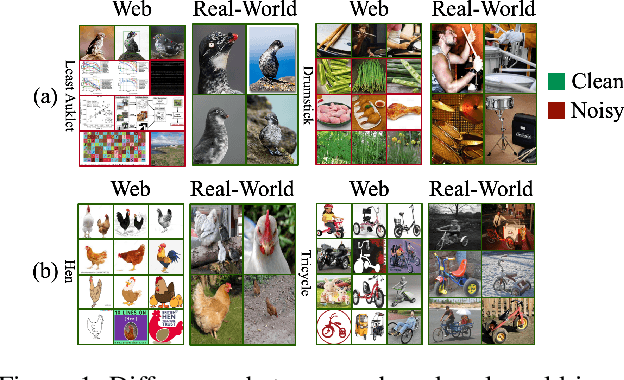
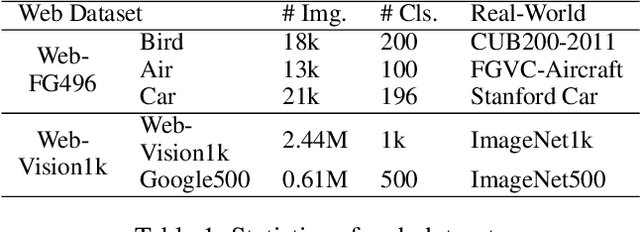
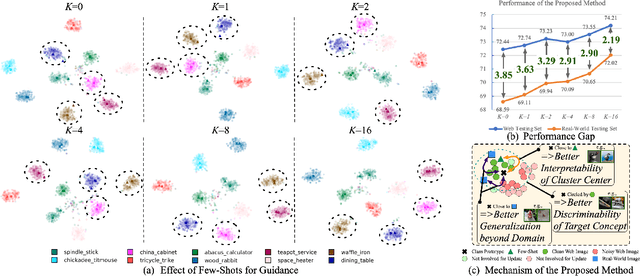
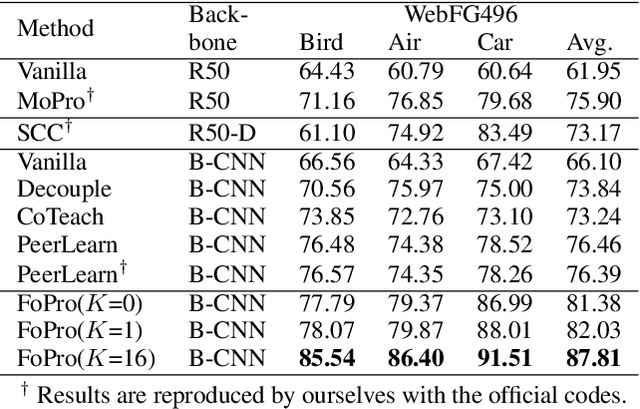
Recently, webly supervised learning (WSL) has been studied to leverage numerous and accessible data from the Internet. Most existing methods focus on learning noise-robust models from web images while neglecting the performance drop caused by the differences between web domain and real-world domain. However, only by tackling the performance gap above can we fully exploit the practical value of web datasets. To this end, we propose a Few-shot guided Prototypical (FoPro) representation learning method, which only needs a few labeled examples from reality and can significantly improve the performance in the real-world domain. Specifically, we initialize each class center with few-shot real-world data as the ``realistic" prototype. Then, the intra-class distance between web instances and ``realistic" prototypes is narrowed by contrastive learning. Finally, we measure image-prototype distance with a learnable metric. Prototypes are polished by adjacent high-quality web images and involved in removing distant out-of-distribution samples. In experiments, FoPro is trained on web datasets with a few real-world examples guided and evaluated on real-world datasets. Our method achieves the state-of-the-art performance on three fine-grained datasets and two large-scale datasets. Compared with existing WSL methods under the same few-shot settings, FoPro still excels in real-world generalization. Code is available at https://github.com/yuleiqin/fopro.
Efficient stereo matching on embedded GPUs with zero-means cross correlation
Dec 01, 2022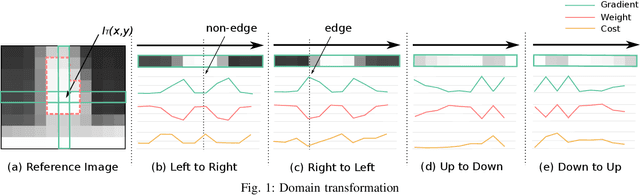
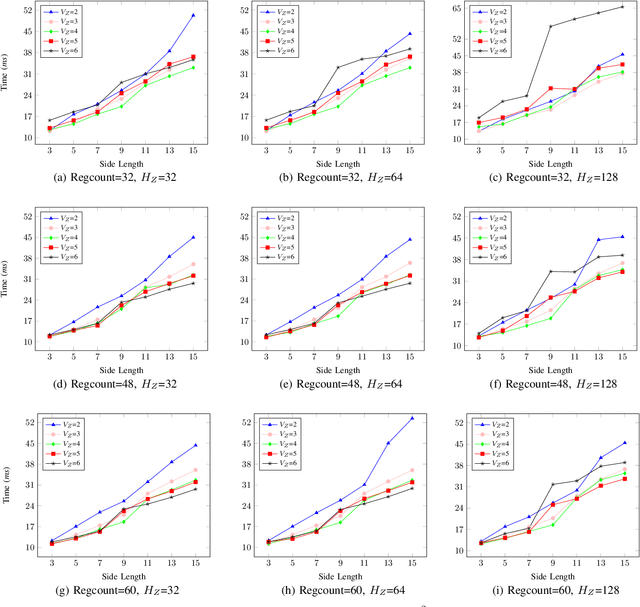
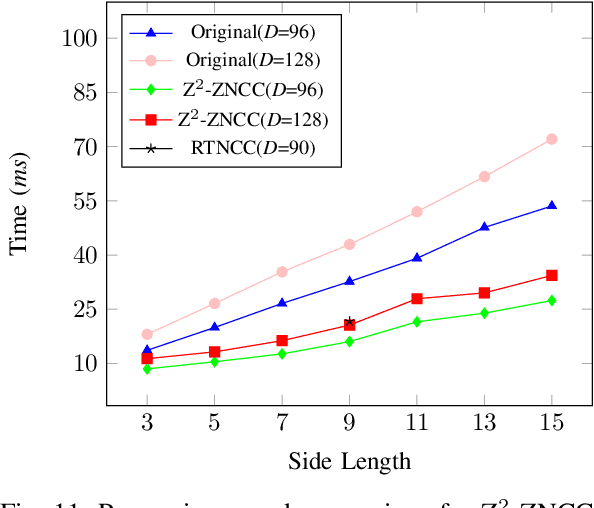
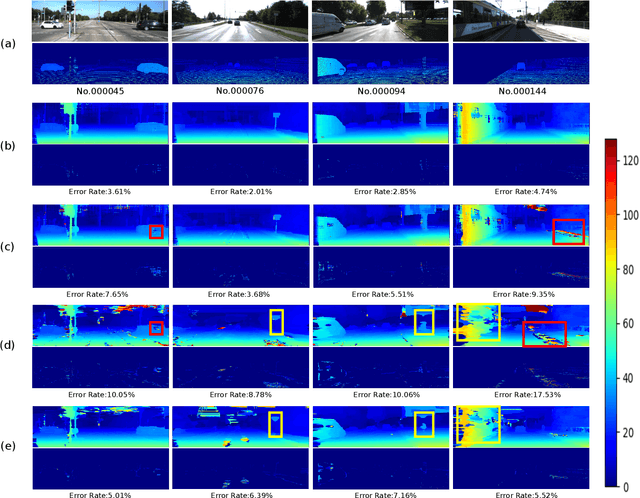
Mobile stereo-matching systems have become an important part of many applications, such as automated-driving vehicles and autonomous robots. Accurate stereo-matching methods usually lead to high computational complexity; however, mobile platforms have only limited hardware resources to keep their power consumption low; this makes it difficult to maintain both an acceptable processing speed and accuracy on mobile platforms. To resolve this trade-off, we herein propose a novel acceleration approach for the well-known zero-means normalized cross correlation (ZNCC) matching cost calculation algorithm on a Jetson Tx2 embedded GPU. In our method for accelerating ZNCC, target images are scanned in a zigzag fashion to efficiently reuse one pixel's computation for its neighboring pixels; this reduces the amount of data transmission and increases the utilization of on-chip registers, thus increasing the processing speed. As a result, our method is 2X faster than the traditional image scanning method, and 26% faster than the latest NCC method. By combining this technique with the domain transformation (DT) algorithm, our system show real-time processing speed of 32 fps, on a Jetson Tx2 GPU for 1,280x384 pixel images with a maximum disparity of 128. Additionally, the evaluation results on the KITTI 2015 benchmark show that our combined system is more accurate than the same algorithm combined with census by 7.26%, while maintaining almost the same processing speed.