 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High-Perceptual Quality JPEG Decoding via Posterior Sampling
Nov 21, 2022

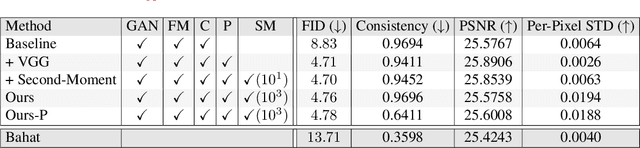
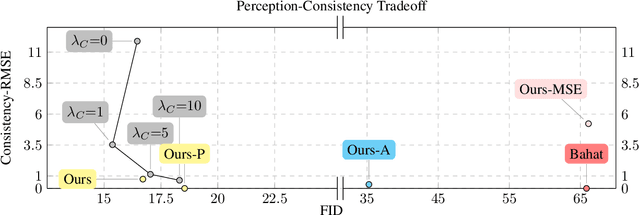
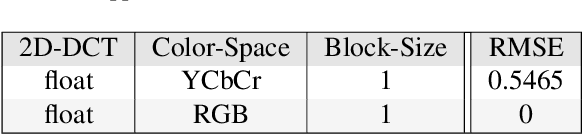
JPEG is arguably the most popular image coding format, achieving high compression ratios via lossy quantization that may create visual artifacts degradation. Numerous attempts to remove these artifacts were conceived over the years, and common to most of these is the use of deterministic post-processing algorithms that optimize some distortion measure (e.g., PSNR, SSIM). In this paper we propose a different paradigm for JPEG artifact correction: Our method is stochastic, and the objective we target is high perceptual quality -- striving to obtain sharp, detailed and visually pleasing reconstructed images, while being consistent with the compressed input. These goals are achieved by training a stochastic conditional generator (conditioned on the compressed input), accompanied by a theoretically well-founded loss term, resulting in a sampler from the posterior distribution. Our solution offers a diverse set of plausible and fast reconstructions for a given input with perfect consistency. We demonstrate our scheme's unique properties and its superiority to a variety of alternative methods on the FFHQ and ImageNet datasets.
Perceiver-VL: Efficient Vision-and-Language Modeling with Iterative Latent Attention
Nov 21, 2022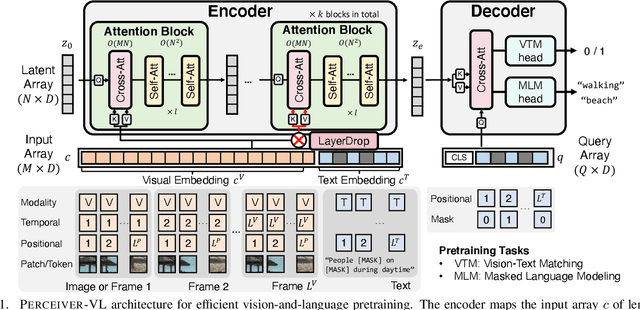
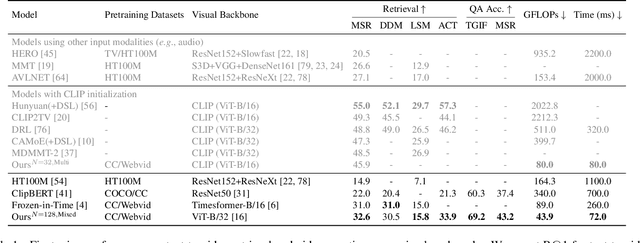
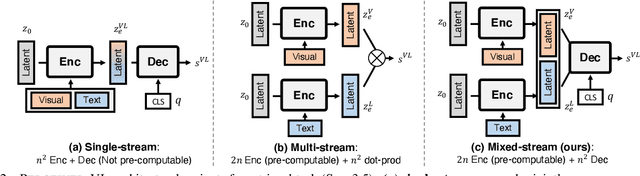
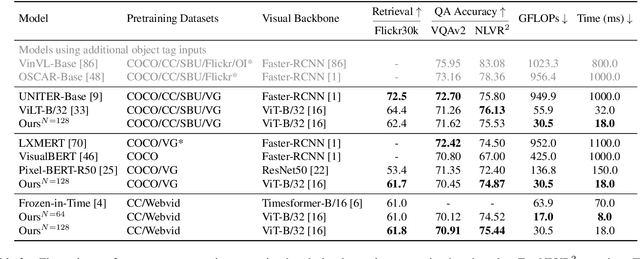
We present Perceiver-VL, a vision-and-language framework that efficiently handles high-dimensional multimodal inputs such as long videos and text. Powered by the iterative latent cross-attention of Perceiver, our framework scales with linear complexity, in contrast to the quadratic complexity of self-attention used in many state-of-the-art transformer-based models. To further improve the efficiency of our framework, we also study applying LayerDrop on cross-attention layers and introduce a mixed-stream architecture for cross-modal retrieval. We evaluate Perceiver-VL on diverse video-text and image-text benchmarks, where Perceiver-VL achieves the lowest GFLOPs and latency while maintaining competitive performance. In addition, we also provide comprehensive analyses of various aspects of our framework, including pretraining data, scalability of latent size and input size, dropping cross-attention layers at inference to reduce latency, modality aggregation strategy, positional encoding, and weight initialization strategy. Our code and checkpoints are available at: https://github.com/zinengtang/Perceiver_VL
Unifying Vision-Language Representation Space with Single-tower Transformer
Nov 21, 2022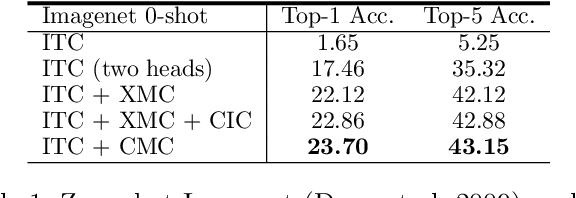
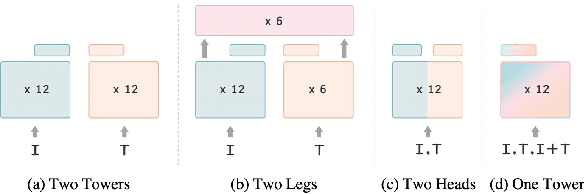
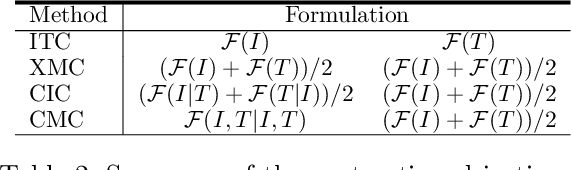

Contrastive learning is a form of distance learning that aims to learn invariant features from two related representations. In this paper, we explore the bold hypothesis that an image and its caption can be simply regarded as two different views of the underlying mutual information, and train a model to learn a unified vision-language representation space that encodes both modalities at once in a modality-agnostic manner. We first identify difficulties in learning a generic one-tower model for vision-language pretraining (VLP), and propose OneR as a simple yet effective framework for our goal. We discover intriguing properties that distinguish OneR from the previous works that learn modality-specific representation spaces such as zero-shot object localization, text-guided visual reasoning and multi-modal retrieval, and present analyses to provide insights into this new form of multi-modal representation learning. Thorough evaluations demonstrate the potential of a unified modality-agnostic VLP framework.
Stripformer: Strip Transformer for Fast Image Deblurring
Apr 10, 2022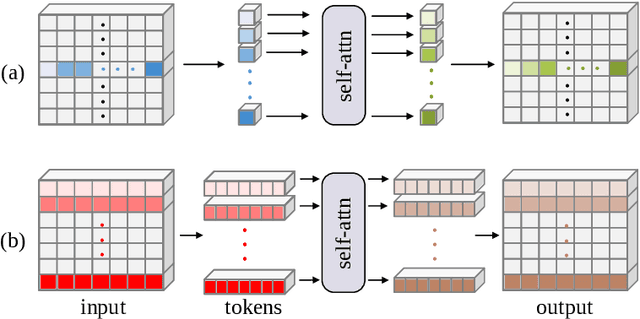
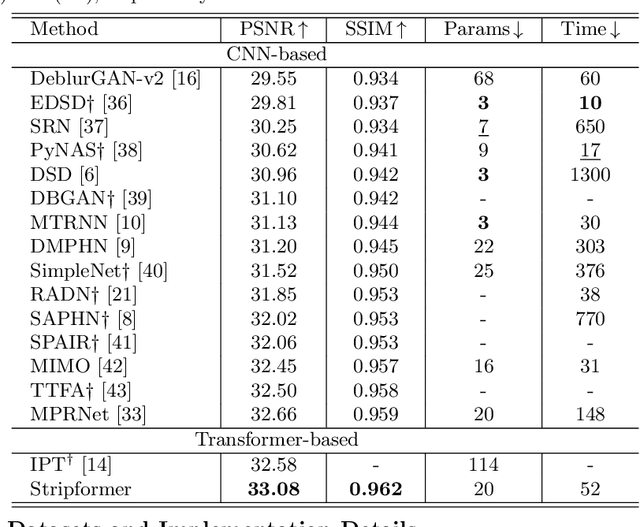
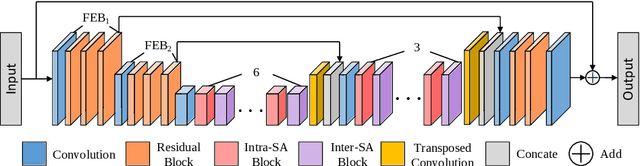
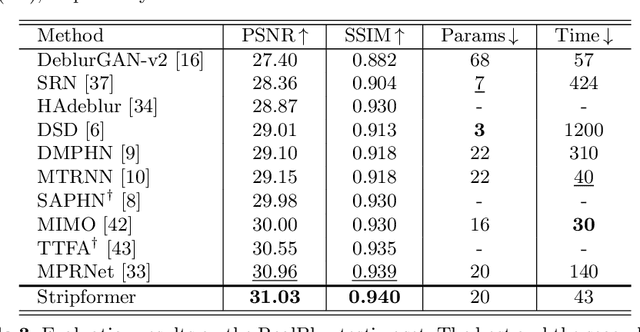
Images taken in dynamic scenes may contain unwanted motion blur, which significantly degrades visual quality. Such blur causes short- and long-range region-specific smoothing artifacts that are often directional and non-uniform, which is difficult to be removed. Inspired by the current success of transformers on computer vision and image processing tasks, we develop, Stripformer, a transformer-based architecture that constructs intra- and inter-strip tokens to reweight image features in the horizontal and vertical directions to catch blurred patterns with different orientations. It stacks interlaced intra-strip and inter-strip attention layers to reveal blur magnitudes. In addition to detecting region-specific blurred patterns of various orientations and magnitudes, Stripformer is also a token-efficient and parameter-efficient transformer model, demanding much less memory usage and computation cost than the vanilla transformer but works better without relying on tremendous training data. Experimental results show that Stripformer performs favorably against state-of-the-art models in dynamic scene deblurring.
Contextualize differential privacy in image database: a lightweight image differential privacy approach based on principle component analysis inverse
Feb 19, 2022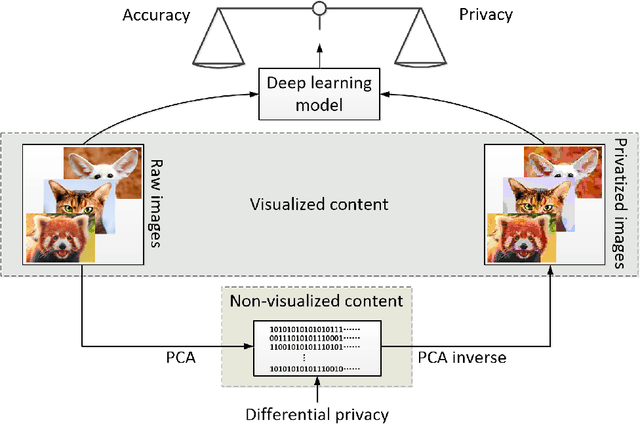


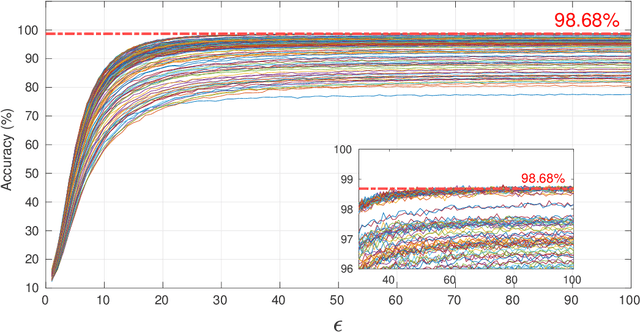
Differential privacy (DP) has been the de-facto standard to preserve privacy-sensitive information in database. Nevertheless, there lacks a clear and convincing contextualization of DP in image database, where individual images' indistinguishable contribution to a certain analysis can be achieved and observed when DP is exerted. As a result, the privacy-accuracy trade-off due to integrating DP is insufficiently demonstrated in the context of differentially-private image database. This work aims at contextualizing DP in image database by an explicit and intuitive demonstration of integrating conceptional differential privacy with images. To this end, we design a lightweight approach dedicating to privatizing image database as a whole and preserving the statistical semantics of the image database to an adjustable level, while making individual images' contribution to such statistics indistinguishable. The designed approach leverages principle component analysis (PCA) to reduce the raw image with large amount of attributes to a lower dimensional space whereby DP is performed, so as to decrease the DP load of calculating sensitivity attribute-by-attribute. The DP-exerted image data, which is not visible in its privatized format, is visualized through PCA inverse such that both a human and machine inspector can evaluate the privatization and quantify the privacy-accuracy trade-off in an analysis on the privatized image database. Using the devised approach, we demonstrate the contextualization of DP in images by two use cases based on deep learning models, where we show the indistinguishability of individual images induced by DP and the privatized images' retention of statistical semantics in deep learning tasks, which is elaborated by quantitative analyses on the privacy-accuracy trade-off under different privatization settings.
Facial Expression Video Generation Based-On Spatio-temporal Convolutional GAN: FEV-GAN
Oct 20, 2022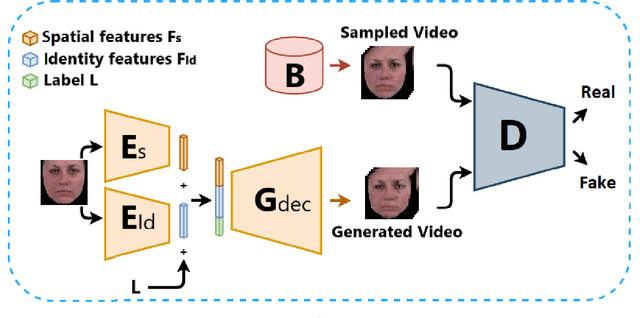
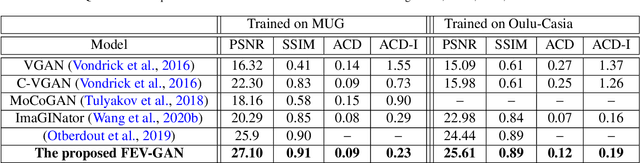

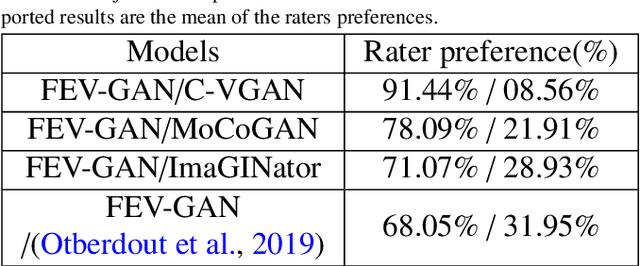
Facial expression generation has always been an intriguing task for scientists and researchers all over the globe. In this context, we present our novel approach for generating videos of the six basic facial expressions. Starting from a single neutral facial image and a label indicating the desired facial expression, we aim to synthesize a video of the given identity performing the specified facial expression. Our approach, referred to as FEV-GAN (Facial Expression Video GAN), is based on Spatio-temporal Convolutional GANs, that are known to model both content and motion in the same network. Previous methods based on such a network have shown a good ability to generate coherent videos with smooth temporal evolution. However, they still suffer from low image quality and low identity preservation capability. In this work, we address this problem by using a generator composed of two image encoders. The first one is pre-trained for facial identity feature extraction and the second for spatial feature extraction. We have qualitatively and quantitatively evaluated our model on two international facial expression benchmark databases: MUG and Oulu-CASIA NIR&VIS. The experimental results analysis demonstrates the effectiveness of our approach in generating videos of the six basic facial expressions while preserving the input identity. The analysis also proves that the use of both identity and spatial features enhances the decoder ability to better preserve the identity and generate high-quality videos. The code and the pre-trained model will soon be made publicly available.
* 13 pages, 8 figures, accepted in ISWA journal
Seeing 3D Objects in a Single Image via Self-Supervised Static-Dynamic Disentanglement
Jul 22, 2022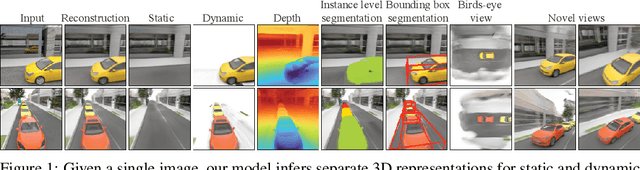
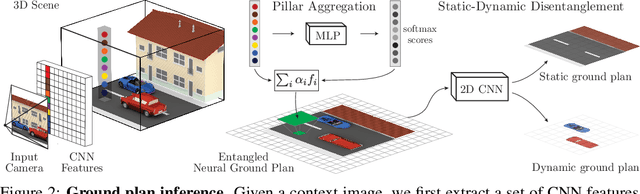
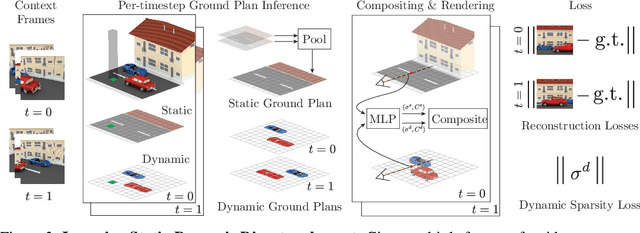

Human perception reliably identifies movable and immovable parts of 3D scenes, and completes the 3D structure of objects and background from incomplete observations. We learn this skill not via labeled examples, but simply by observing objects move. In this work, we propose an approach that observes unlabeled multi-view videos at training time and learns to map a single image observation of a complex scene, such as a street with cars, to a 3D neural scene representation that is disentangled into movable and immovable parts while plausibly completing its 3D structure. We separately parameterize movable and immovable scene parts via 2D neural ground plans. These ground plans are 2D grids of features aligned with the ground plane that can be locally decoded into 3D neural radiance fields. Our model is trained self-supervised via neural rendering. We demonstrate that the structure inherent to our disentangled 3D representation enables a variety of downstream tasks in street-scale 3D scenes using simple heuristics, such as extraction of object-centric 3D representations, novel view synthesis, instance segmentation, and 3D bounding box prediction, highlighting its value as a backbone for data-efficient 3D scene understanding models. This disentanglement further enables scene editing via object manipulation such as deletion, insertion, and rigid-body motion.
Decontamination of the scientific literature
Oct 28, 2022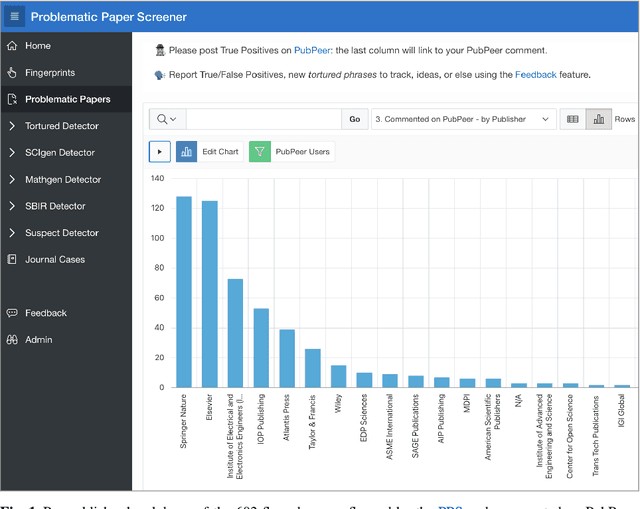
Research misconduct and frauds pollute the scientific literature. Honest errors and malevolent data fabrication, image manipulation, journal hijacking, and plagiarism passed peer review unnoticed. Problematic papers deceive readers, authors citing them, and AI-powered literature-based discovery. Flagship publishers accepted hundreds flawed papers despite claiming to enforce peer review. This application ambitions to decontaminate the scientific literature using curative and preventive actions.
Collecting The Puzzle Pieces: Disentangled Self-Driven Human Pose Transfer by Permuting Textures
Oct 04, 2022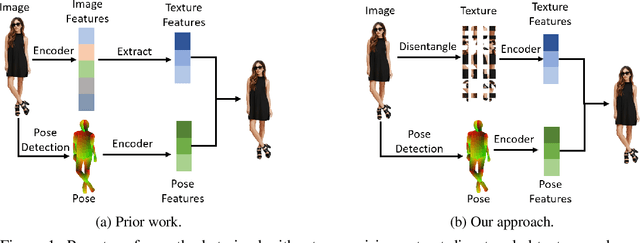
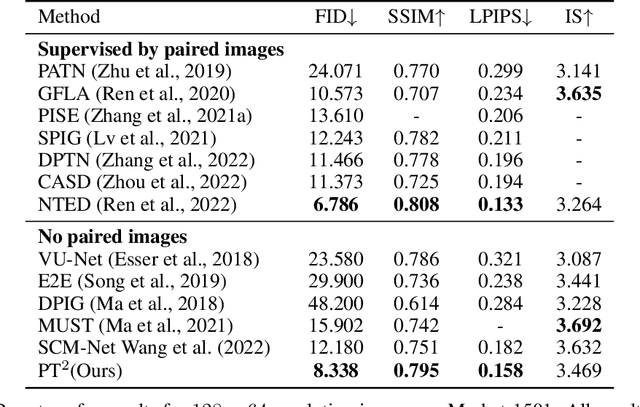
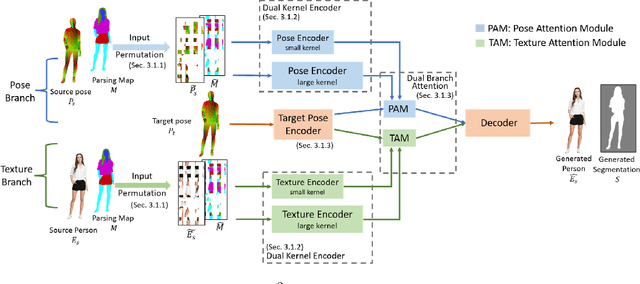
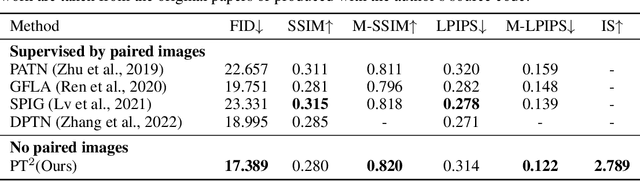
Human pose transfer aims to synthesize a new view of a person under a given pose. Recent works achieve this via self-reconstruction, which disentangles pose and texture features from the person image, then combines the two features to reconstruct the person. Such feature-level disentanglement is a difficult and ill-defined problem that could lead to loss of details and unwanted artifacts. In this paper, we propose a self-driven human pose transfer method that permutes the textures at random, then reconstructs the image with a dual branch attention to achieve image-level disentanglement and detail-preserving texture transfer. We find that compared with feature-level disentanglement, image-level disentanglement is more controllable and reliable. Furthermore, we introduce a dual kernel encoder that gives different sizes of receptive fields in order to reduce the noise caused by permutation and thus recover clothing details while aligning pose and textures. Extensive experiments on DeepFashion and Market-1501 shows that our model improves the quality of generated images in terms of FID, LPIPS and SSIM over other self-driven methods, and even outperforming some fully-supervised methods. A user study also shows that among self-driven approaches, images generated by our method are preferred in 72% of cases over prior work.
Uni4Eye: Unified 2D and 3D Self-supervised Pre-training via Masked Image Modeling Transformer for Ophthalmic Image Classification
Mar 09, 2022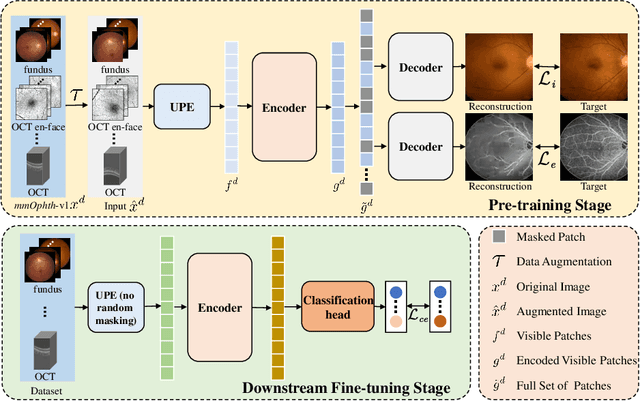
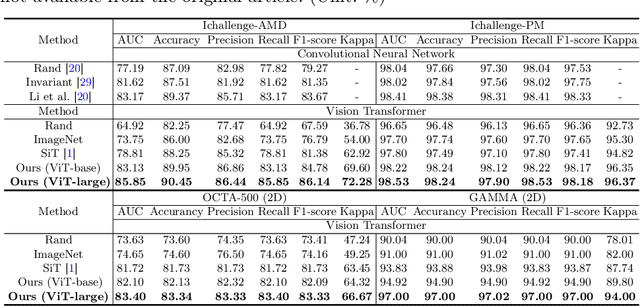
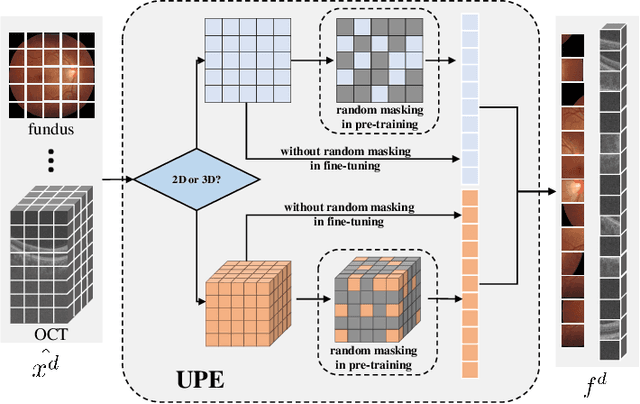
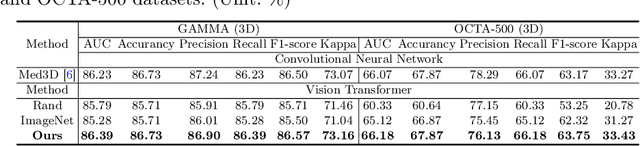
A large-scale labeled dataset is a key factor for the success of supervised deep learning in computer vision. However, a limited number of annotated data is very common, especially in ophthalmic image analysis, since manual annotation is time-consuming and labor-intensive. Self-supervised learning (SSL) methods bring huge opportunities for better utilizing unlabeled data, as they do not need massive annotations. With an attempt to use as many as possible unlabeled ophthalmic images, it is necessary to break the dimension barrier, simultaneously making use of both 2D and 3D images. In this paper, we propose a universal self-supervised Transformer framework, named Uni4Eye, to discover the inherent image property and capture domain-specific feature embedding in ophthalmic images. Uni4Eye can serve as a global feature extractor, which builds its basis on a Masked Image Modeling task with a Vision Transformer (ViT) architecture. We employ a Unified Patch Embedding module to replace the origin patch embedding module in ViT for jointly processing both 2D and 3D input images. Besides, we design a dual-branch multitask decoder module to simultaneously perform two reconstruction tasks on the input image and its gradient map, delivering discriminative representations for better convergence. We evaluate the performance of our pre-trained Uni4Eye encoder by fine-tuning it on six downstream ophthalmic image classification tasks. The superiority of Uni4Eye is successfully established through comparisons to other state-of-the-art SSL pre-training methods.