 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Blind Image Inpainting with Sparse Directional Filter Dictionaries for Lightweight CNNs
May 13, 2022
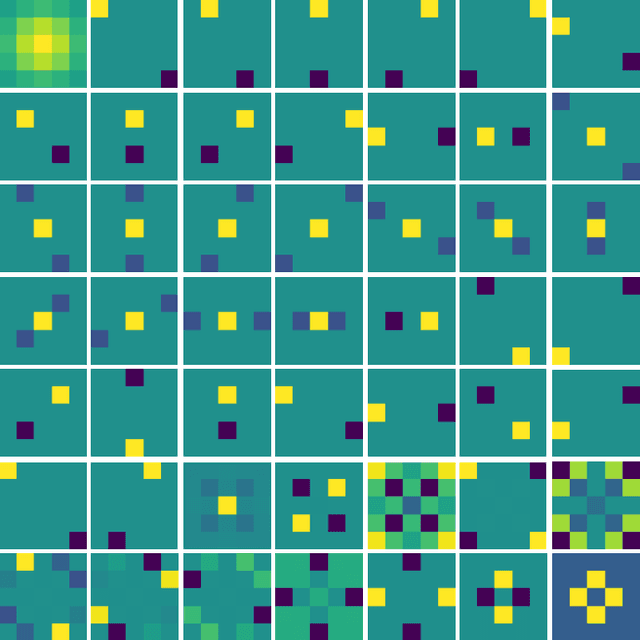
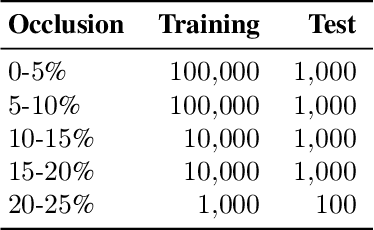
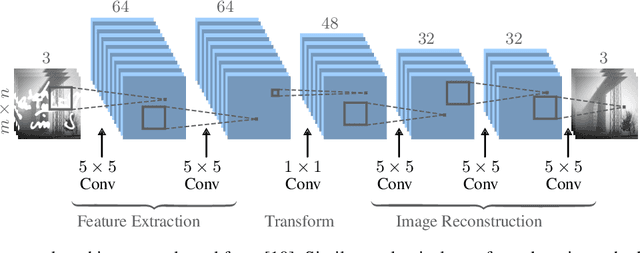
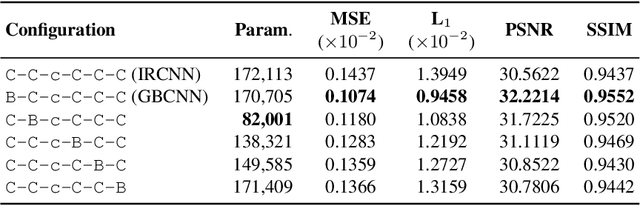
Blind inpainting algorithms based on deep learning architectures have shown a remarkable performance in recent years, typically outperforming model-based methods both in terms of image quality and run time. However, neural network strategies typically lack a theoretical explanation, which contrasts with the well-understood theory underlying model-based methods. In this work, we leverage the advantages of both approaches by integrating theoretically founded concepts from transform domain methods and sparse approximations into a CNN-based approach for blind image inpainting. To this end, we present a novel strategy to learn convolutional kernels that applies a specifically designed filter dictionary whose elements are linearly combined with trainable weights. Numerical experiments demonstrate the competitiveness of this approach. Our results show not only an improved inpainting quality compared to conventional CNNs but also significantly faster network convergence within a lightweight network design.
StyleAM: Perception-Oriented Unsupervised Domain Adaption for Non-reference Image Quality Assessment
Jul 29, 2022
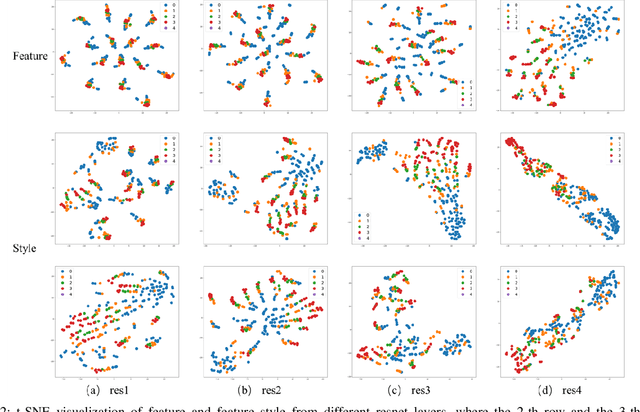
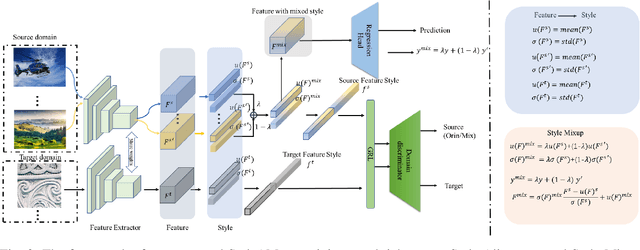
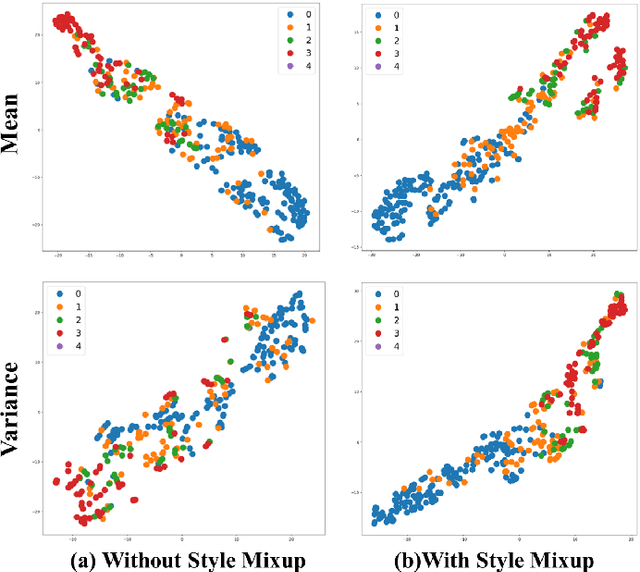
Deep neural networks (DNNs) have shown great potential in non-reference image quality assessment (NR-IQA). However, the annotation of NR-IQA is labor-intensive and time-consuming, which severely limits their application especially for authentic images. To relieve the dependence on quality annotation, some works have applied unsupervised domain adaptation (UDA) to NR-IQA. However, the above methods ignore that the alignment space used in classification is sub-optimal, since the space is not elaborately designed for perception. To solve this challenge, we propose an effective perception-oriented unsupervised domain adaptation method StyleAM for NR-IQA, which transfers sufficient knowledge from label-rich source domain data to label-free target domain images via Style Alignment and Mixup. Specifically, we find a more compact and reliable space i.e., feature style space for perception-oriented UDA based on an interesting/amazing observation, that the feature style (i.e., the mean and variance) of the deep layer in DNNs is exactly associated with the quality score in NR-IQA. Therefore, we propose to align the source and target domains in a more perceptual-oriented space i.e., the feature style space, to reduce the intervention from other quality-irrelevant feature factors. Furthermore, to increase the consistency between quality score and its feature style, we also propose a novel feature augmentation strategy Style Mixup, which mixes the feature styles (i.e., the mean and variance) before the last layer of DNNs together with mixing their labels. Extensive experimental results on two typical cross-domain settings (i.e., synthetic to authentic, and multiple distortions to one distortion) have demonstrated the effectiveness of our proposed StyleAM on NR-IQA.
Hospital-Agnostic Image Representation Learning in Digital Pathology
Apr 05, 2022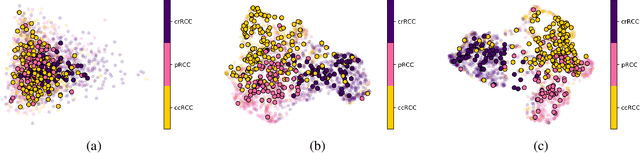

Whole Slide Images (WSIs) in digital pathology are used to diagnose cancer subtypes. The difference in procedures to acquire WSIs at various trial sites gives rise to variability in the histopathology images, thus making consistent diagnosis challenging. These differences may stem from variability in image acquisition through multi-vendor scanners, variable acquisition parameters, and differences in staining procedure; as well, patient demographics may bias the glass slide batches before image acquisition. These variabilities are assumed to cause a domain shift in the images of different hospitals. It is crucial to overcome this domain shift because an ideal machine-learning model must be able to work on the diverse sources of images, independent of the acquisition center. A domain generalization technique is leveraged in this study to improve the generalization capability of a Deep Neural Network (DNN), to an unseen histopathology image set (i.e., from an unseen hospital/trial site) in the presence of domain shift. According to experimental results, the conventional supervised-learning regime generalizes poorly to data collected from different hospitals. However, the proposed hospital-agnostic learning can improve the generalization considering the low-dimensional latent space representation visualization, and classification accuracy results.
Edge-based Monocular Thermal-Inertial Odometry in Visually Degraded Environments
Oct 18, 2022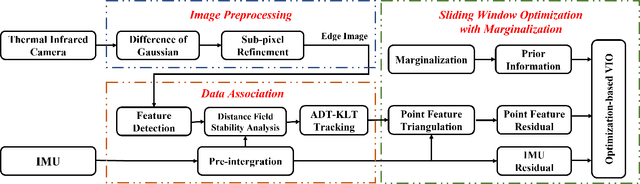
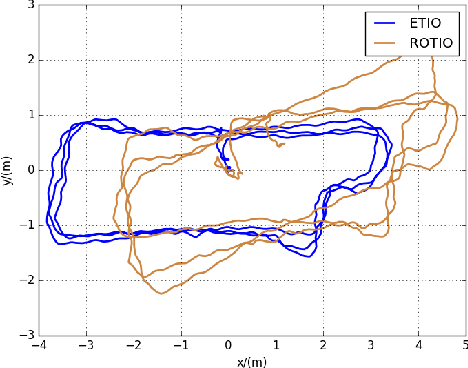
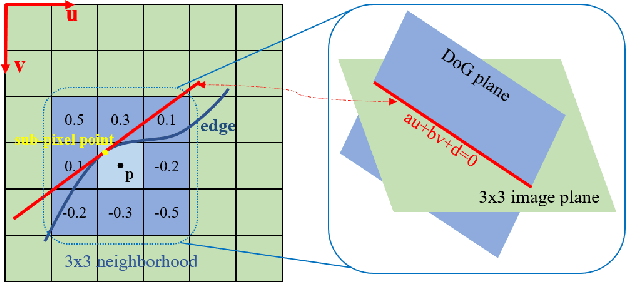
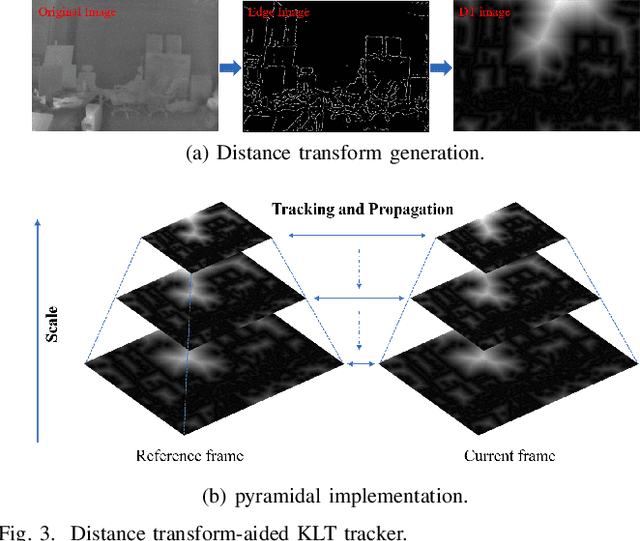
State estimation in complex illumination environments based on conventional visual-inertial odometry is a challenging task due to the severe visual degradation of the visual camera. The thermal infrared camera is capable of all-day time and is less affected by illumination variation. However, most existing visual data association algorithms are incompatible because the thermal infrared data contains large noise and low contrast. Motivated by the phenomenon that thermal radiation varies most significantly at the edges of objects, the study proposes an ETIO, which is the first edge-based monocular thermal-inertial odometry for robust localization in visually degraded environments. Instead of the raw image, we utilize the binarized image from edge extraction for pose estimation to overcome the poor thermal infrared image quality. Then, an adaptive feature tracking strategy ADT-KLT is developed for robust data association based on limited edge information and its distance distribution. Finally, a pose graph optimization performs real-time estimation over a sliding window of recent states by combining IMU pre-integration with reprojection error of all edge feature observations. We evaluated the performance of the proposed system on public datasets and real-world experiments and compared it against state-of-the-art methods. The proposed ETIO was verified with the ability to enable accurate and robust localization all-day time.
Image Retrieval from Contextual Descriptions
Mar 29, 2022


The ability to integrate context, including perceptual and temporal cues, plays a pivotal role in grounding the meaning of a linguistic utterance. In order to measure to what extent current vision-and-language models master this ability, we devise a new multimodal challenge, Image Retrieval from Contextual Descriptions (ImageCoDe). In particular, models are tasked with retrieving the correct image from a set of 10 minimally contrastive candidates based on a contextual description. As such, each description contains only the details that help distinguish between images. Because of this, descriptions tend to be complex in terms of syntax and discourse and require drawing pragmatic inferences. Images are sourced from both static pictures and video frames. We benchmark several state-of-the-art models, including both cross-encoders such as ViLBERT and bi-encoders such as CLIP, on ImageCoDe. Our results reveal that these models dramatically lag behind human performance: the best variant achieves an accuracy of 20.9 on video frames and 59.4 on static pictures, compared with 90.8 in humans. Furthermore, we experiment with new model variants that are better equipped to incorporate visual and temporal context into their representations, which achieve modest gains. Our hope is that ImageCoDE will foster progress in grounded language understanding by encouraging models to focus on fine-grained visual differences.
Panoptic-based Object Style-Align for Image-to-Image Translation
Dec 03, 2021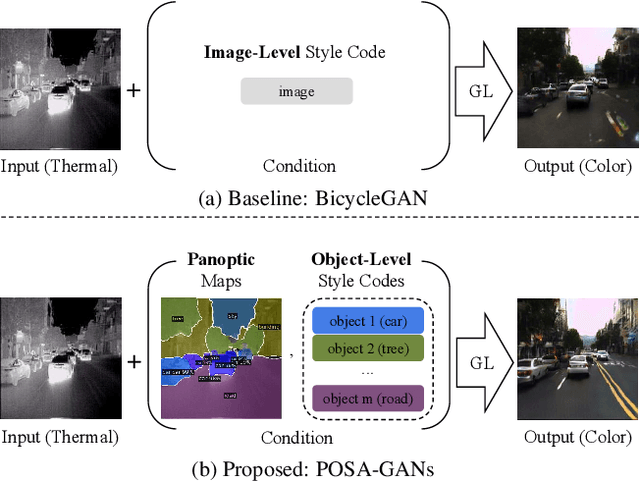

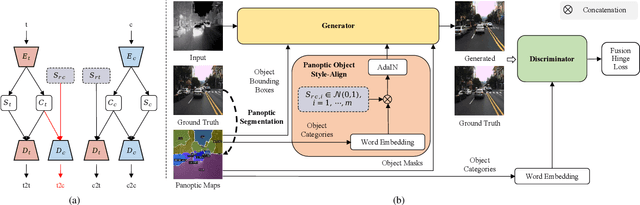
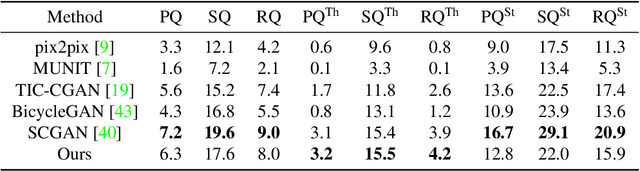
Despite remarkable recent progress in image translation, the complex scene with multiple discrepant objects remains a challenging problem. Because the translated images have low fidelity and tiny objects in fewer details and obtain unsatisfactory performance in object recognition. Without the thorough object perception (i.e., bounding boxes, categories, and masks) of the image as prior knowledge, the style transformation of each object will be difficult to track in the image translation process. We propose panoptic-based object style-align generative adversarial networks (POSA-GANs) for image-to-image translation together with a compact panoptic segmentation dataset. The panoptic segmentation model is utilized to extract panoptic-level perception (i.e., overlap-removed foreground object instances and background semantic regions in the image). This is utilized to guide the alignment between the object content codes of the input domain image and object style codes sampled from the style space of the target domain. The style-aligned object representations are further transformed to obtain precise boundaries layout for higher fidelity object generation. The proposed method was systematically compared with different competing methods and obtained significant improvement on both image quality and object recognition performance for translated images.
GAN Prior based Null-Space Learning for Consistent Super-Resolution
Nov 24, 2022

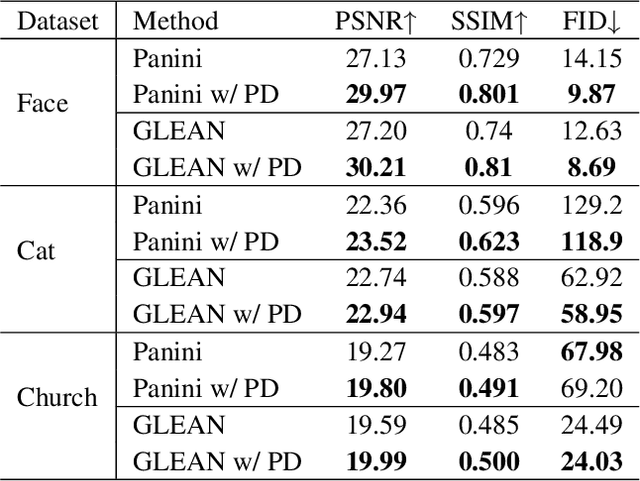
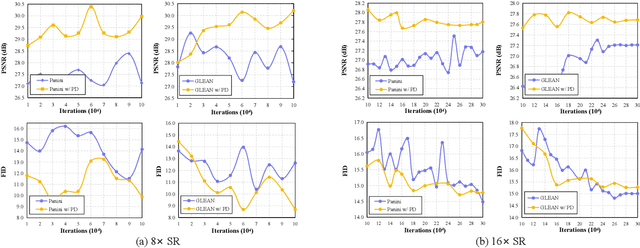
Consistency and realness have always been the two critical issues of image super-resolution. While the realness has been dramatically improved with the use of GAN prior, the state-of-the-art methods still suffer inconsistencies in local structures and colors (e.g., tooth and eyes). In this paper, we show that these inconsistencies can be analytically eliminated by learning only the null-space component while fixing the range-space part. Further, we design a pooling-based decomposition (PD), a universal range-null space decomposition for super-resolution tasks, which is concise, fast, and parameter-free. PD can be easily applied to state-of-the-art GAN Prior based SR methods to eliminate their inconsistencies, neither compromising the realness nor bringing extra parameters or computational costs. Besides, our ablation studies reveal that PD can replace pixel-wise losses for training and achieve better generalization performance when facing unseen downsamplings or even real-world degradation. Experiments show that the use of PD refreshes state-of-the-art SR performance and speeds up the convergence of training up to 2~10 times.
Collaborative Training of Medical Artificial Intelligence Models with non-uniform Labels
Nov 24, 2022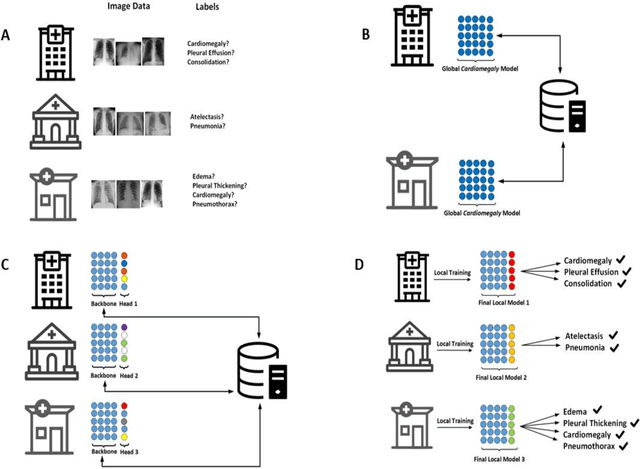
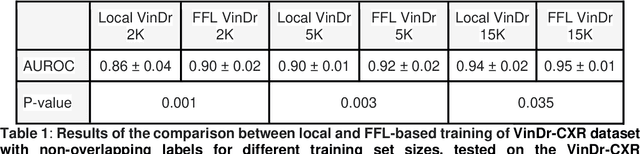
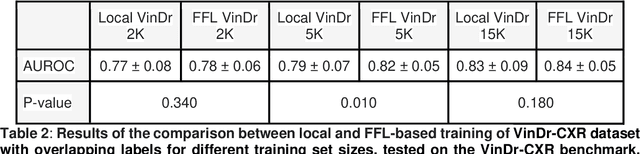
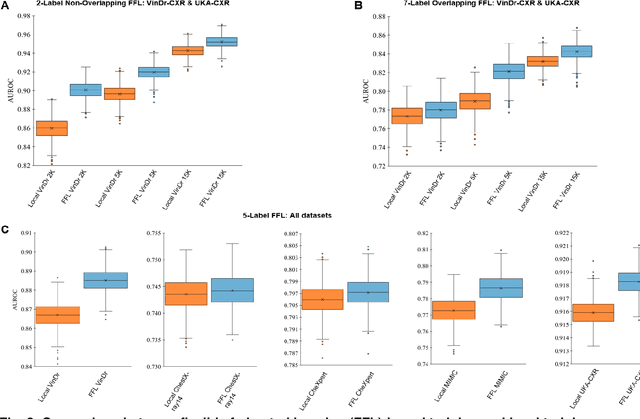
Artificial intelligence (AI) methods are revolutionizing medical image analysis. However, robust AI models require large multi-site datasets for training. While multiple stakeholders have provided publicly available datasets, the ways in which these data are labeled differ widely. For example, one dataset of chest radiographs might contain labels denoting the presence of metastases in the lung, while another dataset of chest radiograph might focus on the presence of pneumonia. With conventional approaches, these data cannot be used together to train a single AI model. We propose a new framework that we call flexible federated learning (FFL) for collaborative training on such data. Using publicly available data of 695,000 chest radiographs from five institutions - each with differing labels - we demonstrate that large and heterogeneously labeled datasets can be used to train one big AI model with this framework. We find that models trained with FFL are superior to models that are trained on matching annotations only. This may pave the way for training of truly large-scale AI models that make efficient use of all existing data.
Image Edge Restoring Filter
Dec 27, 2021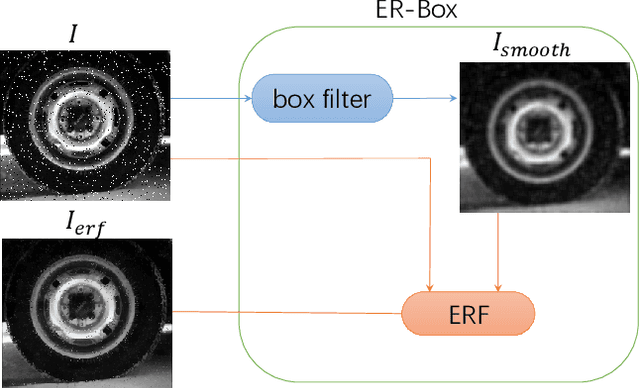


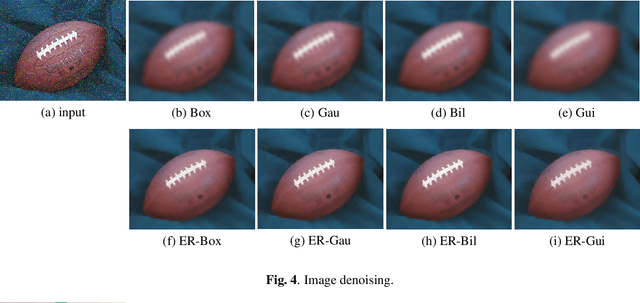
In computer vision, image processing and computer graphics, image smoothing filtering is a very basic and important task and to be expected possessing good edge-preserving smoothing property. Here we address the problem that the edge-preserving ability of many popular local smoothing filters needs to be improved. In this paper, we propose the image Edge Restoring Filter (ERF) to restore the blur edge pixels in the output of local smoothing filters to be clear. The proposed filter can been implemented after many local smoothing filter (such as Box filter, Gaussian filter, Bilateral Filter, Guided Filter and so on). The combinations of "original local smoothing filters + ERF" have better edge-preserving smoothing property than the original local smoothing filters. Experiments on image smoothing, image denoising and image enhancement demonstrate the excellent edges restoring ability of the proposed filter and good edgepreserving smoothing property of the combination "original local smoothing filters + ERF". The proposed filter would benefit a great variety of applications given that smoothing filtering is a high frequently used and fundamental operation.
High-Perceptual Quality JPEG Decoding via Posterior Sampling
Nov 21, 2022
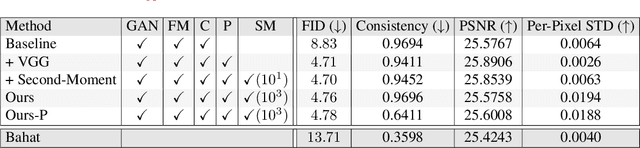
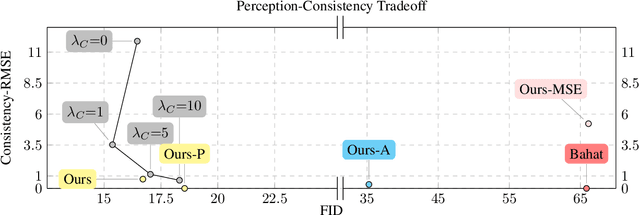
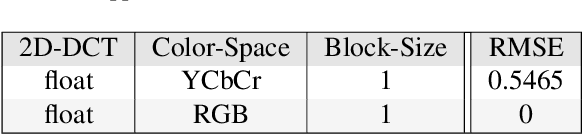
JPEG is arguably the most popular image coding format, achieving high compression ratios via lossy quantization that may create visual artifacts degradation. Numerous attempts to remove these artifacts were conceived over the years, and common to most of these is the use of deterministic post-processing algorithms that optimize some distortion measure (e.g., PSNR, SSIM). In this paper we propose a different paradigm for JPEG artifact correction: Our method is stochastic, and the objective we target is high perceptual quality -- striving to obtain sharp, detailed and visually pleasing reconstructed images, while being consistent with the compressed input. These goals are achieved by training a stochastic conditional generator (conditioned on the compressed input), accompanied by a theoretically well-founded loss term, resulting in a sampler from the posterior distribution. Our solution offers a diverse set of plausible and fast reconstructions for a given input with perfect consistency. We demonstrate our scheme's unique properties and its superiority to a variety of alternative methods on the FFHQ and ImageNet datasets.