 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SAC-GAN: Structure-Aware Image-to-Image Composition for Self-Driving
Dec 30, 2021

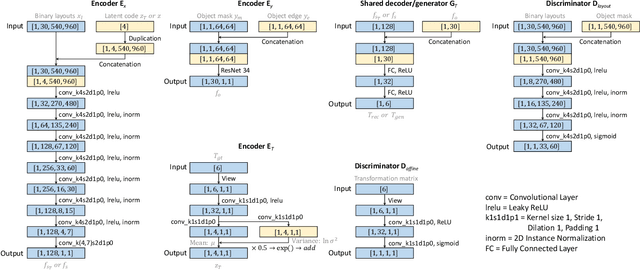
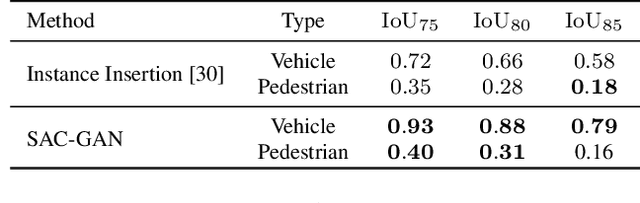

We present a compositional approach to image augmentation for self-driving applications. It is an end-to-end neural network that is trained to seamlessly compose an object (e.g., a vehicle or pedestrian) represented as a cropped patch from an object image, into a background scene image. As our approach emphasizes more on semantic and structural coherence of the composed images, rather than their pixel-level RGB accuracies, we tailor the input and output of our network with structure-aware features and design our network losses accordingly. Specifically, our network takes the semantic layout features from the input scene image, features encoded from the edges and silhouette in the input object patch, as well as a latent code as inputs, and generates a 2D spatial affine transform defining the translation and scaling of the object patch. The learned parameters are further fed into a differentiable spatial transformer network to transform the object patch into the target image, where our model is trained adversarially using an affine transform discriminator and a layout discriminator. We evaluate our network, coined SAC-GAN for structure-aware composition, on prominent self-driving datasets in terms of quality, composability, and generalizability of the composite images. Comparisons are made to state-of-the-art alternatives, confirming superiority of our method.
Name Your Style: An Arbitrary Artist-aware Image Style Transfer
Mar 05, 2022
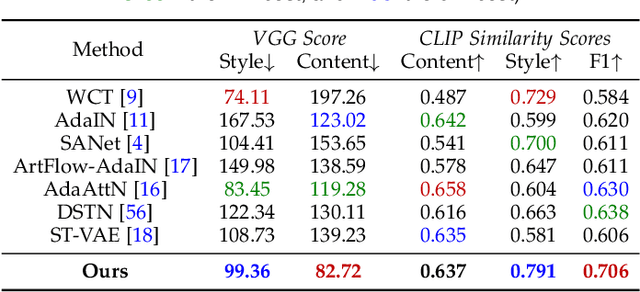
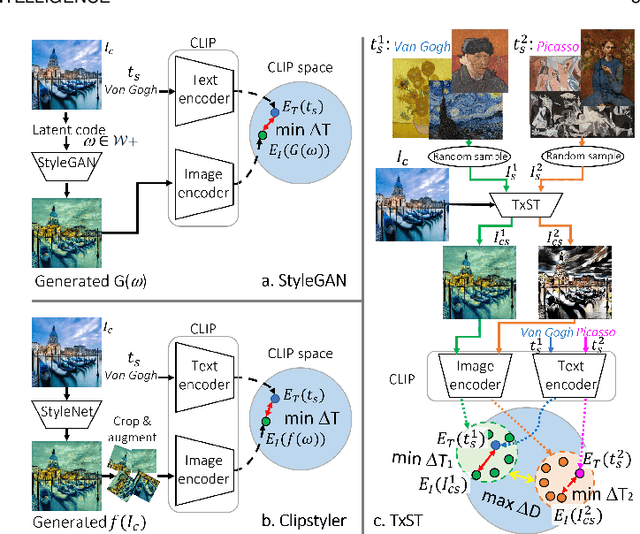
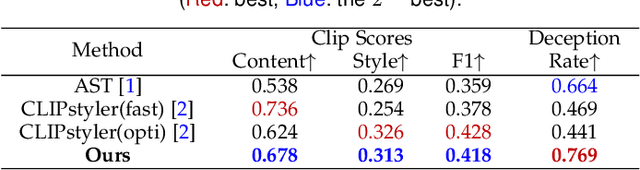
Image style transfer has attracted widespread attention in the past few years. Despite its remarkable results, it requires additional style images available as references, making it less flexible and inconvenient. Using text is the most natural way to describe the style. More importantly, text can describe implicit abstract styles, like styles of specific artists or art movements. In this paper, we propose a text-driven image style transfer (TxST) that leverages advanced image-text encoders to control arbitrary style transfer. We introduce a contrastive training strategy to effectively extract style descriptions from the image-text model (i.e., CLIP), which aligns stylization with the text description. To this end, we also propose a novel and efficient attention module that explores cross-attentions to fuse style and content features. Finally, we achieve an arbitrary artist-aware image style transfer to learn and transfer specific artistic characters such as Picasso, oil painting, or a rough sketch. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods on both image and textual styles. Moreover, it can mimic the styles of one or many artists to achieve attractive results, thus highlighting a promising direction in image style transfer.
Ultrafast Image Retrieval from a Holographic Memory Disc for High-Speed Operation of a Shift, Scale, and Rotation Invariant Target Recognition System
Nov 07, 2022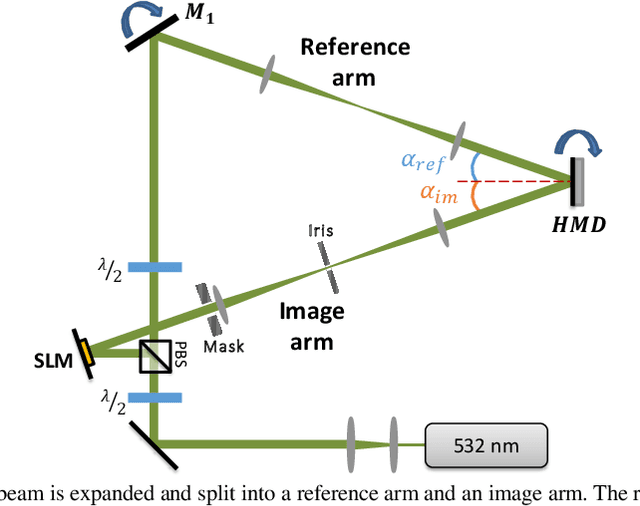

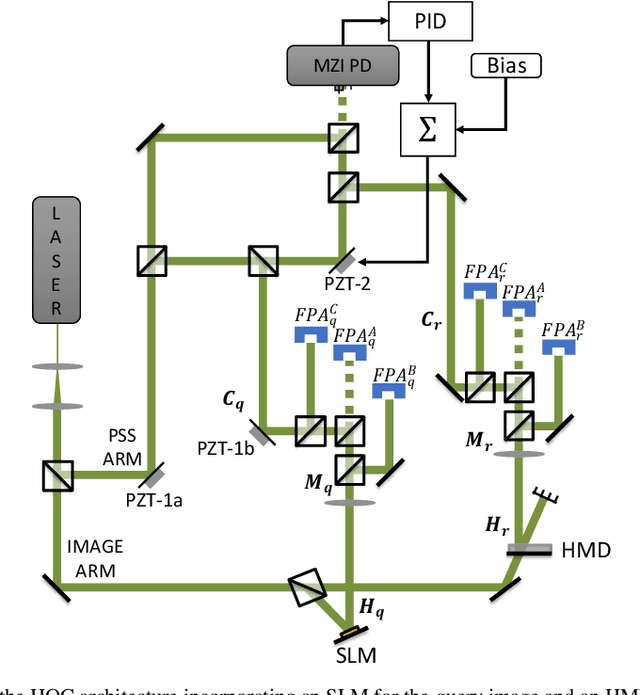

The hybrid opto-electronic correlator (HOC) architecture has been shown to be able to detect matches in a shift, scale, and rotation invariant (SSRI) manner by incorporating a polar Mellin transform (PMT) pre-processing step. Here we demonstrate the design and use of a thick holographic memory disc (HMD) for high-speed SSRI correlation employing an HOC. The HMD was written to have 1,320 stored images, including both unprocessed images and their PMTs. We further propose and demonstrate a novel approach whereby the HOC inputs are spatially shifted to produce correlation signals without requiring stabilization of optical phases, yielding results that are in good agreement with the theory. Use of this approach vastly simplifies the design and operation of the HOC, while improving its stability significantly. Finally, a real-time opto-electronic PMT pre-processor utilizing an FPGA is proposed and prototyped, allowing for the automatic conversion of images into their PMTs without additional processing delay.
* Conference
ISNAS-DIP: Image-Specific Neural Architecture Search for Deep Image Prior
Nov 27, 2021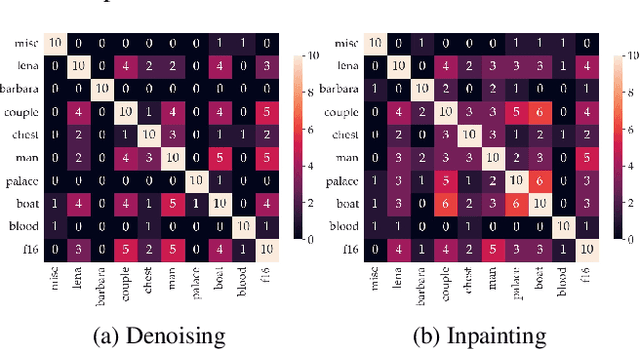
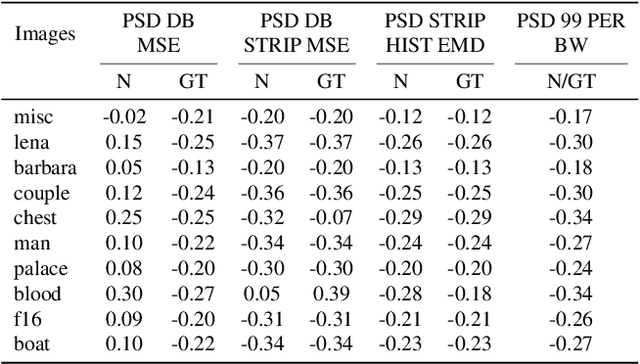
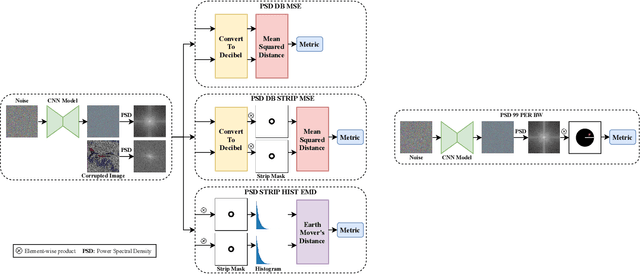
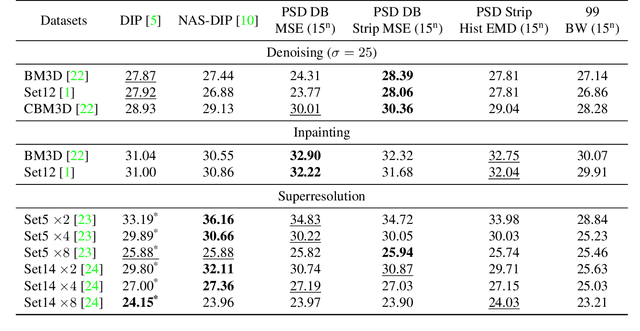
Recent works show that convolutional neural network (CNN) architectures have a spectral bias towards lower frequencies, which has been leveraged for various image restoration tasks in the Deep Image Prior (DIP) framework. The benefit of the inductive bias the network imposes in the DIP framework depends on the architecture. Therefore, researchers have studied how to automate the search to determine the best-performing model. However, common neural architecture search (NAS) techniques are resource and time-intensive. Moreover, best-performing models are determined for a whole dataset of images instead of for each image independently, which would be prohibitively expensive. In this work, we first show that optimal neural architectures in the DIP framework are image-dependent. Leveraging this insight, we then propose an image-specific NAS strategy for the DIP framework that requires substantially less training than typical NAS approaches, effectively enabling image-specific NAS. For a given image, noise is fed to a large set of untrained CNNs, and their outputs' power spectral densities (PSD) are compared to that of the corrupted image using various metrics. Based on this, a small cohort of image-specific architectures is chosen and trained to reconstruct the corrupted image. Among this cohort, the model whose reconstruction is closest to the average of the reconstructed images is chosen as the final model. We justify the proposed strategy's effectiveness by (1) demonstrating its performance on a NAS Dataset for DIP that includes 500+ models from a particular search space (2) conducting extensive experiments on image denoising, inpainting, and super-resolution tasks. Our experiments show that image-specific metrics can reduce the search space to a small cohort of models, of which the best model outperforms current NAS approaches for image restoration.
EBHI:A New Enteroscope Biopsy Histopathological H&E Image Dataset for Image Classification Evaluation
Feb 17, 2022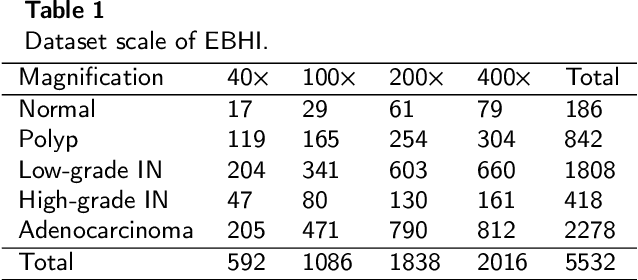
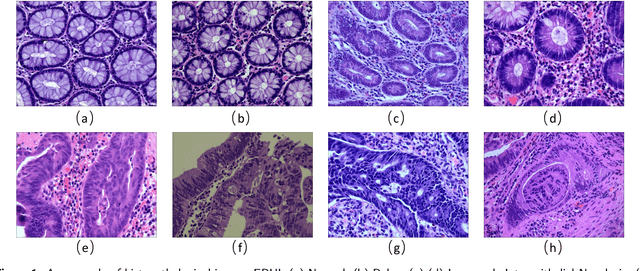
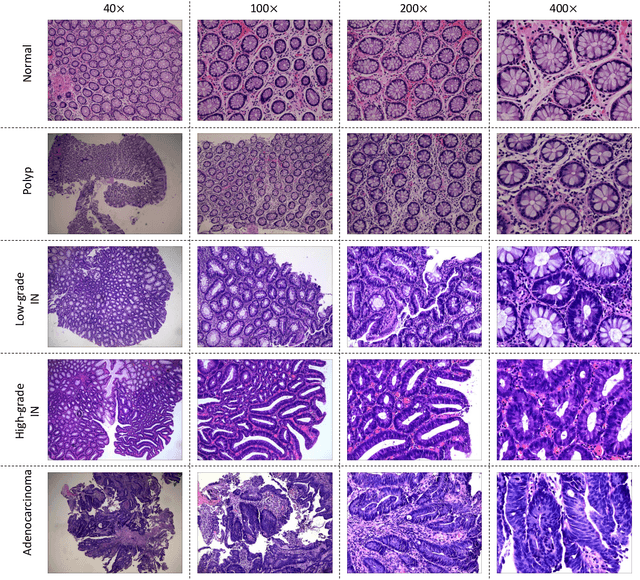
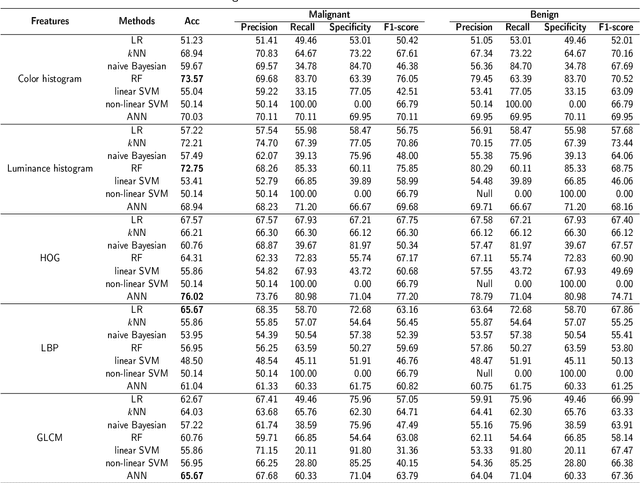
Background and purpose: Colorectal cancer has become the third most common cancer worldwide, accounting for approximately 10% of cancer patients. Early detection of the disease is important for the treatment of colorectal cancer patients. Histopathological examination is the gold standard for screening colorectal cancer. However, the current lack of histopathological image datasets of colorectal cancer, especially enteroscope biopsies, hinders the accurate evaluation of computer-aided diagnosis techniques. Methods: A new publicly available Enteroscope Biopsy Histopathological H&E Image Dataset (EBHI) is published in this paper. To demonstrate the effectiveness of the EBHI dataset, we have utilized several machine learning, convolutional neural networks and novel transformer-based classifiers for experimentation and evaluation, using an image with a magnification of 200x. Results: Experimental results show that the deep learning method performs well on the EBHI dataset. Traditional machine learning methods achieve maximum accuracy of 76.02% and deep learning method achieves a maximum accuracy of 95.37%. Conclusion: To the best of our knowledge, EBHI is the first publicly available colorectal histopathology enteroscope biopsy dataset with four magnifications and five types of images of tumor differentiation stages, totaling 5532 images. We believe that EBHI could attract researchers to explore new classification algorithms for the automated diagnosis of colorectal cancer, which could help physicians and patients in clinical settings.
Minority-Oriented Vicinity Expansion with Attentive Aggregation for Video Long-Tailed Recognition
Nov 24, 2022
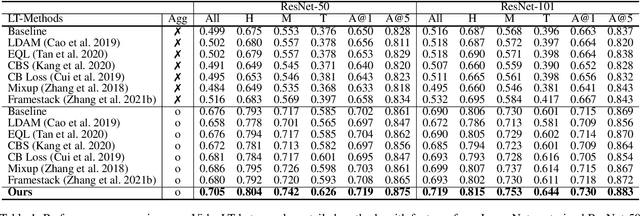
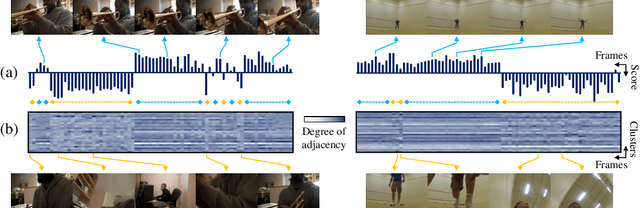
A dramatic increase in real-world video volume with extremely diverse and emerging topics naturally forms a long-tailed video distribution in terms of their categories, and it spotlights the need for Video Long-Tailed Recognition (VLTR). In this work, we summarize the challenges in VLTR and explore how to overcome them. The challenges are: (1) it is impractical to re-train the whole model for high-quality features, (2) acquiring frame-wise labels requires extensive cost, and (3) long-tailed data triggers biased training. Yet, most existing works for VLTR unavoidably utilize image-level features extracted from pretrained models which are task-irrelevant, and learn by video-level labels. Therefore, to deal with such (1) task-irrelevant features and (2) video-level labels, we introduce two complementary learnable feature aggregators. Learnable layers in each aggregator are to produce task-relevant representations, and each aggregator is to assemble the snippet-wise knowledge into a video representative. Then, we propose Minority-Oriented Vicinity Expansion (MOVE) that explicitly leverages the class frequency into approximating the vicinity distributions to alleviate (3) biased training. By combining these solutions, our approach achieves state-of-the-art results on large-scale VideoLT and synthetically induced Imbalanced-MiniKinetics200. With VideoLT features from ResNet-50, it attains 18% and 58% relative improvements on head and tail classes over the previous state-of-the-art method, respectively.
Split-PU: Hardness-aware Training Strategy for Positive-Unlabeled Learning
Nov 30, 2022
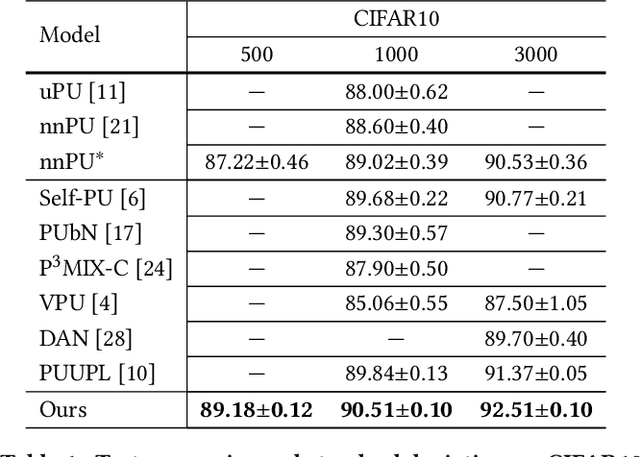
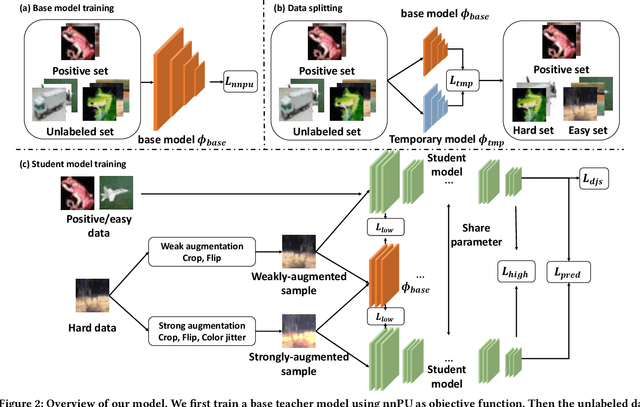
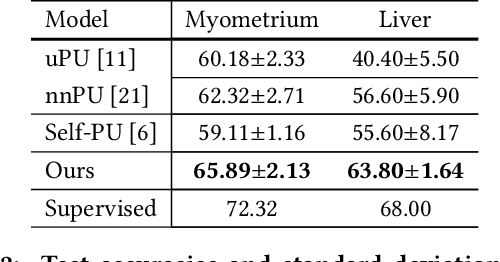
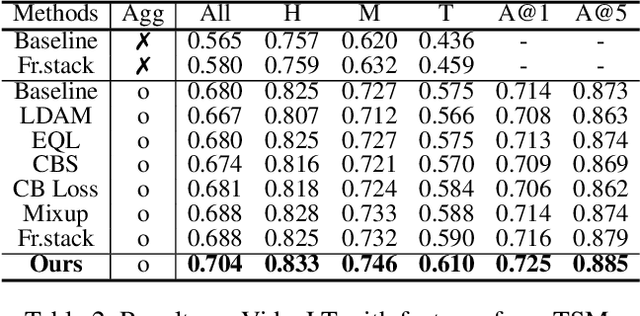
Positive-Unlabeled (PU) learning aims to learn a model with rare positive samples and abundant unlabeled samples. Compared with classical binary classification, the task of PU learning is much more challenging due to the existence of many incompletely-annotated data instances. Since only part of the most confident positive samples are available and evidence is not enough to categorize the rest samples, many of these unlabeled data may also be the positive samples. Research on this topic is particularly useful and essential to many real-world tasks which demand very expensive labelling cost. For example, the recognition tasks in disease diagnosis, recommendation system and satellite image recognition may only have few positive samples that can be annotated by the experts. These methods mainly omit the intrinsic hardness of some unlabeled data, which can result in sub-optimal performance as a consequence of fitting the easy noisy data and not sufficiently utilizing the hard data. In this paper, we focus on improving the commonly-used nnPU with a novel training pipeline. We highlight the intrinsic difference of hardness of samples in the dataset and the proper learning strategies for easy and hard data. By considering this fact, we propose first splitting the unlabeled dataset with an early-stop strategy. The samples that have inconsistent predictions between the temporary and base model are considered as hard samples. Then the model utilizes a noise-tolerant Jensen-Shannon divergence loss for easy data; and a dual-source consistency regularization for hard data which includes a cross-consistency between student and base model for low-level features and self-consistency for high-level features and predictions, respectively.
Pex: Memory-efficient Microcontroller Deep Learning through Partial Execution
Nov 30, 2022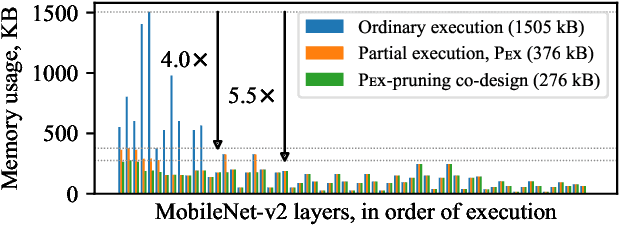
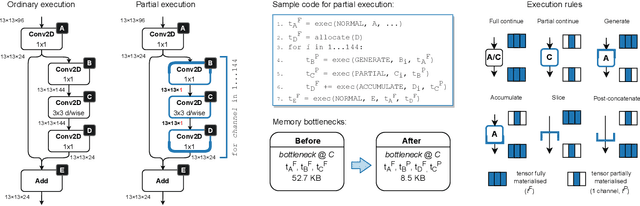

Embedded and IoT devices, largely powered by microcontroller units (MCUs), could be made more intelligent by leveraging on-device deep learning. One of the main challenges of neural network inference on an MCU is the extremely limited amount of read-write on-chip memory (SRAM, < 512 kB). SRAM is consumed by the neural network layer (operator) input and output buffers, which, traditionally, must be in memory (materialised) for an operator to execute. We discuss a novel execution paradigm for microcontroller deep learning, which modifies the execution of neural networks to avoid materialising full buffers in memory, drastically reducing SRAM usage with no computation overhead. This is achieved by exploiting the properties of operators, which can consume/produce a fraction of their input/output at a time. We describe a partial execution compiler, Pex, which produces memory-efficient execution schedules automatically by identifying subgraphs of operators whose execution can be split along the feature ("channel") dimension. Memory usage is reduced further by targeting memory bottlenecks with structured pruning, leading to the co-design of the network architecture and its execution schedule. Our evaluation of image and audio classification models: (a) establishes state-of-the-art performance in low SRAM usage regimes for considered tasks with up to +2.9% accuracy increase; (b) finds that a 4x memory reduction is possible by applying partial execution alone, or up to 10.5x when using the compiler-pruning co-design, while maintaining the classification accuracy compared to prior work; (c) uses the recovered SRAM to process higher resolution inputs instead, increasing accuracy by up to +3.9% on Visual Wake Words.
CASS: Cross Architectural Self-Supervision for Medical Image Analysis
Jun 08, 2022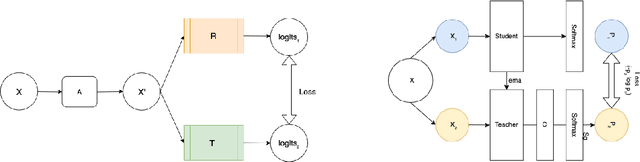
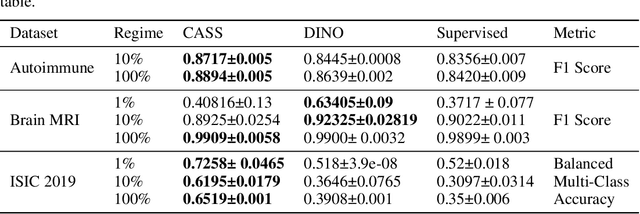


Recent advances in Deep Learning and Computer Vision have alleviated many of the bottlenecks, allowing algorithms to be label-free with better performance. Specifically, Transformers provide a global perspective of the image, which Convolutional Neural Networks (CNN) lack by design. Here we present \textbf{C}ross \textbf{A}rchitectural - \textbf{S}elf \textbf{S}upervision , a novel self-supervised learning approach which leverages transformers and CNN simultaneously, while also being computationally accessible to general practitioners via easily available cloud services. Compared to existing state-of-the-art self-supervised learning approaches, we empirically show CASS trained CNNs, and Transformers gained an average of 8.5\% with 100\% labelled data, 7.3\% with 10\% labelled data, and 11.5\% with 1\% labelled data, across three diverse datasets. Notably, one of the employed datasets included histopathology slides of an autoimmune disease, a topic underrepresented in Medical Imaging and has minimal data. In addition, our findings reveal that CASS is twice as efficient as other state-of-the-art methods in terms of training time.
Sparse4D: Multi-view 3D Object Detection with Sparse Spatial-Temporal Fusion
Nov 19, 2022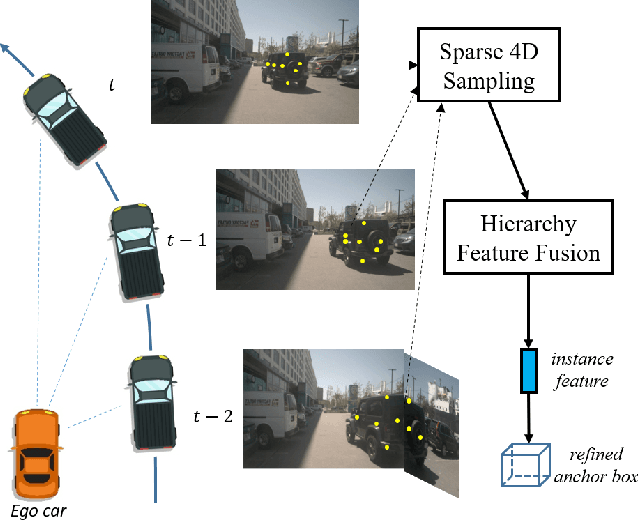
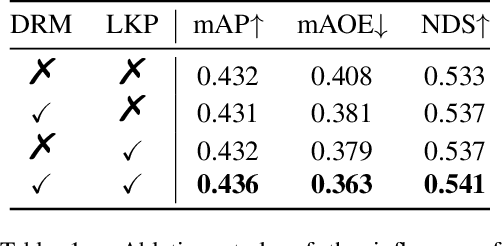
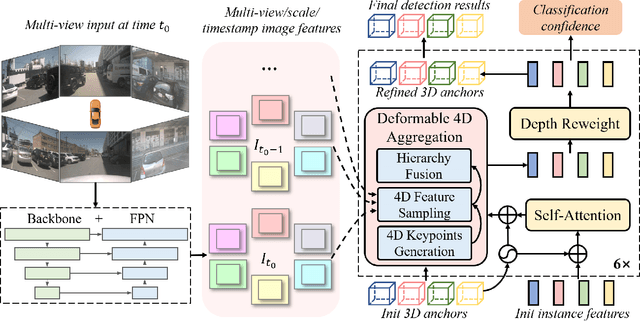
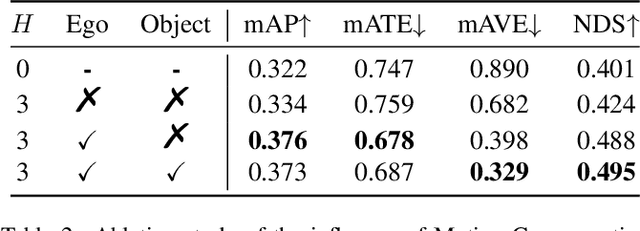
Bird-eye-view (BEV) based methods have made great progress recently in multi-view 3D detection task. Comparing with BEV based methods, sparse based methods lag behind in performance, but still have lots of non-negligible merits. To push sparse 3D detection further, in this work, we introduce a novel method, named Sparse4D, which does the iterative refinement of anchor boxes via sparsely sampling and fusing spatial-temporal features. (1) Sparse 4D Sampling: for each 3D anchor, we assign multiple 4D keypoints, which are then projected to multi-view/scale/timestamp image features to sample corresponding features; (2) Hierarchy Feature Fusion: we hierarchically fuse sampled features of different view/scale, different timestamp and different keypoints to generate high-quality instance feature. In this way, Sparse4D can efficiently and effectively achieve 3D detection without relying on dense view transformation nor global attention, and is more friendly to edge devices deployment. Furthermore, we introduce an instance-level depth reweight module to alleviate the ill-posed issue in 3D-to-2D projection. In experiment, our method outperforms all sparse based methods and most BEV based methods on detection task in the nuScenes dataset.