 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A New Path: Scaling Vision-and-Language Navigation with Synthetic Instructions and Imitation Learning
Oct 06, 2022
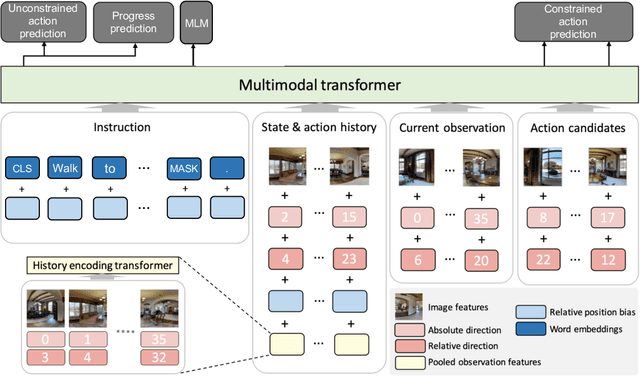
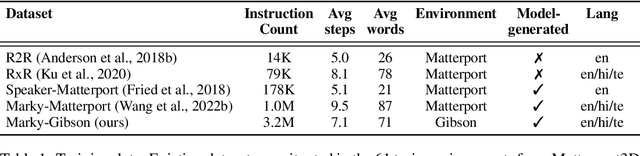
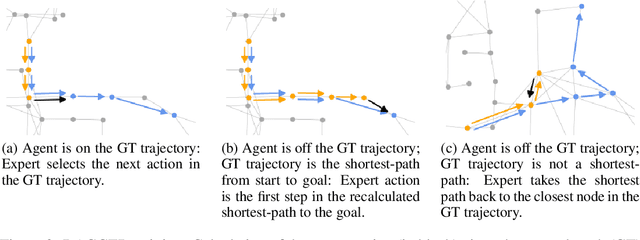

Recent studies in Vision-and-Language Navigation (VLN) train RL agents to execute natural-language navigation instructions in photorealistic environments, as a step towards intelligent agents or robots that can follow human instructions. However, given the scarcity of human instruction data and limited diversity in the training environments, these agents still struggle with complex language grounding and spatial language understanding. Pre-training on large text and image-text datasets from the web has been extensively explored but the improvements are limited. To address the scarcity of in-domain instruction data, we investigate large-scale augmentation with synthetic instructions. We take 500+ indoor environments captured in densely-sampled 360 deg panoramas, construct navigation trajectories through these panoramas, and generate a visually-grounded instruction for each trajectory using Marky (Wang et al., 2022), a high-quality multilingual navigation instruction generator. To further increase the variability of the trajectories, we also synthesize image observations from novel viewpoints using an image-to-image GAN. The resulting dataset of 4.2M instruction-trajectory pairs is two orders of magnitude larger than existing human-annotated datasets, and contains a wider variety of environments and viewpoints. To efficiently leverage data at this scale, we train a transformer agent with imitation learning for over 700M steps of experience. On the challenging Room-across-Room dataset, our approach outperforms all existing RL agents, improving the state-of-the-art NDTW from 71.1 to 79.1 in seen environments, and from 64.6 to 66.8 in unseen test environments. Our work points to a new path to improving instruction-following agents, emphasizing large-scale imitation learning and the development of synthetic instruction generation capabilities.
Few-shot Metric Learning: Online Adaptation of Embedding for Retrieval
Nov 14, 2022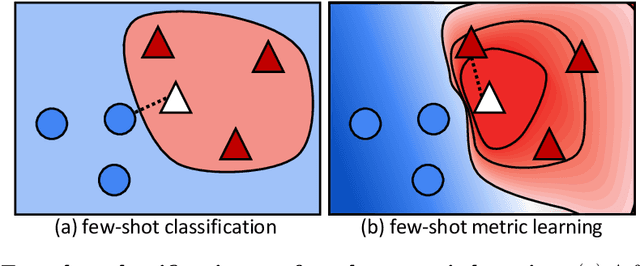

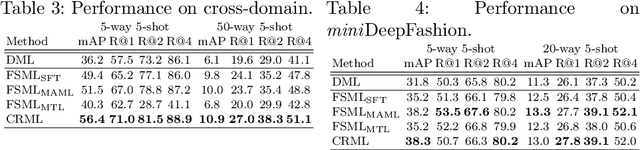
Metric learning aims to build a distance metric typically by learning an effective embedding function that maps similar objects into nearby points in its embedding space. Despite recent advances in deep metric learning, it remains challenging for the learned metric to generalize to unseen classes with a substantial domain gap. To tackle the issue, we explore a new problem of few-shot metric learning that aims to adapt the embedding function to the target domain with only a few annotated data. We introduce three few-shot metric learning baselines and propose the Channel-Rectifier Meta-Learning (CRML), which effectively adapts the metric space online by adjusting channels of intermediate layers. Experimental analyses on miniImageNet, CUB-200-2011, MPII, as well as a new dataset, miniDeepFashion, demonstrate that our method consistently improves the learned metric by adapting it to target classes and achieves a greater gain in image retrieval when the domain gap from the source classes is larger.
Explainer Divergence Scores (EDS): Some Post-Hoc Explanations May be Effective for Detecting Unknown Spurious Correlations
Nov 14, 2022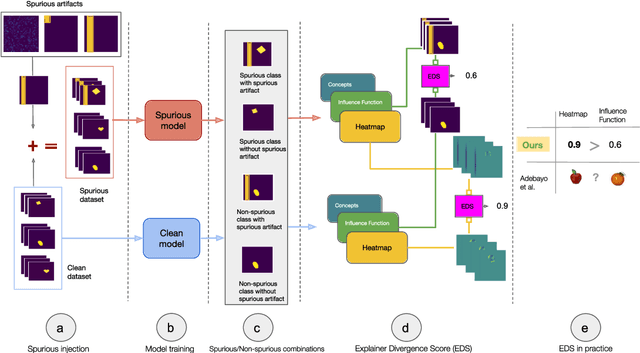
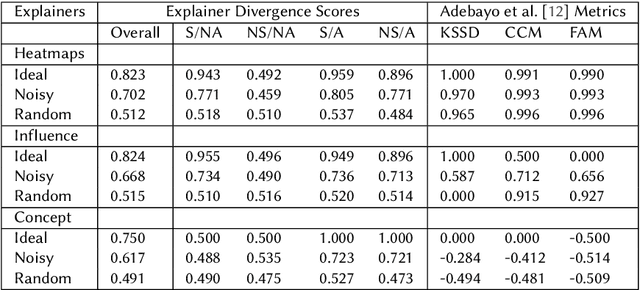
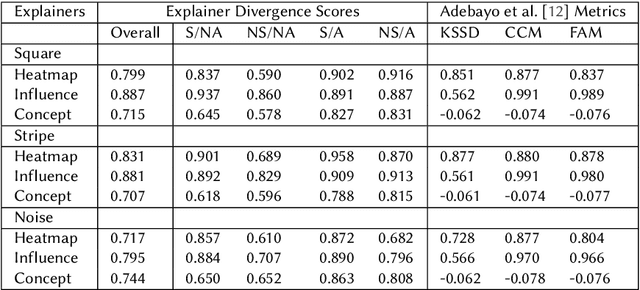
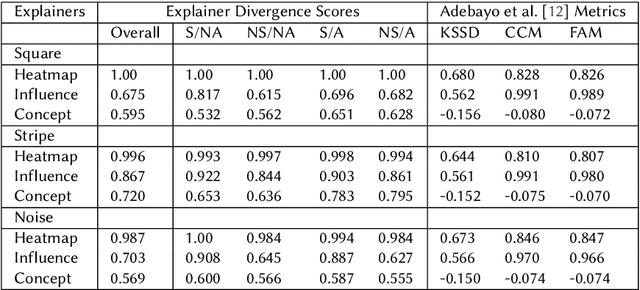
Recent work has suggested post-hoc explainers might be ineffective for detecting spurious correlations in Deep Neural Networks (DNNs). However, we show there are serious weaknesses with the existing evaluation frameworks for this setting. Previously proposed metrics are extremely difficult to interpret and are not directly comparable between explainer methods. To alleviate these constraints, we propose a new evaluation methodology, Explainer Divergence Scores (EDS), grounded in an information theory approach to evaluate explainers. EDS is easy to interpret and naturally comparable across explainers. We use our methodology to compare the detection performance of three different explainers - feature attribution methods, influential examples and concept extraction, on two different image datasets. We discover post-hoc explainers often contain substantial information about a DNN's dependence on spurious artifacts, but in ways often imperceptible to human users. This suggests the need for new techniques that can use this information to better detect a DNN's reliance on spurious correlations.
TriDoNet: A Triple Domain Model-driven Network for CT Metal Artifact Reduction
Nov 14, 2022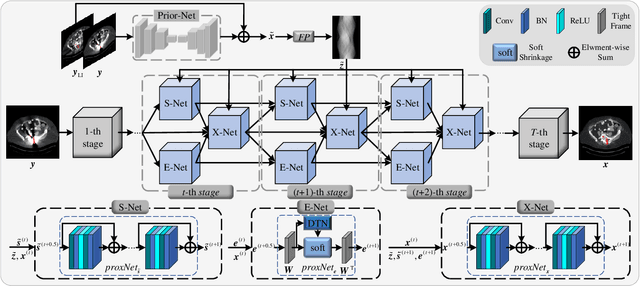
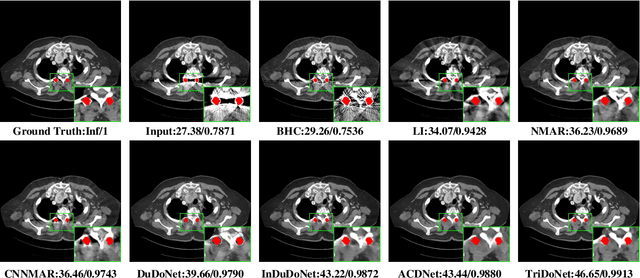
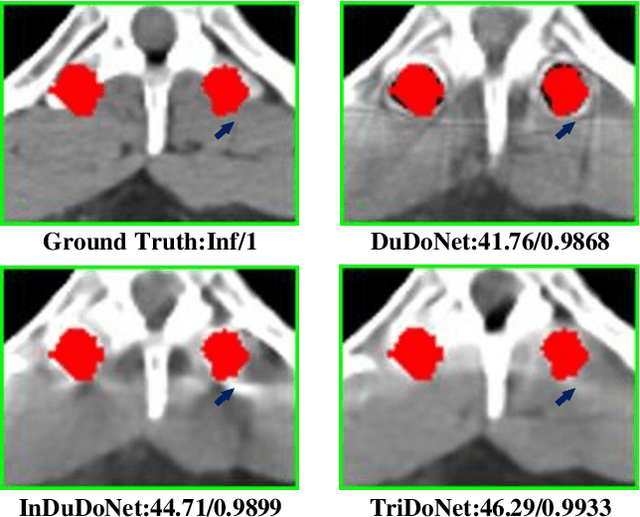
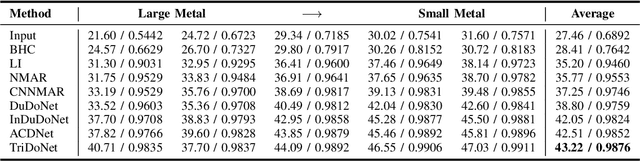
Recent deep learning-based methods have achieved promising performance for computed tomography metal artifact reduction (CTMAR). However, most of them suffer from two limitations: (i) the domain knowledge is not fully embedded into the network training; (ii) metal artifacts lack effective representation models. The aforementioned limitations leave room for further performance improvement. Against these issues, we propose a novel triple domain model-driven CTMAR network, termed as TriDoNet, whose network training exploits triple domain knowledge, i.e., the knowledge of the sinogram, CT image, and metal artifact domains. Specifically, to explore the non-local repetitive streaking patterns of metal artifacts, we encode them as an explicit tight frame sparse representation model with adaptive thresholds. Furthermore, we design a contrastive regularization (CR) built upon contrastive learning to exploit clean CT images and metal-affected images as positive and negative samples, respectively. Experimental results show that our TriDoNet can generate superior artifact-reduced CT images.
A Transformer-based Network for Deformable Medical Image Registration
Feb 24, 2022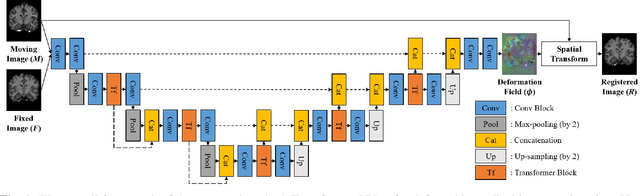
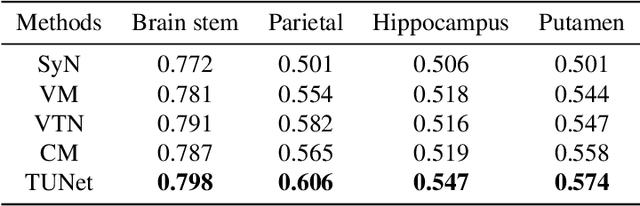
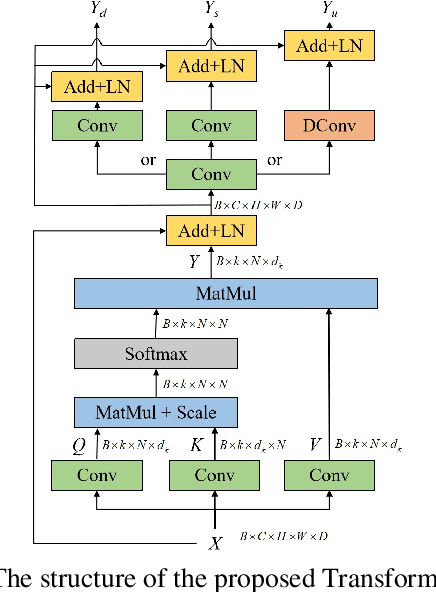
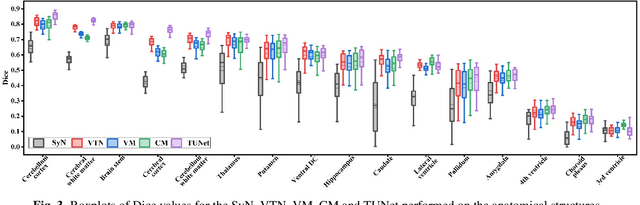
Deformable medical image registration plays an important role in clinical diagnosis and treatment. Recently, the deep learning (DL) based image registration methods have been widely investigated and showed excellent performance in computational speed. However, these methods cannot provide enough registration accuracy because of insufficient ability in representing both the global and local features of the moving and fixed images. To address this issue, this paper has proposed the transformer based image registration method. This method uses the distinctive transformer to extract the global and local image features for generating the deformation fields, based on which the registered image is produced in an unsupervised way. Our method can improve the registration accuracy effectively by means of self-attention mechanism and bi-level information flow. Experimental results on such brain MR image datasets as LPBA40 and OASIS-1 demonstrate that compared with several traditional and DL based registration methods, our method provides higher registration accuracy in terms of dice values.
* 5 pages, 4 figures, 18 conferences
Ground Plane Matters: Picking Up Ground Plane Prior in Monocular 3D Object Detection
Nov 03, 2022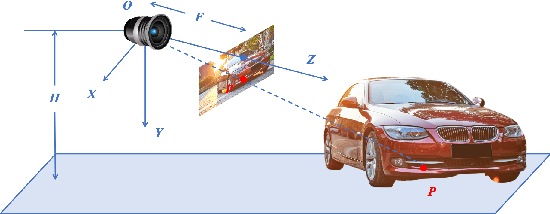



The ground plane prior is a very informative geometry clue in monocular 3D object detection (M3OD). However, it has been neglected by most mainstream methods. In this paper, we identify two key factors that limit the applicability of ground plane prior: the projection point localization issue and the ground plane tilt issue. To pick up the ground plane prior for M3OD, we propose a Ground Plane Enhanced Network (GPENet) which resolves both issues at one go. For the projection point localization issue, instead of using the bottom vertices or bottom center of the 3D bounding box (BBox), we leverage the object's ground contact points, which are explicit pixels in the image and easy for the neural network to detect. For the ground plane tilt problem, our GPENet estimates the horizon line in the image and derives a novel mathematical expression to accurately estimate the ground plane equation. An unsupervised vertical edge mining algorithm is also proposed to address the occlusion of the horizon line. Furthermore, we design a novel 3D bounding box deduction method based on a dynamic back projection algorithm, which could take advantage of the accurate contact points and the ground plane equation. Additionally, using only M3OD labels, contact point and horizon line pseudo labels can be easily generated with NO extra data collection and label annotation cost. Extensive experiments on the popular KITTI benchmark show that our GPENet can outperform other methods and achieve state-of-the-art performance, well demonstrating the effectiveness and the superiority of the proposed approach. Moreover, our GPENet works better than other methods in cross-dataset evaluation on the nuScenes dataset. Our code and models will be published.
Editable Indoor Lighting Estimation
Nov 09, 2022
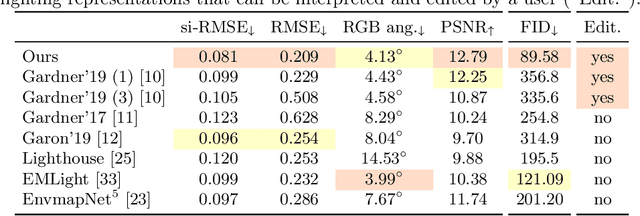
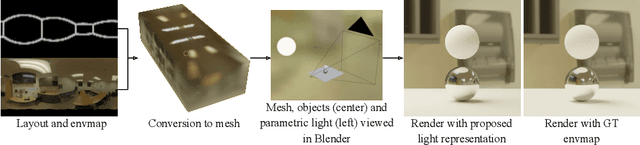
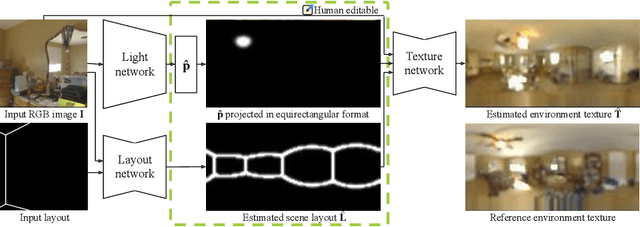
We present a method for estimating lighting from a single perspective image of an indoor scene. Previous methods for predicting indoor illumination usually focus on either simple, parametric lighting that lack realism, or on richer representations that are difficult or even impossible to understand or modify after prediction. We propose a pipeline that estimates a parametric light that is easy to edit and allows renderings with strong shadows, alongside with a non-parametric texture with high-frequency information necessary for realistic rendering of specular objects. Once estimated, the predictions obtained with our model are interpretable and can easily be modified by an artist/user with a few mouse clicks. Quantitative and qualitative results show that our approach makes indoor lighting estimation easier to handle by a casual user, while still producing competitive results.
SegNeRF: 3D Part Segmentation with Neural Radiance Fields
Nov 22, 2022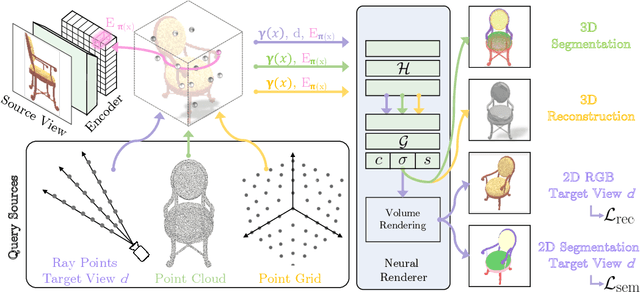


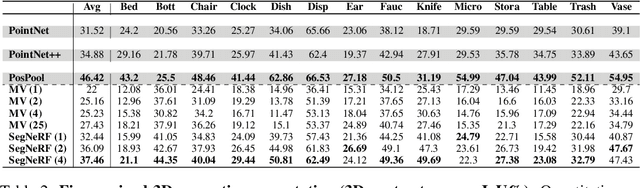
Recent advances in Neural Radiance Fields (NeRF) boast impressive performances for generative tasks such as novel view synthesis and 3D reconstruction. Methods based on neural radiance fields are able to represent the 3D world implicitly by relying exclusively on posed images. Yet, they have seldom been explored in the realm of discriminative tasks such as 3D part segmentation. In this work, we attempt to bridge that gap by proposing SegNeRF: a neural field representation that integrates a semantic field along with the usual radiance field. SegNeRF inherits from previous works the ability to perform novel view synthesis and 3D reconstruction, and enables 3D part segmentation from a few images. Our extensive experiments on PartNet show that SegNeRF is capable of simultaneously predicting geometry, appearance, and semantic information from posed images, even for unseen objects. The predicted semantic fields allow SegNeRF to achieve an average mIoU of $\textbf{30.30%}$ for 2D novel view segmentation, and $\textbf{37.46%}$ for 3D part segmentation, boasting competitive performance against point-based methods by using only a few posed images. Additionally, SegNeRF is able to generate an explicit 3D model from a single image of an object taken in the wild, with its corresponding part segmentation.
Compositional Scene Modeling with Global Object-Centric Representations
Nov 22, 2022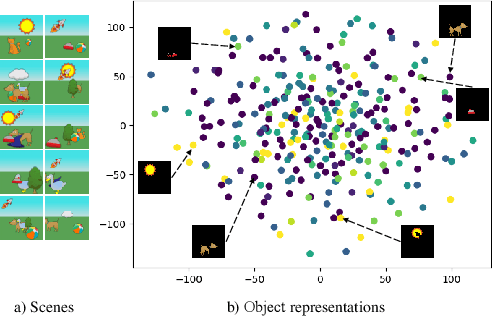
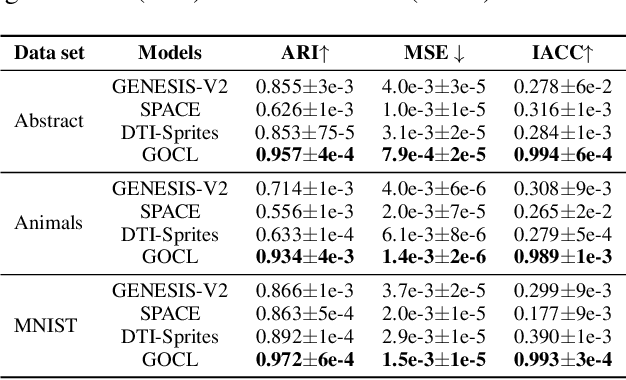
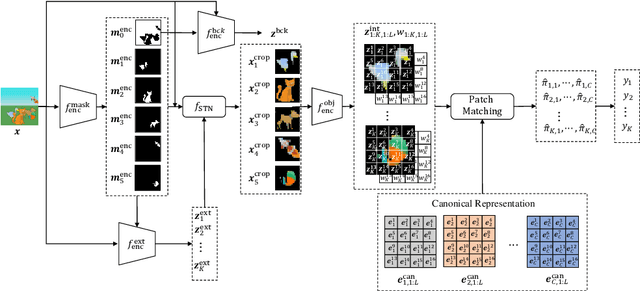
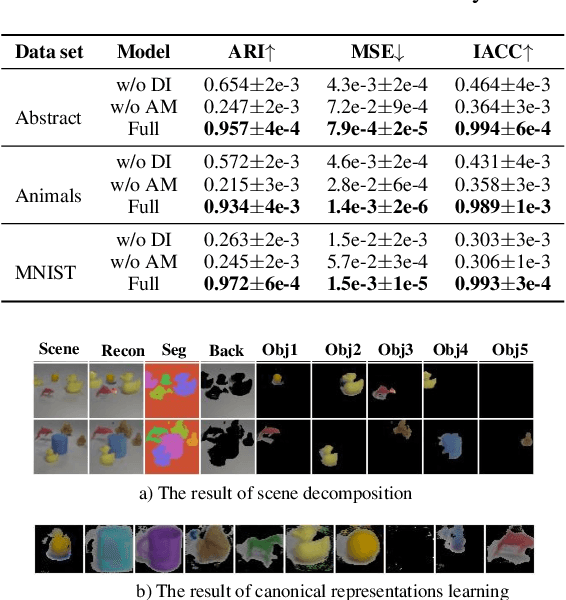
The appearance of the same object may vary in different scene images due to perspectives and occlusions between objects. Humans can easily identify the same object, even if occlusions exist, by completing the occluded parts based on its canonical image in the memory. Achieving this ability is still a challenge for machine learning, especially under the unsupervised learning setting. Inspired by such an ability of humans, this paper proposes a compositional scene modeling method to infer global representations of canonical images of objects without any supervision. The representation of each object is divided into an intrinsic part, which characterizes globally invariant information (i.e. canonical representation of an object), and an extrinsic part, which characterizes scene-dependent information (e.g., position and size). To infer the intrinsic representation of each object, we employ a patch-matching strategy to align the representation of a potentially occluded object with the canonical representations of objects, and sample the most probable canonical representation based on the category of object determined by amortized variational inference. Extensive experiments are conducted on four object-centric learning benchmarks, and experimental results demonstrate that the proposed method not only outperforms state-of-the-arts in terms of segmentation and reconstruction, but also achieves good global object identification performance.
PromptTTS: Controllable Text-to-Speech with Text Descriptions
Nov 22, 2022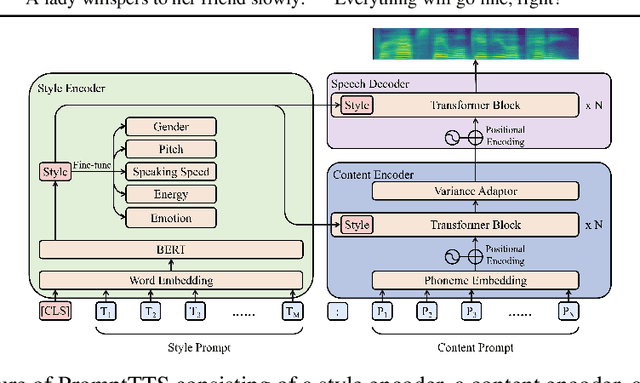
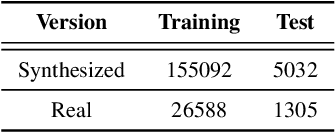

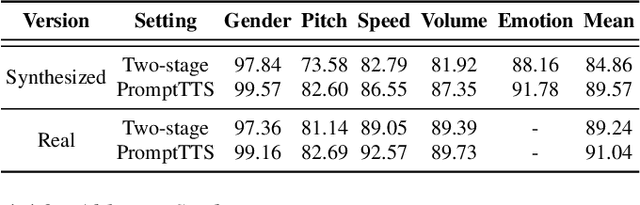
Using a text description as prompt to guide the generation of text or images (e.g., GPT-3 or DALLE-2) has drawn wide attention recently. Beyond text and image generation, in this work, we explore the possibility of utilizing text descriptions to guide speech synthesis. Thus, we develop a text-to-speech (TTS) system (dubbed as PromptTTS) that takes a prompt with both style and content descriptions as input to synthesize the corresponding speech. Specifically, PromptTTS consists of a style encoder and a content encoder to extract the corresponding representations from the prompt, and a speech decoder to synthesize speech according to the extracted style and content representations. Compared with previous works in controllable TTS that require users to have acoustic knowledge to understand style factors such as prosody and pitch, PromptTTS is more user-friendly since text descriptions are a more natural way to express speech style (e.g., ''A lady whispers to her friend slowly''). Given that there is no TTS dataset with prompts, to benchmark the task of PromptTTS, we construct and release a dataset containing prompts with style and content information and the corresponding speech. Experiments show that PromptTTS can generate speech with precise style control and high speech quality. Audio samples and our dataset are publicly available.