 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Visual-textual Sentiment Analysis by Fusing Expert Features
Nov 23, 2022

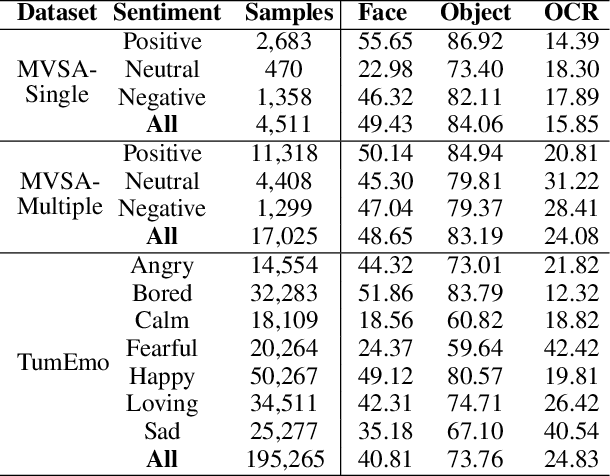
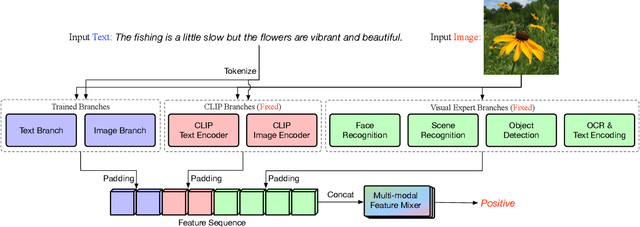
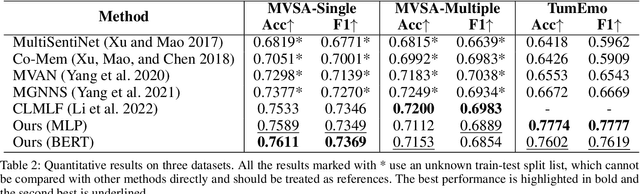
Visual-textual sentiment analysis aims to predict sentiment with the input of a pair of image and text. The main challenge of visual-textual sentiment analysis is how to learn effective visual features for sentiment prediction since input images are often very diverse. To address this challenge, we propose a new method that improves visual-textual sentiment analysis by introducing powerful expert visual features. The proposed method consists of four parts: (1) a visual-textual branch to learn features directly from data for sentiment analysis, (2) a visual expert branch with a set of pre-trained "expert" encoders to extract effective visual features, (3) a CLIP branch to implicitly model visual-textual correspondence, and (4) a multimodal feature fusion network based on either BERT or MLP to fuse multimodal features and make sentiment prediction. Extensive experiments on three datasets show that our method produces better visual-textual sentiment analysis performance than existing methods.
ActMAD: Activation Matching to Align Distributions for Test-Time-Training
Nov 23, 2022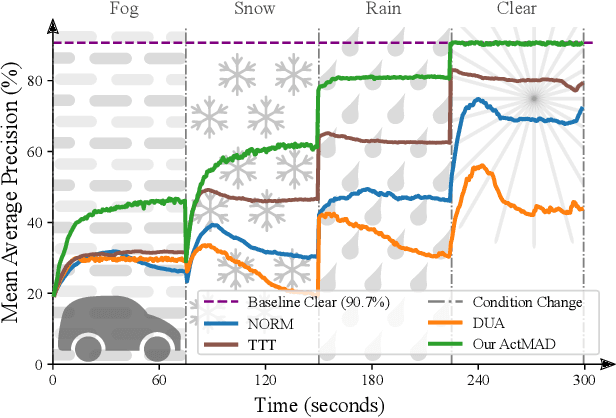
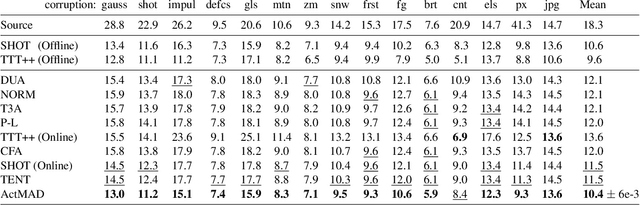
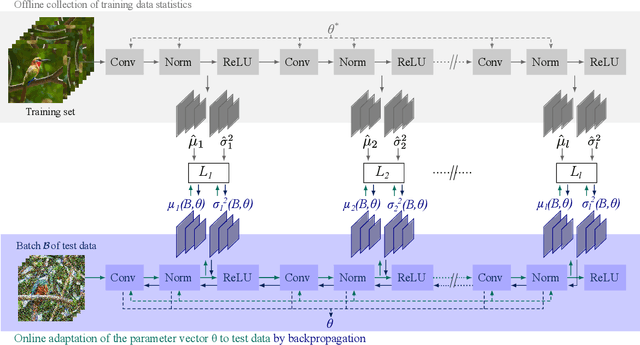
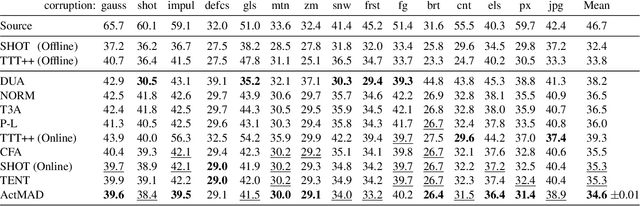
Test-Time-Training (TTT) is an approach to cope with out-of-distribution (OOD) data by adapting a trained model to distribution shifts occurring at test-time. We propose to perform this adaptation via Activation Matching (ActMAD): We analyze activations of the model and align activation statistics of the OOD test data to those of the training data. In contrast to existing methods, which model the distribution of entire channels in the ultimate layer of the feature extractor, we model the distribution of each feature in multiple layers across the network. This results in a more fine-grained supervision and makes ActMAD attain state of the art performance on CIFAR-100C and Imagenet-C. ActMAD is also architecture- and task-agnostic, which lets us go beyond image classification, and score 15.4% improvement over previous approaches when evaluating a KITTI-trained object detector on KITTI-Fog. Our experiments highlight that ActMAD can be applied to online adaptation in realistic scenarios, requiring little data to attain its full performance.
R2C-GAN: Restore-to-Classify GANs for Blind X-Ray Restoration and COVID-19 Classification
Sep 29, 2022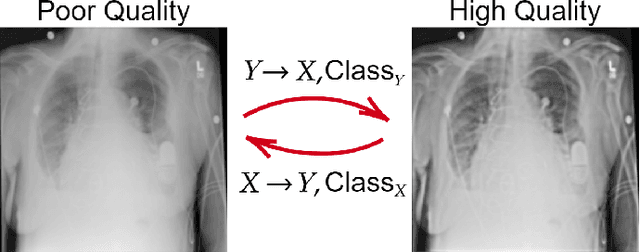
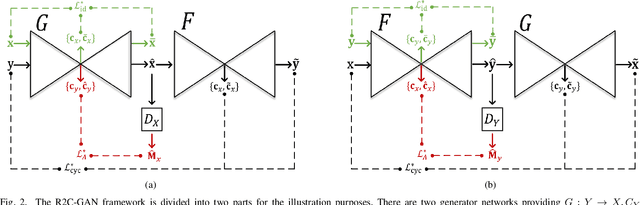
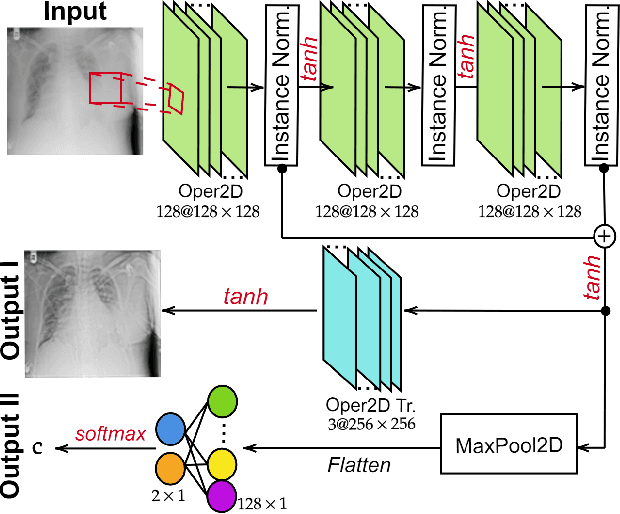
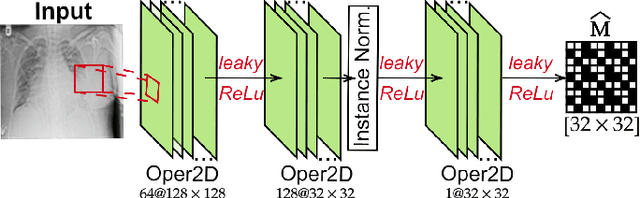
Restoration of poor quality images with a blended set of artifacts plays a vital role for a reliable diagnosis. Existing studies have focused on specific restoration problems such as image deblurring, denoising, and exposure correction where there is usually a strong assumption on the artifact type and severity. As a pioneer study in blind X-ray restoration, we propose a joint model for generic image restoration and classification: Restore-to-Classify Generative Adversarial Networks (R2C-GANs). Such a jointly optimized model keeps any disease intact after the restoration. Therefore, this will naturally lead to a higher diagnosis performance thanks to the improved X-ray image quality. To accomplish this crucial objective, we define the restoration task as an Image-to-Image translation problem from poor quality having noisy, blurry, or over/under-exposed images to high quality image domain. The proposed R2C-GAN model is able to learn forward and inverse transforms between the two domains using unpaired training samples. Simultaneously, the joint classification preserves the disease label during restoration. Moreover, the R2C-GANs are equipped with operational layers/neurons reducing the network depth and further boosting both restoration and classification performances. The proposed joint model is extensively evaluated over the QaTa-COV19 dataset for Coronavirus Disease 2019 (COVID-19) classification. The proposed restoration approach achieves over 90% F1-Score which is significantly higher than the performance of any deep model. Moreover, in the qualitative analysis, the restoration performance of R2C-GANs is approved by a group of medical doctors. We share the software implementation at https://github.com/meteahishali/R2C-GAN.
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Mar 26, 2022
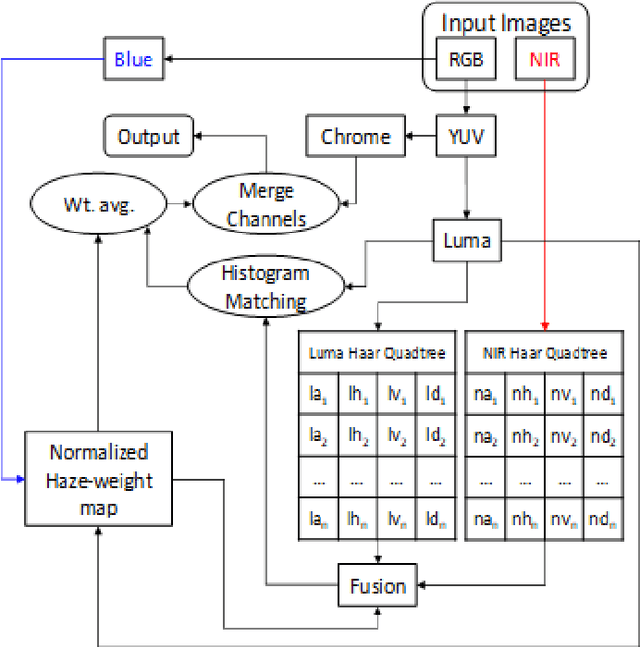
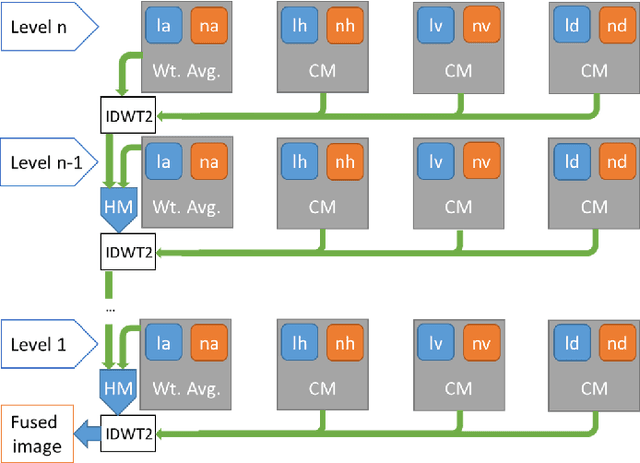
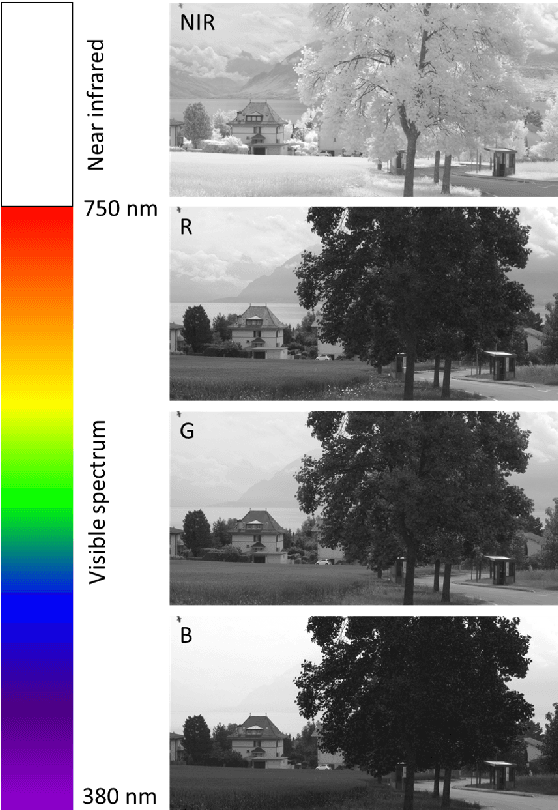
We propose a fusion algorithm for haze removal that combines color information from an RGB image and edge information extracted from its corresponding NIR image using Haar wavelets. The proposed algorithm is based on the key observation that NIR edge features are more prominent in the hazy regions of the image than the RGB edge features in those same regions. To combine the color and edge information, we introduce a haze-weight map which proportionately distributes the color and edge information during the fusion process. Because NIR images are, intrinsically, nearly haze-free, our work makes no assumptions like existing works that rely on a scattering model and essentially designing a depth-independent method. This helps in minimizing artifacts and gives a more realistic sense to the restored haze-free image. Extensive experiments show that the proposed algorithm is both qualitatively and quantitatively better on several key metrics when compared to existing state-of-the-art methods.
* Accepted in 25th International Conference on Pattern Recognition (ICPR 2020)
Auto Lead Extraction and Digitization of ECG Paper Records using cGAN
Nov 12, 2022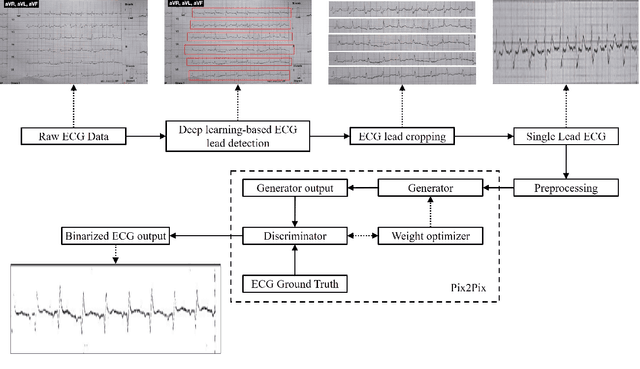
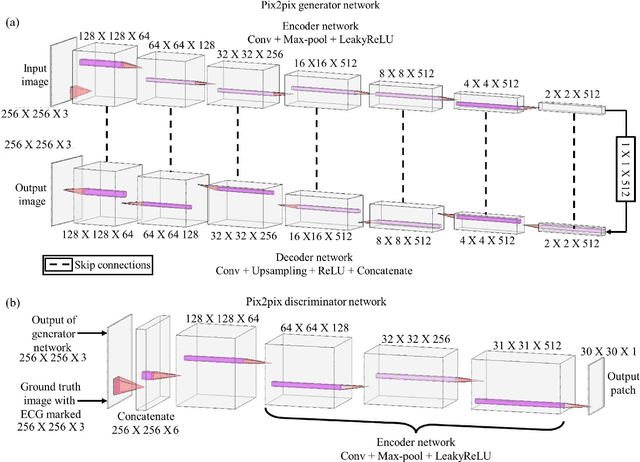
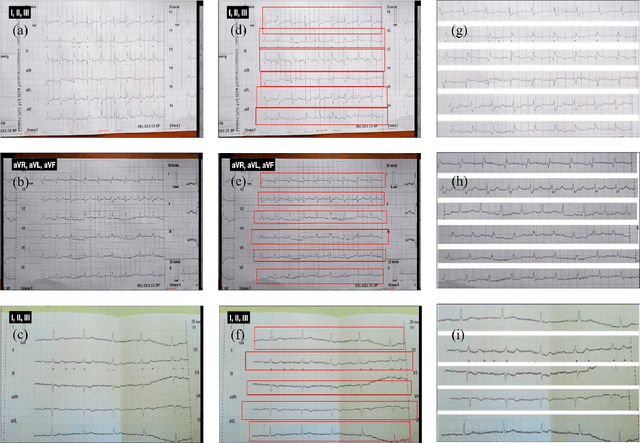
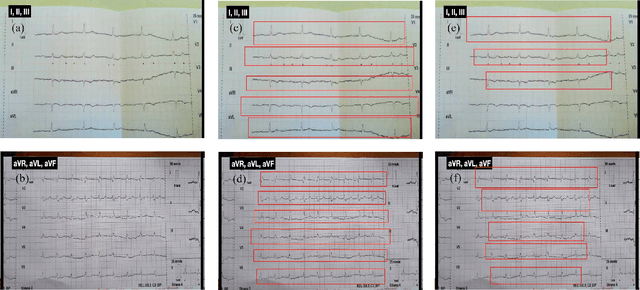
Purpose: An Electrocardiogram (ECG) is the simplest and fastest bio-medical test that is used to detect any heart-related disease. ECG signals are generally stored in paper form, which makes it difficult to store and analyze the data. While capturing ECG leads from paper ECG records, a lot of background information is also captured, which results in incorrect data interpretation. Methods: We propose a deep learning-based model for individually extracting all 12 leads from 12-lead ECG images captured using a camera. To simplify the analysis of the ECG and the calculation of complex parameters, we also propose a method to convert the paper ECG format into a storable digital format. The You Only Look Once, Version 3 (YOLOv3) algorithm has been used to extract the leads present in the image. These leads are then passed on to another deep learning model which separates the ECG signal and background from the single-lead image. After that, vertical scanning is performed on the ECG signal to convert it into a 1-Dimensional (1D) digital form. To perform the task of digitalization, we used the pix-2-pix deep learning model and binarized the ECG signals. Results: Our proposed method was able to achieve an accuracy of 97.4 %. Conclusion: The information on the paper ECG fades away over time. Hence, the digitized ECG signals make it possible to store the records and access them anytime. This proves highly beneficial for heart patients who require frequent ECG reports. The stored data can also be useful for research purposes, as this data can be used to develop computer algorithms that are capable of analyzing the data.
DALL-E-Bot: Introducing Web-Scale Diffusion Models to Robotics
Oct 05, 2022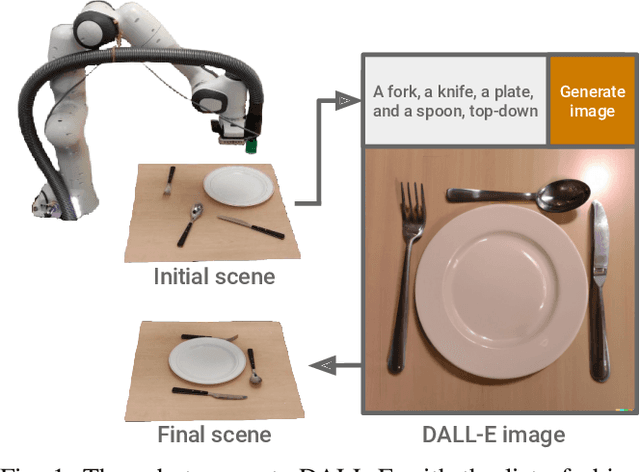
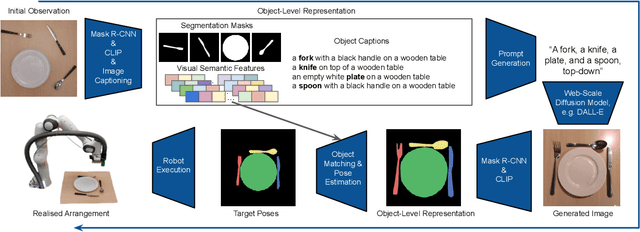

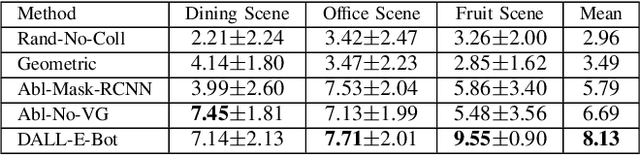
We introduce the first work to explore web-scale diffusion models for robotics. DALL-E-Bot enables a robot to rearrange objects in a scene, by first inferring a text description of those objects, then generating an image representing a natural, human-like arrangement of those objects, and finally physically arranging the objects according to that image. The significance is that we achieve this zero-shot using DALL-E, without needing any further data collection or training. Encouraging real-world results with human studies show that this is an exciting direction for the future of web-scale robot learning algorithms. We also propose a list of recommendations to the text-to-image community, to align further developments of these models with applications to robotics. Videos are available at: https://www.robot-learning.uk/dall-e-bot
Image Captioning In the Transformer Age
Apr 15, 2022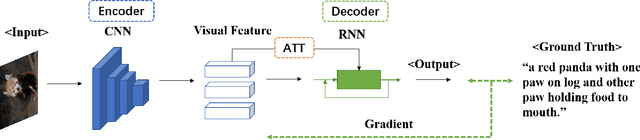
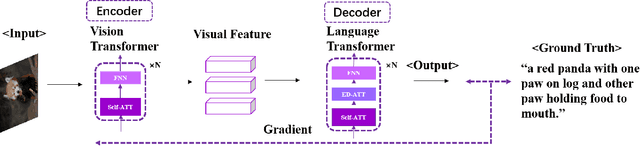
Image Captioning (IC) has achieved astonishing developments by incorporating various techniques into the CNN-RNN encoder-decoder architecture. However, since CNN and RNN do not share the basic network component, such a heterogeneous pipeline is hard to be trained end-to-end where the visual encoder will not learn anything from the caption supervision. This drawback inspires the researchers to develop a homogeneous architecture that facilitates end-to-end training, for which Transformer is the perfect one that has proven its huge potential in both vision and language domains and thus can be used as the basic component of the visual encoder and language decoder in an IC pipeline. Meantime, self-supervised learning releases the power of the Transformer architecture that a pre-trained large-scale one can be generalized to various tasks including IC. The success of these large-scale models seems to weaken the importance of the single IC task. However, we demonstrate that IC still has its specific significance in this age by analyzing the connections between IC with some popular self-supervised learning paradigms. Due to the page limitation, we only refer to highly important papers in this short survey and more related works can be found at https://github.com/SjokerLily/awesome-image-captioning.
Improving Zero-Shot Models with Label Distribution Priors
Dec 01, 2022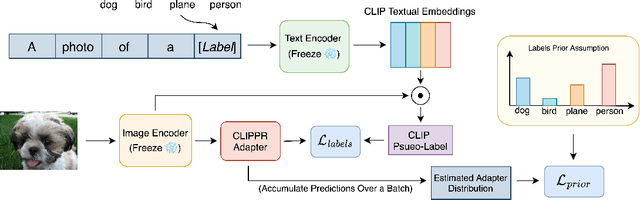

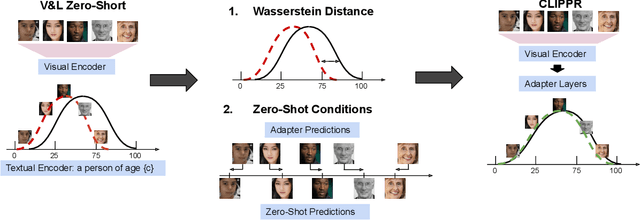

Labeling large image datasets with attributes such as facial age or object type is tedious and sometimes infeasible. Supervised machine learning methods provide a highly accurate solution, but require manual labels which are often unavailable. Zero-shot models (e.g., CLIP) do not require manual labels but are not as accurate as supervised ones, particularly when the attribute is numeric. We propose a new approach, CLIPPR (CLIP with Priors), which adapts zero-shot models for regression and classification on unlabelled datasets. Our method does not use any annotated images. Instead, we assume a prior over the label distribution in the dataset. We then train an adapter network on top of CLIP under two competing objectives: i) minimal change of predictions from the original CLIP model ii) minimal distance between predicted and prior distribution of labels. Additionally, we present a novel approach for selecting prompts for Vision & Language models using a distributional prior. Our method is effective and presents a significant improvement over the original model. We demonstrate an improvement of 28% in mean absolute error on the UTK age regression task. We also present promising results for classification benchmarks, improving the classification accuracy on the ImageNet dataset by 2.83%, without using any labels.
Hyperbolic Contrastive Learning for Visual Representations beyond Objects
Dec 01, 2022
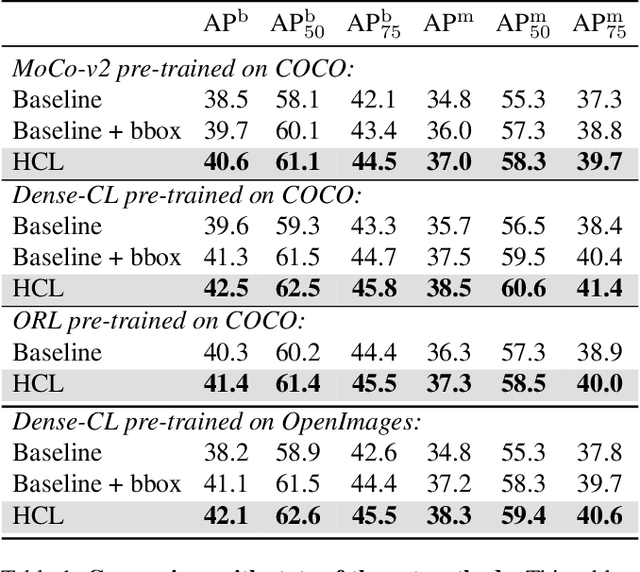
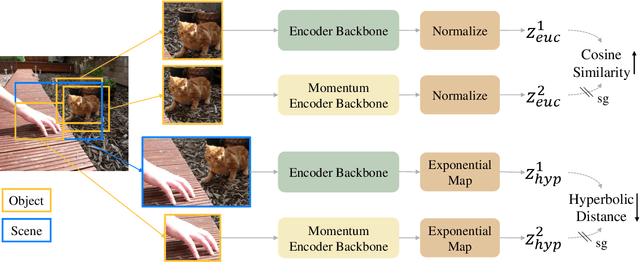
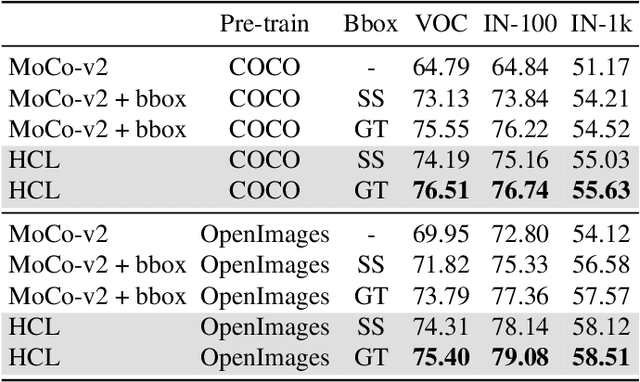
Although self-/un-supervised methods have led to rapid progress in visual representation learning, these methods generally treat objects and scenes using the same lens. In this paper, we focus on learning representations for objects and scenes that preserve the structure among them. Motivated by the observation that visually similar objects are close in the representation space, we argue that the scenes and objects should instead follow a hierarchical structure based on their compositionality. To exploit such a structure, we propose a contrastive learning framework where a Euclidean loss is used to learn object representations and a hyperbolic loss is used to encourage representations of scenes to lie close to representations of their constituent objects in a hyperbolic space. This novel hyperbolic objective encourages the scene-object hypernymy among the representations by optimizing the magnitude of their norms. We show that when pretraining on the COCO and OpenImages datasets, the hyperbolic loss improves downstream performance of several baselines across multiple datasets and tasks, including image classification, object detection, and semantic segmentation. We also show that the properties of the learned representations allow us to solve various vision tasks that involve the interaction between scenes and objects in a zero-shot fashion. Our code can be found at \url{https://github.com/shlokk/HCL/tree/main/HCL}.
Multi-View Consistent Generative Adversarial Networks for 3D-aware Image Synthesis
Apr 13, 2022
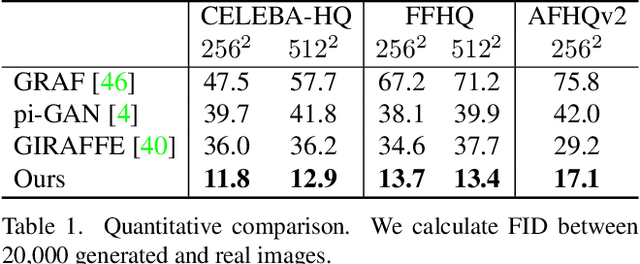
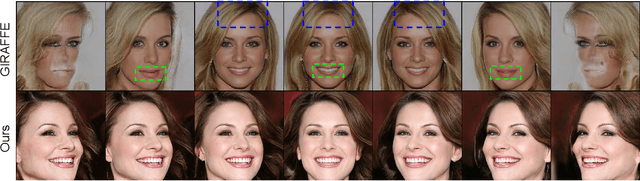
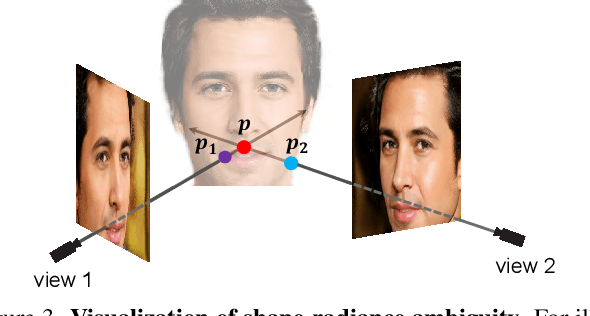
3D-aware image synthesis aims to generate images of objects from multiple views by learning a 3D representation. However, one key challenge remains: existing approaches lack geometry constraints, hence usually fail to generate multi-view consistent images. To address this challenge, we propose Multi-View Consistent Generative Adversarial Networks (MVCGAN) for high-quality 3D-aware image synthesis with geometry constraints. By leveraging the underlying 3D geometry information of generated images, i.e., depth and camera transformation matrix, we explicitly establish stereo correspondence between views to perform multi-view joint optimization. In particular, we enforce the photometric consistency between pairs of views and integrate a stereo mixup mechanism into the training process, encouraging the model to reason about the correct 3D shape. Besides, we design a two-stage training strategy with feature-level multi-view joint optimization to improve the image quality. Extensive experiments on three datasets demonstrate that MVCGAN achieves the state-of-the-art performance for 3D-aware image synthesis.