 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pose-disentangled Contrastive Learning for Self-supervised Facial Representation
Nov 24, 2022
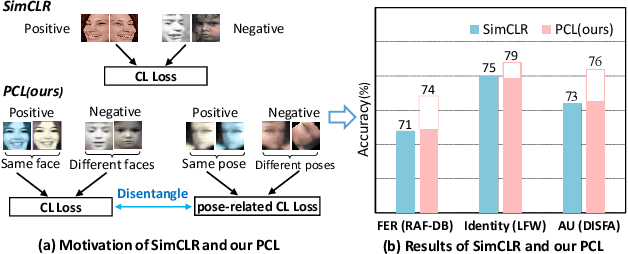
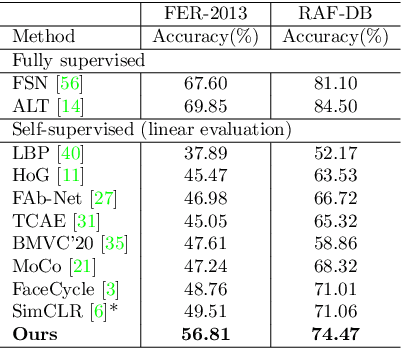
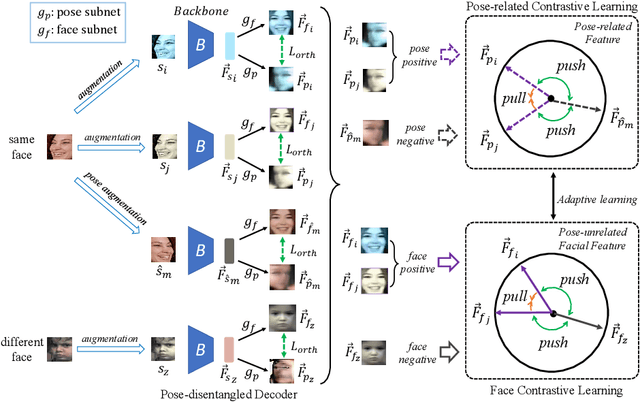
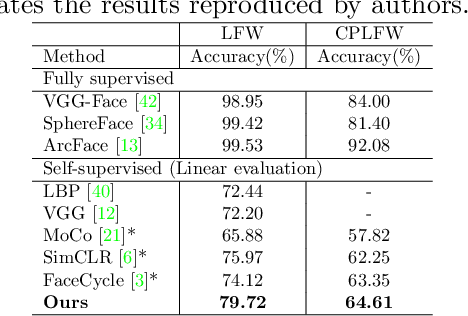
Self-supervised facial representation has recently attracted increasing attention due to its ability to perform face understanding without relying on large-scale annotated datasets heavily. However, analytically, current contrastive-based self-supervised learning still performs unsatisfactorily for learning facial representation. More specifically, existing contrastive learning (CL) tends to learn pose-invariant features that cannot depict the pose details of faces, compromising the learning performance. To conquer the above limitation of CL, we propose a novel Pose-disentangled Contrastive Learning (PCL) method for general self-supervised facial representation. Our PCL first devises a pose-disentangled decoder (PDD) with a delicately designed orthogonalizing regulation, which disentangles the pose-related features from the face-aware features; therefore, pose-related and other pose-unrelated facial information could be performed in individual subnetworks and do not affect each other's training. Furthermore, we introduce a pose-related contrastive learning scheme that learns pose-related information based on data augmentation of the same image, which would deliver more effective face-aware representation for various downstream tasks. We conducted a comprehensive linear evaluation on three challenging downstream facial understanding tasks, i.e., facial expression recognition, face recognition, and AU detection. Experimental results demonstrate that our method outperforms cutting-edge contrastive and other self-supervised learning methods with a great margin.
Shortcut Removal for Improved OOD-Generalization
Nov 24, 2022


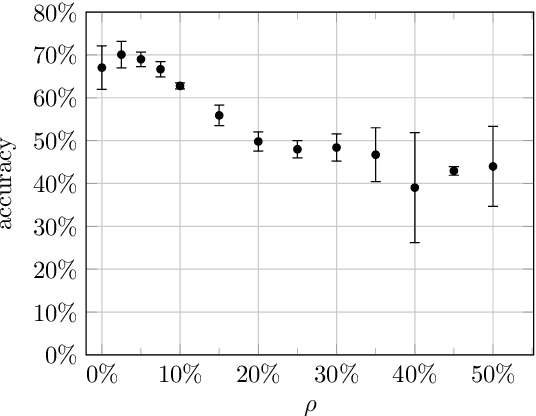
Machine learning is a data-driven discipline, and learning success is largely dependent on the quality of the underlying data sets. However, it is becoming increasingly clear that even high performance on held-out test data does not necessarily mean that a model generalizes or learns anything meaningful at all. One reason for this is the presence of machine learning shortcuts, i.e., hints in the data that are predictive but accidental and semantically unconnected to the problem. We present a new approach to detect such shortcuts and a technique to automatically remove them from datasets. Using an adversarially trained lens, any small and highly predictive clues in images can be detected and removed. We show that this approach 1) does not cause degradation of model performance in the absence of these shortcuts, and 2) reliably identifies and neutralizes shortcuts from different image datasets. In our experiments, we are able to recover up to 93,8% of model performance in the presence of different shortcuts. Finally, we apply our model to a real-world dataset from the medical domain consisting of chest x-rays and identify and remove several types of shortcuts that are known to hinder real-world applicability. Thus, we hope that our proposed approach fosters real-world applicability of machine learning.
Sports Camera Pose Refinement Using an Evolution Strategy
Nov 03, 2022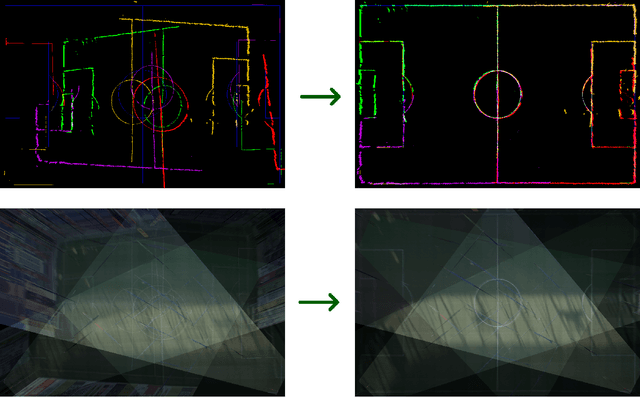
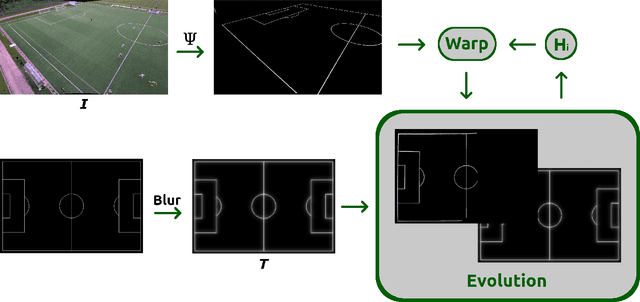
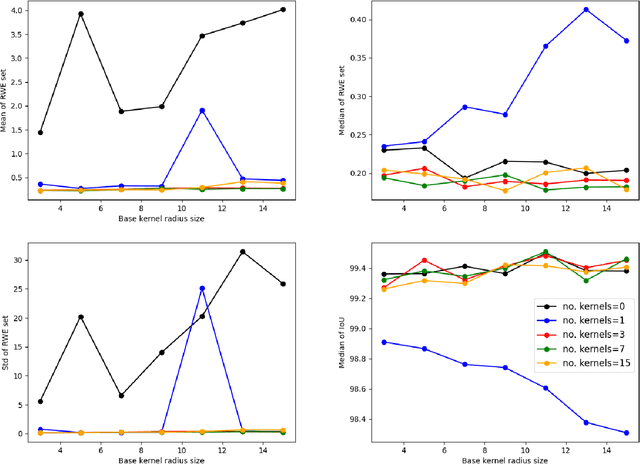
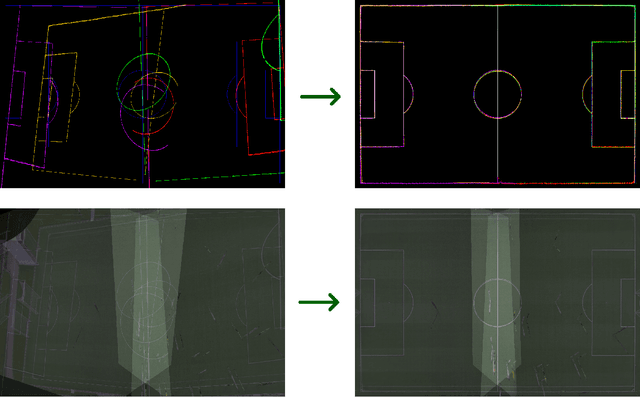
This paper presents a robust end-to-end method for sports cameras extrinsic parameters optimization using a novel evolution strategy. First, we developed a neural network architecture for an edge or area-based segmentation of a sports field. Secondly, we implemented the evolution strategy, which purpose is to refine extrinsic camera parameters given a single, segmented sports field image. Experimental comparison with state-of-the-art camera pose refinement methods on real-world data demonstrates the superiority of the proposed algorithm. We also perform an ablation study and propose a way to generalize the method to additionally refine the intrinsic camera matrix.
Seeing the Unseen: Errors and Bias in Visual Datasets
Nov 03, 2022

From face recognition in smartphones to automatic routing on self-driving cars, machine vision algorithms lie in the core of these features. These systems solve image based tasks by identifying and understanding objects, subsequently making decisions from these information. However, errors in datasets are usually induced or even magnified in algorithms, at times resulting in issues such as recognising black people as gorillas and misrepresenting ethnicities in search results. This paper tracks the errors in datasets and their impacts, revealing that a flawed dataset could be a result of limited categories, incomprehensive sourcing and poor classification.
MultiStyleGAN: Multiple One-shot Face Stylizations using a Single GAN
Oct 08, 2022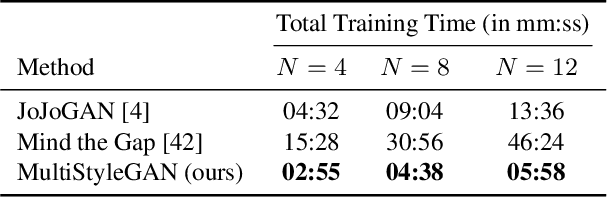
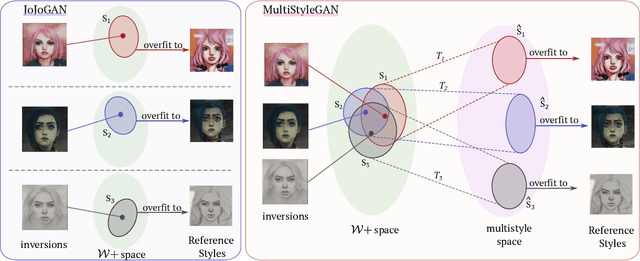
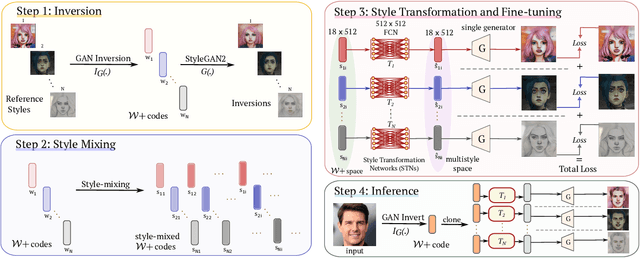

Image stylization aims at applying a reference style to arbitrary input images. A common scenario is one-shot stylization, where only one example is available for each reference style. A successful recent approach for one-shot face stylization is JoJoGAN, which fine-tunes a pre-trained StyleGAN2 generator on a single style reference image. However, it cannot generate multiple stylizations without fine-tuning a new model for each style separately. In this work, we present a MultiStyleGAN method that is capable of producing multiple different face stylizations at once by fine-tuning a single generator. The key component of our method is a learnable Style Transformation module that takes latent codes as input and learns linear mappings to different regions of the latent space to produce distinct codes for each style, resulting in a multistyle space. Our model inherently mitigates overfitting since it is trained on multiple styles, hence improving the quality of stylizations. Our method can learn upwards of $12$ image stylizations at once, bringing upto $8\times$ improvement in training time. We support our results through user studies that indicate meaningful improvements over existing methods.
3D-UCaps: 3D Capsules Unet for Volumetric Image Segmentation
Mar 16, 2022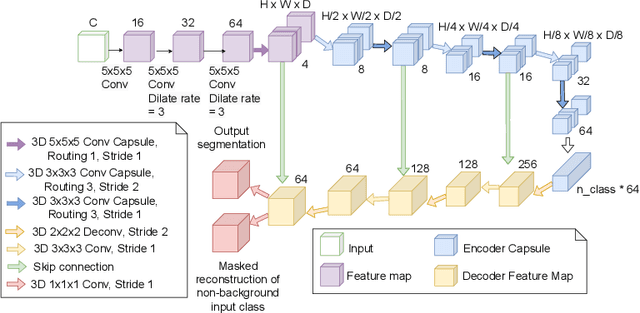
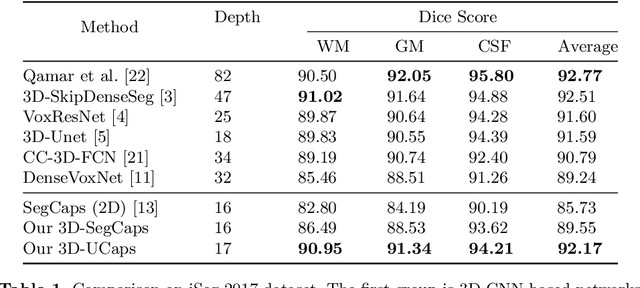
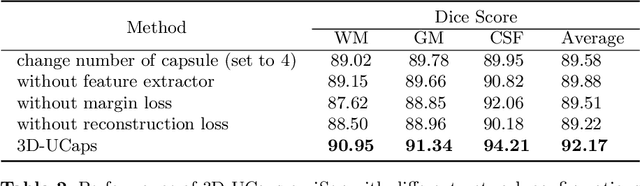
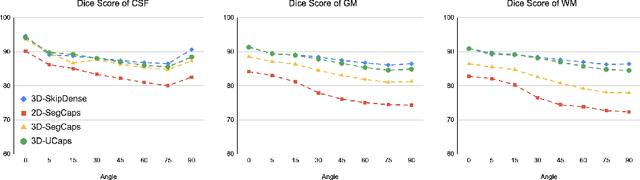
Medical image segmentation has been so far achieving promising results with Convolutional Neural Networks (CNNs). However, it is arguable that in traditional CNNs, its pooling layer tends to discard important information such as positions. Moreover, CNNs are sensitive to rotation and affine transformation. Capsule network is a data-efficient network design proposed to overcome such limitations by replacing pooling layers with dynamic routing and convolutional strides, which aims to preserve the part-whole relationships. Capsule network has shown a great performance in image recognition and natural language processing, but applications for medical image segmentation, particularly volumetric image segmentation, has been limited. In this work, we propose 3D-UCaps, a 3D voxel-based Capsule network for medical volumetric image segmentation. We build the concept of capsules into a CNN by designing a network with two pathways: the first pathway is encoded by 3D Capsule blocks, whereas the second pathway is decoded by 3D CNNs blocks. 3D-UCaps, therefore inherits the merits from both Capsule network to preserve the spatial relationship and CNNs to learn visual representation. We conducted experiments on various datasets to demonstrate the robustness of 3D-UCaps including iSeg-2017, LUNA16, Hippocampus, and Cardiac, where our method outperforms previous Capsule networks and 3D-Unets.
visClust: A visual clustering algorithm based on orthogonal projections
Nov 07, 2022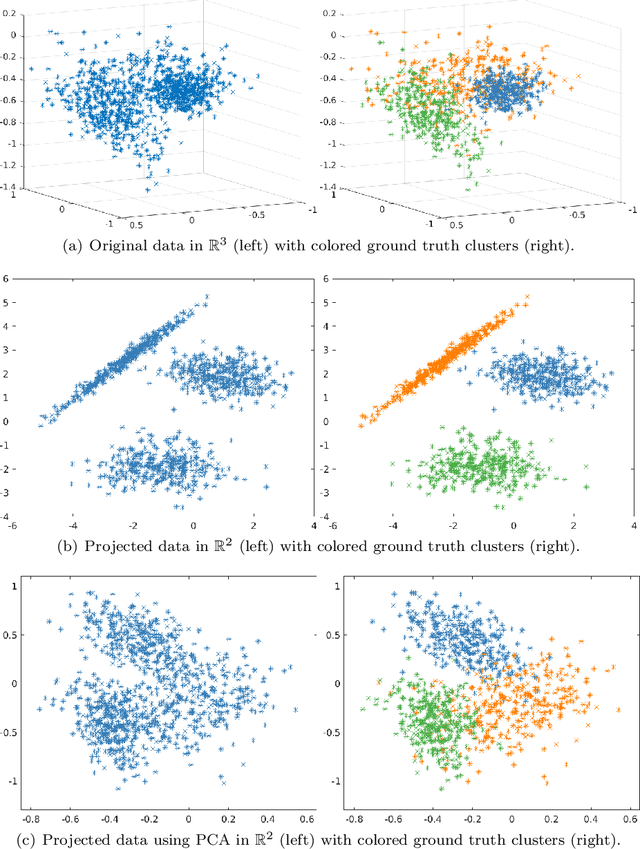


We present a novel clustering algorithm, visClust, that is based on lower dimensional data representations and visual interpretation. Thereto, we design a transformation that allows the data to be represented by a binary integer array enabling the further use of image processing methods to select a partition. Qualitative and quantitative analyses show that the algorithm obtains high accuracy (measured with an adjusted one-sided Rand-Index) and requires low runtime and RAM. We compare the results to 6 state-of-the-art algorithms, confirming the quality of visClust by outperforming in most experiments. Moreover, the algorithm asks for just one obligatory input parameter while allowing optimization via optional parameters. The code is made available on GitHub.
HiVLP: Hierarchical Vision-Language Pre-Training for Fast Image-Text Retrieval
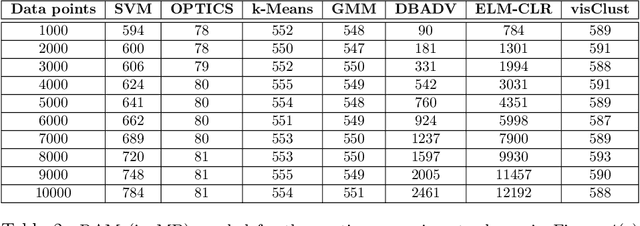
May 24, 2022
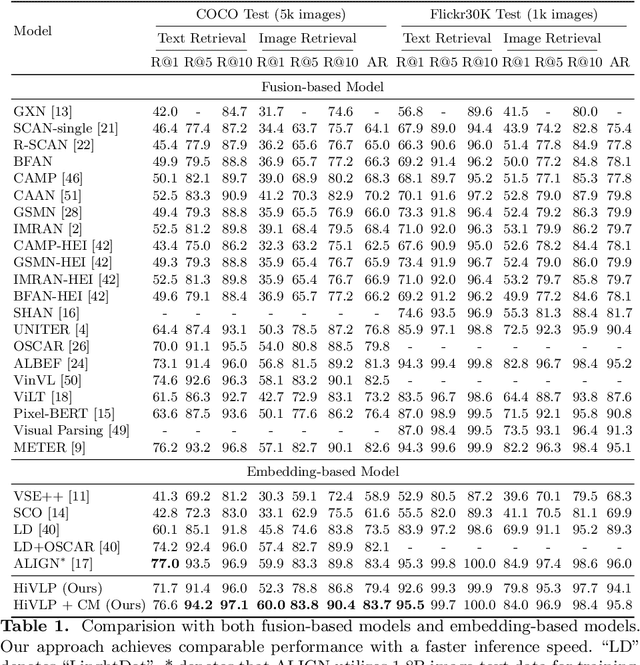
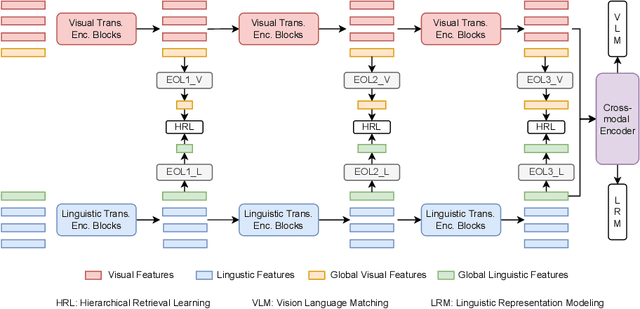
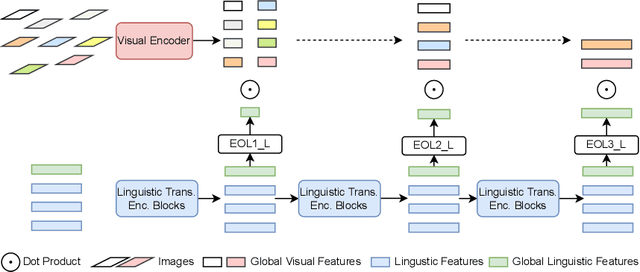
In the past few years, the emergence of vision-language pre-training (VLP) has brought cross-modal retrieval to a new era. However, due to the latency and computation demand, it is commonly challenging to apply VLP in a real-time online retrieval system. To alleviate the defect, this paper proposes a \textbf{Hi}erarchical \textbf{V}ision-\textbf{}Language \textbf{P}re-Training (\textbf{HiVLP}) for fast Image-Text Retrieval (ITR). Specifically, we design a novel hierarchical retrieval objective, which uses the representation of different dimensions for coarse-to-fine ITR, i.e., using low-dimensional representation for large-scale coarse retrieval and high-dimensional representation for small-scale fine retrieval. We evaluate our proposed HiVLP on two popular image-text retrieval benchmarks, i.e., Flickr30k and COCO. Extensive experiments demonstrate that our HiVLP not only has fast inference speed but also can be easily scaled to large-scale ITR scenarios. The detailed results show that HiVLP is $1,427$$\sim$$120,649\times$ faster than the fusion-based model UNITER and 2$\sim$5 faster than the fastest embedding-based model LightingDot in different candidate scenarios. It also achieves about +4.9 AR on COCO and +3.8 AR on Flickr30K than LightingDot and achieves comparable performance with the state-of-the-art (SOTA) fusion-based model METER.
Evidence fusion with contextual discounting for multi-modality medical image segmentation
Jun 27, 2022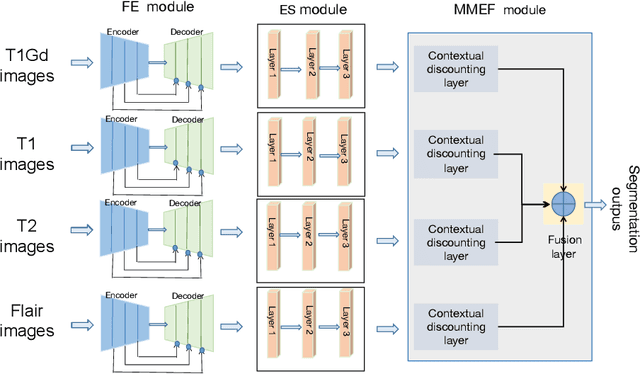
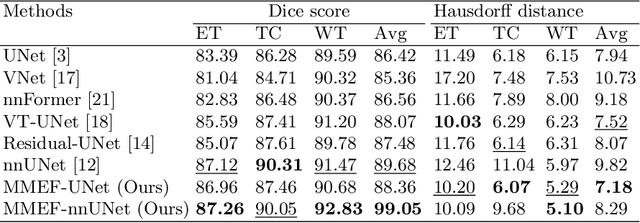
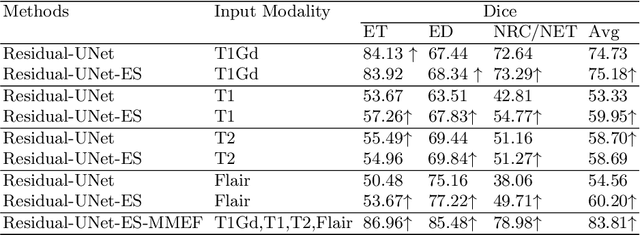
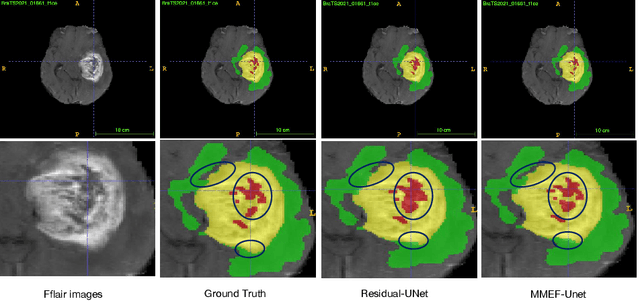
As information sources are usually imperfect, it is necessary to take into account their reliability in multi-source information fusion tasks. In this paper, we propose a new deep framework allowing us to merge multi-MR image segmentation results using the formalism of Dempster-Shafer theory while taking into account the reliability of different modalities relative to different classes. The framework is composed of an encoder-decoder feature extraction module, an evidential segmentation module that computes a belief function at each voxel for each modality, and a multi-modality evidence fusion module, which assigns a vector of discount rates to each modality evidence and combines the discounted evidence using Dempster's rule. The whole framework is trained by minimizing a new loss function based on a discounted Dice index to increase segmentation accuracy and reliability. The method was evaluated on the BraTs 2021 database of 1251 patients with brain tumors. Quantitative and qualitative results show that our method outperforms the state of the art, and implements an effective new idea for merging multi-information within deep neural networks.
A Fast Alternating Minimization Algorithm for Coded Aperture Snapshot Spectral Imaging Based on Sparsity and Deep Image Priors
Jun 12, 2022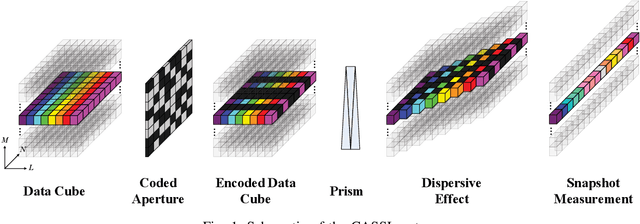
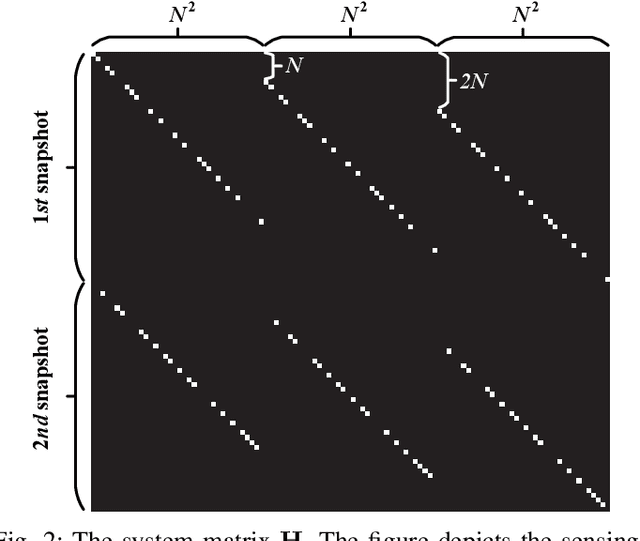
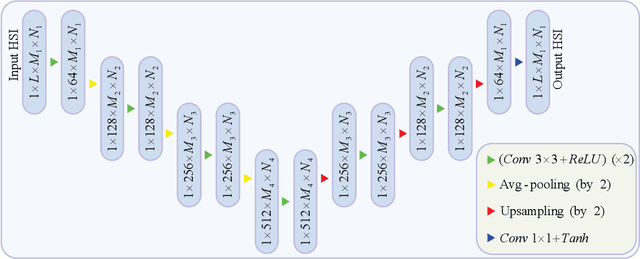

Coded aperture snapshot spectral imaging (CASSI) is a technique used to reconstruct three-dimensional hyperspectral images (HSIs) from one or several two-dimensional projection measurements. However, fewer projection measurements or more spectral channels leads to a severly ill-posed problem, in which case regularization methods have to be applied. In order to significantly improve the accuracy of reconstruction, this paper proposes a fast alternating minimization algorithm based on the sparsity and deep image priors (Fama-SDIP) of natural images. By integrating deep image prior (DIP) into the principle of compressive sensing (CS) reconstruction, the proposed algorithm can achieve state-of-the-art results without any training dataset. Extensive experiments show that Fama-SDIP method significantly outperforms prevailing leading methods on simulation and real HSI datasets.