 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Smart Recycling Bin Using Waste Image Classification At The Edge
Oct 02, 2022
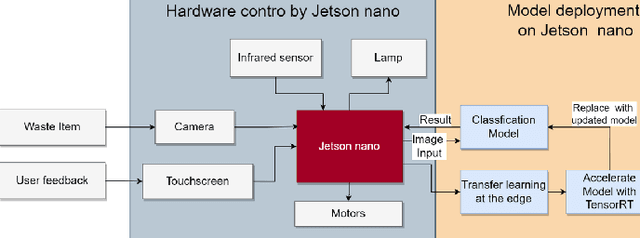
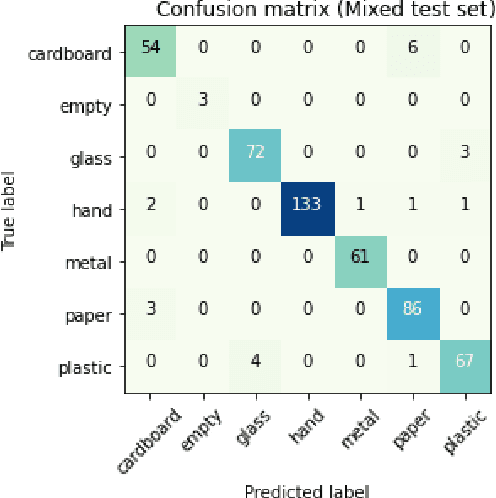
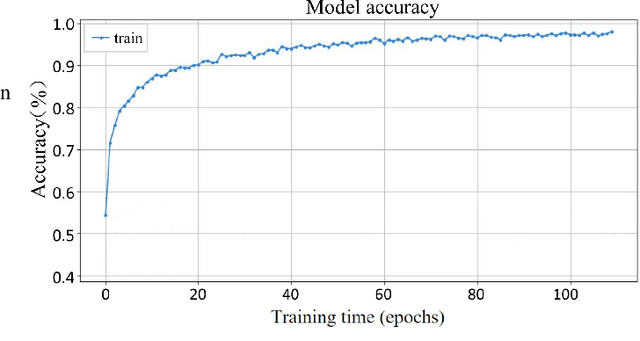
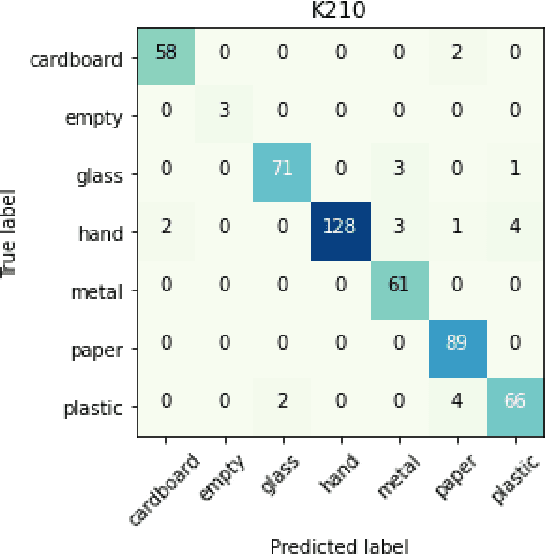
Rapid economic growth gives rise to the urgent demand for a more efficient waste recycling system. This work thereby developed an innovative recycling bin that automatically separates urban waste to increase the recycling rate. We collected 1800 recycling waste images and combined them with an existing public dataset to train classification models for two embedded systems, Jetson Nano and K210, targeting different markets. The model reached an accuracy of 95.98% on Jetson Nano and 96.64% on K210. A bin program was designed to collect feedback from users. On Jetson Nano, the overall power consumption of the application was reduced by 30% from the previous work to 4.7 W, while the second system, K210, only needed 0.89 W of power to operate. In summary, our work demonstrated a fully functional prototype of an energy-saving, high-accuracy smart recycling bin, which can be commercialized in the future to improve urban waste recycling.
UNeXt: MLP-based Rapid Medical Image Segmentation Network
Mar 09, 2022
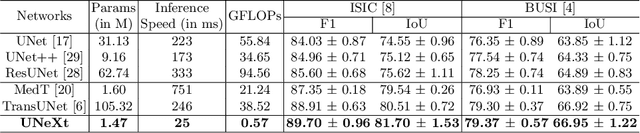
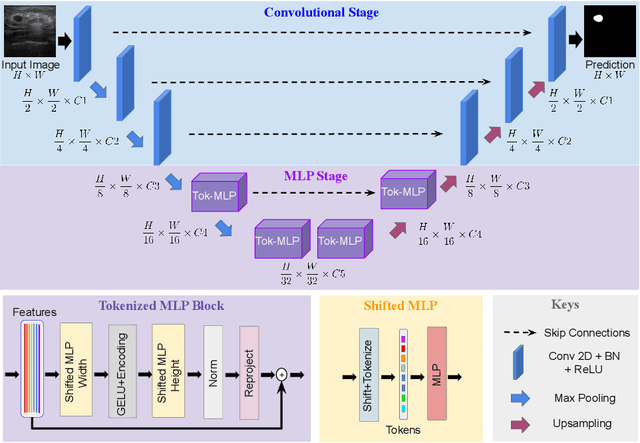
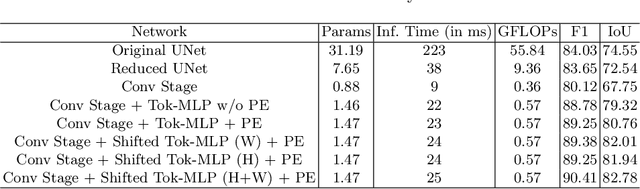
UNet and its latest extensions like TransUNet have been the leading medical image segmentation methods in recent years. However, these networks cannot be effectively adopted for rapid image segmentation in point-of-care applications as they are parameter-heavy, computationally complex and slow to use. To this end, we propose UNeXt which is a Convolutional multilayer perceptron (MLP) based network for image segmentation. We design UNeXt in an effective way with an early convolutional stage and a MLP stage in the latent stage. We propose a tokenized MLP block where we efficiently tokenize and project the convolutional features and use MLPs to model the representation. To further boost the performance, we propose shifting the channels of the inputs while feeding in to MLPs so as to focus on learning local dependencies. Using tokenized MLPs in latent space reduces the number of parameters and computational complexity while being able to result in a better representation to help segmentation. The network also consists of skip connections between various levels of encoder and decoder. We test UNeXt on multiple medical image segmentation datasets and show that we reduce the number of parameters by 72x, decrease the computational complexity by 68x, and improve the inference speed by 10x while also obtaining better segmentation performance over the state-of-the-art medical image segmentation architectures. Code is available at https://github.com/jeya-maria-jose/UNeXt-pytorch
CoNFies: Controllable Neural Face Avatars
Nov 16, 2022



Neural Radiance Fields (NeRF) are compelling techniques for modeling dynamic 3D scenes from 2D image collections. These volumetric representations would be well suited for synthesizing novel facial expressions but for two problems. First, deformable NeRFs are object agnostic and model holistic movement of the scene: they can replay how the motion changes over time, but they cannot alter it in an interpretable way. Second, controllable volumetric representations typically require either time-consuming manual annotations or 3D supervision to provide semantic meaning to the scene. We propose a controllable neural representation for face self-portraits (CoNFies), that solves both of these problems within a common framework, and it can rely on automated processing. We use automated facial action recognition (AFAR) to characterize facial expressions as a combination of action units (AU) and their intensities. AUs provide both the semantic locations and control labels for the system. CoNFies outperformed competing methods for novel view and expression synthesis in terms of visual and anatomic fidelity of expressions.
Boosting Object Representation Learning via Motion and Object Continuity
Nov 16, 2022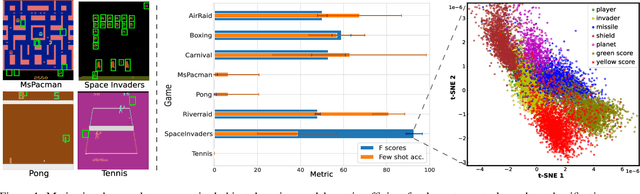
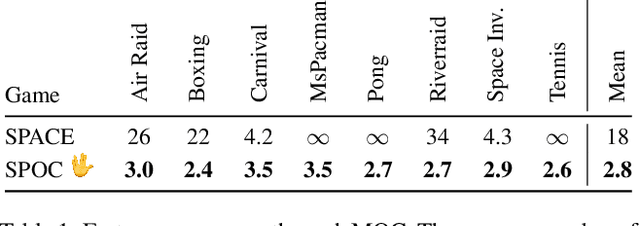
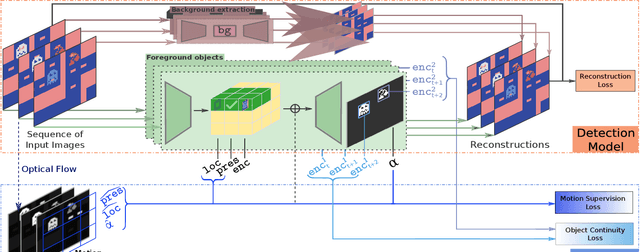
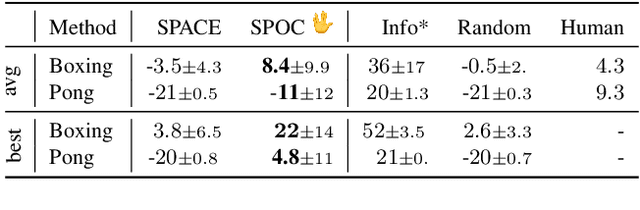
Recent unsupervised multi-object detection models have shown impressive performance improvements, largely attributed to novel architectural inductive biases. Unfortunately, they may produce suboptimal object encodings for downstream tasks. To overcome this, we propose to exploit object motion and continuity, i.e., objects do not pop in and out of existence. This is accomplished through two mechanisms: (i) providing priors on the location of objects through integration of optical flow, and (ii) a contrastive object continuity loss across consecutive image frames. Rather than developing an explicit deep architecture, the resulting Motion and Object Continuity (MOC) scheme can be instantiated using any baseline object detection model. Our results show large improvements in the performances of a SOTA model in terms of object discovery, convergence speed and overall latent object representations, particularly for playing Atari games. Overall, we show clear benefits of integrating motion and object continuity for downstream tasks, moving beyond object representation learning based only on reconstruction.
Improving Human Image Synthesis with Residual Fast Fourier Transformation and Wasserstein Distance
May 24, 2022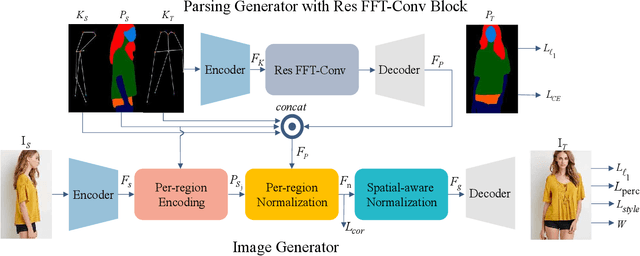
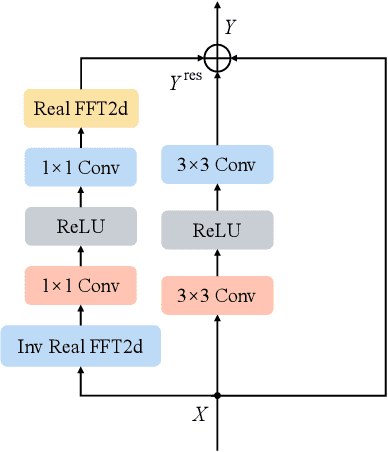
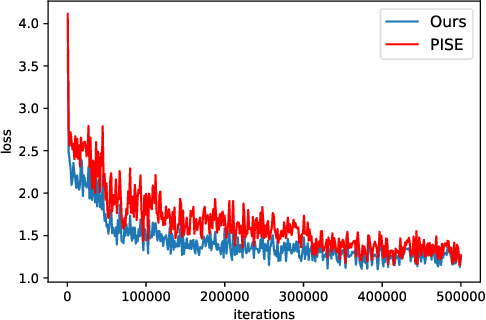
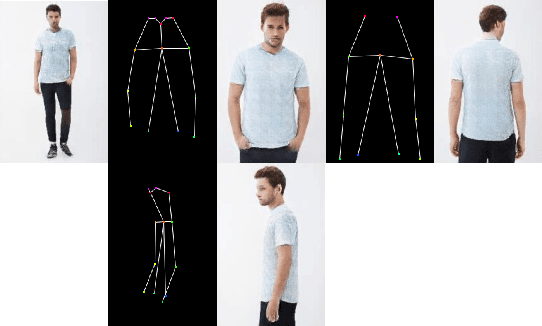
With the rapid development of the Metaverse, virtual humans have emerged, and human image synthesis and editing techniques, such as pose transfer, have recently become popular. Most of the existing techniques rely on GANs, which can generate good human images even with large variants and occlusions. But from our best knowledge, the existing state-of-the-art method still has the following problems: the first is that the rendering effect of the synthetic image is not realistic, such as poor rendering of some regions. And the second is that the training of GAN is unstable and slow to converge, such as model collapse. Based on the above two problems, we propose several methods to solve them. To improve the rendering effect, we use the Residual Fast Fourier Transform Block to replace the traditional Residual Block. Then, spectral normalization and Wasserstein distance are used to improve the speed and stability of GAN training. Experiments demonstrate that the methods we offer are effective at solving the problems listed above, and we get state-of-the-art scores in LPIPS and PSNR.
Robust Medical Image Classification from Noisy Labeled Data with Global and Local Representation Guided Co-training
May 10, 2022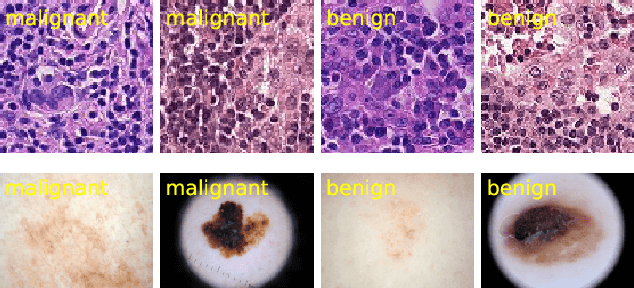
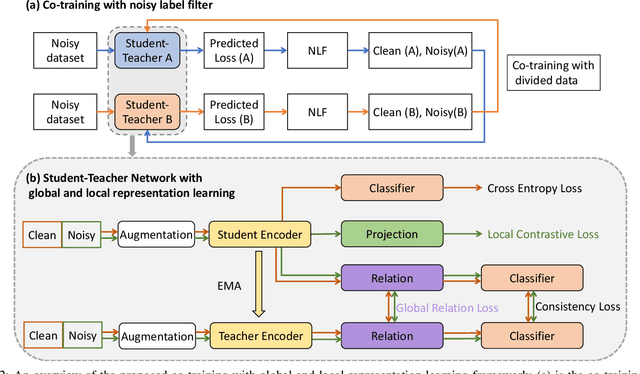
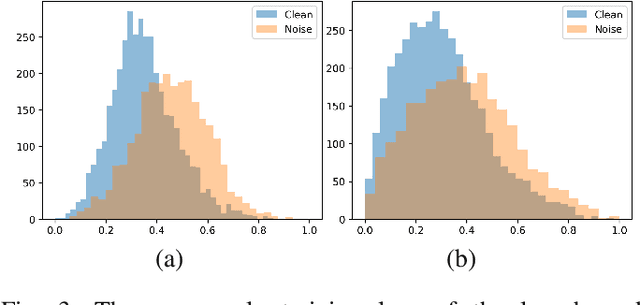
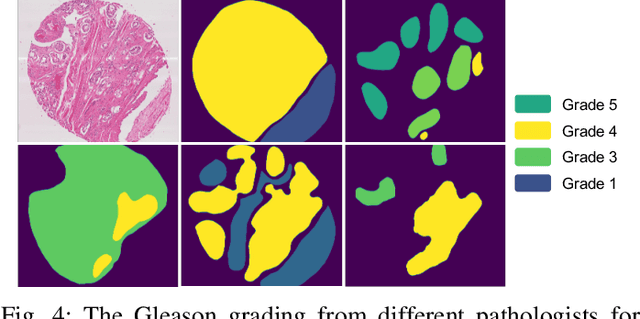
Deep neural networks have achieved remarkable success in a wide variety of natural image and medical image computing tasks. However, these achievements indispensably rely on accurately annotated training data. If encountering some noisy-labeled images, the network training procedure would suffer from difficulties, leading to a sub-optimal classifier. This problem is even more severe in the medical image analysis field, as the annotation quality of medical images heavily relies on the expertise and experience of annotators. In this paper, we propose a novel collaborative training paradigm with global and local representation learning for robust medical image classification from noisy-labeled data to combat the lack of high quality annotated medical data. Specifically, we employ the self-ensemble model with a noisy label filter to efficiently select the clean and noisy samples. Then, the clean samples are trained by a collaborative training strategy to eliminate the disturbance from imperfect labeled samples. Notably, we further design a novel global and local representation learning scheme to implicitly regularize the networks to utilize noisy samples in a self-supervised manner. We evaluated our proposed robust learning strategy on four public medical image classification datasets with three types of label noise,ie,random noise, computer-generated label noise, and inter-observer variability noise. Our method outperforms other learning from noisy label methods and we also conducted extensive experiments to analyze each component of our method.
Multi-Objective Evolutionary for Object Detection Mobile Architectures Search
Nov 05, 2022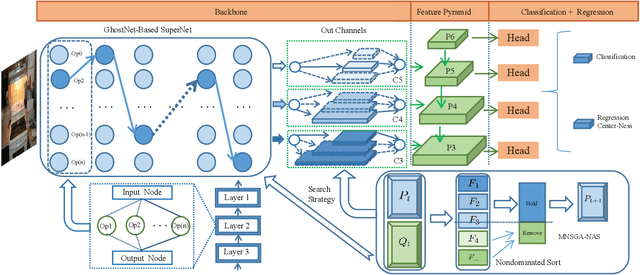
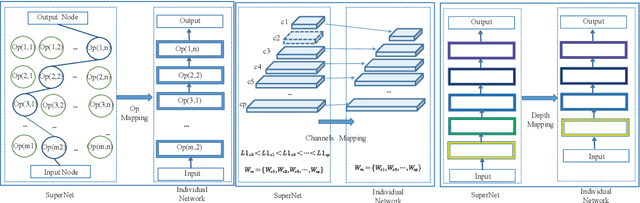
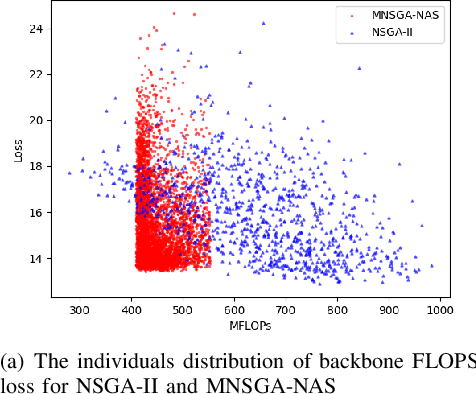

Recently, Neural architecture search has achieved great success on classification tasks for mobile devices. The backbone network for object detection is usually obtained on the image classification task. However, the architecture which is searched through the classification task is sub-optimal because of the gap between the task of image and object detection. As while work focuses on backbone network architecture search for mobile device object detection is limited, mainly because the backbone always requires expensive ImageNet pre-training. Accordingly, it is necessary to study the approach of network architecture search for mobile device object detection without expensive pre-training. In this work, we propose a mobile object detection backbone network architecture search algorithm which is a kind of evolutionary optimized method based on non-dominated sorting for NAS scenarios. It can quickly search to obtain the backbone network architecture within certain constraints. It better solves the problem of suboptimal linear combination accuracy and computational cost. The proposed approach can search the backbone networks with different depths, widths, or expansion sizes via a technique of weight mapping, making it possible to use NAS for mobile devices detection tasks a lot more efficiently. In our experiments, we verify the effectiveness of the proposed approach on YoloX-Lite, a lightweight version of the target detection framework. Under similar computational complexity, the accuracy of the backbone network architecture we search for is 2.0% mAP higher than MobileDet. Our improved backbone network can reduce the computational effort while improving the accuracy of the object detection network. To prove its effectiveness, a series of ablation studies have been carried out and the working mechanism has been analyzed in detail.
MultiStyleGAN: Multiple One-shot Face Stylizations using a Single GAN
Oct 08, 2022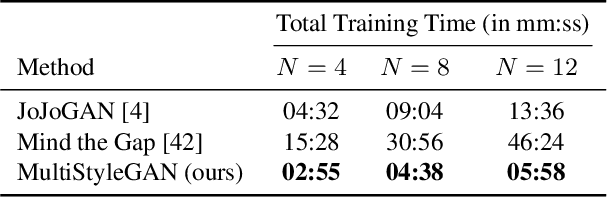
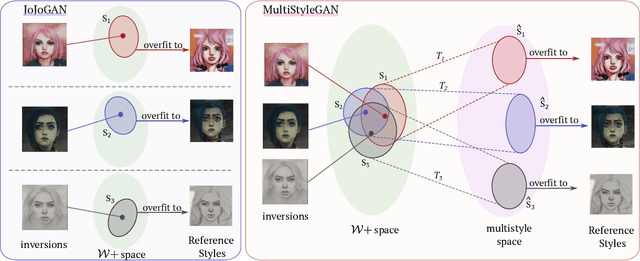
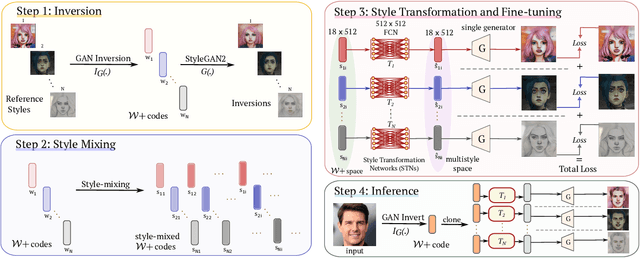

Image stylization aims at applying a reference style to arbitrary input images. A common scenario is one-shot stylization, where only one example is available for each reference style. A successful recent approach for one-shot face stylization is JoJoGAN, which fine-tunes a pre-trained StyleGAN2 generator on a single style reference image. However, it cannot generate multiple stylizations without fine-tuning a new model for each style separately. In this work, we present a MultiStyleGAN method that is capable of producing multiple different face stylizations at once by fine-tuning a single generator. The key component of our method is a learnable Style Transformation module that takes latent codes as input and learns linear mappings to different regions of the latent space to produce distinct codes for each style, resulting in a multistyle space. Our model inherently mitigates overfitting since it is trained on multiple styles, hence improving the quality of stylizations. Our method can learn upwards of $12$ image stylizations at once, bringing upto $8\times$ improvement in training time. We support our results through user studies that indicate meaningful improvements over existing methods.
Seeing the Unseen: Errors and Bias in Visual Datasets
Nov 03, 2022

From face recognition in smartphones to automatic routing on self-driving cars, machine vision algorithms lie in the core of these features. These systems solve image based tasks by identifying and understanding objects, subsequently making decisions from these information. However, errors in datasets are usually induced or even magnified in algorithms, at times resulting in issues such as recognising black people as gorillas and misrepresenting ethnicities in search results. This paper tracks the errors in datasets and their impacts, revealing that a flawed dataset could be a result of limited categories, incomprehensive sourcing and poor classification.
Sports Camera Pose Refinement Using an Evolution Strategy
Nov 03, 2022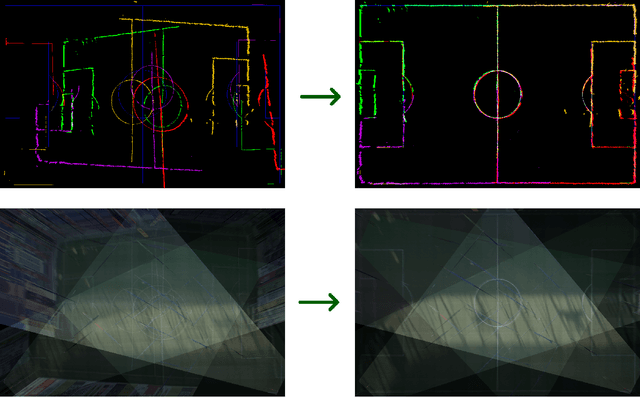
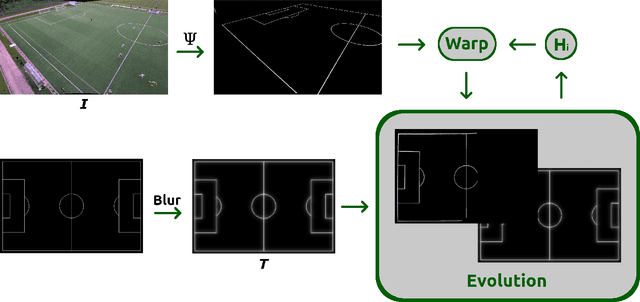
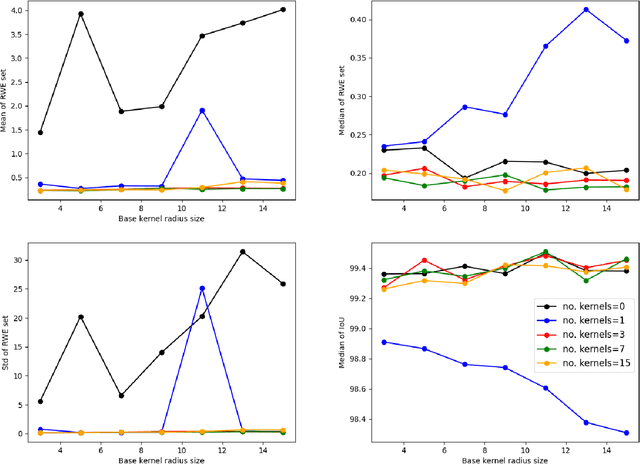
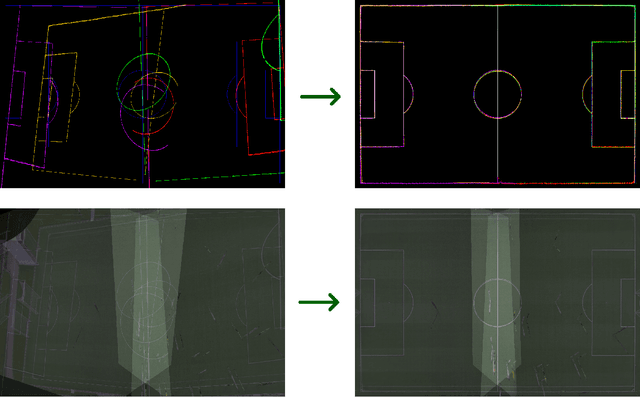
This paper presents a robust end-to-end method for sports cameras extrinsic parameters optimization using a novel evolution strategy. First, we developed a neural network architecture for an edge or area-based segmentation of a sports field. Secondly, we implemented the evolution strategy, which purpose is to refine extrinsic camera parameters given a single, segmented sports field image. Experimental comparison with state-of-the-art camera pose refinement methods on real-world data demonstrates the superiority of the proposed algorithm. We also perform an ablation study and propose a way to generalize the method to additionally refine the intrinsic camera matrix.