 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HiVLP: Hierarchical Vision-Language Pre-Training for Fast Image-Text Retrieval
May 24, 2022

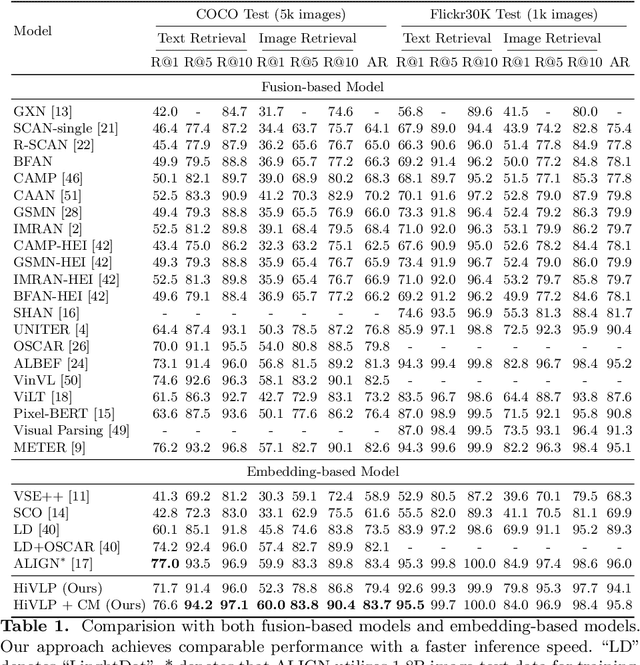
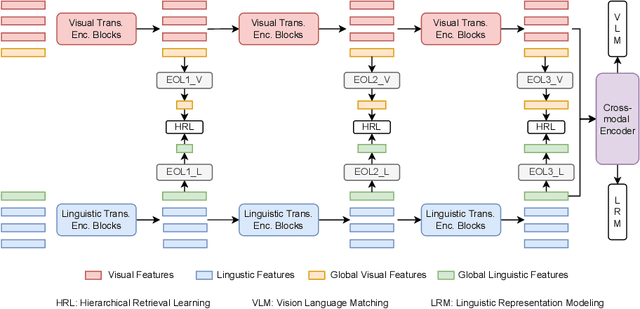
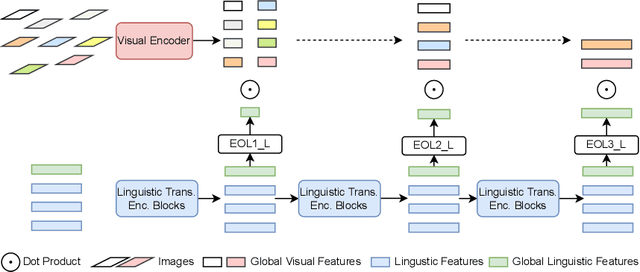
In the past few years, the emergence of vision-language pre-training (VLP) has brought cross-modal retrieval to a new era. However, due to the latency and computation demand, it is commonly challenging to apply VLP in a real-time online retrieval system. To alleviate the defect, this paper proposes a \textbf{Hi}erarchical \textbf{V}ision-\textbf{}Language \textbf{P}re-Training (\textbf{HiVLP}) for fast Image-Text Retrieval (ITR). Specifically, we design a novel hierarchical retrieval objective, which uses the representation of different dimensions for coarse-to-fine ITR, i.e., using low-dimensional representation for large-scale coarse retrieval and high-dimensional representation for small-scale fine retrieval. We evaluate our proposed HiVLP on two popular image-text retrieval benchmarks, i.e., Flickr30k and COCO. Extensive experiments demonstrate that our HiVLP not only has fast inference speed but also can be easily scaled to large-scale ITR scenarios. The detailed results show that HiVLP is $1,427$$\sim$$120,649\times$ faster than the fusion-based model UNITER and 2$\sim$5 faster than the fastest embedding-based model LightingDot in different candidate scenarios. It also achieves about +4.9 AR on COCO and +3.8 AR on Flickr30K than LightingDot and achieves comparable performance with the state-of-the-art (SOTA) fusion-based model METER.
A Fast Alternating Minimization Algorithm for Coded Aperture Snapshot Spectral Imaging Based on Sparsity and Deep Image Priors
Jun 12, 2022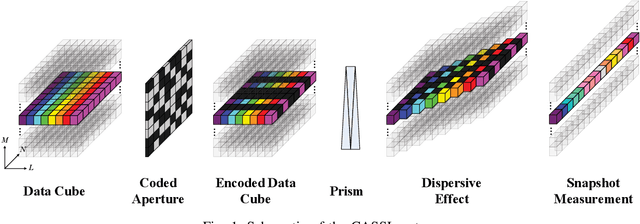
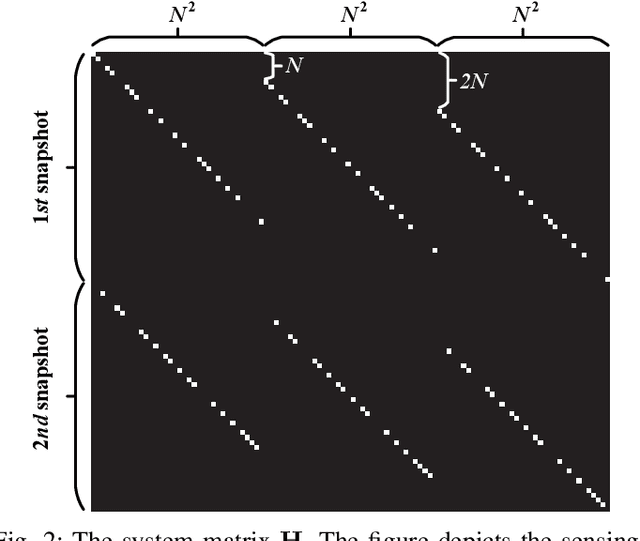
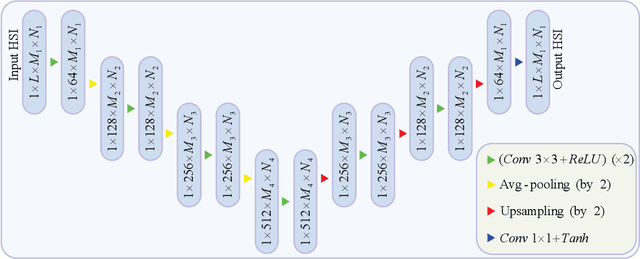

Coded aperture snapshot spectral imaging (CASSI) is a technique used to reconstruct three-dimensional hyperspectral images (HSIs) from one or several two-dimensional projection measurements. However, fewer projection measurements or more spectral channels leads to a severly ill-posed problem, in which case regularization methods have to be applied. In order to significantly improve the accuracy of reconstruction, this paper proposes a fast alternating minimization algorithm based on the sparsity and deep image priors (Fama-SDIP) of natural images. By integrating deep image prior (DIP) into the principle of compressive sensing (CS) reconstruction, the proposed algorithm can achieve state-of-the-art results without any training dataset. Extensive experiments show that Fama-SDIP method significantly outperforms prevailing leading methods on simulation and real HSI datasets.
Image Search with Text Feedback by Additive Attention Compositional Learning
Mar 08, 2022
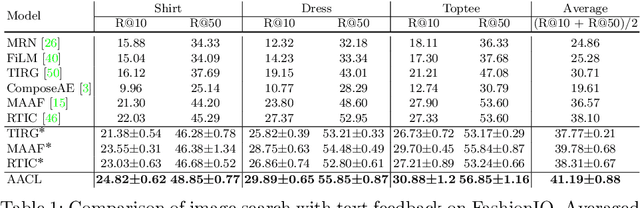
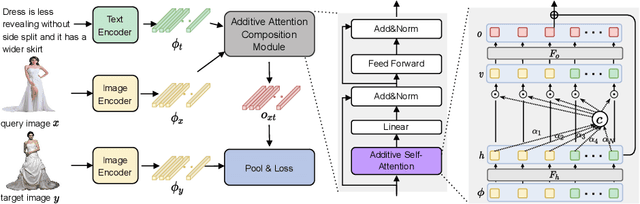
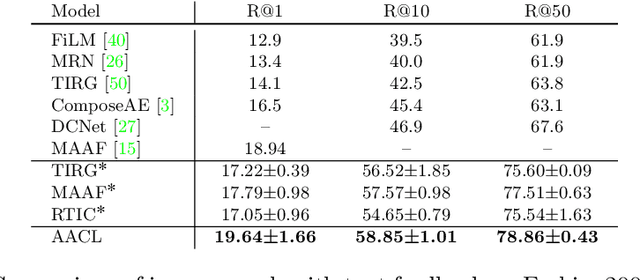
Effective image retrieval with text feedback stands to impact a range of real-world applications, such as e-commerce. Given a source image and text feedback that describes the desired modifications to that image, the goal is to retrieve the target images that resemble the source yet satisfy the given modifications by composing a multi-modal (image-text) query. We propose a novel solution to this problem, Additive Attention Compositional Learning (AACL), that uses a multi-modal transformer-based architecture and effectively models the image-text contexts. Specifically, we propose a novel image-text composition module based on additive attention that can be seamlessly plugged into deep neural networks. We also introduce a new challenging benchmark derived from the Shopping100k dataset. AACL is evaluated on three large-scale datasets (FashionIQ, Fashion200k, and Shopping100k), each with strong baselines. Extensive experiments show that AACL achieves new state-of-the-art results on all three datasets.
Image Style Transfer: from Artistic to Photorealistic
Mar 12, 2022


The rapid advancement of deep learning has significantly boomed the development of photorealistic style transfer. In this review, we reviewed the development of photorealistic style transfer starting from artistic style transfer and the contribution of traditional image processing techniques on photorealistic style transfer, including some work that had been completed in the Multimedia lab at the University of Alberta. Many techniques were discussed in this review. However, our focus is on VGG-based techniques, whitening and coloring transform (WCTs) based techniques, the combination of deep learning with traditional image processing techniques.
U-Net and its variants for Medical Image Segmentation : A short review
Apr 17, 2022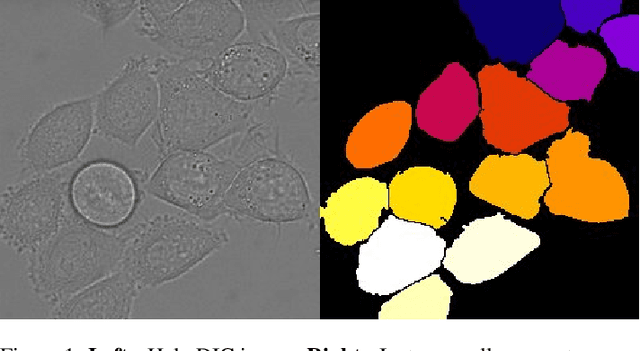
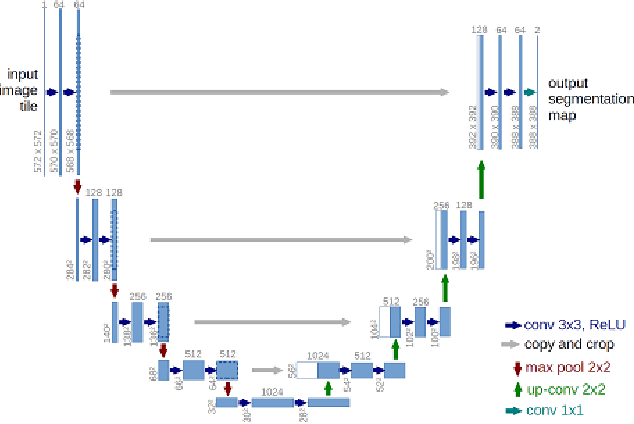
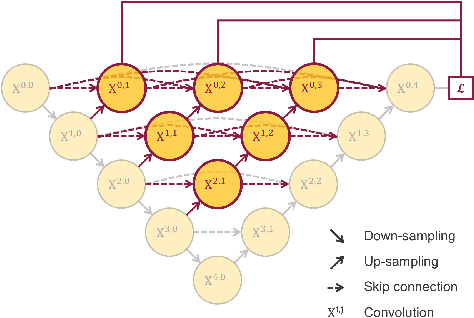
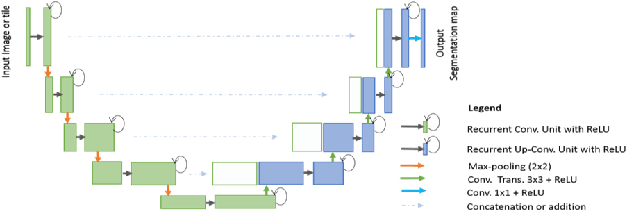
The paper is a short review of medical image segmentation using U-Net and its variants. As we understand going through a medical images is not an easy job for any clinician either radiologist or pathologist. Analysing medical images is the only way to perform non-invasive diagnosis. Segmenting out the regions of interest has significant importance in medical images and is key for diagnosis. This paper also gives a bird eye view of how medical image segmentation has evolved. Also discusses challenge's and success of the deep neural architectures. Following how different hybrid architectures have built upon strong techniques from visual recognition tasks. In the end we will see current challenges and future directions for medical image segmentation(MIS).
Diffusion Model Based Posterior Sampling for Noisy Linear Inverse Problems
Nov 20, 2022

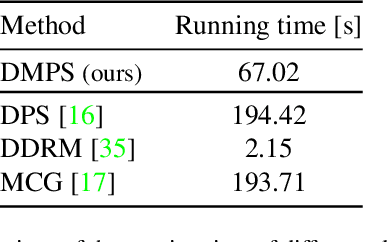

We consider the ubiquitous linear inverse problems with additive Gaussian noise and propose an unsupervised general-purpose sampling approach called diffusion model based posterior sampling (DMPS) to reconstruct the unknown signal from noisy linear measurements. Specifically, the prior of the unknown signal is implicitly modeled by one pre-trained diffusion model (DM). In posterior sampling, to address the intractability of exact noise-perturbed likelihood score, a simple yet effective noise-perturbed pseudo-likelihood score is introduced under the uninformative prior assumption. While DMPS applies to any kind of DM with proper modifications, we focus on the ablated diffusion model (ADM) as one specific example and evaluate its efficacy on a variety of linear inverse problems such as image super-resolution, denoising, deblurring, colorization. Experimental results demonstrate that, for both in-distribution and out-of-distribution samples, DMPS achieves highly competitive or even better performances on various tasks while being 3 times faster than the leading competitor. The code to reproduce the results is available at https://github.com/mengxiangming/dmps.
Patch-level Gaze Distribution Prediction for Gaze Following
Nov 20, 2022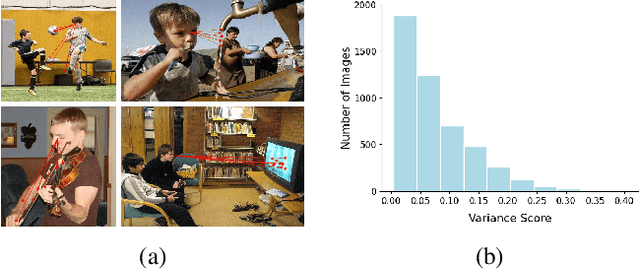
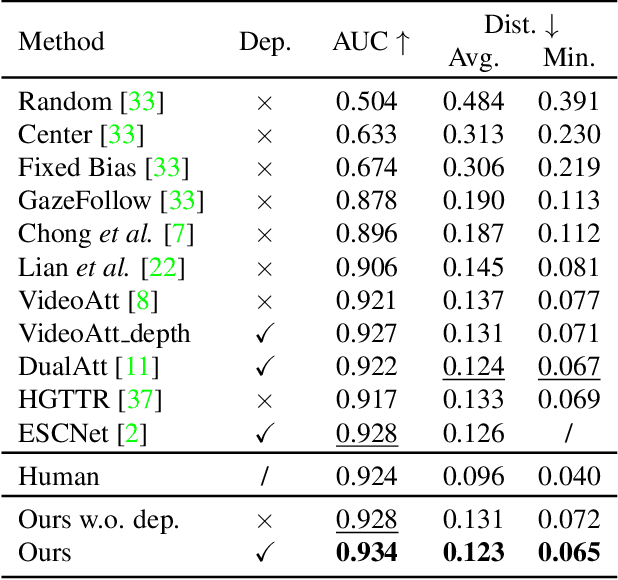
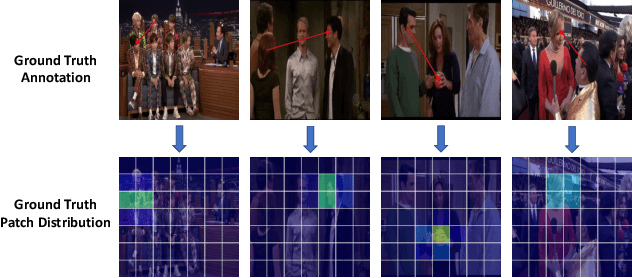
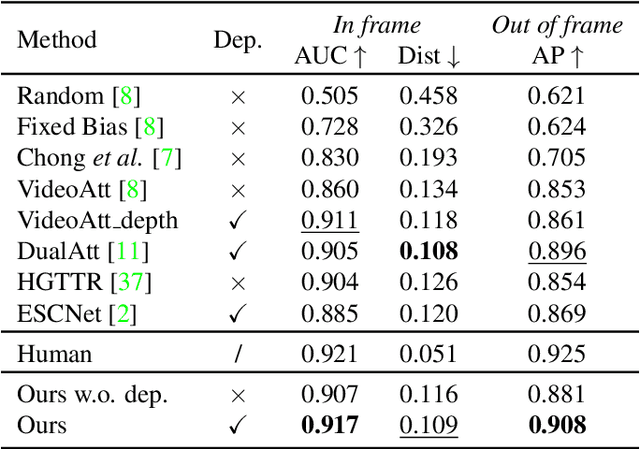
Gaze following aims to predict where a person is looking in a scene, by predicting the target location, or indicating that the target is located outside the image. Recent works detect the gaze target by training a heatmap regression task with a pixel-wise mean-square error (MSE) loss, while formulating the in/out prediction task as a binary classification task. This training formulation puts a strict, pixel-level constraint in higher resolution on the single annotation available in training, and does not consider annotation variance and the correlation between the two subtasks. To address these issues, we introduce the patch distribution prediction (PDP) method. We replace the in/out prediction branch in previous models with the PDP branch, by predicting a patch-level gaze distribution that also considers the outside cases. Experiments show that our model regularizes the MSE loss by predicting better heatmap distributions on images with larger annotation variances, meanwhile bridging the gap between the target prediction and in/out prediction subtasks, showing a significant improvement in performance on both subtasks on public gaze following datasets.
Unsupervised Image Fusion Using Deep Image Priors
Oct 18, 2021
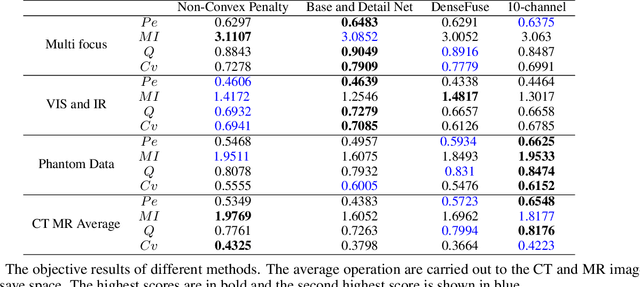
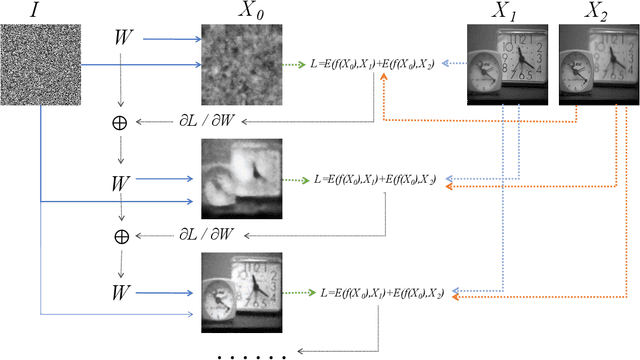
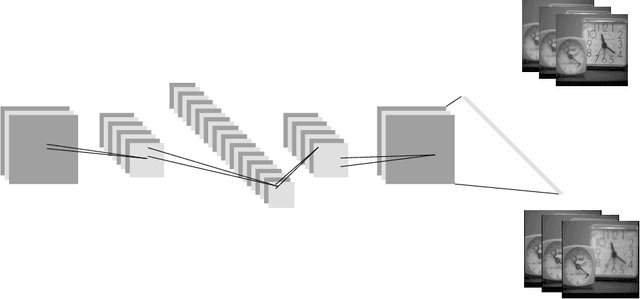
A significant number of researchers have recently applied deep learning methods to image fusion. However, most of these works either require a large amount of training data or depend on pre-trained models or frameworks. This inevitably encounters a shortage of training data or a mismatch between the framework and the actual problem. Recently, the publication of Deep Image Prior (DIP) method made it possible to do image restoration totally training-data-free. However, the original design of DIP is hard to be generalized to multi-image processing problems. This paper introduces a novel loss calculation structure, in the framework of DIP, while formulating image fusion as an inverse problem. This enables the extension of DIP to general multisensor/multifocus image fusion problems. Secondly, we propose a multi-channel approach to improve the effect of DIP. Finally, an evaluation is conducted using several commonly used image fusion assessment metrics. The results are compared with state-of-the-art traditional and deep learning image fusion methods. Our method outperforms previous techniques for a range of metrics. In particular, it is shown to provide the best objective results for most metrics when applied to medical images.
SISL:Self-Supervised Image Signature Learning for Splicing Detection and Localization
Mar 15, 2022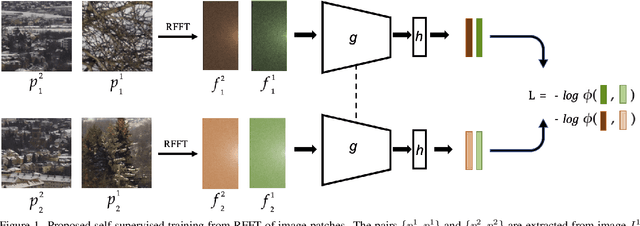
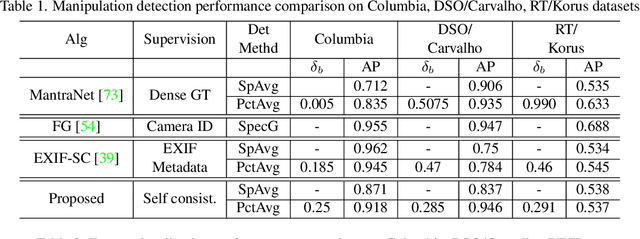
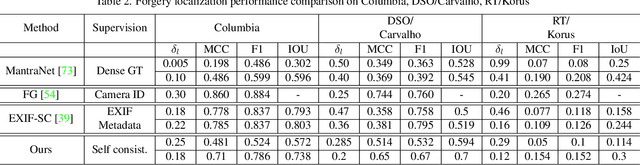

Recent algorithms for image manipulation detection almost exclusively use deep network models. These approaches require either dense pixelwise groundtruth masks, camera ids, or image metadata to train the networks. On one hand, constructing a training set to represent the countless tampering possibilities is impractical. On the other hand, social media platforms or commercial applications are often constrained to remove camera ids as well as metadata from images. A self-supervised algorithm for training manipulation detection models without dense groundtruth or camera/image metadata would be extremely useful for many forensics applications. In this paper, we propose self-supervised approach for training splicing detection/localization models from frequency transforms of images. To identify the spliced regions, our deep network learns a representation to capture an image specific signature by enforcing (image) self consistency . We experimentally demonstrate that our proposed model can yield similar or better performances of multiple existing methods on standard datasets without relying on labels or metadata.
Object Class Aware Video Anomaly Detection through Image Translation
May 03, 2022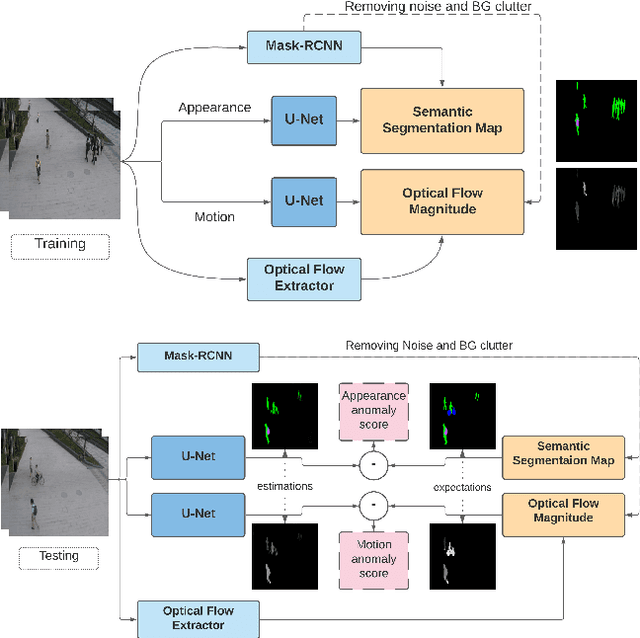
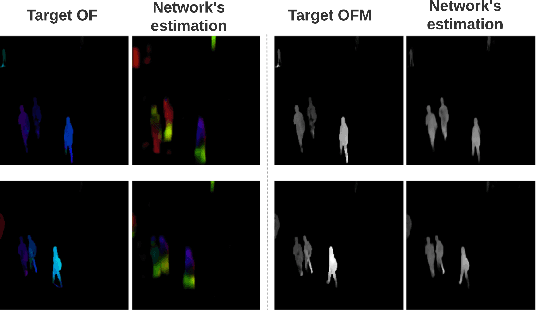
Semi-supervised video anomaly detection (VAD) methods formulate the task of anomaly detection as detection of deviations from the learned normal patterns. Previous works in the field (reconstruction or prediction-based methods) suffer from two drawbacks: 1) They focus on low-level features, and they (especially holistic approaches) do not effectively consider the object classes. 2) Object-centric approaches neglect some of the context information (such as location). To tackle these challenges, this paper proposes a novel two-stream object-aware VAD method that learns the normal appearance and motion patterns through image translation tasks. The appearance branch translates the input image to the target semantic segmentation map produced by Mask-RCNN, and the motion branch associates each frame with its expected optical flow magnitude. Any deviation from the expected appearance or motion in the inference stage shows the degree of potential abnormality. We evaluated our proposed method on the ShanghaiTech, UCSD-Ped1, and UCSD-Ped2 datasets and the results show competitive performance compared with state-of-the-art works. Most importantly, the results show that, as significant improvements to previous methods, detections by our method are completely explainable and anomalies are localized accurately in the frames.