 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Geo-Localization via Ground-to-Satellite Cross-View Image Retrieval
May 22, 2022
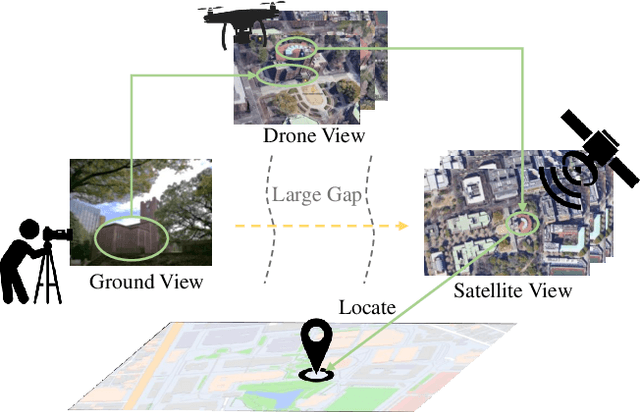
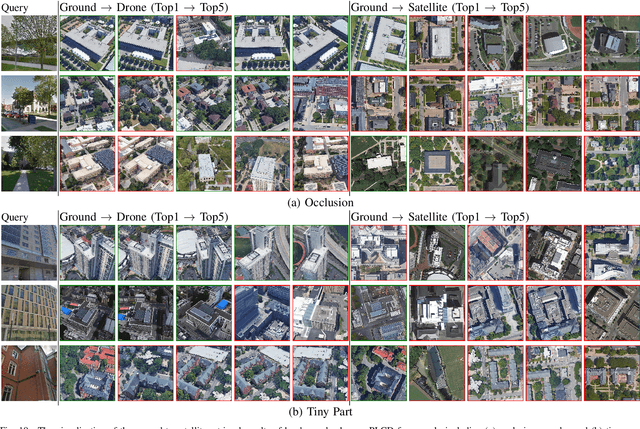
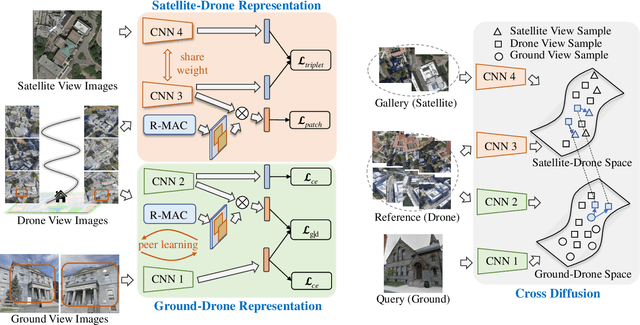
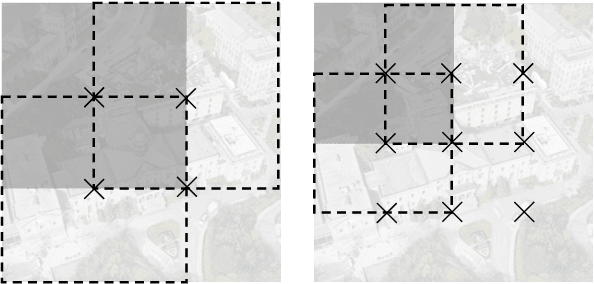
The large variation of viewpoint and irrelevant content around the target always hinder accurate image retrieval and its subsequent tasks. In this paper, we investigate an extremely challenging task: given a ground-view image of a landmark, we aim to achieve cross-view geo-localization by searching out its corresponding satellite-view images. Specifically, the challenge comes from the gap between ground-view and satellite-view, which includes not only large viewpoint changes (some parts of the landmark may be invisible from front view to top view) but also highly irrelevant background (the target landmark tend to be hidden in other surrounding buildings), making it difficult to learn a common representation or a suitable mapping. To address this issue, we take advantage of drone-view information as a bridge between ground-view and satellite-view domains. We propose a Peer Learning and Cross Diffusion (PLCD) framework. PLCD consists of three parts: 1) a peer learning across ground-view and drone-view to find visible parts to benefit ground-drone cross-view representation learning; 2) a patch-based network for satellite-drone cross-view representation learning; 3) a cross diffusion between ground-drone space and satellite-drone space. Extensive experiments conducted on the University-Earth and University-Google datasets show that our method outperforms state-of-the-arts significantly.
* 13 pages, 10 figures
Contextualize differential privacy in image database: a lightweight image differential privacy approach based on principle component analysis inverse
Feb 16, 2022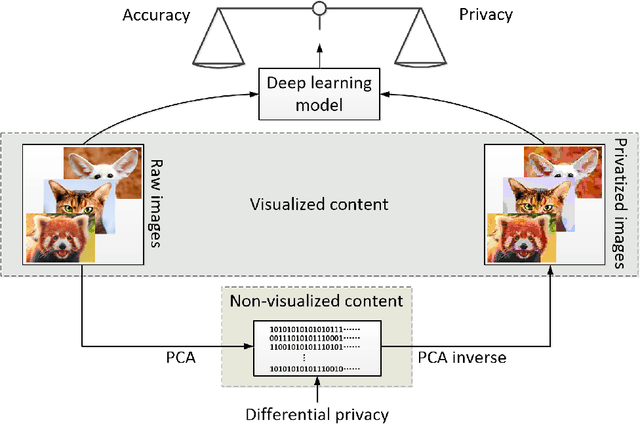


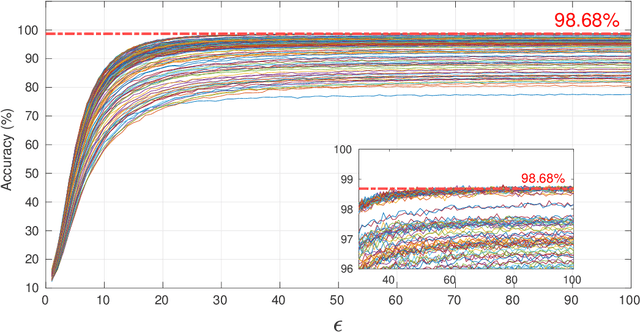
Differential privacy (DP) has been the de-facto standard to preserve privacy-sensitive information in database. Nevertheless, there lacks a clear and convincing contextualization of DP in image database, where individual images' indistinguishable contribution to a certain analysis can be achieved and observed when DP is exerted. As a result, the privacy-accuracy trade-off due to integrating DP is insufficiently demonstrated in the context of differentially-private image database. This work aims at contextualizing DP in image database by an explicit and intuitive demonstration of integrating conceptional differential privacy with images. To this end, we design a lightweight approach dedicating to privatizing image database as a whole and preserving the statistical semantics of the image database to an adjustable level, while making individual images' contribution to such statistics indistinguishable. The designed approach leverages principle component analysis (PCA) to reduce the raw image with large amount of attributes to a lower dimensional space whereby DP is performed, so as to decrease the DP load of calculating sensitivity attribute-by-attribute. The DP-exerted image data, which is not visible in its privatized format, is visualized through PCA inverse such that both a human and machine inspector can evaluate the privatization and quantify the privacy-accuracy trade-off in an analysis on the privatized image database. Using the devised approach, we demonstrate the contextualization of DP in images by two use cases based on deep learning models, where we show the indistinguishability of individual images induced by DP and the privatized images' retention of statistical semantics in deep learning tasks, which is elaborated by quantitative analyses on the privacy-accuracy trade-off under different privatization settings.
RUST: Latent Neural Scene Representations from Unposed Imagery
Nov 25, 2022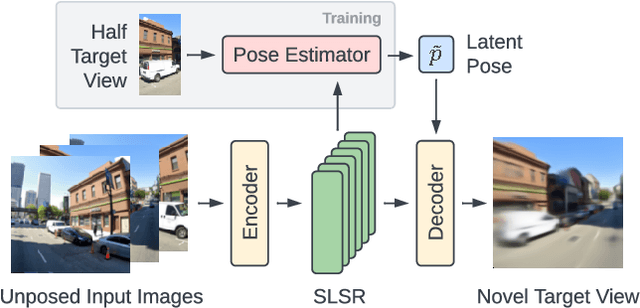
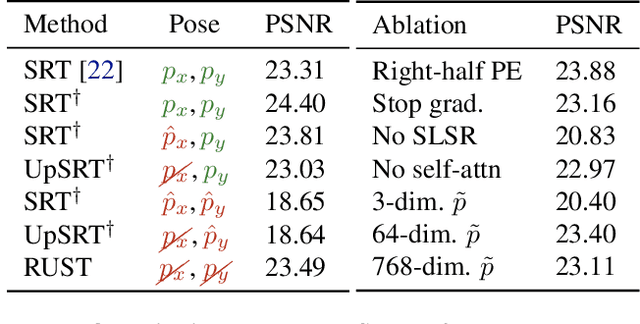
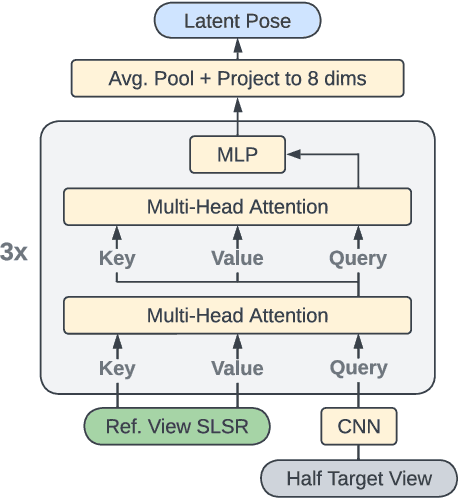
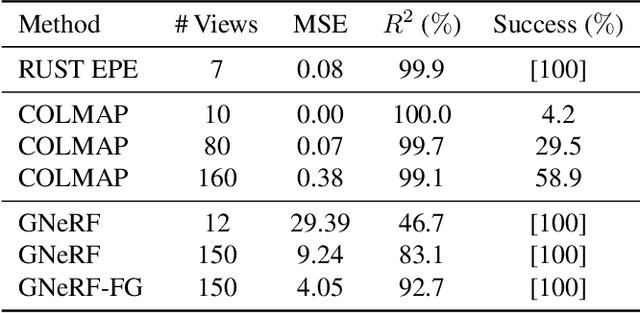
Inferring the structure of 3D scenes from 2D observations is a fundamental challenge in computer vision. Recently popularized approaches based on neural scene representations have achieved tremendous impact and have been applied across a variety of applications. One of the major remaining challenges in this space is training a single model which can provide latent representations which effectively generalize beyond a single scene. Scene Representation Transformer (SRT) has shown promise in this direction, but scaling it to a larger set of diverse scenes is challenging and necessitates accurately posed ground truth data. To address this problem, we propose RUST (Really Unposed Scene representation Transformer), a pose-free approach to novel view synthesis trained on RGB images alone. Our main insight is that one can train a Pose Encoder that peeks at the target image and learns a latent pose embedding which is used by the decoder for view synthesis. We perform an empirical investigation into the learned latent pose structure and show that it allows meaningful test-time camera transformations and accurate explicit pose readouts. Perhaps surprisingly, RUST achieves similar quality as methods which have access to perfect camera pose, thereby unlocking the potential for large-scale training of amortized neural scene representations.
Data-Consistent Non-Cartesian Deep Subspace Learning for Efficient Dynamic MR Image Reconstruction
May 03, 2022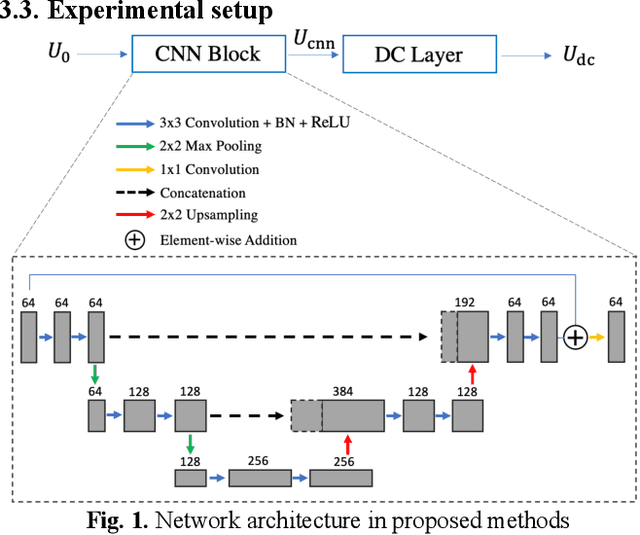
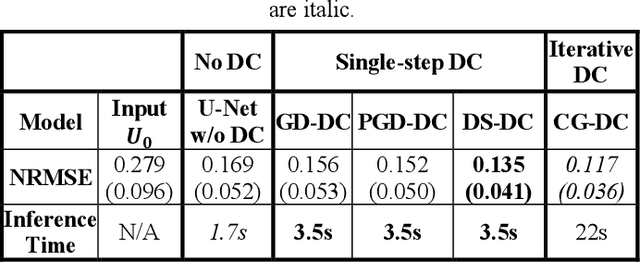
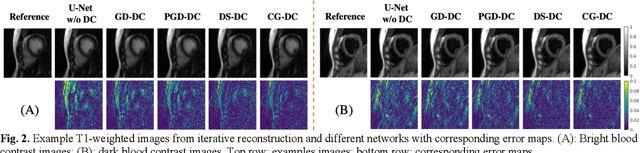
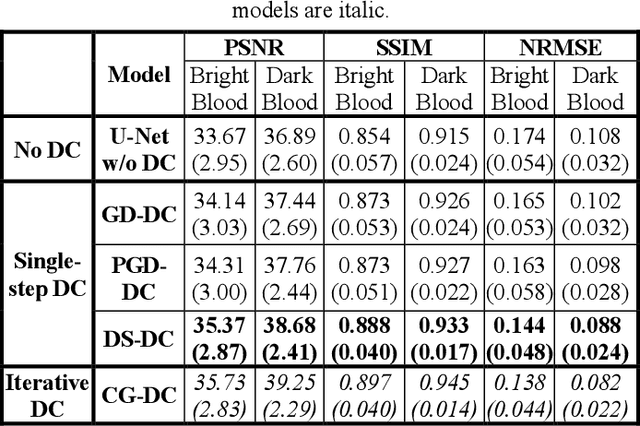
Non-Cartesian sampling with subspace-constrained image reconstruction is a popular approach to dynamic MRI, but slow iterative reconstruction limits its clinical application. Data-consistent (DC) deep learning can accelerate reconstruction with good image quality, but has not been formulated for non-Cartesian subspace imaging. In this study, we propose a DC non-Cartesian deep subspace learning framework for fast, accurate dynamic MR image reconstruction. Four novel DC formulations are developed and evaluated: two gradient decent approaches, a directly solved approach, and a conjugate gradient approach. We applied a U-Net model with and without DC layers to reconstruct T1-weighted images for cardiac MR Multitasking (an advanced multidimensional imaging method), comparing our results to the iteratively reconstructed reference. Experimental results show that the proposed framework significantly improves reconstruction accuracy over the U-Net model without DC, while significantly accelerating the reconstruction over conventional iterative reconstruction.
Semi-Supervised Representative Region Texture Extraction of Façade
Dec 05, 2022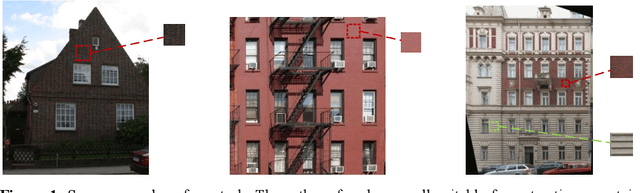

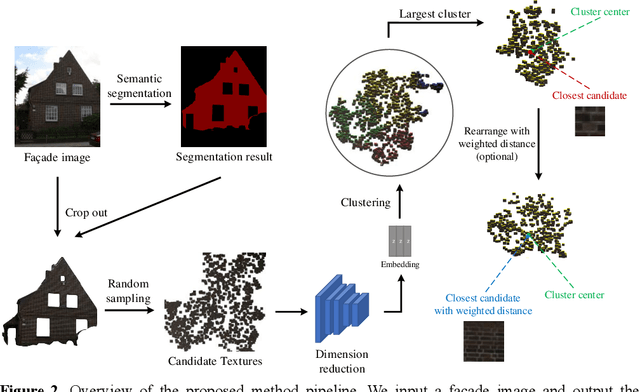

Researches of analysis and parsing around fa\c{c}ades to enrich the 3D feature of fa\c{c}ade models by semantic information raised some attention in the community, whose main idea is to generate higher resolution components with similar shapes and textures to increase the overall resolution at the expense of reconstruction accuracy. While this approach works well for components like windows and doors, there is no solution for fa\c{c}ade background at present. In this paper, we introduce the concept of representative region texture, which can be used in the above modeling approach by tiling the representative texture around the fa\c{c}ade region, and propose a semi-supervised way to do representative region texture extraction from a fa\c{c}ade image. Our method does not require any additional labelled data to train as long as the semantic information is given, while a traditional end-to-end model requires plenty of data to increase its performance. Our method can extract texture from any repetitive images, not just fa\c{c}ade, which is not capable in an end-to-end model as it relies on the distribution of training set. Clustering with weighted distance is introduced to further increase the robustness to noise or an imprecise segmentation, and make the extracted texture have a higher resolution and more suitable for tiling. We verify our method on various fa\c{c}ade images, and the result shows our method has a significant performance improvement compared to only a random crop on fa\c{c}ade. We also demonstrate some application scenarios and proposed a fa\c{c}ade modeling workflow with the representative region texture, which has a better visual resolution for a regular fa\c{c}ade.
Improving the Robustness of Neural Multiplication Units with Reversible Stochasticity
Nov 10, 2022
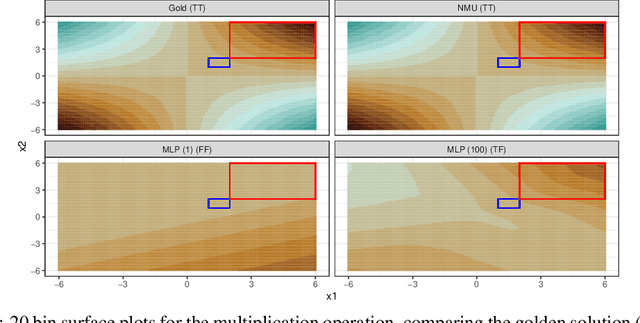

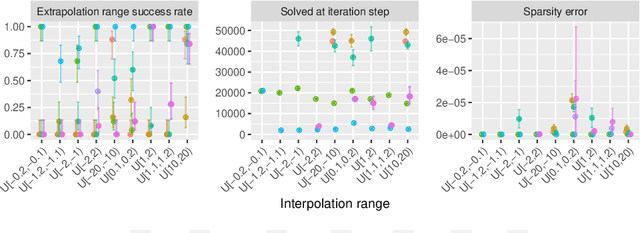
Multilayer Perceptrons struggle to learn certain simple arithmetic tasks. Specialist neural modules for arithmetic can outperform classical architectures with gains in extrapolation, interpretability and convergence speeds, but are highly sensitive to the training range. In this paper, we show that Neural Multiplication Units (NMUs) are unable to reliably learn tasks as simple as multiplying two inputs when given different training ranges. Causes of failure are linked to inductive and input biases which encourage convergence to solutions in undesirable optima. A solution, the stochastic NMU (sNMU), is proposed to apply reversible stochasticity, encouraging avoidance of such optima whilst converging to the true solution. Empirically, we show that stochasticity provides improved robustness with the potential to improve learned representations of upstream networks for numerical and image tasks.
EigenFairing: 3D Model Fairing using Image Coherence
Jun 10, 2022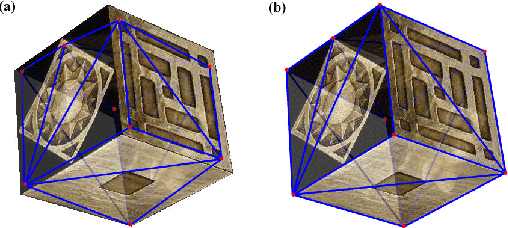
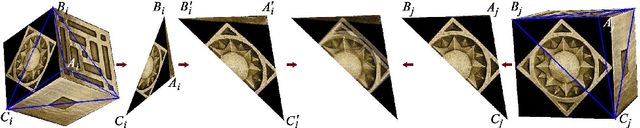

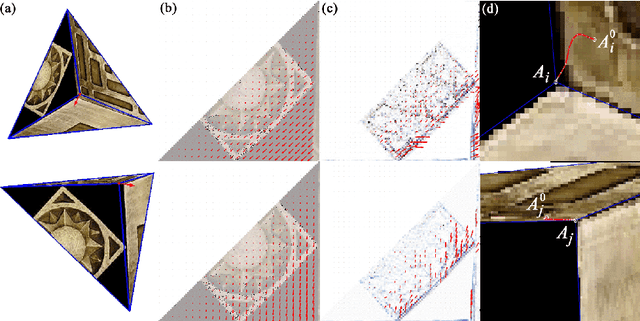
A surface is often modeled as a triangulated mesh of 3D points and textures associated with faces of the mesh. The 3D points could be either sampled from range data or derived from a set of images using a stereo or Structure-from-Motion algorithm. When the points do not lie at critical points of maximum curvature or discontinuities of the real surface, faces of the mesh do not lie close to the modeled surface. This results in textural artifacts, and the model is not perfectly coherent with a set of actual images -- the ones that are used to texture-map its mesh. This paper presents a technique for perfecting the 3D surface model by repositioning its vertices so that it is coherent with a set of observed images of the object. The textural artifacts and incoherence with images are due to the non-planarity of a surface patch being approximated by a planar face, as observed from multiple viewpoints. Image areas from the viewpoints are used to represent texture for the patch in Eigenspace. The Eigenspace representation captures variations of texture, which we seek to minimize. A coherence measure based on the difference between the face textures reconstructed from Eigenspace and the actual images is used to reposition the vertices so that the model is improved or faired. We refer to this technique of model refinement as EigenFairing, by which the model is faired, both geometrically and texturally, to better approximate the real surface.
* British Machine Vision Conference, BMVC 2004, Kingston, UK, September 7-9, 2004
Learning Audio-Video Modalities from Image Captions
Apr 01, 2022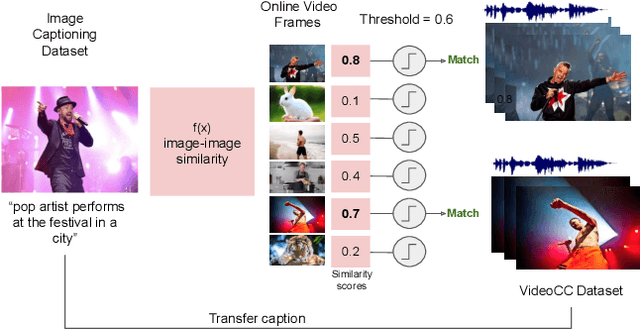
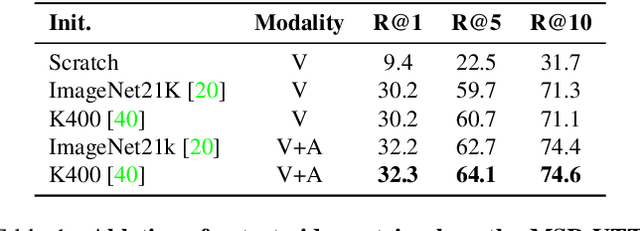

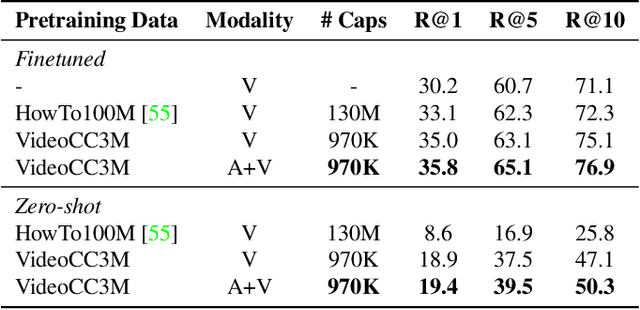
A major challenge in text-video and text-audio retrieval is the lack of large-scale training data. This is unlike image-captioning, where datasets are in the order of millions of samples. To close this gap we propose a new video mining pipeline which involves transferring captions from image captioning datasets to video clips with no additional manual effort. Using this pipeline, we create a new large-scale, weakly labelled audio-video captioning dataset consisting of millions of paired clips and captions. We show that training a multimodal transformed based model on this data achieves competitive performance on video retrieval and video captioning, matching or even outperforming HowTo100M pretraining with 20x fewer clips. We also show that our mined clips are suitable for text-audio pretraining, and achieve state of the art results for the task of audio retrieval.
Ghost Image Processing
Dec 14, 2021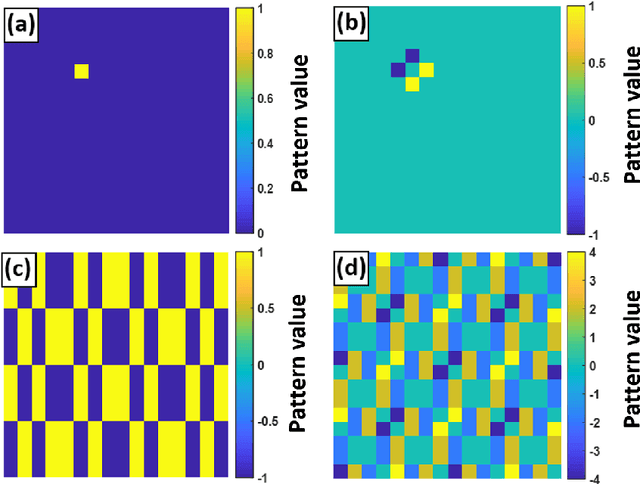
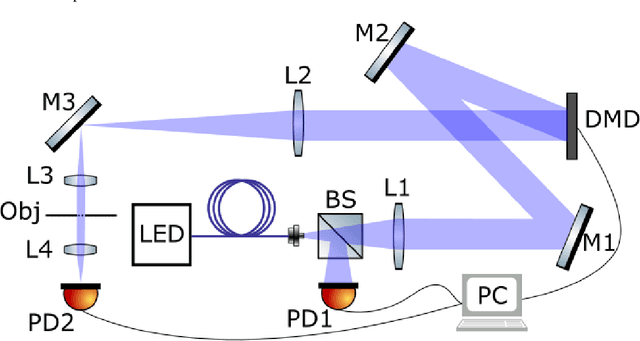

In computational ghost imaging the object is illuminated with a sequence of known patterns, and the scattered light is collected using a detector that has no spatial resolution. Using those patterns and the total intensity measurement from the detector, one can reconstruct the desired image. Here we study how the reconstructed image is modified if the patterns used for the reconstruction are not the same as the illumination patterns, and show that one can choose how to illuminate the object, such that the reconstruction process behaves like a spatial filtering operation on the image. The ability to measure directly a processed image, allows one to bypass the post-processing steps, and thus avoid any noise amplification they imply. As a simple example we show the case of an edge-detection filter.
Hyperspectral image reconstruction for spectral camera based on ghost imaging via sparsity constraints using V-DUnet
Jun 28, 2022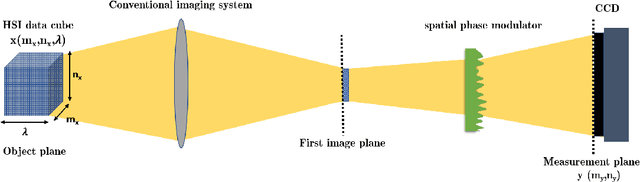
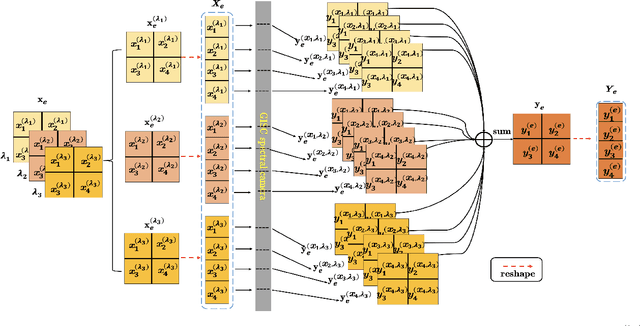
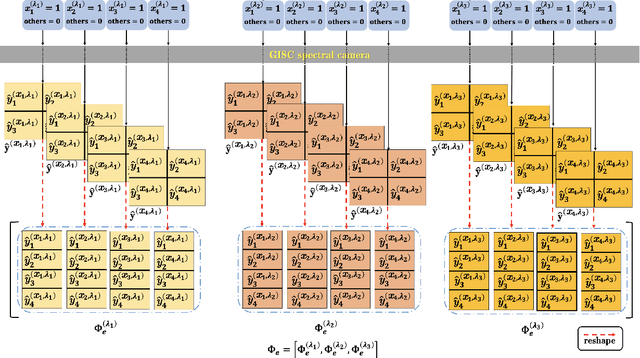
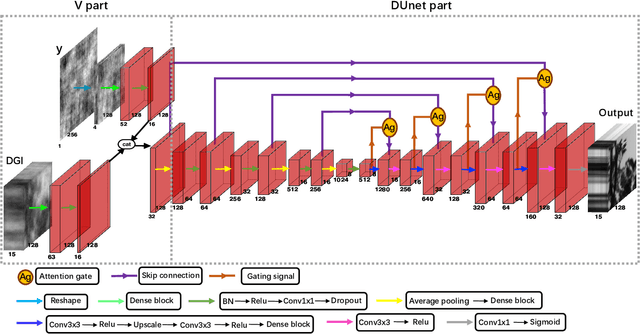
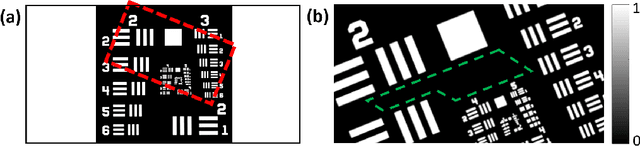
Spectral camera based on ghost imaging via sparsity constraints (GISC spectral camera) obtains three-dimensional (3D) hyperspectral information with two-dimensional (2D) compressive measurements in a single shot, which has attracted much attention in recent years. However, its imaging quality and real-time performance of reconstruction still need to be further improved. Recently, deep learning has shown great potential in improving the reconstruction quality and reconstruction speed for computational imaging. When applying deep learning into GISC spectral camera, there are several challenges need to be solved: 1) how to deal with the large amount of 3D hyperspectral data, 2) how to reduce the influence caused by the uncertainty of the random reference measurements, 3) how to improve the reconstructed image quality as far as possible. In this paper, we present an end-to-end V-DUnet for the reconstruction of 3D hyperspectral data in GISC spectral camera. To reduce the influence caused by the uncertainty of the measurement matrix and enhance the reconstructed image quality, both differential ghost imaging results and the detected measurements are sent into the network's inputs. Compared with compressive sensing algorithm, such as PICHCS and TwIST, it not only significantly improves the imaging quality with high noise immunity, but also speeds up the reconstruction time by more than two orders of magnitude.