 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Relating Regularization and Generalization through the Intrinsic Dimension of Activations
Nov 23, 2022
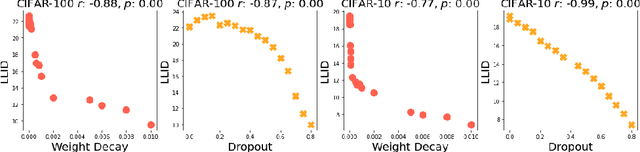
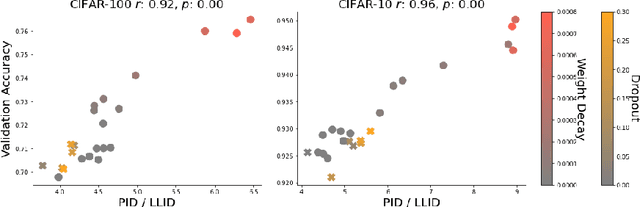
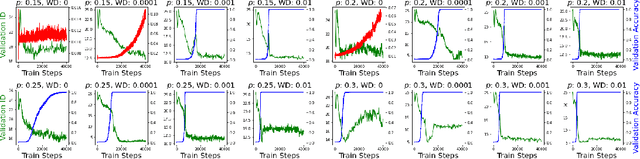

Given a pair of models with similar training set performance, it is natural to assume that the model that possesses simpler internal representations would exhibit better generalization. In this work, we provide empirical evidence for this intuition through an analysis of the intrinsic dimension (ID) of model activations, which can be thought of as the minimal number of factors of variation in the model's representation of the data. First, we show that common regularization techniques uniformly decrease the last-layer ID (LLID) of validation set activations for image classification models and show how this strongly affects generalization performance. We also investigate how excessive regularization decreases a model's ability to extract features from data in earlier layers, leading to a negative effect on validation accuracy even while LLID continues to decrease and training accuracy remains near-perfect. Finally, we examine the LLID over the course of training of models that exhibit grokking. We observe that well after training accuracy saturates, when models ``grok'' and validation accuracy suddenly improves from random to perfect, there is a co-occurent sudden drop in LLID, thus providing more insight into the dynamics of sudden generalization.
A Masked Face Classification Benchmark
Nov 23, 2022
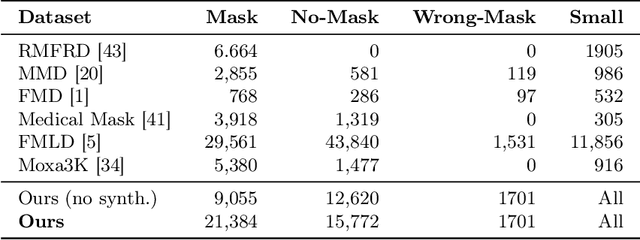

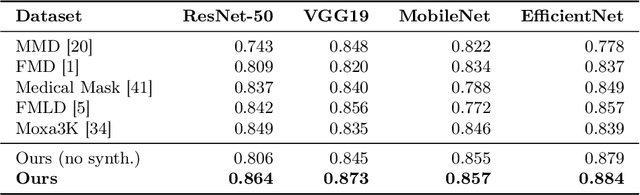
We propose a novel image dataset focused on tiny faces wearing face masks for mask classification purposes, dubbed Small Face MASK (SF-MASK), composed of a collection made from 20k low-resolution images exported from diverse and heterogeneous datasets, ranging from 7 x 7 to 64 x 64 pixel resolution. An accurate visualization of this collection, through counting grids, made it possible to highlight gaps in the variety of poses assumed by the heads of the pedestrians. In particular, faces filmed by very high cameras, in which the facial features appear strongly skewed, are absent. To address this structural deficiency, we produced a set of synthetic images which resulted in a satisfactory covering of the intra-class variance. Furthermore, a small subsample of 1701 images contains badly worn face masks, opening to multi-class classification challenges. Experiments on SF-MASK focus on face mask classification using several classifiers. Results show that the richness of SF-MASK (real + synthetic images) leads all of the tested classifiers to perform better than exploiting comparative face mask datasets, on a fixed 1077 images testing set. Dataset and evaluation code are publicly available here: https://github.com/HumaticsLAB/sf-mask
Physics-informed deep diffusion MRI reconstruction: break the bottleneck of training data in artificial intelligence
Oct 20, 2022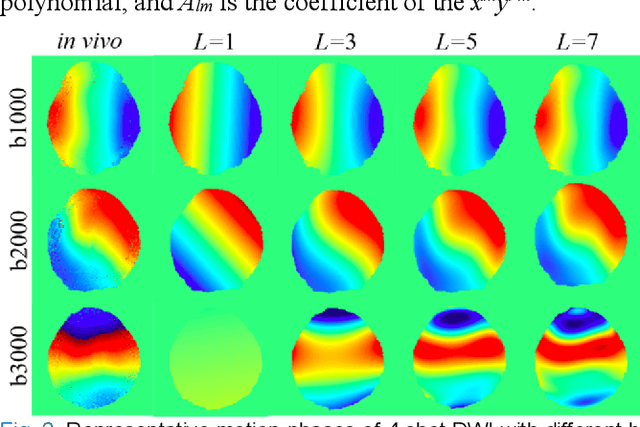
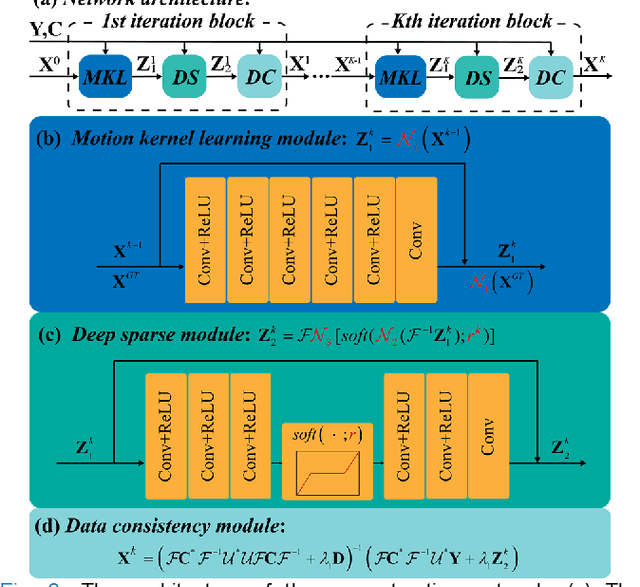
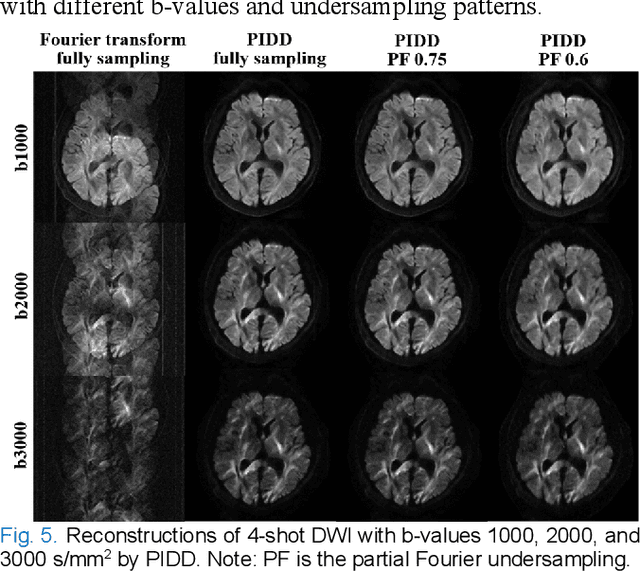
In this work, we propose a Physics-Informed Deep Diffusion magnetic resonance imaging (DWI) reconstruction method (PIDD). PIDD contains two main components: The multi-shot DWI data synthesis and a deep learning reconstruction network. For data synthesis, we first mathematically analyze the motion during the multi-shot data acquisition and approach it by a simplified physical motion model. The motion model inspires a polynomial model for motion-induced phase synthesis. Then, lots of synthetic phases are combined with a few real data to generate a large amount of training data. For reconstruction network, we exploit the smoothness property of each shot image phase as learnable convolution kernels in the k-space and complementary sparsity in the image domain. Results on both synthetic and in vivo brain data show that, the proposed PIDD trained on synthetic data enables sub-second ultra-fast, high-quality, and robust reconstruction with different b-values and undersampling patterns.
Analysis of Different Losses for Deep Learning Image Colorization
Apr 06, 2022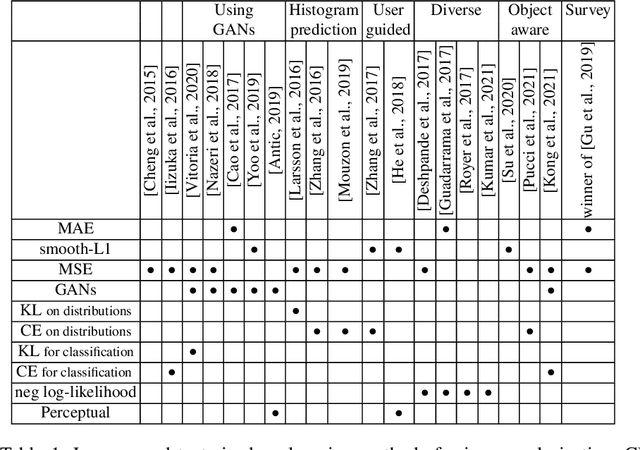
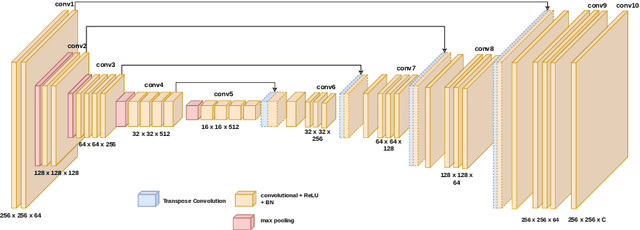
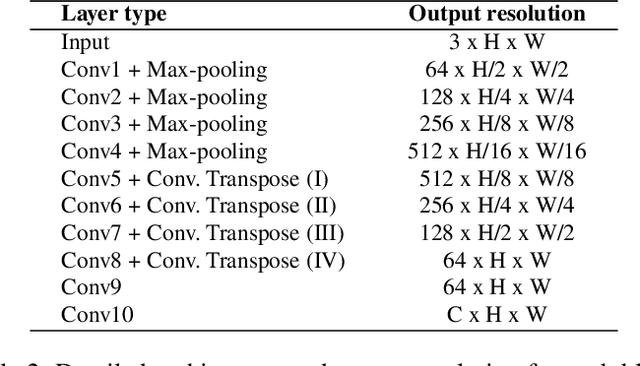

Image colorization aims to add color information to a grayscale image in a realistic way. Recent methods mostly rely on deep learning strategies. While learning to automatically colorize an image, one can define well-suited objective functions related to the desired color output. Some of them are based on a specific type of error between the predicted image and ground truth one, while other losses rely on the comparison of perceptual properties. But, is the choice of the objective function that crucial, i.e., does it play an important role in the results? In this chapter, we aim to answer this question by analyzing the impact of the loss function on the estimated colorization results. To that goal, we review the different losses and evaluation metrics that are used in the literature. We then train a baseline network with several of the reviewed objective functions: classic L1 and L2 losses, as well as more complex combinations such as Wasserstein GAN and VGG-based LPIPS loss. Quantitative results show that the models trained with VGG-based LPIPS provide overall slightly better results for most evaluation metrics. Qualitative results exhibit more vivid colors when with Wasserstein GAN plus the L2 loss or again with the VGG-based LPIPS. Finally, the convenience of quantitative user studies is also discussed to overcome the difficulty of properly assessing on colorized images, notably for the case of old archive photographs where no ground truth is available.
Estimating the Resize Parameter in End-to-end Learned Image Compression
Apr 26, 2022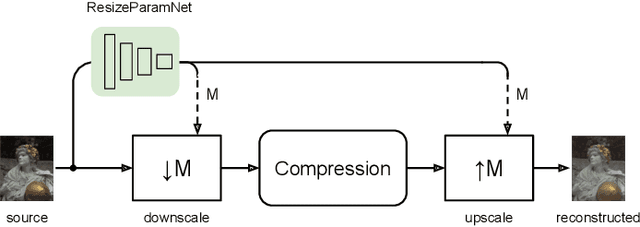
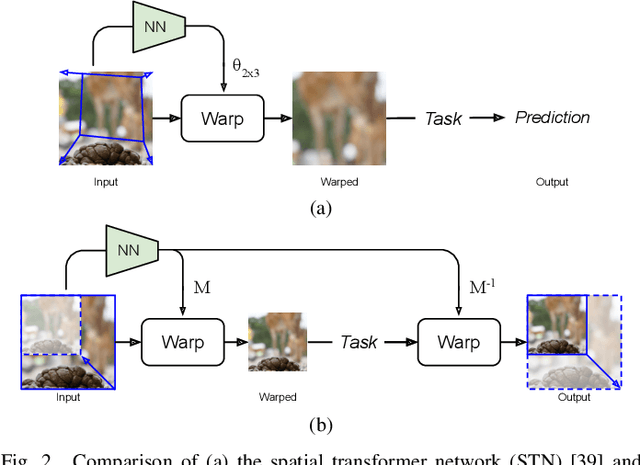
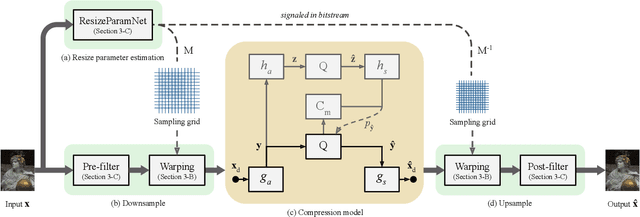
We describe a search-free resizing framework that can further improve the rate-distortion tradeoff of recent learned image compression models. Our approach is simple: compose a pair of differentiable downsampling/upsampling layers that sandwich a neural compression model. To determine resize factors for different inputs, we utilize another neural network jointly trained with the compression model, with the end goal of minimizing the rate-distortion objective. Our results suggest that "compression friendly" downsampled representations can be quickly determined during encoding by using an auxiliary network and differentiable image warping. By conducting extensive experimental tests on existing deep image compression models, we show results that our new resizing parameter estimation framework can provide Bj{\o}ntegaard-Delta rate (BD-rate) improvement of about 10% against leading perceptual quality engines. We also carried out a subjective quality study, the results of which show that our new approach yields favorable compressed images. To facilitate reproducible research in this direction, the implementation used in this paper is being made freely available online at: https://github.com/treammm/ResizeCompression.
Patcher: Patch Transformers with Mixture of Experts for Precise Medical Image Segmentation
Jun 03, 2022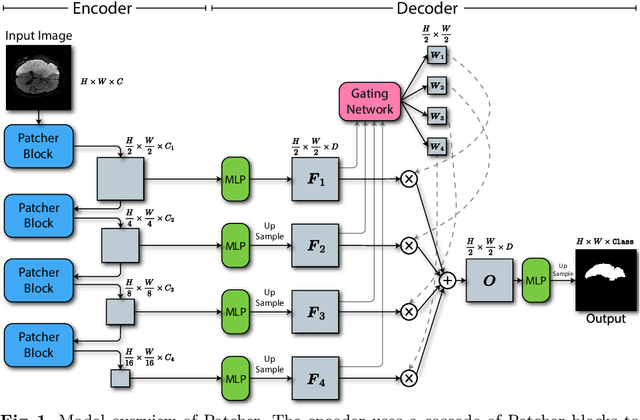
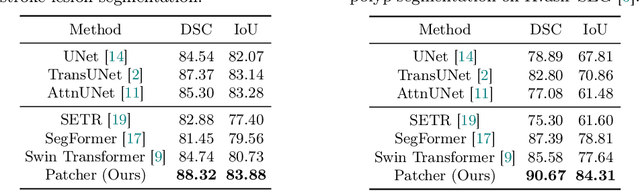


We present a new encoder-decoder Vision Transformer architecture, Patcher, for medical image segmentation. Unlike standard Vision Transformers, it employs Patcher blocks that segment an image into large patches, each of which is further divided into small patches. Transformers are applied to the small patches within a large patch, which constrains the receptive field of each pixel. We intentionally make the large patches overlap to enhance intra-patch communication. The encoder employs a cascade of Patcher blocks with increasing receptive fields to extract features from local to global levels. This design allows Patcher to benefit from both the coarse-to-fine feature extraction common in CNNs and the superior spatial relationship modeling of Transformers. We also propose a new mixture-of-experts (MoE) based decoder, which treats the feature maps from the encoder as experts and selects a suitable set of expert features to predict the label for each pixel. The use of MoE enables better specializations of the expert features and reduces interference between them during inference. Extensive experiments demonstrate that Patcher outperforms state-of-the-art Transformer- and CNN-based approaches significantly on stroke lesion segmentation and polyp segmentation. Code for Patcher will be released with publication to facilitate future research.
Spot the fake lungs: Generating Synthetic Medical Images using Neural Diffusion Models
Nov 02, 2022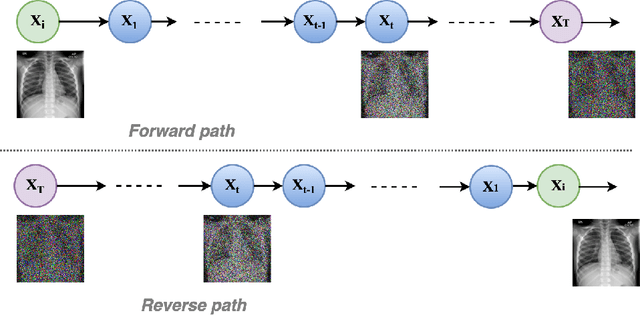
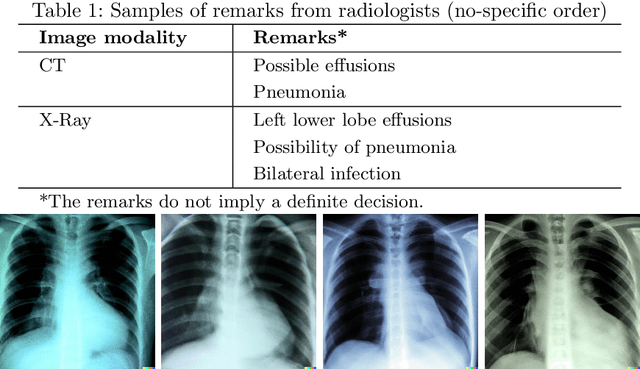
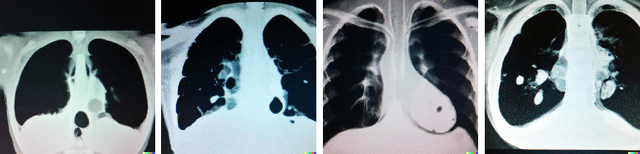
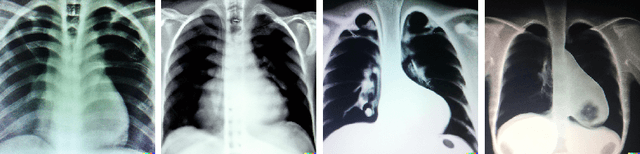
Generative models are becoming popular for the synthesis of medical images. Recently, neural diffusion models have demonstrated the potential to generate photo-realistic images of objects. However, their potential to generate medical images is not explored yet. In this work, we explore the possibilities of synthesis of medical images using neural diffusion models. First, we use a pre-trained DALLE2 model to generate lungs X-Ray and CT images from an input text prompt. Second, we train a stable diffusion model with 3165 X-Ray images and generate synthetic images. We evaluate the synthetic image data through a qualitative analysis where two independent radiologists label randomly chosen samples from the generated data as real, fake, or unsure. Results demonstrate that images generated with the diffusion model can translate characteristics that are otherwise very specific to certain medical conditions in chest X-Ray or CT images. Careful tuning of the model can be very promising. To the best of our knowledge, this is the first attempt to generate lungs X-Ray and CT images using neural diffusion models. This work aims to introduce a new dimension in artificial intelligence for medical imaging. Given that this is a new topic, the paper will serve as an introduction and motivation for the research community to explore the potential of diffusion models for medical image synthesis. We have released the synthetic images on https://www.kaggle.com/datasets/hazrat/awesomelungs.
What Images are More Memorable to Machines?
Nov 14, 2022
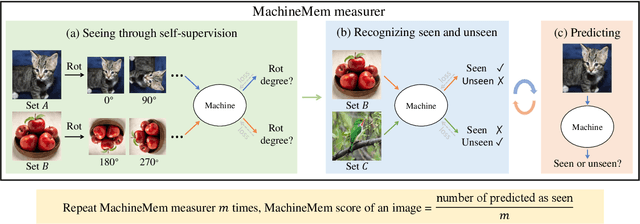
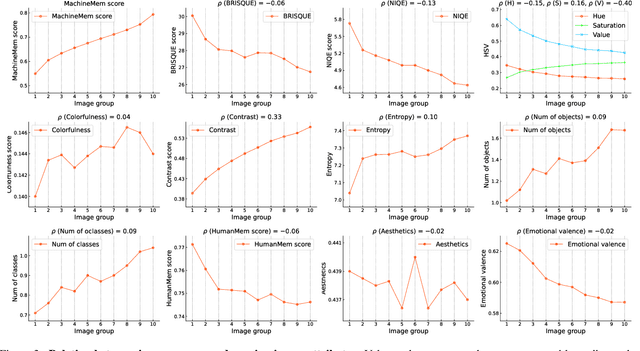

This paper studies the problem of measuring and predicting how memorable an image is to pattern recognition machines, as a path to explore machine intelligence. Firstly, we propose a self-supervised machine memory quantification pipeline, dubbed ``MachineMem measurer'', to collect machine memorability scores of images. Similar to humans, machines also tend to memorize certain kinds of images, whereas the types of images that machines and humans memorialize are different. Through in-depth analysis and comprehensive visualizations, we gradually unveil that "complex" images are usually more memorable to machines. We further conduct extensive experiments across 11 different machines (from linear classifiers to modern ViTs) and 9 pre-training methods to analyze and understand machine memory. This work proposes the concept of machine memorability and opens a new research direction at the interface between machine memory and visual data.
Improving Human Image Synthesis with Residual Fast Fourier Transformation and Wasserstein Distance
May 26, 2022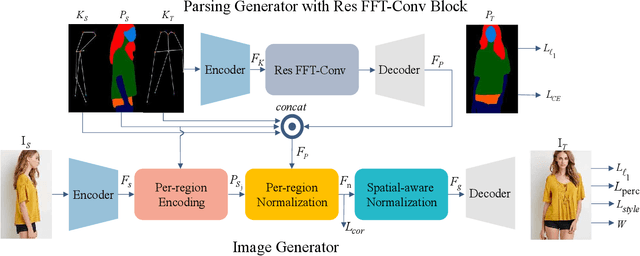
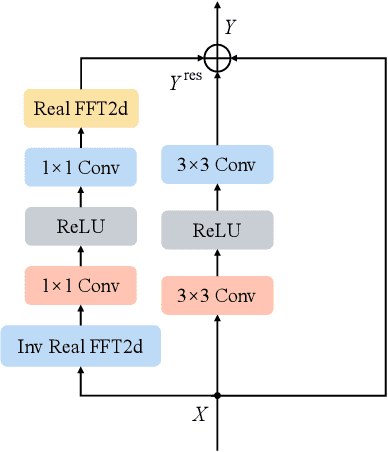
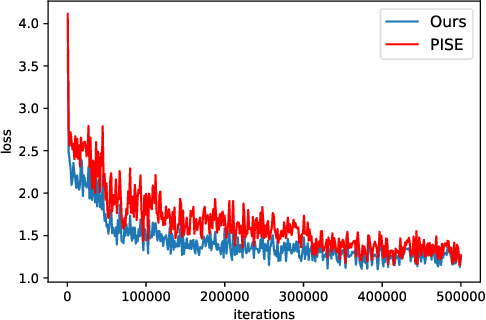
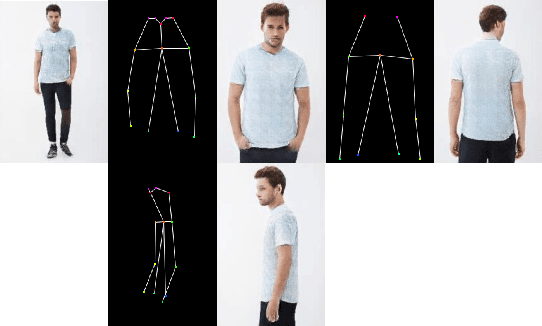
With the rapid development of the Metaverse, virtual humans have emerged, and human image synthesis and editing techniques, such as pose transfer, have recently become popular. Most of the existing techniques rely on GANs, which can generate good human images even with large variants and occlusions. But from our best knowledge, the existing state-of-the-art method still has the following problems: the first is that the rendering effect of the synthetic image is not realistic, such as poor rendering of some regions. And the second is that the training of GAN is unstable and slow to converge, such as model collapse. Based on the above two problems, we propose several methods to solve them. To improve the rendering effect, we use the Residual Fast Fourier Transform Block to replace the traditional Residual Block. Then, spectral normalization and Wasserstein distance are used to improve the speed and stability of GAN training. Experiments demonstrate that the methods we offer are effective at solving the problems listed above, and we get state-of-the-art scores in LPIPS and PSNR.
Coordinate Translator for Learning Deformable Medical Image Registration
Mar 05, 2022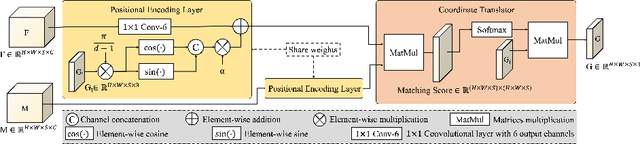
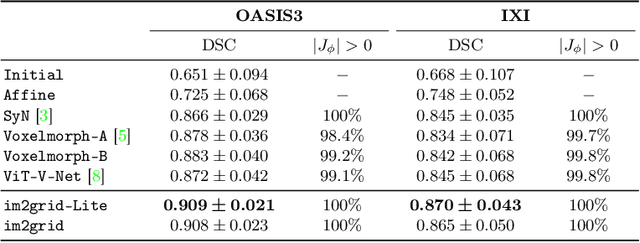
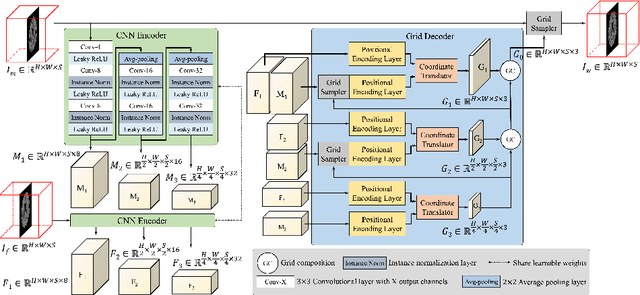
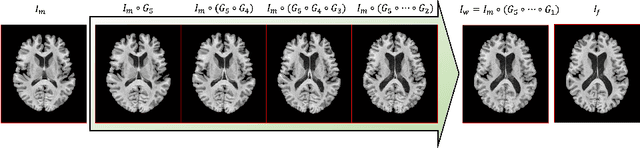
The majority of deep learning (DL) based deformable image registration methods use convolutional neural networks (CNNs) to estimate displacement fields from pairs of moving and fixed images. This, however, requires the convolutional kernels in the CNN to not only extract intensity features from the inputs but also understand image coordinate systems. We argue that the latter task is challenging for traditional CNNs, limiting their performance in registration tasks. To tackle this problem, we first introduce Coordinate Translator (CoTr), a differentiable module that identifies matched features between the fixed and moving image and outputs their coordinate correspondences without the need for training. It unloads the burden of understanding image coordinate systems for CNNs, allowing them to focus on feature extraction. We then propose a novel deformable registration network, im2grid, that uses multiple CoTr's with the hierarchical features extracted from a CNN encoder and outputs a deformation field in a coarse-to-fine fashion. We compared im2grid with the state-of-the-art DL and non-DL methods for unsupervised 3D magnetic resonance image registration. Our experiments show that im2grid outperforms these methods both qualitatively and quantitatively.