 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Federated Learning Scheme for Neuro-developmental Disorders: Multi-Aspect ASD Detection
Oct 31, 2022
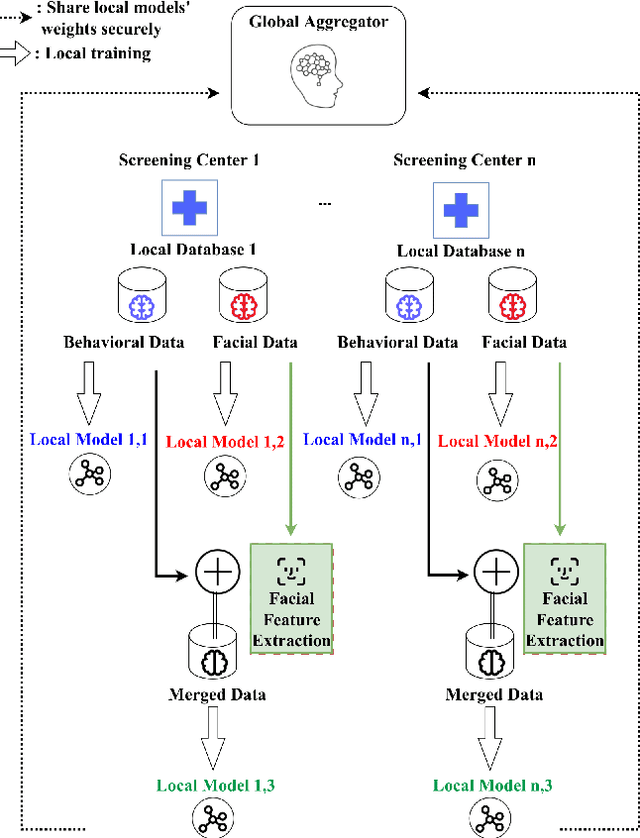


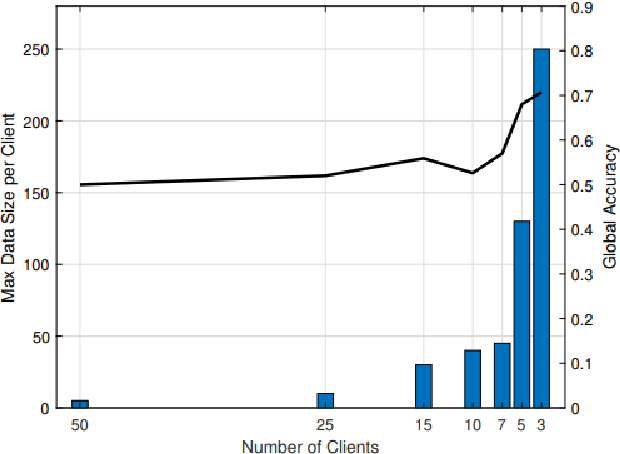
Autism Spectrum Disorder (ASD) is a neuro-developmental syndrome resulting from alterations in the embryological brain before birth. This disorder distinguishes its patients by special socially restricted and repetitive behavior in addition to specific behavioral traits. Hence, this would possibly deteriorate their social behavior among other individuals, as well as their overall interaction within their community. Moreover, medical research has proved that ASD also affects the facial characteristics of its patients, making the syndrome recognizable from distinctive signs within an individual's face. Given that as a motivation behind our work, we propose a novel privacy-preserving federated learning scheme to predict ASD in a certain individual based on their behavioral and facial features, embedding a merging process of both data features through facial feature extraction while respecting patient data privacy. After training behavioral and facial image data on federated machine learning models, promising results are achieved, with 70\% accuracy for the prediction of ASD according to behavioral traits in a federated learning environment, and a 62\% accuracy is reached for the prediction of ASD given an image of the patient's face. Then, we test the behavior of regular as well as federated ML on our merged data, behavioral and facial, where a 65\% accuracy is achieved with the regular logistic regression model and 63\% accuracy with the federated learning model.
A Self-Supervised Descriptor for Image Copy Detection
Mar 25, 2022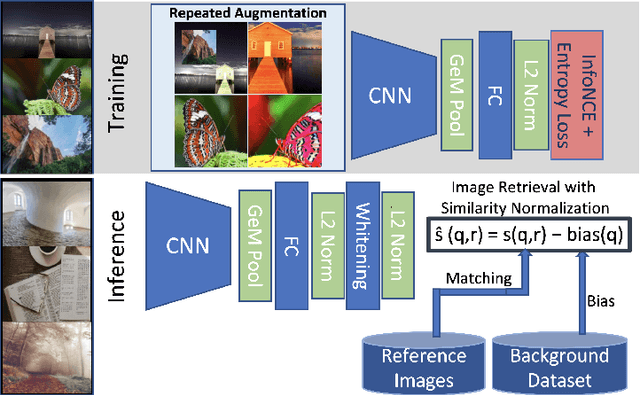


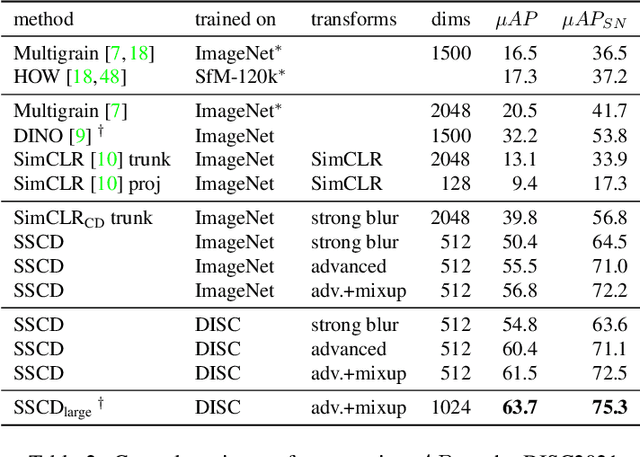
Image copy detection is an important task for content moderation. We introduce SSCD, a model that builds on a recent self-supervised contrastive training objective. We adapt this method to the copy detection task by changing the architecture and training objective, including a pooling operator from the instance matching literature, and adapting contrastive learning to augmentations that combine images. Our approach relies on an entropy regularization term, promoting consistent separation between descriptor vectors, and we demonstrate that this significantly improves copy detection accuracy. Our method produces a compact descriptor vector, suitable for real-world web scale applications. Statistical information from a background image distribution can be incorporated into the descriptor. On the recent DISC2021 benchmark, SSCD is shown to outperform both baseline copy detection models and self-supervised architectures designed for image classification by huge margins, in all settings. For example, SSCD out-performs SimCLR descriptors by 48% absolute. Code is available at https://github.com/facebookresearch/sscd-copy-detection.
S2F2: Self-Supervised High Fidelity Face Reconstruction from Monocular Image
Apr 05, 2022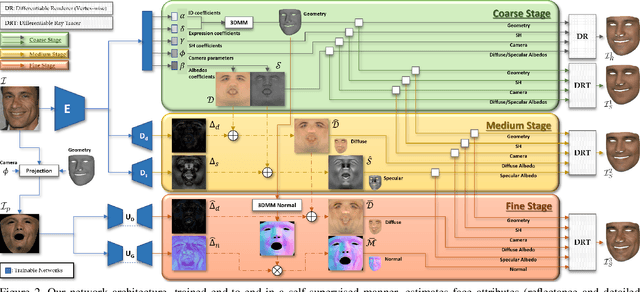


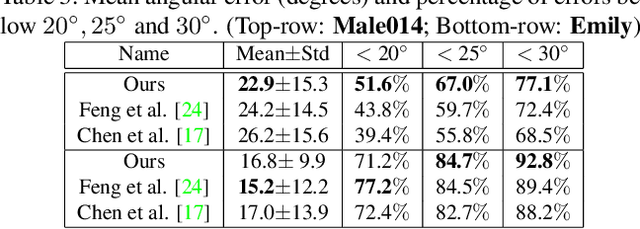
We present a novel face reconstruction method capable of reconstructing detailed face geometry, spatially varying face reflectance from a single monocular image. We build our work upon the recent advances of DNN-based auto-encoders with differentiable ray tracing image formation, trained in self-supervised manner. While providing the advantage of learning-based approaches and real-time reconstruction, the latter methods lacked fidelity. In this work, we achieve, for the first time, high fidelity face reconstruction using self-supervised learning only. Our novel coarse-to-fine deep architecture allows us to solve the challenging problem of decoupling face reflectance from geometry using a single image, at high computational speed. Compared to state-of-the-art methods, our method achieves more visually appealing reconstruction.
Reflectance-Guided, Contrast-Accumulated Histogram Equalization
Sep 14, 2022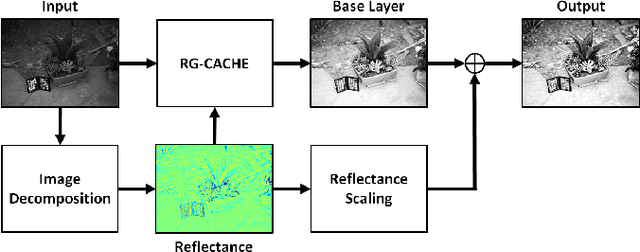
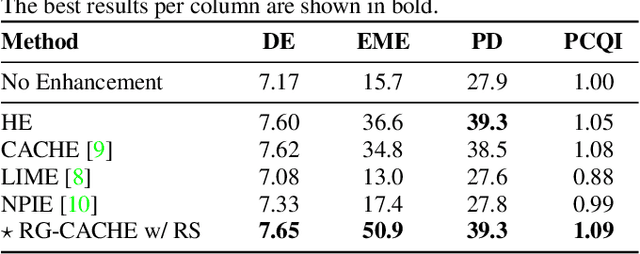


Existing image enhancement methods fall short of expectations because with them it is difficult to improve global and local image contrast simultaneously. To address this problem, we propose a histogram equalization-based method that adapts to the data-dependent requirements of brightness enhancement and improves the visibility of details without losing the global contrast. This method incorporates the spatial information provided by image context in density estimation for discriminative histogram equalization. To minimize the adverse effect of non-uniform illumination, we propose defining spatial information on the basis of image reflectance estimated with edge preserving smoothing. Our method works particularly well for determining how the background brightness should be adaptively adjusted and for revealing useful image details hidden in the dark.
Wassmap: Wasserstein Isometric Mapping for Image Manifold Learning
Apr 13, 2022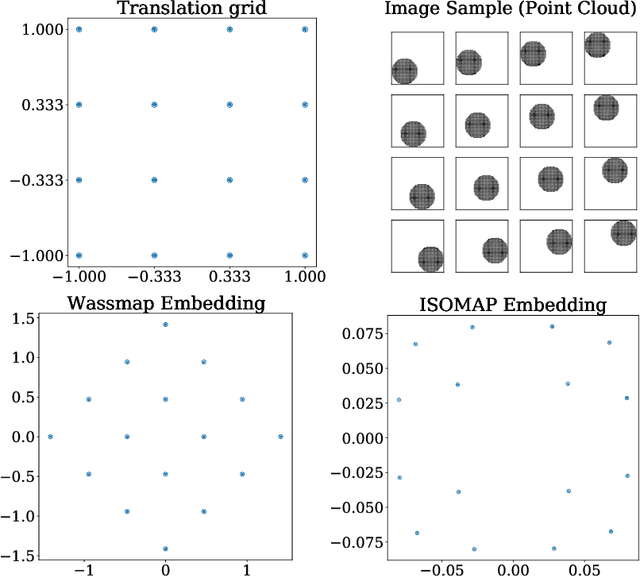
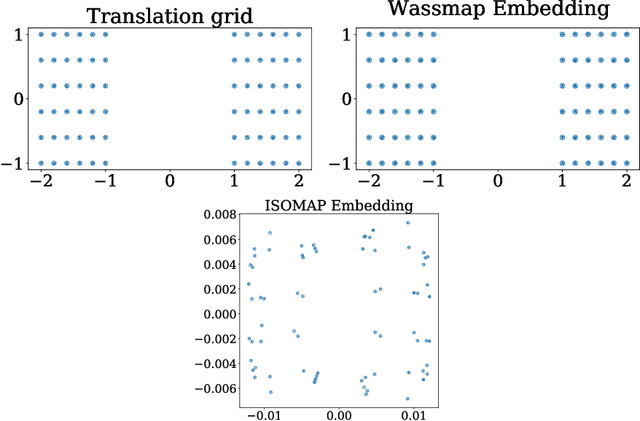
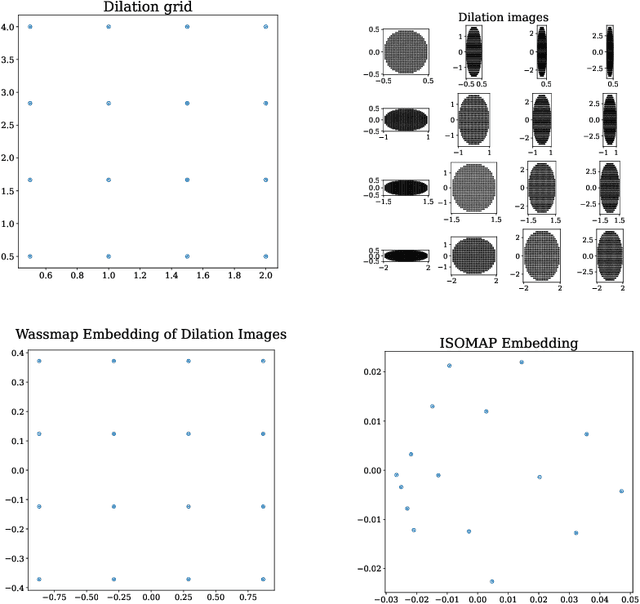
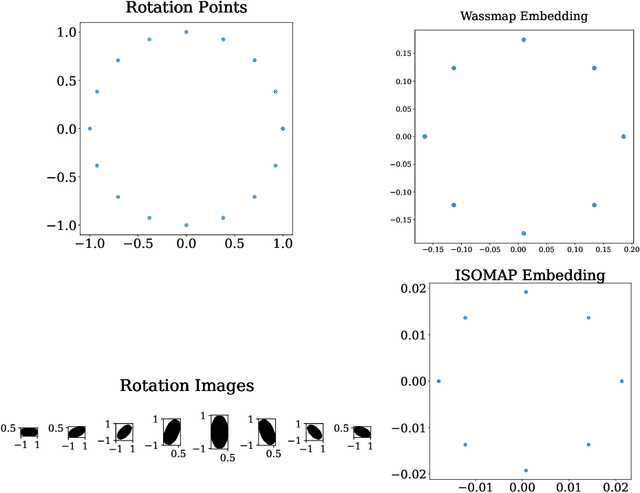
In this paper, we propose Wasserstein Isometric Mapping (Wassmap), a parameter-free nonlinear dimensionality reduction technique that provides solutions to some drawbacks in existing global nonlinear dimensionality reduction algorithms in imaging applications. Wassmap represents images via probability measures in Wasserstein space, then uses pairwise quadratic Wasserstein distances between the associated measures to produce a low-dimensional, approximately isometric embedding. We show that the algorithm is able to exactly recover parameters of some image manifolds including those generated by translations or dilations of a fixed generating measure. Additionally, we show that a discrete version of the algorithm retrieves parameters from manifolds generated from discrete measures by providing a theoretical bridge to transfer recovery results from functional data to discrete data. Testing of the proposed algorithms on various image data manifolds show that Wassmap yields good embeddings compared with other global techniques.
DP-NeRF: Deblurred Neural Radiance Field with Physical Scene Priors
Dec 02, 2022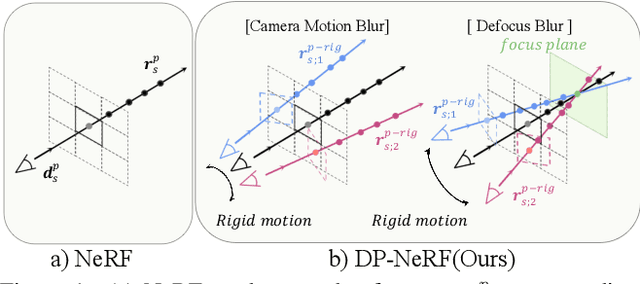
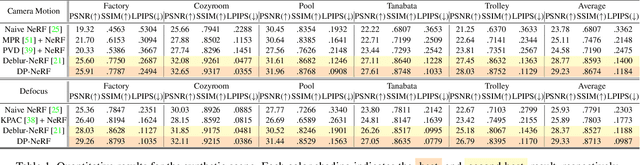
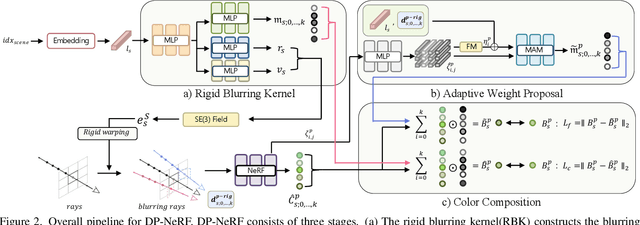

Neural Radiance Field(NeRF) has exhibited outstanding three-dimensional(3D) reconstruction quality via the novel view synthesis from multi-view images and paired calibrated camera parameters. However, previous NeRF-based systems have been demonstrated under strictly controlled settings, with little attention paid to less ideal scenarios, including with the presence of noise such as exposure, illumination changes, and blur. In particular, though blur frequently occurs in real situations, NeRF that can handle blurred images has received little attention. The few studies that have investigated NeRF for blurred images have not considered geometric and appearance consistency in 3D space, which is one of the most important factors in 3D reconstruction. This leads to inconsistency and the degradation of the perceptual quality of the constructed scene. Hence, this paper proposes a DP-NeRF, a novel clean NeRF framework for blurred images, which is constrained with two physical priors. These priors are derived from the actual blurring process during image acquisition by the camera. DP-NeRF proposes rigid blurring kernel to impose 3D consistency utilizing the physical priors and adaptive weight proposal to refine the color composition error in consideration of the relationship between depth and blur. We present extensive experimental results for synthetic and real scenes with two types of blur: camera motion blur and defocus blur. The results demonstrate that DP-NeRF successfully improves the perceptual quality of the constructed NeRF ensuring 3D geometric and appearance consistency. We further demonstrate the effectiveness of our model with comprehensive ablation analysis.
Navigating to Objects in the Real World
Dec 02, 2022

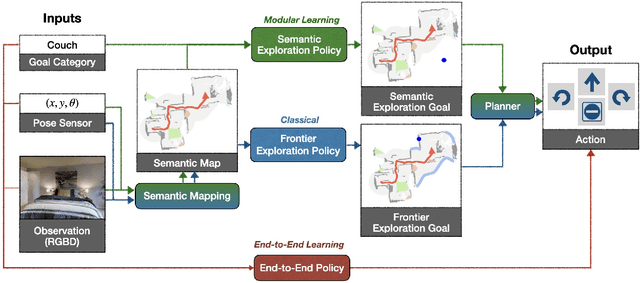
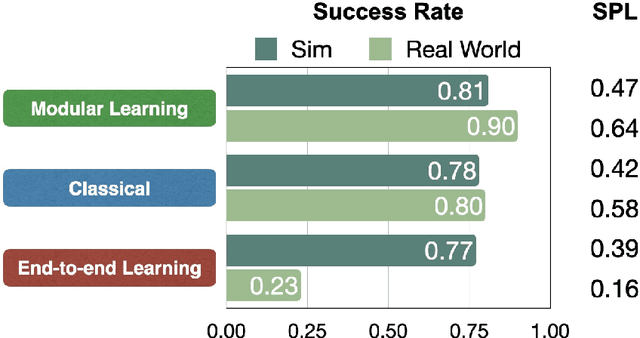
Semantic navigation is necessary to deploy mobile robots in uncontrolled environments like our homes, schools, and hospitals. Many learning-based approaches have been proposed in response to the lack of semantic understanding of the classical pipeline for spatial navigation, which builds a geometric map using depth sensors and plans to reach point goals. Broadly, end-to-end learning approaches reactively map sensor inputs to actions with deep neural networks, while modular learning approaches enrich the classical pipeline with learning-based semantic sensing and exploration. But learned visual navigation policies have predominantly been evaluated in simulation. How well do different classes of methods work on a robot? We present a large-scale empirical study of semantic visual navigation methods comparing representative methods from classical, modular, and end-to-end learning approaches across six homes with no prior experience, maps, or instrumentation. We find that modular learning works well in the real world, attaining a 90% success rate. In contrast, end-to-end learning does not, dropping from 77% simulation to 23% real-world success rate due to a large image domain gap between simulation and reality. For practitioners, we show that modular learning is a reliable approach to navigate to objects: modularity and abstraction in policy design enable Sim-to-Real transfer. For researchers, we identify two key issues that prevent today's simulators from being reliable evaluation benchmarks - (A) a large Sim-to-Real gap in images and (B) a disconnect between simulation and real-world error modes - and propose concrete steps forward.
Optimizing Explanations by Network Canonization and Hyperparameter Search
Nov 30, 2022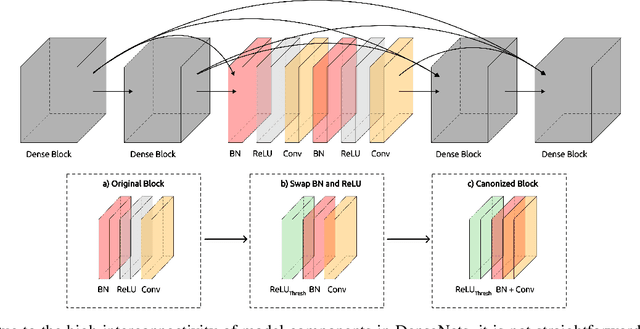
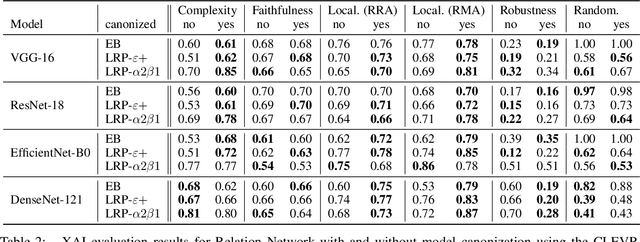
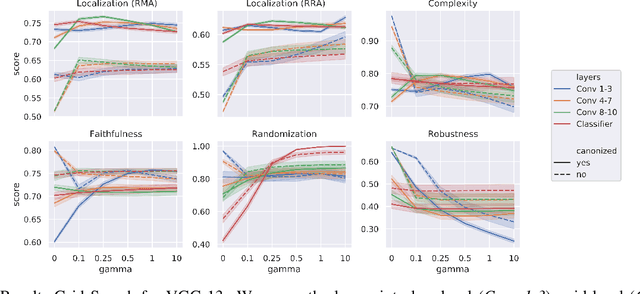
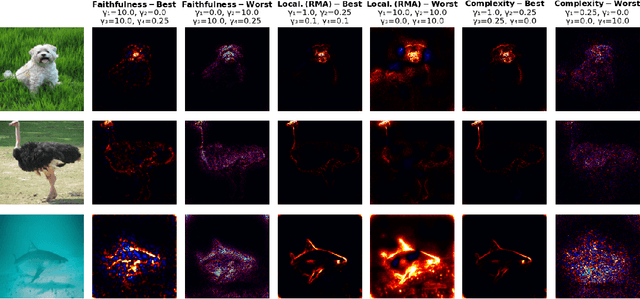
Explainable AI (XAI) is slowly becoming a key component for many AI applications. Rule-based and modified backpropagation XAI approaches however often face challenges when being applied to modern model architectures including innovative layer building blocks, which is caused by two reasons. Firstly, the high flexibility of rule-based XAI methods leads to numerous potential parameterizations. Secondly, many XAI methods break the implementation-invariance axiom because they struggle with certain model components, e.g., BatchNorm layers. The latter can be addressed with model canonization, which is the process of re-structuring the model to disregard problematic components without changing the underlying function. While model canonization is straightforward for simple architectures (e.g., VGG, ResNet), it can be challenging for more complex and highly interconnected models (e.g., DenseNet). Moreover, there is only little quantifiable evidence that model canonization is beneficial for XAI. In this work, we propose canonizations for currently relevant model blocks applicable to popular deep neural network architectures,including VGG, ResNet, EfficientNet, DenseNets, as well as Relation Networks. We further suggest a XAI evaluation framework with which we quantify and compare the effect sof model canonization for various XAI methods in image classification tasks on the Pascal-VOC and ILSVRC2017 datasets, as well as for Visual Question Answering using CLEVR-XAI. Moreover, addressing the former issue outlined above, we demonstrate how our evaluation framework can be applied to perform hyperparameter search for XAI methods to optimize the quality of explanations.
Attention-based Depth Distillation with 3D-Aware Positional Encoding for Monocular 3D Object Detection
Nov 30, 2022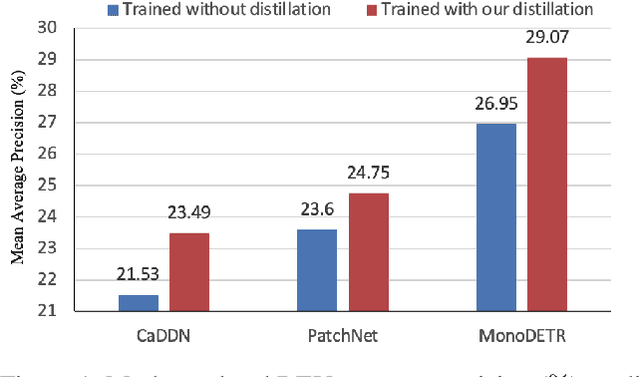
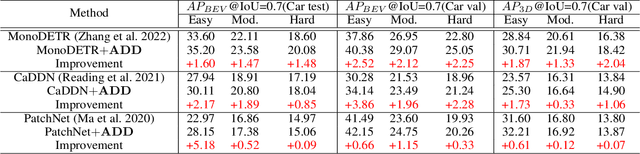
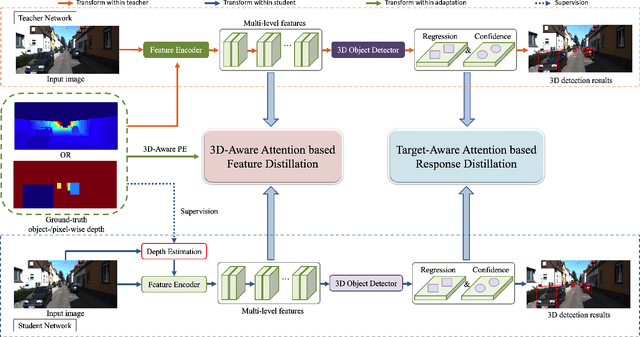
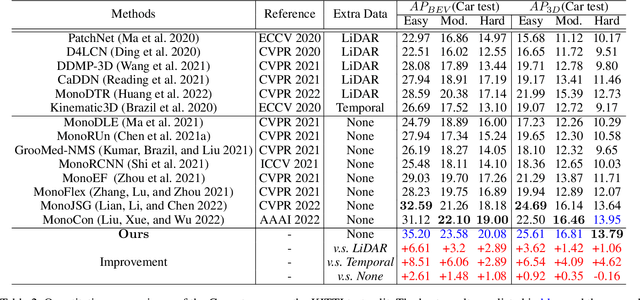
Monocular 3D object detection is a low-cost but challenging task, as it requires generating accurate 3D localization solely from a single image input. Recent developed depth-assisted methods show promising results by using explicit depth maps as intermediate features, which are either precomputed by monocular depth estimation networks or jointly evaluated with 3D object detection. However, inevitable errors from estimated depth priors may lead to misaligned semantic information and 3D localization, hence resulting in feature smearing and suboptimal predictions. To mitigate this issue, we propose ADD, an Attention-based Depth knowledge Distillation framework with 3D-aware positional encoding. Unlike previous knowledge distillation frameworks that adopt stereo- or LiDAR-based teachers, we build up our teacher with identical architecture as the student but with extra ground-truth depth as input. Credit to our teacher design, our framework is seamless, domain-gap free, easily implementable, and is compatible with object-wise ground-truth depth. Specifically, we leverage intermediate features and responses for knowledge distillation. Considering long-range 3D dependencies, we propose \emph{3D-aware self-attention} and \emph{target-aware cross-attention} modules for student adaptation. Extensive experiments are performed to verify the effectiveness of our framework on the challenging KITTI 3D object detection benchmark. We implement our framework on three representative monocular detectors, and we achieve state-of-the-art performance with no additional inference computational cost relative to baseline models. Our code is available at https://github.com/rockywind/ADD.
Physics-informed deep diffusion MRI reconstruction: break the bottleneck of training data in artificial intelligence
Oct 20, 2022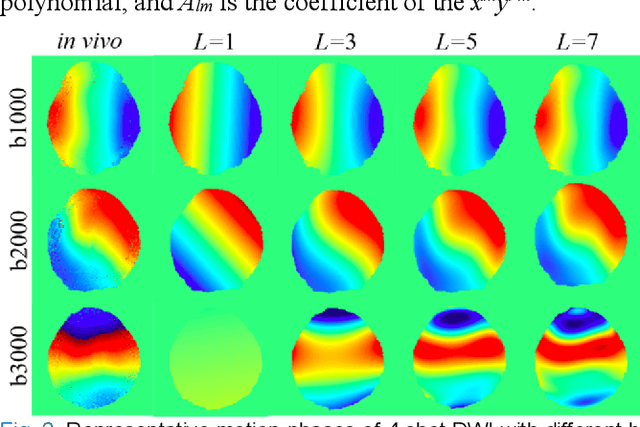
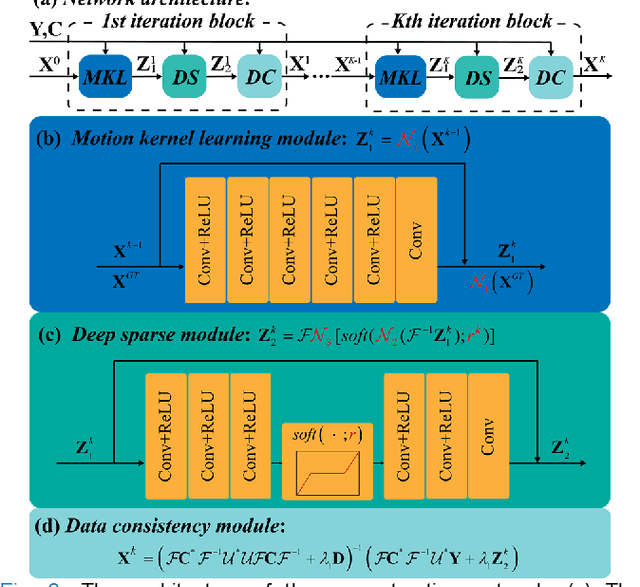
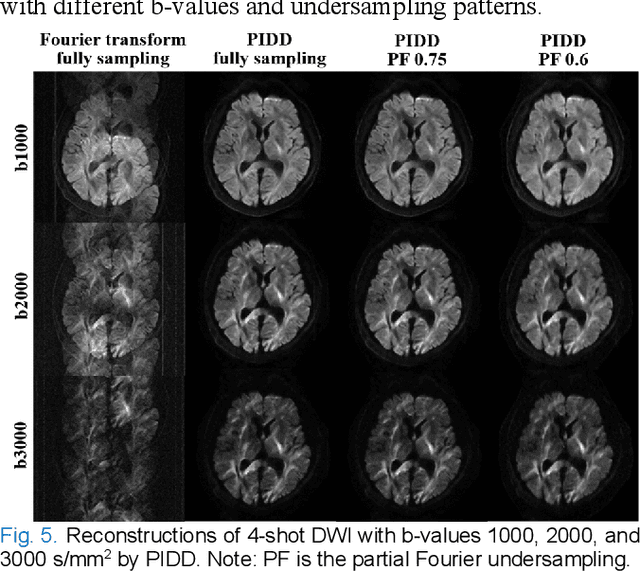
In this work, we propose a Physics-Informed Deep Diffusion magnetic resonance imaging (DWI) reconstruction method (PIDD). PIDD contains two main components: The multi-shot DWI data synthesis and a deep learning reconstruction network. For data synthesis, we first mathematically analyze the motion during the multi-shot data acquisition and approach it by a simplified physical motion model. The motion model inspires a polynomial model for motion-induced phase synthesis. Then, lots of synthetic phases are combined with a few real data to generate a large amount of training data. For reconstruction network, we exploit the smoothness property of each shot image phase as learnable convolution kernels in the k-space and complementary sparsity in the image domain. Results on both synthetic and in vivo brain data show that, the proposed PIDD trained on synthetic data enables sub-second ultra-fast, high-quality, and robust reconstruction with different b-values and undersampling patterns.