 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Task-Aware Low-Rank Adaptation of Segment Anything Model
Mar 16, 2024
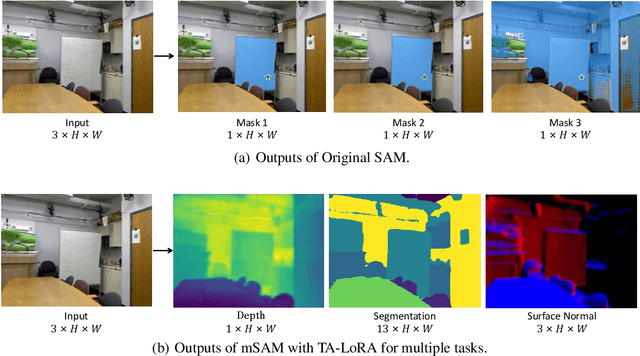
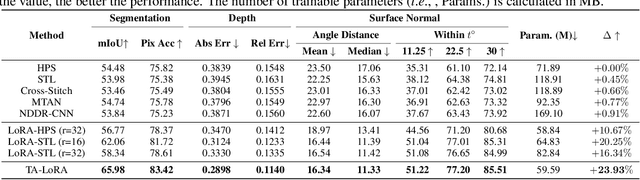
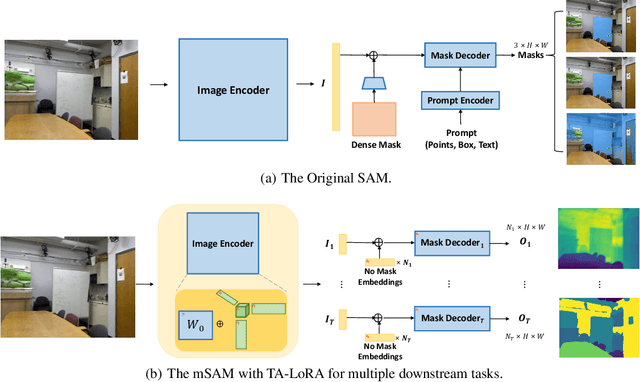
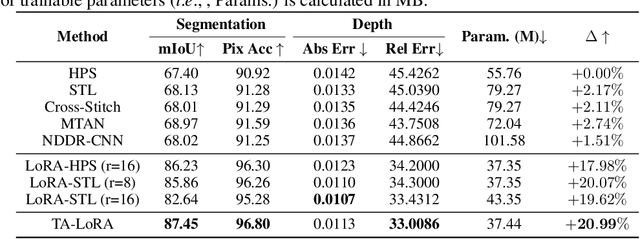
The Segment Anything Model (SAM), with its remarkable zero-shot capability, has been proven to be a powerful foundation model for image segmentation tasks, which is an important task in computer vision. However, the transfer of its rich semantic information to multiple different downstream tasks remains unexplored. In this paper, we propose the Task-Aware Low-Rank Adaptation (TA-LoRA) method, which enables SAM to work as a foundation model for multi-task learning. Specifically, TA-LoRA injects an update parameter tensor into each layer of the encoder in SAM and leverages a low-rank tensor decomposition method to incorporate both task-shared and task-specific information. Furthermore, we introduce modified SAM (mSAM) for multi-task learning where we remove the prompt encoder of SAM and use task-specific no mask embeddings and mask decoder for each task. Extensive experiments conducted on benchmark datasets substantiate the efficacy of TA-LoRA in enhancing the performance of mSAM across multiple downstream tasks.
Graph Regularized NMF with L20-norm for Unsupervised Feature Learning
Mar 16, 2024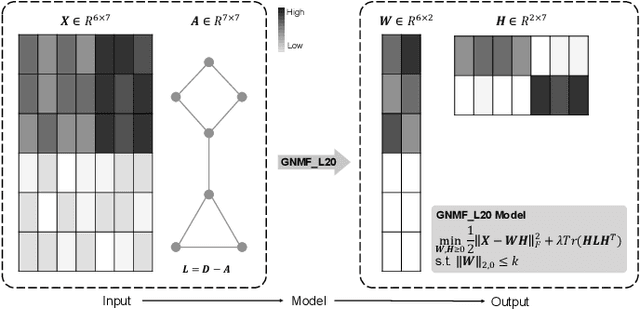

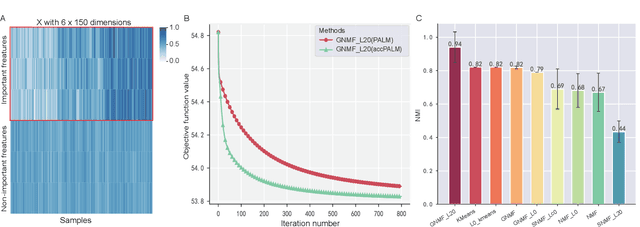
Nonnegative Matrix Factorization (NMF) is a widely applied technique in the fields of machine learning and data mining. Graph Regularized Non-negative Matrix Factorization (GNMF) is an extension of NMF that incorporates graph regularization constraints. GNMF has demonstrated exceptional performance in clustering and dimensionality reduction, effectively discovering inherent low-dimensional structures embedded within high-dimensional spaces. However, the sensitivity of GNMF to noise limits its stability and robustness in practical applications. In order to enhance feature sparsity and mitigate the impact of noise while mining row sparsity patterns in the data for effective feature selection, we introduce the $\ell_{2,0}$-norm constraint as the sparsity constraints for GNMF. We propose an unsupervised feature learning framework based on GNMF\_$\ell_{20}$ and devise an algorithm based on PALM and its accelerated version to address this problem. Additionally, we establish the convergence of the proposed algorithms and validate the efficacy and superiority of our approach through experiments conducted on both simulated and real image data.
Generalized Relevance Learning Grassmann Quantization
Mar 14, 2024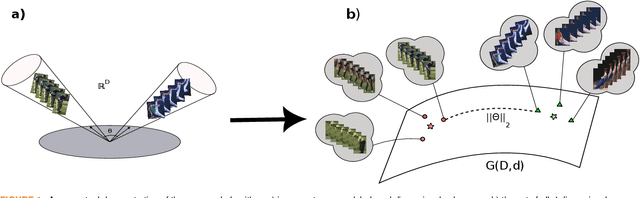


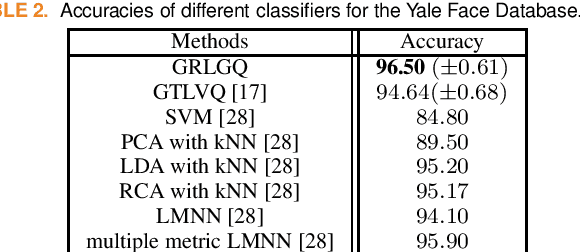
Due to advancements in digital cameras, it is easy to gather multiple images (or videos) from an object under different conditions. Therefore, image-set classification has attracted more attention, and different solutions were proposed to model them. A popular way to model image sets is subspaces, which form a manifold called the Grassmann manifold. In this contribution, we extend the application of Generalized Relevance Learning Vector Quantization to deal with Grassmann manifold. The proposed model returns a set of prototype subspaces and a relevance vector. While prototypes model typical behaviours within classes, the relevance factors specify the most discriminative principal vectors (or images) for the classification task. They both provide insights into the model's decisions by highlighting influential images and pixels for predictions. Moreover, due to learning prototypes, the model complexity of the new method during inference is independent of dataset size, unlike previous works. We applied it to several recognition tasks including handwritten digit recognition, face recognition, activity recognition, and object recognition. Experiments demonstrate that it outperforms previous works with lower complexity and can successfully model the variation, such as handwritten style or lighting conditions. Moreover, the presence of relevances makes the model robust to the selection of subspaces' dimensionality.
VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
Mar 14, 2024
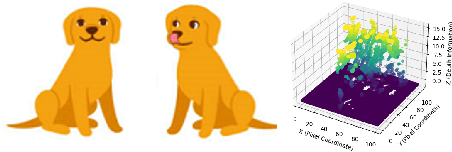

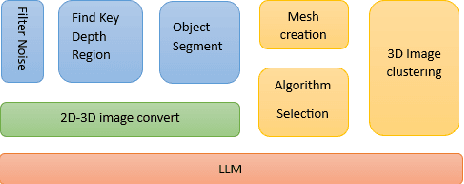
The evolution of text to visual components facilitates people's daily lives, such as generating image, videos from text and identifying the desired elements within the images. Computer vision models involving the multimodal abilities in the previous days are focused on image detection, classification based on well-defined objects. Large language models (LLMs) introduces the transformation from nature language to visual objects, which present the visual layout for text contexts. OpenAI GPT-4 has emerged as the pinnacle in LLMs, while the computer vision (CV) domain boasts a plethora of state-of-the-art (SOTA) models and algorithms to convert 2D images to their 3D representations. However, the mismatching between the algorithms with the problem could lead to undesired results. In response to this challenge, we propose an unified VisionGPT-3D framework to consolidate the state-of-the-art vision models, thereby facilitating the development of vision-oriented AI. VisionGPT-3D provides a versatile multimodal framework building upon the strengths of multimodal foundation models. It seamlessly integrates various SOTA vision models and brings the automation in the selection of SOTA vision models, identifies the suitable 3D mesh creation algorithms corresponding to 2D depth maps analysis, generates optimal results based on diverse multimodal inputs such as text prompts. Keywords: VisionGPT-3D, 3D vision understanding, Multimodal agent
Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring
Mar 14, 2024

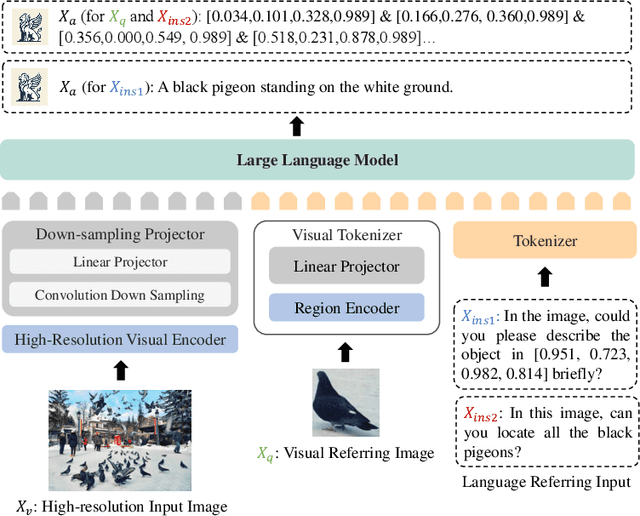
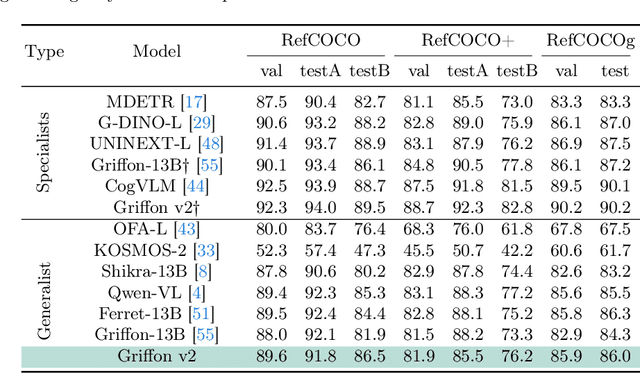
Large Vision Language Models have achieved fine-grained object perception, but the limitation of image resolution remains a significant obstacle to surpass the performance of task-specific experts in complex and dense scenarios. Such limitation further restricts the model's potential to achieve nuanced visual and language referring in domains such as GUI Agents, Counting and \etc. To address this issue, we introduce a unified high-resolution generalist model, Griffon v2, enabling flexible object referring with visual and textual prompts. To efficiently scaling up image resolution, we design a simple and lightweight down-sampling projector to overcome the input tokens constraint in Large Language Models. This design inherently preserves the complete contexts and fine details, and significantly improves multimodal perception ability especially for small objects. Building upon this, we further equip the model with visual-language co-referring capabilities through a plug-and-play visual tokenizer. It enables user-friendly interaction with flexible target images, free-form texts and even coordinates. Experiments demonstrate that Griffon v2 can localize any objects of interest with visual and textual referring, achieve state-of-the-art performance on REC, phrase grounding, and REG tasks, and outperform expert models in object detection and object counting. Data, codes and models will be released at https://github.com/jefferyZhan/Griffon.
VDNA-PR: Using General Dataset Representations for Robust Sequential Visual Place Recognition
Mar 14, 2024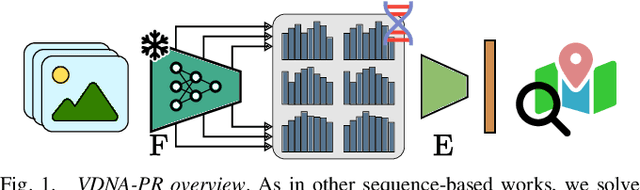
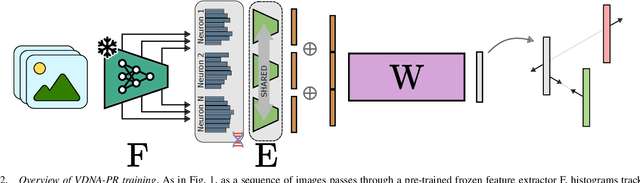

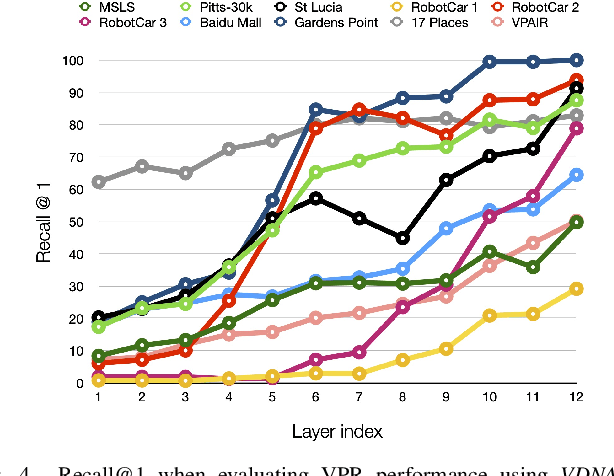
This paper adapts a general dataset representation technique to produce robust Visual Place Recognition (VPR) descriptors, crucial to enable real-world mobile robot localisation. Two parallel lines of work on VPR have shown, on one side, that general-purpose off-the-shelf feature representations can provide robustness to domain shifts, and, on the other, that fused information from sequences of images improves performance. In our recent work on measuring domain gaps between image datasets, we proposed a Visual Distribution of Neuron Activations (VDNA) representation to represent datasets of images. This representation can naturally handle image sequences and provides a general and granular feature representation derived from a general-purpose model. Moreover, our representation is based on tracking neuron activation values over the list of images to represent and is not limited to a particular neural network layer, therefore having access to high- and low-level concepts. This work shows how VDNAs can be used for VPR by learning a very lightweight and simple encoder to generate task-specific descriptors. Our experiments show that our representation can allow for better robustness than current solutions to serious domain shifts away from the training data distribution, such as to indoor environments and aerial imagery.
RSAM-Seg: A SAM-based Approach with Prior Knowledge Integration for Remote Sensing Image Semantic Segmentation
Feb 29, 2024The development of high-resolution remote sensing satellites has provided great convenience for research work related to remote sensing. Segmentation and extraction of specific targets are essential tasks when facing the vast and complex remote sensing images. Recently, the introduction of Segment Anything Model (SAM) provides a universal pre-training model for image segmentation tasks. While the direct application of SAM to remote sensing image segmentation tasks does not yield satisfactory results, we propose RSAM-Seg, which stands for Remote Sensing SAM with Semantic Segmentation, as a tailored modification of SAM for the remote sensing field and eliminates the need for manual intervention to provide prompts. Adapter-Scale, a set of supplementary scaling modules, are proposed in the multi-head attention blocks of the encoder part of SAM. Furthermore, Adapter-Feature are inserted between the Vision Transformer (ViT) blocks. These modules aim to incorporate high-frequency image information and image embedding features to generate image-informed prompts. Experiments are conducted on four distinct remote sensing scenarios, encompassing cloud detection, field monitoring, building detection and road mapping tasks . The experimental results not only showcase the improvement over the original SAM and U-Net across cloud, buildings, fields and roads scenarios, but also highlight the capacity of RSAM-Seg to discern absent areas within the ground truth of certain datasets, affirming its potential as an auxiliary annotation method. In addition, the performance in few-shot scenarios is commendable, underscores its potential in dealing with limited datasets.
Exploiting Structural Consistency of Chest Anatomy for Unsupervised Anomaly Detection in Radiography Images
Mar 13, 2024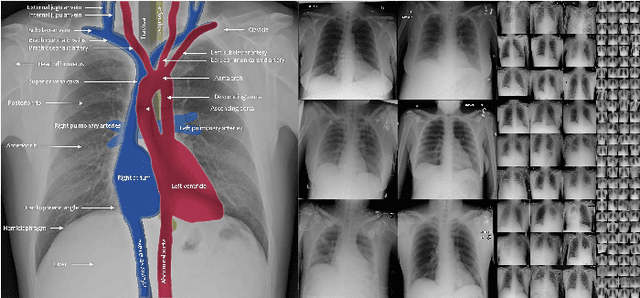
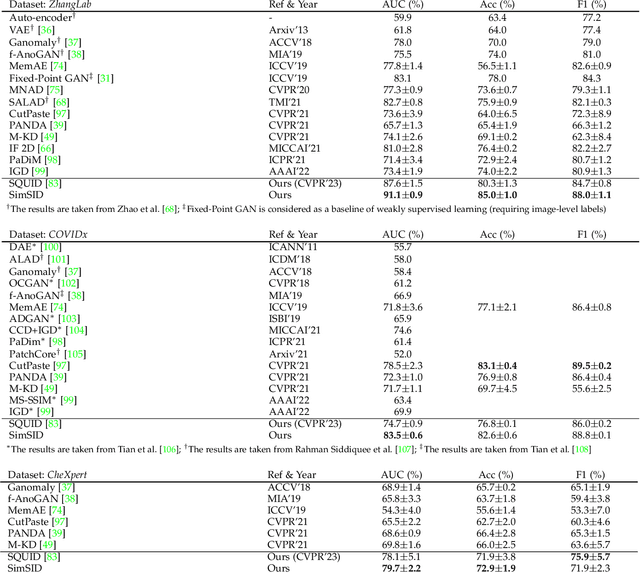
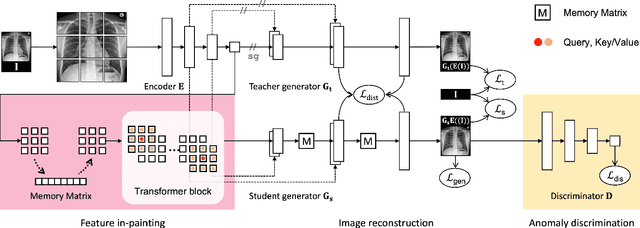
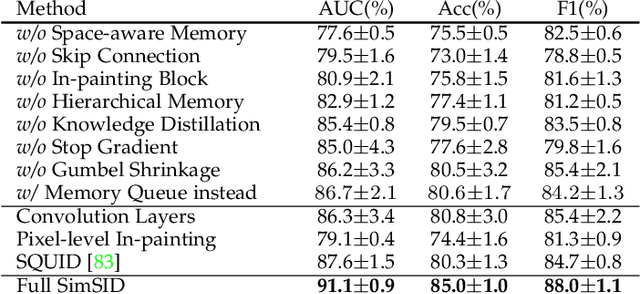
Radiography imaging protocols focus on particular body regions, therefore producing images of great similarity and yielding recurrent anatomical structures across patients. Exploiting this structured information could potentially ease the detection of anomalies from radiography images. To this end, we propose a Simple Space-Aware Memory Matrix for In-painting and Detecting anomalies from radiography images (abbreviated as SimSID). We formulate anomaly detection as an image reconstruction task, consisting of a space-aware memory matrix and an in-painting block in the feature space. During the training, SimSID can taxonomize the ingrained anatomical structures into recurrent visual patterns, and in the inference, it can identify anomalies (unseen/modified visual patterns) from the test image. Our SimSID surpasses the state of the arts in unsupervised anomaly detection by +8.0%, +5.0%, and +9.9% AUC scores on ZhangLab, COVIDx, and CheXpert benchmark datasets, respectively. Code: https://github.com/MrGiovanni/SimSID
DuPL: Dual Student with Trustworthy Progressive Learning for Robust Weakly Supervised Semantic Segmentation
Mar 17, 2024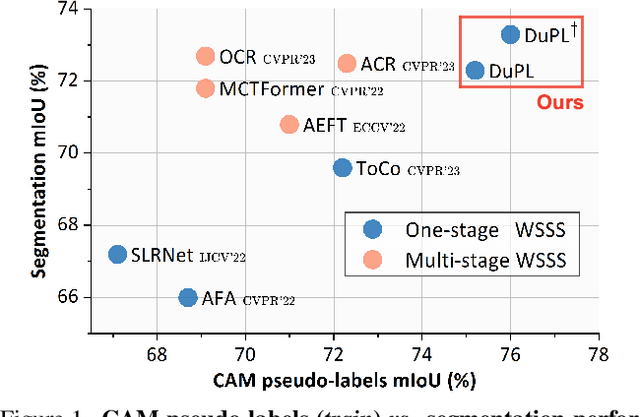
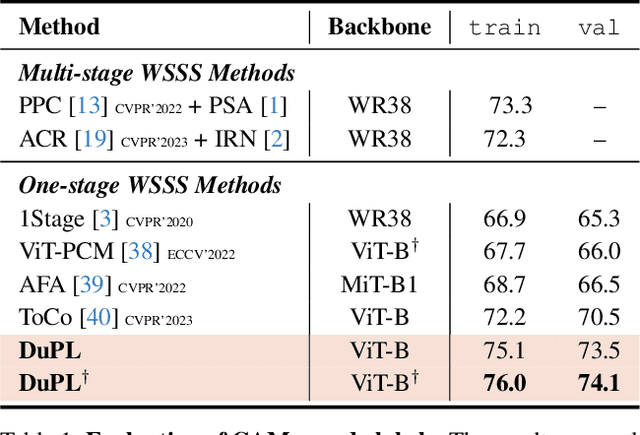
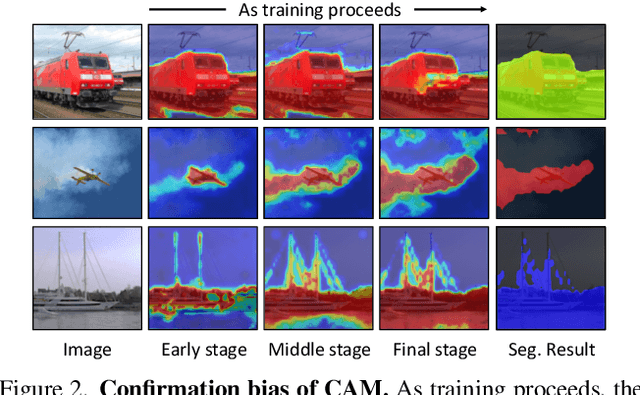
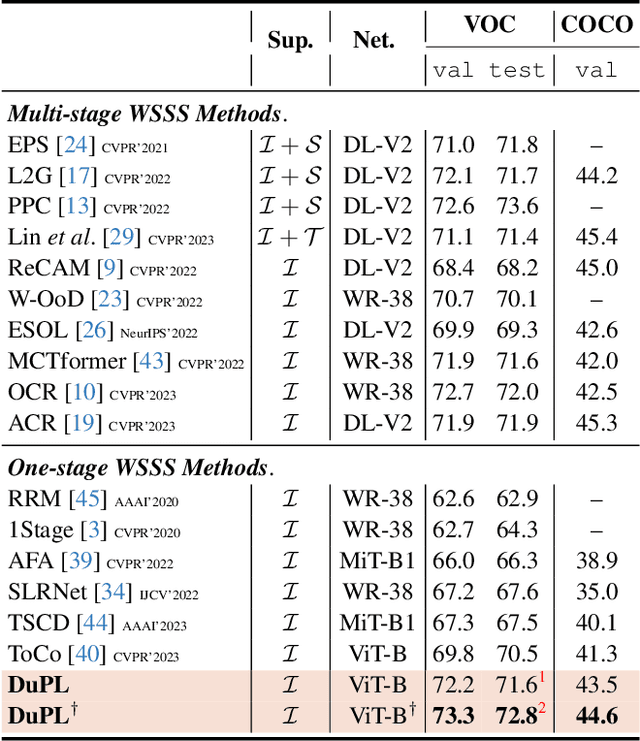
Recently, One-stage Weakly Supervised Semantic Segmentation (WSSS) with image-level labels has gained increasing interest due to simplification over its cumbersome multi-stage counterpart. Limited by the inherent ambiguity of Class Activation Map (CAM), we observe that one-stage pipelines often encounter confirmation bias caused by incorrect CAM pseudo-labels, impairing their final segmentation performance. Although recent works discard many unreliable pseudo-labels to implicitly alleviate this issue, they fail to exploit sufficient supervision for their models. To this end, we propose a dual student framework with trustworthy progressive learning (DuPL). Specifically, we propose a dual student network with a discrepancy loss to yield diverse CAMs for each sub-net. The two sub-nets generate supervision for each other, mitigating the confirmation bias caused by learning their own incorrect pseudo-labels. In this process, we progressively introduce more trustworthy pseudo-labels to be involved in the supervision through dynamic threshold adjustment with an adaptive noise filtering strategy. Moreover, we believe that every pixel, even discarded from supervision due to its unreliability, is important for WSSS. Thus, we develop consistency regularization on these discarded regions, providing supervision of every pixel. Experiment results demonstrate the superiority of the proposed DuPL over the recent state-of-the-art alternatives on PASCAL VOC 2012 and MS COCO datasets. Code is available at https://github.com/Wu0409/DuPL.
Training A Small Emotional Vision Language Model for Visual Art Comprehension
Mar 17, 2024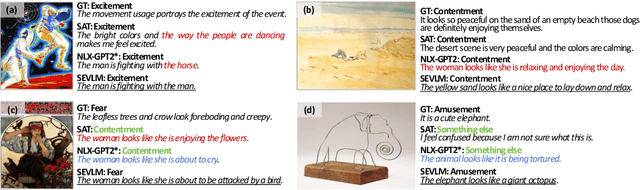
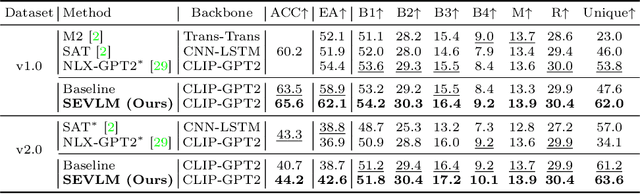
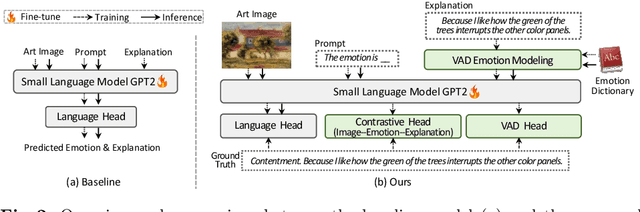

This paper develops small vision language models to understand visual art, which, given an art work, aims to identify its emotion category and explain this prediction with natural language. While small models are computationally efficient, their capacity is much limited compared with large models. To break this trade-off, this paper builds a small emotional vision language model (SEVLM) by emotion modeling and input-output feature alignment. On the one hand, based on valence-arousal-dominance (VAD) knowledge annotated by psychology experts, we introduce and fuse emotional features derived through VAD dictionary and a VAD head to align VAD vectors of predicted emotion explanation and the ground truth. This allows the vision language model to better understand and generate emotional texts, compared with using traditional text embeddings alone. On the other hand, we design a contrastive head to pull close embeddings of the image, its emotion class, and explanation, which aligns model outputs and inputs. On two public affective explanation datasets, we show that the proposed techniques consistently improve the visual art understanding performance of baseline SEVLMs. Importantly, the proposed model can be trained and evaluated on a single RTX 2080 Ti while exhibiting very strong performance: it not only outperforms the state-of-the-art small models but is also competitive compared with LLaVA 7B after fine-tuning and GPT4(V).