 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Transfer Learning with Kernel Methods
Nov 01, 2022
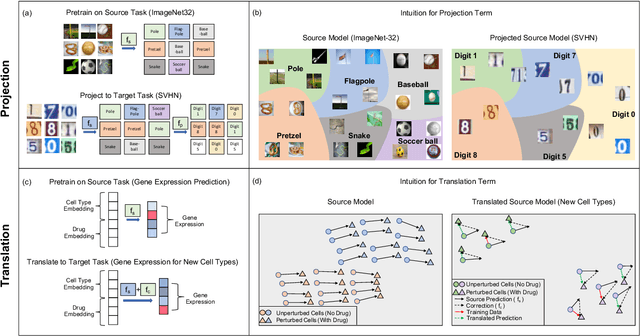
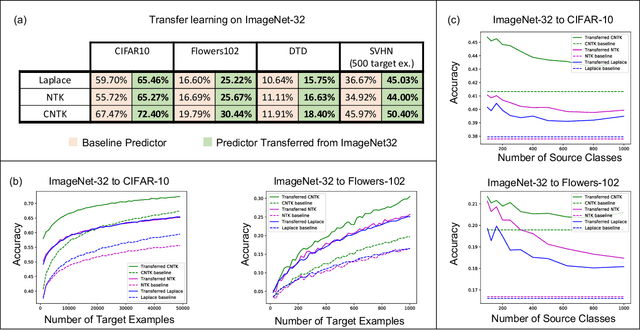
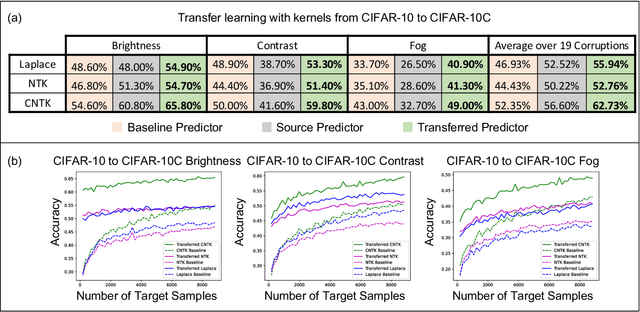
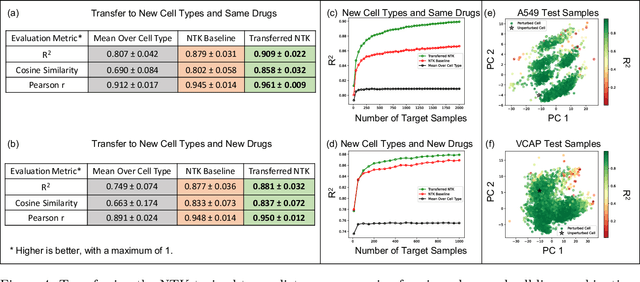
Transfer learning refers to the process of adapting a model trained on a source task to a target task. While kernel methods are conceptually and computationally simple machine learning models that are competitive on a variety of tasks, it has been unclear how to perform transfer learning for kernel methods. In this work, we propose a transfer learning framework for kernel methods by projecting and translating the source model to the target task. We demonstrate the effectiveness of our framework in applications to image classification and virtual drug screening. In particular, we show that transferring modern kernels trained on large-scale image datasets can result in substantial performance increase as compared to using the same kernel trained directly on the target task. In addition, we show that transfer-learned kernels allow a more accurate prediction of the effect of drugs on cancer cell lines. For both applications, we identify simple scaling laws that characterize the performance of transfer-learned kernels as a function of the number of target examples. We explain this phenomenon in a simplified linear setting, where we are able to derive the exact scaling laws. By providing a simple and effective transfer learning framework for kernel methods, our work enables kernel methods trained on large datasets to be easily adapted to a variety of downstream target tasks.
Hospital-Agnostic Image Representation Learning in Digital Pathology
Apr 05, 2022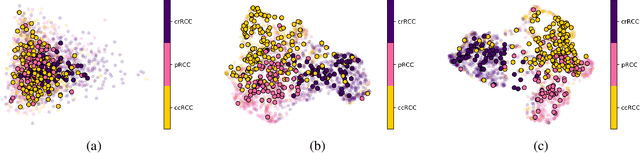

Whole Slide Images (WSIs) in digital pathology are used to diagnose cancer subtypes. The difference in procedures to acquire WSIs at various trial sites gives rise to variability in the histopathology images, thus making consistent diagnosis challenging. These differences may stem from variability in image acquisition through multi-vendor scanners, variable acquisition parameters, and differences in staining procedure; as well, patient demographics may bias the glass slide batches before image acquisition. These variabilities are assumed to cause a domain shift in the images of different hospitals. It is crucial to overcome this domain shift because an ideal machine-learning model must be able to work on the diverse sources of images, independent of the acquisition center. A domain generalization technique is leveraged in this study to improve the generalization capability of a Deep Neural Network (DNN), to an unseen histopathology image set (i.e., from an unseen hospital/trial site) in the presence of domain shift. According to experimental results, the conventional supervised-learning regime generalizes poorly to data collected from different hospitals. However, the proposed hospital-agnostic learning can improve the generalization considering the low-dimensional latent space representation visualization, and classification accuracy results.
ReFace: Improving Clothes-Changing Re-Identification With Face Features
Nov 24, 2022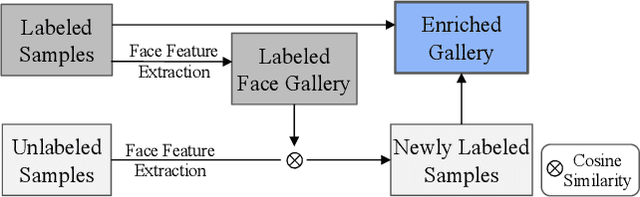
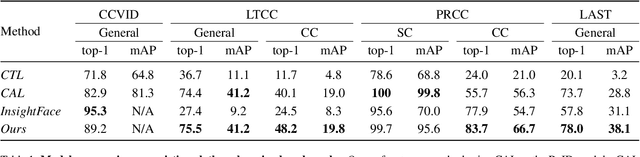
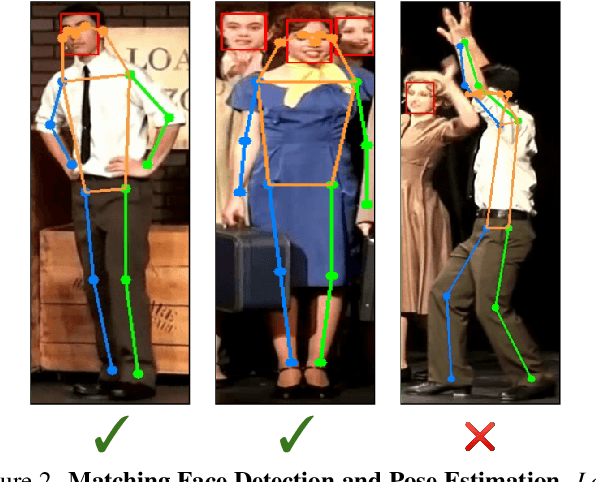
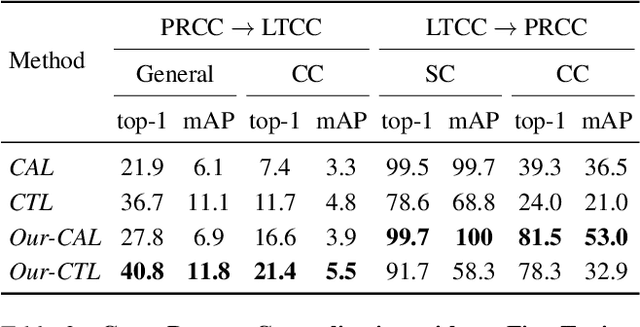
Person re-identification (ReID) has been an active research field for many years. Despite that, models addressing this problem tend to perform poorly when the task is to re-identify the same people over a prolonged time, due to appearance changes such as different clothes and hairstyles. In this work, we introduce a new method that takes full advantage of the ability of existing ReID models to extract appearance-related features and combines it with a face feature extraction model to achieve new state-of-the-art results, both on image-based and video-based benchmarks. Moreover, we show how our method could be used for an application in which multiple people of interest, under clothes-changing settings, should be re-identified given an unseen video and a limited amount of labeled data. We claim that current ReID benchmarks do not represent such real-world scenarios, and publish a new dataset, 42Street, based on a theater play as an example of such an application. We show that our proposed method outperforms existing models also on this dataset while using only pre-trained modules and without any further training.
Image Retrieval from Contextual Descriptions
Mar 29, 2022


The ability to integrate context, including perceptual and temporal cues, plays a pivotal role in grounding the meaning of a linguistic utterance. In order to measure to what extent current vision-and-language models master this ability, we devise a new multimodal challenge, Image Retrieval from Contextual Descriptions (ImageCoDe). In particular, models are tasked with retrieving the correct image from a set of 10 minimally contrastive candidates based on a contextual description. As such, each description contains only the details that help distinguish between images. Because of this, descriptions tend to be complex in terms of syntax and discourse and require drawing pragmatic inferences. Images are sourced from both static pictures and video frames. We benchmark several state-of-the-art models, including both cross-encoders such as ViLBERT and bi-encoders such as CLIP, on ImageCoDe. Our results reveal that these models dramatically lag behind human performance: the best variant achieves an accuracy of 20.9 on video frames and 59.4 on static pictures, compared with 90.8 in humans. Furthermore, we experiment with new model variants that are better equipped to incorporate visual and temporal context into their representations, which achieve modest gains. Our hope is that ImageCoDE will foster progress in grounded language understanding by encouraging models to focus on fine-grained visual differences.
Parallel Inversion of Neural Radiance Fields for Robust Pose Estimation
Oct 18, 2022

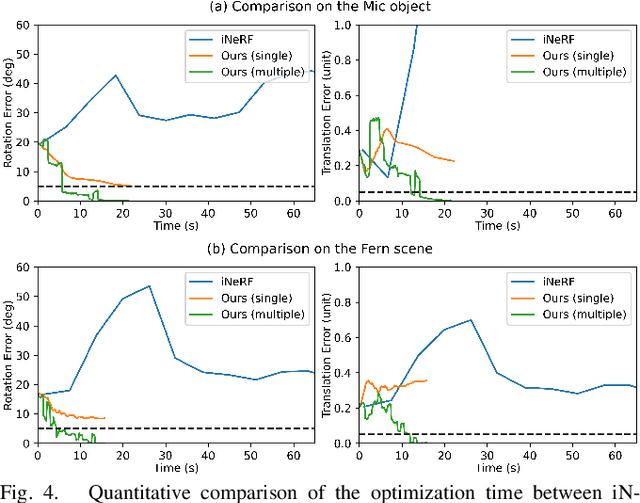

We present a parallelized optimization method based on fast Neural Radiance Fields (NeRF) for estimating 6-DoF target poses. Given a single observed RGB image of the target, we can predict the translation and rotation of the camera by minimizing the residual between pixels rendered from a fast NeRF model and pixels in the observed image. We integrate a momentum-based camera extrinsic optimization procedure into Instant Neural Graphics Primitives, a recent exceptionally fast NeRF implementation. By introducing parallel Monte Carlo sampling into the pose estimation task, our method overcomes local minima and improves efficiency in a more extensive search space. We also show the importance of adopting a more robust pixel-based loss function to reduce error. Experiments demonstrate that our method can achieve improved generalization and robustness on both synthetic and real-world benchmarks.
Very Low-Resolution Iris Recognition Via Eigen-Patch Super-Resolution and Matcher Fusion
Oct 18, 2022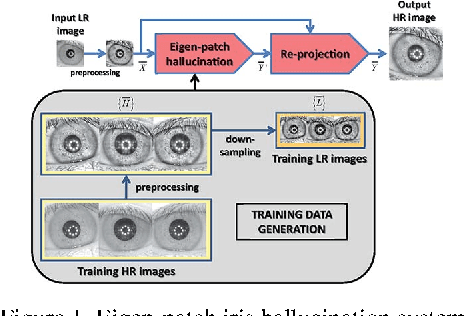
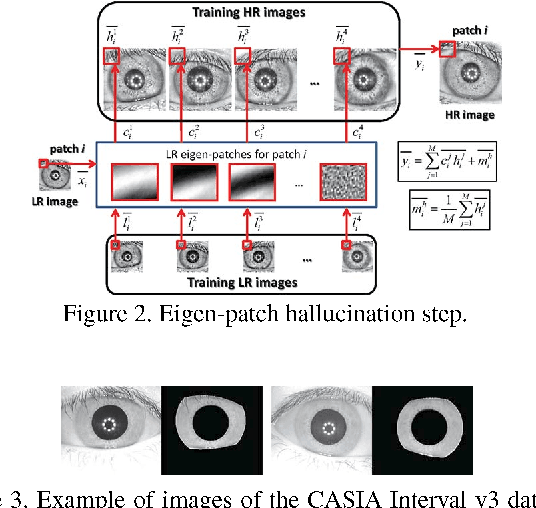
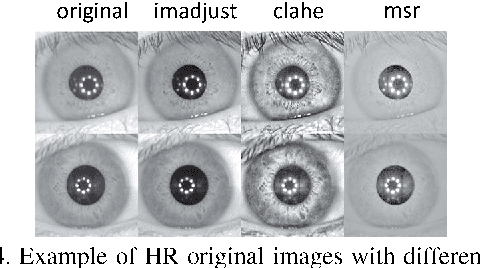
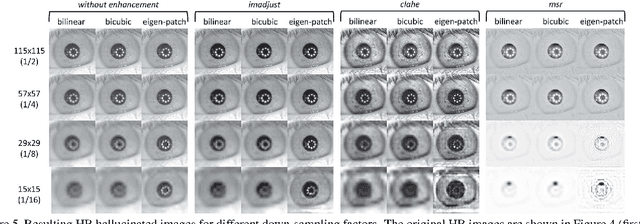
Current research in iris recognition is moving towards enabling more relaxed acquisition conditions. This has effects on the quality of acquired images, with low resolution being a predominant issue. Here, we evaluate a super-resolution algorithm used to reconstruct iris images based on Eigen-transformation of local image patches. Each patch is reconstructed separately, allowing better quality of enhanced images by preserving local information. Contrast enhancement is used to improve the reconstruction quality, while matcher fusion has been adopted to improve iris recognition performance. We validate the system using a database of 1,872 near-infrared iris images. The presented approach is superior to bilinear or bicubic interpolation, especially at lower resolutions, and the fusion of the two systems pushes the EER to below 5% for down-sampling factors up to a image size of only 13x13.
Provably Learning Diverse Features in Multi-View Data with Midpoint Mixup
Oct 24, 2022
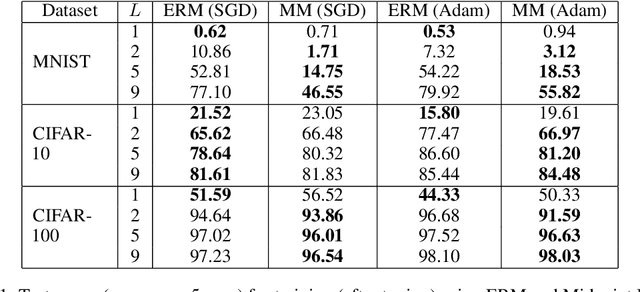
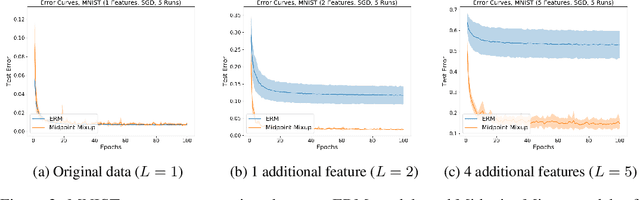
Mixup is a data augmentation technique that relies on training using random convex combinations of data points and their labels. In recent years, Mixup has become a standard primitive used in the training of state-of-the-art image classification models due to its demonstrated benefits over empirical risk minimization with regards to generalization and robustness. In this work, we try to explain some of this success from a feature learning perspective. We focus our attention on classification problems in which each class may have multiple associated features (or views) that can be used to predict the class correctly. Our main theoretical results demonstrate that, for a non-trivial class of data distributions with two features per class, training a 2-layer convolutional network using empirical risk minimization can lead to learning only one feature for almost all classes while training with a specific instantiation of Mixup succeeds in learning both features for every class. We also show empirically that these theoretical insights extend to the practical settings of image benchmarks modified to have additional synthetic features.
Stripformer: Strip Transformer for Fast Image Deblurring
Apr 10, 2022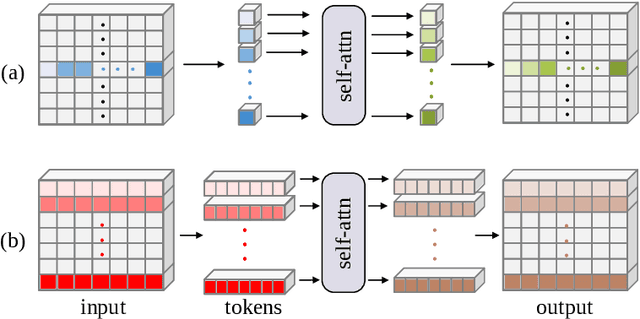
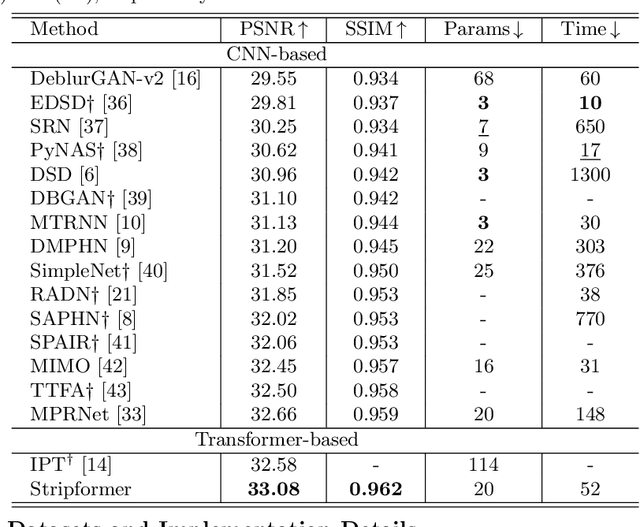
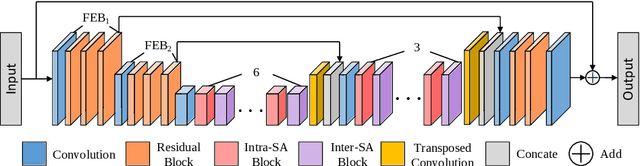
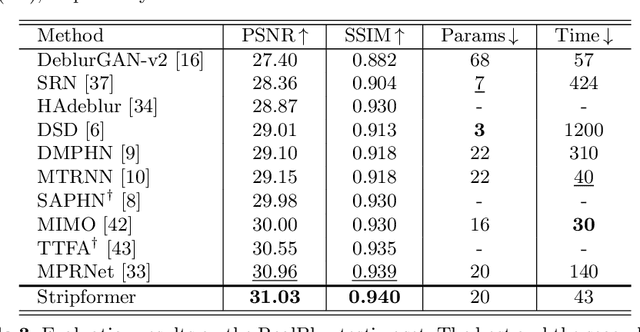
Images taken in dynamic scenes may contain unwanted motion blur, which significantly degrades visual quality. Such blur causes short- and long-range region-specific smoothing artifacts that are often directional and non-uniform, which is difficult to be removed. Inspired by the current success of transformers on computer vision and image processing tasks, we develop, Stripformer, a transformer-based architecture that constructs intra- and inter-strip tokens to reweight image features in the horizontal and vertical directions to catch blurred patterns with different orientations. It stacks interlaced intra-strip and inter-strip attention layers to reveal blur magnitudes. In addition to detecting region-specific blurred patterns of various orientations and magnitudes, Stripformer is also a token-efficient and parameter-efficient transformer model, demanding much less memory usage and computation cost than the vanilla transformer but works better without relying on tremendous training data. Experimental results show that Stripformer performs favorably against state-of-the-art models in dynamic scene deblurring.
Unsupervised Cross-Domain Feature Extraction for Single Blood Cell Image Classification
Jul 01, 2022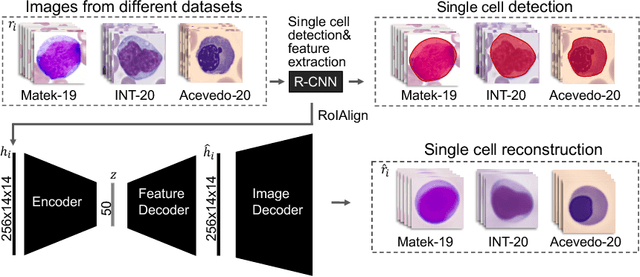
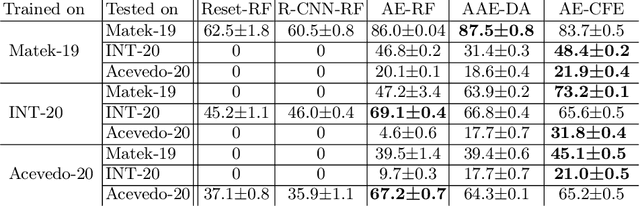
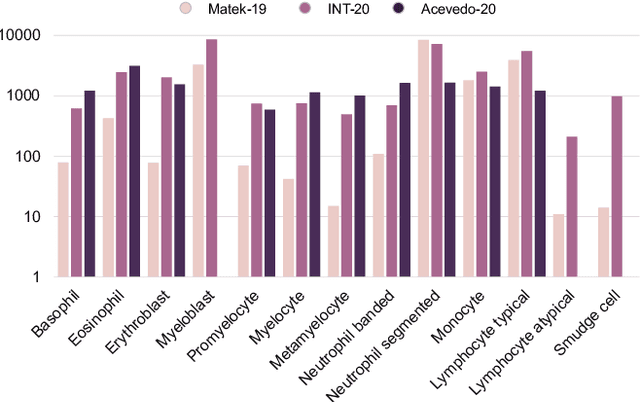
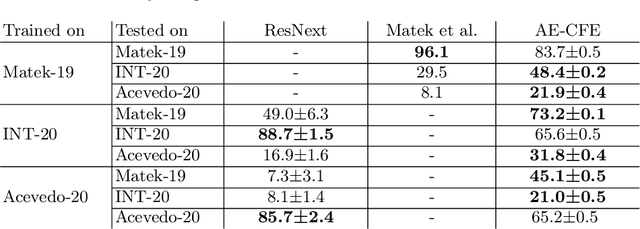
Diagnosing hematological malignancies requires identification and classification of white blood cells in peripheral blood smears. Domain shifts caused by different lab procedures, staining, illumination, and microscope settings hamper the re-usability of recently developed machine learning methods on data collected from different sites. Here, we propose a cross-domain adapted autoencoder to extract features in an unsupervised manner on three different datasets of single white blood cells scanned from peripheral blood smears. The autoencoder is based on an R-CNN architecture allowing it to focus on the relevant white blood cell and eliminate artifacts in the image. To evaluate the quality of the extracted features we use a simple random forest to classify single cells. We show that thanks to the rich features extracted by the autoencoder trained on only one of the datasets, the random forest classifier performs satisfactorily on the unseen datasets, and outperforms published oracle networks in the cross-domain task. Our results suggest the possibility of employing this unsupervised approach in more complicated diagnosis and prognosis tasks without the need to add expensive expert labels to unseen data.
Multilingual and Multimodal Topic Modelling with Pretrained Embeddings
Nov 15, 2022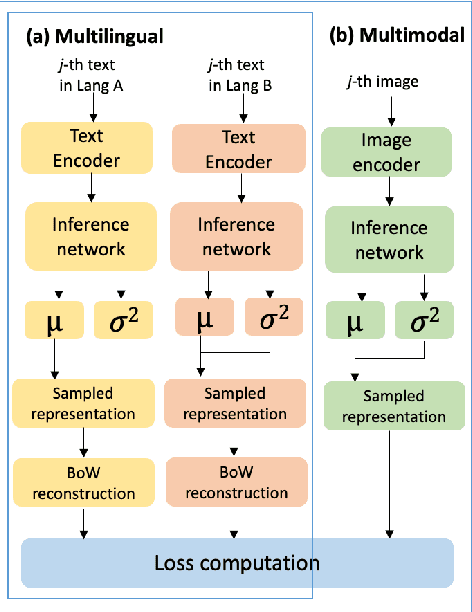
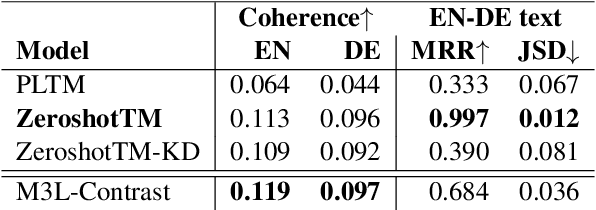
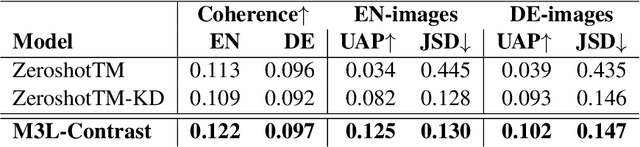
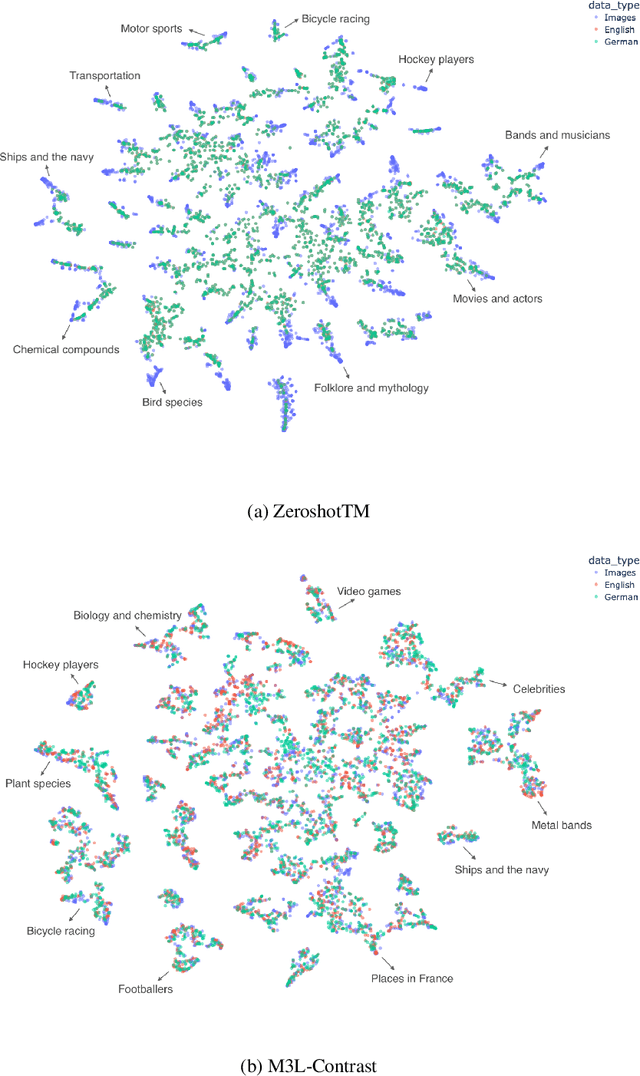
This paper presents M3L-Contrast -- a novel multimodal multilingual (M3L) neural topic model for comparable data that maps texts from multiple languages and images into a shared topic space. Our model is trained jointly on texts and images and takes advantage of pretrained document and image embeddings to abstract the complexities between different languages and modalities. As a multilingual topic model, it produces aligned language-specific topics and as multimodal model, it infers textual representations of semantic concepts in images. We demonstrate that our model is competitive with a zero-shot topic model in predicting topic distributions for comparable multilingual data and significantly outperforms a zero-shot model in predicting topic distributions for comparable texts and images. We also show that our model performs almost as well on unaligned embeddings as it does on aligned embeddings.