 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
High-resolution and reliable automatic target recognition based on photonic ISAR imaging system with explainable deep learning
Dec 03, 2022
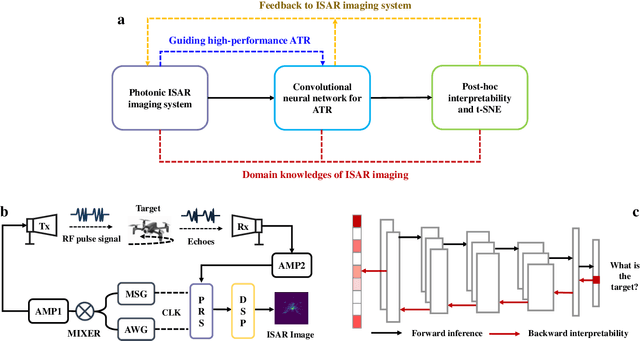
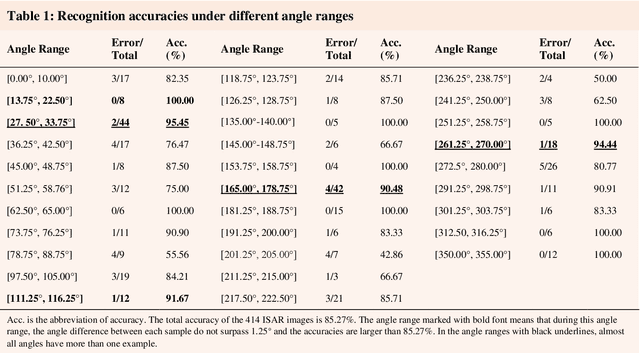

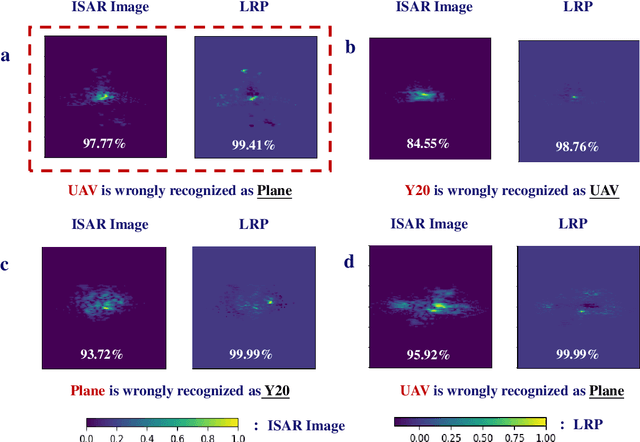
Automatic target recognition (ATR) based on inverse synthetic aperture radar (ISAR) images, which is extensively utilized to surveil environment in military and civil fields, must be high-precision and reliable. Photonic technologies' advantage of broad bandwidth enables ISAR systems to realize high-resolution imaging, which is in favor of achieving high-performance ATR. Deep learning (DL) algorithms have achieved excellent recognition accuracies. However, the lack of interpretability of DL algorithms causes the head-scratching problem of credibility. In this paper, we exploit the inner relationship between a photonic ISAR imaging system and behaviors of a convolutional neural network (CNN) to deeply comprehend the intelligent recognition. Specifically, we manipulate imaging physical process and analyze network outputs, the relevance between the ISAR image and network output, and the visualization of features in the network output layer. Consequently, the broader imaging bandwidths and appropriate imaging angles lead to more detailed structural and contour features and the bigger discrepancy among ISAR images of different targets, which contributes to the CNN recognizing and distinguishing objects according to physical laws. Then, based on the photonic ISAR imaging system and the explainable CNN, we accomplish a high-accuracy and reliable ATR. To the best of our knowledge, there is no precedent of explaining the DL algorithms by exploring the influence of the physical process of data generation on network behaviors. It is anticipated that this work can not only inspire the accomplishment of a high-performance ATR but also bring new insights to explore network behaviors and thus achieve better intelligent abilities.
Understanding the Robustness of Multi-Exit Models under Common Corruptions
Dec 03, 2022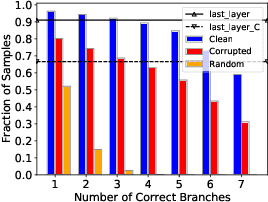
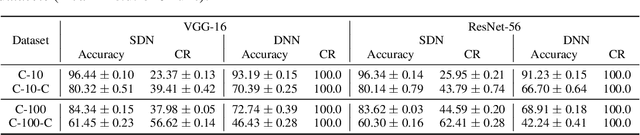
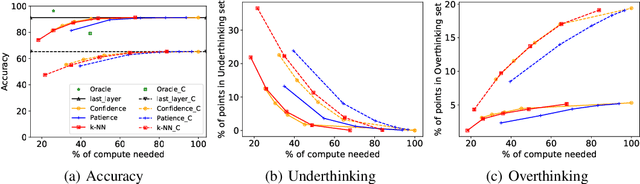
Multi-Exit models (MEMs) use an early-exit strategy to improve the accuracy and efficiency of deep neural networks (DNNs) by allowing samples to exit the network before the last layer. However, the effectiveness of MEMs in the presence of distribution shifts remains largely unexplored. Our work examines how distribution shifts generated by common image corruptions affect the accuracy/efficiency of MEMs. We find that under common corruptions, early-exiting at the first correct exit reduces the inference cost and provides a significant boost in accuracy ( 10%) over exiting at the last layer. However, with realistic early-exit strategies, which do not assume knowledge about the correct exits, MEMs still reduce inference cost but provide a marginal improvement in accuracy (1%) compared to exiting at the last layer. Moreover, the presence of distribution shift widens the gap between an MEM's maximum classification accuracy and realistic early-exit strategies by 5% on average compared with the gap on in-distribution data. Our empirical analysis shows that the lack of calibration due to a distribution shift increases the susceptibility of such early-exit strategies to exit early and increases misclassification rates. Furthermore, the lack of calibration increases the inconsistency in the predictions of the model across exits, leading to both inefficient inference and more misclassifications compared with evaluation on in-distribution data. Finally, we propose two metrics, underthinking and overthinking, that quantify the different behavior of practical early-exit strategy under distribution shifts, and provide insights into improving the practical utility of MEMs.
Background-Mixed Augmentation for Weakly Supervised Change Detection
Dec 01, 2022
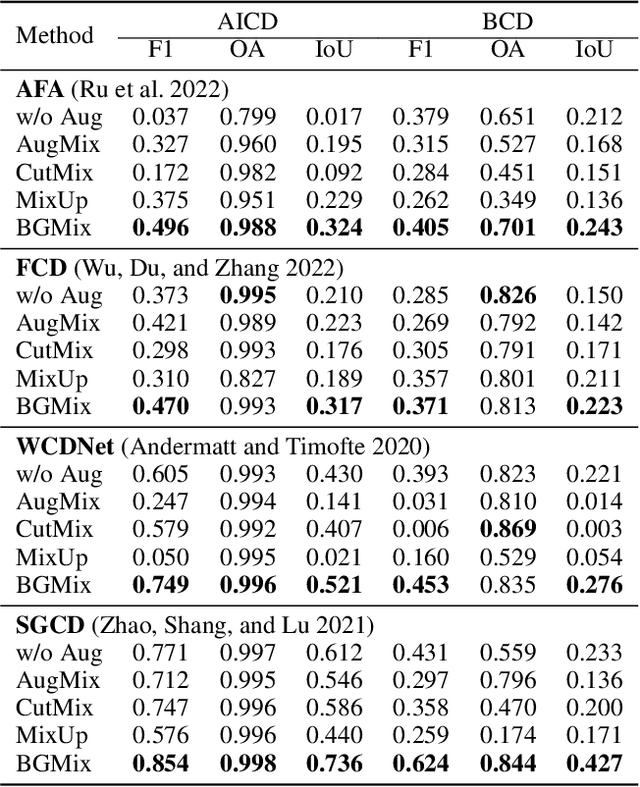

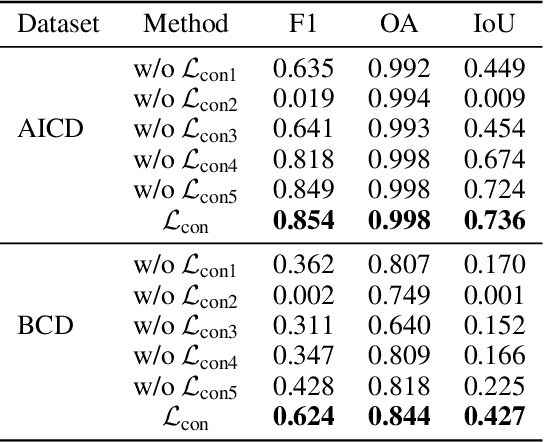
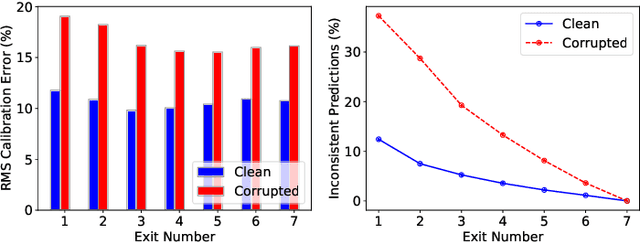
Change detection (CD) is to decouple object changes (i.e., object missing or appearing) from background changes (i.e., environment variations) like light and season variations in two images captured in the same scene over a long time span, presenting critical applications in disaster management, urban development, etc. In particular, the endless patterns of background changes require detectors to have a high generalization against unseen environment variations, making this task significantly challenging. Recent deep learning-based methods develop novel network architectures or optimization strategies with paired-training examples, which do not handle the generalization issue explicitly and require huge manual pixel-level annotation efforts. In this work, for the first attempt in the CD community, we study the generalization issue of CD from the perspective of data augmentation and develop a novel weakly supervised training algorithm that only needs image-level labels. Different from general augmentation techniques for classification, we propose the background-mixed augmentation that is specifically designed for change detection by augmenting examples under the guidance of a set of background-changing images and letting deep CD models see diverse environment variations. Moreover, we propose the augmented & real data consistency loss that encourages the generalization increase significantly. Our method as a general framework can enhance a wide range of existing deep learning-based detectors. We conduct extensive experiments in two public datasets and enhance four state-of-the-art methods, demonstrating the advantages of our method. We release the code at https://github.com/tsingqguo/bgmix.
Differentiable Fuzzy $\mathcal{ALC}$: A Neural-Symbolic Representation Language for Symbol Grounding
Dec 01, 2022
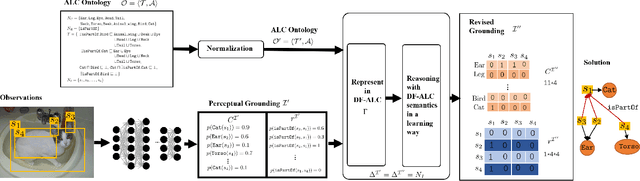


Neural-symbolic computing aims at integrating robust neural learning and sound symbolic reasoning into a single framework, so as to leverage the complementary strengths of both of these, seemingly unrelated (maybe even contradictory) AI paradigms. The central challenge in neural-symbolic computing is to unify the formulation of neural learning and symbolic reasoning into a single framework with common semantics, that is, to seek a joint representation between a neural model and a logical theory that can support the basic grounding learned by the neural model and also stick to the semantics of the logical theory. In this paper, we propose differentiable fuzzy $\mathcal{ALC}$ (DF-$\mathcal{ALC}$) for this role, as a neural-symbolic representation language with the desired semantics. DF-$\mathcal{ALC}$ unifies the description logic $\mathcal{ALC}$ and neural models for symbol grounding; in particular, it infuses an $\mathcal{ALC}$ knowledge base into neural models through differentiable concept and role embeddings. We define a hierarchical loss to the constraint that the grounding learned by neural models must be semantically consistent with $\mathcal{ALC}$ knowledge bases. And we find that capturing the semantics in grounding solely by maximizing satisfiability cannot revise grounding rationally. We further define a rule-based loss for DF adapting to symbol grounding problems. The experiment results show that DF-$\mathcal{ALC}$ with rule-based loss can improve the performance of image object detectors in an unsupervised learning way, even in low-resource situations.
BEV-LGKD: A Unified LiDAR-Guided Knowledge Distillation Framework for BEV 3D Object Detection
Dec 01, 2022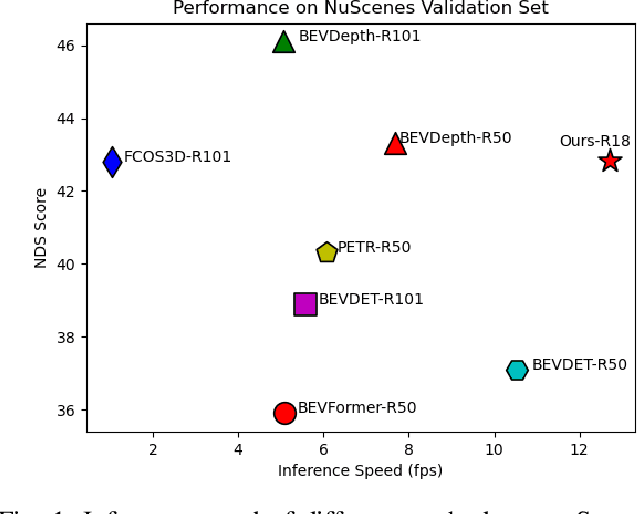
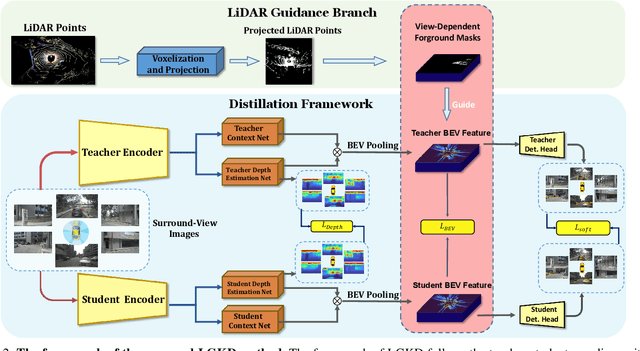
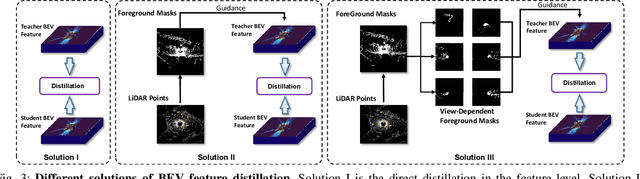
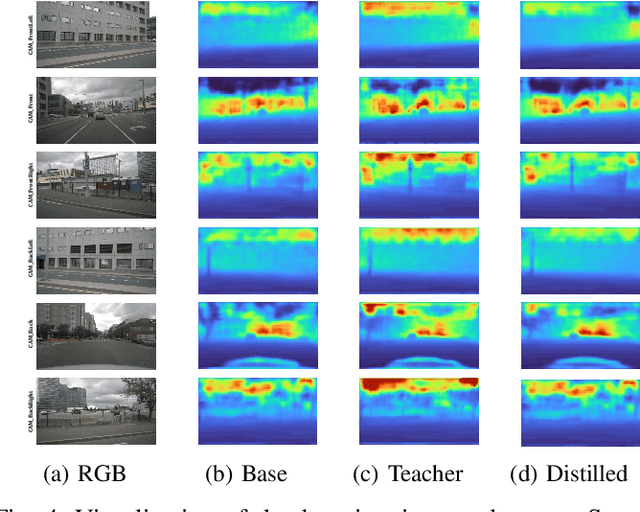
Recently, Bird's-Eye-View (BEV) representation has gained increasing attention in multi-view 3D object detection, which has demonstrated promising applications in autonomous driving. Although multi-view camera systems can be deployed at low cost, the lack of depth information makes current approaches adopt large models for good performance. Therefore, it is essential to improve the efficiency of BEV 3D object detection. Knowledge Distillation (KD) is one of the most practical techniques to train efficient yet accurate models. However, BEV KD is still under-explored to the best of our knowledge. Different from image classification tasks, BEV 3D object detection approaches are more complicated and consist of several components. In this paper, we propose a unified framework named BEV-LGKD to transfer the knowledge in the teacher-student manner. However, directly applying the teacher-student paradigm to BEV features fails to achieve satisfying results due to heavy background information in RGB cameras. To solve this problem, we propose to leverage the localization advantage of LiDAR points. Specifically, we transform the LiDAR points to BEV space and generate the foreground mask and view-dependent mask for the teacher-student paradigm. It is to be noted that our method only uses LiDAR points to guide the KD between RGB models. As the quality of depth estimation is crucial for BEV perception, we further introduce depth distillation to our framework. Our unified framework is simple yet effective and achieves a significant performance boost. Code will be released.
Experimental Observations of the Topology of Convolutional Neural Network Activations
Dec 01, 2022
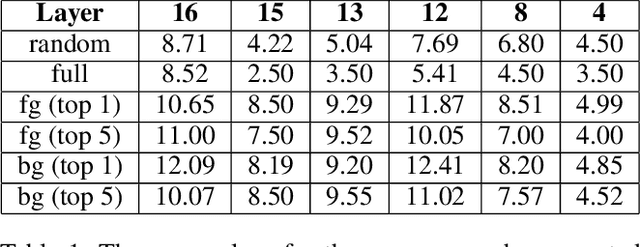
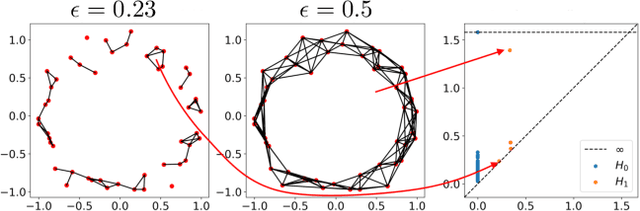
Topological data analysis (TDA) is a branch of computational mathematics, bridging algebraic topology and data science, that provides compact, noise-robust representations of complex structures. Deep neural networks (DNNs) learn millions of parameters associated with a series of transformations defined by the model architecture, resulting in high-dimensional, difficult-to-interpret internal representations of input data. As DNNs become more ubiquitous across multiple sectors of our society, there is increasing recognition that mathematical methods are needed to aid analysts, researchers, and practitioners in understanding and interpreting how these models' internal representations relate to the final classification. In this paper, we apply cutting edge techniques from TDA with the goal of gaining insight into the interpretability of convolutional neural networks used for image classification. We use two common TDA approaches to explore several methods for modeling hidden-layer activations as high-dimensional point clouds, and provide experimental evidence that these point clouds capture valuable structural information about the model's process. First, we demonstrate that a distance metric based on persistent homology can be used to quantify meaningful differences between layers, and we discuss these distances in the broader context of existing representational similarity metrics for neural network interpretability. Second, we show that a mapper graph can provide semantic insight into how these models organize hierarchical class knowledge at each layer. These observations demonstrate that TDA is a useful tool to help deep learning practitioners unlock the hidden structures of their models.
Visual Semantic Parsing: From Images to Abstract Meaning Representation
Oct 27, 2022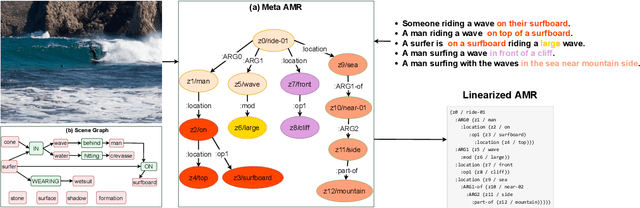
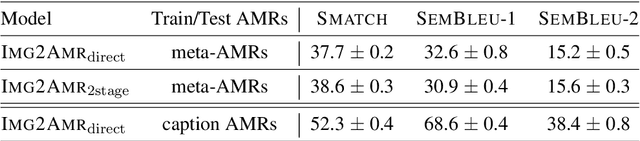

The success of scene graphs for visual scene understanding has brought attention to the benefits of abstracting a visual input (e.g., image) into a structured representation, where entities (people and objects) are nodes connected by edges specifying their relations. Building these representations, however, requires expensive manual annotation in the form of images paired with their scene graphs or frames. These formalisms remain limited in the nature of entities and relations they can capture. In this paper, we propose to leverage a widely-used meaning representation in the field of natural language processing, the Abstract Meaning Representation (AMR), to address these shortcomings. Compared to scene graphs, which largely emphasize spatial relationships, our visual AMR graphs are more linguistically informed, with a focus on higher-level semantic concepts extrapolated from visual input. Moreover, they allow us to generate meta-AMR graphs to unify information contained in multiple image descriptions under one representation. Through extensive experimentation and analysis, we demonstrate that we can re-purpose an existing text-to-AMR parser to parse images into AMRs. Our findings point to important future research directions for improved scene understanding.
Boosting Point Clouds Rendering via Radiance Mapping
Oct 27, 2022



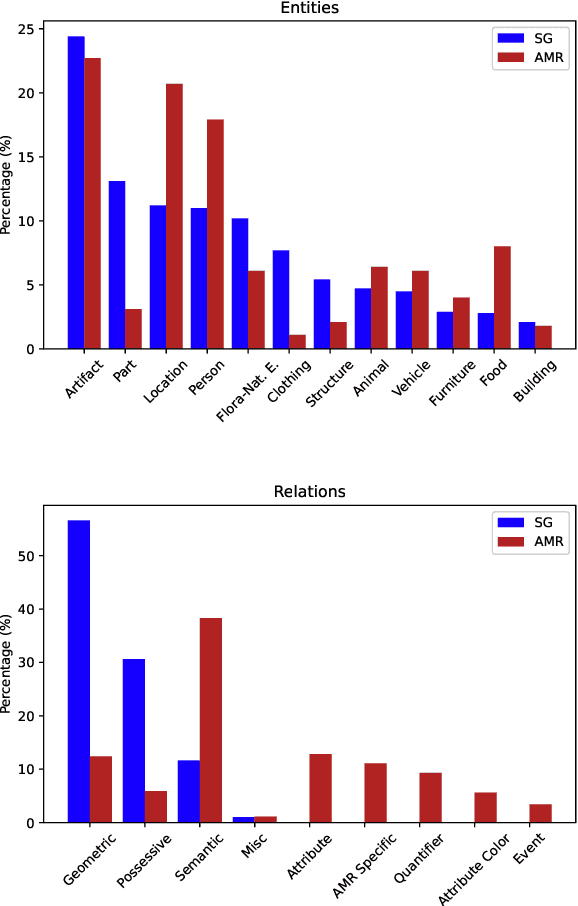
Recent years we have witnessed rapid development in NeRF-based image rendering due to its high quality. However, point clouds rendering is somehow less explored. Compared to NeRF-based rendering which suffers from dense spatial sampling, point clouds rendering is naturally less computation intensive, which enables its deployment in mobile computing device. In this work, we focus on boosting the image quality of point clouds rendering with a compact model design. We first analyze the adaption of the volume rendering formulation on point clouds. Based on the analysis, we simplify the NeRF representation to a spatial mapping function which only requires single evaluation per pixel. Further, motivated by ray marching, we rectify the the noisy raw point clouds to the estimated intersection between rays and surfaces as queried coordinates, which could avoid spatial frequency collapse and neighbor point disturbance. Composed of rasterization, spatial mapping and the refinement stages, our method achieves the state-of-the-art performance on point clouds rendering, outperforming prior works by notable margins, with a smaller model size. We obtain a PSNR of 31.74 on NeRF-Synthetic, 25.88 on ScanNet and 30.81 on DTU. Code and data would be released soon.
MSF3DDETR: Multi-Sensor Fusion 3D Detection Transformer for Autonomous Driving
Oct 27, 2022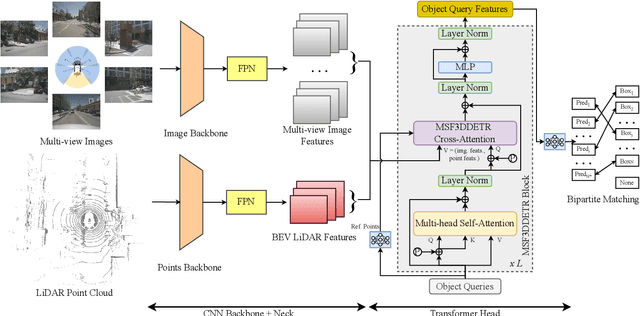
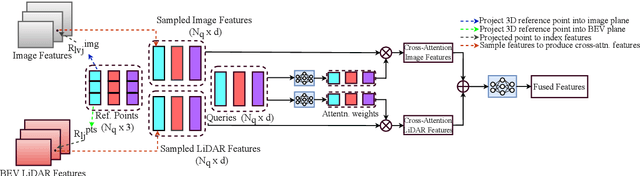

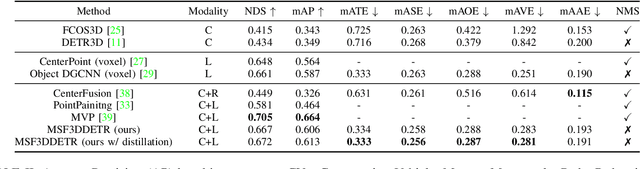
3D object detection is a significant task for autonomous driving. Recently with the progress of vision transformers, the 2D object detection problem is being treated with the set-to-set loss. Inspired by these approaches on 2D object detection and an approach for multi-view 3D object detection DETR3D, we propose MSF3DDETR: Multi-Sensor Fusion 3D Detection Transformer architecture to fuse image and LiDAR features to improve the detection accuracy. Our end-to-end single-stage, anchor-free and NMS-free network takes in multi-view images and LiDAR point clouds and predicts 3D bounding boxes. Firstly, we link the object queries learnt from data to the image and LiDAR features using a novel MSF3DDETR cross-attention block. Secondly, the object queries interacts with each other in multi-head self-attention block. Finally, MSF3DDETR block is repeated for $L$ number of times to refine the object queries. The MSF3DDETR network is trained end-to-end on the nuScenes dataset using Hungarian algorithm based bipartite matching and set-to-set loss inspired by DETR. We present both quantitative and qualitative results which are competitive to the state-of-the-art approaches.
Hospital-Agnostic Image Representation Learning in Digital Pathology
Apr 05, 2022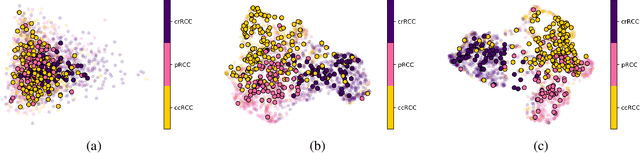

Whole Slide Images (WSIs) in digital pathology are used to diagnose cancer subtypes. The difference in procedures to acquire WSIs at various trial sites gives rise to variability in the histopathology images, thus making consistent diagnosis challenging. These differences may stem from variability in image acquisition through multi-vendor scanners, variable acquisition parameters, and differences in staining procedure; as well, patient demographics may bias the glass slide batches before image acquisition. These variabilities are assumed to cause a domain shift in the images of different hospitals. It is crucial to overcome this domain shift because an ideal machine-learning model must be able to work on the diverse sources of images, independent of the acquisition center. A domain generalization technique is leveraged in this study to improve the generalization capability of a Deep Neural Network (DNN), to an unseen histopathology image set (i.e., from an unseen hospital/trial site) in the presence of domain shift. According to experimental results, the conventional supervised-learning regime generalizes poorly to data collected from different hospitals. However, the proposed hospital-agnostic learning can improve the generalization considering the low-dimensional latent space representation visualization, and classification accuracy results.