 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Dynamic Clustering Network for Unsupervised Semantic Segmentation
Oct 12, 2022


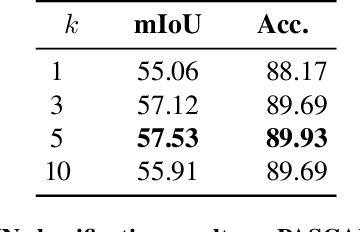
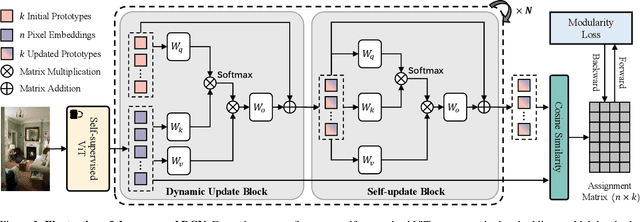
Recently, the ability of self-supervised Vision Transformer (ViT) to represent pixel-level semantic relationships promotes the development of unsupervised dense prediction tasks. In this work, we investigate transferring self-supervised ViT to unsupervised semantic segmentation task. According to the analysis that the pixel-level representations of self-supervised ViT within a single image achieve good intra-class compactness and inter-class discrimination, we propose the Dynamic Clustering Network (DCN) to dynamically infer the underlying cluster centers for different images. By training with the proposed modularity loss, the DCN learns to project a set of prototypes to cluster centers for pixel representations in each image and assign pixels to different clusters, resulting on dividing each image to class-agnostic regions. For achieving unsupervised semantic segmentation task, we treat it as a region classification problem. Based on the regions produced by the DCN, we explore different ways to extract region-level representations and classify them in an unsupervised manner. We demonstrate the effectiveness of the proposed method trough experiments on unsupervised semantic segmentation, and achieve state-of-the-art performance on PASCAL VOC 2012 unsupervised semantic segmentation task.
Analysis of the performance of U-Net neural networks for the segmentation of living cells
Oct 04, 2022
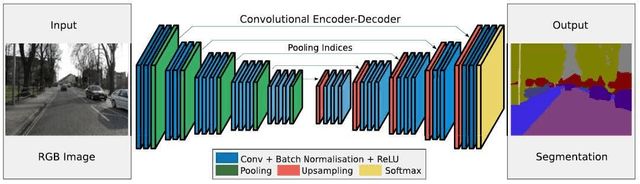
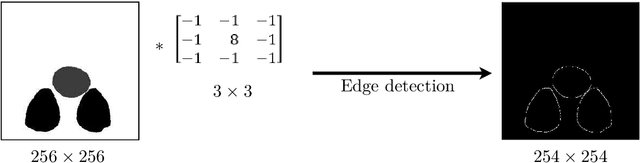
The automated analysis of microscopy images is a challenge in the context of single-cell tracking and quantification. This work has as goals the study of the performance of deep learning for segmenting microscopy images and the improvement of the previously available pipeline for tracking single cells. Deep learning techniques, mainly convolutional neural networks, have been applied to cell segmentation problems and have shown high accuracy and fast performance. To perform the image segmentation, an analysis of hyperparameters was done in order to implement a convolutional neural network with U-Net architecture. Furthermore, different models were built in order to optimize the size of the network and the number of learnable parameters. The trained network is then used in the pipeline that localizes the traps in a microfluidic device, performs the image segmentation on trap images, and evaluates the fluorescence intensity and the area of single cells over time. The tracking of the cells during an experiment is performed by image processing algorithms, such as centroid estimation and watershed. Finally, with all improvements in the neural network to segment single cells and in the pipeline, quasi-real-time image analysis was enabled, where 6.20GB of data was processed in 4 minutes.
Iterative, Deep Synthetic Aperture Sonar Image Segmentation
Mar 28, 2022
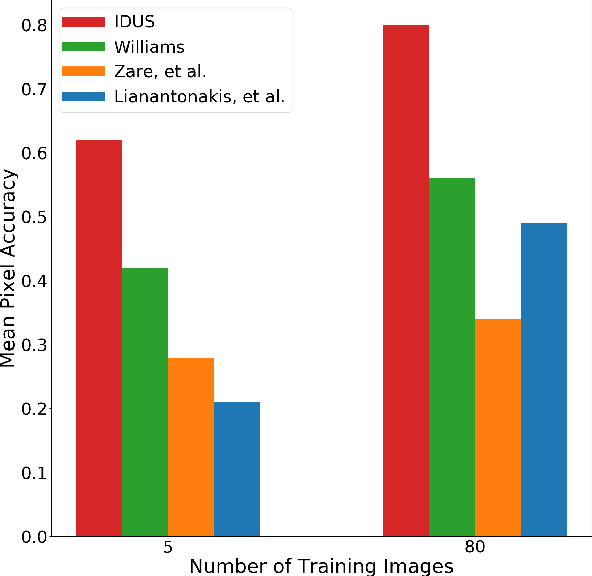
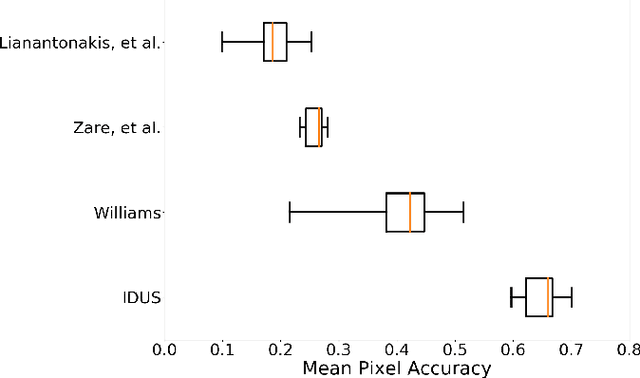
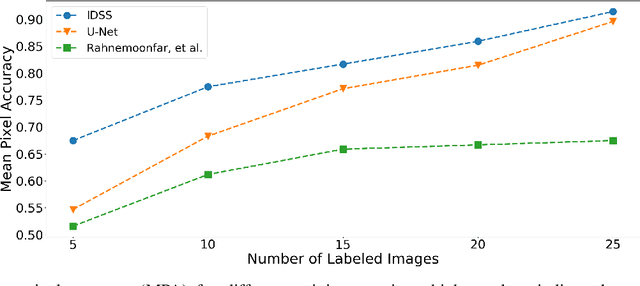
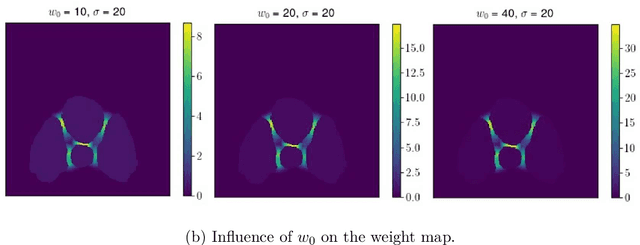
Synthetic aperture sonar (SAS) systems produce high-resolution images of the seabed environment. Moreover, deep learning has demonstrated superior ability in finding robust features for automating imagery analysis. However, the success of deep learning is conditioned on having lots of labeled training data, but obtaining generous pixel-level annotations of SAS imagery is often practically infeasible. This challenge has thus far limited the adoption of deep learning methods for SAS segmentation. Algorithms exist to segment SAS imagery in an unsupervised manner, but they lack the benefit of state-of-the-art learning methods and the results present significant room for improvement. In view of the above, we propose a new iterative algorithm for unsupervised SAS image segmentation combining superpixel formation, deep learning, and traditional clustering methods. We call our method Iterative Deep Unsupervised Segmentation (IDUS). IDUS is an unsupervised learning framework that can be divided into four main steps: 1) A deep network estimates class assignments. 2) Low-level image features from the deep network are clustered into superpixels. 3) Superpixels are clustered into class assignments (which we call pseudo-labels) using $k$-means. 4) Resulting pseudo-labels are used for loss backpropagation of the deep network prediction. These four steps are performed iteratively until convergence. A comparison of IDUS to current state-of-the-art methods on a realistic benchmark dataset for SAS image segmentation demonstrates the benefits of our proposal even as the IDUS incurs a much lower computational burden during inference (actual labeling of a test image). Finally, we also develop a semi-supervised (SS) extension of IDUS called IDSS and demonstrate experimentally that it can further enhance performance while outperforming supervised alternatives that exploit the same labeled training imagery.
Structure Representation Network and Uncertainty Feedback Learning for Dense Non-Uniform Fog Removal
Oct 06, 2022
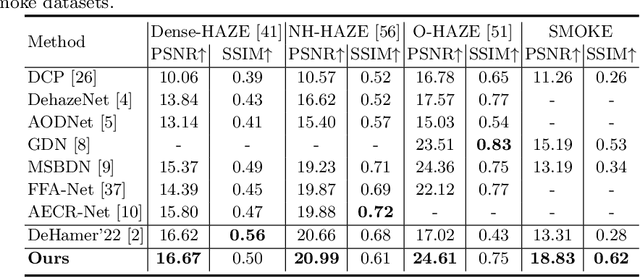
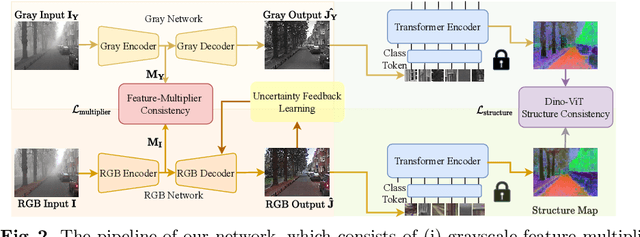

Few existing image defogging or dehazing methods consider dense and non-uniform particle distributions, which usually happen in smoke, dust and fog. Dealing with these dense and/or non-uniform distributions can be intractable, since fog's attenuation and airlight (or veiling effect) significantly weaken the background scene information in the input image. To address this problem, we introduce a structure-representation network with uncertainty feedback learning. Specifically, we extract the feature representations from a pre-trained Vision Transformer (DINO-ViT) module to recover the background information. To guide our network to focus on non-uniform fog areas, and then remove the fog accordingly, we introduce the uncertainty feedback learning, which produces the uncertainty maps, that have higher uncertainty in denser fog regions, and can be regarded as an attention map that represents fog's density and uneven distribution. Based on the uncertainty map, our feedback network refines our defogged output iteratively. Moreover, to handle the intractability of estimating the atmospheric light colors, we exploit the grayscale version of our input image, since it is less affected by varying light colors that are possibly present in the input image. The experimental results demonstrate the effectiveness of our method both quantitatively and qualitatively compared to the state-of-the-art methods in handling dense and non-uniform fog or smoke.
Novel View Synthesis with Diffusion Models
Oct 06, 2022
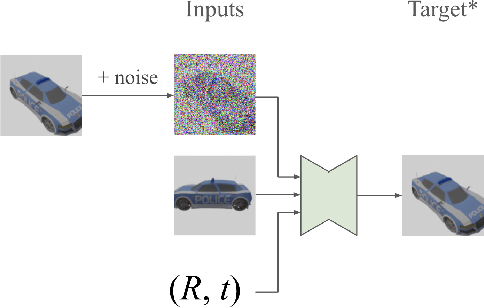
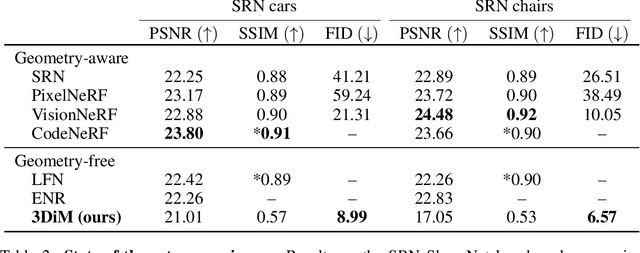
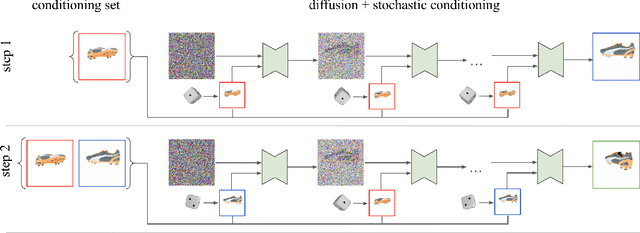
We present 3DiM, a diffusion model for 3D novel view synthesis, which is able to translate a single input view into consistent and sharp completions across many views. The core component of 3DiM is a pose-conditional image-to-image diffusion model, which takes a source view and its pose as inputs, and generates a novel view for a target pose as output. 3DiM can generate multiple views that are 3D consistent using a novel technique called stochastic conditioning. The output views are generated autoregressively, and during the generation of each novel view, one selects a random conditioning view from the set of available views at each denoising step. We demonstrate that stochastic conditioning significantly improves the 3D consistency of a naive sampler for an image-to-image diffusion model, which involves conditioning on a single fixed view. We compare 3DiM to prior work on the SRN ShapeNet dataset, demonstrating that 3DiM's generated completions from a single view achieve much higher fidelity, while being approximately 3D consistent. We also introduce a new evaluation methodology, 3D consistency scoring, to measure the 3D consistency of a generated object by training a neural field on the model's output views. 3DiM is geometry free, does not rely on hyper-networks or test-time optimization for novel view synthesis, and allows a single model to easily scale to a large number of scenes.
Blind Image Inpainting with Sparse Directional Filter Dictionaries for Lightweight CNNs
May 13, 2022
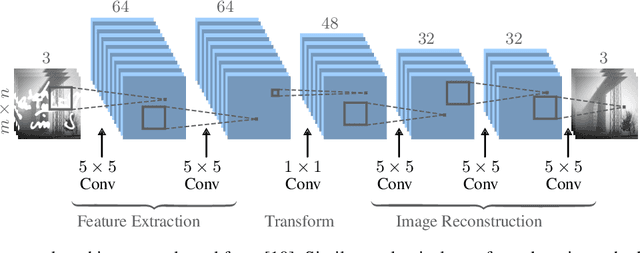
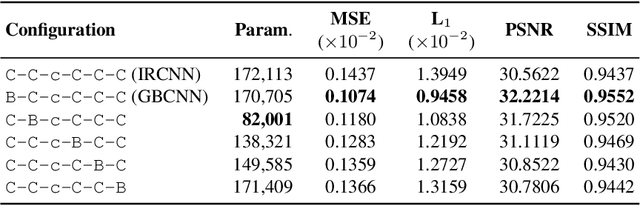
Blind inpainting algorithms based on deep learning architectures have shown a remarkable performance in recent years, typically outperforming model-based methods both in terms of image quality and run time. However, neural network strategies typically lack a theoretical explanation, which contrasts with the well-understood theory underlying model-based methods. In this work, we leverage the advantages of both approaches by integrating theoretically founded concepts from transform domain methods and sparse approximations into a CNN-based approach for blind image inpainting. To this end, we present a novel strategy to learn convolutional kernels that applies a specifically designed filter dictionary whose elements are linearly combined with trainable weights. Numerical experiments demonstrate the competitiveness of this approach. Our results show not only an improved inpainting quality compared to conventional CNNs but also significantly faster network convergence within a lightweight network design.
A Noise-level-aware Framework for PET Image Denoising
Mar 15, 2022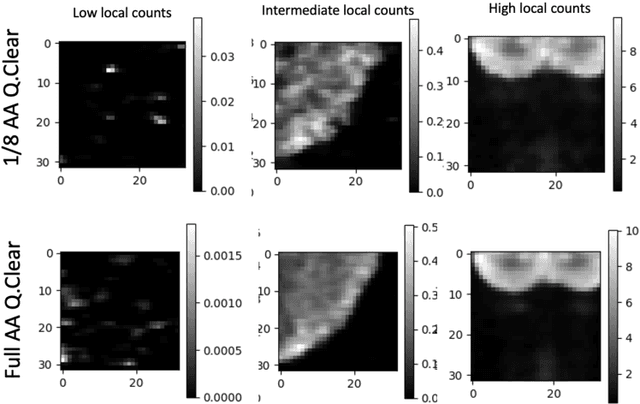
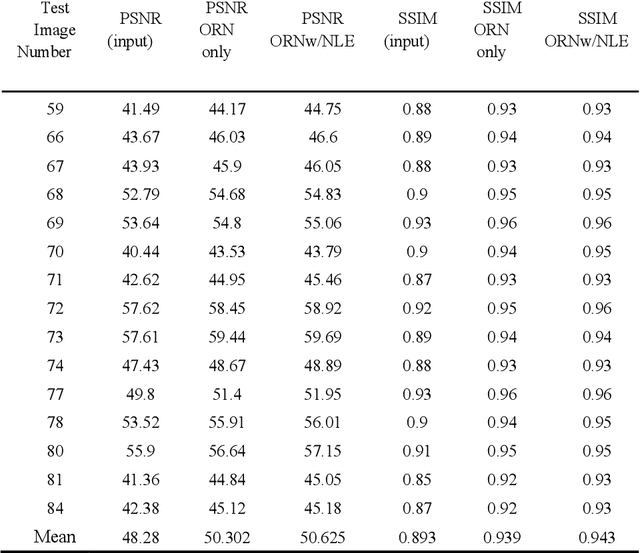
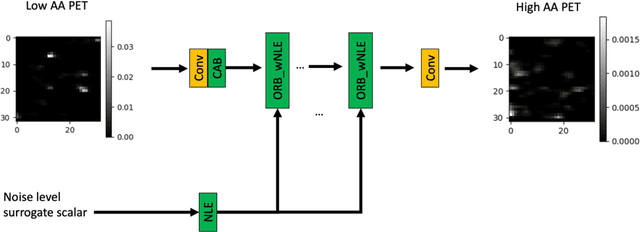
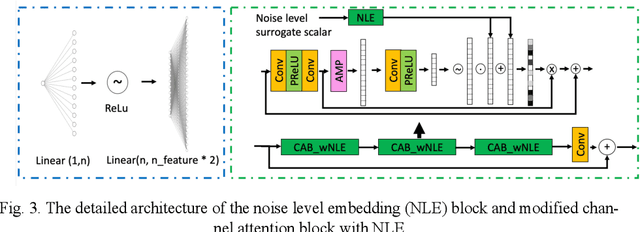
In PET, the amount of relative (signal-dependent) noise present in different body regions can be significantly different and is inherently related to the number of counts present in that region. The number of counts in a region depends, in principle and among other factors, on the total administered activity, scanner sensitivity, image acquisition duration, radiopharmaceutical tracer uptake in the region, and patient local body morphometry surrounding the region. In theory, less amount of denoising operations is needed to denoise a high-count (low relative noise) image than images a low-count (high relative noise) image, and vice versa. The current deep-learning-based methods for PET image denoising are predominantly trained on image appearance only and have no special treatment for images of different noise levels. Our hypothesis is that by explicitly providing the local relative noise level of the input image to a deep convolutional neural network (DCNN), the DCNN can outperform itself trained on image appearance only. To this end, we propose a noise-level-aware framework denoising framework that allows embedding of local noise level into a DCNN. The proposed is trained and tested on 30 and 15 patient PET images acquired on a GE Discovery MI PET/CT system. Our experiments showed that the increases in both PSNR and SSIM from our backbone network with relative noise level embedding (NLE) versus the same network without NLE were statistically significant with p<0.001, and the proposed method significantly outperformed a strong baseline method by a large margin.
PetsGAN: Rethinking Priors for Single Image Generation
Mar 03, 2022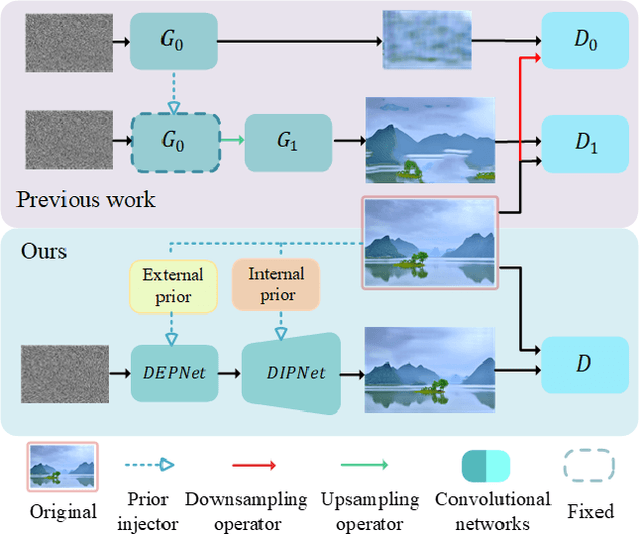
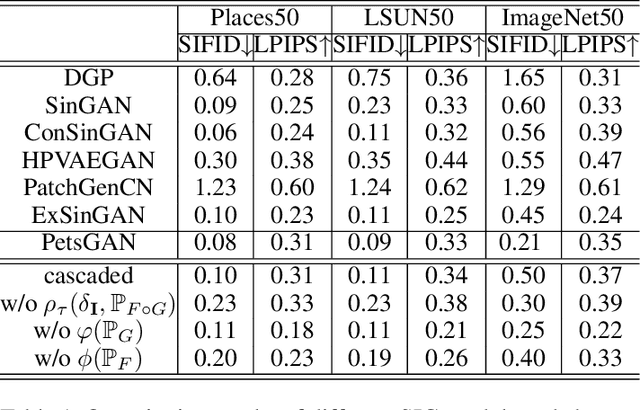

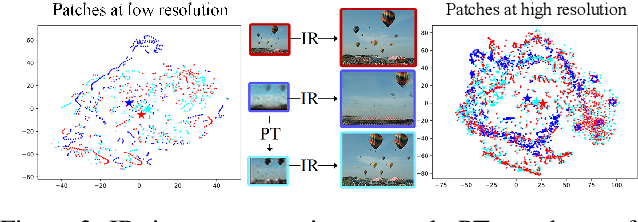
Single image generation (SIG), described as generating diverse samples that have similar visual content with the given single image, is first introduced by SinGAN which builds a pyramid of GANs to progressively learn the internal patch distribution of the single image. It also shows great potentials in a wide range of image manipulation tasks. However, the paradigm of SinGAN has limitations in terms of generation quality and training time. Firstly, due to the lack of high-level information, SinGAN cannot handle the object images well as it does on the scene and texture images. Secondly, the separate progressive training scheme is time-consuming and easy to cause artifact accumulation. To tackle these problems, in this paper, we dig into the SIG problem and improve SinGAN by fully-utilization of internal and external priors. The main contributions of this paper include: 1) We introduce to SIG a regularized latent variable model. To the best of our knowledge, it is the first time to give a clear formulation and optimization goal of SIG, and all the existing methods for SIG can be regarded as special cases of this model. 2) We design a novel Prior-based end-to-end training GAN (PetsGAN) to overcome the problems of SinGAN. Our method gets rid of the time-consuming progressive training scheme and can be trained end-to-end. 3) We construct abundant qualitative and quantitative experiments to show the superiority of our method on both generated image quality, diversity, and the training speed. Moreover, we apply our method to other image manipulation tasks (e.g., style transfer, harmonization), and the results further prove the effectiveness and efficiency of our method.
Diagnostics for Deep Neural Networks with Automated Copy/Paste Attacks
Nov 22, 2022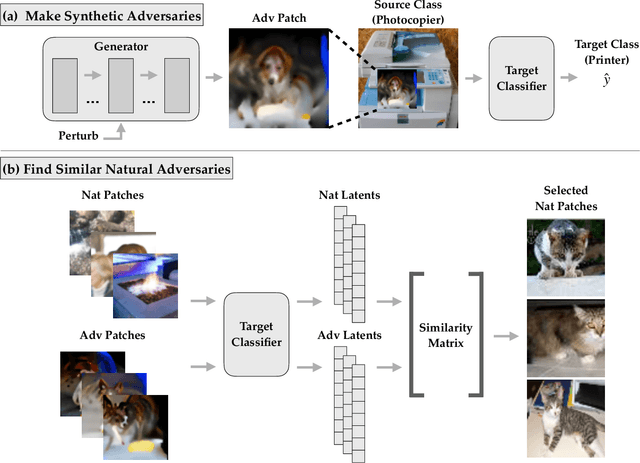

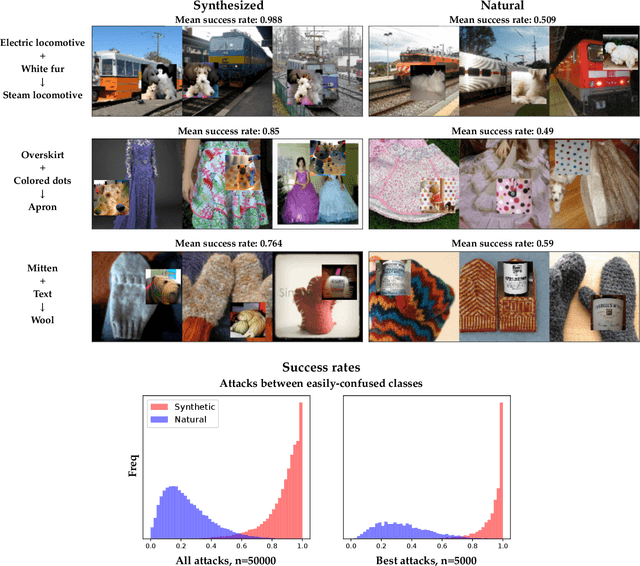
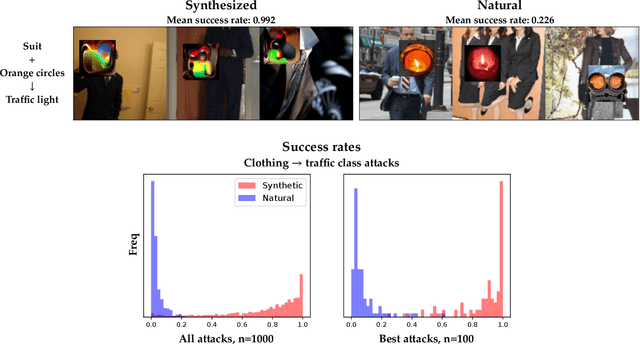
Deep neural networks (DNNs) are powerful, but they can make mistakes that pose significant risks. A model performing well on a test set does not imply safety in deployment, so it is important to have additional tools to understand its flaws. Adversarial examples can help reveal weaknesses, but they are often difficult for a human to interpret or draw generalizable, actionable conclusions from. Some previous works have addressed this by studying human-interpretable attacks. We build on these with three contributions. First, we introduce a method termed Search for Natural Adversarial Features Using Embeddings (SNAFUE) which offers a fully-automated method for finding "copy/paste" attacks in which one natural image can be pasted into another in order to induce an unrelated misclassification. Second, we use this to red team an ImageNet classifier and identify hundreds of easily-describable sets of vulnerabilities. Third, we compare this approach with other interpretability tools by attempting to rediscover trojans. Our results suggest that SNAFUE can be useful for interpreting DNNs and generating adversarial data for them. Code is available at https://github.com/thestephencasper/snafue
MagicPony: Learning Articulated 3D Animals in the Wild
Nov 22, 2022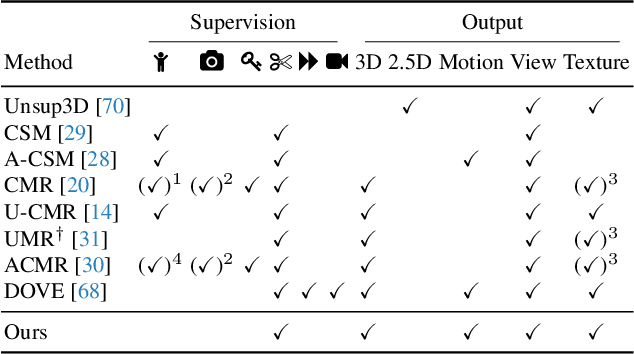
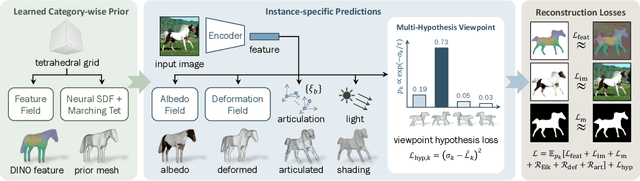
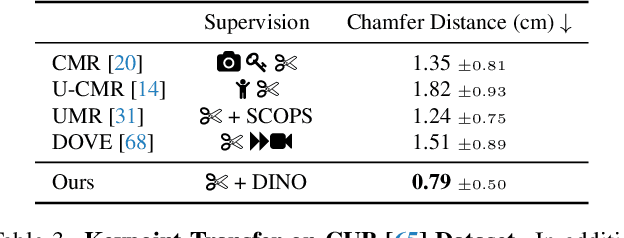
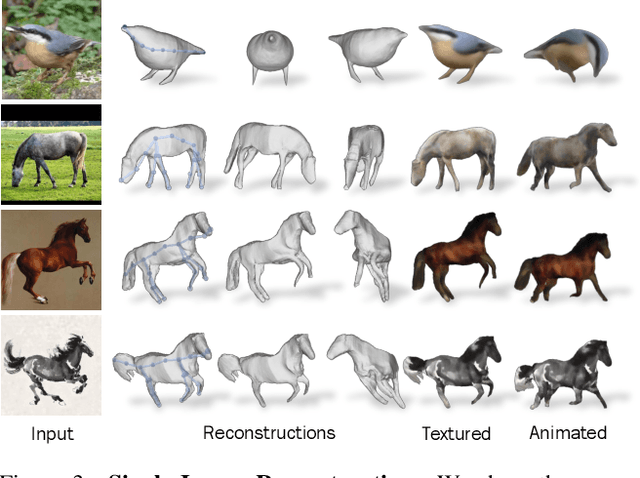
We consider the problem of learning a function that can estimate the 3D shape, articulation, viewpoint, texture, and lighting of an articulated animal like a horse, given a single test image. We present a new method, dubbed MagicPony, that learns this function purely from in-the-wild single-view images of the object category, with minimal assumptions about the topology of deformation. At its core is an implicit-explicit representation of articulated shape and appearance, combining the strengths of neural fields and meshes. In order to help the model understand an object's shape and pose, we distil the knowledge captured by an off-the-shelf self-supervised vision transformer and fuse it into the 3D model. To overcome common local optima in viewpoint estimation, we further introduce a new viewpoint sampling scheme that comes at no added training cost. Compared to prior works, we show significant quantitative and qualitative improvements on this challenging task. The model also demonstrates excellent generalisation in reconstructing abstract drawings and artefacts, despite the fact that it is only trained on real images.