 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hyperbolic Sliced-Wasserstein via Geodesic and Horospherical Projections
Nov 18, 2022


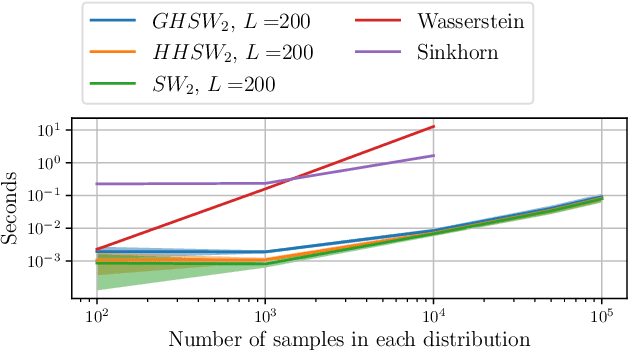
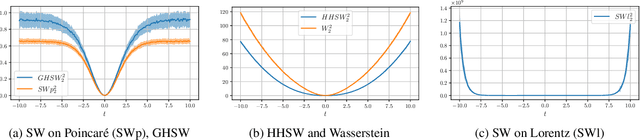
It has been shown beneficial for many types of data which present an underlying hierarchical structure to be embedded in hyperbolic spaces. Consequently, many tools of machine learning were extended to such spaces, but only few discrepancies to compare probability distributions defined over those spaces exist. Among the possible candidates, optimal transport distances are well defined on such Riemannian manifolds and enjoy strong theoretical properties, but suffer from high computational cost. On Euclidean spaces, sliced-Wasserstein distances, which leverage a closed-form of the Wasserstein distance in one dimension, are more computationally efficient, but are not readily available on hyperbolic spaces. In this work, we propose to derive novel hyperbolic sliced-Wasserstein discrepancies. These constructions use projections on the underlying geodesics either along horospheres or geodesics. We study and compare them on different tasks where hyperbolic representations are relevant, such as sampling or image classification.
MouseGAN++: Unsupervised Disentanglement and Contrastive Representation for Multiple MRI Modalities Synthesis and Structural Segmentation of Mouse Brain
Dec 04, 2022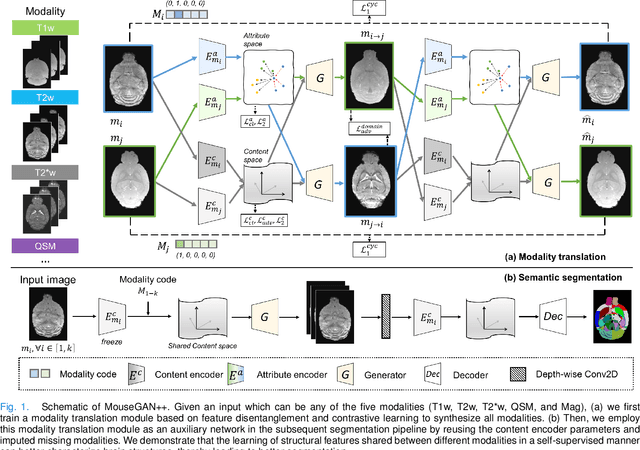
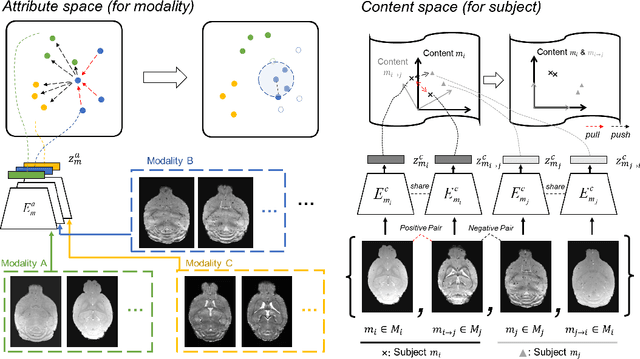
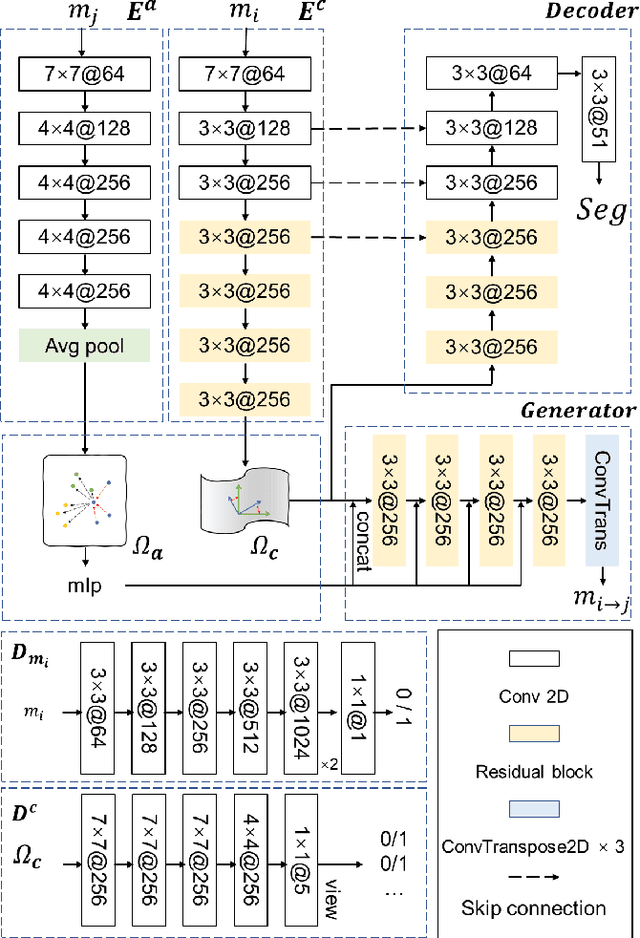
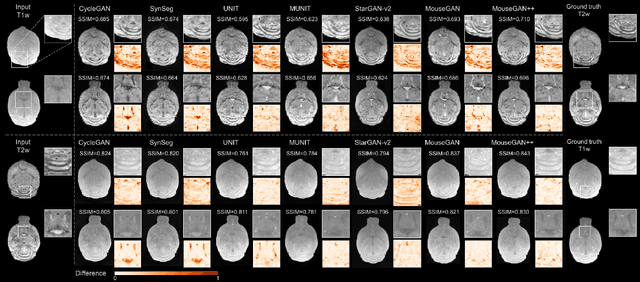
Segmenting the fine structure of the mouse brain on magnetic resonance (MR) images is critical for delineating morphological regions, analyzing brain function, and understanding their relationships. Compared to a single MRI modality, multimodal MRI data provide complementary tissue features that can be exploited by deep learning models, resulting in better segmentation results. However, multimodal mouse brain MRI data is often lacking, making automatic segmentation of mouse brain fine structure a very challenging task. To address this issue, it is necessary to fuse multimodal MRI data to produce distinguished contrasts in different brain structures. Hence, we propose a novel disentangled and contrastive GAN-based framework, named MouseGAN++, to synthesize multiple MR modalities from single ones in a structure-preserving manner, thus improving the segmentation performance by imputing missing modalities and multi-modality fusion. Our results demonstrate that the translation performance of our method outperforms the state-of-the-art methods. Using the subsequently learned modality-invariant information as well as the modality-translated images, MouseGAN++ can segment fine brain structures with averaged dice coefficients of 90.0% (T2w) and 87.9% (T1w), respectively, achieving around +10% performance improvement compared to the state-of-the-art algorithms. Our results demonstrate that MouseGAN++, as a simultaneous image synthesis and segmentation method, can be used to fuse cross-modality information in an unpaired manner and yield more robust performance in the absence of multimodal data. We release our method as a mouse brain structural segmentation tool for free academic usage at https://github.com/yu02019.
Improving Training and Inference of Face Recognition Models via Random Temperature Scaling
Dec 02, 2022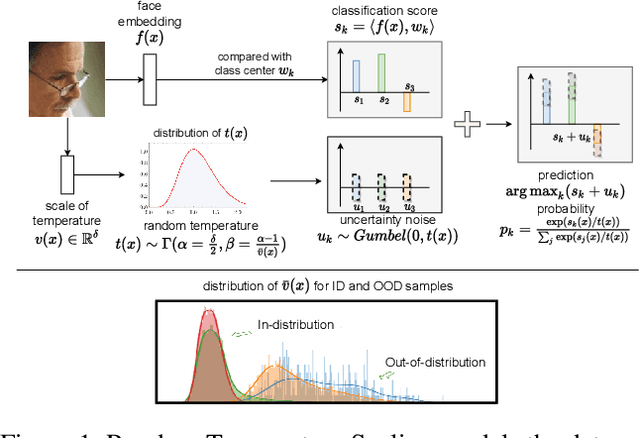
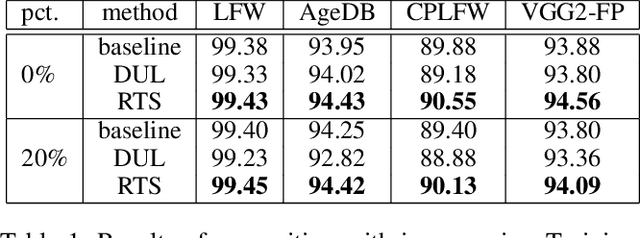
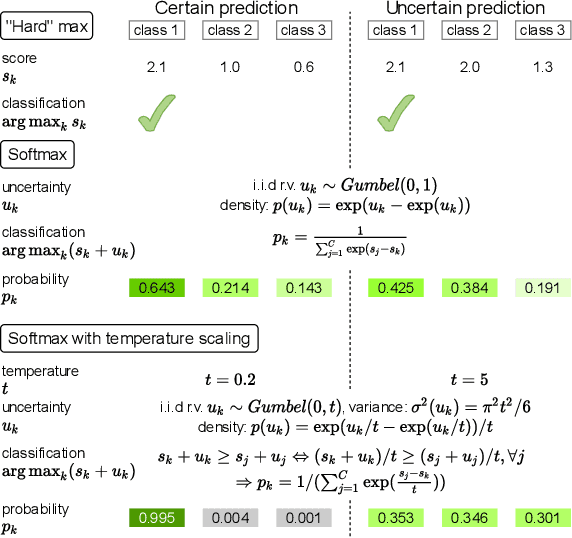
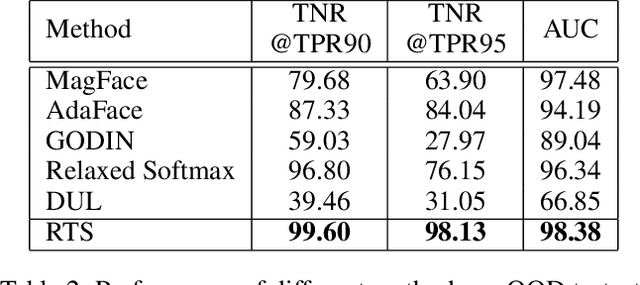
Data uncertainty is commonly observed in the images for face recognition (FR). However, deep learning algorithms often make predictions with high confidence even for uncertain or irrelevant inputs. Intuitively, FR algorithms can benefit from both the estimation of uncertainty and the detection of out-of-distribution (OOD) samples. Taking a probabilistic view of the current classification model, the temperature scalar is exactly the scale of uncertainty noise implicitly added in the softmax function. Meanwhile, the uncertainty of images in a dataset should follow a prior distribution. Based on the observation, a unified framework for uncertainty modeling and FR, Random Temperature Scaling (RTS), is proposed to learn a reliable FR algorithm. The benefits of RTS are two-fold. (1) In the training phase, it can adjust the learning strength of clean and noisy samples for stability and accuracy. (2) In the test phase, it can provide a score of confidence to detect uncertain, low-quality and even OOD samples, without training on extra labels. Extensive experiments on FR benchmarks demonstrate that the magnitude of variance in RTS, which serves as an OOD detection metric, is closely related to the uncertainty of the input image. RTS can achieve top performance on both the FR and OOD detection tasks. Moreover, the model trained with RTS can perform robustly on datasets with noise. The proposed module is light-weight and only adds negligible computation cost to the model.
An Approach for Noisy, Crowdsourced Datasets Utilizing Ensemble Modeling, 'Human Softmax' Distributions, and Entropic Measures of Uncertainty
Oct 28, 2022


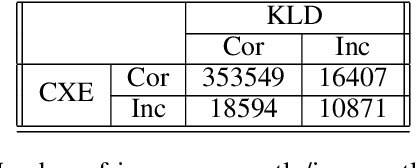
Noisy, crowdsourced image datasets prove challenging, even for the best neural networks. Two issues which complicate classification on such datasets are class imbalance and ground-truth uncertainty in labeling. The AL-ALL and AL-PUB datasets-consisting of tightly cropped, individual characters from images of ancient Greek papyri are strongly affected by both issues. The application of ensemble modeling to such a dataset can help identify images where the ground-truth is questionable and quantify the trustworthiness of those samples. We apply stacked generalization consisting of nearly identical ResNets: one utilizing cross-entropy (CXE) and the other Kullback-Liebler Divergence (KLD). The CXE network uses standard labeling drawn from the crowdsourced consensus. In contrast, the KLD network uses probabilistic labeling for each image derived from the distribution of crowdsourced annotations. We refer to this labeling as the Human Softmax (HSM) distribution. For our ensemble model, we apply a k-nearest neighbors model to the outputs of the CXE and KLD networks. Individually, the ResNet models have approximately 93% accuracy, while the ensemble model achieves an accuracy of >95%. We also perform an analysis of the Shannon entropy of the various models' output distributions to measure classification uncertainty.
Digital twins of physical printing-imaging channel
Oct 28, 2022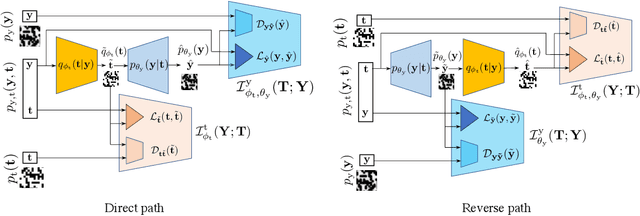
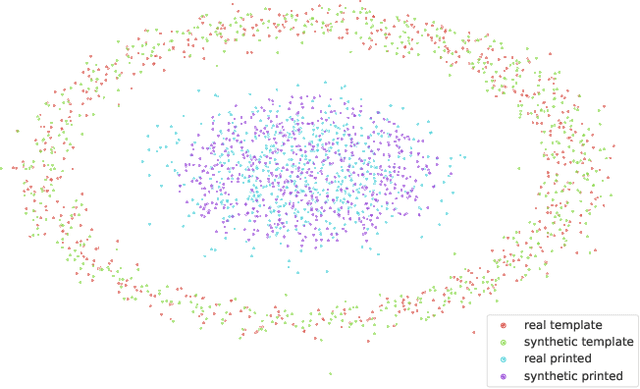
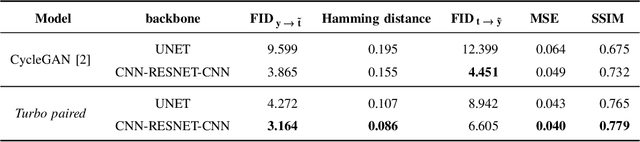
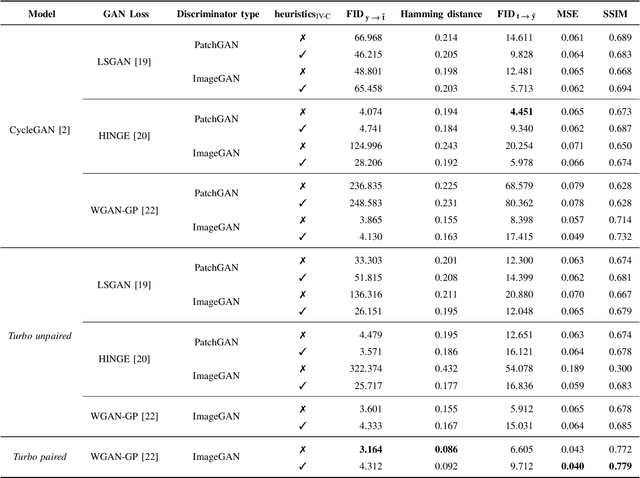
In this paper, we address the problem of modeling a printing-imaging channel built on a machine learning approach a.k.a. digital twin for anti-counterfeiting applications based on copy detection patterns (CDP). The digital twin is formulated on an information-theoretic framework called Turbo that uses variational approximations of mutual information developed for both encoder and decoder in a two-directional information passage. The proposed model generalizes several state-of-the-art architectures such as adversarial autoencoder (AAE), CycleGAN and adversarial latent space autoencoder (ALAE). This model can be applied to any type of printing and imaging and it only requires training data consisting of digital templates or artworks that are sent to a printing device and data acquired by an imaging device. Moreover, these data can be paired, unpaired or hybrid paired-unpaired which makes the proposed architecture very flexible and scalable to many practical setups. We demonstrate the impact of various architectural factors, metrics and discriminators on the overall system performance in the task of generation/prediction of printed CDP from their digital counterparts and vice versa. We also compare the proposed system with several state-of-the-art methods used for image-to-image translation applications.
Universal Adversarial Directions
Oct 28, 2022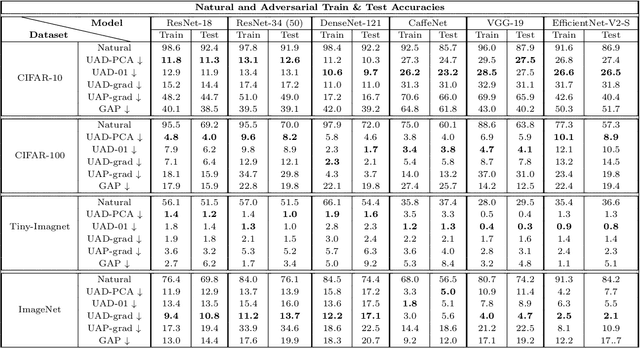

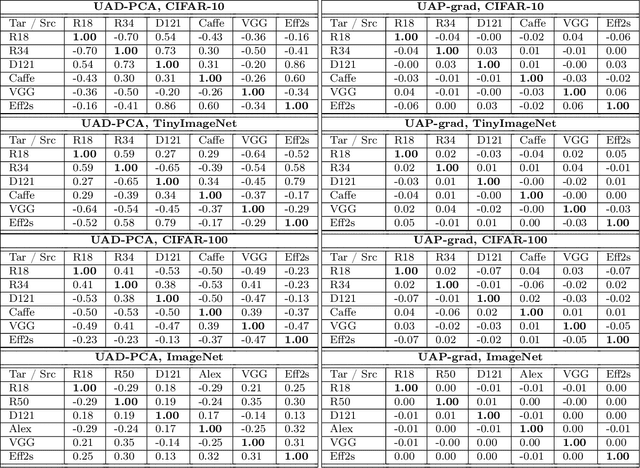
Despite their great success in image recognition tasks, deep neural networks (DNNs) have been observed to be susceptible to universal adversarial perturbations (UAPs) which perturb all input samples with a single perturbation vector. However, UAPs often struggle in transferring across DNN architectures and lead to challenging optimization problems. In this work, we study the transferability of UAPs by analyzing equilibrium in the universal adversarial example game between the classifier and UAP adversary players. We show that under mild assumptions the universal adversarial example game lacks a pure Nash equilibrium, indicating UAPs' suboptimal transferability across DNN classifiers. To address this issue, we propose Universal Adversarial Directions (UADs) which only fix a universal direction for adversarial perturbations and allow the perturbations' magnitude to be chosen freely across samples. We prove that the UAD adversarial example game can possess a Nash equilibrium with a pure UAD strategy, implying the potential transferability of UADs. We also connect the UAD optimization problem to the well-known principal component analysis (PCA) and develop an efficient PCA-based algorithm for optimizing UADs. We evaluate UADs over multiple benchmark image datasets. Our numerical results show the superior transferability of UADs over standard gradient-based UAPs.
Improving Chest X-Ray Classification by RNN-based Patient Monitoring
Oct 28, 2022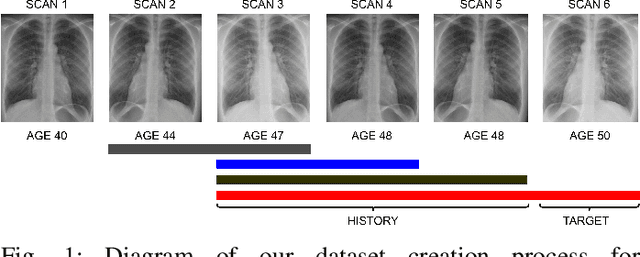
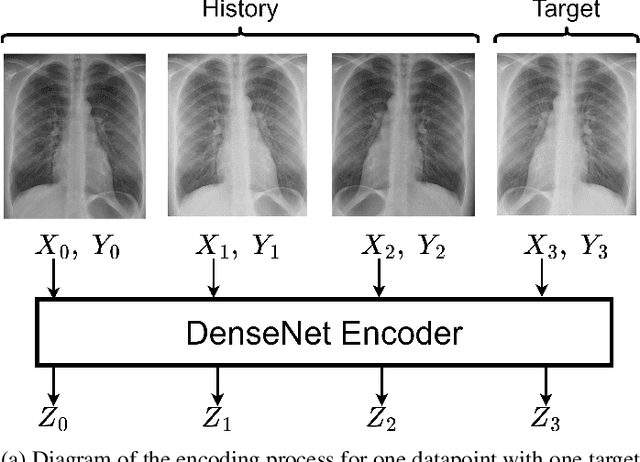
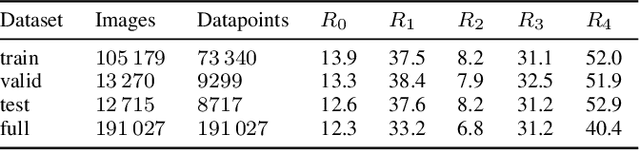

Chest X-Ray imaging is one of the most common radiological tools for detection of various pathologies related to the chest area and lung function. In a clinical setting, automated assessment of chest radiographs has the potential of assisting physicians in their decision making process and optimize clinical workflows, for example by prioritizing emergency patients. Most work analyzing the potential of machine learning models to classify chest X-ray images focuses on vision methods processing and predicting pathologies for one image at a time. However, many patients undergo such a procedure multiple times during course of a treatment or during a single hospital stay. The patient history, that is previous images and especially the corresponding diagnosis contain useful information that can aid a classification system in its prediction. In this study, we analyze how information about diagnosis can improve CNN-based image classification models by constructing a novel dataset from the well studied CheXpert dataset of chest X-rays. We show that a model trained on additional patient history information outperforms a model trained without the information by a significant margin. We provide code to replicate the dataset creation and model training.
DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
Nov 02, 2022

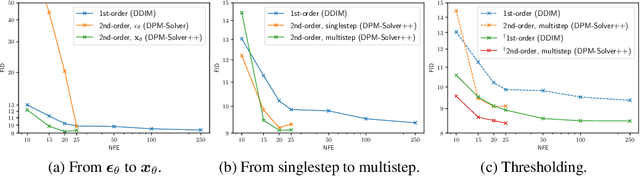
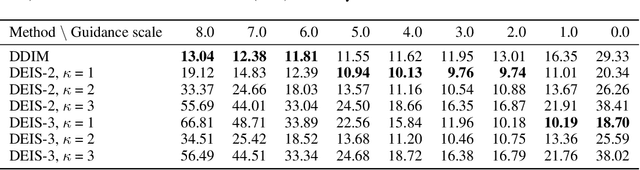
Diffusion probabilistic models (DPMs) have achieved impressive success in high-resolution image synthesis, especially in recent large-scale text-to-image generation applications. An essential technique for improving the sample quality of DPMs is guided sampling, which usually needs a large guidance scale to obtain the best sample quality. The commonly-used fast sampler for guided sampling is DDIM, a first-order diffusion ODE solver that generally needs 100 to 250 steps for high-quality samples. Although recent works propose dedicated high-order solvers and achieve a further speedup for sampling without guidance, their effectiveness for guided sampling has not been well-tested before. In this work, we demonstrate that previous high-order fast samplers suffer from instability issues, and they even become slower than DDIM when the guidance scale grows large. To further speed up guided sampling, we propose DPM-Solver++, a high-order solver for the guided sampling of DPMs. DPM-Solver++ solves the diffusion ODE with the data prediction model and adopts thresholding methods to keep the solution matches training data distribution. We further propose a multistep variant of DPM-Solver++ to address the instability issue by reducing the effective step size. Experiments show that DPM-Solver++ can generate high-quality samples within only 15 to 20 steps for guided sampling by pixel-space and latent-space DPMs.
Learning Visual Planning Models from Partially Observed Images
Nov 25, 2022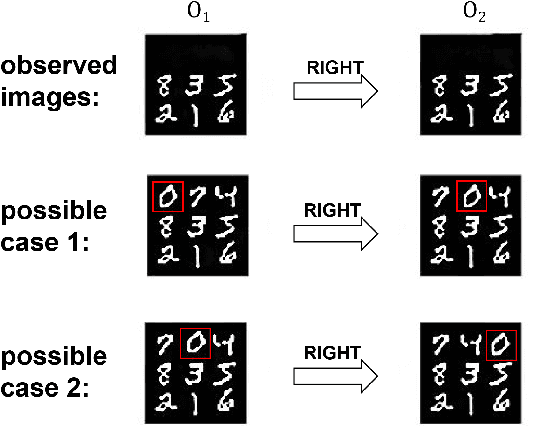
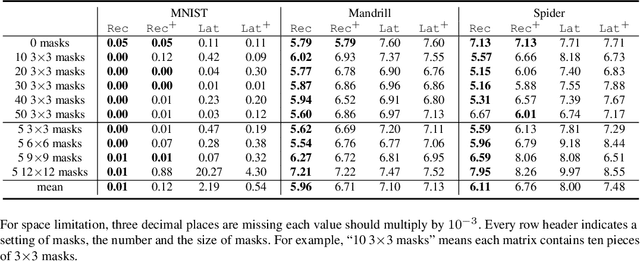
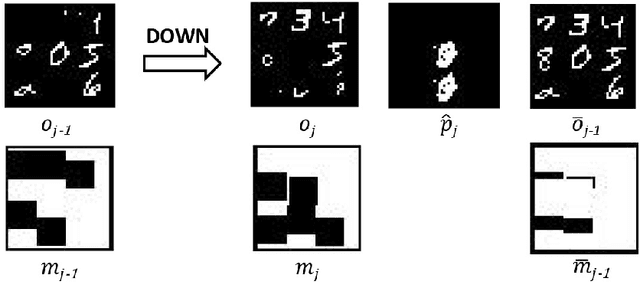
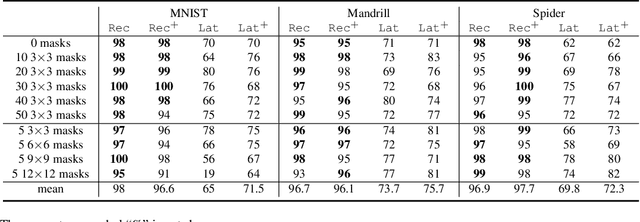
There has been increasing attention on planning model learning in classical planning. Most existing approaches, however, focus on learning planning models from structured data in symbolic representations. It is often difficult to obtain such structured data in real-world scenarios. Although a number of approaches have been developed for learning planning models from fully observed unstructured data (e.g., images), in many scenarios raw observations are often incomplete. In this paper, we provide a novel framework, \aType{Recplan}, for learning a transition model from partially observed raw image traces. More specifically, by considering the preceding and subsequent images in a trace, we learn the latent state representations of raw observations and then build a transition model based on such representations. Additionally, we propose a neural-network-based approach to learn a heuristic model that estimates the distance toward a given goal observation. Based on the learned transition model and heuristic model, we implement a classical planner for images. We exhibit empirically that our approach is more effective than a state-of-the-art approach of learning visual planning models in the environment with incomplete observations.
Word to Sentence Visual Semantic Similarity for Caption Generation: Lessons Learned
Sep 26, 2022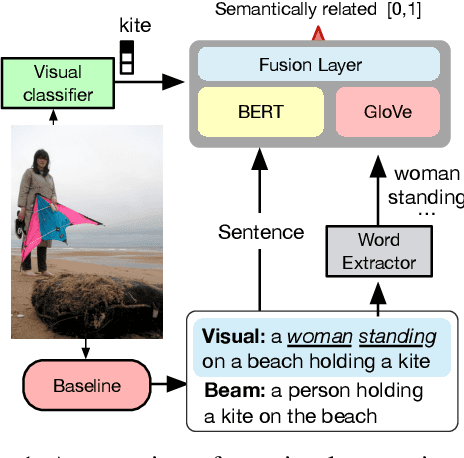
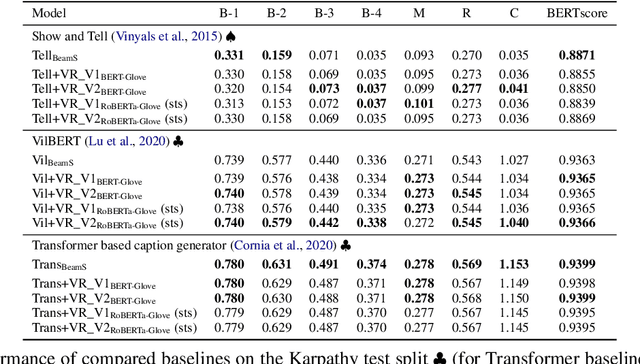
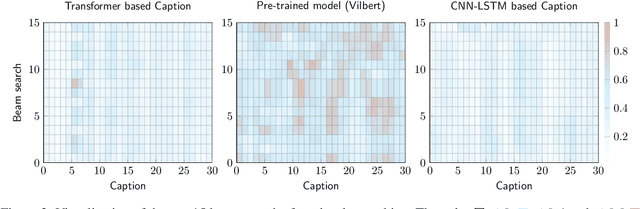
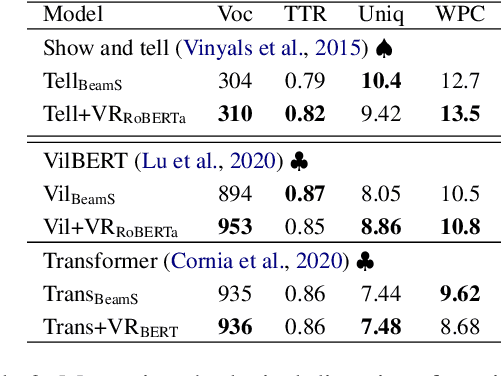
This paper focuses on enhancing the captions generated by image-caption generation systems. We propose an approach for improving caption generation systems by choosing the most closely related output to the image rather than the most likely output produced by the model. Our model revises the language generation output beam search from a visual context perspective. We employ a visual semantic measure in a word and sentence level manner to match the proper caption to the related information in the image. The proposed approach can be applied to any caption system as a post-processing based method.