 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Class Adaptive Network Calibration
Nov 28, 2022
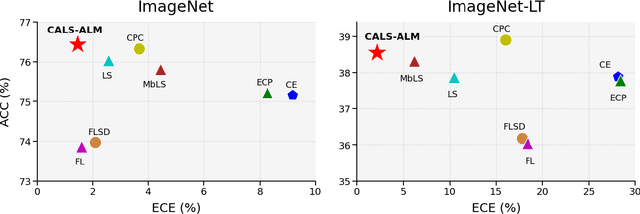
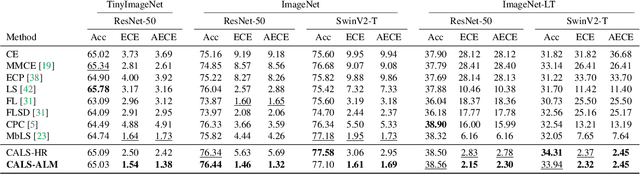
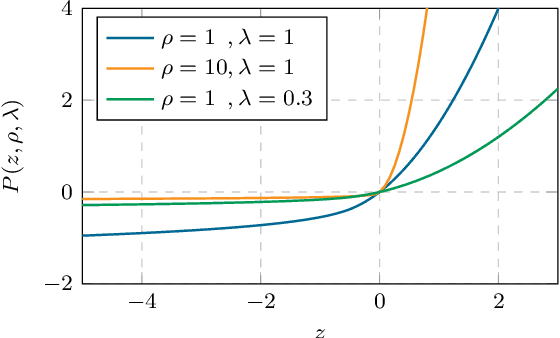
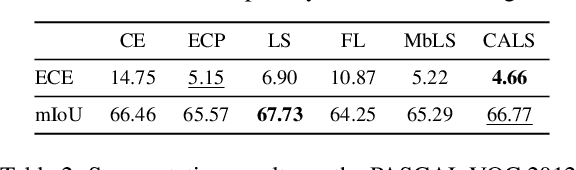
Recent studies have revealed that, beyond conventional accuracy, calibration should also be considered for training modern deep neural networks. To address miscalibration during learning, some methods have explored different penalty functions as part of the learning objective, alongside a standard classification loss, with a hyper-parameter controlling the relative contribution of each term. Nevertheless, these methods share two major drawbacks: 1) the scalar balancing weight is the same for all classes, hindering the ability to address different intrinsic difficulties or imbalance among classes; and 2) the balancing weight is usually fixed without an adaptive strategy, which may prevent from reaching the best compromise between accuracy and calibration, and requires hyper-parameter search for each application. We propose Class Adaptive Label Smoothing (CALS) for calibrating deep networks, which allows to learn class-wise multipliers during training, yielding a powerful alternative to common label smoothing penalties. Our method builds on a general Augmented Lagrangian approach, a well-established technique in constrained optimization, but we introduce several modifications to tailor it for large-scale, class-adaptive training. Comprehensive evaluation and multiple comparisons on a variety of benchmarks, including standard and long-tailed image classification, semantic segmentation, and text classification, demonstrate the superiority of the proposed method. The code is available at https://github.com/by-liu/CALS.
H3WB: Human3.6M 3D WholeBody Dataset and Benchmark
Nov 28, 2022
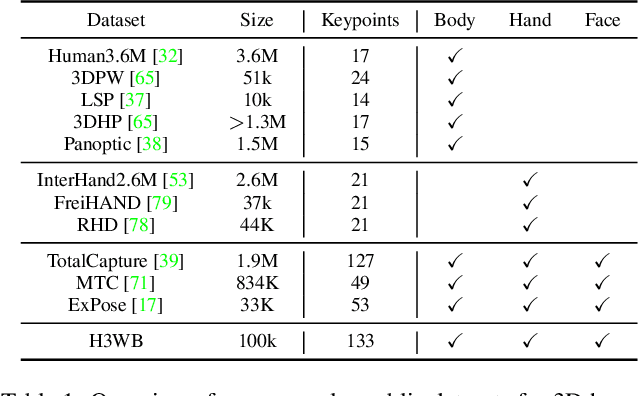
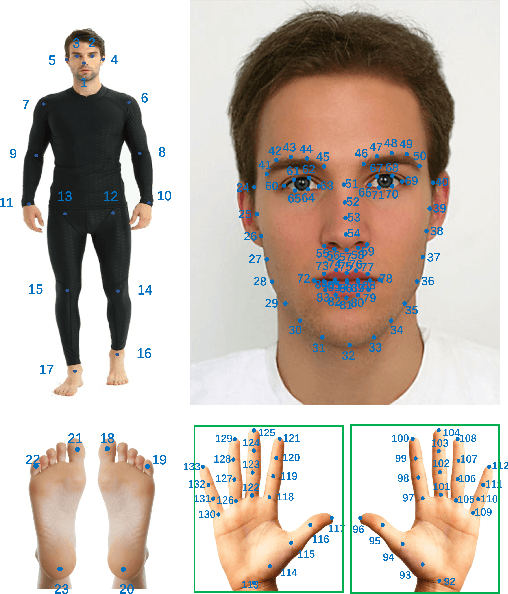
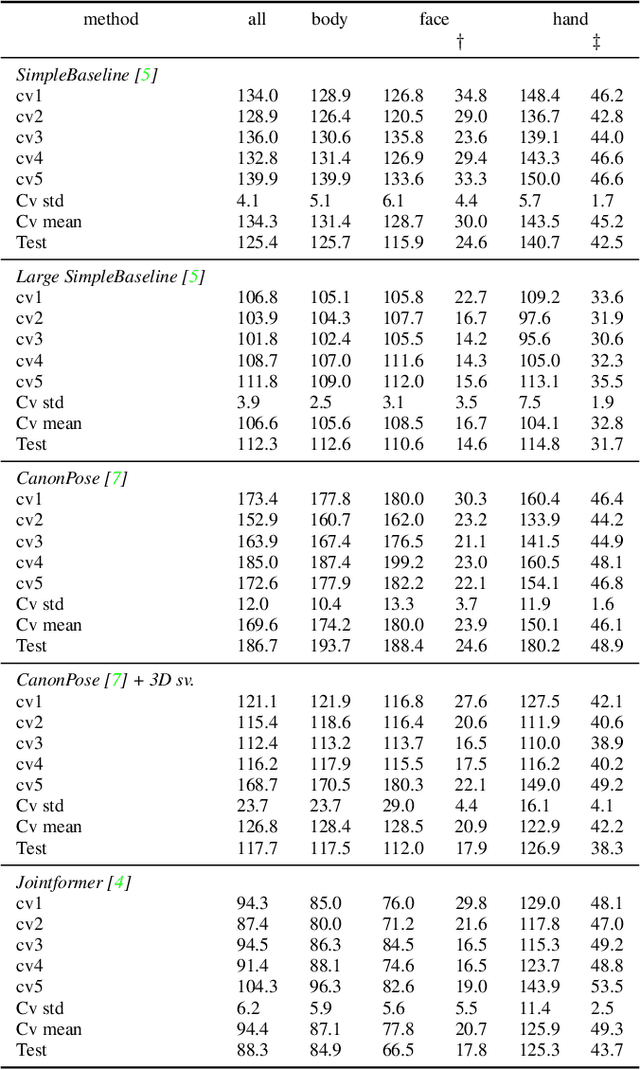
3D human whole-body pose estimation aims to localize precise 3D keypoints on the entire human body, including the face, hands, body, and feet. Due to the lack of a large-scale fully annotated 3D whole-body dataset, a common approach has been to train several deep networks separately on datasets dedicated to specific body parts, and combine them during inference. This approach suffers from complex training and inference pipelines because of the different biases in each dataset used. It also lacks a common benchmark which makes it difficult to compare different methods. To address these issues, we introduce Human3.6M 3D WholeBody (H3WB) which provides whole-body annotations for the Human3.6M dataset using the COCO Wholebody layout. H3WB is a large scale dataset with 133 whole-body keypoint annotations on 100K images, made possible by our new multi-view pipeline. Along with H3WB, we propose 3 tasks: i) 3D whole-body pose lifting from 2D complete whole-body pose, ii) 3D whole-body pose lifting from 2D incomplete whole-body pose, iii) 3D whole-body pose estimation from a single RGB image. We also report several baselines from popular methods for these tasks. The dataset is publicly available at \url{https://github.com/wholebody3d/wholebody3d}.
Autonomous Golf Putting with Data-Driven and Physics-Based Methods
Nov 15, 2022
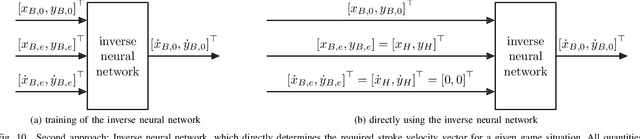
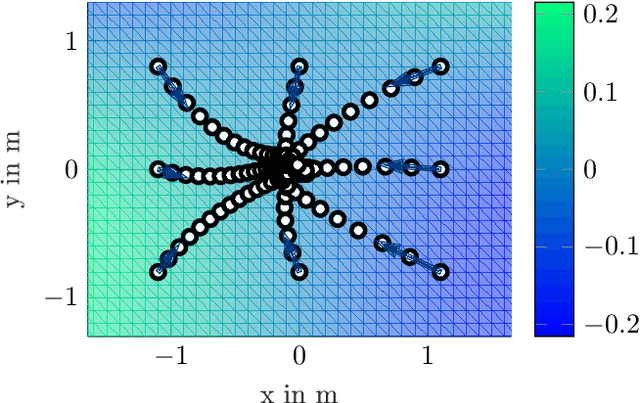

We are developing a self-learning mechatronic golf robot using combined data-driven and physics-based methods, to have the robot autonomously learn to putt the ball from an arbitrary point on the green. Apart from the mechatronic control design of the robot, this task is accomplished by a camera system with image recognition and a neural network for predicting the stroke velocity vector required for a successful hole-in-one. To minimize the number of time-consuming interactions with the real system, the neural network is pretrained by evaluating basic physical laws on a model, which approximates the golf ball dynamics on the green surface in a data-driven manner. Thus, we demonstrate the synergetic combination of data-driven and physics-based methods on the golf robot as a mechatronic example system.
Seeing 3D Objects in a Single Image via Self-Supervised Static-Dynamic Disentanglement
Jul 22, 2022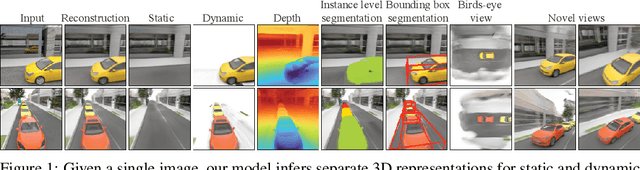
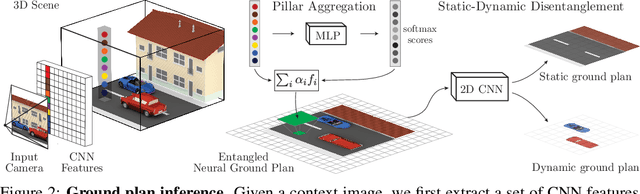
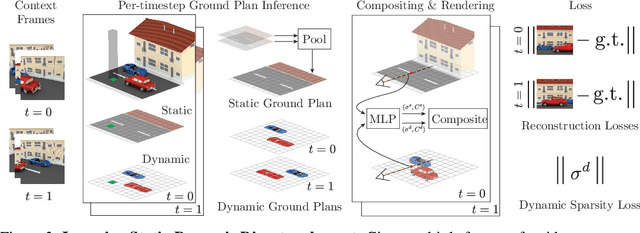

Human perception reliably identifies movable and immovable parts of 3D scenes, and completes the 3D structure of objects and background from incomplete observations. We learn this skill not via labeled examples, but simply by observing objects move. In this work, we propose an approach that observes unlabeled multi-view videos at training time and learns to map a single image observation of a complex scene, such as a street with cars, to a 3D neural scene representation that is disentangled into movable and immovable parts while plausibly completing its 3D structure. We separately parameterize movable and immovable scene parts via 2D neural ground plans. These ground plans are 2D grids of features aligned with the ground plane that can be locally decoded into 3D neural radiance fields. Our model is trained self-supervised via neural rendering. We demonstrate that the structure inherent to our disentangled 3D representation enables a variety of downstream tasks in street-scale 3D scenes using simple heuristics, such as extraction of object-centric 3D representations, novel view synthesis, instance segmentation, and 3D bounding box prediction, highlighting its value as a backbone for data-efficient 3D scene understanding models. This disentanglement further enables scene editing via object manipulation such as deletion, insertion, and rigid-body motion.
Rolling Shutter Inversion: Bring Rolling Shutter Images to High Framerate Global Shutter Video
Oct 06, 2022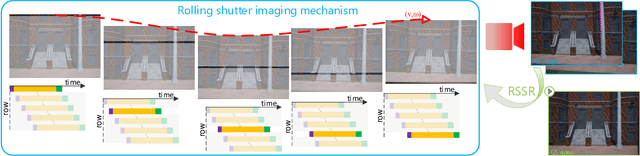
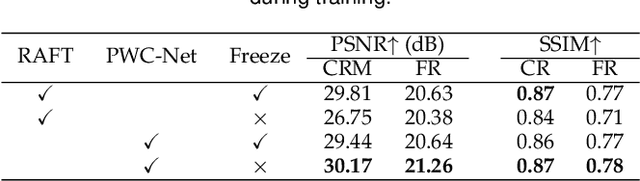
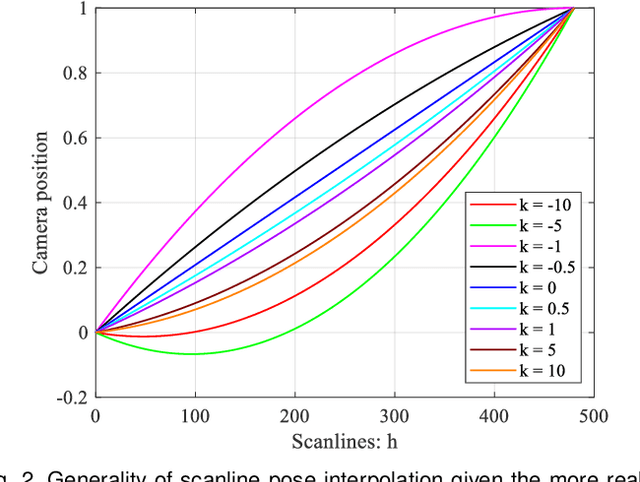
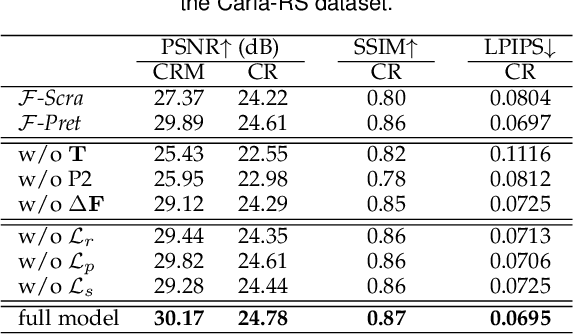
A single rolling-shutter (RS) image may be viewed as a row-wise combination of a sequence of global-shutter (GS) images captured by a (virtual) moving GS camera within the exposure duration. Although RS cameras are widely used, the RS effect causes obvious image distortion especially in the presence of fast camera motion, hindering downstream computer vision tasks. In this paper, we propose to invert the RS image capture mechanism, i.e., recovering a continuous high framerate GS video from two time-consecutive RS frames. We call this task the RS temporal super-resolution (RSSR) problem. The RSSR is a very challenging task, and to our knowledge, no practical solution exists to date. This paper presents a novel deep-learning based solution. By leveraging the multi-view geometry relationship of the RS imaging process, our learning-based framework successfully achieves high framerate GS generation. Specifically, three novel contributions can be identified: (i) novel formulations for bidirectional RS undistortion flows under constant velocity as well as constant acceleration motion model. (ii) a simple linear scaling operation, which bridges the RS undistortion flow and regular optical flow. (iii) a new mutual conversion scheme between varying RS undistortion flows that correspond to different scanlines. Our method also exploits the underlying spatial-temporal geometric relationships within a deep learning framework, where no additional supervision is required beyond the necessary middle-scanline GS image. Building upon these contributions, we represent the very first rolling-shutter temporal super-resolution deep-network that is able to recover high framerate GS videos from just two RS frames. Extensive experimental results on both synthetic and real data show that our proposed method can produce high-quality GS image sequences with rich details, outperforming the state-of-the-art methods.
One-Shot Synthesis of Images and Segmentation Masks
Sep 15, 2022
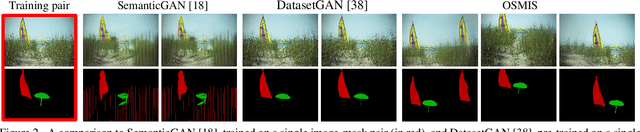
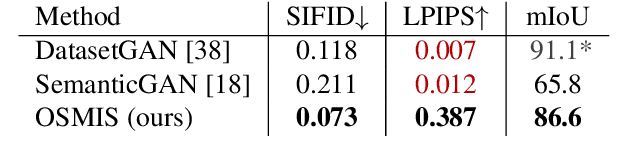
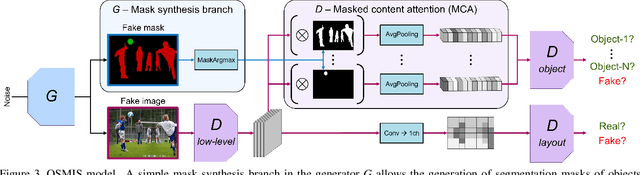
Joint synthesis of images and segmentation masks with generative adversarial networks (GANs) is promising to reduce the effort needed for collecting image data with pixel-wise annotations. However, to learn high-fidelity image-mask synthesis, existing GAN approaches first need a pre-training phase requiring large amounts of image data, which limits their utilization in restricted image domains. In this work, we take a step to reduce this limitation, introducing the task of one-shot image-mask synthesis. We aim to generate diverse images and their segmentation masks given only a single labelled example, and assuming, contrary to previous models, no access to any pre-training data. To this end, inspired by the recent architectural developments of single-image GANs, we introduce our OSMIS model which enables the synthesis of segmentation masks that are precisely aligned to the generated images in the one-shot regime. Besides achieving the high fidelity of generated masks, OSMIS outperforms state-of-the-art single-image GAN models in image synthesis quality and diversity. In addition, despite not using any additional data, OSMIS demonstrates an impressive ability to serve as a source of useful data augmentation for one-shot segmentation applications, providing performance gains that are complementary to standard data augmentation techniques. Code is available at https://github.com/ boschresearch/one-shot-synthesis
Giga-SSL: Self-Supervised Learning for Gigapixel Images
Dec 06, 2022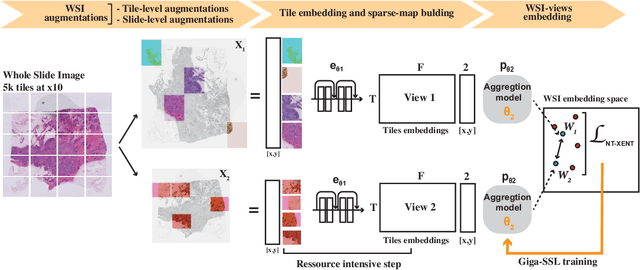
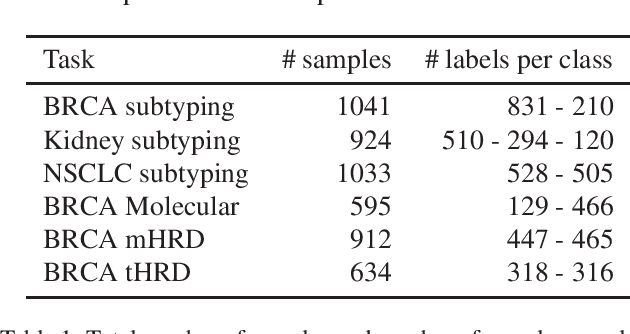
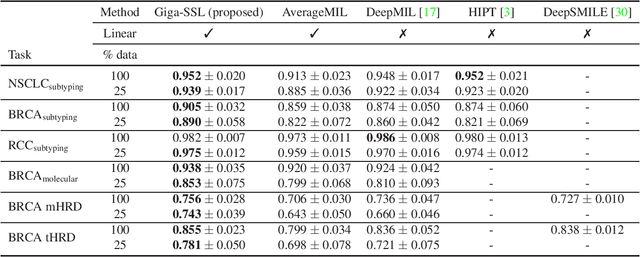
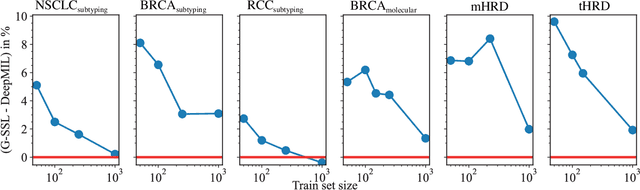
Whole slide images (WSI) are microscopy images of stained tissue slides routinely prepared for diagnosis and treatment selection in medical practice. WSI are very large (gigapixel size) and complex (made of up to millions of cells). The current state-of-the-art (SoTA) approach to classify WSI subdivides them into tiles, encodes them by pre-trained networks and applies Multiple Instance Learning (MIL) to train for specific downstream tasks. However, annotated datasets are often small, typically a few hundred to a few thousand WSI, which may cause overfitting and underperforming models. Conversely, the number of unannotated WSI is ever increasing, with datasets of tens of thousands (soon to be millions) of images available. While it has been previously proposed to use these unannotated data to identify suitable tile representations by self-supervised learning (SSL), downstream classification tasks still require full supervision because parts of the MIL architecture is not trained during tile level SSL pre-training. Here, we propose a strategy of slide level SSL to leverage the large number of WSI without annotations to infer powerful slide representations. Applying our method to The Cancer-Genome Atlas, one of the most widely used data resources in cancer research (16 TB image data), we are able to downsize the dataset to 23 MB without any loss in predictive power: we show that a linear classifier trained on top of these embeddings maintains or improves previous SoTA performances on various benchmark WSI classification tasks. Finally, we observe that training a classifier on these representations with tiny datasets (e.g. 50 slides) improved performances over SoTA by an average of +6.3 AUC points over all downstream tasks.
Single Slice Thigh CT Muscle Group Segmentation with Domain Adaptation and Self-Training
Nov 30, 2022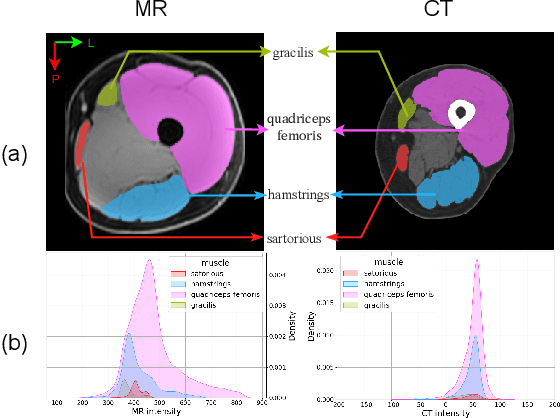
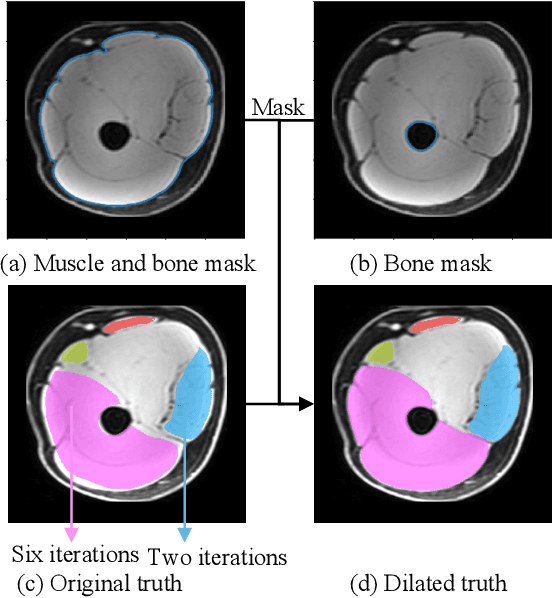
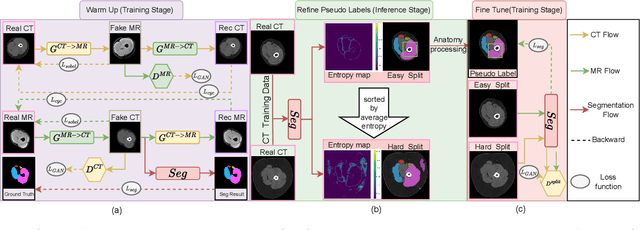
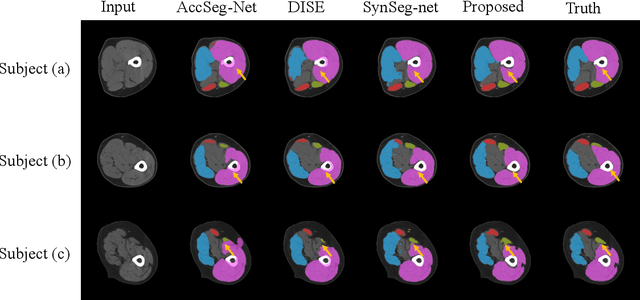
Objective: Thigh muscle group segmentation is important for assessment of muscle anatomy, metabolic disease and aging. Many efforts have been put into quantifying muscle tissues with magnetic resonance (MR) imaging including manual annotation of individual muscles. However, leveraging publicly available annotations in MR images to achieve muscle group segmentation on single slice computed tomography (CT) thigh images is challenging. Method: We propose an unsupervised domain adaptation pipeline with self-training to transfer labels from 3D MR to single CT slice. First, we transform the image appearance from MR to CT with CycleGAN and feed the synthesized CT images to a segmenter simultaneously. Single CT slices are divided into hard and easy cohorts based on the entropy of pseudo labels inferenced by the segmenter. After refining easy cohort pseudo labels based on anatomical assumption, self-training with easy and hard splits is applied to fine tune the segmenter. Results: On 152 withheld single CT thigh images, the proposed pipeline achieved a mean Dice of 0.888(0.041) across all muscle groups including sartorius, hamstrings, quadriceps femoris and gracilis. muscles Conclusion: To our best knowledge, this is the first pipeline to achieve thigh imaging domain adaptation from MR to CT. The proposed pipeline is effective and robust in extracting muscle groups on 2D single slice CT thigh images.The container is available for public use at https://github.com/MASILab/DA_CT_muscle_seg
A Tale of Two Cities: Data and Configuration Variances in Robust Deep Learning
Nov 18, 2022
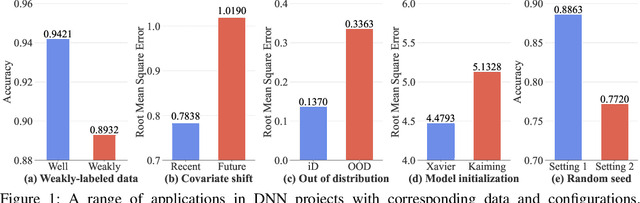
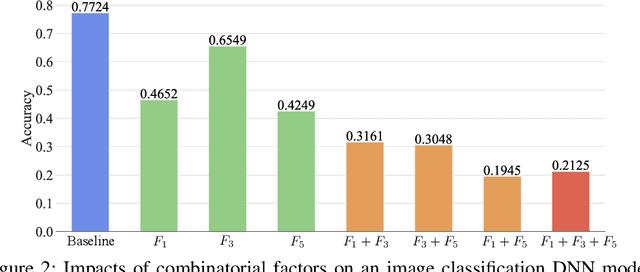
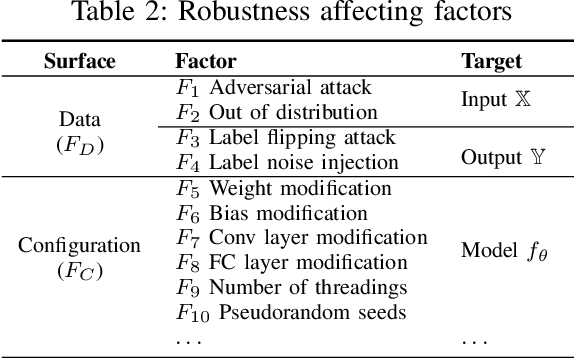
Deep neural networks (DNNs), are widely used in many industries such as image recognition, supply chain, medical diagnosis, and autonomous driving. However, prior work has shown the high accuracy of a DNN model does not imply high robustness (i.e., consistent performances on new and future datasets) because the input data and external environment (e.g., software and model configurations) for a deployed model are constantly changing. Hence, ensuring the robustness of deep learning is not an option but a priority to enhance business and consumer confidence. Previous studies mostly focus on the data aspect of model variance. In this article, we systematically summarize DNN robustness issues and formulate them in a holistic view through two important aspects, i.e., data and software configuration variances in DNNs. We also provide a predictive framework to generate representative variances (counterexamples) by considering both data and configurations for robust learning through the lens of search-based optimization.
Estimating more camera poses for ego-centric videos is essential for VQ3D
Nov 18, 2022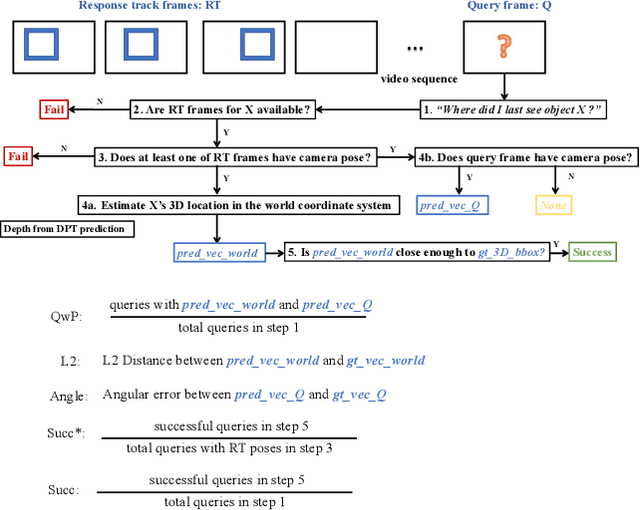

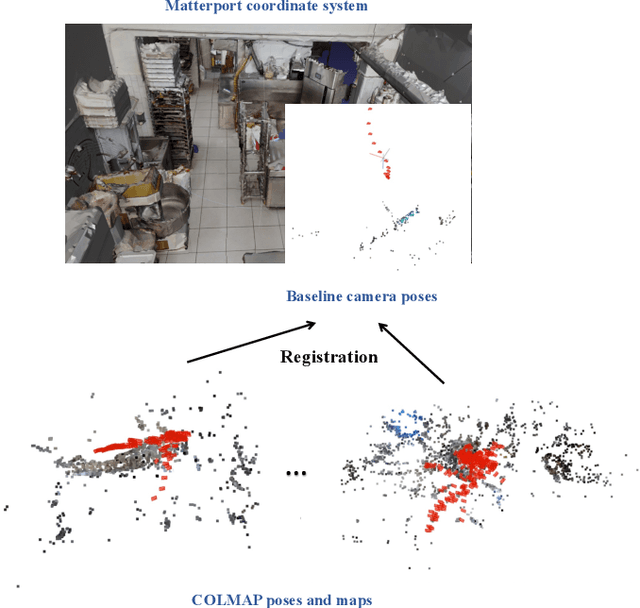

Visual queries 3D localization (VQ3D) is a task in the Ego4D Episodic Memory Benchmark. Given an egocentric video, the goal is to answer queries of the form "Where did I last see object X?", where the query object X is specified as a static image, and the answer should be a 3D displacement vector pointing to object X. However, current techniques use naive ways to estimate the camera poses of video frames, resulting in a low query with pose (QwP) ratio, thus a poor overall success rate. We design a new pipeline for the challenging egocentric video camera pose estimation problem in our work. Moreover, we revisit the current VQ3D framework and optimize it in terms of performance and efficiency. As a result, we get the top-1 overall success rate of 25.8% on VQ3D leaderboard, which is two times better than the 8.7% reported by the baseline.