 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Image Deblurring: A Survey
Jan 26, 2022

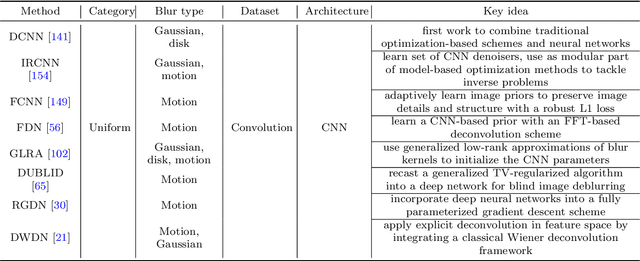
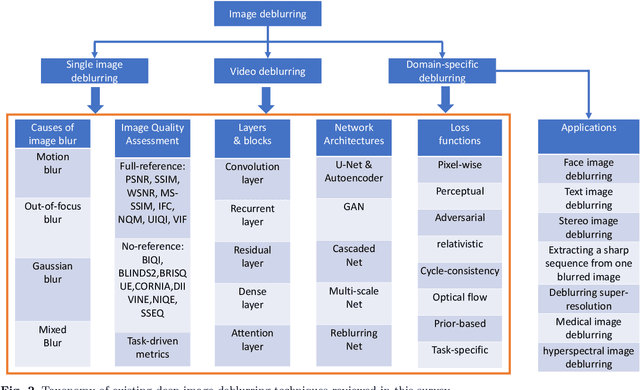
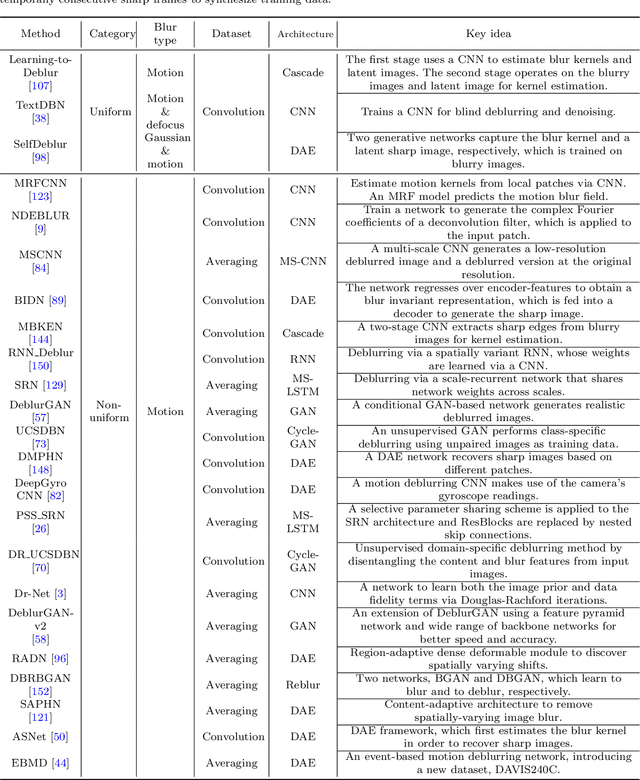
Image deblurring is a classic problem in low-level computer vision, which aims to recover a sharp image from a blurred input image. Recent advances in deep learning have led to significant progress in solving this problem, and a large number of deblurring networks have been proposed. This paper presents a comprehensive and timely survey of recently published deep-learning based image deblurring approaches, aiming to serve the community as a useful literature review. We start by discussing common causes of image blur, introduce benchmark datasets and performance metrics, and summarize different problem formulations. Next we present a taxonomy of methods using convolutional neural networks (CNN) based on architecture, loss function, and application, offering a detailed review and comparison. In addition, we discuss some domain-specific deblurring applications including face images, text, and stereo image pairs. We conclude by discussing key challenges and future research directions.
Animating Still Images
Sep 21, 2022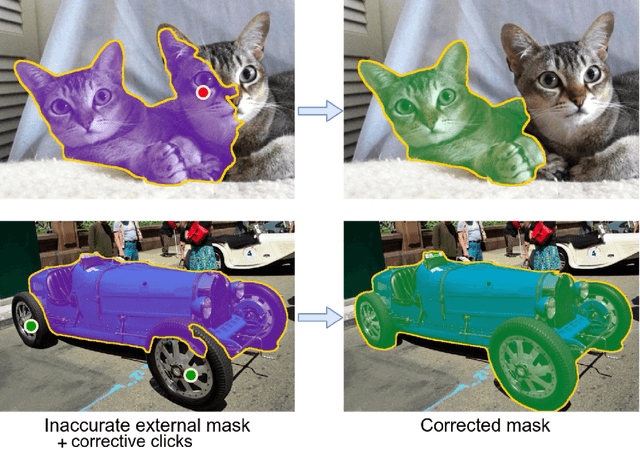
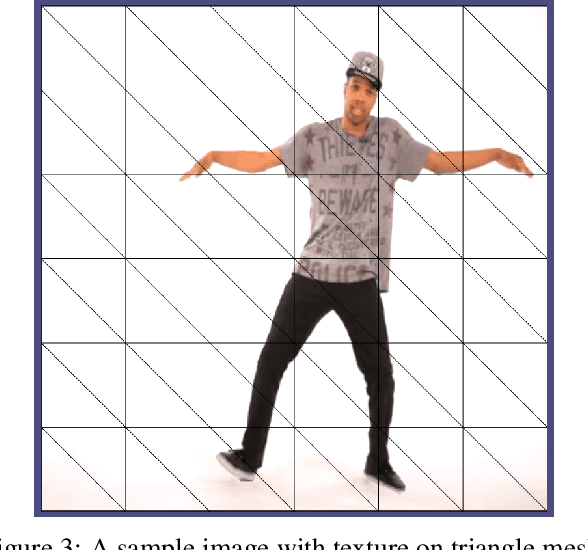
We present a method for imparting motion to a still 2D image. Our method uses deep learning to segment a section of the image denoted as subject, then uses in-painting to complete the background, and finally adds animation to the subject by embedding the image in a triangle mesh, while preserving the rest of the image.
Deep Generative Models on 3D Representations: A Survey
Oct 27, 2022
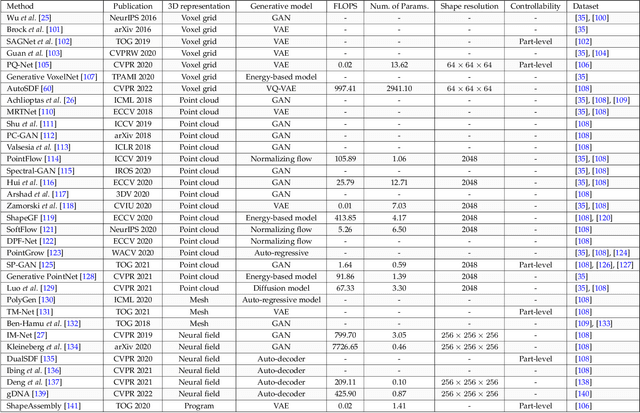
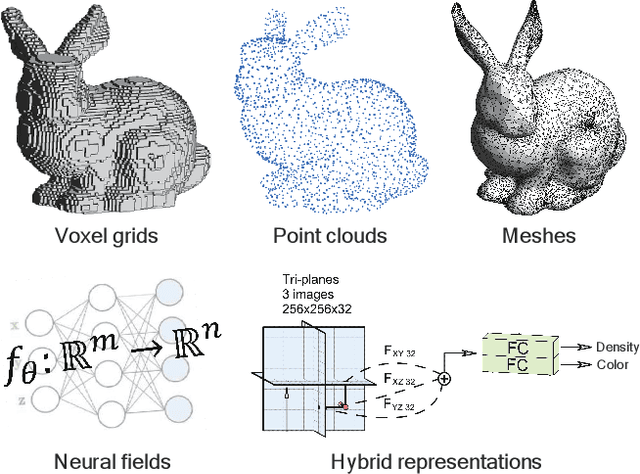

Generative models, as an important family of statistical modeling, target learning the observed data distribution via generating new instances. Along with the rise of neural networks, deep generative models, such as variational autoencoders (VAEs) and generative adversarial network (GANs), have made tremendous progress in 2D image synthesis. Recently, researchers switch their attentions from the 2D space to the 3D space considering that 3D data better aligns with our physical world and hence enjoys great potential in practice. However, unlike a 2D image, which owns an efficient representation (i.e., pixel grid) by nature, representing 3D data could face far more challenges. Concretely, we would expect an ideal 3D representation to be capable enough to model shapes and appearances in details, and to be highly efficient so as to model high-resolution data with fast speed and low memory cost. However, existing 3D representations, such as point clouds, meshes, and recent neural fields, usually fail to meet the above requirements simultaneously. In this survey, we make a thorough review of the development of 3D generation, including 3D shape generation and 3D-aware image synthesis, from the perspectives of both algorithms and more importantly representations. We hope that our discussion could help the community track the evolution of this field and further spark some innovative ideas to advance this challenging task.
StyLandGAN: A StyleGAN based Landscape Image Synthesis using Depth-map
May 13, 2022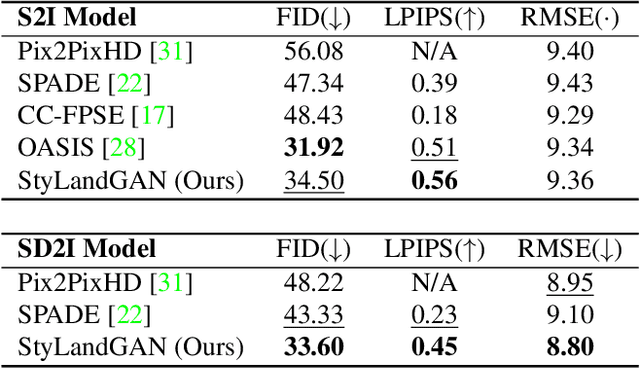

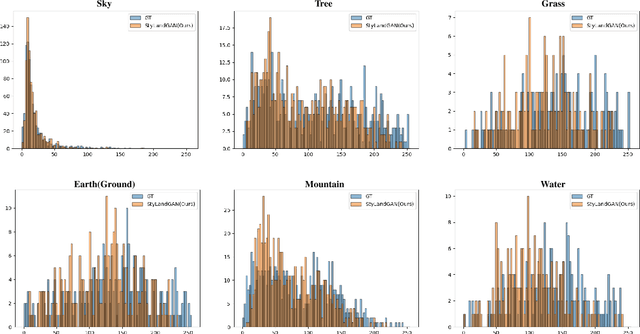
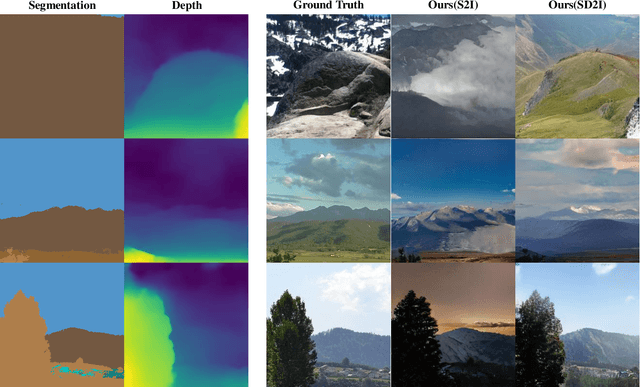
Despite recent success in conditional image synthesis, prevalent input conditions such as semantics and edges are not clear enough to express `Linear (Ridges)' and `Planar (Scale)' representations. To address this problem, we propose a novel framework StyLandGAN, which synthesizes desired landscape images using a depth map which has higher expressive power. Our StyleLandGAN is extended from the unconditional generation model to accept input conditions. We also propose a '2-phase inference' pipeline which generates diverse depth maps and shifts local parts so that it can easily reflect user's intend. As a comparison, we modified the existing semantic image synthesis models to accept a depth map as well. Experimental results show that our method is superior to existing methods in quality, diversity, and depth-accuracy.
A Targeted Sampling Strategy for Compressive Cryo Focused Ion Beam Scanning Electron Microscopy
Nov 07, 2022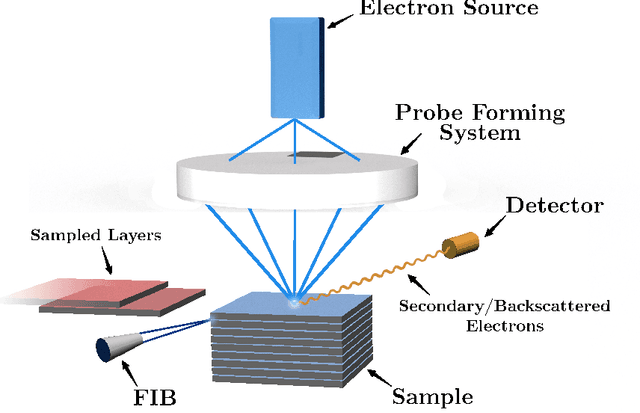
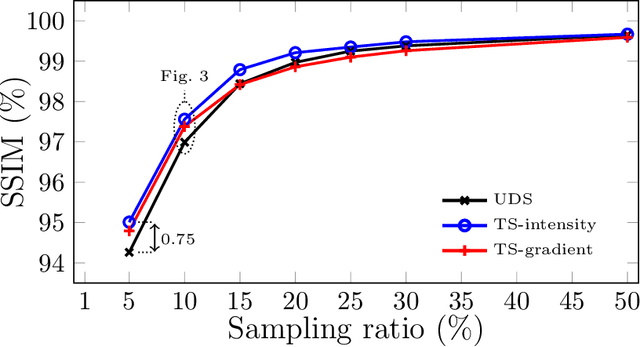

Cryo Focused Ion-Beam Scanning Electron Microscopy (cryo FIB-SEM) enables three-dimensional and nanoscale imaging of biological specimens via a slice and view mechanism. The FIB-SEM experiments are, however, limited by a slow (typically, several hours) acquisition process and the high electron doses imposed on the beam sensitive specimen can cause damage. In this work, we present a compressive sensing variant of cryo FIB-SEM capable of reducing the operational electron dose and increasing speed. We propose two Targeted Sampling (TS) strategies that leverage the reconstructed image of the previous sample layer as a prior for designing the next subsampling mask. Our image recovery is based on a blind Bayesian dictionary learning approach, i.e., Beta Process Factor Analysis (BPFA). This method is experimentally viable due to our ultra-fast GPU-based implementation of BPFA. Simulations on artificial compressive FIB-SEM measurements validate the success of proposed methods: the operational electron dose can be reduced by up to 20 times. These methods have large implications for the cryo FIB-SEM community, in which the imaging of beam sensitive biological materials without beam damage is crucial.
CycDA: Unsupervised Cycle Domain Adaptation from Image to Video
Mar 30, 2022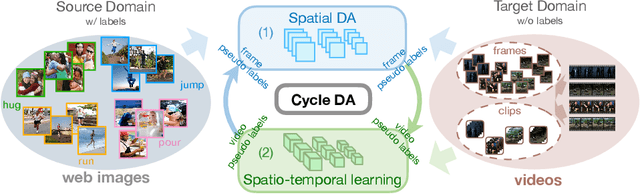
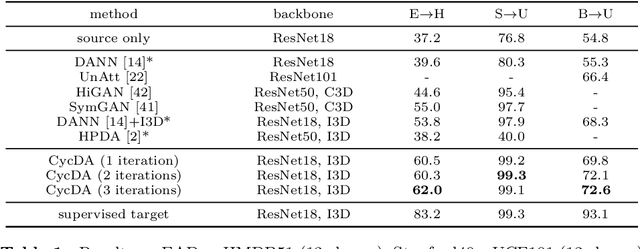
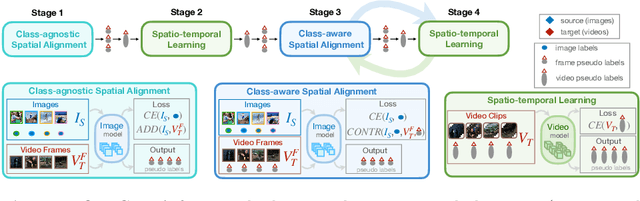
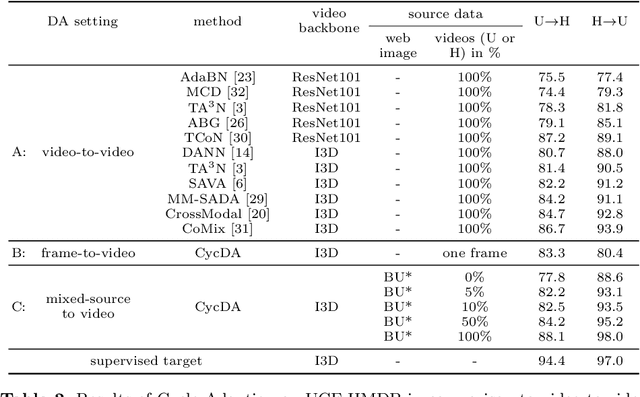
Although action recognition has achieved impressive results over recent years, both collection and annotation of video training data are still time-consuming and cost intensive. Therefore, image-to-video adaptation has been proposed to exploit labeling-free web image source for adapting on unlabeled target videos. This poses two major challenges: (1) spatial domain shift between web images and video frames; (2) modality gap between image and video data. To address these challenges, we propose Cycle Domain Adaptation (CycDA), a cycle-based approach for unsupervised image-to-video domain adaptation by leveraging the joint spatial information in images and videos on the one hand and, on the other hand, training an independent spatio-temporal model to bridge the modality gap. We alternate between the spatial and spatio-temporal learning with knowledge transfer between the two in each cycle. We evaluate our approach on benchmark datasets for image-to-video as well as for mixed-source domain adaptation achieving state-of-the-art results and demonstrating the benefits of our cyclic adaptation.
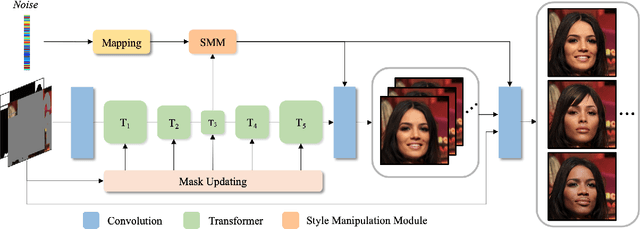
Style Transformer for Image Inversion and Editing
Mar 15, 2022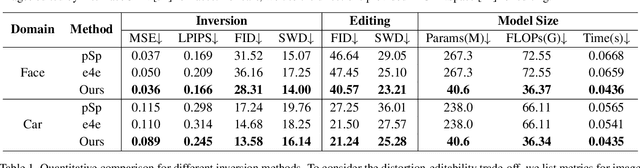
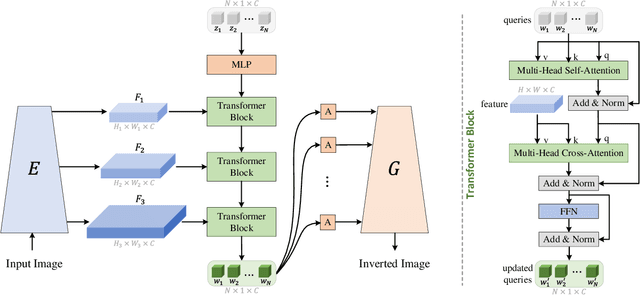
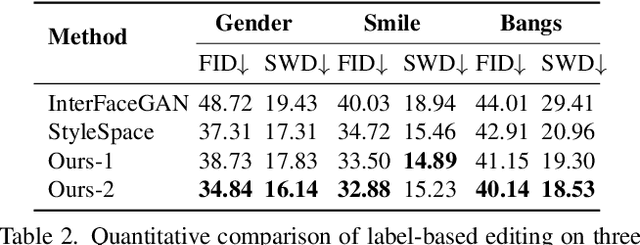
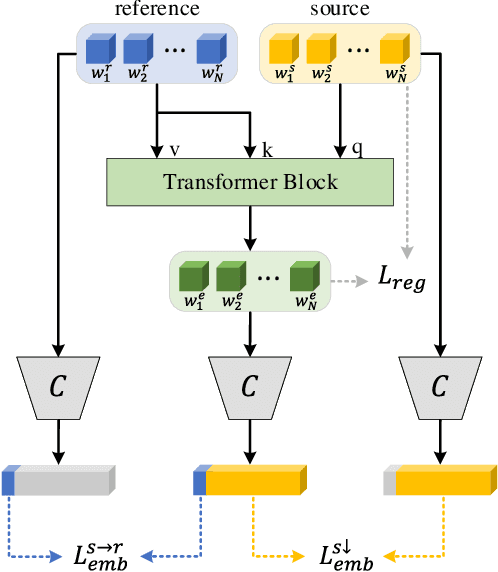
Existing GAN inversion methods fail to provide latent codes for reliable reconstruction and flexible editing simultaneously. This paper presents a transformer-based image inversion and editing model for pretrained StyleGAN which is not only with less distortions, but also of high quality and flexibility for editing. The proposed model employs a CNN encoder to provide multi-scale image features as keys and values. Meanwhile it regards the style code to be determined for different layers of the generator as queries. It first initializes query tokens as learnable parameters and maps them into W+ space. Then the multi-stage alternate self- and cross-attention are utilized, updating queries with the purpose of inverting the input by the generator. Moreover, based on the inverted code, we investigate the reference- and label-based attribute editing through a pretrained latent classifier, and achieve flexible image-to-image translation with high quality results. Extensive experiments are carried out, showing better performances on both inversion and editing tasks within StyleGAN.
XMorpher: Full Transformer for Deformable Medical Image Registration via Cross Attention
Jun 15, 2022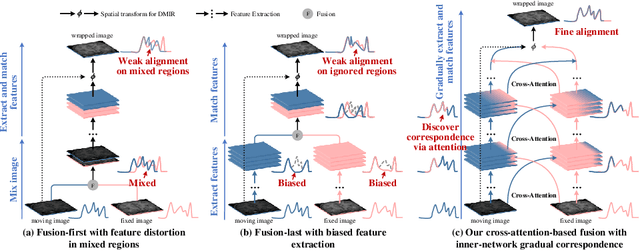
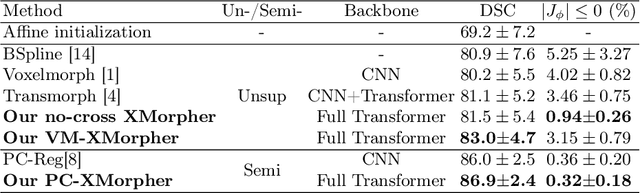
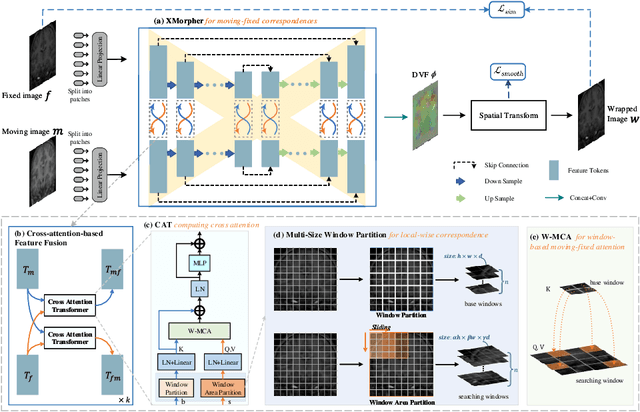
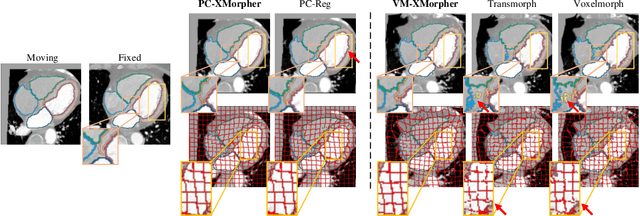
An effective backbone network is important to deep learning-based Deformable Medical Image Registration (DMIR), because it extracts and matches the features between two images to discover the mutual correspondence for fine registration. However, the existing deep networks focus on single image situation and are limited in registration task which is performed on paired images. Therefore, we advance a novel backbone network, XMorpher, for the effective corresponding feature representation in DMIR. 1) It proposes a novel full transformer architecture including dual parallel feature extraction networks which exchange information through cross attention, thus discovering multi-level semantic correspondence while extracting respective features gradually for final effective registration. 2) It advances the Cross Attention Transformer (CAT) blocks to establish the attention mechanism between images which is able to find the correspondence automatically and prompts the features to fuse efficiently in the network. 3) It constrains the attention computation between base windows and searching windows with different sizes, and thus focuses on the local transformation of deformable registration and enhances the computing efficiency at the same time. Without any bells and whistles, our XMorpher gives Voxelmorph 2.8% improvement on DSC , demonstrating its effective representation of the features from the paired images in DMIR. We believe that our XMorpher has great application potential in more paired medical images. Our XMorpher is open on https://github.com/Solemoon/XMorpher
Physically-Based Editing of Indoor Scene Lighting from a Single Image
May 19, 2022
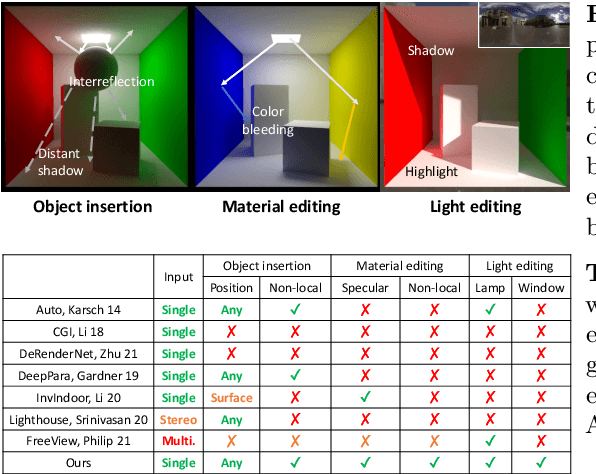
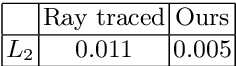
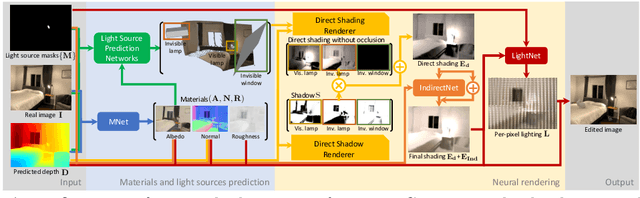
We present a method to edit complex indoor lighting from a single image with its predicted depth and light source segmentation masks. This is an extremely challenging problem that requires modeling complex light transport, and disentangling HDR lighting from material and geometry with only a partial LDR observation of the scene. We tackle this problem using two novel components: 1) a holistic scene reconstruction method that estimates scene reflectance and parametric 3D lighting, and 2) a neural rendering framework that re-renders the scene from our predictions. We use physically-based indoor light representations that allow for intuitive editing, and infer both visible and invisible light sources. Our neural rendering framework combines physically-based direct illumination and shadow rendering with deep networks to approximate global illumination. It can capture challenging lighting effects, such as soft shadows, directional lighting, specular materials, and interreflections. Previous single image inverse rendering methods usually entangle scene lighting and geometry and only support applications like object insertion. Instead, by combining parametric 3D lighting estimation with neural scene rendering, we demonstrate the first automatic method to achieve full scene relighting, including light source insertion, removal, and replacement, from a single image. All source code and data will be publicly released.
SketchySGD: Reliable Stochastic Optimization via Robust Curvature Estimates
Dec 02, 2022
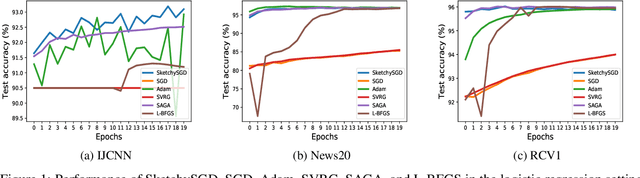
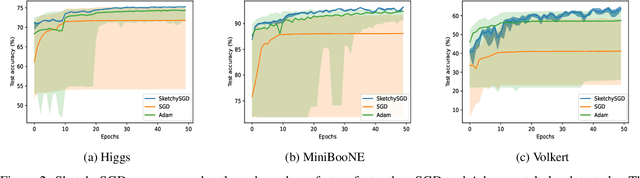
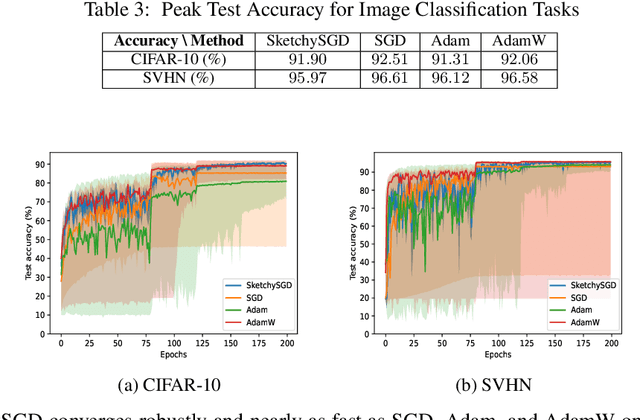
We introduce SketchySGD, a stochastic quasi-Newton method that uses sketching to approximate the curvature of the loss function. Quasi-Newton methods are among the most effective algorithms in traditional optimization, where they converge much faster than first-order methods such as SGD. However, for contemporary deep learning, quasi-Newton methods are considered inferior to first-order methods like SGD and Adam owing to higher per-iteration complexity and fragility due to inexact gradients. SketchySGD circumvents these issues by a novel combination of subsampling, randomized low-rank approximation, and dynamic regularization. In the convex case, we show SketchySGD with a fixed stepsize converges to a small ball around the optimum at a faster rate than SGD for ill-conditioned problems. In the non-convex case, SketchySGD converges linearly under two additional assumptions, interpolation and the Polyak-Lojaciewicz condition, the latter of which holds with high probability for wide neural networks. Numerical experiments on image and tabular data demonstrate the improved reliability and speed of SketchySGD for deep learning, compared to standard optimizers such as SGD and Adam and existing quasi-Newton methods.