 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Modeling Image Composition for Complex Scene Generation
Jun 02, 2022
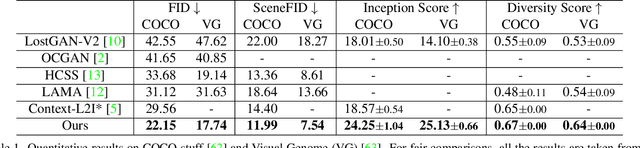
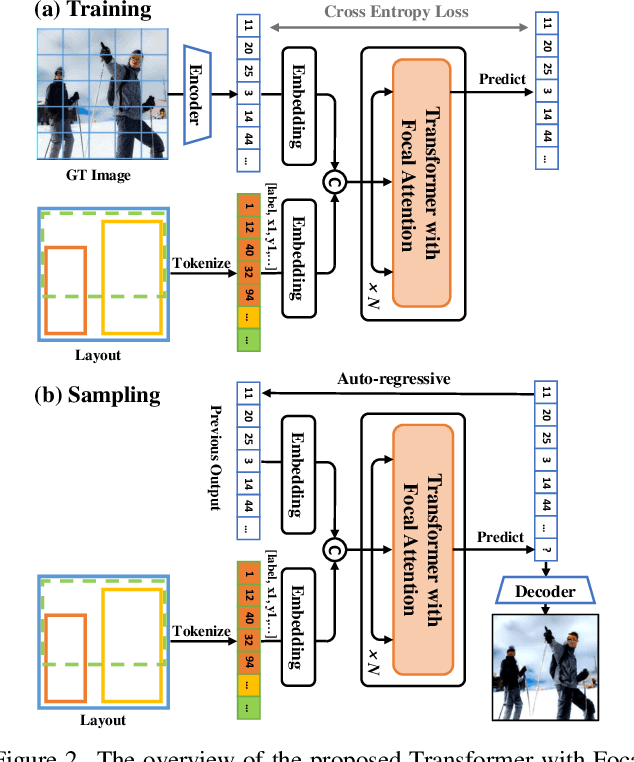
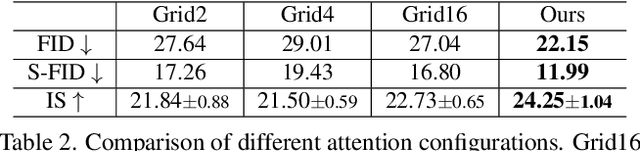
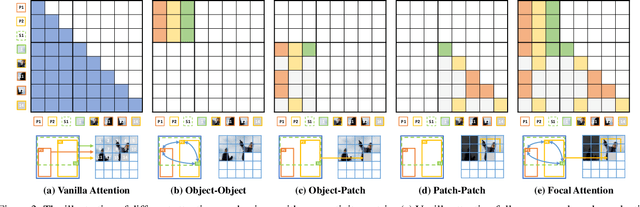
We present a method that achieves state-of-the-art results on challenging (few-shot) layout-to-image generation tasks by accurately modeling textures, structures and relationships contained in a complex scene. After compressing RGB images into patch tokens, we propose the Transformer with Focal Attention (TwFA) for exploring dependencies of object-to-object, object-to-patch and patch-to-patch. Compared to existing CNN-based and Transformer-based generation models that entangled modeling on pixel-level&patch-level and object-level&patch-level respectively, the proposed focal attention predicts the current patch token by only focusing on its highly-related tokens that specified by the spatial layout, thereby achieving disambiguation during training. Furthermore, the proposed TwFA largely increases the data efficiency during training, therefore we propose the first few-shot complex scene generation strategy based on the well-trained TwFA. Comprehensive experiments show the superiority of our method, which significantly increases both quantitative metrics and qualitative visual realism with respect to state-of-the-art CNN-based and transformer-based methods. Code is available at https://github.com/JohnDreamer/TwFA.
MonoGraspNet: 6-DoF Grasping with a Single RGB Image
Sep 26, 2022
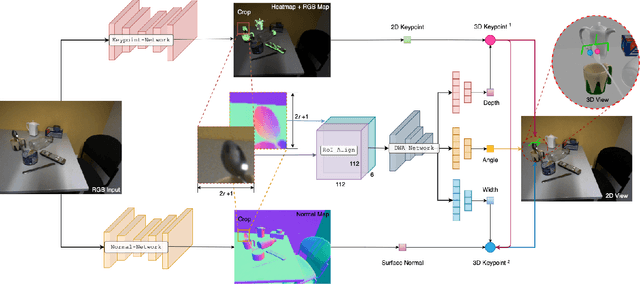
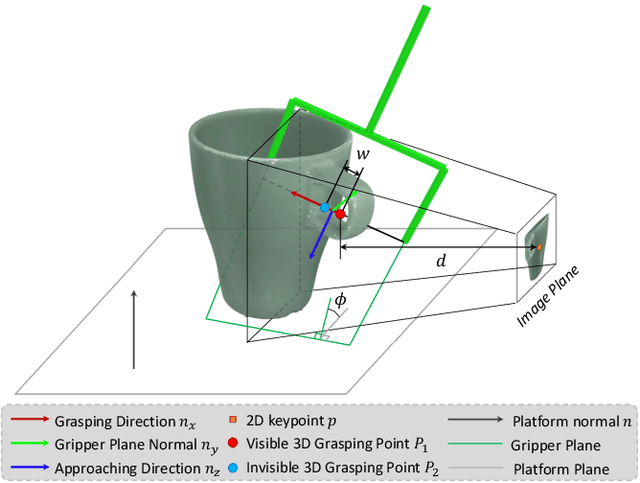

6-DoF robotic grasping is a long-lasting but unsolved problem. Recent methods utilize strong 3D networks to extract geometric grasping representations from depth sensors, demonstrating superior accuracy on common objects but perform unsatisfactorily on photometrically challenging objects, e.g., objects in transparent or reflective materials. The bottleneck lies in that the surface of these objects can not reflect back accurate depth due to the absorption or refraction of light. In this paper, in contrast to exploiting the inaccurate depth data, we propose the first RGB-only 6-DoF grasping pipeline called MonoGraspNet that utilizes stable 2D features to simultaneously handle arbitrary object grasping and overcome the problems induced by photometrically challenging objects. MonoGraspNet leverages keypoint heatmap and normal map to recover the 6-DoF grasping poses represented by our novel representation parameterized with 2D keypoints with corresponding depth, grasping direction, grasping width, and angle. Extensive experiments in real scenes demonstrate that our method can achieve competitive results in grasping common objects and surpass the depth-based competitor by a large margin in grasping photometrically challenging objects. To further stimulate robotic manipulation research, we additionally annotate and open-source a multi-view and multi-scene real-world grasping dataset, containing 120 objects of mixed photometric complexity with 20M accurate grasping labels.
CAISE: Conversational Agent for Image Search and Editing
Feb 24, 2022
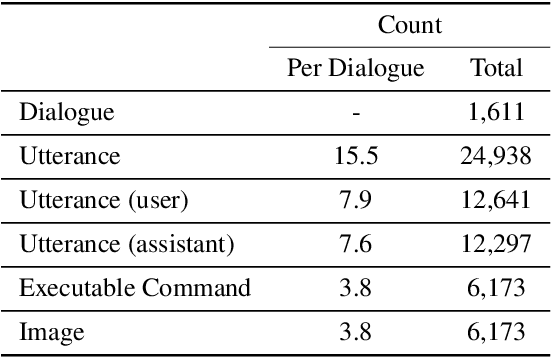

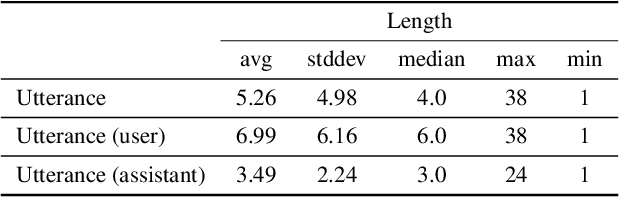
Demand for image editing has been increasing as users' desire for expression is also increasing. However, for most users, image editing tools are not easy to use since the tools require certain expertise in photo effects and have complex interfaces. Hence, users might need someone to help edit their images, but having a personal dedicated human assistant for every user is impossible to scale. For that reason, an automated assistant system for image editing is desirable. Additionally, users want more image sources for diverse image editing works, and integrating an image search functionality into the editing tool is a potential remedy for this demand. Thus, we propose a dataset of an automated Conversational Agent for Image Search and Editing (CAISE). To our knowledge, this is the first dataset that provides conversational image search and editing annotations, where the agent holds a grounded conversation with users and helps them to search and edit images according to their requests. To build such a system, we first collect image search and editing conversations between pairs of annotators. The assistant-annotators are equipped with a customized image search and editing tool to address the requests from the user-annotators. The functions that the assistant-annotators conduct with the tool are recorded as executable commands, allowing the trained system to be useful for real-world application execution. We also introduce a generator-extractor baseline model for this task, which can adaptively select the source of the next token (i.e., from the vocabulary or from textual/visual contexts) for the executable command. This serves as a strong starting point while still leaving a large human-machine performance gap for useful future work. Our code and dataset are publicly available at: https://github.com/hyounghk/CAISE
Inharmonious Region Localization with Auxiliary Style Feature
Oct 05, 2022

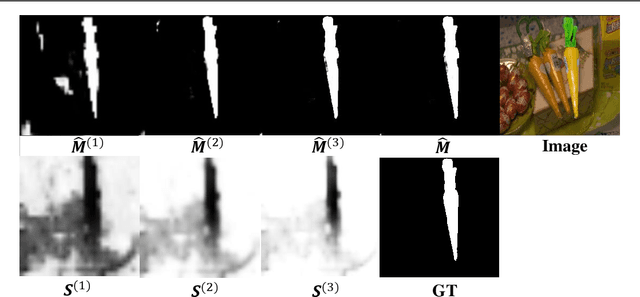
With the prevalence of image editing techniques, users can create fantastic synthetic images, but the image quality may be compromised by the color/illumination discrepancy between the manipulated region and background. Inharmonious region localization aims to localize the inharmonious region in a synthetic image. In this work, we attempt to leverage auxiliary style feature to facilitate this task. Specifically, we propose a novel color mapping module and a style feature loss to extract discriminative style features containing task-relevant color/illumination information. Based on the extracted style features, we also propose a novel style voting module to guide the localization of inharmonious region. Moreover, we introduce semantic information into the style voting module to achieve further improvement. Our method surpasses the existing methods by a large margin on the benchmark dataset.
Using Language to Extend to Unseen Domains
Oct 20, 2022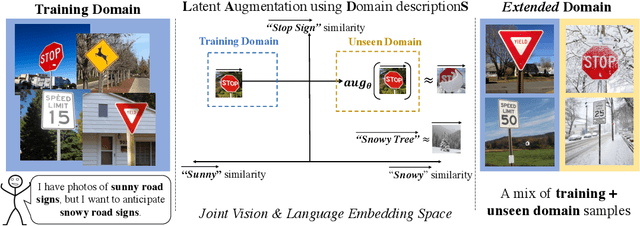
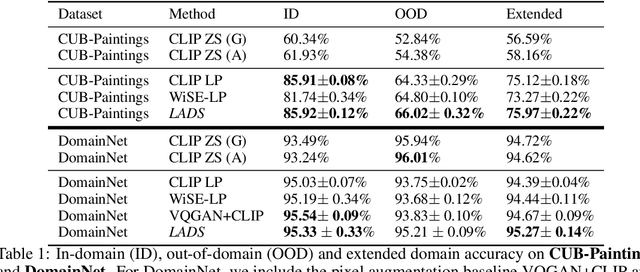
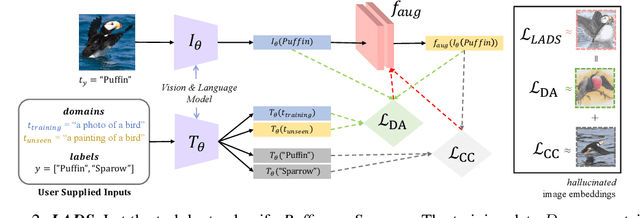

It is expensive to collect training data for every possible domain that a vision model may encounter when deployed. We instead consider how simply verbalizing the training domain (e.g. "photos of birds") as well as domains we want to extend to but do not have data for (e.g. "paintings of birds") can improve robustness. Using a multimodal model with a joint image and language embedding space, our method LADS learns a transformation of the image embeddings from the training domain to each unseen test domain, while preserving task relevant information. Without using any images from the unseen test domain, we show that over the extended domain containing both training and unseen test domains, LADS outperforms standard fine-tuning and ensemble approaches over a suite of four benchmarks targeting domain adaptation and dataset bias
Automating Cobb Angle Measurement for Adolescent Idiopathic Scoliosis using Instance Segmentation
Nov 25, 2022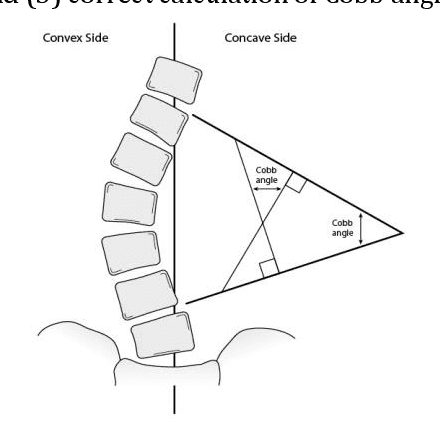
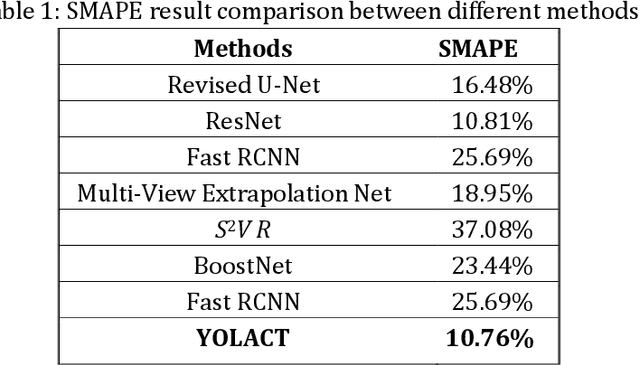
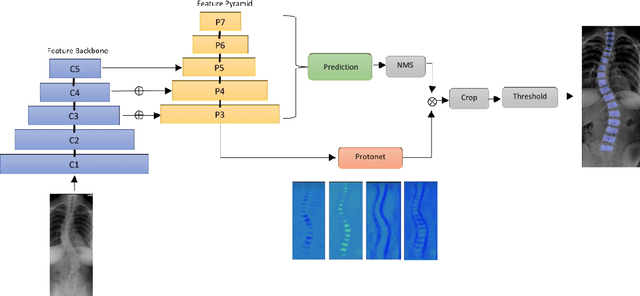

Scoliosis is a three-dimensional deformity of the spine, most often diagnosed in childhood. It affects 2-3% of the population, which is approximately seven million people in North America. Currently, the reference standard for assessing scoliosis is based on the manual assignment of Cobb angles at the site of the curvature center. This manual process is time consuming and unreliable as it is affected by inter- and intra-observer variance. To overcome these inaccuracies, machine learning (ML) methods can be used to automate the Cobb angle measurement process. This paper proposes to address the Cobb angle measurement task using YOLACT, an instance segmentation model. The proposed method first segments the vertebrae in an X-Ray image using YOLACT, then it tracks the important landmarks using the minimum bounding box approach. Lastly, the extracted landmarks are used to calculate the corresponding Cobb angles. The model achieved a Symmetric Mean Absolute Percentage Error (SMAPE) score of 10.76%, demonstrating the reliability of this process in both vertebra localization and Cobb angle measurement.
Ladder Siamese Network: a Method and Insights for Multi-level Self-Supervised Learning
Nov 25, 2022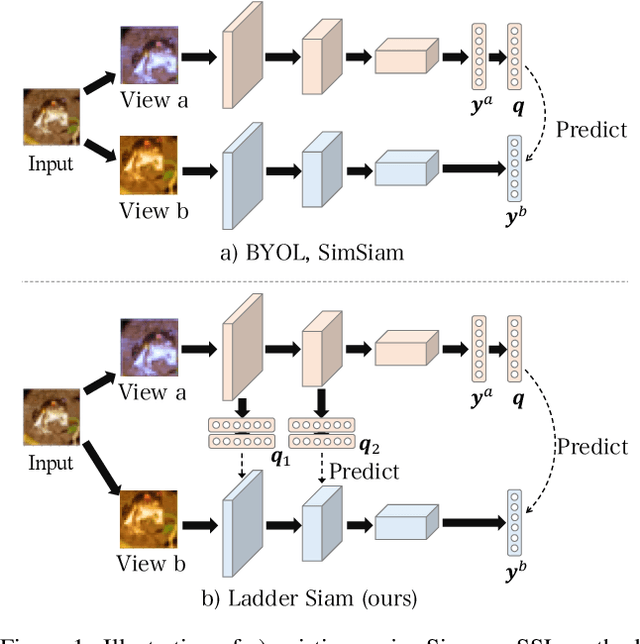
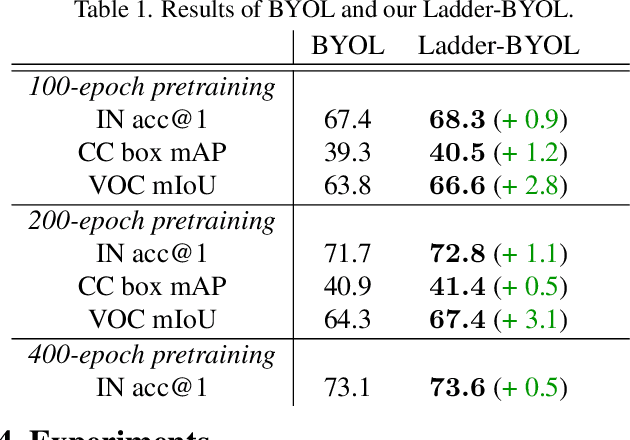
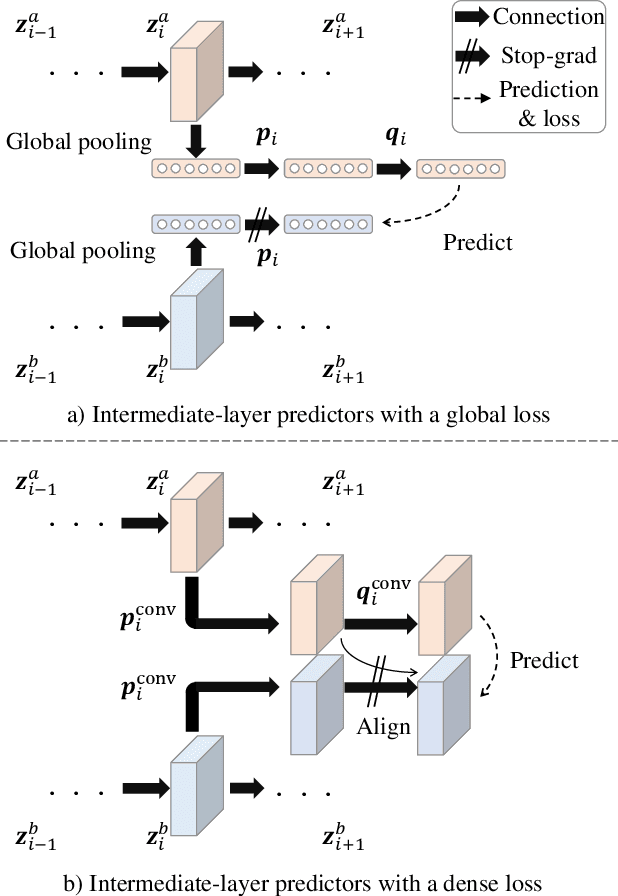
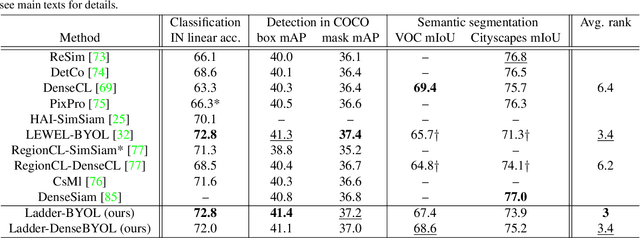
Siamese-network-based self-supervised learning (SSL) suffers from slow convergence and instability in training. To alleviate this, we propose a framework to exploit intermediate self-supervisions in each stage of deep nets, called the Ladder Siamese Network. Our self-supervised losses encourage the intermediate layers to be consistent with different data augmentations to single samples, which facilitates training progress and enhances the discriminative ability of the intermediate layers themselves. While some existing work has already utilized multi-level self supervisions in SSL, ours is different in that 1) we reveal its usefulness with non-contrastive Siamese frameworks in both theoretical and empirical viewpoints, and 2) ours improves image-level classification, instance-level detection, and pixel-level segmentation simultaneously. Experiments show that the proposed framework can improve BYOL baselines by 1.0% points in ImageNet linear classification, 1.2% points in COCO detection, and 3.1% points in PASCAL VOC segmentation. In comparison with the state-of-the-art methods, our Ladder-based model achieves competitive and balanced performances in all tested benchmarks without causing large degradation in one.
Reliability-based Mesh-to-Grid Image Reconstruction
May 20, 2022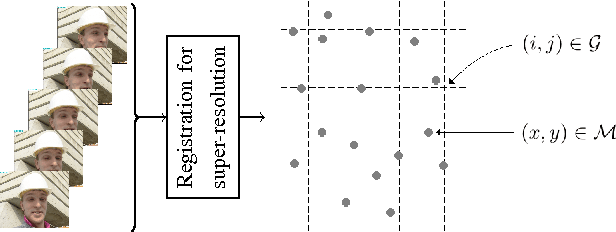
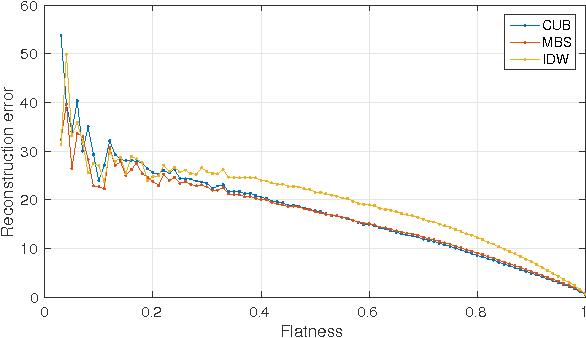
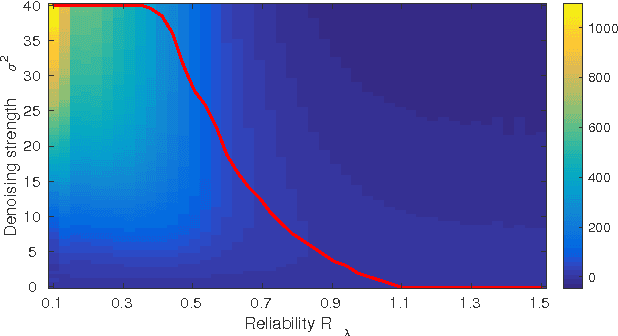

This paper presents a novel method for the reconstruction of images from samples located at non-integer positions, called mesh. This is a common scenario for many image processing applications, such as super-resolution, warping or virtual view generation in multi-camera systems. The proposed method relies on a set of initial estimates that are later refined by a new reliability-based content-adaptive framework that employs denoising in order to reduce the reconstruction error. The reliability of the initial estimate is computed so stronger denoising is applied to less reliable estimates. The proposed technique can improve the reconstruction quality by more than 2 dB (in terms of PSNR) with respect to the initial estimate and it outperforms the state-of-the-art denoising-based refinement by up to 0.7 dB.
RegCLR: A Self-Supervised Framework for Tabular Representation Learning in the Wild
Nov 02, 2022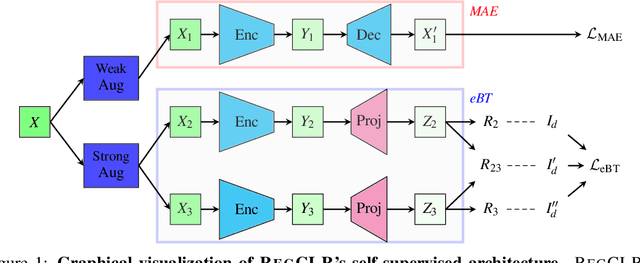
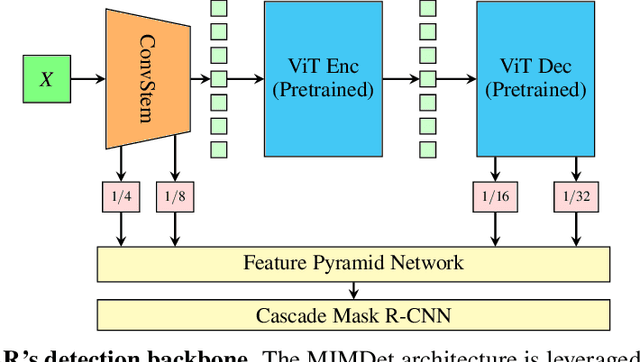
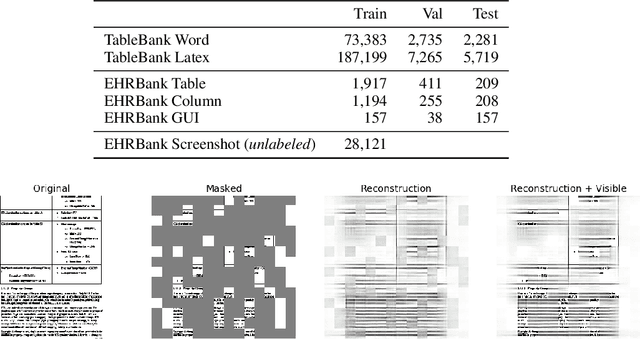
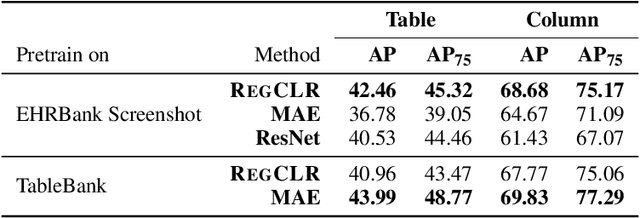
Recent advances in self-supervised learning (SSL) using large models to learn visual representations from natural images are rapidly closing the gap between the results produced by fully supervised learning and those produced by SSL on downstream vision tasks. Inspired by this advancement and primarily motivated by the emergence of tabular and structured document image applications, we investigate which self-supervised pretraining objectives, architectures, and fine-tuning strategies are most effective. To address these questions, we introduce RegCLR, a new self-supervised framework that combines contrastive and regularized methods and is compatible with the standard Vision Transformer architecture. Then, RegCLR is instantiated by integrating masked autoencoders as a representative example of a contrastive method and enhanced Barlow Twins as a representative example of a regularized method with configurable input image augmentations in both branches. Several real-world table recognition scenarios (e.g., extracting tables from document images), ranging from standard Word and Latex documents to even more challenging electronic health records (EHR) computer screen images, have been shown to benefit greatly from the representations learned from this new framework, with detection average-precision (AP) improving relatively by 4.8% for Table, 11.8% for Column, and 11.1% for GUI objects over a previous fully supervised baseline on real-world EHR screen images.
Lightweight Image Enhancement Network for Mobile Devices Using Self-Feature Extraction and Dense Modulation
May 02, 2022
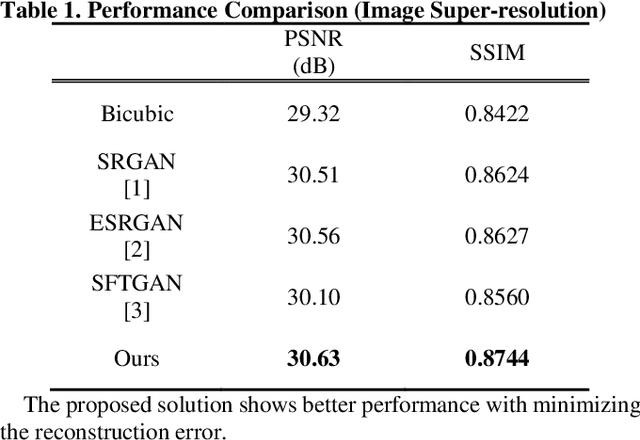
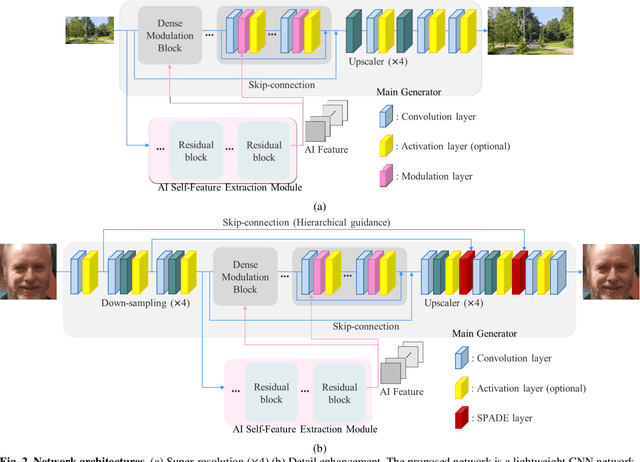

Convolutional neural network (CNN) based image enhancement methods such as super-resolution and detail enhancement have achieved remarkable performances. However, amounts of operations including convolution and parameters within the networks cost high computing power and need huge memory resource, which limits the applications with on-device requirements. Lightweight image enhancement network should restore details, texture, and structural information from low-resolution input images while keeping their fidelity. To address these issues, a lightweight image enhancement network is proposed. The proposed network include self-feature extraction module which produces modulation parameters from low-quality image itself, and provides them to modulate the features in the network. Also, dense modulation block is proposed for unit block of the proposed network, which uses dense connections of concatenated features applied in modulation layers. Experimental results demonstrate better performance over existing approaches in terms of both quantitative and qualitative evaluations.