 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Supervised Learning with Multi-View Rendering for 3D Point Cloud Analysis
Oct 28, 2022
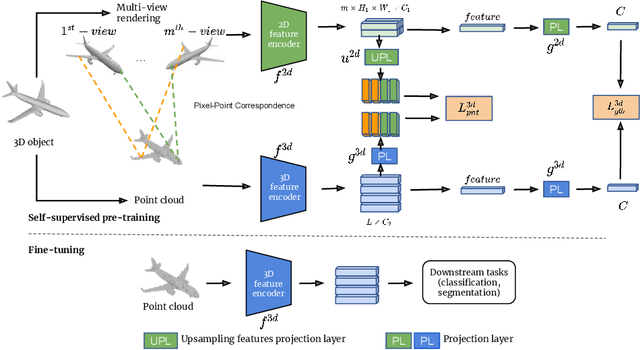
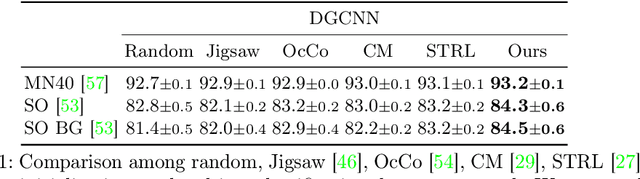
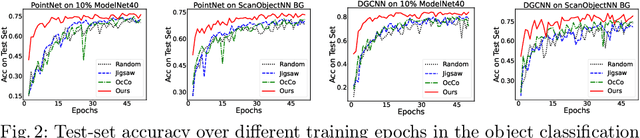
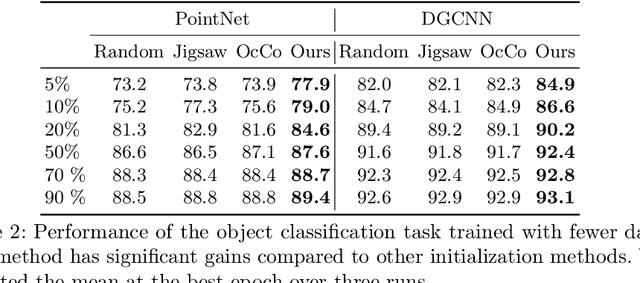
Recently, great progress has been made in 3D deep learning with the emergence of deep neural networks specifically designed for 3D point clouds. These networks are often trained from scratch or from pre-trained models learned purely from point cloud data. Inspired by the success of deep learning in the image domain, we devise a novel pre-training technique for better model initialization by utilizing the multi-view rendering of the 3D data. Our pre-training is self-supervised by a local pixel/point level correspondence loss computed from perspective projection and a global image/point cloud level loss based on knowledge distillation, thus effectively improving upon popular point cloud networks, including PointNet, DGCNN and SR-UNet. These improved models outperform existing state-of-the-art methods on various datasets and downstream tasks. We also analyze the benefits of synthetic and real data for pre-training, and observe that pre-training on synthetic data is also useful for high-level downstream tasks. Code and pre-trained models are available at https://github.com/VinAIResearch/selfsup_pcd.
Deep Learning-Based Anomaly Detection in Synthetic Aperture Radar Imaging
Oct 28, 2022
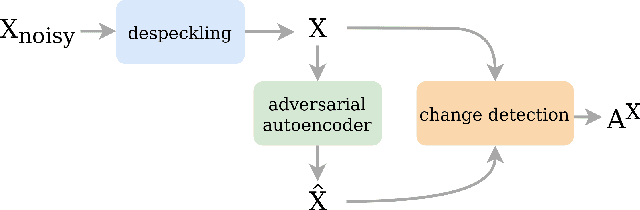

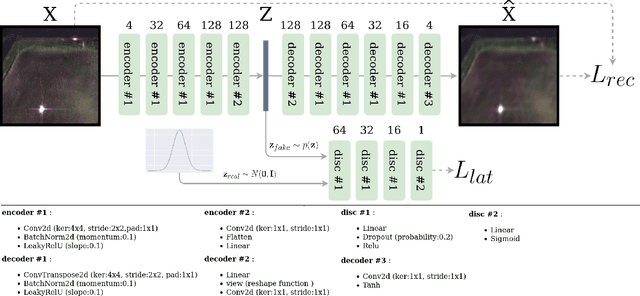
In this paper, we proposed to investigate unsupervised anomaly detection in Synthetic Aperture Radar (SAR) images. Our approach considers anomalies as abnormal patterns that deviate from their surroundings but without any prior knowledge of their characteristics. In the literature, most model-based algorithms face three main issues. First, the speckle noise corrupts the image and potentially leads to numerous false detections. Second, statistical approaches may exhibit deficiencies in modeling spatial correlation in SAR images. Finally, neural networks based on supervised learning approaches are not recommended due to the lack of annotated SAR data, notably for the class of abnormal patterns. Our proposed method aims to address these issues through a self-supervised algorithm. The speckle is first removed through the deep learning SAR2SAR algorithm. Then, an adversarial autoencoder is trained to reconstruct an anomaly-free SAR image. Finally, a change detection processing step is applied between the input and the output to detect anomalies. Experiments are performed to show the advantages of our method compared to the conventional Reed-Xiaoli algorithm, highlighting the importance of an efficient despeckling pre-processing step.
Design of Convolutional Extreme Learning Machines for Vision-Based Navigation Around Small Bodies
Oct 28, 2022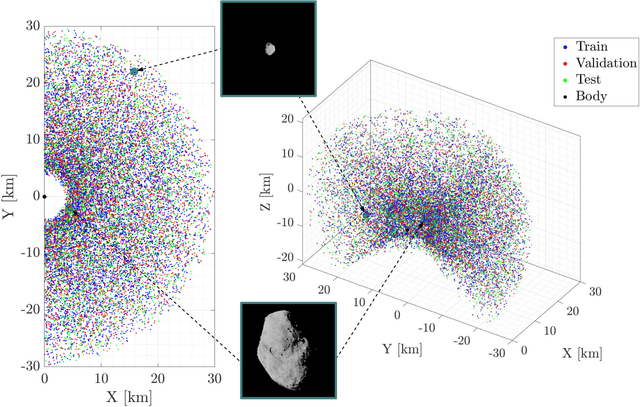
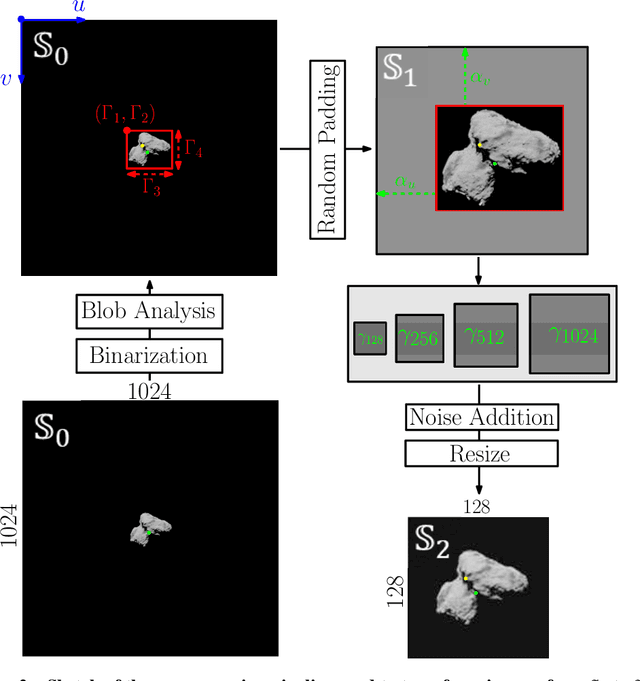
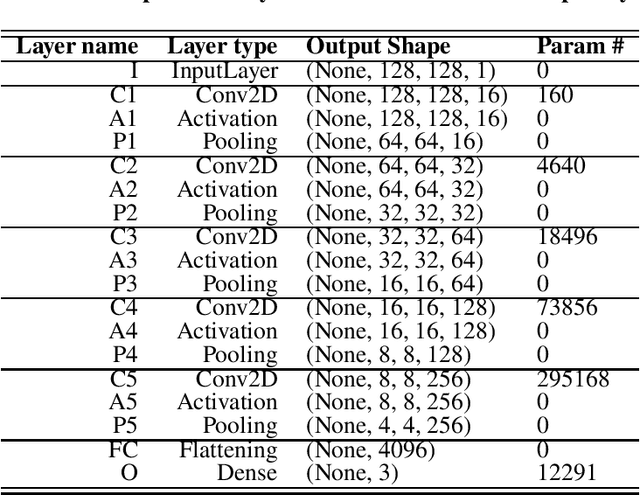
Deep learning architectures such as convolutional neural networks are the standard in computer vision for image processing tasks. Their accuracy however often comes at the cost of long and computationally expensive training, the need for large annotated datasets, and extensive hyper-parameter searches. On the other hand, a different method known as convolutional extreme learning machine has shown the potential to perform equally with a dramatic decrease in training time. Space imagery, especially about small bodies, could be well suited for this method. In this work, convolutional extreme learning machine architectures are designed and tested against their deep-learning counterparts. Because of the relatively fast training time of the former, convolutional extreme learning machine architectures enable efficient exploration of the architecture design space, which would have been impractical with the latter, introducing a methodology for an efficient design of a neural network architecture for computer vision tasks. Also, the coupling between the image processing method and labeling strategy is investigated and demonstrated to play a major role when considering vision-based navigation around small bodies.
Near-Infrared Depth-Independent Image Dehazing using Haar Wavelets
Mar 26, 2022
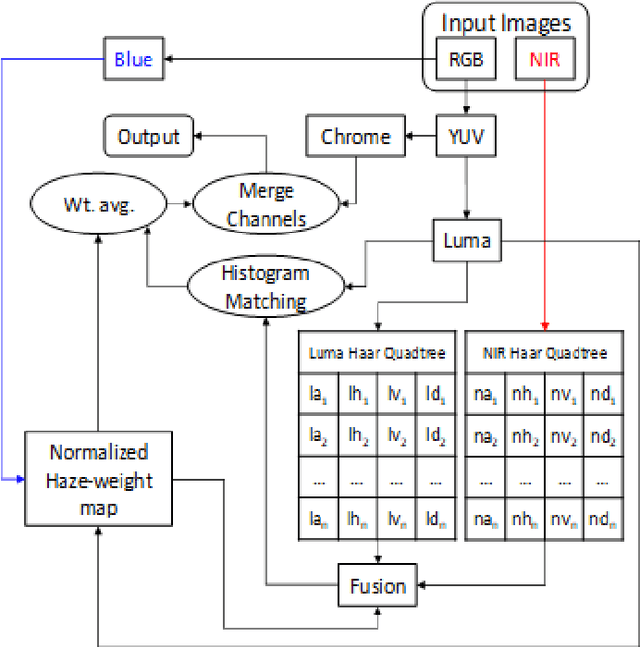
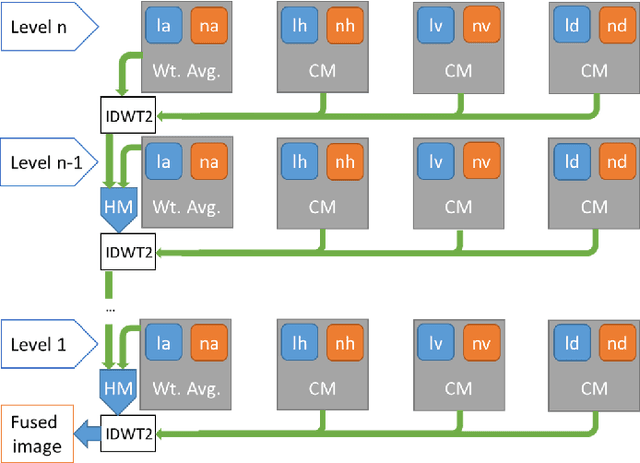
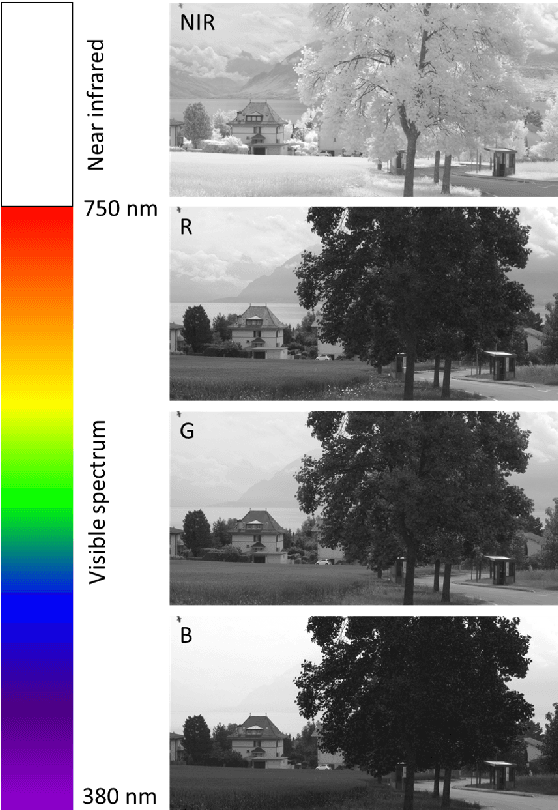
We propose a fusion algorithm for haze removal that combines color information from an RGB image and edge information extracted from its corresponding NIR image using Haar wavelets. The proposed algorithm is based on the key observation that NIR edge features are more prominent in the hazy regions of the image than the RGB edge features in those same regions. To combine the color and edge information, we introduce a haze-weight map which proportionately distributes the color and edge information during the fusion process. Because NIR images are, intrinsically, nearly haze-free, our work makes no assumptions like existing works that rely on a scattering model and essentially designing a depth-independent method. This helps in minimizing artifacts and gives a more realistic sense to the restored haze-free image. Extensive experiments show that the proposed algorithm is both qualitatively and quantitatively better on several key metrics when compared to existing state-of-the-art methods.
* Accepted in 25th International Conference on Pattern Recognition (ICPR 2020)
Realtime Fewshot Portrait Stylization Based On Geometric Alignment
Nov 28, 2022
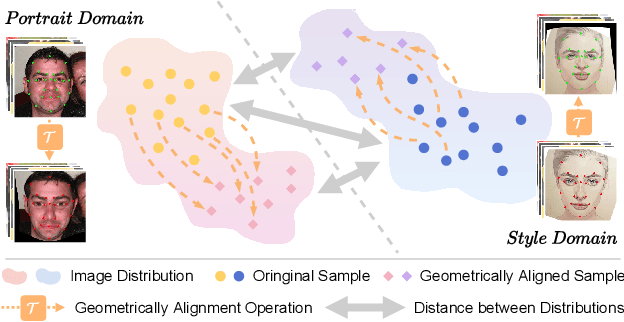
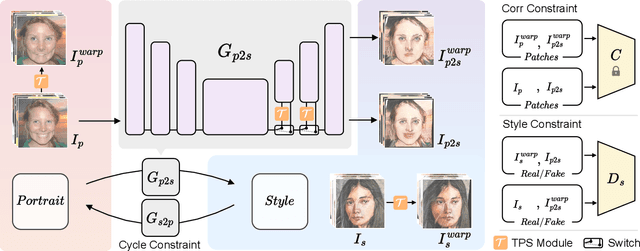
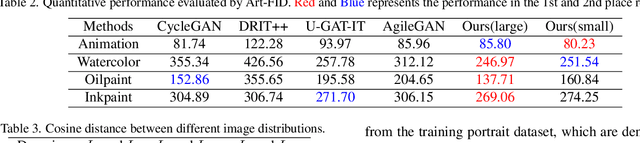
This paper presents a portrait stylization method designed for real-time mobile applications with limited style examples available. Previous learning based stylization methods suffer from the geometric and semantic gaps between portrait domain and style domain, which obstacles the style information to be correctly transferred to the portrait images, leading to poor stylization quality. Based on the geometric prior of human facial attributions, we propose to utilize geometric alignment to tackle this issue. Firstly, we apply Thin-Plate-Spline (TPS) on feature maps in the generator network and also directly to style images in pixel space, generating aligned portrait-style image pairs with identical landmarks, which closes the geometric gaps between two domains. Secondly, adversarial learning maps the textures and colors of portrait images to the style domain. Finally, geometric aware cycle consistency preserves the content and identity information unchanged, and deformation invariant constraint suppresses artifacts and distortions. Qualitative and quantitative comparison validate our method outperforms existing methods, and experiments proof our method could be trained with limited style examples (100 or less) in real-time (more than 40 FPS) on mobile devices. Ablation study demonstrates the effectiveness of each component in the framework.
SuS-X: Training-Free Name-Only Transfer of Vision-Language Models
Nov 28, 2022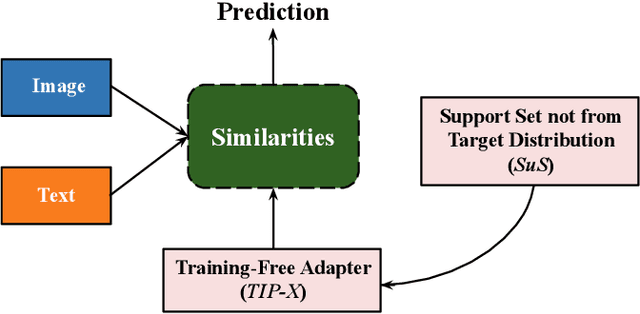
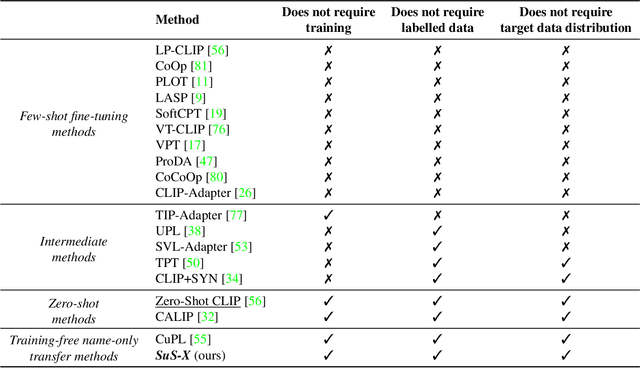
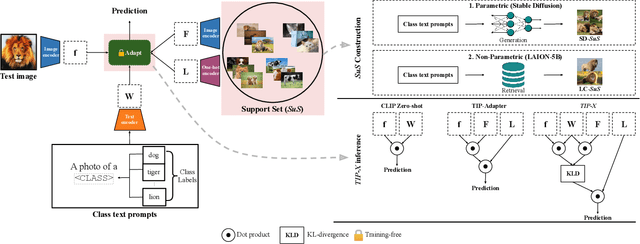
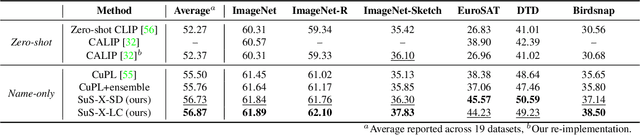
Contrastive Language-Image Pre-training (CLIP) has emerged as a simple yet effective way to train large-scale vision-language models. CLIP demonstrates impressive zero-shot classification and retrieval on diverse downstream tasks. However, to leverage its full potential, fine-tuning still appears to be necessary. Fine-tuning the entire CLIP model can be resource-intensive and unstable. Moreover, recent methods that aim to circumvent this need for fine-tuning still require access to images from the target distribution. In this paper, we pursue a different approach and explore the regime of training-free "name-only transfer" in which the only knowledge we possess about the downstream task comprises the names of downstream target categories. We propose a novel method, SuS-X, consisting of two key building blocks -- SuS and TIP-X, that requires neither intensive fine-tuning nor costly labelled data. SuS-X achieves state-of-the-art zero-shot classification results on 19 benchmark datasets. We further show the utility of TIP-X in the training-free few-shot setting, where we again achieve state-of-the-art results over strong training-free baselines. Code is available at https://github.com/vishaal27/SuS-X.
Generating 2D and 3D Master Faces for Dictionary Attacks with a Network-Assisted Latent Space Evolution
Nov 28, 2022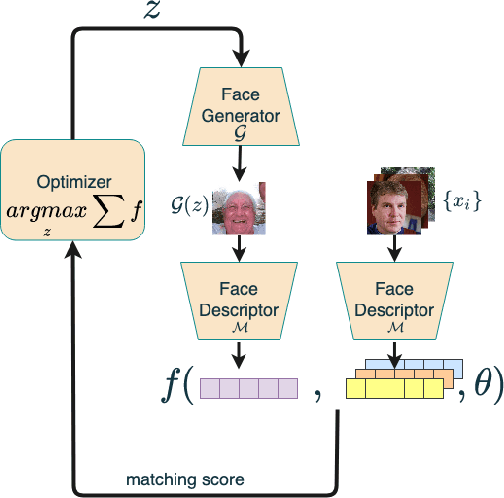
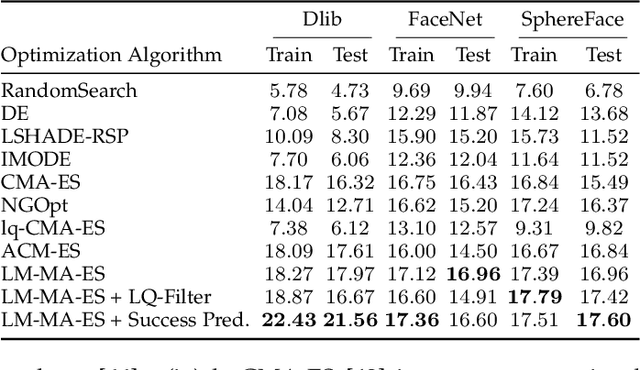
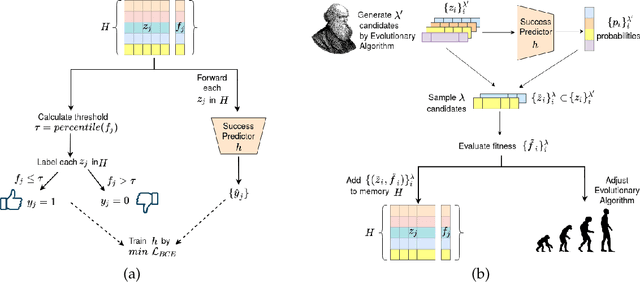
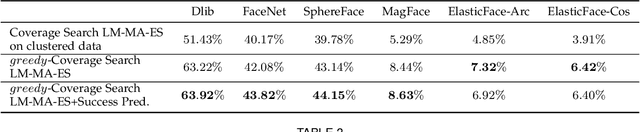
A master face is a face image that passes face-based identity authentication for a high percentage of the population. These faces can be used to impersonate, with a high probability of success, any user, without having access to any user information. We optimize these faces for 2D and 3D face verification models, by using an evolutionary algorithm in the latent embedding space of the StyleGAN face generator. For 2D face verification, multiple evolutionary strategies are compared, and we propose a novel approach that employs a neural network to direct the search toward promising samples, without adding fitness evaluations. The results we present demonstrate that it is possible to obtain a considerable coverage of the identities in the LFW or RFW datasets with less than 10 master faces, for six leading deep face recognition systems. In 3D, we generate faces using the 2D StyleGAN2 generator and predict a 3D structure using a deep 3D face reconstruction network. When employing two different 3D face recognition systems, we are able to obtain a coverage of 40%-50%. Additionally, we present the generation of paired 2D RGB and 3D master faces, which simultaneously match 2D and 3D models with high impersonation rates.
Image Captioning In the Transformer Age
Apr 15, 2022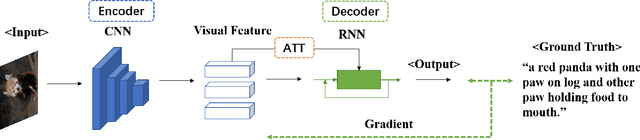
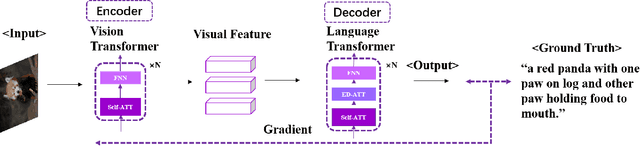
Image Captioning (IC) has achieved astonishing developments by incorporating various techniques into the CNN-RNN encoder-decoder architecture. However, since CNN and RNN do not share the basic network component, such a heterogeneous pipeline is hard to be trained end-to-end where the visual encoder will not learn anything from the caption supervision. This drawback inspires the researchers to develop a homogeneous architecture that facilitates end-to-end training, for which Transformer is the perfect one that has proven its huge potential in both vision and language domains and thus can be used as the basic component of the visual encoder and language decoder in an IC pipeline. Meantime, self-supervised learning releases the power of the Transformer architecture that a pre-trained large-scale one can be generalized to various tasks including IC. The success of these large-scale models seems to weaken the importance of the single IC task. However, we demonstrate that IC still has its specific significance in this age by analyzing the connections between IC with some popular self-supervised learning paradigms. Due to the page limitation, we only refer to highly important papers in this short survey and more related works can be found at https://github.com/SjokerLily/awesome-image-captioning.
Multi-View Consistent Generative Adversarial Networks for 3D-aware Image Synthesis
Apr 13, 2022
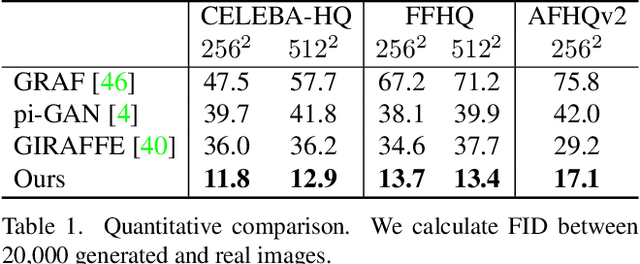
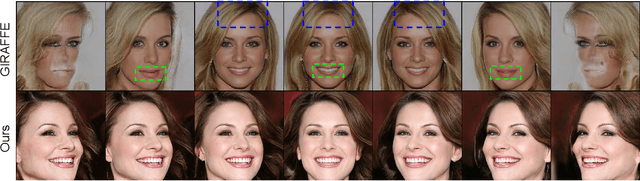
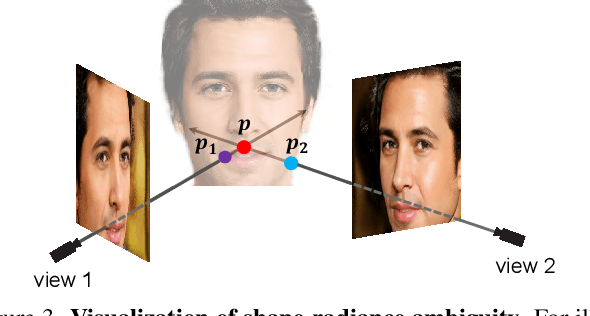
3D-aware image synthesis aims to generate images of objects from multiple views by learning a 3D representation. However, one key challenge remains: existing approaches lack geometry constraints, hence usually fail to generate multi-view consistent images. To address this challenge, we propose Multi-View Consistent Generative Adversarial Networks (MVCGAN) for high-quality 3D-aware image synthesis with geometry constraints. By leveraging the underlying 3D geometry information of generated images, i.e., depth and camera transformation matrix, we explicitly establish stereo correspondence between views to perform multi-view joint optimization. In particular, we enforce the photometric consistency between pairs of views and integrate a stereo mixup mechanism into the training process, encouraging the model to reason about the correct 3D shape. Besides, we design a two-stage training strategy with feature-level multi-view joint optimization to improve the image quality. Extensive experiments on three datasets demonstrate that MVCGAN achieves the state-of-the-art performance for 3D-aware image synthesis.
PAEDID: Patch Autoencoder Based Deep Image Decomposition For Pixel-level Defective Region Segmentation
Apr 11, 2022
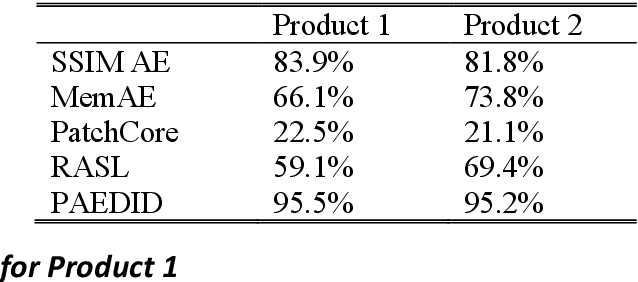

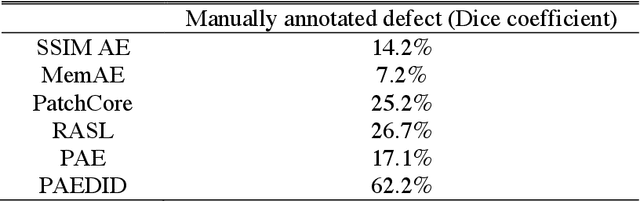
Unsupervised pixel-level defective region segmentation is an important task in image-based anomaly detection for various industrial applications. The state-of-the-art methods have their own advantages and limitations: matrix-decomposition-based methods are robust to noise but lack complex background image modeling capability; representation-based methods are good at defective region localization but lack accuracy in defective region shape contour extraction; reconstruction-based methods detected defective region match well with the ground truth defective region shape contour but are noisy. To combine the best of both worlds, we present an unsupervised patch autoencoder based deep image decomposition (PAEDID) method for defective region segmentation. In the training stage, we learn the common background as a deep image prior by a patch autoencoder (PAE) network. In the inference stage, we formulate anomaly detection as an image decomposition problem with the deep image prior and domain-specific regularizations. By adopting the proposed approach, the defective regions in the image can be accurately extracted in an unsupervised fashion. We demonstrate the effectiveness of the PAEDID method in simulation studies and an industrial dataset in the case study.