 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The transport problem for non-additive measures
Dec 08, 2022
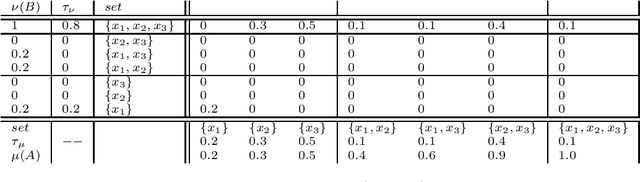
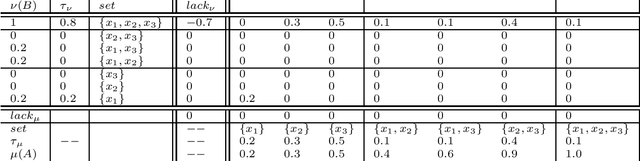
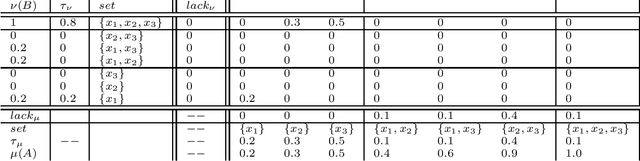

Non-additive measures, also known as fuzzy measures, capacities, and monotonic games, are increasingly used in different fields. Applications have been built within computer science and artificial intelligence related to e.g. decision making, image processing, machine learning for both classification, and regression. Tools for measure identification have been built. In short, as non-additive measures are more general than additive ones (i.e., than probabilities), they have better modeling capabilities allowing to model situations and problems that cannot be modeled by the latter. See e.g. the application of non-additive measures and the Choquet integral to model both Ellsberg paradox and Allais paradox. Because of that, there is an increasing need to analyze non-additive measures. The need for distances and similarities to compare them is no exception. Some work has been done for defining $f$-divergence for them. In this work we tackle the problem of defining the optimal transport problem for non-additive measures. Distances for pairs of probability distributions based on the optimal transport are extremely used in practical applications, and they are being studied extensively for their mathematical properties. We consider that it is necessary to provide appropriate definitions with a similar flavour, and that generalize the standard ones, for non-additive measures. We provide definitions based on the M\"obius transform, but also based on the $(\max, +)$-transform that we consider that has some advantages. We will discuss in this paper the problems that arise to define the transport problem for non-additive measures, and discuss ways to solve them. In this paper we provide the definitions of the optimal transport problem, and prove some properties.
Cross-view Geo-localization via Learning Disentangled Geometric Layout Correspondence
Dec 08, 2022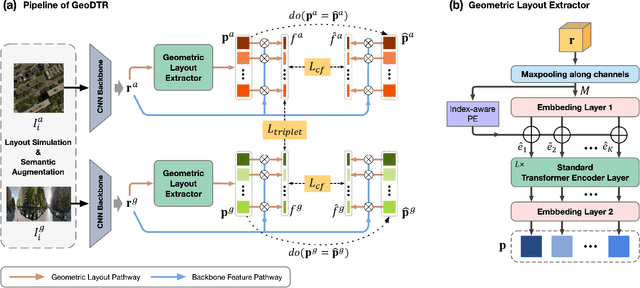
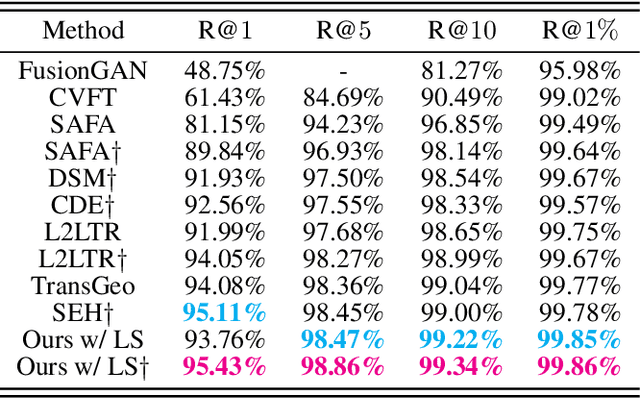

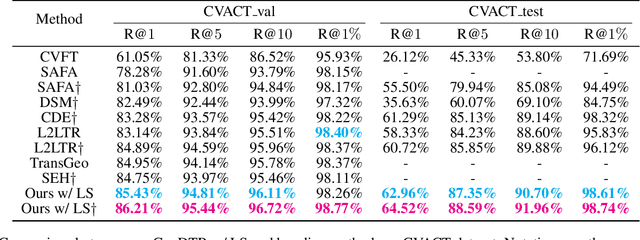
Cross-view geo-localization aims to estimate the location of a query ground image by matching it to a reference geo-tagged aerial images database. As an extremely challenging task, its difficulties root in the drastic view changes and different capturing time between two views. Despite these difficulties, recent works achieve outstanding progress on cross-view geo-localization benchmarks. However, existing methods still suffer from poor performance on the cross-area benchmarks, in which the training and testing data are captured from two different regions. We attribute this deficiency to the lack of ability to extract the spatial configuration of visual feature layouts and models' overfitting on low-level details from the training set. In this paper, we propose GeoDTR which explicitly disentangles geometric information from raw features and learns the spatial correlations among visual features from aerial and ground pairs with a novel geometric layout extractor module. This module generates a set of geometric layout descriptors, modulating the raw features and producing high-quality latent representations. In addition, we elaborate on two categories of data augmentations, (i) Layout simulation, which varies the spatial configuration while keeping the low-level details intact. (ii) Semantic augmentation, which alters the low-level details and encourages the model to capture spatial configurations. These augmentations help to improve the performance of the cross-view geo-localization models, especially on the cross-area benchmarks. Moreover, we propose a counterfactual-based learning process to benefit the geometric layout extractor in exploring spatial information. Extensive experiments show that GeoDTR not only achieves state-of-the-art results but also significantly boosts the performance on same-area and cross-area benchmarks.
R2C-GAN: Restore-to-Classify GANs for Blind X-Ray Restoration and COVID-19 Classification
Sep 29, 2022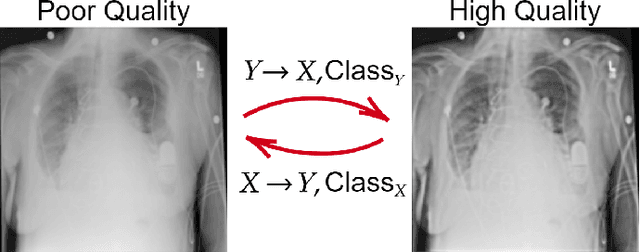
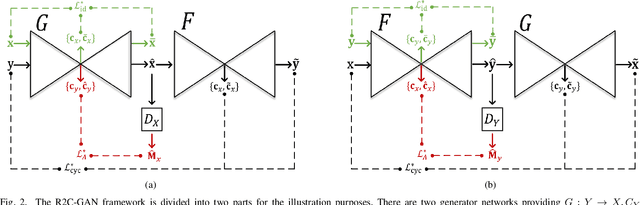
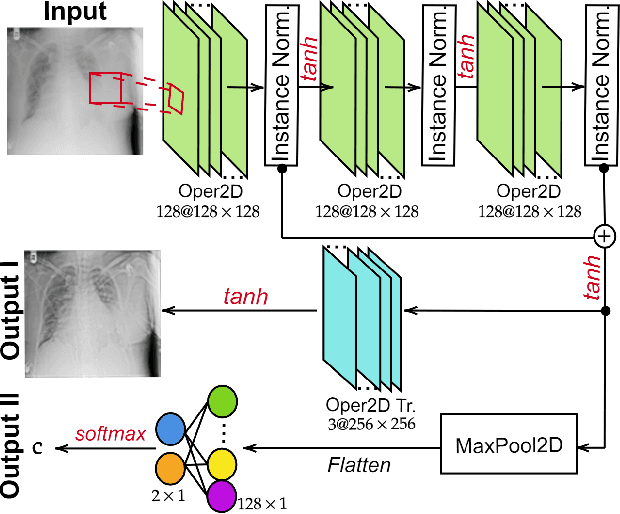
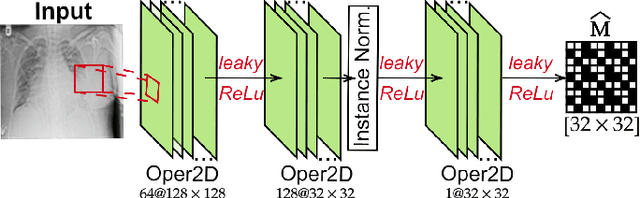
Restoration of poor quality images with a blended set of artifacts plays a vital role for a reliable diagnosis. Existing studies have focused on specific restoration problems such as image deblurring, denoising, and exposure correction where there is usually a strong assumption on the artifact type and severity. As a pioneer study in blind X-ray restoration, we propose a joint model for generic image restoration and classification: Restore-to-Classify Generative Adversarial Networks (R2C-GANs). Such a jointly optimized model keeps any disease intact after the restoration. Therefore, this will naturally lead to a higher diagnosis performance thanks to the improved X-ray image quality. To accomplish this crucial objective, we define the restoration task as an Image-to-Image translation problem from poor quality having noisy, blurry, or over/under-exposed images to high quality image domain. The proposed R2C-GAN model is able to learn forward and inverse transforms between the two domains using unpaired training samples. Simultaneously, the joint classification preserves the disease label during restoration. Moreover, the R2C-GANs are equipped with operational layers/neurons reducing the network depth and further boosting both restoration and classification performances. The proposed joint model is extensively evaluated over the QaTa-COV19 dataset for Coronavirus Disease 2019 (COVID-19) classification. The proposed restoration approach achieves over 90% F1-Score which is significantly higher than the performance of any deep model. Moreover, in the qualitative analysis, the restoration performance of R2C-GANs is approved by a group of medical doctors. We share the software implementation at https://github.com/meteahishali/R2C-GAN.
DALL-E-Bot: Introducing Web-Scale Diffusion Models to Robotics
Oct 05, 2022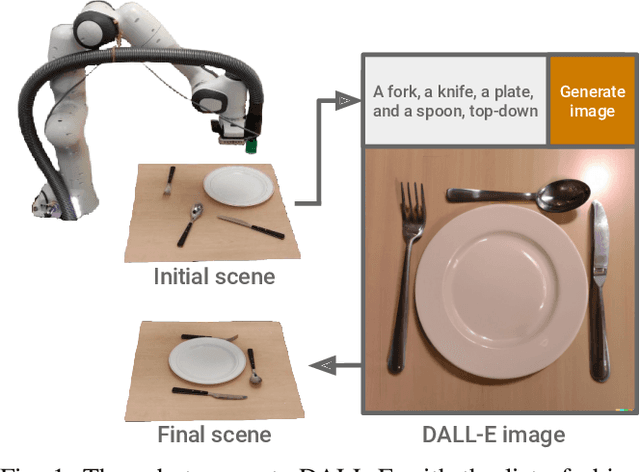
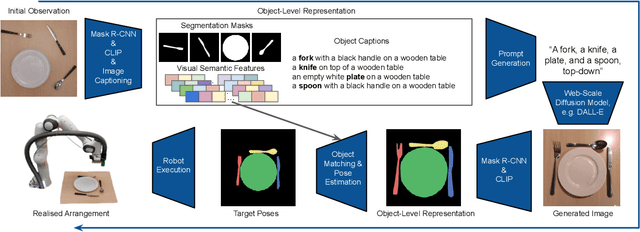

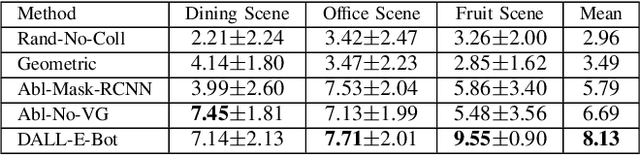
We introduce the first work to explore web-scale diffusion models for robotics. DALL-E-Bot enables a robot to rearrange objects in a scene, by first inferring a text description of those objects, then generating an image representing a natural, human-like arrangement of those objects, and finally physically arranging the objects according to that image. The significance is that we achieve this zero-shot using DALL-E, without needing any further data collection or training. Encouraging real-world results with human studies show that this is an exciting direction for the future of web-scale robot learning algorithms. We also propose a list of recommendations to the text-to-image community, to align further developments of these models with applications to robotics. Videos are available at: https://www.robot-learning.uk/dall-e-bot
MonoGraspNet: 6-DoF Grasping with a Single RGB Image
Sep 26, 2022
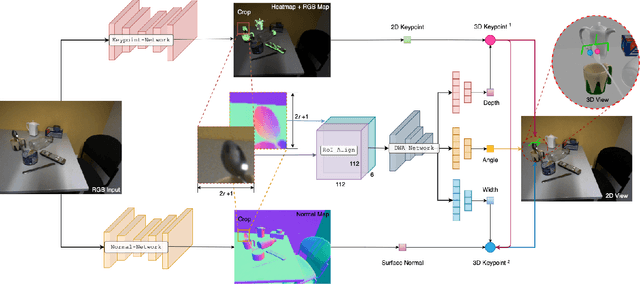
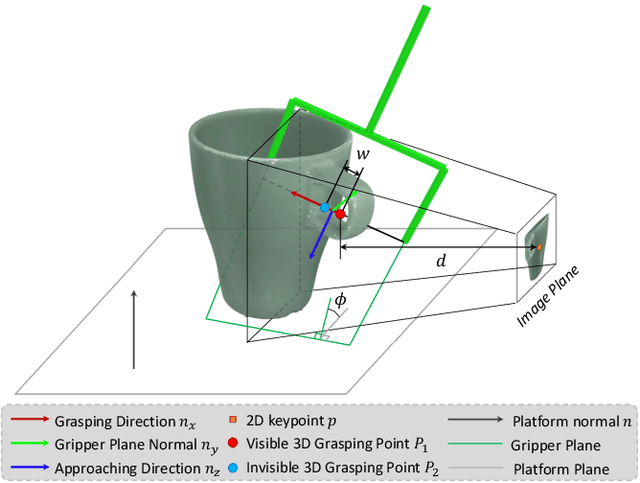

6-DoF robotic grasping is a long-lasting but unsolved problem. Recent methods utilize strong 3D networks to extract geometric grasping representations from depth sensors, demonstrating superior accuracy on common objects but perform unsatisfactorily on photometrically challenging objects, e.g., objects in transparent or reflective materials. The bottleneck lies in that the surface of these objects can not reflect back accurate depth due to the absorption or refraction of light. In this paper, in contrast to exploiting the inaccurate depth data, we propose the first RGB-only 6-DoF grasping pipeline called MonoGraspNet that utilizes stable 2D features to simultaneously handle arbitrary object grasping and overcome the problems induced by photometrically challenging objects. MonoGraspNet leverages keypoint heatmap and normal map to recover the 6-DoF grasping poses represented by our novel representation parameterized with 2D keypoints with corresponding depth, grasping direction, grasping width, and angle. Extensive experiments in real scenes demonstrate that our method can achieve competitive results in grasping common objects and surpass the depth-based competitor by a large margin in grasping photometrically challenging objects. To further stimulate robotic manipulation research, we additionally annotate and open-source a multi-view and multi-scene real-world grasping dataset, containing 120 objects of mixed photometric complexity with 20M accurate grasping labels.
Accurate 3-DoF Camera Geo-Localization via Ground-to-Satellite Image Matching
Mar 26, 2022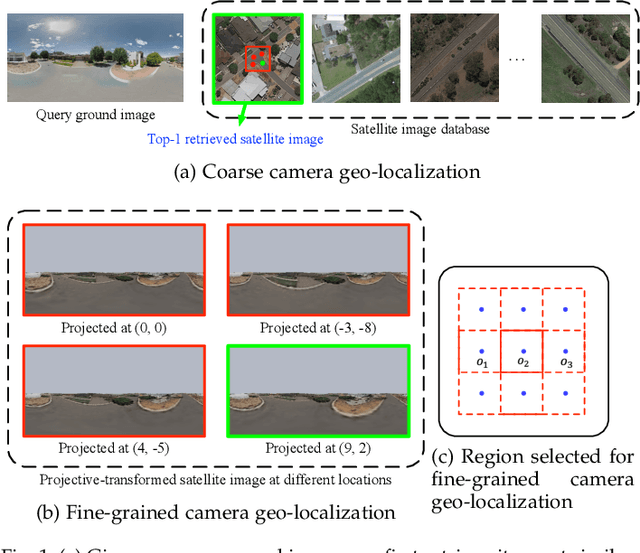
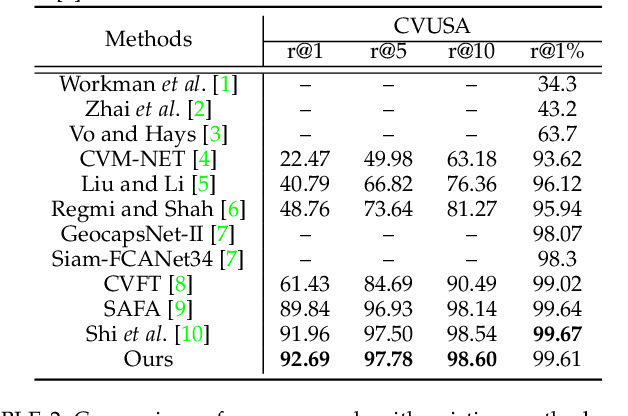

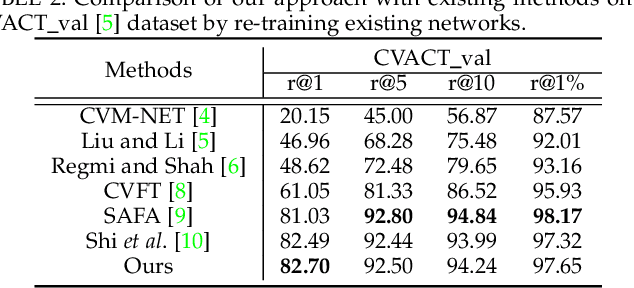
We address the problem of ground-to-satellite image geo-localization, that is, estimating the camera latitude, longitude and orientation (azimuth angle) by matching a query image captured at the ground level against a large-scale database with geotagged satellite images. Our prior arts treat the above task as pure image retrieval by selecting the most similar satellite reference image matching the ground-level query image. However, such an approach often produces coarse location estimates because the geotag of the retrieved satellite image only corresponds to the image center while the ground camera can be located at any point within the image. To further consolidate our prior research findings, we present a novel geometry-aware geo-localization method. Our new method is able to achieve the fine-grained location of a query image, up to pixel size precision of the satellite image, once its coarse location and orientation have been determined. Moreover, we propose a new geometry-aware image retrieval pipeline to improve the coarse localization accuracy. Apart from a polar transform in our conference work, this new pipeline also maps satellite image pixels to the ground-level plane in the ground-view via a geometry-constrained projective transform to emphasize informative regions, such as road structures, for cross-view geo-localization. Extensive quantitative and qualitative experiments demonstrate the effectiveness of our newly proposed framework. We also significantly improve the performance of coarse localization results compared to the state-of-the-art in terms of location recalls.
RegCLR: A Self-Supervised Framework for Tabular Representation Learning in the Wild
Nov 02, 2022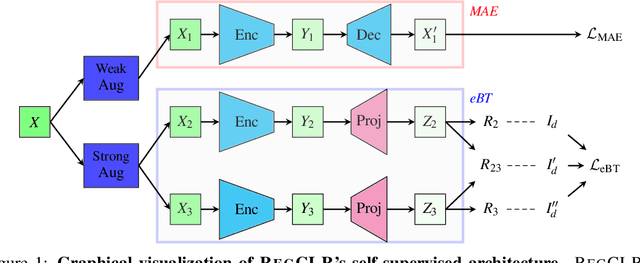
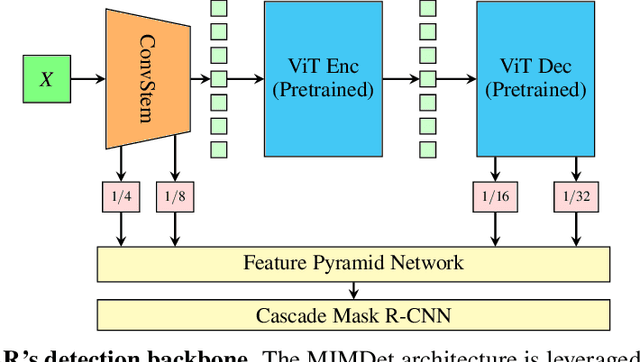
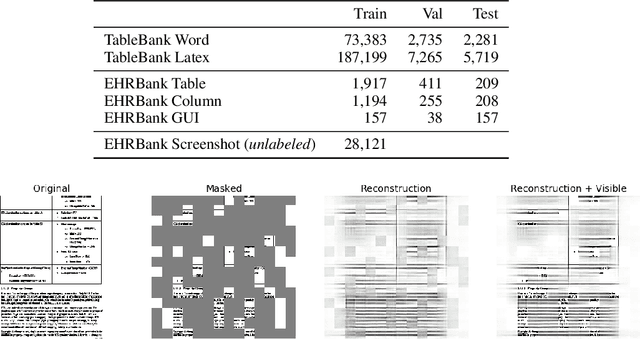
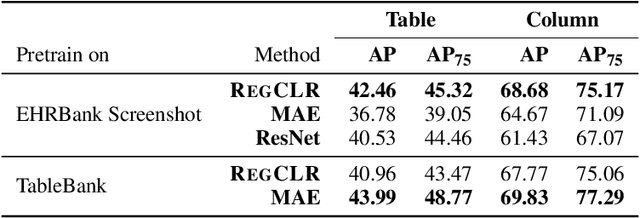
Recent advances in self-supervised learning (SSL) using large models to learn visual representations from natural images are rapidly closing the gap between the results produced by fully supervised learning and those produced by SSL on downstream vision tasks. Inspired by this advancement and primarily motivated by the emergence of tabular and structured document image applications, we investigate which self-supervised pretraining objectives, architectures, and fine-tuning strategies are most effective. To address these questions, we introduce RegCLR, a new self-supervised framework that combines contrastive and regularized methods and is compatible with the standard Vision Transformer architecture. Then, RegCLR is instantiated by integrating masked autoencoders as a representative example of a contrastive method and enhanced Barlow Twins as a representative example of a regularized method with configurable input image augmentations in both branches. Several real-world table recognition scenarios (e.g., extracting tables from document images), ranging from standard Word and Latex documents to even more challenging electronic health records (EHR) computer screen images, have been shown to benefit greatly from the representations learned from this new framework, with detection average-precision (AP) improving relatively by 4.8% for Table, 11.8% for Column, and 11.1% for GUI objects over a previous fully supervised baseline on real-world EHR screen images.
Grasping the Inconspicuous
Nov 15, 2022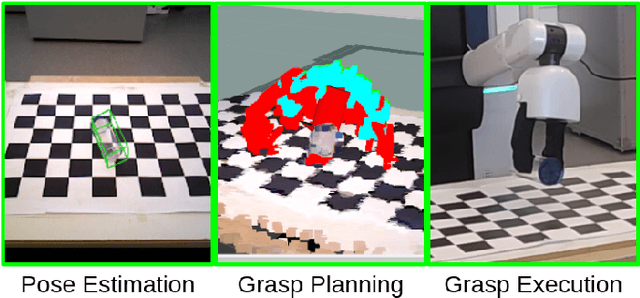
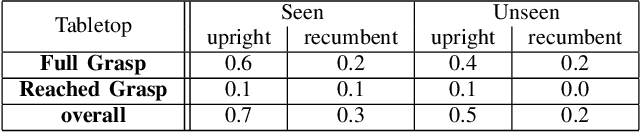


Transparent objects are common in day-to-day life and hence find many applications that require robot grasping. Many solutions toward object grasping exist for non-transparent objects. However, due to the unique visual properties of transparent objects, standard 3D sensors produce noisy or distorted measurements. Modern approaches tackle this problem by either refining the noisy depth measurements or using some intermediate representation of the depth. Towards this, we study deep learning 6D pose estimation from RGB images only for transparent object grasping. To train and test the suitability of RGB-based object pose estimation, we construct a dataset of RGB-only images with 6D pose annotations. The experiments demonstrate the effectiveness of RGB image space for grasping transparent objects.
Opening the Black Box of Learned Image Coders
Feb 26, 2022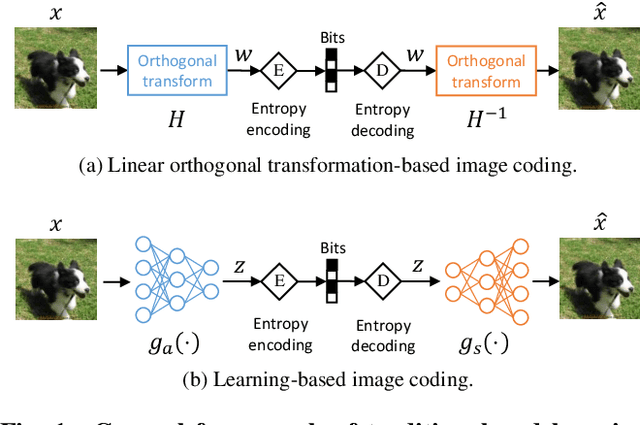
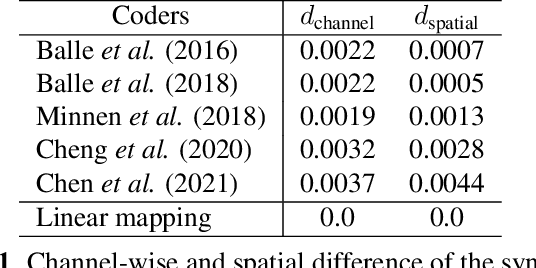


End-to-end learned lossy image coders, as opposed to hand-crafted image codecs, have shown increasing superiority in terms of the rate-distortion performance. However, they are mainly treated as a black-box system and their interpretability is not well studied. In this paper, we investigate learned image coders from the perspective of linear transform coding by measuring their channel response and linearity. For different learned image coder designs, we show that their end-to-end learned non-linear transforms share similar properties with linear orthogonal transformations. Our analysis provides insights into understanding how learned image coders work and could benefit future design and development.
R2-MLP: Round-Roll MLP for Multi-View 3D Object Recognition
Nov 20, 2022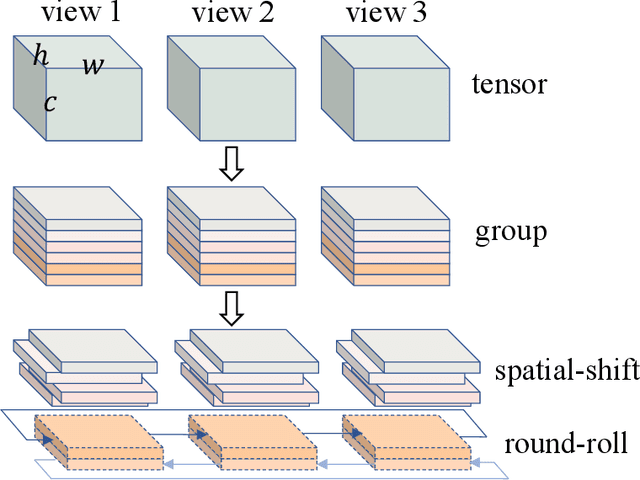
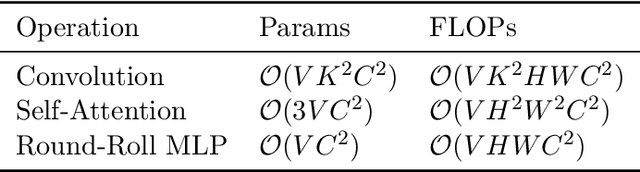
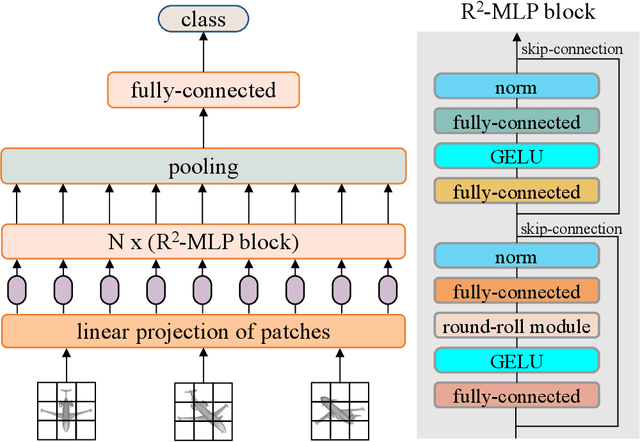

Recently, vision architectures based exclusively on multi-layer perceptrons (MLPs) have gained much attention in the computer vision community. MLP-like models achieve competitive performance on a single 2D image classification with less inductive bias without hand-crafted convolution layers. In this work, we explore the effectiveness of MLP-based architecture for the view-based 3D object recognition task. We present an MLP-based architecture termed as Round-Roll MLP (R$^2$-MLP). It extends the spatial-shift MLP backbone by considering the communications between patches from different views. R$^2$-MLP rolls part of the channels along the view dimension and promotes information exchange between neighboring views. We benchmark MLP results on ModelNet10 and ModelNet40 datasets with ablations in various aspects. The experimental results show that, with a conceptually simple structure, our R$^2$-MLP achieves competitive performance compared with existing state-of-the-art methods.