 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generating 2D and 3D Master Faces for Dictionary Attacks with a Network-Assisted Latent Space Evolution
Nov 28, 2022
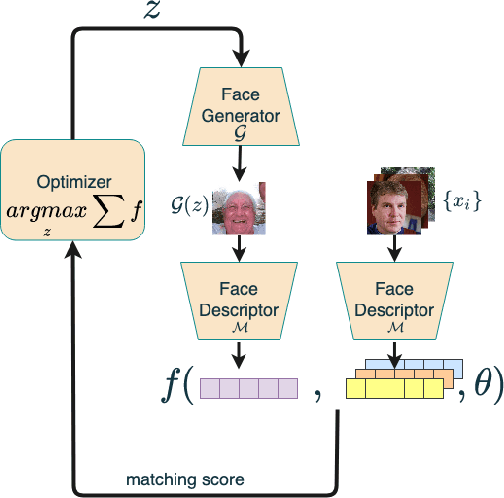
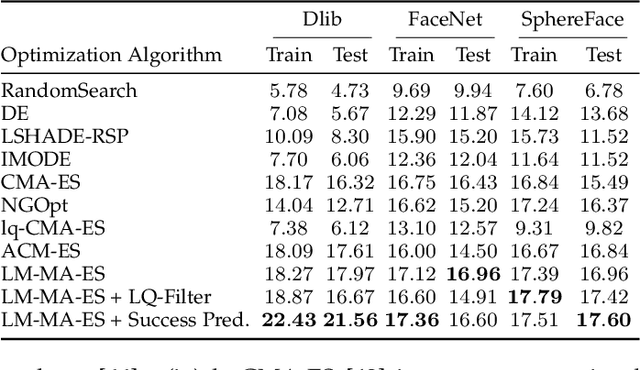
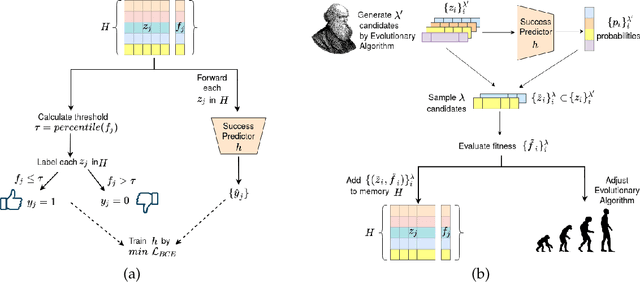
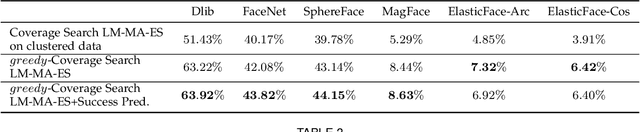
A master face is a face image that passes face-based identity authentication for a high percentage of the population. These faces can be used to impersonate, with a high probability of success, any user, without having access to any user information. We optimize these faces for 2D and 3D face verification models, by using an evolutionary algorithm in the latent embedding space of the StyleGAN face generator. For 2D face verification, multiple evolutionary strategies are compared, and we propose a novel approach that employs a neural network to direct the search toward promising samples, without adding fitness evaluations. The results we present demonstrate that it is possible to obtain a considerable coverage of the identities in the LFW or RFW datasets with less than 10 master faces, for six leading deep face recognition systems. In 3D, we generate faces using the 2D StyleGAN2 generator and predict a 3D structure using a deep 3D face reconstruction network. When employing two different 3D face recognition systems, we are able to obtain a coverage of 40%-50%. Additionally, we present the generation of paired 2D RGB and 3D master faces, which simultaneously match 2D and 3D models with high impersonation rates.
SAGE: Saliency-Guided Mixup with Optimal Rearrangements
Oct 31, 2022

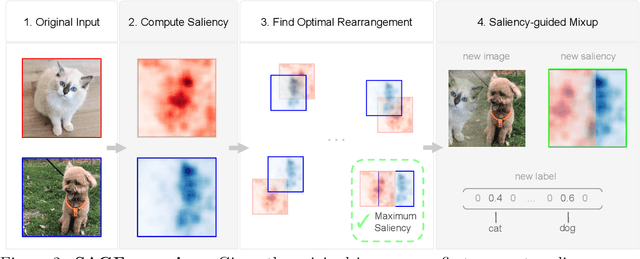
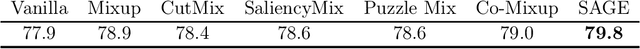
Data augmentation is a key element for training accurate models by reducing overfitting and improving generalization. For image classification, the most popular data augmentation techniques range from simple photometric and geometrical transformations, to more complex methods that use visual saliency to craft new training examples. As augmentation methods get more complex, their ability to increase the test accuracy improves, yet, such methods become cumbersome, inefficient and lead to poor out-of-domain generalization, as we show in this paper. This motivates a new augmentation technique that allows for high accuracy gains while being simple, efficient (i.e., minimal computation overhead) and generalizable. To this end, we introduce Saliency-Guided Mixup with Optimal Rearrangements (SAGE), which creates new training examples by rearranging and mixing image pairs using visual saliency as guidance. By explicitly leveraging saliency, SAGE promotes discriminative foreground objects and produces informative new images useful for training. We demonstrate on CIFAR-10 and CIFAR-100 that SAGE achieves better or comparable performance to the state of the art while being more efficient. Additionally, evaluations in the out-of-distribution setting, and few-shot learning on mini-ImageNet, show that SAGE achieves improved generalization performance without trading off robustness.
StyleT2I: Toward Compositional and High-Fidelity Text-to-Image Synthesis
Mar 29, 2022
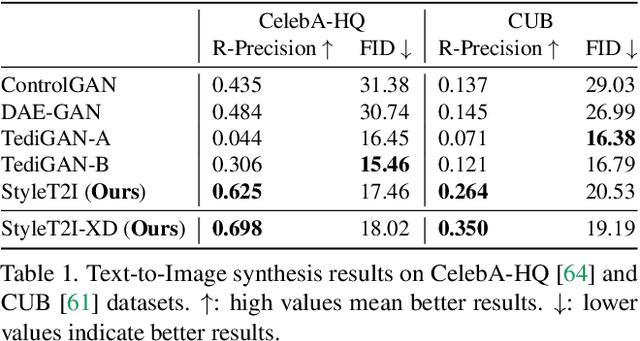
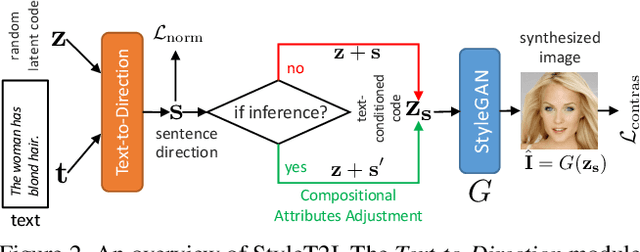
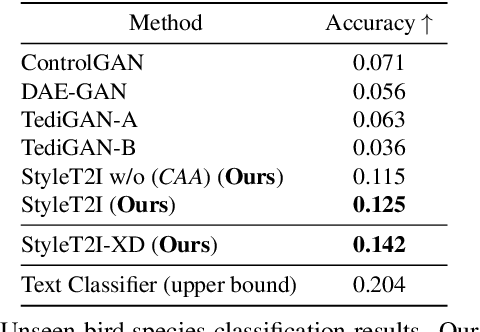
Although progress has been made for text-to-image synthesis, previous methods fall short of generalizing to unseen or underrepresented attribute compositions in the input text. Lacking compositionality could have severe implications for robustness and fairness, e.g., inability to synthesize the face images of underrepresented demographic groups. In this paper, we introduce a new framework, StyleT2I, to improve the compositionality of text-to-image synthesis. Specifically, we propose a CLIP-guided Contrastive Loss to better distinguish different compositions among different sentences. To further improve the compositionality, we design a novel Semantic Matching Loss and a Spatial Constraint to identify attributes' latent directions for intended spatial region manipulations, leading to better disentangled latent representations of attributes. Based on the identified latent directions of attributes, we propose Compositional Attribute Adjustment to adjust the latent code, resulting in better compositionality of image synthesis. In addition, we leverage the $\ell_2$-norm regularization of identified latent directions (norm penalty) to strike a nice balance between image-text alignment and image fidelity. In the experiments, we devise a new dataset split and an evaluation metric to evaluate the compositionality of text-to-image synthesis models. The results show that StyleT2I outperforms previous approaches in terms of the consistency between the input text and synthesized images and achieves higher fidelity.
Reinforced Swin-Convs Transformer for Underwater Image Enhancement
May 01, 2022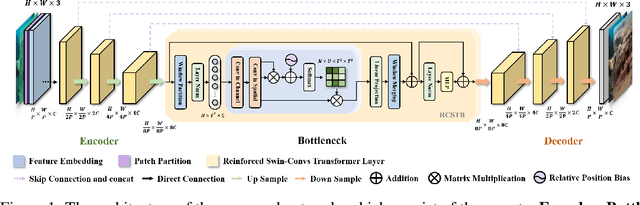
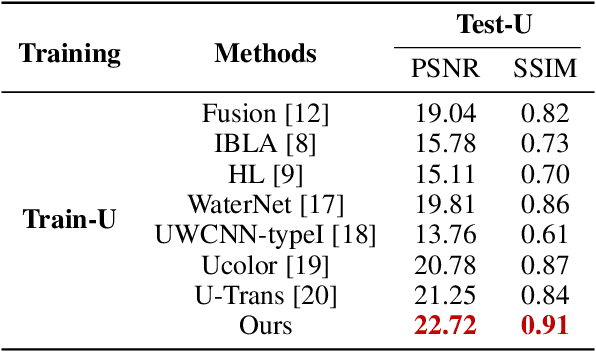
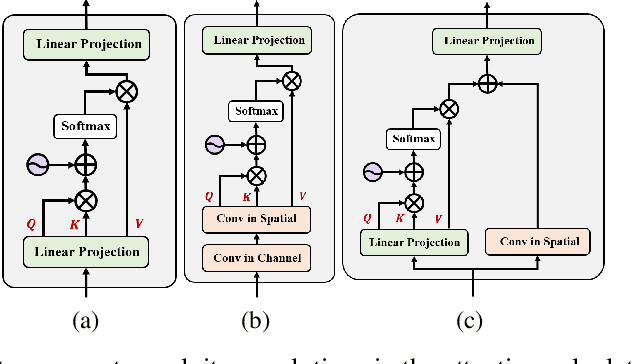
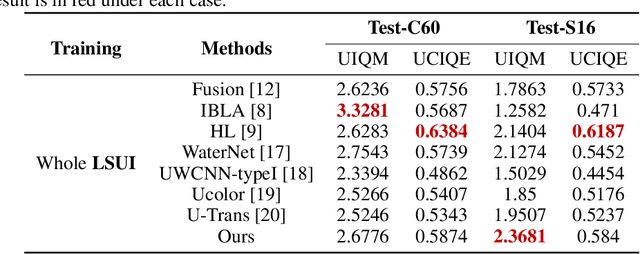
Underwater Image Enhancement (UIE) technology aims to tackle the challenge of restoring the degraded underwater images due to light absorption and scattering. To address problems, a novel U-Net based Reinforced Swin-Convs Transformer for the Underwater Image Enhancement method (URSCT-UIE) is proposed. Specifically, with the deficiency of U-Net based on pure convolutions, we embedded the Swin Transformer into U-Net for improving the ability to capture the global dependency. Then, given the inadequacy of the Swin Transformer capturing the local attention, the reintroduction of convolutions may capture more local attention. Thus, we provide an ingenious manner for the fusion of convolutions and the core attention mechanism to build a Reinforced Swin-Convs Transformer Block (RSCTB) for capturing more local attention, which is reinforced in the channel and the spatial attention of the Swin Transformer. Finally, the experimental results on available datasets demonstrate that the proposed URSCT-UIE achieves state-of-the-art performance compared with other methods in terms of both subjective and objective evaluations. The code will be released on GitHub after acceptance.
Automated Characterization of Catalytically Active Inclusion Body Production in Biotechnological Screening Systems
Sep 30, 2022
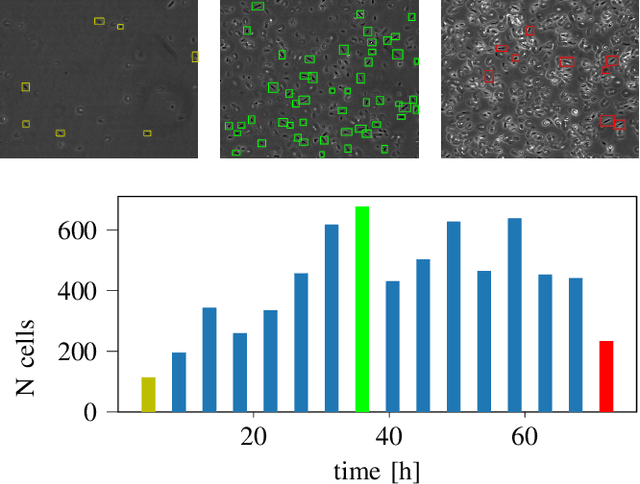

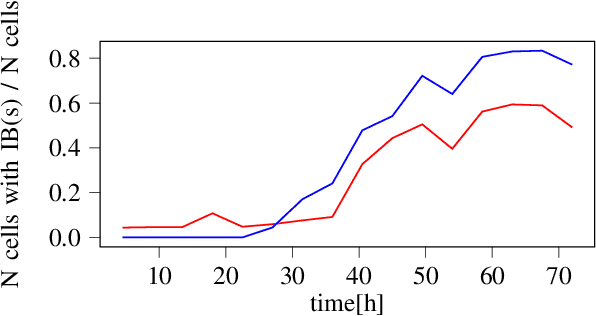
We here propose an automated pipeline for the microscopy image-based characterization of catalytically active inclusion bodies (CatIBs), which includes a fully automatic experimental high-throughput workflow combined with a hybrid approach for multi-object microbial cell segmentation. For automated microscopy, a CatIB producer strain was cultivated in a microbioreactor from which samples were injected into a flow chamber. The flow chamber was fixed under a microscope and an integrated camera took a series of images per sample. To explore heterogeneity of CatIB development during the cultivation and track the size and quantity of CatIBs over time, a hybrid image processing pipeline approach was developed, which combines an ML-based detection of in-focus cells with model-based segmentation. The experimental setup in combination with an automated image analysis unlocks high-throughput screening of CatIB production, saving time and resources. Biotechnological relevance - CatIBs have wide application in synthetic chemistry and biocatalysis, but also could have future biomedical applications such as therapeutics. The proposed hybrid automatic image processing pipeline can be adjusted to treat comparable biological microorganisms, where fully data-driven ML-based segmentation approaches are not feasible due to the lack of training data. Our work is the first step towards image-based bioprocess control.
TAPE: Task-Agnostic Prior Embedding for Image Restoration
Mar 11, 2022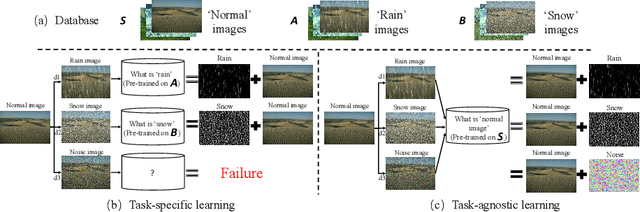

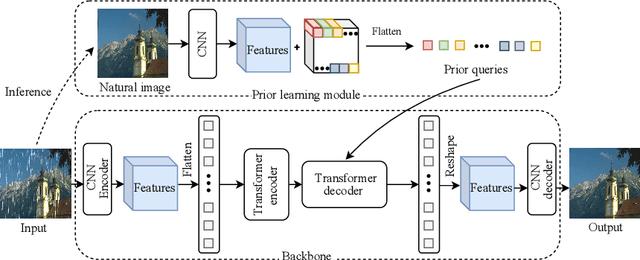

Learning an generalized prior for natural image restoration is an important yet challenging task. Early methods mostly involved handcrafted priors including normalized sparsity, L0 gradients, dark channel priors, etc. Recently, deep neural networks have been used to learn various image priors but do not guarantee to generalize. In this paper, we propose a novel approach that embeds a task-agnostic prior into a transformer. Our approach, named Task-Agnostic Prior Embedding (TAPE), consists of three stages, namely, task-agnostic pre-training, task-agnostic fine-tuning, and task-specific fine-tuning, where the first one embeds prior knowledge about natural images into the transformer and the latter two extracts the knowledge to assist downstream image restoration. Experiments on various types of degradation validate the effectiveness of TAPE. The image restoration performance in terms of PSNR is improved by as much as 1.45 dB and even outperforms task-specific algorithms. More importantly, TAPE shows the ability of disentangling generalized image priors from degraded images, which enjoys favorable transfer ability to unknown downstream tasks.
R2C-GAN: Restore-to-Classify GANs for Blind X-Ray Restoration and COVID-19 Classification
Sep 29, 2022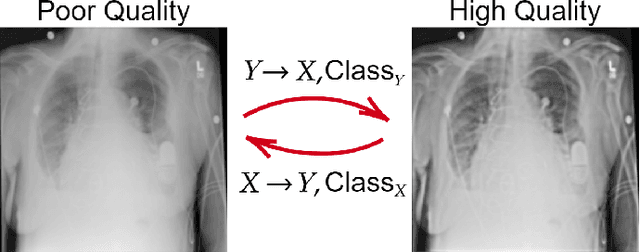
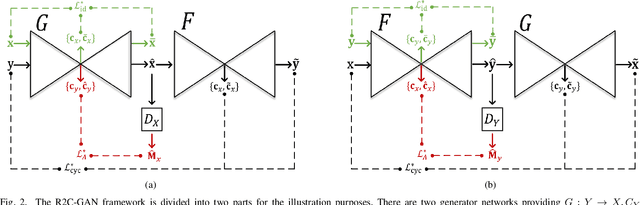
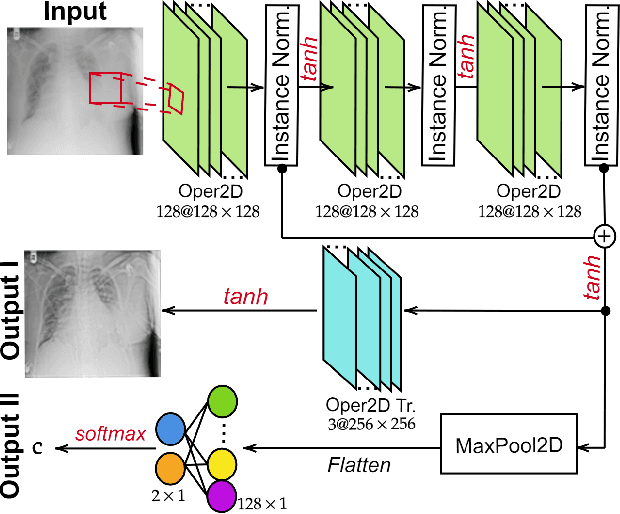
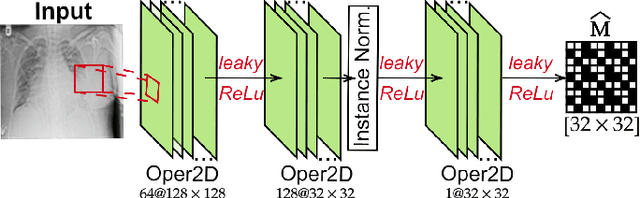
Restoration of poor quality images with a blended set of artifacts plays a vital role for a reliable diagnosis. Existing studies have focused on specific restoration problems such as image deblurring, denoising, and exposure correction where there is usually a strong assumption on the artifact type and severity. As a pioneer study in blind X-ray restoration, we propose a joint model for generic image restoration and classification: Restore-to-Classify Generative Adversarial Networks (R2C-GANs). Such a jointly optimized model keeps any disease intact after the restoration. Therefore, this will naturally lead to a higher diagnosis performance thanks to the improved X-ray image quality. To accomplish this crucial objective, we define the restoration task as an Image-to-Image translation problem from poor quality having noisy, blurry, or over/under-exposed images to high quality image domain. The proposed R2C-GAN model is able to learn forward and inverse transforms between the two domains using unpaired training samples. Simultaneously, the joint classification preserves the disease label during restoration. Moreover, the R2C-GANs are equipped with operational layers/neurons reducing the network depth and further boosting both restoration and classification performances. The proposed joint model is extensively evaluated over the QaTa-COV19 dataset for Coronavirus Disease 2019 (COVID-19) classification. The proposed restoration approach achieves over 90% F1-Score which is significantly higher than the performance of any deep model. Moreover, in the qualitative analysis, the restoration performance of R2C-GANs is approved by a group of medical doctors. We share the software implementation at https://github.com/meteahishali/R2C-GAN.
Automating Cobb Angle Measurement for Adolescent Idiopathic Scoliosis using Instance Segmentation
Nov 25, 2022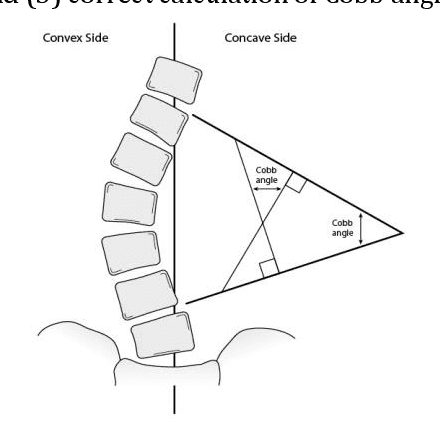
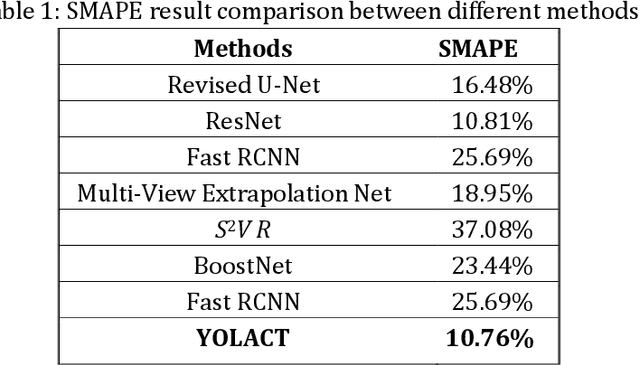
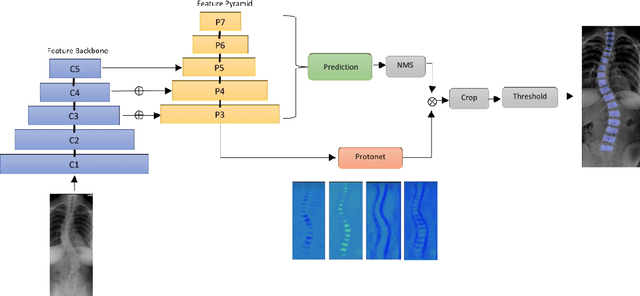

Scoliosis is a three-dimensional deformity of the spine, most often diagnosed in childhood. It affects 2-3% of the population, which is approximately seven million people in North America. Currently, the reference standard for assessing scoliosis is based on the manual assignment of Cobb angles at the site of the curvature center. This manual process is time consuming and unreliable as it is affected by inter- and intra-observer variance. To overcome these inaccuracies, machine learning (ML) methods can be used to automate the Cobb angle measurement process. This paper proposes to address the Cobb angle measurement task using YOLACT, an instance segmentation model. The proposed method first segments the vertebrae in an X-Ray image using YOLACT, then it tracks the important landmarks using the minimum bounding box approach. Lastly, the extracted landmarks are used to calculate the corresponding Cobb angles. The model achieved a Symmetric Mean Absolute Percentage Error (SMAPE) score of 10.76%, demonstrating the reliability of this process in both vertebra localization and Cobb angle measurement.
Ladder Siamese Network: a Method and Insights for Multi-level Self-Supervised Learning
Nov 25, 2022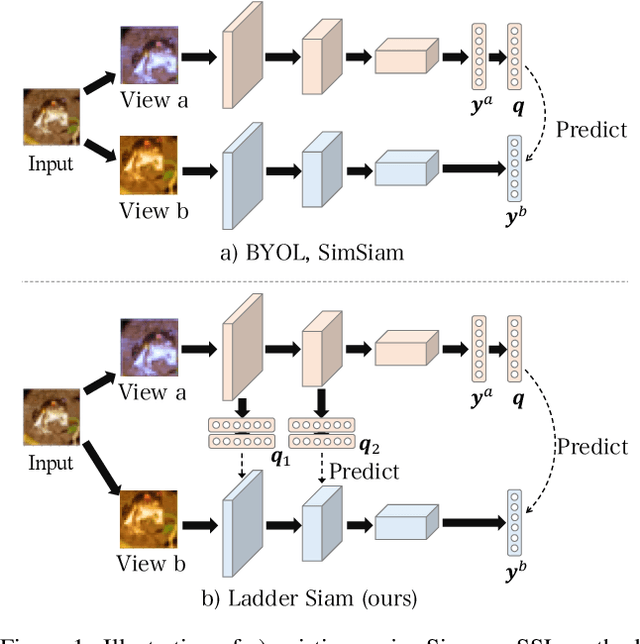
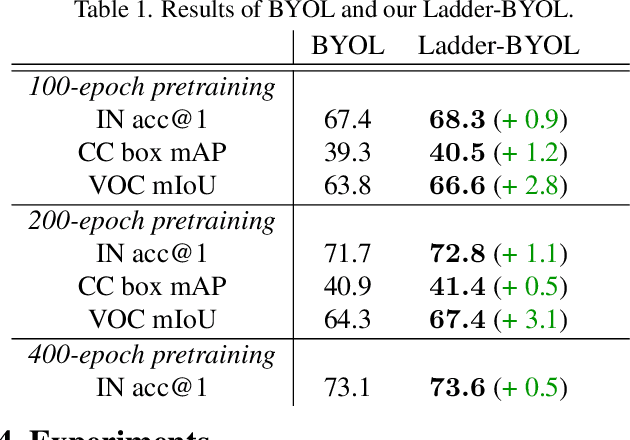
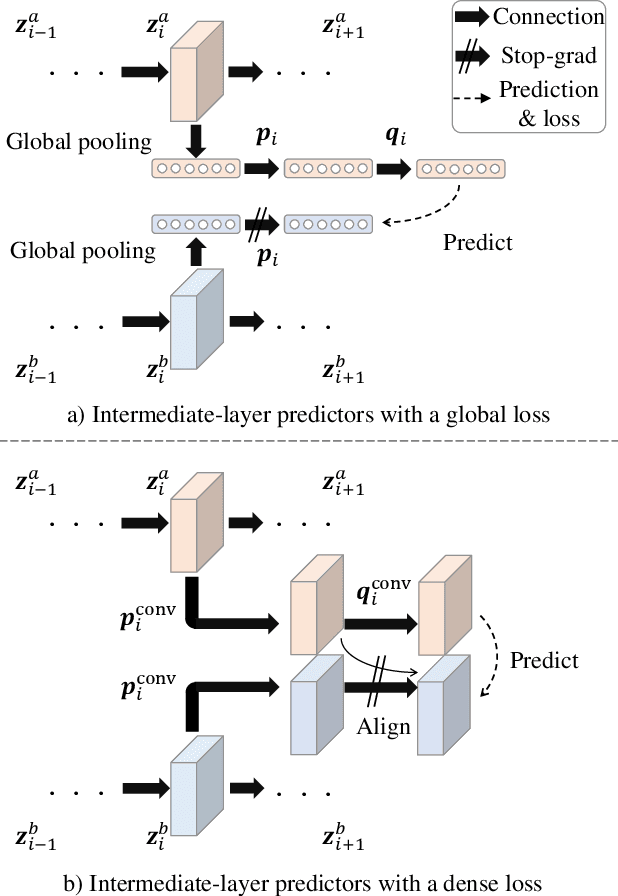
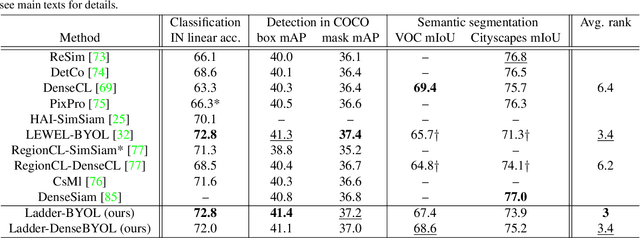
Siamese-network-based self-supervised learning (SSL) suffers from slow convergence and instability in training. To alleviate this, we propose a framework to exploit intermediate self-supervisions in each stage of deep nets, called the Ladder Siamese Network. Our self-supervised losses encourage the intermediate layers to be consistent with different data augmentations to single samples, which facilitates training progress and enhances the discriminative ability of the intermediate layers themselves. While some existing work has already utilized multi-level self supervisions in SSL, ours is different in that 1) we reveal its usefulness with non-contrastive Siamese frameworks in both theoretical and empirical viewpoints, and 2) ours improves image-level classification, instance-level detection, and pixel-level segmentation simultaneously. Experiments show that the proposed framework can improve BYOL baselines by 1.0% points in ImageNet linear classification, 1.2% points in COCO detection, and 3.1% points in PASCAL VOC segmentation. In comparison with the state-of-the-art methods, our Ladder-based model achieves competitive and balanced performances in all tested benchmarks without causing large degradation in one.
Monitoring social distancing with single image depth estimation
Apr 04, 2022
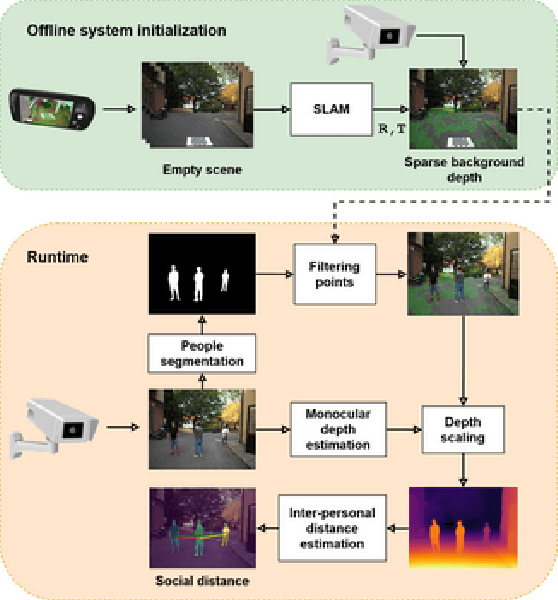
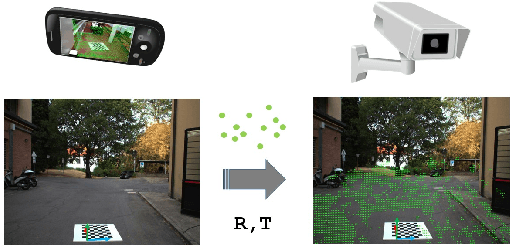

The recent pandemic emergency raised many challenges regarding the countermeasures aimed at containing the virus spread, and constraining the minimum distance between people resulted in one of the most effective strategies. Thus, the implementation of autonomous systems capable of monitoring the so-called social distance gained much interest. In this paper, we aim to address this task leveraging a single RGB frame without additional depth sensors. In contrast to existing single-image alternatives failing when ground localization is not available, we rely on single image depth estimation to perceive the 3D structure of the observed scene and estimate the distance between people. During the setup phase, a straightforward calibration procedure, leveraging a scale-aware SLAM algorithm available even on consumer smartphones, allows us to address the scale ambiguity affecting single image depth estimation. We validate our approach through indoor and outdoor images employing a calibrated LiDAR + RGB camera asset. Experimental results highlight that our proposal enables sufficiently reliable estimation of the inter-personal distance to monitor social distancing effectively. This fact confirms that despite its intrinsic ambiguity, if appropriately driven single image depth estimation can be a viable alternative to other depth perception techniques, more expensive and not always feasible in practical applications. Our evaluation also highlights that our framework can run reasonably fast and comparably to competitors, even on pure CPU systems. Moreover, its practical deployment on low-power systems is around the corner.