 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Masked Contrastive Pre-Training for Efficient Video-Text Retrieval
Dec 02, 2022
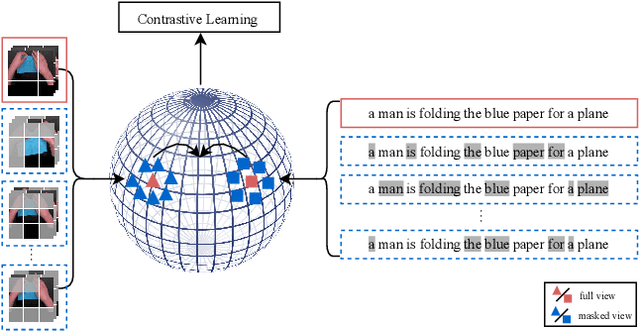
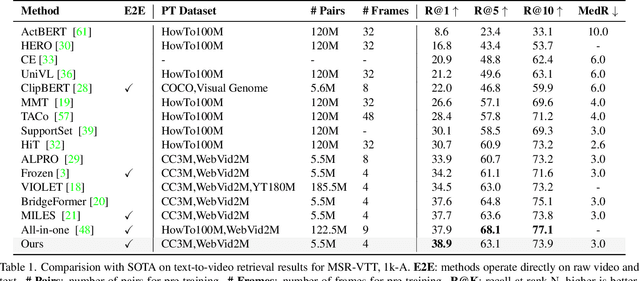
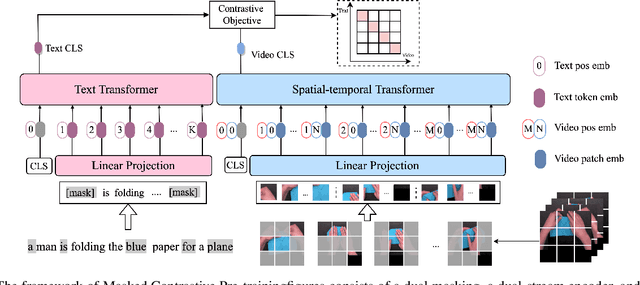
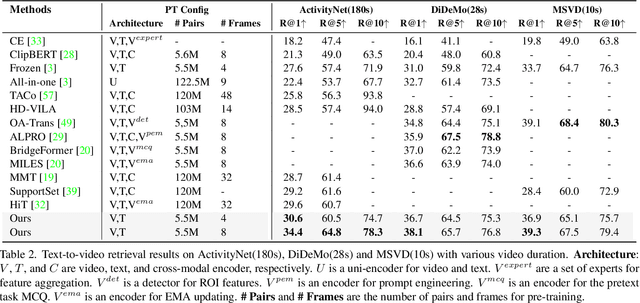
We present a simple yet effective end-to-end Video-language Pre-training (VidLP) framework, Masked Contrastive Video-language Pretraining (MAC), for video-text retrieval tasks. Our MAC aims to reduce video representation's spatial and temporal redundancy in the VidLP model by a mask sampling mechanism to improve pre-training efficiency. Comparing conventional temporal sparse sampling, we propose to randomly mask a high ratio of spatial regions and only feed visible regions into the encoder as sparse spatial sampling. Similarly, we adopt the mask sampling technique for text inputs for consistency. Instead of blindly applying the mask-then-prediction paradigm from MAE, we propose a masked-then-alignment paradigm for efficient video-text alignment. The motivation is that video-text retrieval tasks rely on high-level alignment rather than low-level reconstruction, and multimodal alignment with masked modeling encourages the model to learn a robust and general multimodal representation from incomplete and unstable inputs. Coupling these designs enables efficient end-to-end pre-training: reduce FLOPs (60% off), accelerate pre-training (by 3x), and improve performance. Our MAC achieves state-of-the-art results on various video-text retrieval datasets, including MSR-VTT, DiDeMo, and ActivityNet. Our approach is omnivorous to input modalities. With minimal modifications, we achieve competitive results on image-text retrieval tasks.
TAPE: Task-Agnostic Prior Embedding for Image Restoration
Mar 11, 2022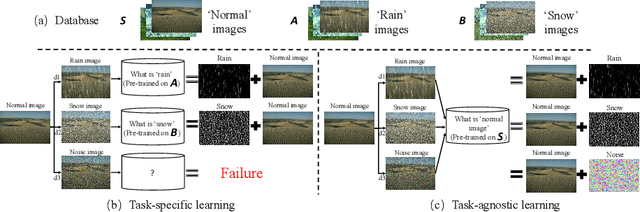

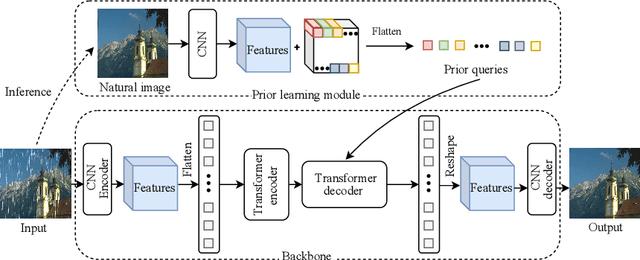

Learning an generalized prior for natural image restoration is an important yet challenging task. Early methods mostly involved handcrafted priors including normalized sparsity, L0 gradients, dark channel priors, etc. Recently, deep neural networks have been used to learn various image priors but do not guarantee to generalize. In this paper, we propose a novel approach that embeds a task-agnostic prior into a transformer. Our approach, named Task-Agnostic Prior Embedding (TAPE), consists of three stages, namely, task-agnostic pre-training, task-agnostic fine-tuning, and task-specific fine-tuning, where the first one embeds prior knowledge about natural images into the transformer and the latter two extracts the knowledge to assist downstream image restoration. Experiments on various types of degradation validate the effectiveness of TAPE. The image restoration performance in terms of PSNR is improved by as much as 1.45 dB and even outperforms task-specific algorithms. More importantly, TAPE shows the ability of disentangling generalized image priors from degraded images, which enjoys favorable transfer ability to unknown downstream tasks.
HandFlow: Quantifying View-Dependent 3D Ambiguity in Two-Hand Reconstruction with Normalizing Flow
Oct 04, 2022
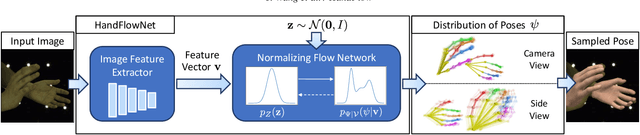
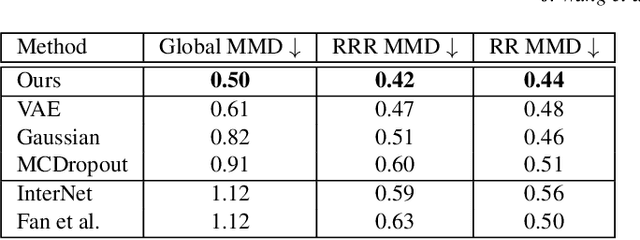
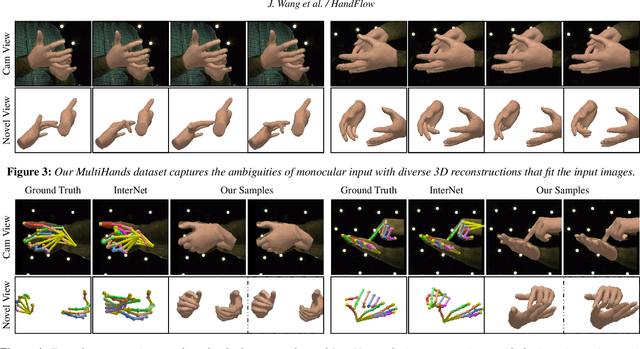
Reconstructing two-hand interactions from a single image is a challenging problem due to ambiguities that stem from projective geometry and heavy occlusions. Existing methods are designed to estimate only a single pose, despite the fact that there exist other valid reconstructions that fit the image evidence equally well. In this paper we propose to address this issue by explicitly modeling the distribution of plausible reconstructions in a conditional normalizing flow framework. This allows us to directly supervise the posterior distribution through a novel determinant magnitude regularization, which is key to varied 3D hand pose samples that project well into the input image. We also demonstrate that metrics commonly used to assess reconstruction quality are insufficient to evaluate pose predictions under such severe ambiguity. To address this, we release the first dataset with multiple plausible annotations per image called MultiHands. The additional annotations enable us to evaluate the estimated distribution using the maximum mean discrepancy metric. Through this, we demonstrate the quality of our probabilistic reconstruction and show that explicit ambiguity modeling is better-suited for this challenging problem.
Statistical Inference for Coadded Astronomical Images
Nov 17, 2022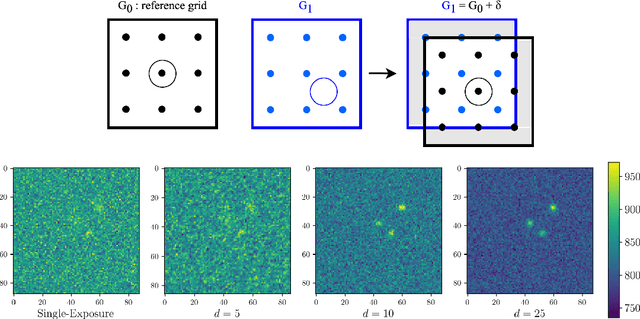
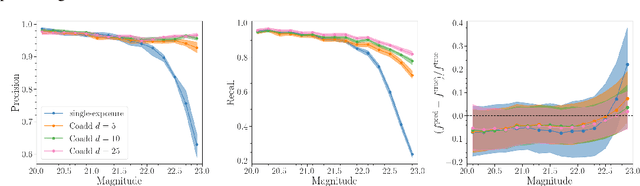
Coadded astronomical images are created by stacking multiple single-exposure images. Because coadded images are smaller in terms of data size than the single-exposure images they summarize, loading and processing them is less computationally expensive. However, image coaddition introduces additional dependence among pixels, which complicates principled statistical analysis of them. We present a principled Bayesian approach for performing light source parameter inference with coadded astronomical images. Our method implicitly marginalizes over the single-exposure pixel intensities that contribute to the coadded images, giving it the computational efficiency necessary to scale to next-generation astronomical surveys. As a proof of concept, we show that our method for estimating the locations and fluxes of stars using simulated coadds outperforms a method trained on single-exposure images.
Monitoring social distancing with single image depth estimation
Apr 04, 2022
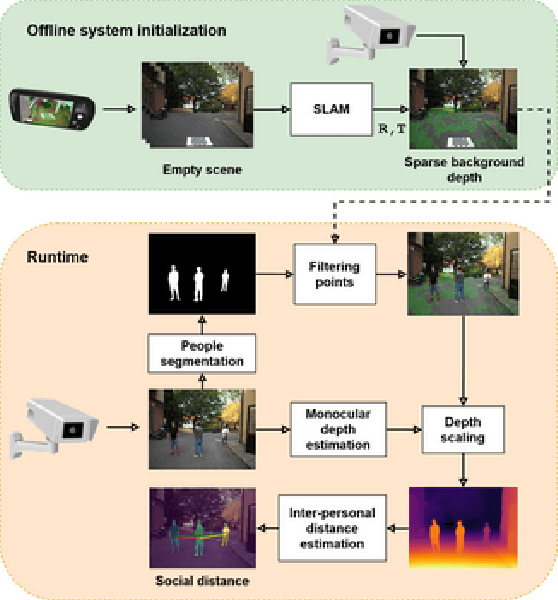
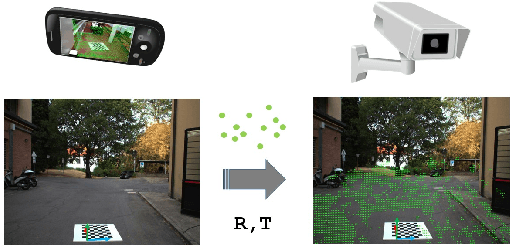

The recent pandemic emergency raised many challenges regarding the countermeasures aimed at containing the virus spread, and constraining the minimum distance between people resulted in one of the most effective strategies. Thus, the implementation of autonomous systems capable of monitoring the so-called social distance gained much interest. In this paper, we aim to address this task leveraging a single RGB frame without additional depth sensors. In contrast to existing single-image alternatives failing when ground localization is not available, we rely on single image depth estimation to perceive the 3D structure of the observed scene and estimate the distance between people. During the setup phase, a straightforward calibration procedure, leveraging a scale-aware SLAM algorithm available even on consumer smartphones, allows us to address the scale ambiguity affecting single image depth estimation. We validate our approach through indoor and outdoor images employing a calibrated LiDAR + RGB camera asset. Experimental results highlight that our proposal enables sufficiently reliable estimation of the inter-personal distance to monitor social distancing effectively. This fact confirms that despite its intrinsic ambiguity, if appropriately driven single image depth estimation can be a viable alternative to other depth perception techniques, more expensive and not always feasible in practical applications. Our evaluation also highlights that our framework can run reasonably fast and comparably to competitors, even on pure CPU systems. Moreover, its practical deployment on low-power systems is around the corner.
Totems: Physical Objects for Verifying Visual Integrity
Sep 26, 2022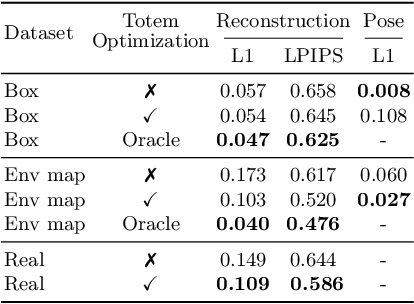
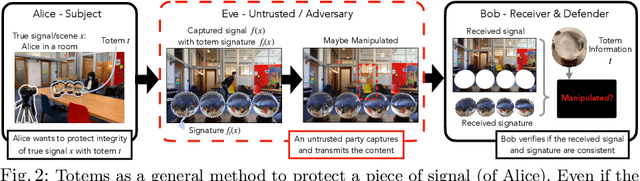

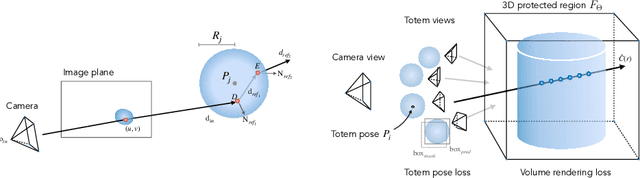
We introduce a new approach to image forensics: placing physical refractive objects, which we call totems, into a scene so as to protect any photograph taken of that scene. Totems bend and redirect light rays, thus providing multiple, albeit distorted, views of the scene within a single image. A defender can use these distorted totem pixels to detect if an image has been manipulated. Our approach unscrambles the light rays passing through the totems by estimating their positions in the scene and using their known geometric and material properties. To verify a totem-protected image, we detect inconsistencies between the scene reconstructed from totem viewpoints and the scene's appearance from the camera viewpoint. Such an approach makes the adversarial manipulation task more difficult, as the adversary must modify both the totem and image pixels in a geometrically consistent manner without knowing the physical properties of the totem. Unlike prior learning-based approaches, our method does not require training on datasets of specific manipulations, and instead uses physical properties of the scene and camera to solve the forensics problem.
Reinforced Swin-Convs Transformer for Underwater Image Enhancement
May 01, 2022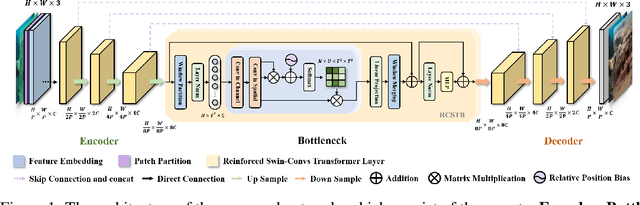
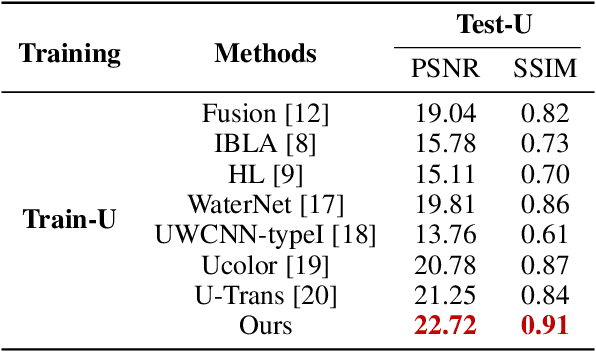
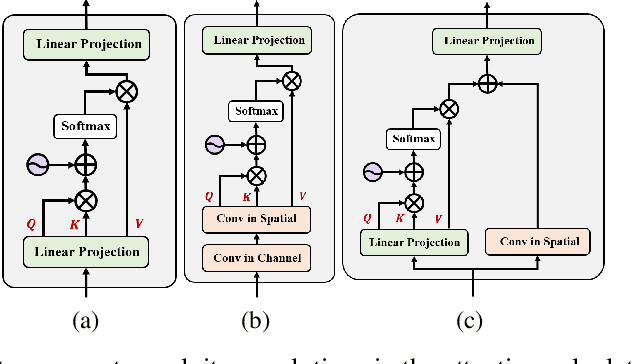
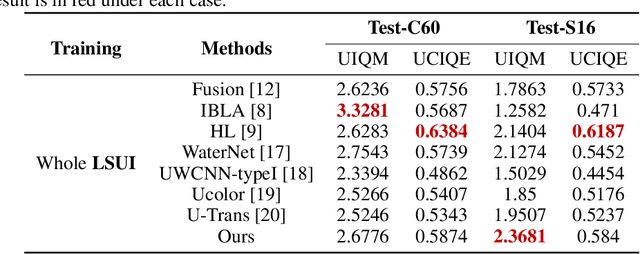
Underwater Image Enhancement (UIE) technology aims to tackle the challenge of restoring the degraded underwater images due to light absorption and scattering. To address problems, a novel U-Net based Reinforced Swin-Convs Transformer for the Underwater Image Enhancement method (URSCT-UIE) is proposed. Specifically, with the deficiency of U-Net based on pure convolutions, we embedded the Swin Transformer into U-Net for improving the ability to capture the global dependency. Then, given the inadequacy of the Swin Transformer capturing the local attention, the reintroduction of convolutions may capture more local attention. Thus, we provide an ingenious manner for the fusion of convolutions and the core attention mechanism to build a Reinforced Swin-Convs Transformer Block (RSCTB) for capturing more local attention, which is reinforced in the channel and the spatial attention of the Swin Transformer. Finally, the experimental results on available datasets demonstrate that the proposed URSCT-UIE achieves state-of-the-art performance compared with other methods in terms of both subjective and objective evaluations. The code will be released on GitHub after acceptance.
Singular Value Decomposition and Entropy Dimension of Fractals
Nov 15, 2022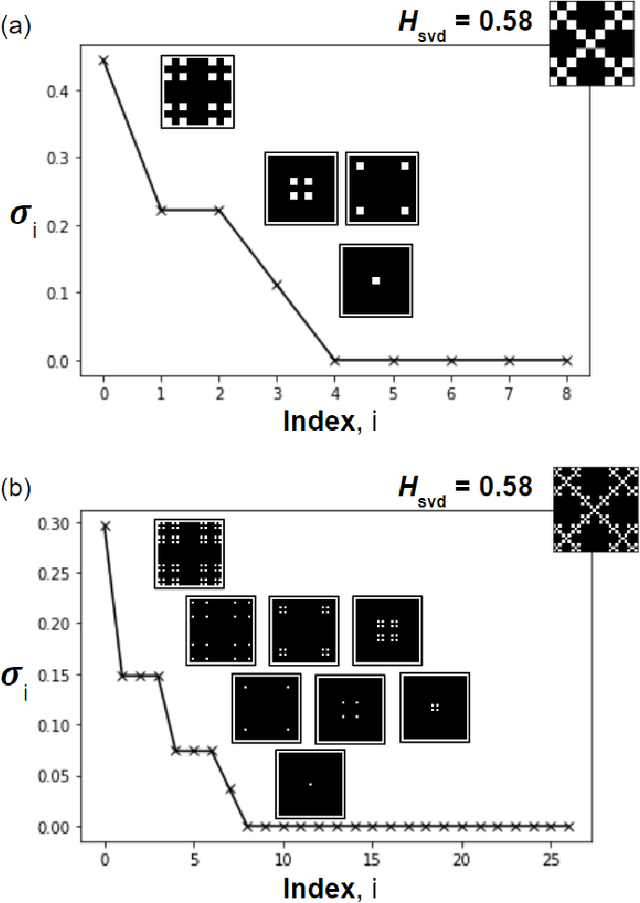
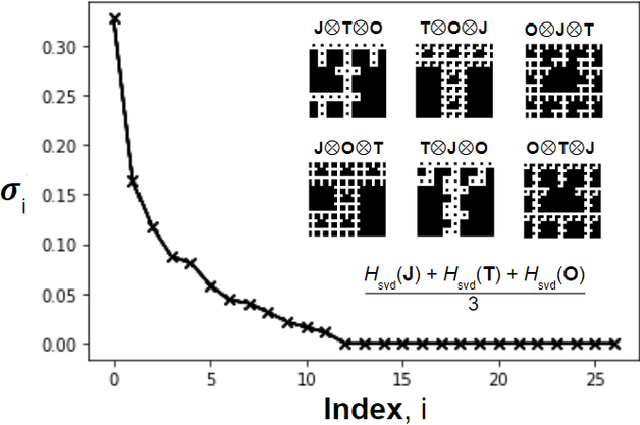
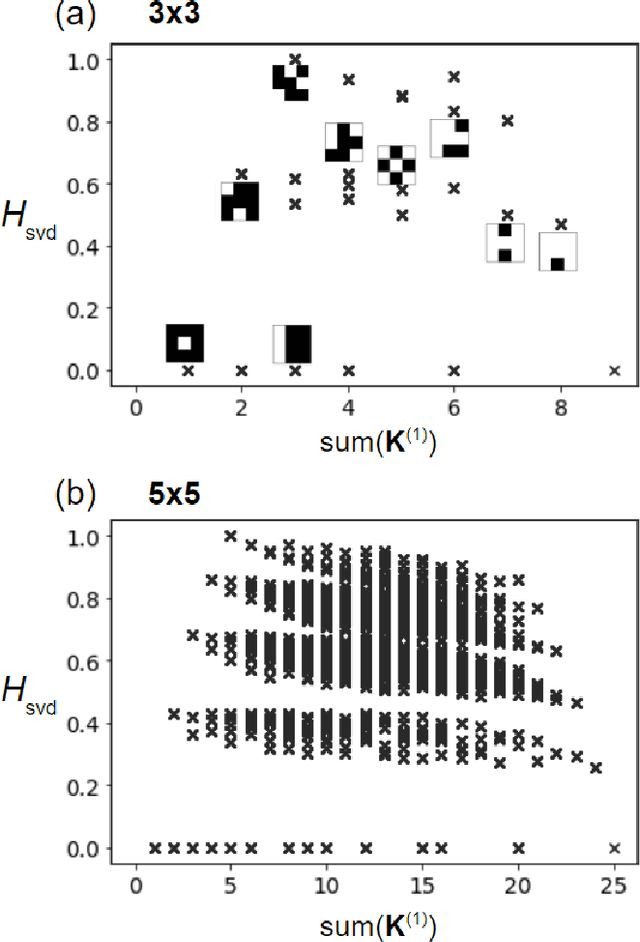
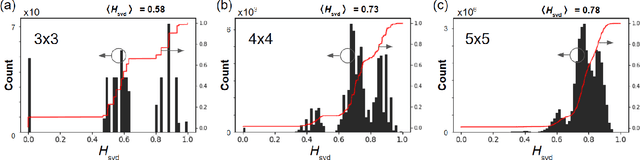
We analyze the singular value decomposition (SVD) and SVD entropy of Cantor fractals produced by the Kronecker product. Our primary results show that SVD entropy is a measure of image ``complexity dimension" that is invariant under the number of Kronecker-product self-iterations (i.e., fractal order). SVD entropy is therefore similar to the fractal Hausdorff complexity dimension but suitable for characterizing fractal wave phenomena. Our field-based normalization (Renyi entropy index = 1) illustrates the uncommon step-shaped and cluster-patterned distributions of the fractal singular values and their SVD entropy. As a modal measure of complexity, SVD entropy has uses for a variety of wireless communication, free-space optical, and remote sensing applications.
Bayesian Federated Neural Matching that Completes Full Information
Nov 15, 2022
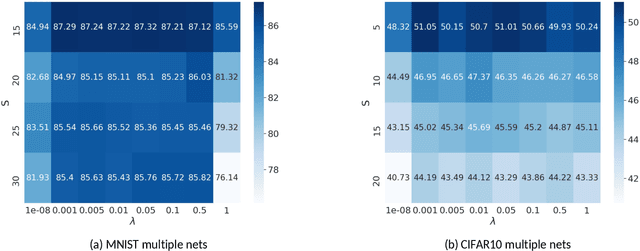
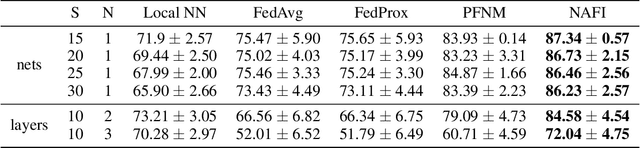

Federated learning is a contemporary machine learning paradigm where locally trained models are distilled into a global model. Due to the intrinsic permutation invariance of neural networks, Probabilistic Federated Neural Matching (PFNM) employs a Bayesian nonparametric framework in the generation process of local neurons, and then creates a linear sum assignment formulation in each alternative optimization iteration. But according to our theoretical analysis, the optimization iteration in PFNM omits global information from existing. In this study, we propose a novel approach that overcomes this flaw by introducing a Kullback-Leibler divergence penalty at each iteration. The effectiveness of our approach is demonstrated by experiments on both image classification and semantic segmentation tasks.
Memory transformers for full context and high-resolution 3D Medical Segmentation
Oct 11, 2022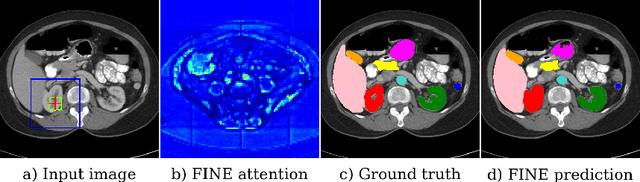
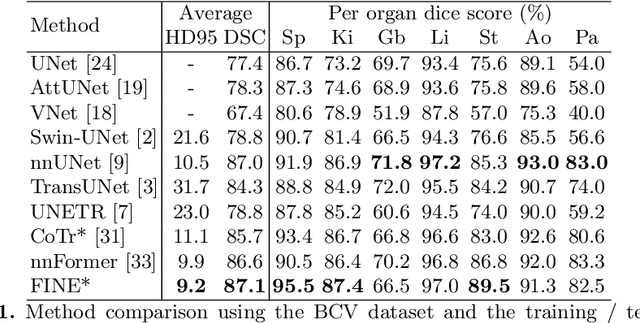
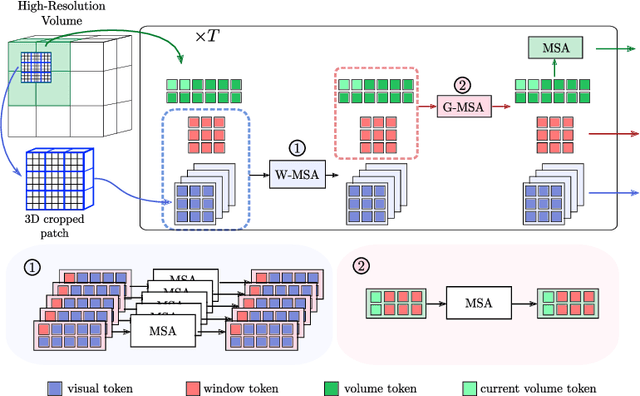

Transformer models achieve state-of-the-art results for image segmentation. However, achieving long-range attention, necessary to capture global context, with high-resolution 3D images is a fundamental challenge. This paper introduces the Full resolutIoN mEmory (FINE) transformer to overcome this issue. The core idea behind FINE is to learn memory tokens to indirectly model full range interactions while scaling well in both memory and computational costs. FINE introduces memory tokens at two levels: the first one allows full interaction between voxels within local image regions (patches), the second one allows full interactions between all regions of the 3D volume. Combined, they allow full attention over high resolution images, e.g. 512 x 512 x 256 voxels and above. Experiments on the BCV image segmentation dataset shows better performances than state-of-the-art CNN and transformer baselines, highlighting the superiority of our full attention mechanism compared to recent transformer baselines, e.g. CoTr, and nnFormer.