 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Survey of Deep Face Restoration: Denoise, Super-Resolution, Deblur, Artifact Removal
Nov 05, 2022


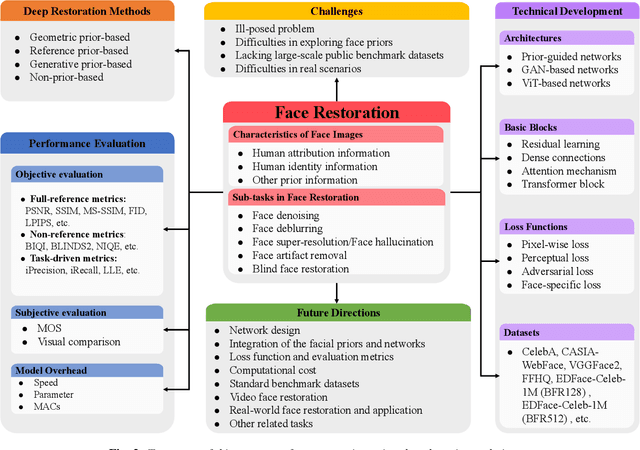
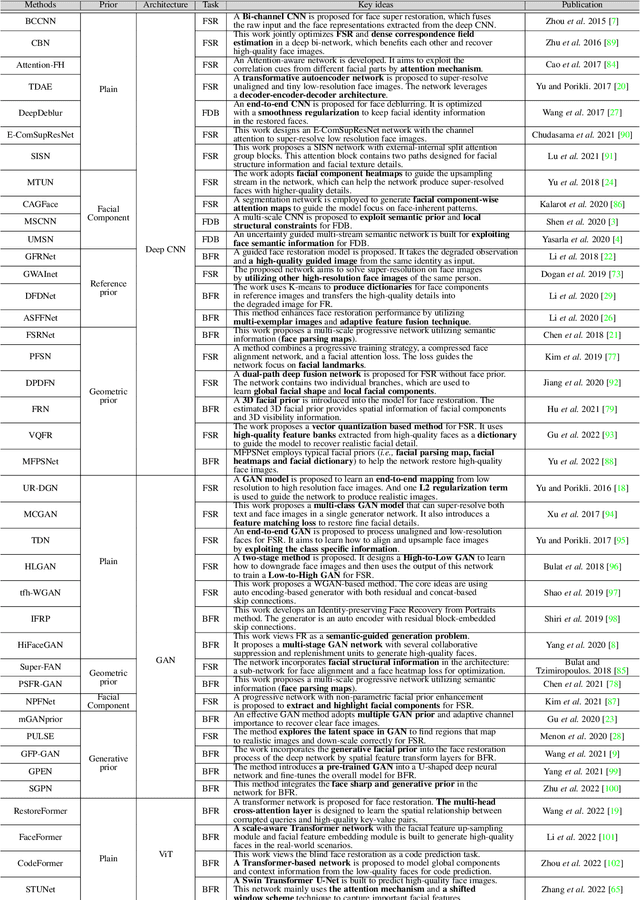
Face Restoration (FR) aims to restore High-Quality (HQ) faces from Low-Quality (LQ) input images, which is a domain-specific image restoration problem in the low-level computer vision area. The early face restoration methods mainly use statistic priors and degradation models, which are difficult to meet the requirements of real-world applications in practice. In recent years, face restoration has witnessed great progress after stepping into the deep learning era. However, there are few works to study deep learning-based face restoration methods systematically. Thus, this paper comprehensively surveys recent advances in deep learning techniques for face restoration. Specifically, we first summarize different problem formulations and analyze the characteristic of the face image. Second, we discuss the challenges of face restoration. Concerning these challenges, we present a comprehensive review of existing FR methods, including prior based methods and deep learning-based methods. Then, we explore developed techniques in the task of FR covering network architectures, loss functions, and benchmark datasets. We also conduct a systematic benchmark evaluation on representative methods. Finally, we discuss future directions, including network designs, metrics, benchmark datasets, applications,etc. We also provide an open-source repository for all the discussed methods, which is available at https://github.com/TaoWangzj/Awesome-Face-Restoration.
SizeGAN: Improving Size Representation in Clothing Catalogs
Nov 05, 2022
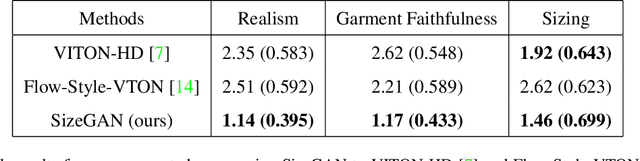
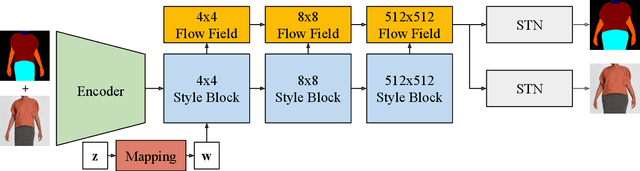
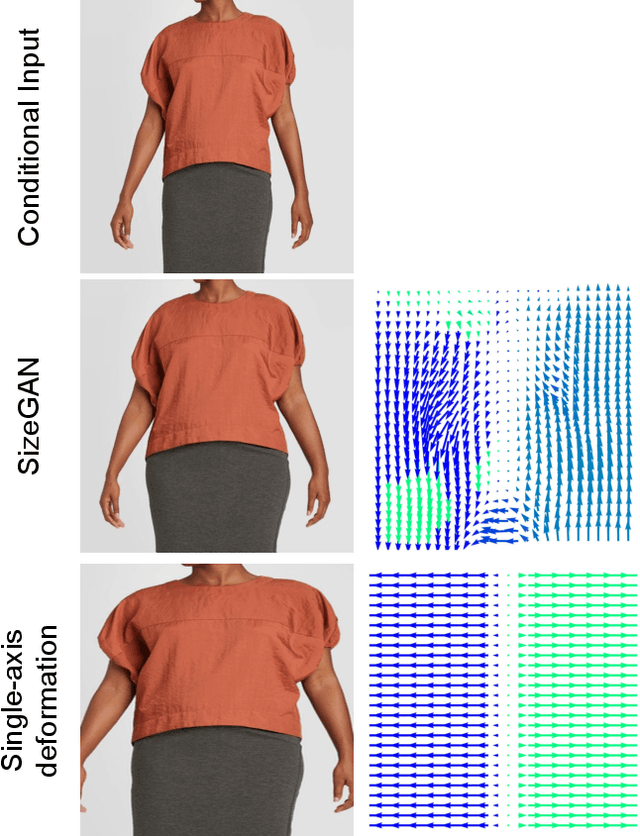
Online clothing catalogs lack diversity in body shape and garment size. Brands commonly display their garments on models of one or two sizes, rarely including plus-size models. In this work, we propose a new method, SizeGAN, for generating images of garments on different-sized models. To change the garment and model size while maintaining a photorealistic image, we incorporate image alignment ideas from the medical imaging literature into the StyleGAN2-ADA architecture. Our method learns deformation fields at multiple resolutions and uses a spatial transformer to modify the garment and model size. We evaluate our approach along three dimensions: realism, garment faithfulness, and size. To our knowledge, SizeGAN is the first method to focus on this size under-representation problem for modeling clothing. We provide an analysis comparing SizeGAN to other plausible approaches and additionally provide the first clothing dataset with size labels. In a user study comparing SizeGAN and two recent virtual try-on methods, we show that our method ranks first in each dimension, and was vastly preferred for realism and garment faithfulness. In comparison to most previous work, which has focused on generating photorealistic images of garments, our work shows that it is possible to generate images that are both photorealistic and cover diverse garment sizes.
CapsNet for Medical Image Segmentation
Mar 16, 2022
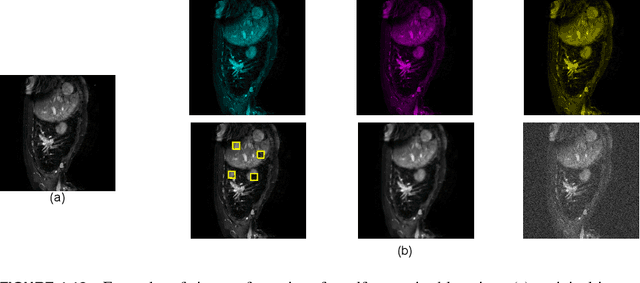

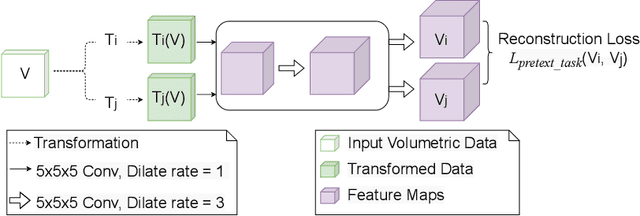
Convolutional Neural Networks (CNNs) have been successful in solving tasks in computer vision including medical image segmentation due to their ability to automatically extract features from unstructured data. However, CNNs are sensitive to rotation and affine transformation and their success relies on huge-scale labeled datasets capturing various input variations. This network paradigm has posed challenges at scale because acquiring annotated data for medical segmentation is expensive, and strict privacy regulations. Furthermore, visual representation learning with CNNs has its own flaws, e.g., it is arguable that the pooling layer in traditional CNNs tends to discard positional information and CNNs tend to fail on input images that differ in orientations and sizes. Capsule network (CapsNet) is a recent new architecture that has achieved better robustness in representation learning by replacing pooling layers with dynamic routing and convolutional strides, which has shown potential results on popular tasks such as classification, recognition, segmentation, and natural language processing. Different from CNNs, which result in scalar outputs, CapsNet returns vector outputs, which aim to preserve the part-whole relationships. In this work, we first introduce the limitations of CNNs and fundamentals of CapsNet. We then provide recent developments of CapsNet for the task of medical image segmentation. We finally discuss various effective network architectures to implement a CapsNet for both 2D images and 3D volumetric medical image segmentation.
Generalizable Implicit Neural Representations via Instance Pattern Composers
Nov 23, 2022

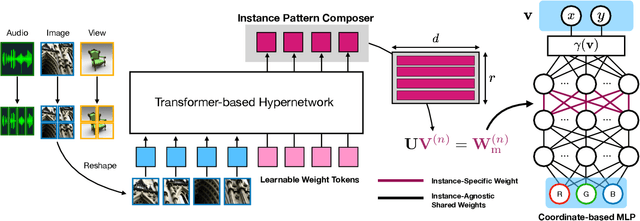

Despite recent advances in implicit neural representations (INRs), it remains challenging for a coordinate-based multi-layer perceptron (MLP) of INRs to learn a common representation across data instances and generalize it for unseen instances. In this work, we introduce a simple yet effective framework for generalizable INRs that enables a coordinate-based MLP to represent complex data instances by modulating only a small set of weights in an early MLP layer as an instance pattern composer; the remaining MLP weights learn pattern composition rules for common representations across instances. Our generalizable INR framework is fully compatible with existing meta-learning and hypernetworks in learning to predict the modulated weight for unseen instances. Extensive experiments demonstrate that our method achieves high performance on a wide range of domains such as an audio, image, and 3D object, while the ablation study validates our weight modulation.
Learning to Imitate Object Interactions from Internet Videos
Nov 23, 2022



We study the problem of imitating object interactions from Internet videos. This requires understanding the hand-object interactions in 4D, spatially in 3D and over time, which is challenging due to mutual hand-object occlusions. In this paper we make two main contributions: (1) a novel reconstruction technique RHOV (Reconstructing Hands and Objects from Videos), which reconstructs 4D trajectories of both the hand and the object using 2D image cues and temporal smoothness constraints; (2) a system for imitating object interactions in a physics simulator with reinforcement learning. We apply our reconstruction technique to 100 challenging Internet videos. We further show that we can successfully imitate a range of different object interactions in a physics simulator. Our object-centric approach is not limited to human-like end-effectors and can learn to imitate object interactions using different embodiments, like a robotic arm with a parallel jaw gripper.
DAM-GAN : Image Inpainting using Dynamic Attention Map based on Fake Texture Detection
Apr 20, 2022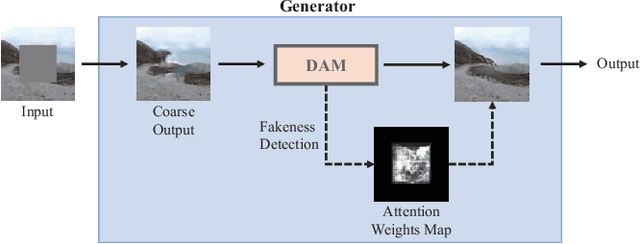
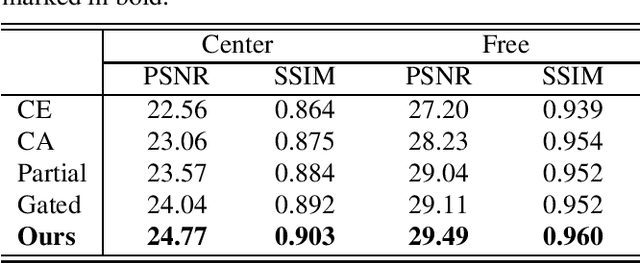
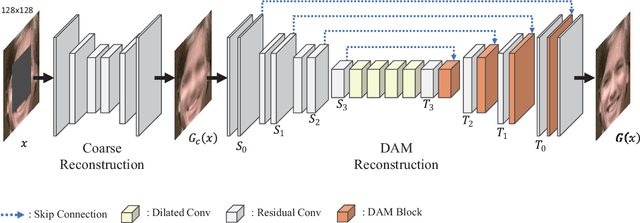
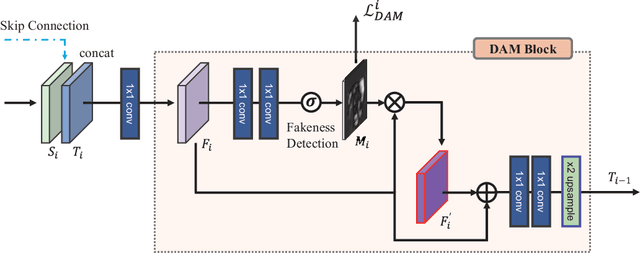
Deep neural advancements have recently brought remarkable image synthesis performance to the field of image inpainting. The adaptation of generative adversarial networks (GAN) in particular has accelerated significant progress in high-quality image reconstruction. However, although many notable GAN-based networks have been proposed for image inpainting, still pixel artifacts or color inconsistency occur in synthesized images during the generation process, which are usually called fake textures. To reduce pixel inconsistency disorder resulted from fake textures, we introduce a GAN-based model using dynamic attention map (DAM-GAN). Our proposed DAM-GAN concentrates on detecting fake texture and products dynamic attention maps to diminish pixel inconsistency from the feature maps in the generator. Evaluation results on CelebA-HQ and Places2 datasets with other image inpainting approaches show the superiority of our network.
Edge-oriented Implicit Neural Representation with Channel Tuning
Sep 22, 2022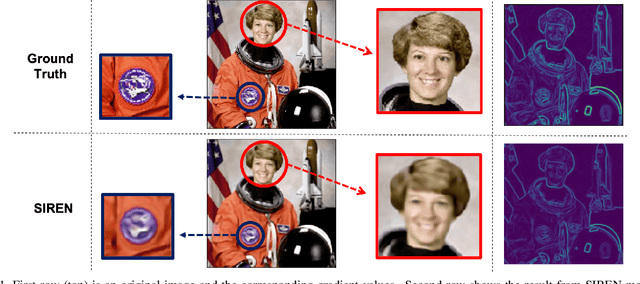

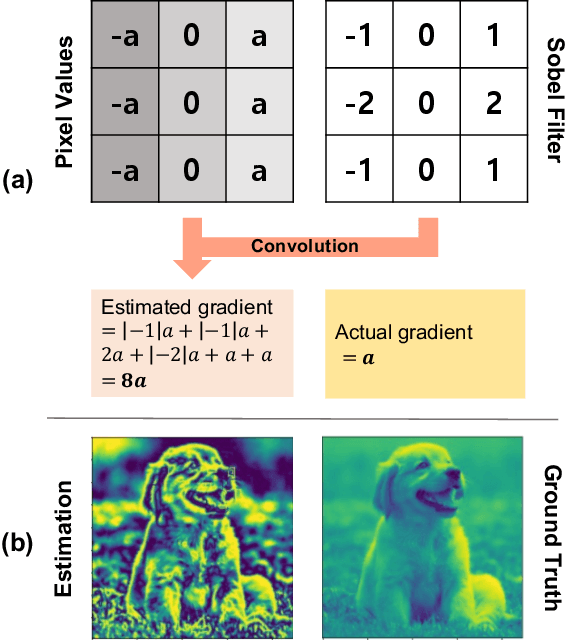
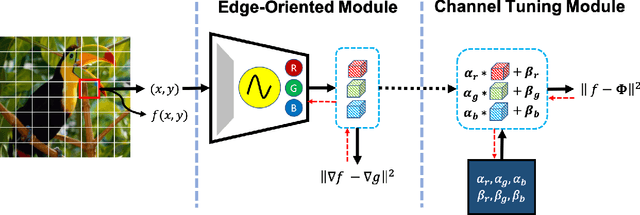
Implicit neural representation, which expresses an image as a continuous function rather than a discrete grid form, is widely used for image processing. Despite its outperforming results, there are still remaining limitations on restoring clear shapes of a given signal such as the edges of an image. In this paper, we propose Gradient Magnitude Adjustment algorithm which calculates the gradient of an image for training the implicit representation. In addition, we propose Edge-oriented Representation Network (EoREN) that can reconstruct the image with clear edges by fitting gradient information (Edge-oriented module). Furthermore, we add Channel-tuning module to adjust the distribution of given signals so that it solves a chronic problem of fitting gradients. By separating backpropagation paths of the two modules, EoREN can learn true color of the image without hindering the role for gradients. We qualitatively show that our model can reconstruct complex signals and demonstrate general reconstruction ability of our model with quantitative results.
CLIPascene: Scene Sketching with Different Types and Levels of Abstraction
Nov 30, 2022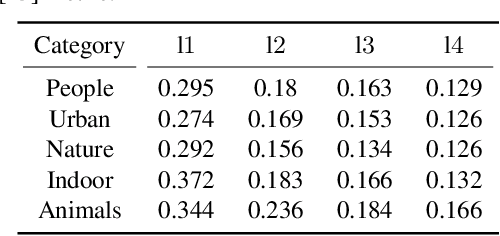

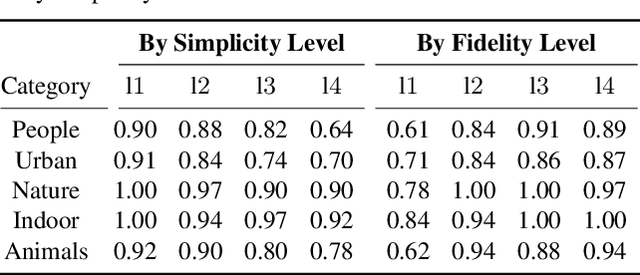

In this paper, we present a method for converting a given scene image into a sketch using different types and multiple levels of abstraction. We distinguish between two types of abstraction. The first considers the fidelity of the sketch, varying its representation from a more precise portrayal of the input to a looser depiction. The second is defined by the visual simplicity of the sketch, moving from a detailed depiction to a sparse sketch. Using an explicit disentanglement into two abstraction axes -- and multiple levels for each one -- provides users additional control over selecting the desired sketch based on their personal goals and preferences. To form a sketch at a given level of fidelity and simplification, we train two MLP networks. The first network learns the desired placement of strokes, while the second network learns to gradually remove strokes from the sketch without harming its recognizability and semantics. Our approach is able to generate sketches of complex scenes including those with complex backgrounds (e.g., natural and urban settings) and subjects (e.g., animals and people) while depicting gradual abstractions of the input scene in terms of fidelity and simplicity.
SPADE: Semi-supervised Anomaly Detection under Distribution Mismatch
Nov 30, 2022
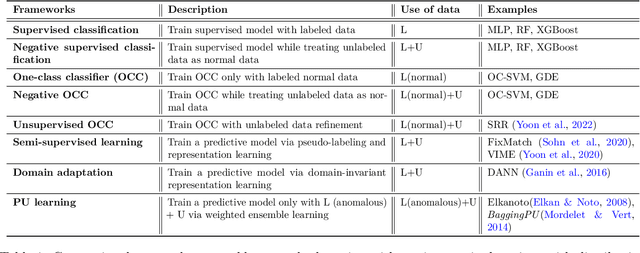
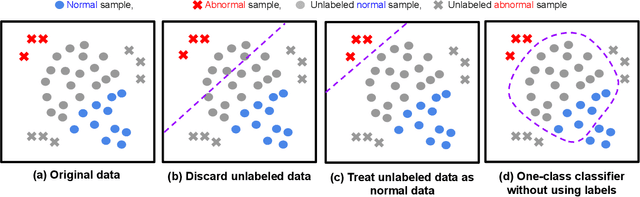
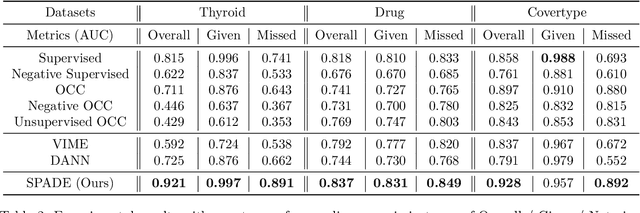
Semi-supervised anomaly detection is a common problem, as often the datasets containing anomalies are partially labeled. We propose a canonical framework: Semi-supervised Pseudo-labeler Anomaly Detection with Ensembling (SPADE) that isn't limited by the assumption that labeled and unlabeled data come from the same distribution. Indeed, the assumption is often violated in many applications - for example, the labeled data may contain only anomalies unlike unlabeled data, or unlabeled data may contain different types of anomalies, or labeled data may contain only 'easy-to-label' samples. SPADE utilizes an ensemble of one class classifiers as the pseudo-labeler to improve the robustness of pseudo-labeling with distribution mismatch. Partial matching is proposed to automatically select the critical hyper-parameters for pseudo-labeling without validation data, which is crucial with limited labeled data. SPADE shows state-of-the-art semi-supervised anomaly detection performance across a wide range of scenarios with distribution mismatch in both tabular and image domains. In some common real-world settings such as model facing new types of unlabeled anomalies, SPADE outperforms the state-of-the-art alternatives by 5% AUC in average.
Rethinking Causality-driven Robot Tool Segmentation with Temporal Constraints
Nov 30, 2022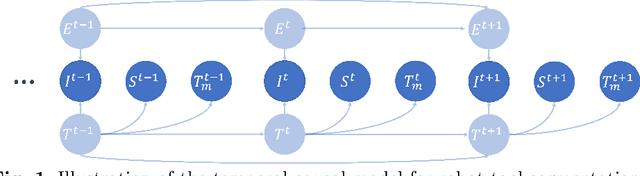
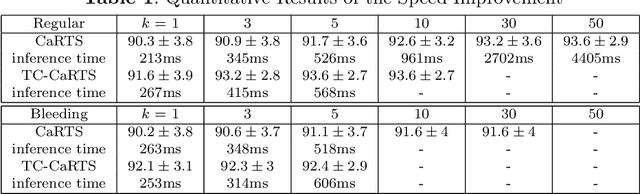
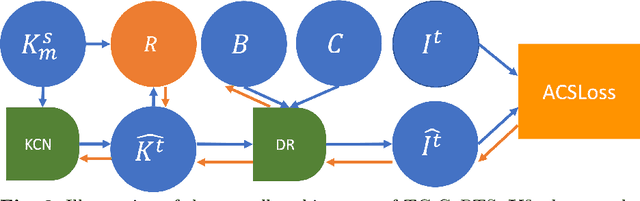
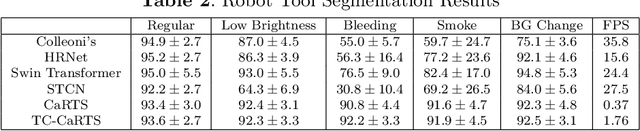
Purpose: Vision-based robot tool segmentation plays a fundamental role in surgical robots and downstream tasks. CaRTS, based on a complementary causal model, has shown promising performance in unseen counterfactual surgical environments in the presence of smoke, blood, etc. However, CaRTS requires over 30 iterations of optimization to converge for a single image due to limited observability. Method: To address the above limitations, we take temporal relation into consideration and propose a temporal causal model for robot tool segmentation on video sequences. We design an architecture named Temporally Constrained CaRTS (TC-CaRTS). TC-CaRTS has three novel modules to complement CaRTS - temporal optimization pipeline, kinematics correction network, and spatial-temporal regularization. Results: Experiment results show that TC-CaRTS requires much fewer iterations to achieve the same or better performance as CaRTS. TC- CaRTS also has the same or better performance in different domains compared to CaRTS. All three modules are proven to be effective. Conclusion: We propose TC-CaRTS, which takes advantage of temporal constraints as additional observability. We show that TC-CaRTS outperforms prior work in the robot tool segmentation task with improved convergence speed on test datasets from different domains.