 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Multimodal Approach for Dementia Detection from Spontaneous Speech with Tensor Fusion Layer
Nov 08, 2022
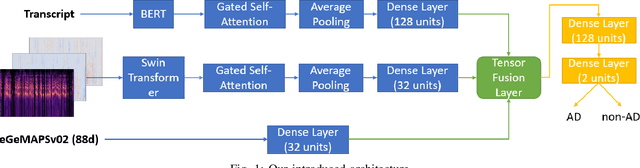
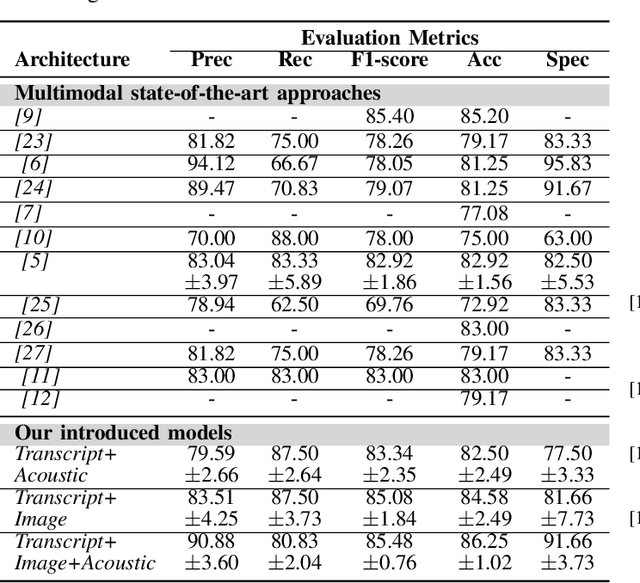
Alzheimer's disease (AD) is a progressive neurological disorder, meaning that the symptoms develop gradually throughout the years. It is also the main cause of dementia, which affects memory, thinking skills, and mental abilities. Nowadays, researchers have moved their interest towards AD detection from spontaneous speech, since it constitutes a time-effective procedure. However, existing state-of-the-art works proposing multimodal approaches do not take into consideration the inter- and intra-modal interactions and propose early and late fusion approaches. To tackle these limitations, we propose deep neural networks, which can be trained in an end-to-end trainable way and capture the inter- and intra-modal interactions. Firstly, each audio file is converted to an image consisting of three channels, i.e., log-Mel spectrogram, delta, and delta-delta. Next, each transcript is passed through a BERT model followed by a gated self-attention layer. Similarly, each image is passed through a Swin Transformer followed by an independent gated self-attention layer. Acoustic features are extracted also from each audio file. Finally, the representation vectors from the different modalities are fed to a tensor fusion layer for capturing the inter-modal interactions. Extensive experiments conducted on the ADReSS Challenge dataset indicate that our introduced approaches obtain valuable advantages over existing research initiatives reaching Accuracy and F1-score up to 86.25% and 85.48% respectively.
Active CT Reconstruction with a Learned Sampling Policy
Nov 03, 2022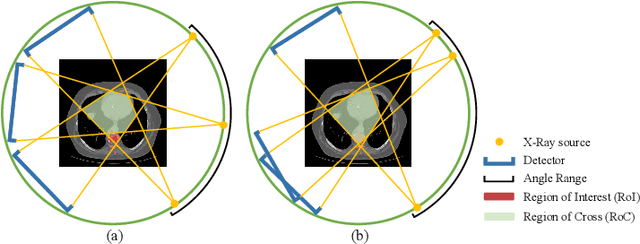
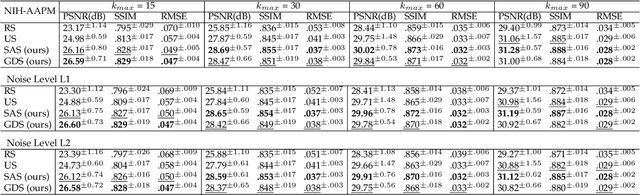


Computed tomography (CT) is a widely-used imaging technology that assists clinical decision-making with high-quality human body representations. To reduce the radiation dose posed by CT, sparse-view and limited-angle CT are developed with preserved image quality. However, these methods are still stuck with a fixed or uniform sampling strategy, which inhibits the possibility of acquiring a better image with an even reduced dose. In this paper, we explore this possibility via learning an active sampling policy that optimizes the sampling positions for patient-specific, high-quality reconstruction. To this end, we design an \textit{intelligent agent} for active recommendation of sampling positions based on on-the-fly reconstruction with obtained sinograms in a progressive fashion. With such a design, we achieve better performances on the NIH-AAPM dataset over popular uniform sampling, especially when the number of views is small. Finally, such a design also enables RoI-aware reconstruction with improved reconstruction quality within regions of interest (RoI's) that are clinically important. Experiments on the VerSe dataset demonstrate this ability of our sampling policy, which is difficult to achieve based on uniform sampling.
FLAIR #1: semantic segmentation and domain adaptation dataset
Nov 28, 2022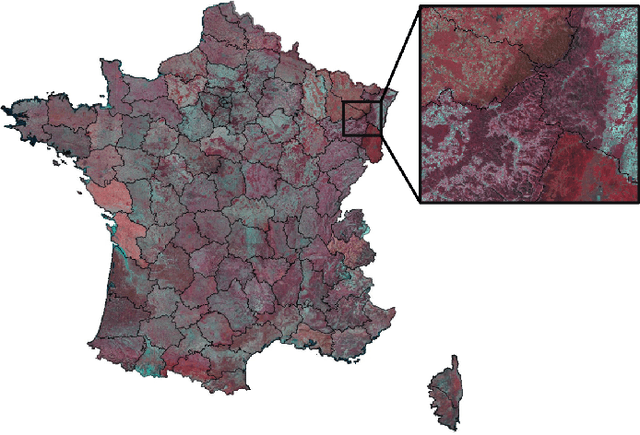
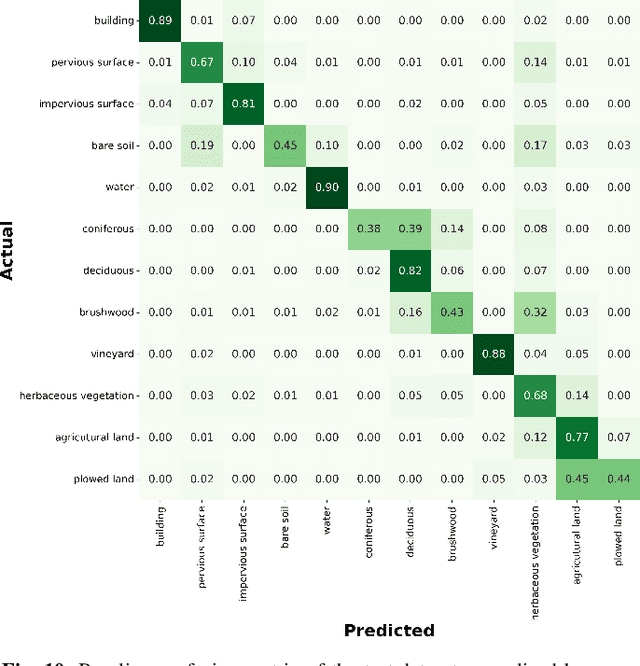
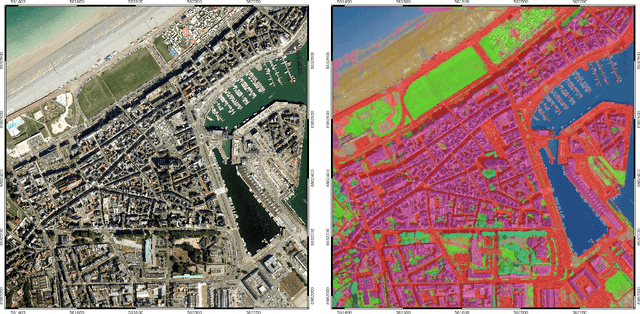
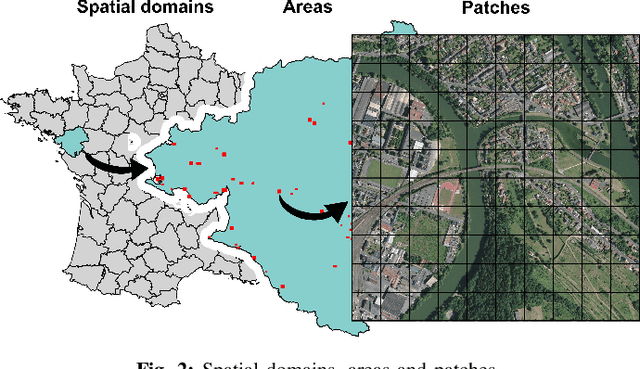
The French National Institute of Geographical and Forest Information (IGN) has the mission to document and measure land-cover on French territory and provides referential geographical datasets, including high-resolution aerial images and topographic maps. The monitoring of land-cover plays a crucial role in land management and planning initiatives, which can have significant socio-economic and environmental impact. Together with remote sensing technologies, artificial intelligence (IA) promises to become a powerful tool in determining land-cover and its evolution. IGN is currently exploring the potential of IA in the production of high-resolution land cover maps. Notably, deep learning methods are employed to obtain a semantic segmentation of aerial images. However, territories as large as France imply heterogeneous contexts: variations in landscapes and image acquisition make it challenging to provide uniform, reliable and accurate results across all of France. The FLAIR-one dataset presented is part of the dataset currently used at IGN to establish the French national reference land cover map "Occupation du sol \`a grande \'echelle" (OCS- GE).
Toward Global Sensing Quality Maximization: A Configuration Optimization Scheme for Camera Networks
Nov 28, 2022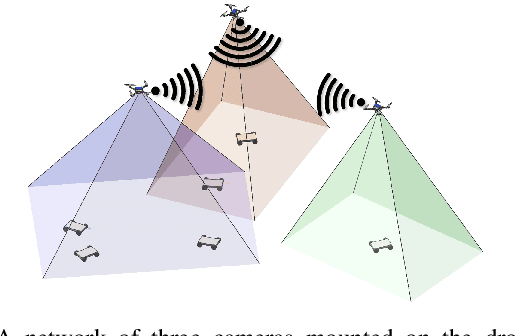
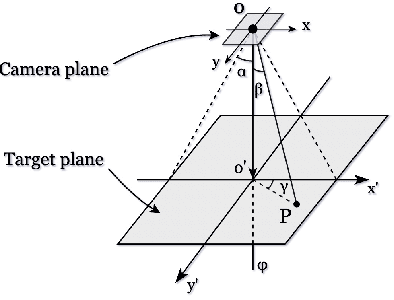
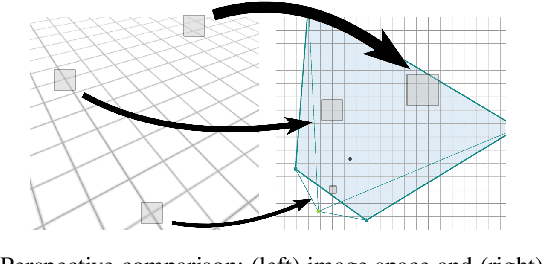
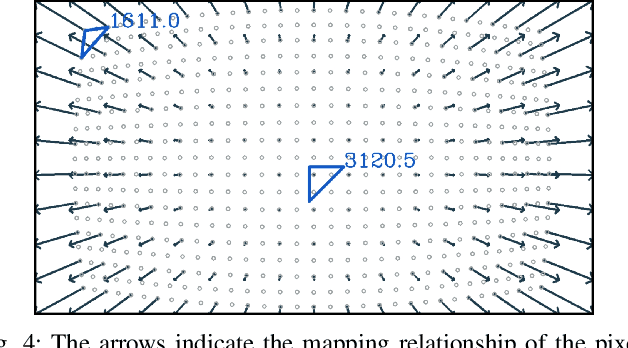
The performance of a camera network monitoring a set of targets depends crucially on the configuration of the cameras. In this paper, we investigate the reconfiguration strategy for the parameterized camera network model, with which the sensing qualities of the multiple targets can be optimized globally and simultaneously. We first propose to use the number of pixels occupied by a unit-length object in image as a metric of the sensing quality of the object, which is determined by the parameters of the camera, such as intrinsic, extrinsic, and distortional coefficients. Then, we form a single quantity that measures the sensing quality of the targets by the camera network. This quantity further serves as the objective function of our optimization problem to obtain the optimal camera configuration. We verify the effectiveness of our approach through extensive simulations and experiments, and the results reveal its improved performance on the AprilTag detection tasks. Codes and related utilities for this work are open-sourced and available at https://github.com/sszxc/MultiCam-Simulation.
Establishment of Neural Networks Robust to Label Noise
Nov 28, 2022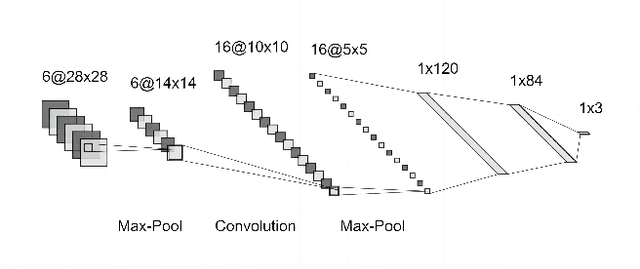

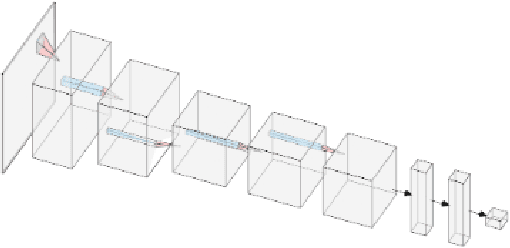

Label noise is a significant obstacle in deep learning model training. It can have a considerable impact on the performance of image classification models, particularly deep neural networks, which are especially susceptible because they have a strong propensity to memorise noisy labels. In this paper, we have examined the fundamental concept underlying related label noise approaches. A transition matrix estimator has been created, and its effectiveness against the actual transition matrix has been demonstrated. In addition, we examined the label noise robustness of two convolutional neural network classifiers with LeNet and AlexNet designs. The two FashionMINIST datasets have revealed the robustness of both models. We are not efficiently able to demonstrate the influence of the transition matrix noise correction on robustness enhancements due to our inability to correctly tune the complex convolutional neural network model due to time and computing resource constraints. There is a need for additional effort to fine-tune the neural network model and explore the precision of the estimated transition model in future research.
DeepAngle: Fast calculation of contact angles in tomography images using deep learning
Nov 28, 2022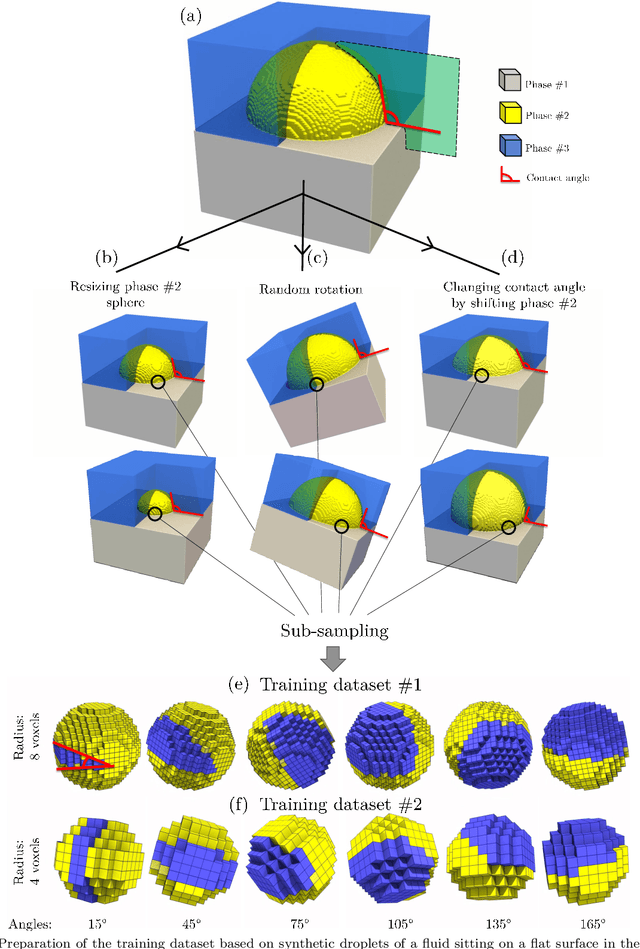
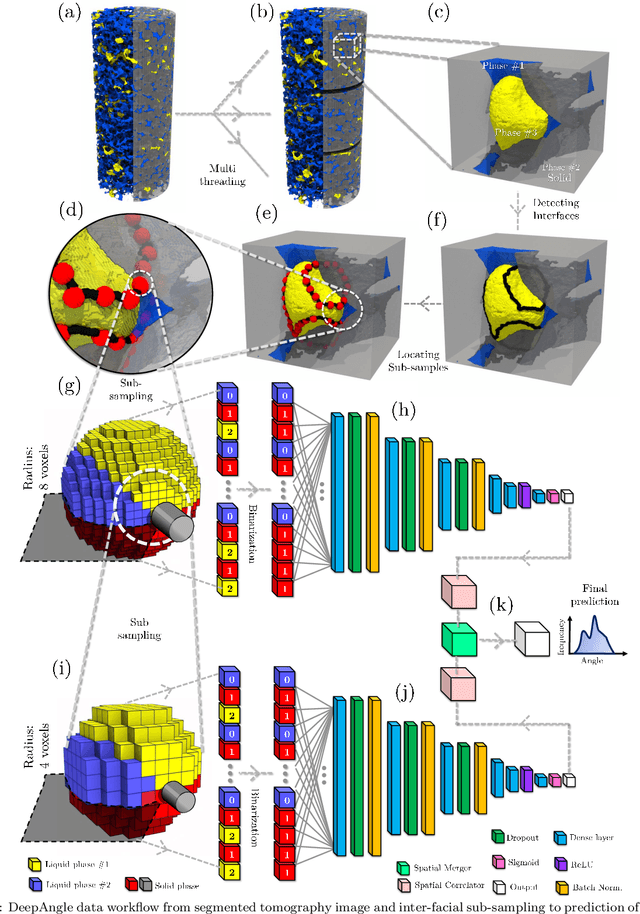
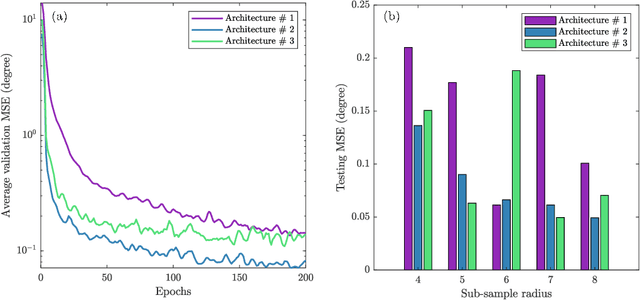
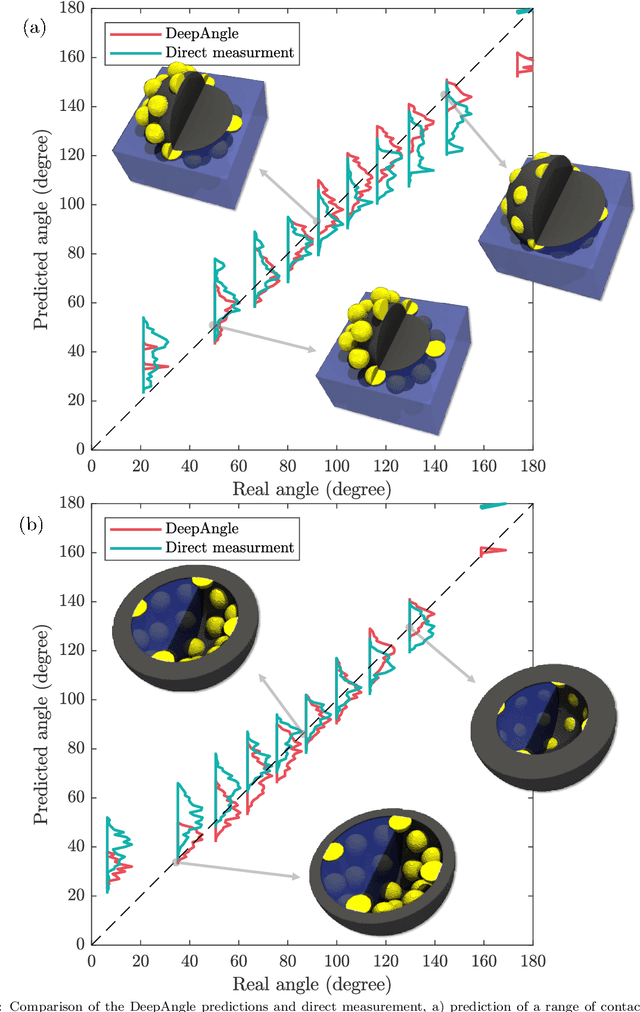
DeepAngle is a machine learning-based method to determine the contact angles of different phases in the tomography images of porous materials. Measurement of angles in 3--D needs to be done within the surface perpendicular to the angle planes, and it could become inaccurate when dealing with the discretized space of the image voxels. A computationally intensive solution is to correlate and vectorize all surfaces using an adaptable grid, and then measure the angles within the desired planes. On the contrary, the present study provides a rapid and low-cost technique powered by deep learning to estimate the interfacial angles directly from images. DeepAngle is tested on both synthetic and realistic images against the direct measurement technique and found to improve the r-squared by 5 to 16% while lowering the computational cost 20 times. This rapid method is especially applicable for processing large tomography data and time-resolved images, which is computationally intensive. The developed code and the dataset are available at an open repository on GitHub (https://www.github.com/ArashRabbani/DeepAngle).
FiT: Parameter Efficient Few-shot Transfer Learning for Personalized and Federated Image Classification
Jun 17, 2022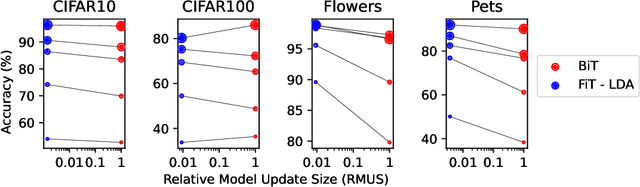
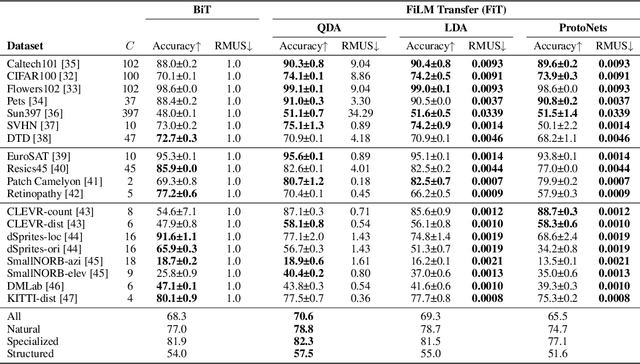

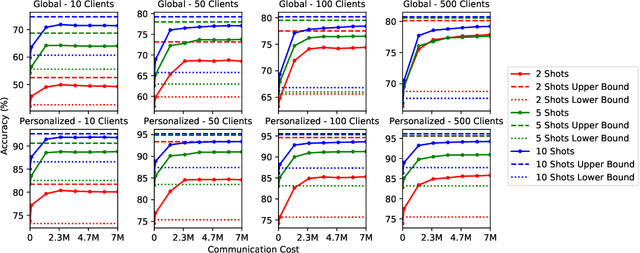
Modern deep learning systems are increasingly deployed in situations such as personalization and federated learning where it is necessary to support i) learning on small amounts of data, and ii) communication efficient distributed training protocols. In this work we develop FiLM Transfer (FiT) which fulfills these requirements in the image classification setting. FiT uses an automatically configured Naive Bayes classifier on top of a fixed backbone that has been pretrained on large image datasets. Parameter efficient FiLM layers are used to modulate the backbone, shaping the representation for the downstream task. The network is trained via an episodic fine-tuning protocol. The approach is parameter efficient which is key for enabling few-shot learning, inexpensive model updates for personalization, and communication efficient federated learning. We experiment with FiT on a wide range of downstream datasets and show that it achieves better classification accuracy than the state-of-the-art Big Transfer (BiT) algorithm at low-shot and on the challenging VTAB-1k benchmark, with fewer than 1% of the updateable parameters. Finally, we demonstrate the parameter efficiency of FiT in distributed low-shot applications including model personalization and federated learning where model update size is an important performance metric.
DeepCluE: Enhanced Image Clustering via Multi-layer Ensembles in Deep Neural Networks
Jun 01, 2022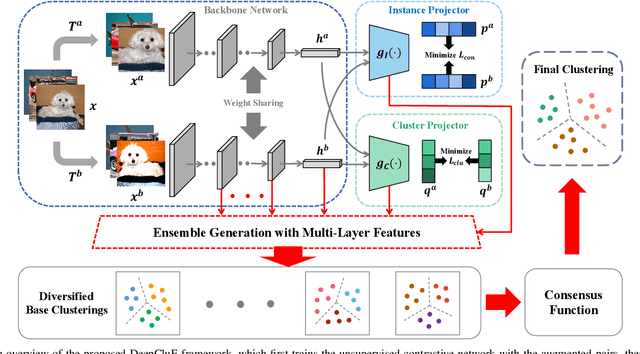

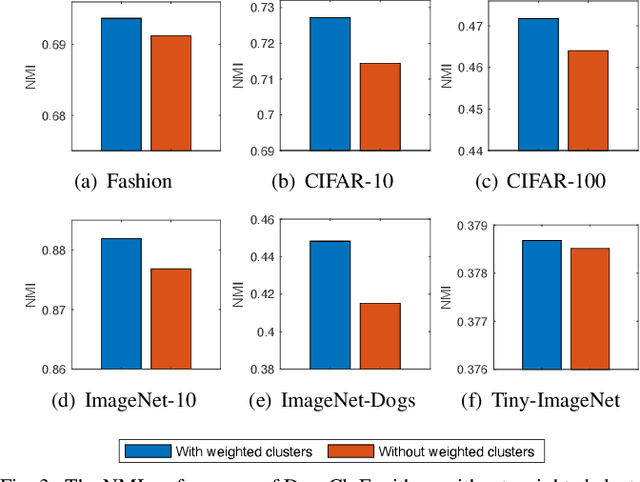
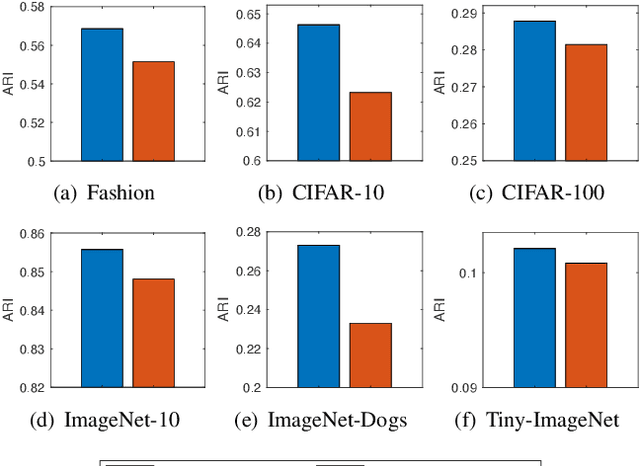
Deep clustering has recently emerged as a promising technique for complex image clustering. Despite the significant progress, previous deep clustering works mostly tend to construct the final clustering by utilizing a single layer of representation, e.g., by performing $K$-means on the last fully-connected layer or by associating some clustering loss to a specific layer. However, few of them have considered the possibilities and potential benefits of jointly leveraging multi-layer representations for enhancing the deep clustering performance. In light of this, this paper presents a Deep Clustering via Ensembles (DeepCluE) approach, which bridges the gap between deep clustering and ensemble clustering by harnessing the power of multiple layers in deep neural networks. Particularly, we utilize a weight-sharing convolutional neural network as the backbone, which is trained with both the instance-level contrastive learning (via an instance projector) and the cluster-level contrastive learning (via a cluster projector) in an unsupervised manner. Thereafter, multiple layers of feature representations are extracted from the trained network, upon which a set of diversified base clusterings can be generated via a highly efficient clusterer. Then, the reliability of the clusters in multiple base clusterings is automatically estimated by exploiting an entropy-based criterion, based on which the multiple base clusterings are further formulated into a weighted-cluster bipartite graph. By partitioning this bipartite graph via transfer cut, the final image clustering result can therefore be obtained. Experimental results on six image datasets confirm the advantages of our DeepCluE approach over the state-of-the-art deep clustering approaches.
WALDO: Future Video Synthesis using Object Layer Decomposition and Parametric Flow Prediction
Nov 25, 2022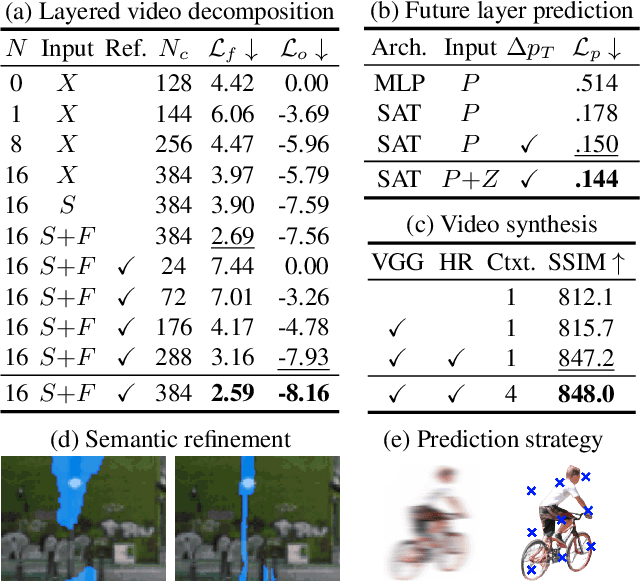
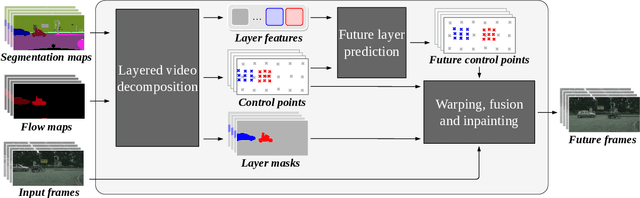
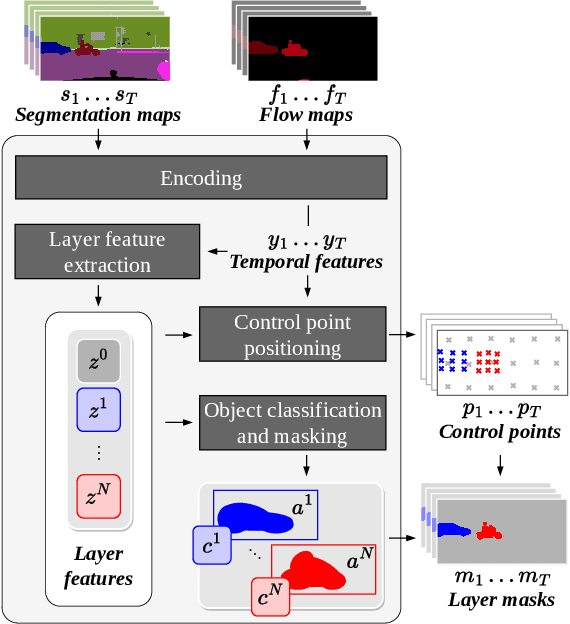
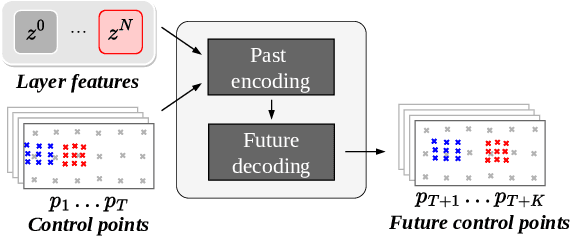
This paper presents WALDO (WArping Layer-Decomposed Objects), a novel approach to the prediction of future video frames from past ones. Individual images are decomposed into multiple layers combining object masks and a small set of control points. The layer structure is shared across all frames in each video to build dense inter-frame connections. Complex scene motions are modeled by combining parametric geometric transformations associated with individual layers, and video synthesis is broken down into discovering the layers associated with past frames, predicting the corresponding transformations for upcoming ones and warping the associated object regions accordingly, and filling in the remaining image parts. Extensive experiments on the Cityscapes (resp. KITTI) dataset show that WALDO significantly outperforms prior works with, e.g., 3, 27, and 51% (resp. 5, 20 and 11%) relative improvement in SSIM, LPIPS and FVD metrics. Code, pretrained models, and video samples synthesized by our approach can be found in the project webpage https://16lemoing.github.io/waldo.
Composite Score for Anomaly Detection in Imbalanced Real-World Industrial Dataset
Nov 25, 2022
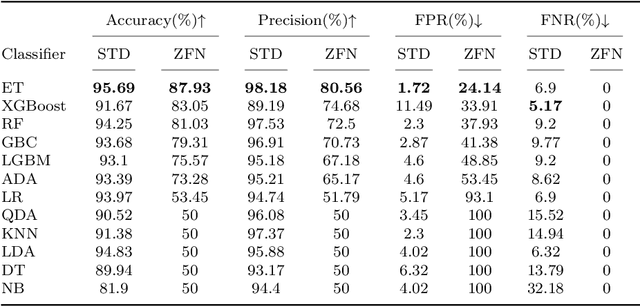
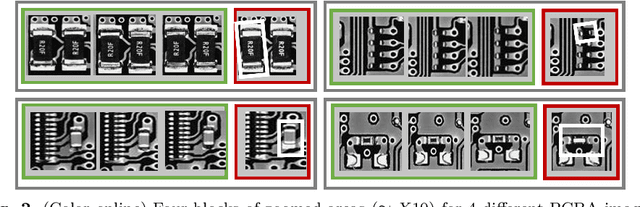
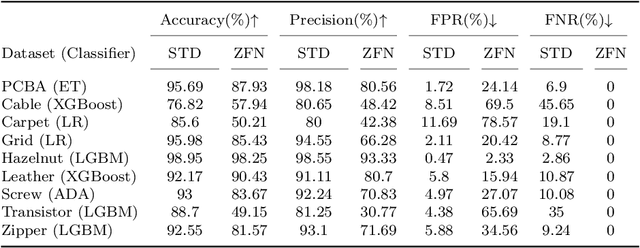
In recent years, the industrial sector has evolved towards its fourth revolution. The quality control domain is particularly interested in advanced machine learning for computer vision anomaly detection. Nevertheless, several challenges have to be faced, including imbalanced datasets, the image complexity, and the zero-false-negative (ZFN) constraint to guarantee the high-quality requirement. This paper illustrates a use case for an industrial partner, where Printed Circuit Board Assembly (PCBA) images are first reconstructed with a Vector Quantized Generative Adversarial Network (VQGAN) trained on normal products. Then, several multi-level metrics are extracted on a few normal and abnormal images, highlighting anomalies through reconstruction differences. Finally, a classifer is trained to build a composite anomaly score thanks to the metrics extracted. This three-step approach is performed on the public MVTec-AD datasets and on the partner PCBA dataset, where it achieves a regular accuracy of 95.69% and 87.93% under the ZFN constraint.