 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Kernel Perspective of Skip Connections in Convolutional Networks
Nov 27, 2022
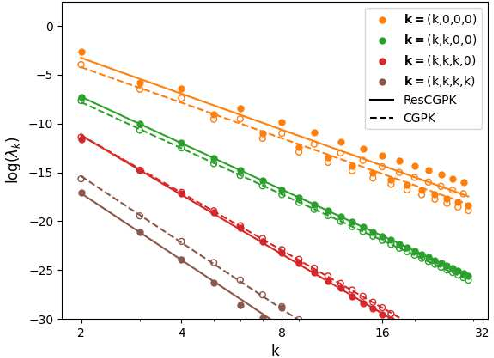
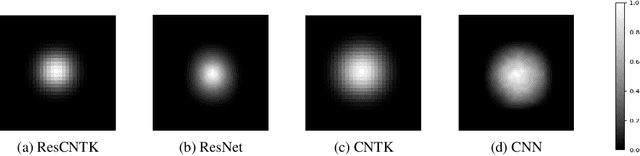
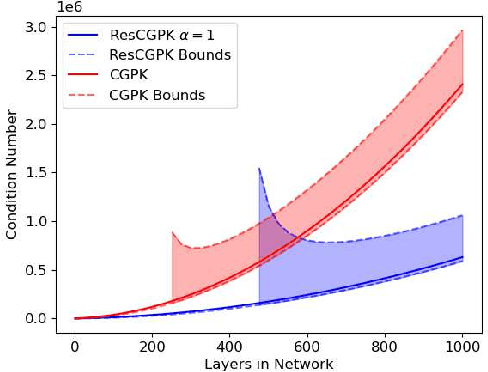
Over-parameterized residual networks (ResNets) are amongst the most successful convolutional neural architectures for image processing. Here we study their properties through their Gaussian Process and Neural Tangent kernels. We derive explicit formulas for these kernels, analyze their spectra, and provide bounds on their implied condition numbers. Our results indicate that (1) with ReLU activation, the eigenvalues of these residual kernels decay polynomially at a similar rate compared to the same kernels when skip connections are not used, thus maintaining a similar frequency bias; (2) however, residual kernels are more locally biased. Our analysis further shows that the matrices obtained by these residual kernels yield favorable condition numbers at finite depths than those obtained without the skip connections, enabling therefore faster convergence of training with gradient descent.
Information Retrieval from the Digitized Books
Dec 02, 2022

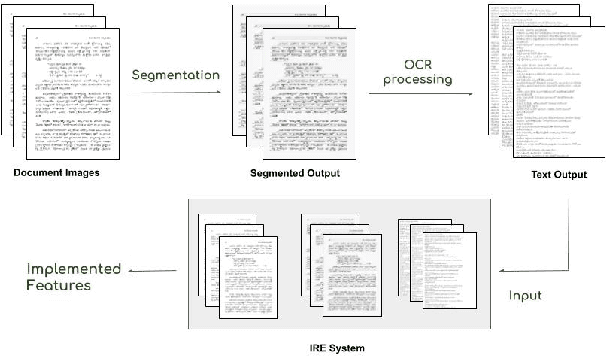
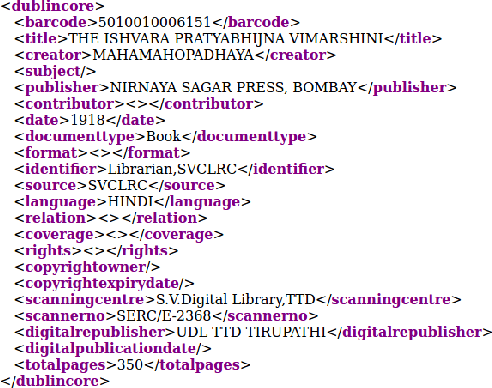
Extracting the relevant information out of a large number of documents is a challenging and tedious task. The quality of results generated by the traditionally available full-text search engine and text-based image retrieval systems is not optimal. Information retrieval (IR) tasks become more challenging with the nontraditional language scripts, as in the case of Indic scripts. The authors have developed OCR (Optical Character Recognition) Search Engine to make an Information Retrieval & Extraction (IRE) system that replicates the current state-of-the-art methods using the IRE and Natural Language Processing (NLP) techniques. Here we have presented the study of the methods used for performing search and retrieval tasks. The details of this system, along with the statistics of the dataset (source: National Digital Library of India or NDLI), is also presented. Additionally, the ideas to further explore and add value to research in IRE are also discussed.
A Dataset with Multibeam Forward-Looking Sonar for Underwater Object Detection
Dec 02, 2022Multibeam forward-looking sonar (MFLS) plays an important role in underwater detection. There are several challenges to the research on underwater object detection with MFLS. Firstly, the research is lack of available dataset. Secondly, the sonar image, generally processed at pixel level and transformed to sector representation for the visual habits of human beings, is disadvantageous to the research in artificial intelligence (AI) areas. Towards these challenges, we present a novel dataset, the underwater acoustic target detection (UATD) dataset, consisting of over 9000 MFLS images captured using Tritech Gemini 1200ik sonar. Our dataset provides raw data of sonar images with annotation of 10 categories of target objects (cube, cylinder, tyres, etc). The data was collected from lake and shallow water. To verify the practicality of UATD, we apply the dataset to the state-of-the-art detectors and provide corresponding benchmarks for its accuracy and efficiency.
StructVPR: Distill Structural Knowledge with Weighting Samples for Visual Place Recognition
Dec 09, 2022Visual place recognition (VPR) is usually considered as a specific image retrieval problem. Limited by existing training frameworks, most deep learning-based works cannot extract sufficiently stable global features from RGB images and rely on a time-consuming re-ranking step to exploit spatial structural information for better performance. In this paper, we propose StructVPR, a novel training architecture for VPR, to enhance structural knowledge in RGB global features and thus improve feature stability in a constantly changing environment. Specifically, StructVPR uses segmentation images as a more definitive source of structural knowledge input into a CNN network and applies knowledge distillation to avoid online segmentation and inference of seg-branch in testing. Considering that not all samples contain high-quality and helpful knowledge, and some even hurt the performance of distillation, we partition samples and weigh each sample's distillation loss to enhance the expected knowledge precisely. Finally, StructVPR achieves impressive performance on several benchmarks using only global retrieval and even outperforms many two-stage approaches by a large margin. After adding additional re-ranking, ours achieves state-of-the-art performance while maintaining a low computational cost.
Frozen CLIP Model is An Efficient Point Cloud Backbone
Dec 09, 2022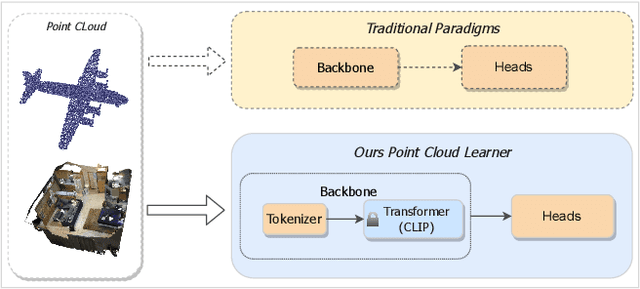

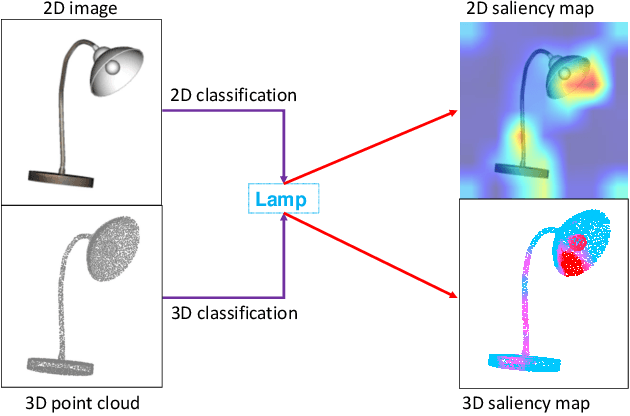
The pretraining-finetuning paradigm has demonstrated great success in NLP and 2D image fields because of the high-quality representation ability and transferability of their pretrained models. However, pretraining such a strong model is difficult in the 3D point cloud field since the training data is limited and point cloud collection is expensive. This paper introduces Efficient Point Cloud Learning (EPCL), an effective and efficient point cloud learner for directly training high-quality point cloud models with a frozen CLIP model. Our EPCL connects the 2D and 3D modalities by semantically aligning the 2D features and point cloud features without paired 2D-3D data. Specifically, the input point cloud is divided into a sequence of tokens and directly fed into the frozen CLIP model to learn point cloud representation. Furthermore, we design a task token to narrow the gap between 2D images and 3D point clouds. Comprehensive experiments on 3D detection, semantic segmentation, classification and few-shot learning demonstrate that the 2D CLIP model can be an efficient point cloud backbone and our method achieves state-of-the-art accuracy on both real-world and synthetic downstream tasks. Code will be available.
Temporal error concealment for fisheye video sequences based on equisolid re-projection
Nov 21, 2022
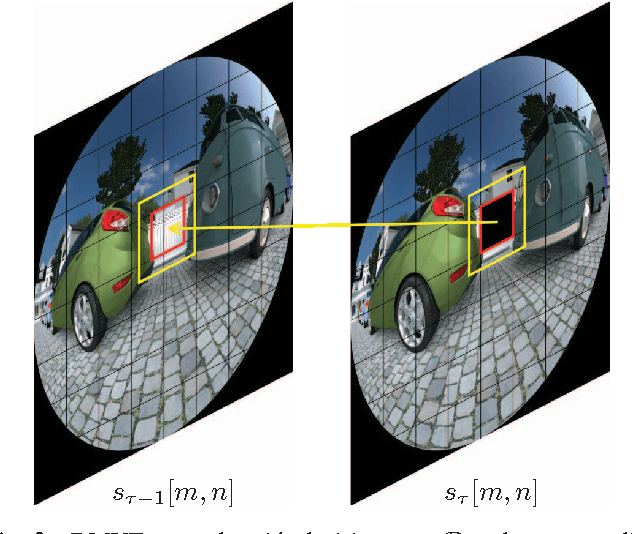
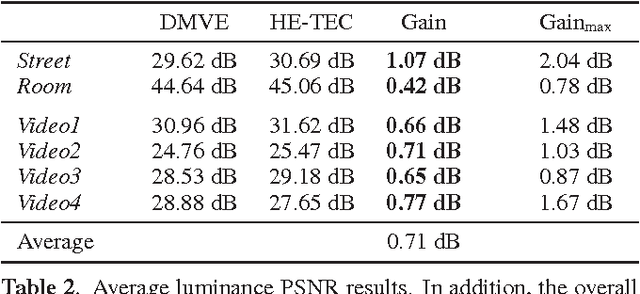
Wide-angle video sequences obtained by fisheye cameras exhibit characteristics that may not very well comply with standard image and video processing techniques such as error concealment. This paper introduces a temporal error concealment technique designed for the inherent characteristics of equisolid fisheye video sequences by applying a re-projection into the equisolid domain after conducting part of the error concealment in the perspective domain. Combining this technique with conventional decoder motion vector estimation achieves average gains of 0.71 dB compared against pure decoder motion vector estimation for the test sequences used. Maximum gains amount to up to 2.04 dB for selected frames.
PatchRot: A Self-Supervised Technique for Training Vision Transformers
Oct 27, 2022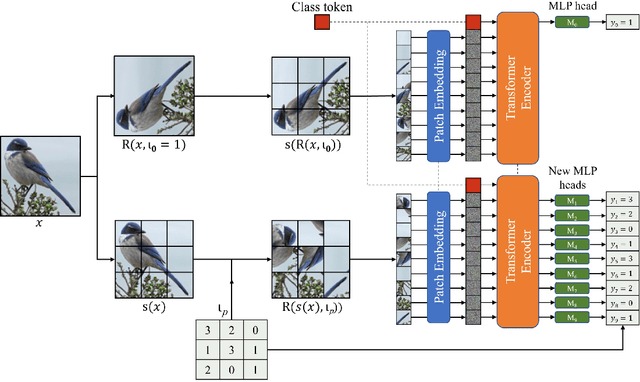
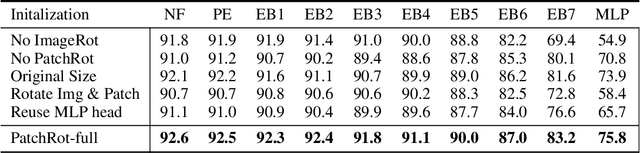
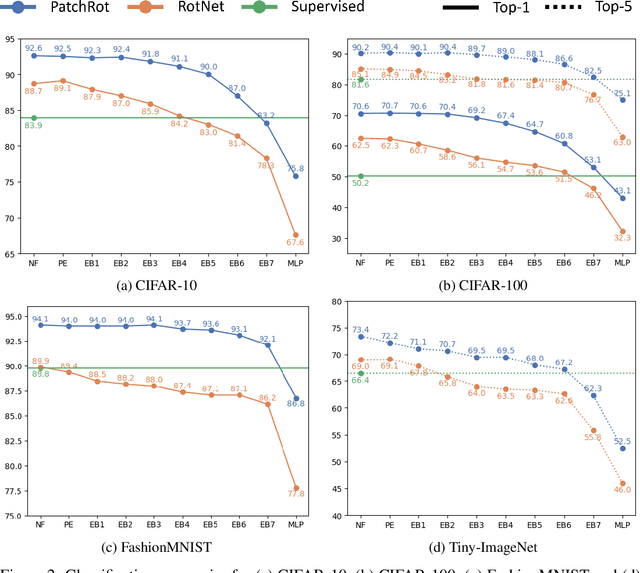
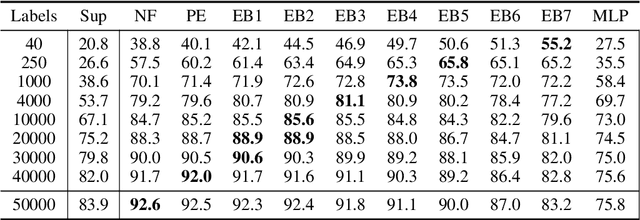
Vision transformers require a huge amount of labeled data to outperform convolutional neural networks. However, labeling a huge dataset is a very expensive process. Self-supervised learning techniques alleviate this problem by learning features similar to supervised learning in an unsupervised way. In this paper, we propose a self-supervised technique PatchRot that is crafted for vision transformers. PatchRot rotates images and image patches and trains the network to predict the rotation angles. The network learns to extract both global and local features from an image. Our extensive experiments on different datasets showcase PatchRot training learns rich features which outperform supervised learning and compared baseline.
Improving dermatology classifiers across populations using images generated by large diffusion models
Nov 23, 2022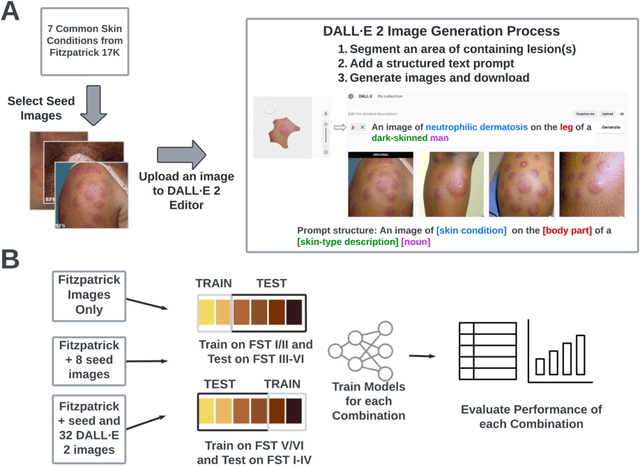
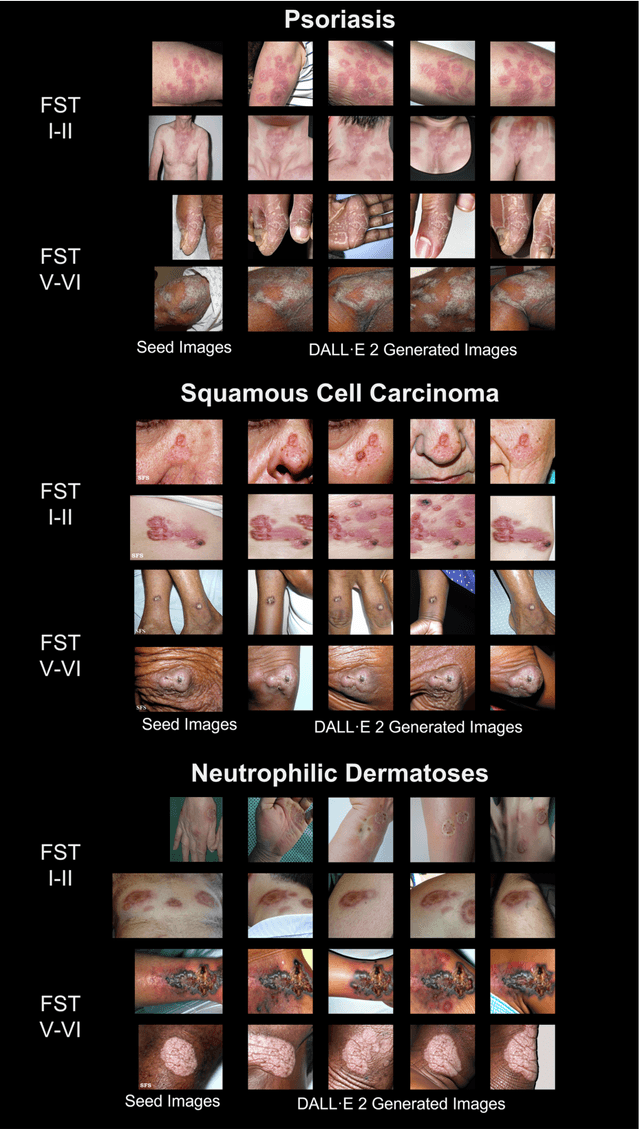
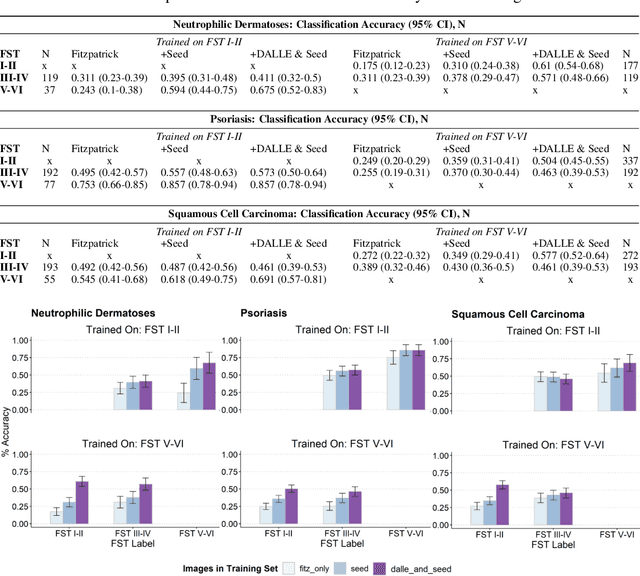
Dermatological classification algorithms developed without sufficiently diverse training data may generalize poorly across populations. While intentional data collection and annotation offer the best means for improving representation, new computational approaches for generating training data may also aid in mitigating the effects of sampling bias. In this paper, we show that DALL$\cdot$E 2, a large-scale text-to-image diffusion model, can produce photorealistic images of skin disease across skin types. Using the Fitzpatrick 17k dataset as a benchmark, we demonstrate that augmenting training data with DALL$\cdot$E 2-generated synthetic images improves classification of skin disease overall and especially for underrepresented groups.
LPT: Long-tailed Prompt Tuning for Image Classification
Oct 03, 2022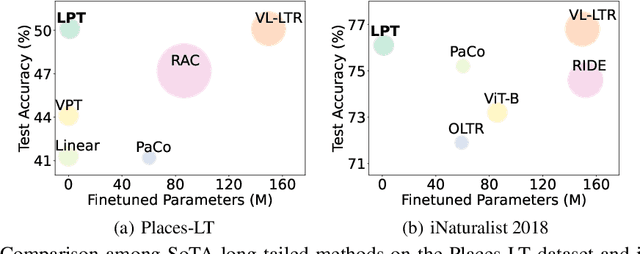
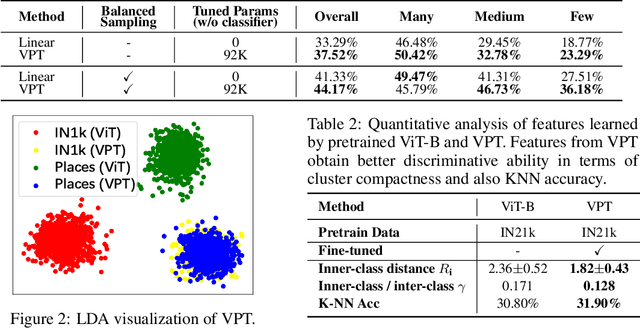
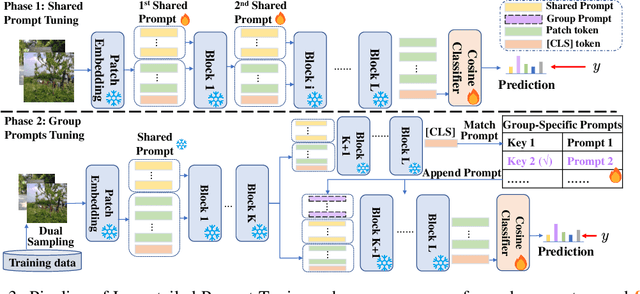
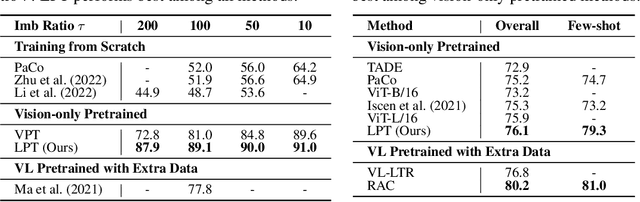
For long-tailed classification, most works often pretrain a big model on a large-scale dataset, and then fine-tune the whole model for adapting to long-tailed data. Though promising, fine-tuning the whole pretrained model tends to suffer from high cost in computation and deployment of different models for different tasks, as well as weakened generalization ability for overfitting to certain features of long-tailed data. To alleviate these issues, we propose an effective Long-tailed Prompt Tuning method for long-tailed classification. LPT introduces several trainable prompts into a frozen pretrained model to adapt it to long-tailed data. For better effectiveness, we divide prompts into two groups: 1) a shared prompt for the whole long-tailed dataset to learn general features and to adapt a pretrained model into target domain; and 2) group-specific prompts to gather group-specific features for the samples which have similar features and also to empower the pretrained model with discrimination ability. Then we design a two-phase training paradigm to learn these prompts. In phase 1, we train the shared prompt via supervised prompt tuning to adapt a pretrained model to the desired long-tailed domain. In phase 2, we use the learnt shared prompt as query to select a small best matched set for a group of similar samples from the group-specific prompt set to dig the common features of these similar samples, then optimize these prompts with dual sampling strategy and asymmetric GCL loss. By only fine-tuning a few prompts while fixing the pretrained model, LPT can reduce training and deployment cost by storing a few prompts, and enjoys a strong generalization ability of the pretrained model. Experiments show that on various long-tailed benchmarks, with only ~1.1% extra parameters, LPT achieves comparable performance than previous whole model fine-tuning methods, and is more robust to domain-shift.
Convolutional networks inherit frequency sensitivity from image statistics
Oct 03, 2022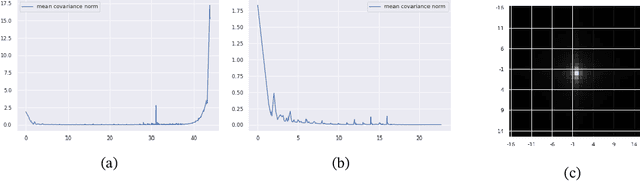

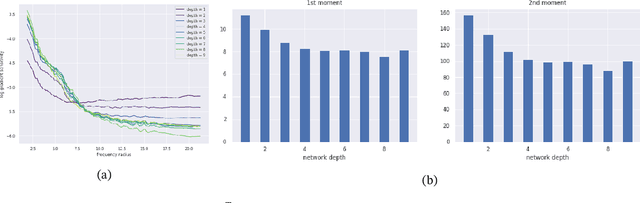
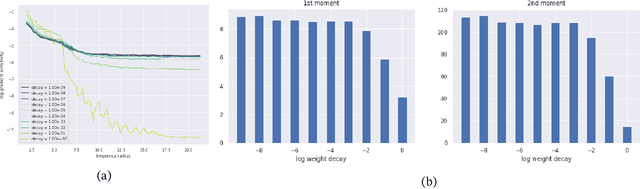
It is widely acknowledged that trained convolutional neural networks (CNNs) have different levels of sensitivity to signals of different frequency. In particular, a number of empirical studies have documented CNNs sensitivity to low-frequency signals. In this work we show with theory and experiments that this observed sensitivity is a consequence of the frequency distribution of natural images, which is known to have most of its power concentrated in low-to-mid frequencies. Our theoretical analysis relies on representations of the layers of a CNN in frequency space, an idea that has previously been used to accelerate computations and study implicit bias of network training algorithms, but to the best of our knowledge has not been applied in the domain of model robustness.