 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Decomposition and Bilinear Pooling Network for Blind Night-Time Image Quality Evaluation
May 12, 2022
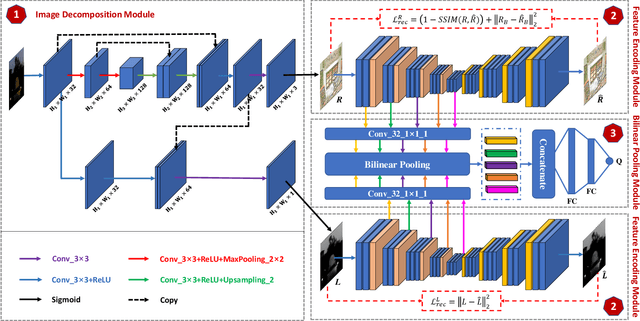
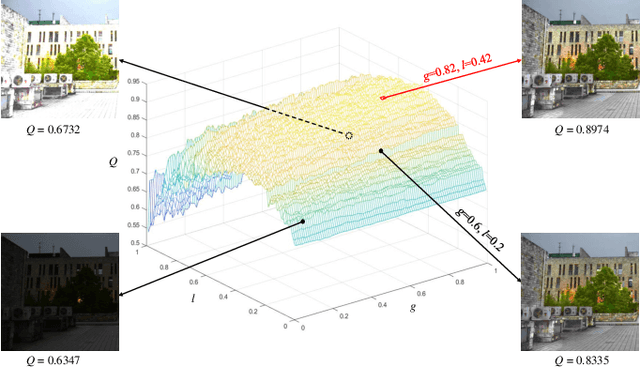
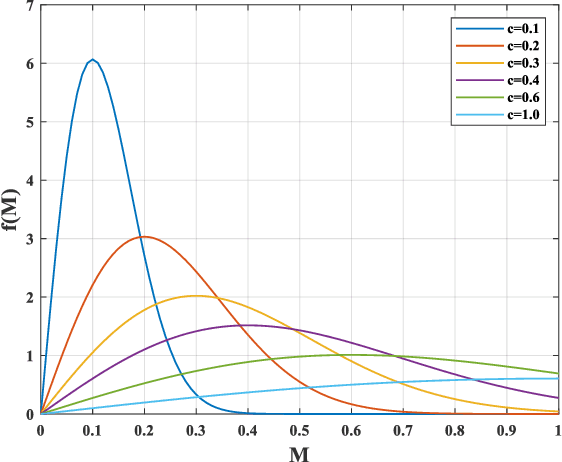
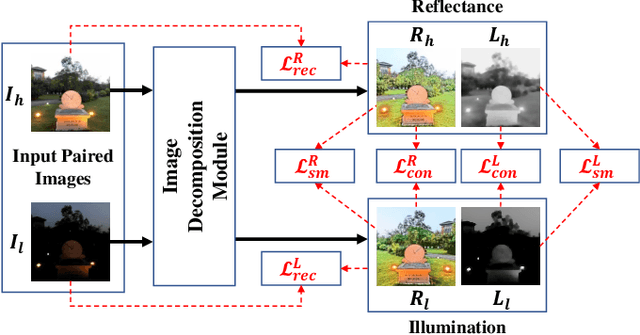
Blind image quality assessment (BIQA), which aims to accurately predict the image quality without any pristine reference information, has been highly concerned in the past decades. Especially, with the help of deep neural networks, great progress has been achieved so far. However, it remains less investigated on BIQA for night-time images (NTIs) which usually suffer from complicated authentic distortions such as reduced visibility, low contrast, additive noises, and color distortions. These diverse authentic degradations particularly challenges the design of effective deep neural network for blind NTI quality evaluation (NTIQE). In this paper, we propose a novel deep decomposition and bilinear pooling network (DDB-Net) to better address this issue. The DDB-Net contains three modules, i.e., an image decomposition module, a feature encoding module, and a bilinear pooling module. The image decomposition module is inspired by the Retinex theory and involves decoupling the input NTI into an illumination layer component responsible for illumination information and a reflectance layer component responsible for content information. Then, the feature encoding module involves learning multi-scale feature representations of degradations that are rooted in the two decoupled components separately. Finally, by modeling illumination-related and content-related degradations as two-factor variations, the two multi-scale feature sets are bilinearly pooled and concatenated together to form a unified representation for quality prediction. The superiority of the proposed DDB-Net is well validated by extensive experiments on two publicly available night-time image databases.
Skin disease diagnosis using image analysis and natural language processing
May 09, 2022
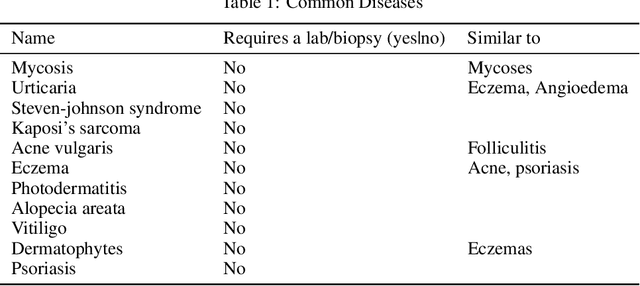
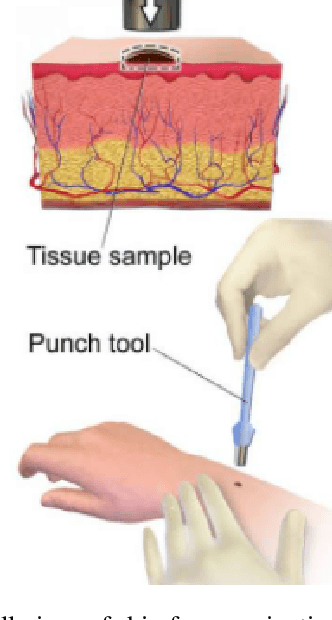
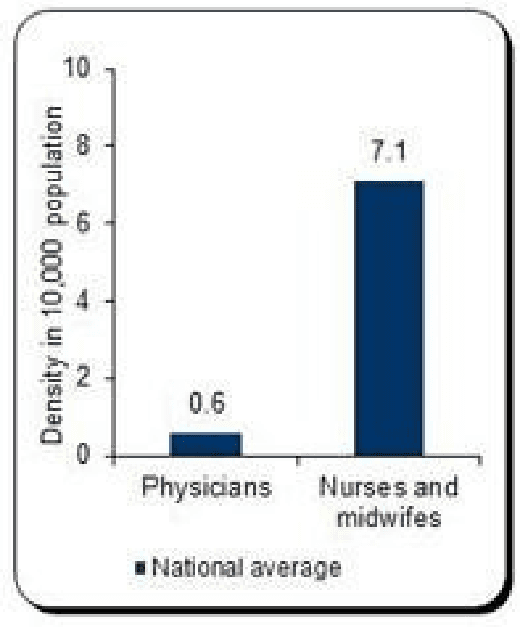
In Zambia, there is a serious shortage of medical staff where each practitioner attends to about 17000 patients in a given district while still, other patients travel over 10 km to access the basic medical services. In this research, we implement a deep learning model that can perform the clinical diagnosis process. The study will prove whether image analysis is capable of performing clinical diagnosis. It will also enable us to understand if we can use image analysis to lessen the workload on medical practitioners by delegating some tasks to an AI. The success of this study has the potential to increase the accessibility of medical services to Zambians, which is one of the national goals of Vision 2030.
Multimodal Tree Decoder for Table of Contents Extraction in Document Images
Dec 06, 2022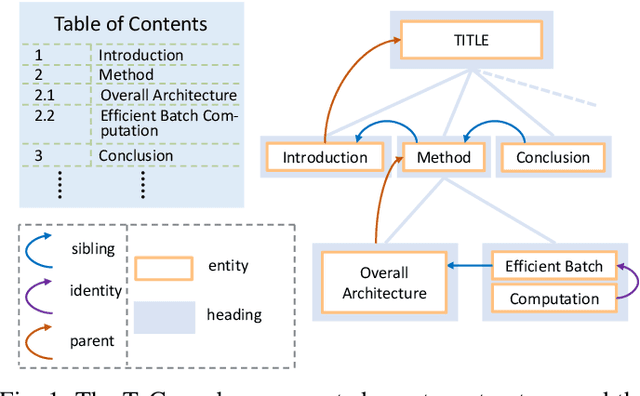

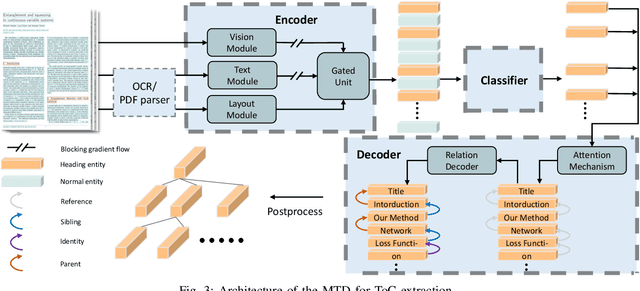
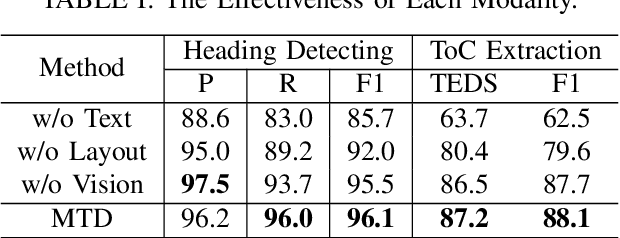
Table of contents (ToC) extraction aims to extract headings of different levels in documents to better understand the outline of the contents, which can be widely used for document understanding and information retrieval. Existing works often use hand-crafted features and predefined rule-based functions to detect headings and resolve the hierarchical relationship between headings. Both the benchmark and research based on deep learning are still limited. Accordingly, in this paper, we first introduce a standard dataset, HierDoc, including image samples from 650 documents of scientific papers with their content labels. Then we propose a novel end-to-end model by using the multimodal tree decoder (MTD) for ToC as a benchmark for HierDoc. The MTD model is mainly composed of three parts, namely encoder, classifier, and decoder. The encoder fuses the multimodality features of vision, text, and layout information for each entity of the document. Then the classifier recognizes and selects the heading entities. Next, to parse the hierarchical relationship between the heading entities, a tree-structured decoder is designed. To evaluate the performance, both the metric of tree-edit-distance similarity (TEDS) and F1-Measure are adopted. Finally, our MTD approach achieves an average TEDS of 87.2% and an average F1-Measure of 88.1% on the test set of HierDoc. The code and dataset will be released at: https://github.com/Pengfei-Hu/MTD.
Robust Point Cloud Segmentation with Noisy Annotations
Dec 06, 2022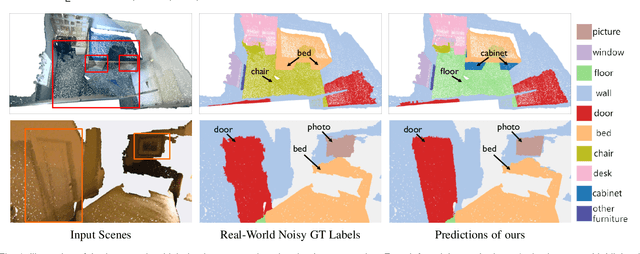

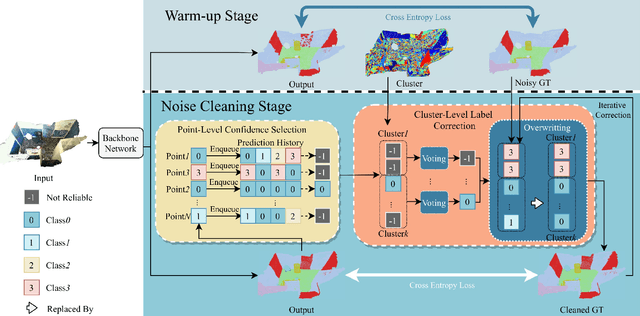
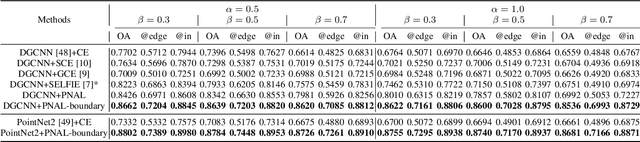
Point cloud segmentation is a fundamental task in 3D. Despite recent progress on point cloud segmentation with the power of deep networks, current learning methods based on the clean label assumptions may fail with noisy labels. Yet, class labels are often mislabeled at both instance-level and boundary-level in real-world datasets. In this work, we take the lead in solving the instance-level label noise by proposing a Point Noise-Adaptive Learning (PNAL) framework. Compared to noise-robust methods on image tasks, our framework is noise-rate blind, to cope with the spatially variant noise rate specific to point clouds. Specifically, we propose a point-wise confidence selection to obtain reliable labels from the historical predictions of each point. A cluster-wise label correction is proposed with a voting strategy to generate the best possible label by considering the neighbor correlations. To handle boundary-level label noise, we also propose a variant ``PNAL-boundary " with a progressive boundary label cleaning strategy. Extensive experiments demonstrate its effectiveness on both synthetic and real-world noisy datasets. Even with $60\%$ symmetric noise and high-level boundary noise, our framework significantly outperforms its baselines, and is comparable to the upper bound trained on completely clean data. Moreover, we cleaned the popular real-world dataset ScanNetV2 for rigorous experiment. Our code and data is available at https://github.com/pleaseconnectwifi/PNAL.
Semantically Enhanced Global Reasoning for Semantic Segmentation
Dec 06, 2022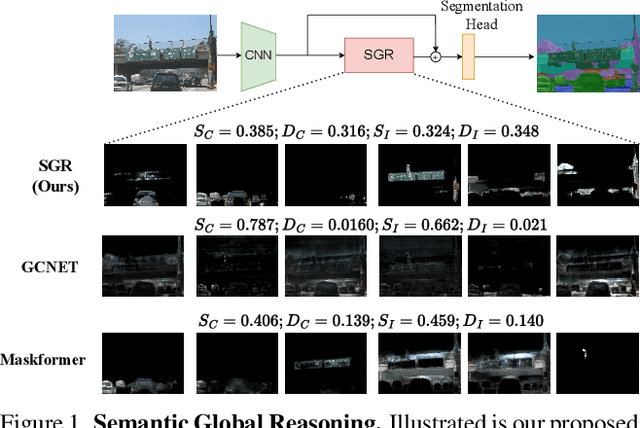
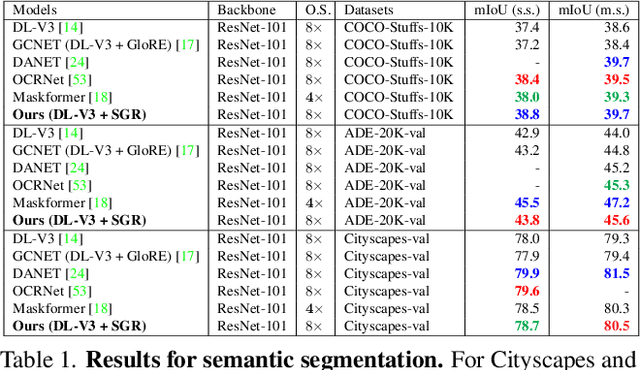
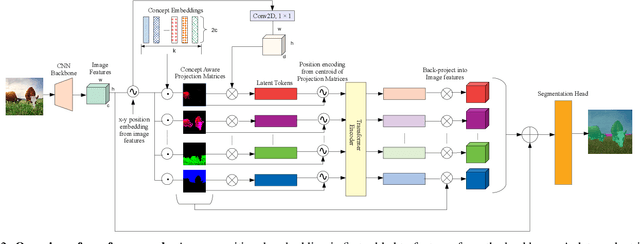
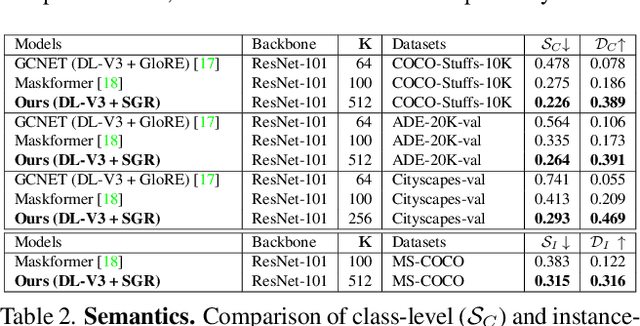
Recent advances in pixel-level tasks (e.g., segmentation) illustrate the benefit of long-range interactions between aggregated region-based representations that can enhance local features. However, such pixel-to-region associations and the resulting representation, which often take the form of attention, cannot model the underlying semantic structure of the scene (e.g., individual objects and, by extension, their interactions). In this work, we take a step toward addressing this limitation. Specifically, we propose an architecture where we learn to project image features into latent region representations and perform global reasoning across them, using a transformer, to produce contextualized and scene-consistent representations that are then fused with original pixel-level features. Our design enables the latent regions to represent semantically meaningful concepts, by ensuring that activated regions are spatially disjoint and unions of such regions correspond to connected object segments. The resulting semantic global reasoning (SGR) is end-to-end trainable and can be combined with any semantic segmentation framework and backbone. Combining SGR with DeepLabV3 results in a semantic segmentation performance that is competitive to the state-of-the-art, while resulting in more semantically interpretable and diverse region representations, which we show can effectively transfer to detection and instance segmentation. Further, we propose a new metric that allows us to measure the semantics of representations at both the object class and instance level.
Towards Real-Time Text2Video via CLIP-Guided, Pixel-Level Optimization
Oct 23, 2022


We introduce an approach to generating videos based on a series of given language descriptions. Frames of the video are generated sequentially and optimized by guidance from the CLIP image-text encoder; iterating through language descriptions, weighting the current description higher than others. As opposed to optimizing through an image generator model itself, which tends to be computationally heavy, the proposed approach computes the CLIP loss directly at the pixel level, achieving general content at a speed suitable for near real-time systems. The approach can generate videos in up to 720p resolution, variable frame-rates, and arbitrary aspect ratios at a rate of 1-2 frames per second. Please visit our website to view videos and access our open-source code: https://pschaldenbrand.github.io/text2video/ .
Generalised Image Outpainting with U-Transformer
Jan 27, 2022

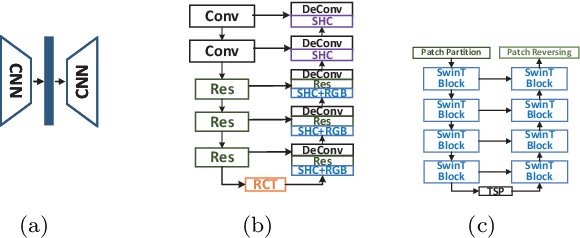
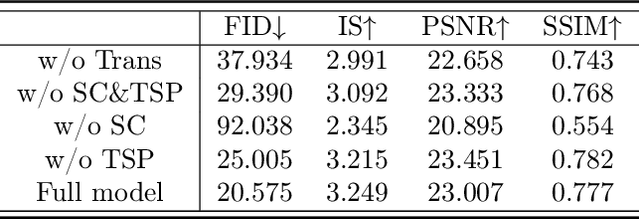
While most present image outpainting conducts horizontal extrapolation, we study the generalised image outpainting problem that extrapolates visual context all-side around a given image. To this end, we develop a novel transformer-based generative adversarial network called U-Transformer able to extend image borders with plausible structure and details even for complicated scenery images. Specifically, we design a generator as an encoder-to-decoder structure embedded with the popular Swin Transformer blocks. As such, our novel framework can better cope with image long-range dependencies which are crucially important for generalised image outpainting. We propose additionally a U-shaped structure and multi-view Temporal Spatial Predictor network to reinforce image self-reconstruction as well as unknown-part prediction smoothly and realistically. We experimentally demonstrate that our proposed method could produce visually appealing results for generalized image outpainting against the state-of-the-art image outpainting approaches.
Group Generalized Mean Pooling for Vision Transformer
Dec 08, 2022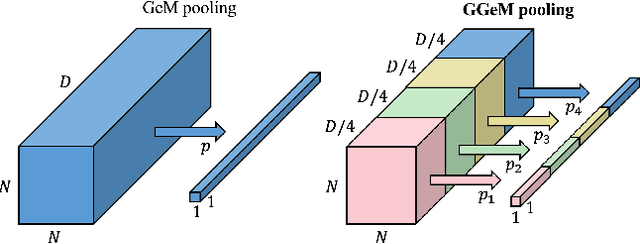
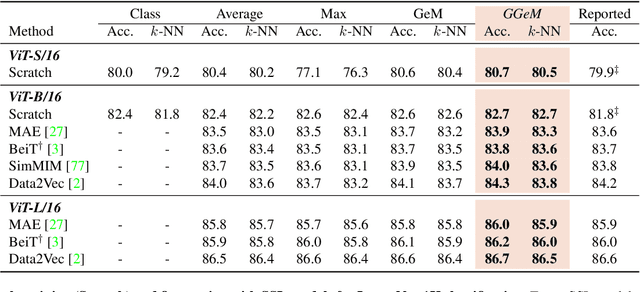
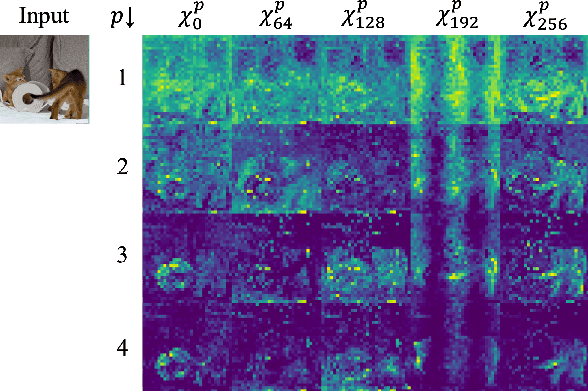
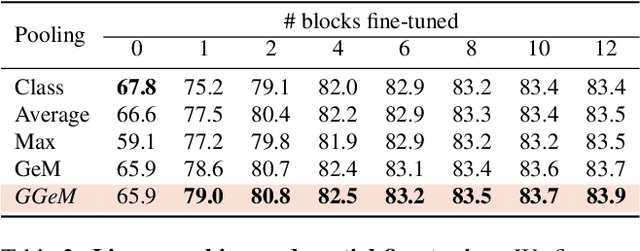
Vision Transformer (ViT) extracts the final representation from either class token or an average of all patch tokens, following the architecture of Transformer in Natural Language Processing (NLP) or Convolutional Neural Networks (CNNs) in computer vision. However, studies for the best way of aggregating the patch tokens are still limited to average pooling, while widely-used pooling strategies, such as max and GeM pooling, can be considered. Despite their effectiveness, the existing pooling strategies do not consider the architecture of ViT and the channel-wise difference in the activation maps, aggregating the crucial and trivial channels with the same importance. In this paper, we present Group Generalized Mean (GGeM) pooling as a simple yet powerful pooling strategy for ViT. GGeM divides the channels into groups and computes GeM pooling with a shared pooling parameter per group. As ViT groups the channels via a multi-head attention mechanism, grouping the channels by GGeM leads to lower head-wise dependence while amplifying important channels on the activation maps. Exploiting GGeM shows 0.1%p to 0.7%p performance boosts compared to the baselines and achieves state-of-the-art performance for ViT-Base and ViT-Large models in ImageNet-1K classification task. Moreover, GGeM outperforms the existing pooling strategies on image retrieval and multi-modal representation learning tasks, demonstrating the superiority of GGeM for a variety of tasks. GGeM is a simple algorithm in that only a few lines of code are necessary for implementation.
MagicMix: Semantic Mixing with Diffusion Models
Oct 28, 2022

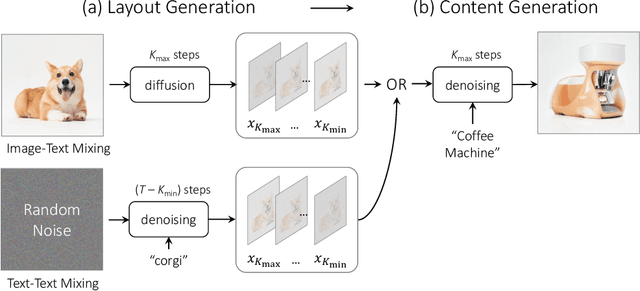
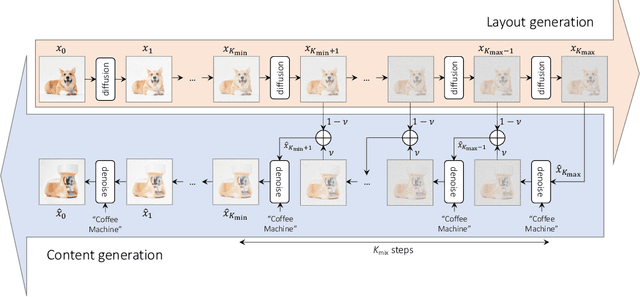
Have you ever imagined what a corgi-alike coffee machine or a tiger-alike rabbit would look like? In this work, we attempt to answer these questions by exploring a new task called semantic mixing, aiming at blending two different semantics to create a new concept (e.g., corgi + coffee machine -- > corgi-alike coffee machine). Unlike style transfer, where an image is stylized according to the reference style without changing the image content, semantic blending mixes two different concepts in a semantic manner to synthesize a novel concept while preserving the spatial layout and geometry. To this end, we present MagicMix, a simple yet effective solution based on pre-trained text-conditioned diffusion models. Motivated by the progressive generation property of diffusion models where layout/shape emerges at early denoising steps while semantically meaningful details appear at later steps during the denoising process, our method first obtains a coarse layout (either by corrupting an image or denoising from a pure Gaussian noise given a text prompt), followed by injection of conditional prompt for semantic mixing. Our method does not require any spatial mask or re-training, yet is able to synthesize novel objects with high fidelity. To improve the mixing quality, we further devise two simple strategies to provide better control and flexibility over the synthesized content. With our method, we present our results over diverse downstream applications, including semantic style transfer, novel object synthesis, breed mixing, and concept removal, demonstrating the flexibility of our method. More results can be found on the project page https://magicmix.github.io
Deep Image Deblurring: A Survey
Jan 26, 2022
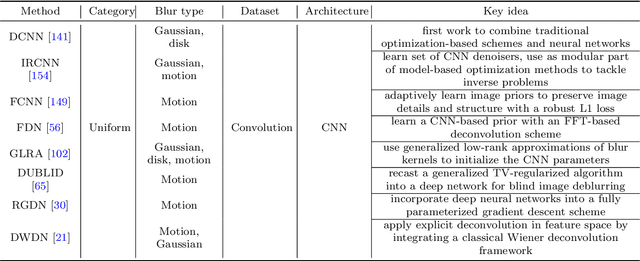
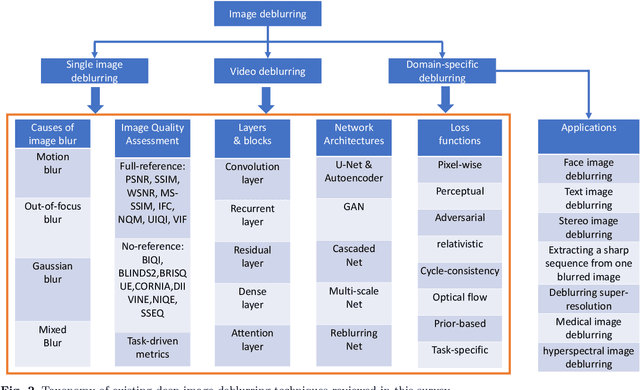
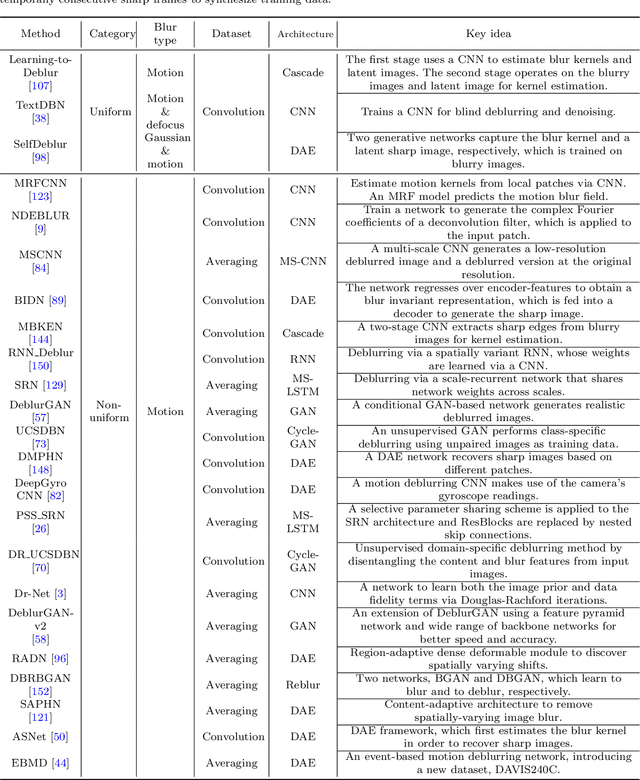
Image deblurring is a classic problem in low-level computer vision, which aims to recover a sharp image from a blurred input image. Recent advances in deep learning have led to significant progress in solving this problem, and a large number of deblurring networks have been proposed. This paper presents a comprehensive and timely survey of recently published deep-learning based image deblurring approaches, aiming to serve the community as a useful literature review. We start by discussing common causes of image blur, introduce benchmark datasets and performance metrics, and summarize different problem formulations. Next we present a taxonomy of methods using convolutional neural networks (CNN) based on architecture, loss function, and application, offering a detailed review and comparison. In addition, we discuss some domain-specific deblurring applications including face images, text, and stereo image pairs. We conclude by discussing key challenges and future research directions.