 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improved Deep Neural Network Generalization Using m-Sharpness-Aware Minimization
Dec 07, 2022

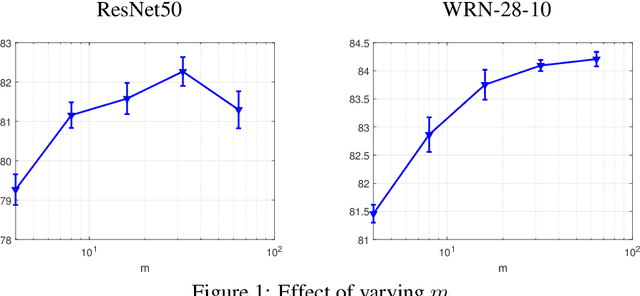
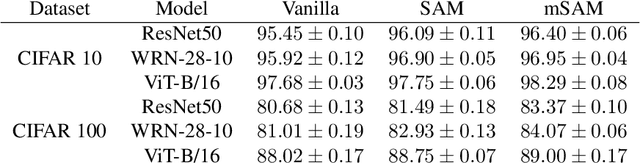

Modern deep learning models are over-parameterized, where the optimization setup strongly affects the generalization performance. A key element of reliable optimization for these systems is the modification of the loss function. Sharpness-Aware Minimization (SAM) modifies the underlying loss function to guide descent methods towards flatter minima, which arguably have better generalization abilities. In this paper, we focus on a variant of SAM known as mSAM, which, during training, averages the updates generated by adversarial perturbations across several disjoint shards of a mini-batch. Recent work suggests that mSAM can outperform SAM in terms of test accuracy. However, a comprehensive empirical study of mSAM is missing from the literature -- previous results have mostly been limited to specific architectures and datasets. To that end, this paper presents a thorough empirical evaluation of mSAM on various tasks and datasets. We provide a flexible implementation of mSAM and compare the generalization performance of mSAM to the performance of SAM and vanilla training on different image classification and natural language processing tasks. We also conduct careful experiments to understand the computational cost of training with mSAM, its sensitivity to hyperparameters and its correlation with the flatness of the loss landscape. Our analysis reveals that mSAM yields superior generalization performance and flatter minima, compared to SAM, across a wide range of tasks without significantly increasing computational costs.
Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
Oct 09, 2022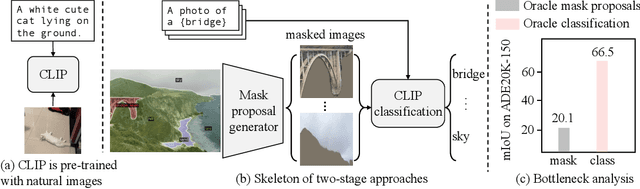
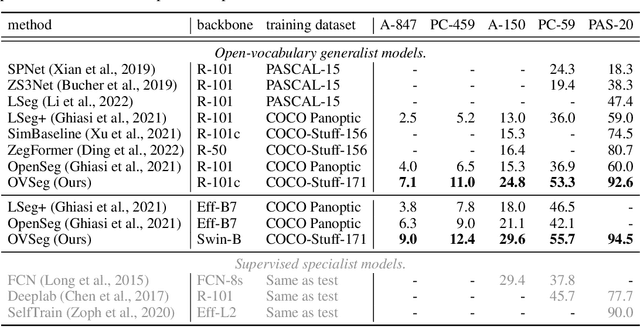
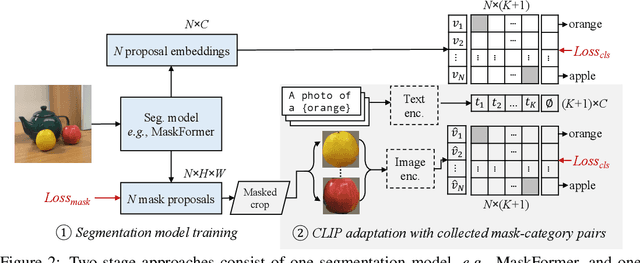
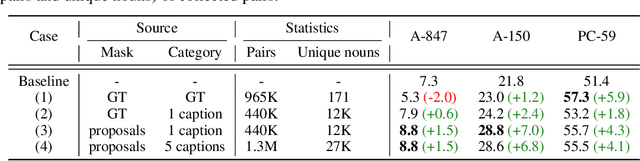
Open-vocabulary semantic segmentation aims to segment an image into semantic regions according to text descriptions, which may not have been seen during training. Recent two-stage methods first generate class-agnostic mask proposals and then leverage pre-trained vision-language models, e.g., CLIP, to classify masked regions. We identify the performance bottleneck of this paradigm to be the pre-trained CLIP model, since it does not perform well on masked images. To address this, we propose to finetune CLIP on a collection of masked image regions and their corresponding text descriptions. We collect training data by mining an existing image-caption dataset (e.g., COCO Captions), using CLIP to match masked image regions to nouns in the image captions. Compared with the more precise and manually annotated segmentation labels with fixed classes (e.g., COCO-Stuff), we find our noisy but diverse dataset can better retain CLIP's generalization ability. Along with finetuning the entire model, we utilize the "blank" areas in masked images using a method we dub mask prompt tuning. Experiments demonstrate mask prompt tuning brings significant improvement without modifying any weights of CLIP, and it can further improve a fully finetuned model. In particular, when trained on COCO and evaluated on ADE20K-150, our best model achieves 29.6% mIoU, which is +8.5% higher than the previous state-of-the-art. For the first time, open-vocabulary generalist models match the performance of supervised specialist models in 2017 without dataset-specific adaptations.
Convolutional Neural Generative Coding: Scaling Predictive Coding to Natural Images
Nov 22, 2022
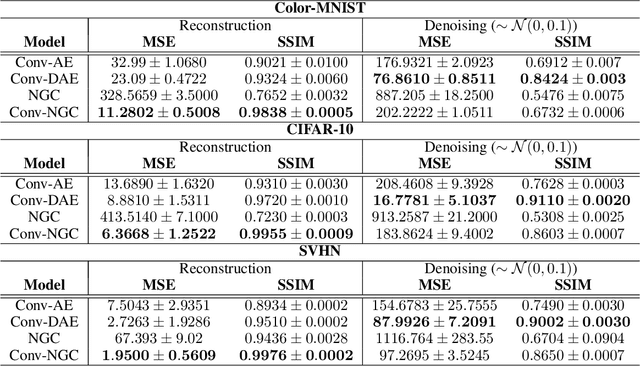
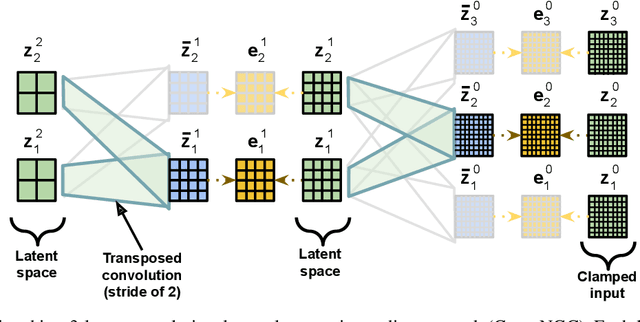
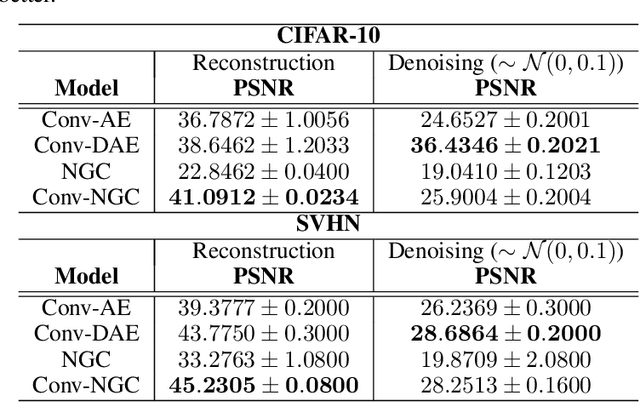
In this work, we develop convolutional neural generative coding (Conv-NGC), a generalization of predictive coding to the case of convolution/deconvolution-based computation. Specifically, we concretely implement a flexible neurobiologically-motivated algorithm that progressively refines latent state maps in order to dynamically form a more accurate internal representation/reconstruction model of natural images. The performance of the resulting sensory processing system is evaluated on several benchmark datasets such as Color-MNIST, CIFAR-10, and Street House View Numbers (SVHN). We study the effectiveness of our brain-inspired neural system on the tasks of reconstruction and image denoising and find that it is competitive with convolutional auto-encoding systems trained by backpropagation of errors and notably outperforms them with respect to out-of-distribution reconstruction (including on the full 90k CINIC-10 test set).
Realistic Endoscopic Image Generation Method Using Virtual-to-real Image-domain Translation
Jan 13, 2022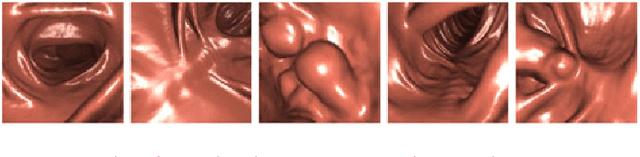
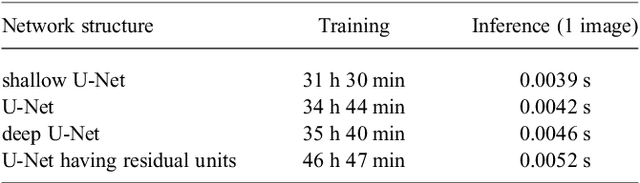
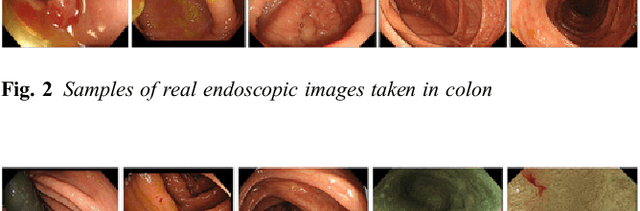
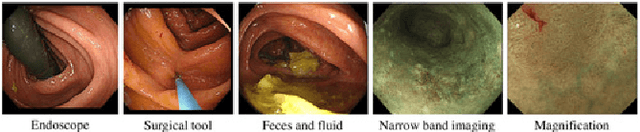
This paper proposes a realistic image generation method for visualization in endoscopic simulation systems. Endoscopic diagnosis and treatment are performed in many hospitals. To reduce complications related to endoscope insertions, endoscopic simulation systems are used for training or rehearsal of endoscope insertions. However, current simulation systems generate non-realistic virtual endoscopic images. To improve the value of the simulation systems, improvement of reality of their generated images is necessary. We propose a realistic image generation method for endoscopic simulation systems. Virtual endoscopic images are generated by using a volume rendering method from a CT volume of a patient. We improve the reality of the virtual endoscopic images using a virtual-to-real image-domain translation technique. The image-domain translator is implemented as a fully convolutional network (FCN). We train the FCN by minimizing a cycle consistency loss function. The FCN is trained using unpaired virtual and real endoscopic images. To obtain high quality image-domain translation results, we perform an image cleansing to the real endoscopic image set. We tested to use the shallow U-Net, U-Net, deep U-Net, and U-Net having residual units as the image-domain translator. The deep U-Net and U-Net having residual units generated quite realistic images.
* Accepted paper as an oral presentation at the Joint MICCAI workshop MIAR | AE-CAI | CARE 2019
CMT: Interpretable Model for Rapid Recognition Pneumonia from Chest X-Ray Images by Fusing Low Complexity Multilevel Attention Mechanism
Oct 29, 2022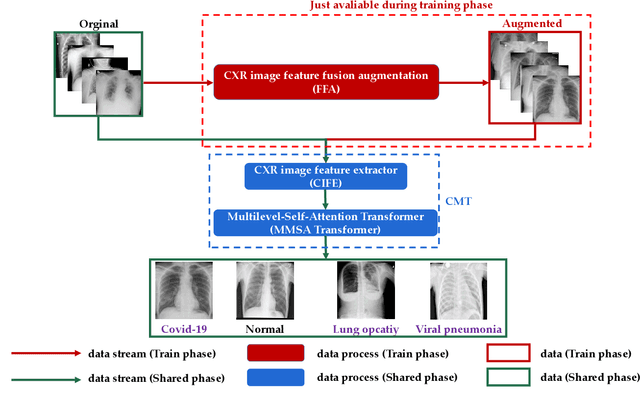
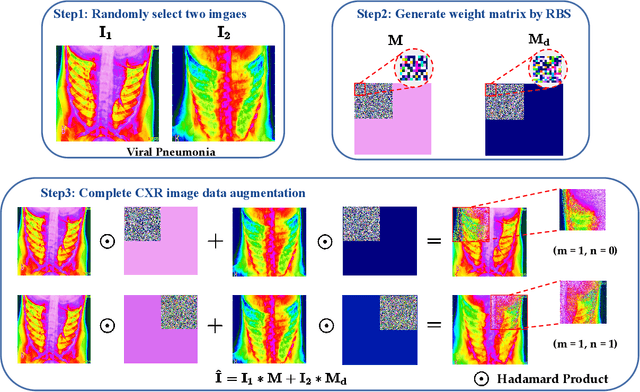
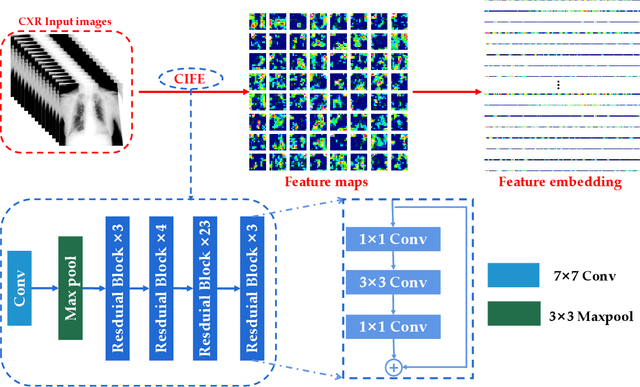
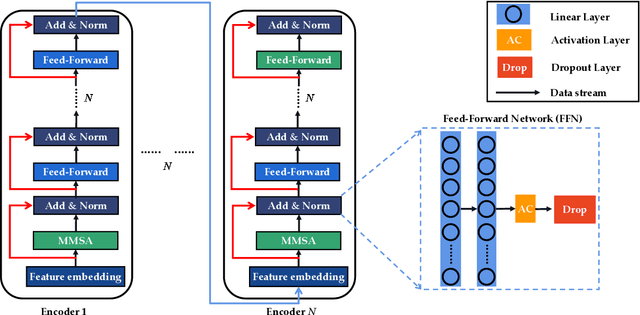
Chest imaging plays an essential role in diagnosing and predicting patients with COVID-19 with evidence of worsening respiratory status. Many deep learning-based diagnostic models for pneumonia have been developed to enable computer-aided diagnosis. However, the long training and inference time make them inflexible. In addition, the lack of interpretability reduces their credibility in clinical medical practice. This paper presents CMT, a model with interpretability and rapid recognition of pneumonia, especially COVID-19 positive. Multiple convolutional layers in CMT are first used to extract features in CXR images, and then Transformer is applied to calculate the possibility of each symptom. To improve the model's generalization performance and to address the problem of sparse medical image data, we propose Feature Fusion Augmentation (FFA), a plug-and-play method for image augmentation. It fuses the features of the two images to varying degrees to produce a new image that does not deviate from the original distribution. Furthermore, to reduce the computational complexity and accelerate the convergence, we propose Multilevel Multi-Head Self-Attention (MMSA), which computes attention on different levels to establish the relationship between global and local features. It significantly improves the model performance while substantially reducing its training and inference time. Experimental results on the largest COVID-19 dataset show the proposed CMT has state-of-the-art performance. The effectiveness of FFA and MMSA is demonstrated in the ablation experiments. In addition, the weights and feature activation maps of the model inference process are visualized to show the CMT's interpretability.
Semantics-Guided Object Removal for Facial Images: with Broad Applicability and Robust Style Preservation
Sep 29, 2022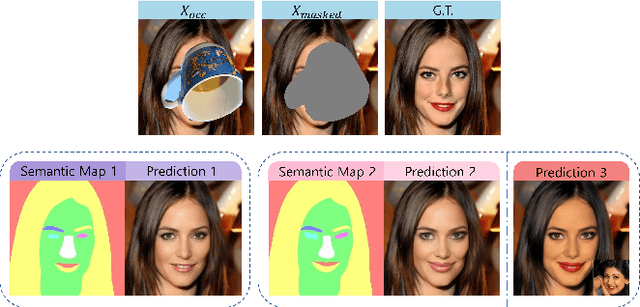

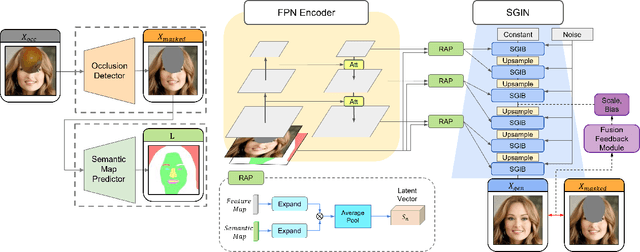
Object removal and image inpainting in facial images is a task in which objects that occlude a facial image are specifically targeted, removed, and replaced by a properly reconstructed facial image. Two different approaches utilizing U-net and modulated generator respectively have been widely endorsed for this task for their unique advantages but notwithstanding each method's innate disadvantages. U-net, a conventional approach for conditional GANs, retains fine details of unmasked regions but the style of the reconstructed image is inconsistent with the rest of the original image and only works robustly when the size of the occluding object is small enough. In contrast, the modulated generative approach can deal with a larger occluded area in an image and provides {a} more consistent style, yet it usually misses out on most of the detailed features. This trade-off between these two models necessitates an invention of a model that can be applied to any size of mask while maintaining a consistent style and preserving minute details of facial features. Here, we propose Semantics-Guided Inpainting Network (SGIN) which itself is a modification of the modulated generator, aiming to take advantage of its advanced generative capability and preserve the high-fidelity details of the original image. By using the guidance of a semantic map, our model is capable of manipulating facial features which grants direction to the one-to-many problem for further practicability.
CycDA: Unsupervised Cycle Domain Adaptation from Image to Video
Mar 30, 2022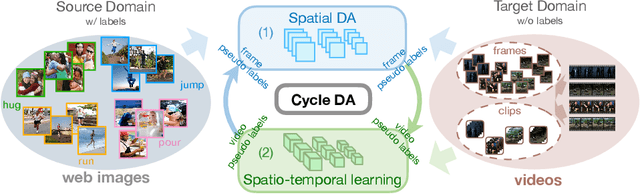
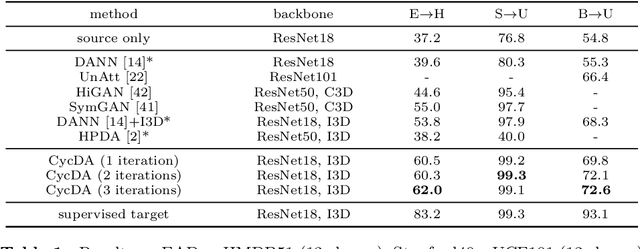
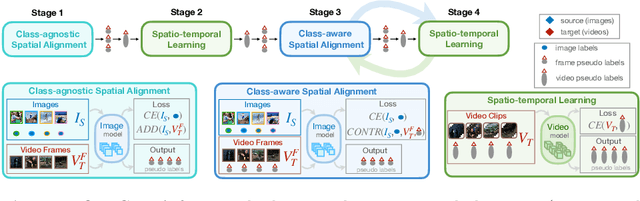
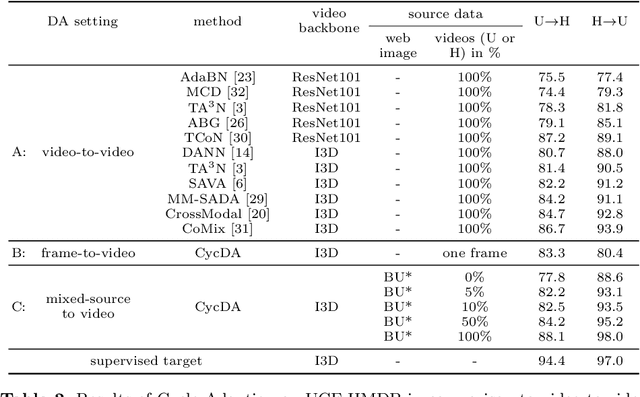
Although action recognition has achieved impressive results over recent years, both collection and annotation of video training data are still time-consuming and cost intensive. Therefore, image-to-video adaptation has been proposed to exploit labeling-free web image source for adapting on unlabeled target videos. This poses two major challenges: (1) spatial domain shift between web images and video frames; (2) modality gap between image and video data. To address these challenges, we propose Cycle Domain Adaptation (CycDA), a cycle-based approach for unsupervised image-to-video domain adaptation by leveraging the joint spatial information in images and videos on the one hand and, on the other hand, training an independent spatio-temporal model to bridge the modality gap. We alternate between the spatial and spatio-temporal learning with knowledge transfer between the two in each cycle. We evaluate our approach on benchmark datasets for image-to-video as well as for mixed-source domain adaptation achieving state-of-the-art results and demonstrating the benefits of our cyclic adaptation.
Latent-NeRF for Shape-Guided Generation of 3D Shapes and Textures
Nov 14, 2022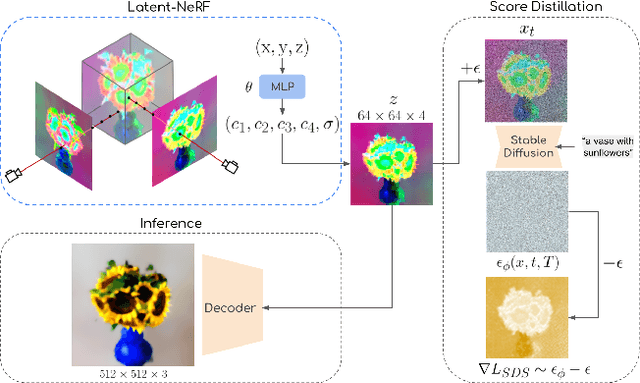
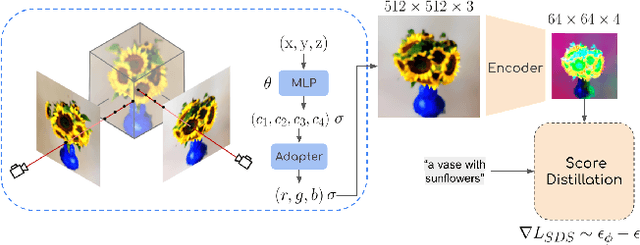
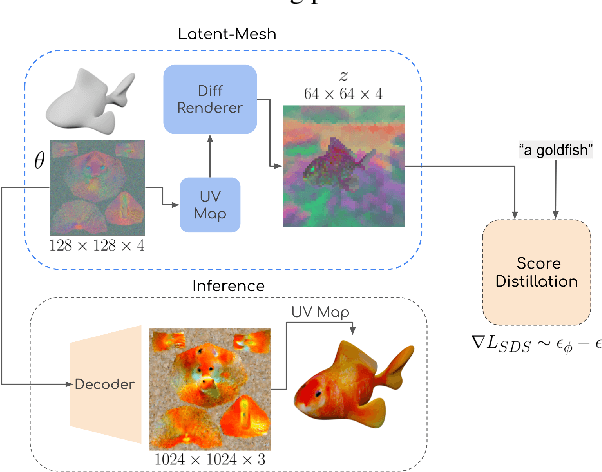
Text-guided image generation has progressed rapidly in recent years, inspiring major breakthroughs in text-guided shape generation. Recently, it has been shown that using score distillation, one can successfully text-guide a NeRF model to generate a 3D object. We adapt the score distillation to the publicly available, and computationally efficient, Latent Diffusion Models, which apply the entire diffusion process in a compact latent space of a pretrained autoencoder. As NeRFs operate in image space, a naive solution for guiding them with latent score distillation would require encoding to the latent space at each guidance step. Instead, we propose to bring the NeRF to the latent space, resulting in a Latent-NeRF. Analyzing our Latent-NeRF, we show that while Text-to-3D models can generate impressive results, they are inherently unconstrained and may lack the ability to guide or enforce a specific 3D structure. To assist and direct the 3D generation, we propose to guide our Latent-NeRF using a Sketch-Shape: an abstract geometry that defines the coarse structure of the desired object. Then, we present means to integrate such a constraint directly into a Latent-NeRF. This unique combination of text and shape guidance allows for increased control over the generation process. We also show that latent score distillation can be successfully applied directly on 3D meshes. This allows for generating high-quality textures on a given geometry. Our experiments validate the power of our different forms of guidance and the efficiency of using latent rendering. Implementation is available at https://github.com/eladrich/latent-nerf
ConchShell: A Generative Adversarial Networks that Turns Pictures into Piano Music
Oct 11, 2022

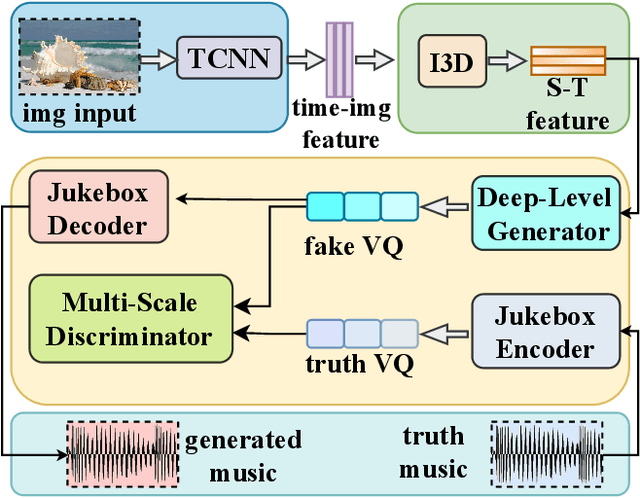
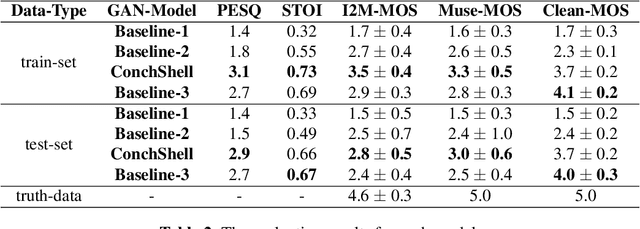
We present ConchShell, a multi-modal generative adversarial framework that takes pictures as input to the network and generates piano music samples that match the picture context. Inspired by I3D, we introduce a novel image feature representation method: time-convolutional neural network (TCNN), which is used to forge features for images in the temporal dimension. Although our image data consists of only six categories, our proposed framework will be innovative and commercially meaningful. The project will provide technical ideas for work such as 3D game voice overs, short-video soundtracks, and real-time generation of metaverse background music.We have also released a new dataset, the Beach-Ocean-Piano Dataset (BOPD) 1, which contains more than 3,000 images and more than 1,500 piano pieces. This dataset will support multimodal image-to-music research.
Exemplar Guided Deep Neural Network for Spatial Transcriptomics Analysis of Gene Expression Prediction
Oct 30, 2022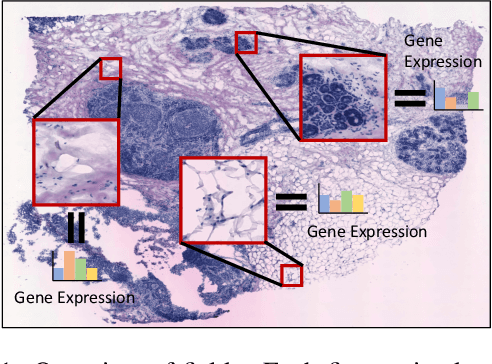
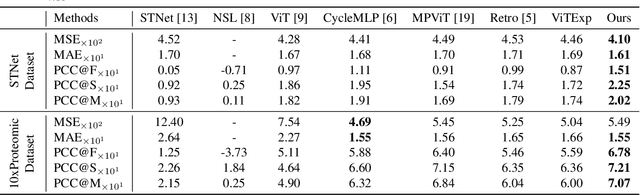
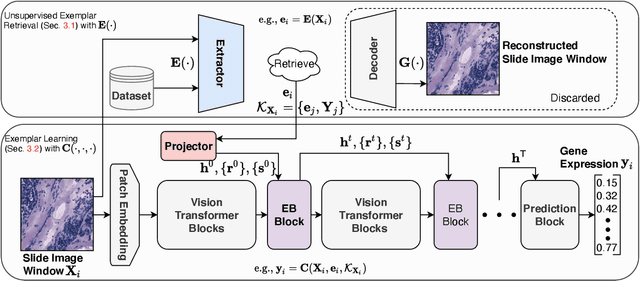
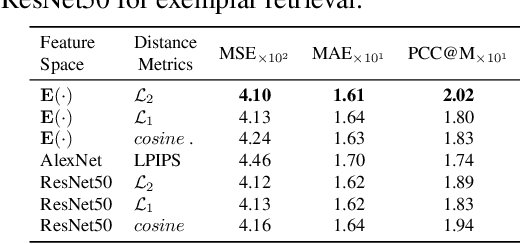
Spatial transcriptomics (ST) is essential for understanding diseases and developing novel treatments. It measures gene expression of each fine-grained area (i.e., different windows) in the tissue slide with low throughput. This paper proposes an Exemplar Guided Network (EGN) to accurately and efficiently predict gene expression directly from each window of a tissue slide image. We apply exemplar learning to dynamically boost gene expression prediction from nearest/similar exemplars of a given tissue slide image window. Our EGN framework composes of three main components: 1) an extractor to structure a representation space for unsupervised exemplar retrievals; 2) a vision transformer (ViT) backbone to progressively extract representations of the input window; and 3) an Exemplar Bridging (EB) block to adaptively revise the intermediate ViT representations by using the nearest exemplars. Finally, we complete the gene expression prediction task with a simple attention-based prediction block. Experiments on standard benchmark datasets indicate the superiority of our approach when comparing with the past state-of-the-art (SOTA) methods.